
Выбор новой технологии бессерверной базы данных в агентстве (пример из практики)
Опубликовано: 2022-03-10Эта статья была любезно поддержана нашими дорогими друзьями из Fauna, которые делают работу с операционными данными продуктивной, масштабируемой и безопасной для каждой команды разработчиков программного обеспечения. Спасибо!

Внедрение новой технологии — одно из самых сложных решений для технолога на руководящей должности. Часто это большая и неудобная область риска, независимо от того, создаете ли вы программное обеспечение для другой организации или в своей собственной.
За последние двенадцать лет работы инженером-программистом я оказался в ситуации, когда мне все чаще приходится оценивать новую технологию . Это может быть следующий интерфейсный фреймворк, новый язык или даже совершенно новая архитектура, например бессерверная.
Фаза экспериментов часто бывает веселой и захватывающей. Именно здесь инженеры-программисты чувствуют себя как дома, наслаждаясь новизной и эйфорией моментов «ага», придумывая новые концепции. Как инженеры, мы любим думать и возиться, но с достаточным опытом каждый инженер узнает, что даже у самой невероятной технологии есть свои недостатки. Вы просто их еще не нашли.
Теперь, как соучредитель креативного агентства, моя команда и я часто имеем уникальную возможность использовать новые технологии. Мы видим много новых проектов, которые становятся прекрасной возможностью для внедрения чего-то нового. Эти проекты также имеют уровень технической изоляции от более крупной организации и часто менее обременены предыдущими решениями.
При этом хорошему руководителю агентства доверяют заботу о чьей-то большой идее и представление ее миру. Мы должны относиться к нему даже с большей осторожностью, чем к своим собственным проектам. Всякий раз, когда я собираюсь сделать окончательный выбор новой технологии, я часто размышляю над этим мудрым советом соучредителя Stack Overflow Джоэла Спольски:
«Вы должны потеть и истекать кровью с этой вещью в течение года или двух, прежде чем вы действительно поймете, что она достаточно хороша, или поймете, что, как бы вы ни старались, вы не можете ...»
Это страх, это то место, в котором не хочет оказаться ни один технический руководитель. Выбор новой технологии для реального проекта достаточно сложен, но как агентство вы должны принимать эти решения с чужим проектом, кем-то другим. чужая мечта, чужие деньги. В агентстве последнее, что вы хотите, — это найти один из этих недостатков перед крайним сроком проекта. Жесткие сроки и бюджеты делают практически невозможным изменение курса после преодоления определенного порога, поэтому обнаружение того, что технология не может сделать что-то критическое или ненадежно слишком поздно в проекте, может иметь катастрофические последствия.
На протяжении всей своей карьеры инженера-программиста я работал в SaaS-компаниях и креативных агентствах. Когда дело доходит до принятия новой технологии для проекта, эти две среды имеют очень разные критерии. Критерии частично совпадают, но в целом агентская среда должна работать с жесткими бюджетами и жесткими временными ограничениями . Хотя мы хотим, чтобы продукты, которые мы создаем, со временем старели, часто сложнее инвестировать в что-то менее проверенное или внедрить технологию с более крутыми кривыми обучения и острыми краями.
При этом у агентств также есть некоторые уникальные ограничения, которых может не быть у отдельной организации. Приходится ориентироваться на эффективность и стабильность. Оплачиваемый час часто является конечной единицей измерения после завершения проекта. Я был в SaaS-компаниях, где потратить день или два на настройку или конвейер сборки не составляет большого труда.
В агентстве такие временные затраты создают нагрузку на отношения, так как финансовые отделы видят сужение прибыли для мало видимых результатов. Мы также должны учитывать долгосрочное обслуживание проекта и, наоборот, что произойдет, если проект нужно будет вернуть клиенту. Поэтому мы должны ориентироваться на эффективность, кривую обучения и стабильность выбранной нами технологии.
При оценке новой технологии я рассматриваю три основные области:
- Технология
- Опыт разработчиков
- Бизнес
В каждой из этих областей есть набор критериев, которые мне хотелось бы выполнить, прежде чем я начну по-настоящему погружаться в код и экспериментировать. В этой статье мы рассмотрим эти критерии и на примере рассмотрения новой базы данных для проекта и рассмотрим ее на высоком уровне с каждой точки зрения. Принятие такого ощутимого решения поможет продемонстрировать, как мы можем применить эту структуру в реальном мире.
