
Добавление возможностей разделения кода на веб-сайт WordPress через PoP
Опубликовано: 2022-03-10Скорость является одним из главных приоритетов для любого веб-сайта в настоящее время. Один из способов ускорить загрузку веб-сайта — это разделение кода: разделение приложения на фрагменты, которые можно загружать по запросу — загрузка только необходимого JavaScript и ничего больше. Веб-сайты, основанные на фреймворках JavaScript, могут сразу реализовать разделение кода с помощью Webpack, популярного сборщика JavaScript. Однако для веб-сайтов WordPress это не так просто. Во-первых, Webpack не создавался специально для работы с WordPress, поэтому для его настройки потребуется некоторое обходное решение; во-вторых, кажется, нет доступных инструментов, которые обеспечивают встроенные возможности загрузки ресурсов по запросу для WordPress.
Учитывая отсутствие подходящего решения для WordPress, я решил реализовать свою собственную версию разделения кода для PoP, созданной мной платформы с открытым исходным кодом для создания веб-сайтов WordPress. Веб-сайт WordPress с установленным PoP будет изначально иметь возможности разделения кода, поэтому ему не нужно будет зависеть от Webpack или любого другого сборщика. В этой статье я покажу вам, как это делается, объяснив, какие решения были приняты на основе аспектов архитектуры фреймворка. В конце я проанализирую производительность веб-сайта с разделением кода и без него, а также преимущества и недостатки использования пользовательской реализации по сравнению с внешним сборщиком. Надеюсь, вам понравится поездка!
Определение стратегии
Разделение кода можно условно разделить на два этапа:
- Расчет того, какие активы должны быть загружены для каждого маршрута,
- Динамическая загрузка этих активов по требованию.
Чтобы выполнить первый шаг, нам нужно будет создать карту зависимостей активов, включая все активы в нашем приложении. Ассеты должны добавляться к этой карте рекурсивно — также должны добавляться зависимости зависимостей, пока больше не понадобится ассет. Затем мы можем вычислить все зависимости, необходимые для конкретного маршрута, пройдя карту зависимостей ресурсов, начиная с точки входа маршрута (т. е. файла или фрагмента кода, с которого он начинает выполнение) вплоть до последнего уровня.
Чтобы решить второй шаг, мы могли бы вычислить, какие ресурсы необходимы для запрошенного URL-адреса на стороне сервера, а затем либо отправить список необходимых ресурсов в ответ, после чего приложение должно будет их загрузить, либо напрямую HTTP/ 2 подтолкнуть ресурсы вместе с ответом.
Однако эти решения не являются оптимальными. В первом случае приложение должно запросить все активы после того, как будет возвращен ответ, поэтому будет дополнительная серия запросов туда и обратно для извлечения активов, и представление не может быть создано до того, как все они будут загружены, что приведет к пользователю приходится ждать (эта проблема облегчается за счет предварительного кэширования всех ресурсов через сервис-воркеров, поэтому время ожидания сокращается, но мы не можем избежать синтаксического анализа ресурсов, который происходит только после получения ответа). Во втором случае мы можем многократно отправлять одни и те же активы (если только мы не добавим дополнительную логику, например, указать, какие ресурсы мы уже загрузили с помощью файлов cookie, но это действительно добавляет нежелательной сложности и блокирует кеширование ответа), и мы не может обслуживать активы из CDN.
Из-за этого я решил, что эта логика будет обрабатываться на стороне клиента. Список ресурсов, необходимых для каждого маршрута, предоставляется приложению на клиенте, поэтому оно уже знает, какие ресурсы необходимы для запрошенного URL-адреса. Это решает проблемы, указанные выше:
- Ресурсы можно загружать сразу, не дожидаясь ответа сервера. (Когда мы объединяем это с сервис-воркерами, мы можем быть уверены, что к моменту получения ответа все ресурсы будут загружены и проанализированы, так что дополнительное время ожидания не потребуется.)
- Приложение знает, какие активы уже загружены; следовательно, он не будет запрашивать все активы, необходимые для этого маршрута, а только те активы, которые еще не загружены.
