
CNN против RNN: разница между CNN и RNN
Опубликовано: 2021-02-25Оглавление
Введение
В области искусственного интеллекта нейронные сети, вдохновленные человеческим мозгом, широко используются для извлечения и обработки сложной информации из различных данных и использования как сверточных нейронных сетей (CNN), так и рекуррентных нейронных сетей (RNN) в таких приложениях. оказываются полезными.
В этой статье мы поймем концепции, лежащие в основе как сверточных нейронных сетей, так и рекуррентных нейронных сетей, увидим их приложения и различим различия между обоими популярными типами нейронных сетей.
Изучите обучение машинному обучению в лучших университетах мира. Заработайте программы Masters, Executive PGP или Advanced Certificate Programs, чтобы ускорить свою карьеру.
Нейронные сети и глубокое обучение
Прежде чем мы перейдем к концепциям как сверточных нейронных сетей, так и рекуррентных нейронных сетей, давайте разберемся в концепциях, лежащих в основе нейронных сетей, и в том, как они связаны с глубоким обучением.
В последнее время глубокое обучение когда-то было концепцией, которая широко используется во многих областях, и поэтому в наши дни это горячая тема. Но в чем причина того, что о нем так много говорят? Чтобы ответить на этот вопрос, мы узнаем о концепции нейронных сетей.
Короче говоря, нейронные сети являются основой глубокого обучения. Они представляют собой определенное количество слоев, состоящих из сильно взаимосвязанных элементов, известных как нейроны, которые выполняют серию преобразований данных, что создает собственное понимание этих данных, которые мы называем термином «функции».

Что такое нейронные сети?
Первая концепция, с которой нам нужно разобраться, — это нейронные сети. Мы знаем, что человеческий мозг — одна из сложных структур, которые когда-либо изучались. Из-за его сложности было очень трудно разгадать его внутреннюю работу, но в настоящее время предпринимаются несколько видов исследований для раскрытия его секретов. Этот человеческий мозг служит источником вдохновения для моделей нейронных сетей.
По определению, нейронные сети — это функциональные единицы глубокого обучения, которые используют эти нейронные сети для имитации активности мозга и решения сложных задач. Когда входные данные поступают в нейронную сеть, они обрабатываются через слои персептрона и, наконец, выдают результат.
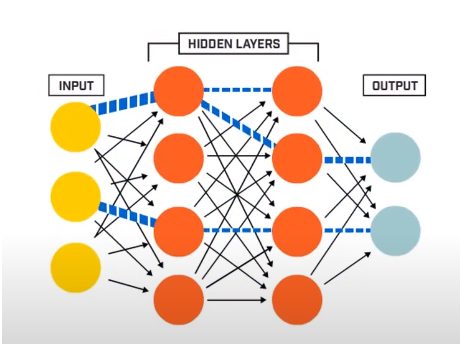
Нейронная сеть состоит в основном из 3 слоев:
- Входной слой
- Скрытые слои
- Выходной слой
Входной слой считывает входные данные, которые передаются в систему нейронной сети для дальнейшей предварительной обработки последующими слоями искусственных нейронов. Все слои, которые существуют между входным и выходным слоями, называются скрытыми слоями.
Именно в этих скрытых слоях присутствующие в них нейроны используют взвешенные входные данные и смещения и производят выходные данные, используя функции активации. Выходной слой — это последний слой нейронов, который дает нам выходные данные для данной программы.
Источник
Как работают нейронные сети?
Теперь, когда у нас есть представление об базовой структуре нейронных сетей, мы пойдем дальше и поймем, как они работают. Чтобы понять его работу, мы должны сначала узнать об одной из основных структур нейронных сетей, известной как персептрон.