Технология
Самое первое, на что следует обратить внимание при оценке новой технологии, — это то, может ли это решение решить проблемы, которые оно якобы решает. Прежде чем углубляться в то, как технология может помочь нашим процессам и бизнес-операциям, важно сначала убедиться, что она соответствует нашим функциональным требованиям . Здесь я также хотел бы взглянуть на то, какие существующие решения мы используем, и как это новое сочетается с ними.
Я буду задавать себе такие вопросы, как:
- Решает ли это как минимум проблему, которую решает мое существующее решение?
- Чем это решение лучше?
- В чем он хуже?
- В тех областях, где ситуация еще хуже, что потребуется для преодоления этих недостатков?
- Заменит ли он несколько инструментов?
- Насколько стабильна технология?
Наш Почему?
На этом этапе я также хочу рассмотреть, почему мы ищем другое решение. Простой ответ: мы столкнулись с проблемой, которую не решают существующие решения . Однако часто это бывает редко. За прошедшие годы мы решили множество проблем с программным обеспечением, используя все современные технологии. Что обычно происходит, так это то, что мы переключаемся на новую технологию, которая делает то, что мы сейчас делаем, проще, стабильнее, быстрее или дешевле.
Возьмем React в качестве примера. Почему мы решили внедрить React, когда jQuery или Vanilla JavaScript выполняли свою работу? В этом случае использование фреймворка показало, что это гораздо лучший способ обработки интерфейсов с отслеживанием состояния. Мы стали быстрее создавать такие вещи, как фильтрация и сортировка , работая со структурами данных вместо прямого манипулирования DOM. Это позволило сэкономить время и повысить стабильность наших решений.
Typescript — еще один пример, когда мы решили принять его, потому что обнаружили повышение стабильности нашего кода и удобство сопровождения. С внедрением новых технологий часто не возникает четкой проблемы, которую мы пытаемся решить, а скорее просто пытаемся оставаться в курсе событий, а затем находим более эффективные и стабильные решения, чем те, которые мы используем в настоящее время.
В случае с базой данных мы специально рассматривали возможность перехода на бессерверный вариант . Мы добились большого успеха с бессерверными приложениями и развертываниями, сокращая наши накладные расходы как организации. Одной из областей, где мы чувствовали, что этого не хватает, был наш уровень данных. Мы видели такие сервисы, как Amazon Aurora, Fauna, Cosmos и Firebase, которые применяли бессерверные принципы к базам данных, и хотели посмотреть, не пора ли самим совершить скачок. В данном случае мы стремились снизить операционные издержки и повысить скорость и эффективность разработки.
На этом уровне важно понять, почему , прежде чем вы начнете погружаться в новые предложения. Это может быть связано с тем, что вы решаете новую проблему, но гораздо чаще вы стремитесь улучшить свою способность решать тип проблемы, которую вы уже решаете. В этом случае вам нужно провести инвентаризацию того, где вы были, чтобы выяснить, что может значительно улучшить ваш рабочий процесс. Основываясь на нашем примере с бессерверными базами данных, нам нужно взглянуть на то, как мы в настоящее время решаем проблемы и где эти решения не оправдывают ожиданий.
Где мы были…
Как агентство мы ранее использовали широкий спектр баз данных, включая, помимо прочего, MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery и облачное хранилище Firebase. Однако подавляющее большинство нашей работы было сосредоточено вокруг трех основных баз данных: PostgreSQL, MongoDB и базы данных Firebase Realtime. На самом деле у каждого из них есть полубессерверные предложения, но некоторые ключевые особенности новых предложений заставили нас пересмотреть наши предыдущие предположения. Давайте сначала посмотрим на наш исторический опыт с каждым из них и на то, почему мы в первую очередь рассматриваем альтернативы.