Отрицательный аспект доставки этого списка на внешний интерфейс заключается в том, что он может стать тяжелым в зависимости от размера веб-сайта (например, от того, сколько маршрутов он предоставляет). Нам нужно найти способ загрузить его, не увеличивая воспринимаемое время загрузки приложения. Подробнее об этом позже.
Приняв эти решения, мы можем приступить к проектированию, а затем реализовать разделение кода в приложении. Для облегчения понимания процесс разбит на следующие этапы:
- Понимание архитектуры приложения,
- Отображение зависимостей активов,
- Список всех маршрутов приложений,
- Создание списка, который определяет, какие активы необходимы для каждого маршрута,
- Динамическая загрузка активов,
- Применение оптимизаций.
Давайте прямо в это!
0. Понимание архитектуры приложения
Нам нужно будет отобразить взаимосвязь всех активов друг с другом. Давайте рассмотрим особенности архитектуры PoP, чтобы разработать наиболее подходящее решение для достижения этой цели.
PoP — это слой, который охватывает WordPress, позволяя нам использовать WordPress в качестве CMS, на которой работает приложение, и в то же время предоставляя настраиваемую среду JavaScript для рендеринга контента на стороне клиента для создания динамических веб-сайтов. Он переопределяет компоненты построения веб-страницы: в то время как WordPress в настоящее время основан на концепции иерархических шаблонов, которые создают HTML (таких как single.php , home.php и archive.php ), PoP основан на концепции «модулей, ”, которые являются либо атомарной функциональностью, либо композицией других модулей. Создание PoP-приложения сродни игре с LEGO — укладывание модулей друг на друга или оборачивание друг друга, что в конечном итоге создает более сложную структуру. Его также можно рассматривать как реализацию атомарного дизайна Брэда Фроста, и он выглядит так:
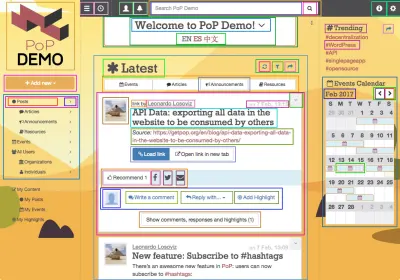
Модули могут быть сгруппированы в объекты более высокого порядка, а именно: блоки, группы блоков, разделы страниц и верхние уровни. Эти сущности тоже являются модулями, только с дополнительными свойствами и обязанностями, и они содержат друг друга в соответствии со строго нисходящей архитектурой, в которой каждый модуль может видеть и изменять свойства всех своих внутренних модулей. Отношения между модулями таковы:
- 1 верхний уровень содержит N pageSections,
- 1 pageSection содержит N блоков или групп блоков,
- 1 группа блоков содержит N блоков или групп блоков,
- 1 блок содержит N модулей,
- 1 модуль содержит N модулей, до бесконечности.
Выполнение кода JavaScript в PoP
PoP динамически создает HTML, начиная с уровня pageSection, последовательно проходя все модули, отображая каждый из них с помощью предопределенного шаблона Handlebars модуля и, наконец, добавляя соответствующие вновь созданные элементы модуля в DOM. Как только это сделано, он выполняет над ними функции JavaScript, которые предопределены для каждого модуля.
PoP отличается от фреймворков JavaScript (таких как React и AngularJS) тем, что поток приложения не возникает на клиенте, но по-прежнему настраивается на бэкэнде внутри конфигурации модуля (который закодирован в объекте PHP). Под влиянием хуков действий WordPress PoP реализует шаблон публикации-подписки:
- Каждый модуль определяет, какие функции JavaScript должны выполняться в соответствующих вновь созданных элементах DOM, не обязательно заранее зная, что будет выполнять этот код или откуда он возьмется.
- Объекты JavaScript должны регистрировать, какие функции JavaScript они реализуют.
- Наконец, во время выполнения PoP вычисляет, какие объекты JavaScript должны выполнять какие функции JavaScript, и вызывает их соответствующим образом.