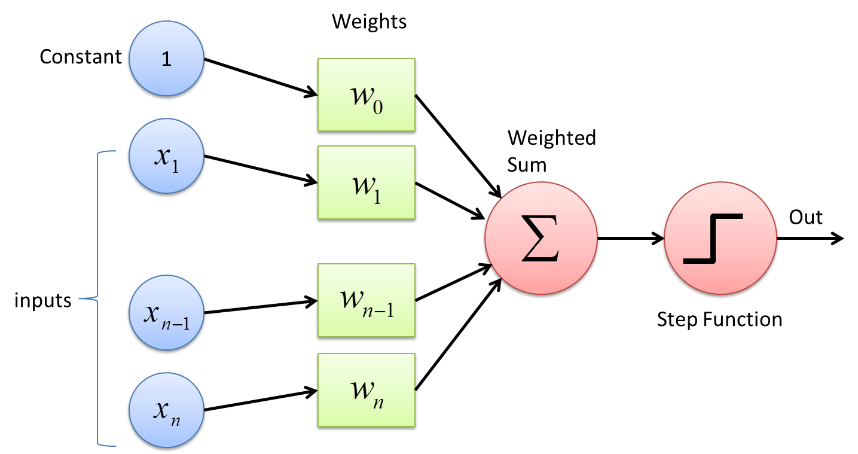
Персептрон — это тип нейронной сети, который является наиболее простым по форме. Это простая искусственная нейронная сеть с прямой связью только с одним скрытым слоем. В сети Perceptron каждый нейрон соединен с каждым другим нейроном в прямом направлении.
Связи между этими нейронами взвешиваются, из-за чего информация, передаваемая между двумя нейронами, усиливается или ослабляется этими весами. В процессе обучения нейронных сетей именно эти веса корректируются для получения правильного значения.
Perceptron использует функцию двоичного классификатора, в которой он отображает вектор переменных, которые являются двоичными по своей природе, в один двоичный выход. Это также может быть использовано в обучении с учителем. Шаги алгоритма обучения персептрона:
- Умножьте все входные данные на их веса w, где w — действительные числа, которые изначально могут быть фиксированными или рандомизированными.
- Сложите произведения, чтобы получить взвешенную сумму ∑ wj xj
- После получения взвешенной суммы входных данных применяется функция активации, чтобы определить, превышает ли взвешенная сумма определенное пороговое значение или нет, в зависимости от примененной функции активации. Выход назначается как 1 или 0 в зависимости от порогового состояния. Здесь значение «-порог» также относится к термину систематическая ошибка, б.
Таким образом, алгоритм обучения персептрона можно использовать для запуска (значение = 1) нейронов, присутствующих в нейронных сетях, которые спроектированы и разработаны сегодня. Другое представление алгоритма обучения персептрона:
f(x) = 1, если ∑ wj xj + b ≥ 0
0, если ∑ wj xj + b < 0
Хотя в настоящее время персептроны широко не используются, они по-прежнему остаются одной из основных концепций нейронных сетей. В ходе дальнейших исследований выяснилось, что небольшие изменения весов или смещения даже в одном персептроне могут значительно изменить выходной сигнал с 1 на 0 или наоборот. Это был один из основных недостатков персептрона. Следовательно, были разработаны более сложные функции активации, такие как ReLU, сигмовидные функции, которые вносят лишь умеренные изменения в веса и смещения искусственных нейронов.
Источник
Сверточные нейронные сети
Сверточная нейронная сеть — это алгоритм глубокого обучения, который принимает изображение в качестве входных данных, присваивает различные веса и смещения различным частям изображения, чтобы они были отличимы друг от друга. Как только они станут дифференцируемыми, используя различные функции активации, модель сверточной нейронной сети может выполнять несколько задач в области обработки изображений, включая распознавание изображений, классификацию изображений, обнаружение объектов и лиц и т. д.
Основой модели сверточной нейронной сети является то, что она получает входное изображение. Входное изображение может быть помечено (например, кошка, собака, лев и т. д.) или не помечено. В зависимости от этого алгоритмы глубокого обучения подразделяются на два типа, а именно контролируемые алгоритмы, где изображения помечены, и неконтролируемые алгоритмы, где изображениям не присваивается какая-либо конкретная метка.