Обычно мы выбирали PostgreSQL для более крупных и долгосрочных проектов, так как это проверенный временем золотой стандарт практически для всего. Он поддерживает классические транзакции, нормализованные данные и совместим с ACID. Существует множество инструментов и ORM, доступных почти на каждом языке, и их даже можно использовать в качестве специальной базы данных NoSQL с поддержкой столбцов JSON. Он хорошо интегрируется со многими существующими фреймворками, библиотеками и языками программирования, что делает его настоящей универсальной рабочей лошадкой. Это также с открытым исходным кодом и, следовательно, не привязывает нас к какому-то одному поставщику. Как говорится, еще никого не уволили за выбор Postgres.
При этом мы постепенно обнаружили, что используем PostgreSQL все меньше и меньше, поскольку мы стали больше ориентироваться на Node. Мы обнаружили, что ORM для Node тусклые и требуют больше пользовательских запросов (хотя сейчас это стало менее проблематичным), а NoSQL кажется более естественным для работы в среде выполнения JavaScript или TypeScript. При этом у нас часто были проекты, которые можно было выполнить довольно быстро с помощью классического реляционного моделирования , такого как рабочие процессы электронной коммерции. Однако работа с локальной настройкой базы данных, унификация потока тестирования между командами и работа с локальными миграциями были теми вещами, которые нам не нравились, и мы были рады оставить их после того, как NoSQL, облачные базы данных стали более популярными.
MongoDB все чаще становилась нашей базой данных, поскольку мы выбрали Node.js в качестве предпочитаемой серверной части. Работа с MongoDB Atlas упростила быструю разработку и тестирование баз данных, которые могла использовать наша команда. Какое-то время MongoDB не была совместима с ACID, не поддерживала транзакции и не одобряла слишком много внутренних операций, подобных соединениям, поэтому для приложений электронной коммерции мы по-прежнему чаще всего использовали Postgres. При этом существует множество библиотек, которые идут с ним, а язык запросов Mongo и первоклассная поддержка JSON дали нам скорость и эффективность, которых мы не испытывали при работе с реляционными базами данных. MongoDB недавно добавила поддержку транзакций ACID, но долгое время это было главной причиной, по которой мы выбирали Postgres.
MongoDB также представила нам новый уровень гибкости. В середине проекта агентства требования обязательно изменятся. Как бы вы ни защищались от этого, всегда есть потребность в данных в последнюю минуту . В целом, в базах данных NoSQL гибкость структуры данных делает эти типы изменений менее резкими. Мы не получили папку, полную файлов миграции, чтобы управлять добавлением, удалением и добавлением столбцов еще до того, как проект увидел свет.
Как сервис Mongo Atlas также был довольно близок к тому, что мы хотели от облачного сервиса базы данных. Мне нравится думать об Atlas как о полубессерверном предложении, поскольку при управлении им все еще возникают некоторые операционные издержки. Вы должны подготовить базу данных определенного размера и заранее выбрать объем памяти. Эти вещи не будут масштабироваться для вас автоматически, поэтому вам нужно будет следить за тем, когда придет время предоставить больше места или памяти. В действительно бессерверной базе данных все это будет происходить автоматически и по требованию.
Мы также использовали базу данных Firebase Realtime для нескольких проектов. Это действительно бессерверное предложение, в котором база данных масштабируется вверх и вниз по запросу, а с оплатой по мере использования это имело смысл для приложений, где масштаб не был заранее известен, а бюджет был ограничен. Мы использовали его вместо MongoDB для недолговечных проектов с простыми требованиями к данным.
Одна вещь, которая нам не нравилась в Firebase, заключалась в том, что она казалась далекой от типичной реляционной модели, построенной на основе нормализованных данных, к которым мы привыкли. Сохранение однородных структур данных означало, что у нас часто было больше дублирования, что могло стать немного уродливым по мере роста проекта. В конечном итоге вам придется обновлять одни и те же данные в нескольких местах или пытаться объединить разные ссылки, что приводит к множеству запросов, которые трудно понять в коде. Хотя нам нравился Firebase, мы никогда не влюблялись в язык запросов и иногда находили документацию тусклой.
В целом и MongoDB, и Firebase одинаково фокусировались на денормализованных данных , и без доступа к эффективным транзакциям мы часто обнаруживали многие рабочие процессы, которые было легко смоделировать в реляционных базах данных, что приводило к более сложному коду на уровне приложений с их Аналоги NoSQL. Если бы мы могли получить гибкость и простоту этих предложений NoSQL с надежностью и реляционным моделированием традиционной базы данных SQL, мы действительно нашли бы отличное сочетание. Мы чувствовали, что MongoDB имеет лучший API и возможности, но у Firebase была действительно бессерверная модель в эксплуатации.