Например, через соответствующий объект PHP модуль календаря указывает, что ему нужно, чтобы функция calendar выполнялась на его элементах DOM, например:
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } Затем объект JavaScript — в данном случае popFullCalendar — объявляет о реализации функции calendar . Это делается путем вызова popJSLibraryManager.register :
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); Наконец, popJSLibraryManager сопоставляет, что и какой код выполняет. Он позволяет объектам JavaScript регистрировать, какие функции они реализуют, и предоставляет метод для выполнения определенной функции из всех подписанных объектов JavaScript:
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } После добавления в DOM нового элемента календаря с идентификатором calendar-293 PoP просто выполнит следующую функцию:
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));Входная точка
Для PoP точкой входа для выполнения кода JavaScript является эта строка в конце вывода HTML:
<script type="text/javascript">popManager.init();</script> popManager.init() сначала инициализирует интерфейсную структуру, а затем выполняет функции JavaScript, определенные всеми отрендеренными модулями, как описано выше. Ниже приведена очень упрощенная форма этой функции (исходный код находится на GitHub). При вызове popJSLibraryManager.execute('pageSectionInitialized', pageSection) и popJSLibraryManager.execute('documentInitialized') все объекты JavaScript, реализующие эти функции ( pageSectionInitialized и documentInitialized ), будут выполнять их.
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); Функция runJSMethods выполняет методы JavaScript, определенные для каждого модуля, начиная с pageSection, который является самым верхним модулем, а затем для всех его внутренних блоков и их внутренних модулей:
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);Таким образом, выполнение JavaScript в PoP слабо связано: вместо жестко фиксированных зависимостей мы выполняем функции JavaScript через хуки, на которые может подписаться любой объект JavaScript.
Веб-страницы и API
Веб-сайт PoP — это самостоятельный API. В PoP нет различия между веб-страницей и API: каждый URL-адрес по умолчанию возвращает веб-страницу, а просто добавив параметр output=json , он вместо этого возвращает свой API (например, getpop.org/en/ — это веб-страница, а getpop.org/en/?output=json — ее API). API используется для динамического рендеринга контента в PoP; поэтому при нажатии на ссылку на другую страницу запрашивается API, потому что к тому времени будет загружен фрейм веб-сайта (например, верхняя и боковая навигация) — тогда набор ресурсов, необходимых для режима API, будет быть подмножеством этого с веб-страницы. Нам нужно будет принять это во внимание при расчете зависимостей для маршрута: загрузка маршрута при первой загрузке веб-сайта или его динамическая загрузка при нажатии на какую-либо ссылку приведет к созданию разных наборов необходимых ресурсов.
Это самые важные аспекты PoP, которые будут определять дизайн и реализацию разделения кода. Приступим к следующему шагу.
1. Отображение зависимостей активов
Мы могли бы добавить файл конфигурации для каждого файла JavaScript с подробным описанием их явных зависимостей. Однако это приведет к дублированию кода, и его будет трудно поддерживать согласованность. Более чистым решением было бы сохранить файлы JavaScript как единственный источник правды, извлекая из них код и затем анализируя этот код для воссоздания зависимостей.
Метаданные, которые мы ищем в исходных файлах JavaScript, чтобы иметь возможность воссоздать сопоставление, следующие:
- внутренние вызовы методов, такие как
this.runJSMethods(...); - вызовы внешних методов, таких как
popJSRuntimeManager.getDOMElements(...); - все вхождения
popJSLibraryManager.execute(...), которые выполняют функцию JavaScript во всех тех объектах, которые ее реализуют; - все вхождения
popJSLibraryManager.register(...), чтобы узнать, какие объекты JavaScript реализуют какие методы JavaScript.
Мы будем использовать jParser и jTokenizer для токенизации наших исходных файлов JavaScript в PHP и извлечения метаданных следующим образом:
- Внутренние вызовы методов (типа
this.runJSMethods) выводятся при нахождении следующей последовательности: либо токенthis, либоthat+.+ какой-то другой токен, который является именем для внутреннего метода (runJSMethods). - Вызовы внешних методов (типа
popJSRuntimeManager.getDOMElements) выводятся при нахождении следующей последовательности: токен, включенный в список всех объектов JavaScript в нашем приложении (этот список нам понадобится заранее, в данном случае он будет содержать объектpopJSRuntimeManager) +.+ какой-то другой токен, который является именем для внешнего метода (getDOMElements). - Всякий раз, когда мы находим
popJSLibraryManager.execute("someFunctionName"), мы выводим метод Javascript какsomeFunctionName. - Всякий раз, когда мы находим
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"]), мы выводим объект JavascriptsomeJSObjectдля реализации методовsomeFunctionName1,someFunctionName2.