Для компьютера входное изображение воспринимается как массив пикселей, чаще в виде матрицы. Изображения в основном имеют форму hxwxd (где h = высота, w = ширина, d = размер). Например, матричный массив изображения размером 16 x 16 x 3 обозначает изображение RGB (3 обозначает значения RGB). С другой стороны, изображение матричного массива 14 x 14 x 1 представляет собой изображение в градациях серого.
Источник
Слои сверточной нейронной сети
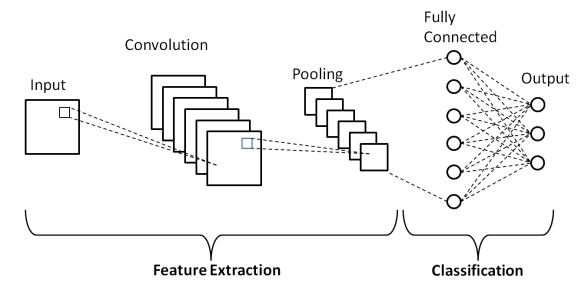
Как показано в приведенной выше базовой архитектуре сверточной нейронной сети, модель CNN состоит из нескольких слоев, через которые входные изображения проходят предварительную обработку для получения выходных данных. В основном эти слои дифференцируются на две части –
- Первые три слоя, включая входной слой, слой свертки и слой объединения, который действует как инструмент извлечения признаков для получения признаков базового уровня из изображений, загруженных в модель.
- Последний полносвязный слой и выходной слой используют выходные данные слоев извлечения признаков и предсказывают класс изображения в зависимости от извлеченных признаков.
Первый слой — это входной слой , где изображение подается в модель сверточной нейронной сети в виде массива матриц, т. е. 32 x 32 x 3, где 3 означает, что изображение представляет собой изображение RGB с одинаковой высотой и шириной. размером 32 пикселя. Затем эти входные изображения проходят через сверточный слой , где выполняется математическая операция свертки.

Входное изображение свертывается с другой квадратной матрицей, известной как ядро или фильтр. Сдвигая ядро один за другим по пикселям входного изображения, мы получаем выходное изображение, известное как карта признаков, которая предоставляет информацию об особенностях базового уровня изображения, таких как края и линии.
За сверточным слоем следует слой объединения , целью которого является уменьшение размера карты объектов для снижения вычислительных затрат. Это делается с помощью нескольких типов объединения, таких как максимальное объединение, среднее объединение и суммирование.
Уровень полной связи (FC) — это предпоследний уровень модели сверточной нейронной сети, где слои выравниваются и передаются на уровень FC. Здесь с помощью функций активации, таких как функции Sigmoid, ReLU и tanH, происходит предсказание метки, которое выдается на конечном выходном слое .
Где CNN терпят неудачу
С таким количеством полезных приложений сверточной нейронной сети в данных визуального изображения у CNN есть небольшой недостаток, заключающийся в том, что они плохо работают с последовательностью изображений (видео) и не могут интерпретировать временную информацию и блоки текста.
Чтобы иметь дело с временными или последовательными данными, такими как предложения, нам нужны алгоритмы, которые учатся на прошлых данных, а также на будущих данных в последовательности. К счастью, рекуррентные нейронные сети делают именно это.
Рекуррентные нейронные сети
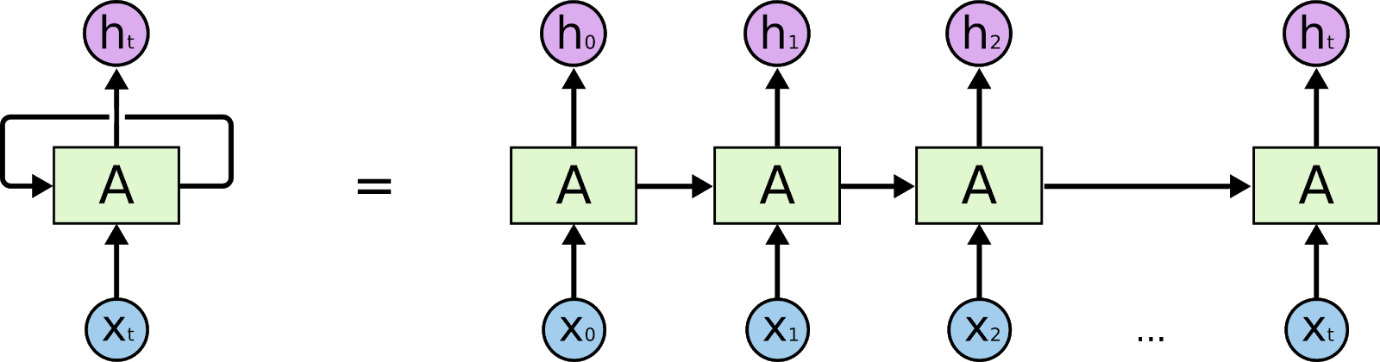
Рекуррентные нейронные сети — это сети, предназначенные для интерпретации временной или последовательной информации. RNN используют другие точки данных в последовательности, чтобы делать более точные прогнозы. Они делают это, принимая входные данные и повторно используя активации предыдущих или более поздних узлов в последовательности, чтобы повлиять на результат.
Источник
Благодаря своей внутренней памяти рекуррентные нейронные сети могут запоминать важные детали, такие как полученные ими данные, что позволяет им очень точно предсказывать, что будет дальше. Следовательно, они являются наиболее предпочтительным алгоритмом для последовательных данных, таких как временные ряды, речь, текст, аудио, видео и многие другие. Рекуррентные нейронные сети могут сформировать гораздо более глубокое понимание последовательности и ее контекста по сравнению с другими алгоритмами.
Как работают рекуррентные нейронные сети?
Основа для понимания работы с рекуррентными нейронными сетями такая же, как и для сверточных нейронных сетей, простых нейронных сетей с прямой связью, также известных как персептрон. Кроме того, в рекуррентных нейронных сетях выходные данные предыдущего шага подаются в качестве входных данных для текущего шага. В большинстве нейронных сетей выходные данные обычно не зависят от входных данных и наоборот, в этом основное отличие RNN от других нейронных сетей.
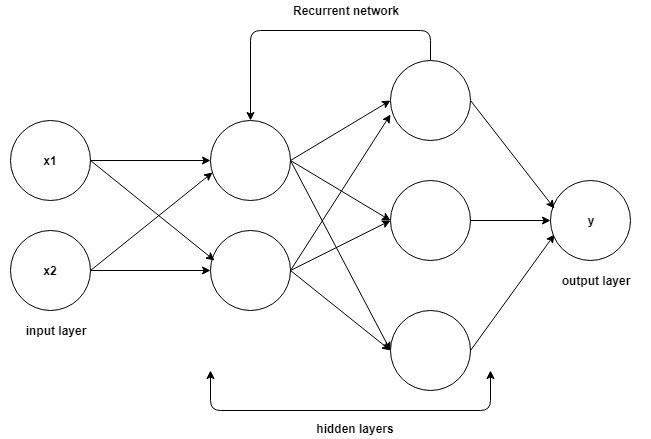
Источник
Следовательно, RNN имеет два входа: настоящее и недавнее прошлое. Это важно, потому что последовательность данных содержит важную информацию о том, что будет дальше, поэтому RNN может делать то, что другие алгоритмы не могут. Основной и наиболее важной особенностью рекуррентных нейронных сетей является скрытое состояние, которое запоминает некоторую информацию о последовательности.
Рекуррентные нейронные сети имеют память, в которой хранится вся информация о том, что было рассчитано. Используя одни и те же параметры для каждого входа и выполняя одну и ту же задачу для всех входов или скрытых слоев, сложность параметров снижается.