Я реализовал скрипт, но не буду описывать его здесь. (Это слишком долго, это не добавляет ценности, но его можно найти в репозитории PoP). Скрипт, который запускается при запросе внутренней страницы на сервере разработки веб-сайта (методология, о которой я писал в предыдущей статье о сервис-воркерах), сгенерирует файл сопоставления и сохранит его на сервере. Я подготовил пример сгенерированного файла сопоставления. Это простой файл JSON, содержащий следующие атрибуты:
-
internalMethodCalls
Для каждого объекта JavaScript перечислите зависимости от внутренних функций между собой. -
externalMethodCalls
Для каждого объекта JavaScript перечислите зависимости внутренних функций от функций других объектов JavaScript. -
publicMethods
Перечислите все зарегистрированные методы и для каждого метода укажите, какие объекты JavaScript его реализуют. -
methodExecutions
Для каждого объекта JavaScript и каждой внутренней функции перечислите все методы, выполняемые черезpopJSLibraryManager.execute('someMethodName').
Обратите внимание, что в результате получается не карта зависимостей активов, а скорее карта зависимостей объектов JavaScript. Из этой карты мы можем установить, всякий раз, когда выполняется функция какого-либо объекта, какие другие объекты также потребуются. Нам по-прежнему нужно настроить, какие объекты JavaScript содержатся в каждом ассете, для всех ассетов (в скрипте jTokenizer объекты JavaScript — это токены, которые мы ищем для идентификации вызовов внешних методов, поэтому эта информация является входной для скрипта и может нельзя получить из самих исходных файлов). Это делается с помощью PHP-объектов ResourceLoaderProcessor , таких как resourceloader-processor.php.
Наконец, объединив карту и конфигурацию, мы сможем рассчитать все необходимые активы для каждого маршрута в приложении.
2. Список всех маршрутов приложений
Нам нужно определить все маршруты, доступные в нашем приложении. Для веб-сайта WordPress этот список будет начинаться с URL-адреса из каждой иерархии шаблонов. Те, которые реализованы для PoP, следующие:
- домашняя страница: https://getpop.org/en/
- автор: https://getpop.org/en/u/leo/
- сингл: https://getpop.org/en/blog/new-feature-code-splitting/
- тег: https://getpop.org/en/tags/internet/
- страница: https://getpop.org/en/philosophy/
- категория: https://getpop.org/en/blog/ (категория фактически реализована как страница, чтобы удалить
category/из пути URL) - 404: https://getpop.org/en/this-page-does-not-exist/
Для каждой из этих иерархий мы должны получить все маршруты, создающие уникальную конфигурацию (т. е. требующие уникального набора ресурсов). В случае PoP имеем следующее:
- домашняя страница и 404 уникальны.
- Страницы тегов всегда имеют одинаковую конфигурацию для любого тега. Таким образом, одного URL для любого тега будет достаточно.
- Отдельный пост зависит от комбинации типа поста (например, «событие» или «публикация») и основной категории поста (например, «блог» или «статья»). Затем нам нужен URL для каждой из этих комбинаций.
- Конфигурация страницы категории зависит от категории. Итак, нам понадобится URL каждой категории сообщений.
- Страница автора зависит от роли автора («индивидуальное лицо», «организация» или «сообщество»). Итак, нам понадобятся URL-адреса для трех авторов, каждый из которых имеет одну из этих ролей.
- Каждая страница может иметь свою конфигурацию («войти», «связаться с нами», «наша миссия» и т. д.). Таким образом, все URL-адреса страниц должны быть добавлены в список.
Как видим, список уже довольно длинный. Кроме того, наше приложение может добавлять параметры к URL-адресу, которые изменяют конфигурацию, потенциально также изменяя требуемые активы. PoP, например, предлагает добавить следующие параметры URL:
- вкладка (
?tab=…), чтобы показать соответствующую информацию: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors; - формат (
?format=…), чтобы изменить способ отображения данных: https://getpop.org/en/blog/?format=list; - target (
?target=…), чтобы открыть страницу в другом разделе pageSection: https://getpop.org/en/add-post/?target=addons.