Разница между CNN и RNN
| Сверточные нейронные сети | Рекуррентные нейронные сети |
| В глубоком обучении сверточная нейронная сеть (CNN или ConvNet) представляет собой класс глубоких нейронных сетей, чаще всего применяемых для анализа визуальных образов. | Рекуррентная нейронная сеть (RNN) — это класс искусственных нейронных сетей, в которых связи между узлами образуют ориентированный граф вдоль временной последовательности. |
| Он подходит для пространственных данных, таких как изображения. | RNN используется для временных данных, также называемых последовательными данными. |
| CNN - это тип искусственной нейронной сети с прямой связью с вариациями многослойного персептрона, предназначенного для использования минимального объема предварительной обработки. | RNN, в отличие от нейронных сетей с прямой связью, может использовать свою внутреннюю память для обработки произвольных последовательностей входных данных. |
| CNN считается более мощным, чем RNN. | RNN включает меньшую совместимость функций по сравнению с CNN. |
| Эта CNN принимает входные данные фиксированного размера и генерирует выходные данные фиксированного размера. | RNN может обрабатывать произвольные длины ввода/вывода. |
| CNN идеально подходят для обработки изображений и видео. | RNN идеально подходят для анализа текста и речи. |
| Приложения включают распознавание изображений, классификацию изображений, анализ медицинских изображений, распознавание лиц и компьютерное зрение. | Приложения включают в себя перевод текста, обработку естественного языка, языковой перевод, анализ настроений и анализ речи. |
Заключение
Таким образом, в этой статье о различиях между двумя наиболее популярными типами нейронных сетей, сверточными нейронными сетями и рекуррентными нейронными сетями, мы изучили базовую структуру нейронной сети, а также основы как CNN, так и RNN, и, наконец, подвели итог. краткое сравнение между ними двумя с их приложениями в реальном мире.
Если вам интересно узнать больше о машинном обучении, ознакомьтесь с программой Executive PG IIIT-B и upGrad по машинному обучению и искусственному интеллекту , которая предназначена для работающих профессионалов и предлагает более 450 часов интенсивного обучения, более 30 тематических исследований и заданий, IIIT -B статус выпускника, 5+ практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Почему CNN быстрее, чем RNN?
CNN быстрее, чем RNN, потому что они предназначены для обработки изображений, а RNN предназначены для обработки текста. Хотя RNN можно научить работать с изображениями, им по-прежнему трудно отделять контрастирующие друг от друга функции, расположенные ближе друг к другу. Например, если у вас есть изображение лица с глазами, носом и ртом, RNN сложно определить, какую функцию отображать первой. CNN используют сетку точек, и с помощью алгоритма их можно научить распознавать формы и узоры. CNN лучше, чем RNN, сортируют изображения; они быстрее, чем RNN, потому что их просто вычислить, и они лучше сортируют изображения.
Для чего используется РНН?
Рекуррентные нейронные сети (RNN) — это класс искусственных нейронных сетей, в которых связи между элементами образуют направленный цикл. Выход одного модуля становится входом другого модуля и так далее, подобно тому, как выход одного нейрона становится входом другого. RNN успешно используются для решения сложных задач, таких как распознавание речи и машинный перевод, которые трудно выполнить стандартными методами.
Что такое RNN и чем он отличается от нейронных сетей с прямой связью?
Рекуррентные нейронные сети (RNN) — это разновидность нейронных сетей, которые используются для обработки последовательных данных. Рекуррентная нейронная сеть состоит из входного слоя, одного или нескольких скрытых слоев и выходного слоя. Скрытые слои предназначены для изучения внутренних представлений входных данных, которые затем представляются выходному слою в качестве внешнего представления. RNN обучается с помощью обратного распространения ошибки. RNN часто сравнивают с нейронными сетями с прямой связью (FNN). Хотя и RNN, и FNN могут изучать внутренние представления данных, RNN способны изучать долгосрочные зависимости, на что не способны FNN.