Некоторые из начальных маршрутов могут иметь один, два или даже три указанных выше параметра, что создает широкий спектр комбинаций:
- отдельный пост: https://getpop.org/en/blog/new-feature-code-splitting/
- авторы отдельных сообщений: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- авторов отдельных сообщений в виде списка: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- авторов отдельных сообщений в виде списка в модальном окне: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
Таким образом, для PoP все возможные маршруты представляют собой комбинацию следующих элементов:
- все первоначальные маршруты иерархии шаблонов;
- все разные значения, для которых иерархия создаст другую конфигурацию;
- все возможные вкладки для каждой иерархии (разные иерархии могут иметь разные значения вкладок: у одного сообщения могут быть вкладки «авторы» и «ответы», а у автора могут быть вкладки «сообщения» и «подписчики»);
- все возможные форматы для каждой вкладки (для разных вкладок могут быть применены разные форматы: вкладка «авторы» может иметь формат «карта», а вкладка «ответы» может не иметь);
- все возможные цели с указанием разделов страниц, где может отображаться каждый маршрут (пост может быть создан в основном разделе или в плавающем окне, страница «Поделиться с друзьями» может быть настроена на открытие в модальном окне).
Следовательно, для немного сложного приложения создание списка со всеми маршрутами не может быть выполнено вручную. Затем мы должны создать сценарий для извлечения этой информации из базы данных, манипулирования ею и, наконец, вывода ее в нужном формате. Этот сценарий получит все категории сообщений, из которых мы можем создать список всех различных URL-адресов страниц категорий, а затем для каждой категории запросить в базе данных любое сообщение в той же категории, что даст URL-адрес для одного опубликовать в каждой категории и так далее. Доступен полный сценарий, начиная с function get_resources() , которая предоставляет хуки, которые должны быть реализованы в каждом из случаев иерархии.
3. Генерация списка, который определяет, какие активы необходимы для каждого маршрута
К настоящему времени у нас есть карта зависимостей ресурсов и список всех маршрутов в приложении. Настало время объединить эти два подхода и создать список, в котором для каждого маршрута указано, какие активы требуются.
Чтобы создать этот список, мы применяем следующую процедуру:
- Создайте список, содержащий все методы JavaScript, которые должны выполняться для каждого маршрута:
Рассчитайте модули маршрута, затем получите конфигурацию для каждого модуля, затем извлеките из конфигурации функции JavaScript, которые модуль должен выполнять, и добавьте их все вместе. - Затем просмотрите карту зависимостей активов для каждой функции JavaScript, соберите список всех необходимых зависимостей и сложите их все вместе.
- Наконец, добавьте шаблоны Handlebars, необходимые для отображения каждого модуля внутри этого маршрута.
Кроме того, как указывалось ранее, у каждого URL-адреса есть режимы веб-страницы и API, поэтому нам нужно запустить описанную выше процедуру дважды, по одному разу для каждого режима (т. е. один раз добавить параметр output=json к URL-адресу, представляющему маршрут для режима API, и один раз сохраняя URL-адрес без изменений для режима веб-страницы). Затем мы создадим два списка, которые будут использоваться по-разному:

- Список режимов веб-страницы будет использоваться при первоначальной загрузке веб-сайта, поэтому соответствующие сценарии для этого маршрута будут включены в исходный HTML-ответ. Этот список будет храниться на сервере.
- Список режимов API будет использоваться при динамической загрузке страницы на сайте. Этот список будет загружен на клиенте, чтобы приложение могло рассчитать, какие дополнительные активы должны быть загружены по запросу при нажатии на ссылку.
Основная часть логики была реализована, начиная с function add_resources_from_settingsprocessors($fetching_json, ...) (ее можно найти в репозитории). Параметр $fetching_json различает режимы веб-страницы ( false ) и API ( true ).
Когда скрипт для режима веб-страницы запускается, он выводит resourceloader-bundle-mapping.json, который представляет собой объект JSON со следующими свойствами:
-
bundle-ids
Это набор до четырех ресурсов (их имена были искажены для производственной среды:eq=>handlebars,er=>handlebars-helpersи т. д.), сгруппированных под идентификатором пакета. -
bundlegroup-ids
Это наборbundle-ids. Каждая группа bundleGroup представляет уникальный набор ресурсов. -
key-ids
Это сопоставление между маршрутами (представленными их хэшем, который идентифицирует набор всех атрибутов, делающих маршрут уникальным) и соответствующей им группой пакетов.
Как можно заметить, сопоставление между маршрутом и его ресурсами не является прямым. Вместо сопоставления key-ids со списком ресурсов он сопоставляет их с уникальной группой bundleGroup, которая сама является списком bundles , и только каждый пакет представляет собой список resources (до четырех элементов в каждом пакете). Почему это было сделано именно так? Это служит двум целям:
- Это позволяет нам идентифицировать все ресурсы в уникальной группе пакетов. Таким образом, вместо того, чтобы включать все ресурсы в ответ HTML, мы можем включить уникальный актив JavaScript, который вместо этого является соответствующим файлом bundleGroup, который объединяет все соответствующие ресурсы. Это полезно при обслуживании устройств, которые до сих пор не поддерживают HTTP/2, а также увеличит время загрузки, потому что Gzip-сжатие одного связанного файла более эффективно, чем сжатие составляющих его файлов по отдельности, а затем их объединение. В качестве альтернативы мы могли бы также загрузить серию пакетов вместо уникальной группы пакетов, что является компромиссом между ресурсами и группами пакетов (загрузка пакетов происходит медленнее, чем пакетов пакетов из-за Gzip'а, но более производительна, если аннулирование происходит часто, так что мы будет загружать только обновленный пакет, а не всю группу пакетов). Скрипты для объединения всех ресурсов в пакеты и группы пакетов находятся в файлах filegenerator-bundles.php и filegenerator-bundlegroups.php.
- Разделение наборов ресурсов на пакеты позволяет нам идентифицировать общие шаблоны (например, определение наборов из четырех ресурсов, которые совместно используются многими маршрутами), что позволяет различным маршрутам связываться с одним и тем же пакетом. В результате сгенерированный список будет иметь меньший размер. Это может быть не очень полезно для списка веб-страниц, который находится на сервере, но отлично подходит для списка API, который будет загружен на клиенте, как мы увидим позже.
Когда скрипт для режима API запущен, он выводит файл resources.js со следующими свойствами:
-
bundlesиbundle-groupsпакетов служат той же цели, что и для режима веб-страницы. -
keysтакже служат той же цели, чтоkey-idsдля режима веб-страницы. Однако вместо хэша в качестве ключа для представления маршрута используется конкатенация всех тех атрибутов, которые делают маршрут уникальным — в нашем случае это формат (f), вкладка (t) и цель (r). -
sources— это исходный файл для каждого ресурса. -
types— это CSS или JavaScript для каждого ресурса (хотя для простоты мы не рассмотрели в этой статье, что ресурсы JavaScript также могут устанавливать ресурсы CSS в качестве зависимостей, а модули могут загружать свои собственные активы CSS, реализуя стратегию прогрессивной загрузки CSS ). -
resourcesфиксирует, какие группы пакетов должны быть загружены для каждой иерархии. -
ordered-load-resourcesсодержит, какие ресурсы должны быть загружены по порядку, чтобы предотвратить загрузку сценариев до их зависимых сценариев (по умолчанию они асинхронны).
Мы рассмотрим, как использовать этот файл в следующем разделе.
4. Динамическая загрузка ресурсов
Как уже говорилось, список API будет загружен на клиенте, поэтому мы можем начать загрузку необходимых ресурсов для маршрута сразу после того, как пользователь щелкнет ссылку.
Загрузка скрипта сопоставления
Сгенерированный JavaScript-файл со списком ресурсов для всех маршрутов в приложении нелегкий — в данном случае он вышел в 85 КБ (который сам по себе оптимизирован, исковеркав имена ресурсов и сгенерировав бандлы для выявления общих паттернов по маршрутам) . Время синтаксического анализа не должно быть большим узким местом, поскольку синтаксический анализ JSON в 10 раз быстрее, чем синтаксический анализ JavaScript для тех же данных. Однако размер является проблемой при передаче по сети, поэтому мы должны загружать этот скрипт таким образом, чтобы он не влиял на воспринимаемое время загрузки приложения и не заставлял пользователя ждать.
Решение, которое я реализовал, состоит в том, чтобы предварительно кэшировать этот файл с помощью сервис-воркеров, загружать его с помощью defer , чтобы он не блокировал основной поток при выполнении критических методов JavaScript, а затем отображать резервное уведомление, если пользователь нажимает на ссылку. до загрузки скрипта: «Веб-сайт все еще загружается, подождите несколько секунд, чтобы перейти по ссылкам». Это достигается путем добавления фиксированного элемента div с классом loadingscreen , размещенного поверх всего во время загрузки скриптов, затем добавления сообщения уведомления с классом notificationmsg внутри элемента div и следующих нескольких строк CSS:
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }Другое решение состоит в том, чтобы разбить этот файл на несколько и загружать их постепенно по мере необходимости (стратегия, которую я уже разработал). Более того, файл размером 85 КБ включает в себя все возможные маршруты в приложении, в том числе такие маршруты, как «объявления автора, показанные в миниатюрах, отображаемые в модальном окне», которые могут быть доступны раз в неделю, если вообще доступны. Маршрутов, к которым чаще всего обращаются, едва ли несколько (домашняя страница, одиночная, автор, тег и все страницы, все без дополнительных атрибутов), что должно привести к созданию файла гораздо меньшего размера, около 30 КБ.
Получение маршрута по запрошенному URL
Мы должны иметь возможность идентифицировать маршрут по запрошенному URL-адресу. Например:
-
https://getpop.org/en/u/leo/сопоставляется с маршрутом «автор», -
https://getpop.org/en/u/leo/?tab=followersсопоставляется с маршрутом «подписчики автора», -
https://getpop.org/en/tags/internet/сопоставляется с маршрутом «тег», -
https://getpop.org/en/tags/сопоставляется с маршрутом «страница/tags/», - и так далее.
Для этого нам нужно будет оценить URL-адрес и вывести из него элементы, которые делают маршрут уникальным: иерархию и все атрибуты (формат, вкладку и цель). Определить атрибуты не проблема, потому что это параметры в URL-адресе. Единственная проблема состоит в том, чтобы вывести иерархию (дом, автор, один, страница или тег) из URL-адреса, сопоставив URL-адрес с несколькими шаблонами. Например,
- Все, что начинается с
https://getpop.org/en/u/, является автором. - Все, что начинается с
https://getpop.org/en/tags/, но не точно является тегом. Если это именноhttps://getpop.org/en/tags/, то это страница. - И так далее.
Приведенная ниже функция, реализованная начиная со строки 321 файла resourceloader.js, должна быть снабжена конфигурацией с шаблонами для всех этих иерархий. Сначала он проверяет, нет ли подпути в URL — в этом случае это «дом». Затем он проверяет один за другим соответствие иерархии для «автора», «тега» и «одиночного». Если это не удается ни с одним из них, то это случай по умолчанию, то есть «страница»:
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };Поскольку все необходимые данные уже находятся в базе данных (все категории, все слаги страниц и т. д.), мы выполним сценарий для автоматического создания этого файла конфигурации в среде разработки или промежуточной среде. The implemented script is resourceloader-config.php, which produces config.js with the URL patterns for the hierarchies “author”, “tag” and “single”, under the key “paths”:
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
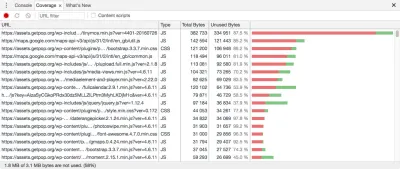
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
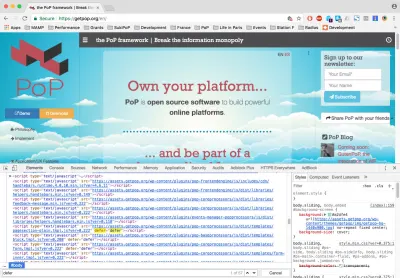
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
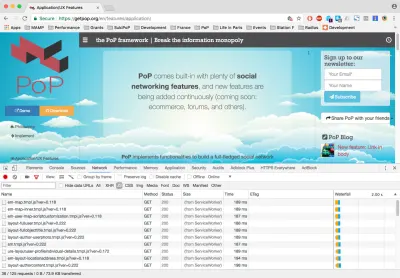
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
Недостатки
- Мы должны поддерживать его.
Если бы мы просто использовали Webpack, мы могли бы положиться на его сообщество в обновлении программного обеспечения и могли бы извлечь выгоду из его экосистемы плагинов. - Скрипты требуют времени для запуска.
Веб-сайт PoP Agenda Urbana имеет 304 различных маршрута, из которых он производит 422 набора уникальных ресурсов. Для этого веб-сайта запуск скрипта, создающего карту зависимостей активов, с использованием MacBook Pro 2012 года, занимает около 8 минут, а запуск скрипта, который генерирует списки со всеми ресурсами и создает файлы bundle и bundleGroup, занимает 15 минут. . Этого времени более чем достаточно, чтобы выпить кофе! - Это требует промежуточной среды.
Если нам нужно подождать около 25 минут для запуска скриптов, мы не сможем запустить их в рабочей среде. Нам потребуется промежуточная среда с точно такой же конфигурацией, что и производственная система. - На сайт добавлен дополнительный код, только для управления.
85 КБ кода сами по себе не функциональны, это просто код для управления другим кодом. - Добавляется сложность.
Это неизбежно в любом случае, если мы хотим разделить наши активы на более мелкие единицы. Webpack также усложнил бы приложение.
Преимущества
- Работает с Вордпресс.
Webpack не работает с WordPress из коробки, и для того, чтобы заставить его работать, требуется некоторое обходное решение. Это решение работает из коробки для WordPress (если установлен PoP). - Он масштабируемый и расширяемый.
Размер и сложность приложения могут расти неограниченно, потому что файлы JavaScript загружаются по запросу. - Он поддерживает Gutenberg (он же WordPress завтрашнего дня).
Поскольку он позволяет нам загружать фреймворки JavaScript по запросу, он будет поддерживать блоки Гутенберга (называемые блоками Гутенберга), которые, как ожидается, будут закодированы в фреймворке, выбранном разработчиком, с потенциальным результатом того, что для одного и того же приложения потребуются разные фреймворки. - Это удобно.
Инструмент сборки позаботится о создании файлов конфигурации. Кроме ожидания, никаких дополнительных усилий с нашей стороны не требуется. - Это упрощает оптимизацию.
В настоящее время, если плагин WordPress хочет выборочно загружать активы JavaScript, он будет использовать множество условных выражений, чтобы проверить, является ли идентификатор страницы правильным. С этим инструментом в этом нет необходимости; процесс автоматический. - Приложение будет загружаться быстрее.
Это была единственная причина, по которой мы закодировали этот инструмент. - Это требует промежуточной среды.
Положительным побочным эффектом является повышенная надежность: мы не будем запускать скрипты на продакшене, поэтому ничего там не сломаем; процесс развертывания не прервется из-за непредвиденного поведения; и разработчик будет вынужден тестировать приложение, используя ту же конфигурацию, что и в продакшене. - Он настроен для нашего приложения.
Нет никаких накладных расходов или обходных путей. Мы получаем именно то, что нам нужно, исходя из архитектуры, с которой мы работаем.
В заключение: да, это того стоит, потому что теперь мы можем применять загрузочные активы по требованию на нашем веб-сайте WordPress и ускорять его загрузку.
Дополнительные ресурсы
- Webpack, включая руководство «Разделение кода»
- «Лучшие сборки Webpack» (видео), К. Адам Уайт
Интеграция Webpack с WordPress - «Гутенберг и WordPress завтрашнего дня», Мортен Рэнд-Хендриксен, WP Tavern.
- «WordPress исследует независимый от JavaScript подход к построению блоков Гутенберга», Сара Гудинг, WP Tavern