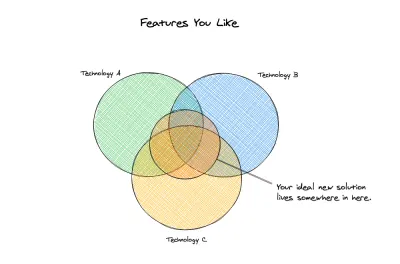
Наш идеал
На этом этапе мы можем начать смотреть, какие новые варианты мы будем рассматривать. Мы четко определили наши предыдущие решения, и мы определили, что для нас важно иметь как минимум в нашем новом решении. У нас есть не только базовый или минимальный набор требований, но и ряд проблем, которые мы хотели бы решить с помощью нового решения. Вот технические требования , которые у нас есть:
- Бессерверная работа с масштабированием по требованию
- Гибкое моделирование (бессхемное)
- Не полагайтесь на миграции или ORM
- ACID-совместимые транзакции
- Поддерживает отношения и нормализованные данные
- Работает как с бессерверными, так и с традиционными бэкендами
Итак, теперь, когда у нас есть список обязательных элементов, мы можем оценить некоторые варианты. Возможно, не так важно, чтобы новое решение достигло каждой цели. Возможно, он просто обеспечивает правильное сочетание функций там, где существующие решения не пересекаются. Например, если вам нужна была гибкость без схемы , вам пришлось отказаться от ACID-транзакций. (Так было долгое время с базами данных.)
Пример из другого домена: если вы хотите иметь проверку машинописного текста при рендеринге шаблона, вам нужно использовать TSX и React. Если вы используете такие опции, как Svelte или Vue, вы можете получить это — частично, но не полностью — через рендеринг шаблона . Таким образом, решение, которое дало вам крошечную площадь и скорость Svelte с проверкой типов на уровне шаблона React и TypeScript, могло быть достаточным для принятия, даже если в нем отсутствовала другая функция. Баланс между желаниями и потребностями будет меняться от проекта к проекту. Вы должны выяснить, где будет значение, и решить, как отметить наиболее важные моменты в вашем анализе.
Теперь мы можем взглянуть на решение и посмотреть, как оно соотносится с нашим желаемым решением. Fauna — это решение для бессерверной базы данных , которое можно масштабировать по требованию и распространять по всему миру. Это база данных без схемы, которая обеспечивает ACID-совместимые транзакции и поддерживает реляционные запросы и нормализованные данные в качестве функции. Fauna может использоваться как в бессерверных приложениях, так и в более традиционных бэкендах и предоставляет библиотеки для работы с наиболее популярными языками. Кроме того, Fauna предоставляет рабочие процессы для аутентификации, а также простую и эффективную мультиарендность. Обе эти функции являются важными дополнительными функциями, на которые следует обратить внимание, поскольку они могут быть решающими факторами, когда в нашей оценке две технологии находятся лицом к лицу.
Теперь, рассмотрев все эти сильные стороны, мы должны оценить слабые стороны . Один из них — «Фауна» — не с открытым исходным кодом. Это означает, что существуют риски привязки к поставщику или изменения бизнеса и цен, которые вы не можете контролировать. Открытый исходный код может быть хорош, потому что вы часто можете передать технологию другому поставщику, если хотите, или потенциально внести свой вклад в проект.
В мире агентств мы должны внимательно следить за привязкой к поставщику , не столько из-за цены, сколько из-за жизнеспособности основного бизнеса. Необходимость менять базы данных в проекте, который находится в процессе разработки или которому уже несколько лет, — обе катастрофы для агентства. Часто клиенту приходится платить за это, а это не очень приятный разговор.
Еще одна слабость, которая нас беспокоила, — это сосредоточенность на JAMstack . Хотя мы любим JAMstack, мы все чаще создаем широкий спектр традиционных веб-приложений. Мы хотим быть уверены, что Fauna продолжит поддерживать эти варианты использования. В прошлом у нас был неудачный опыт с хостинг-провайдером, который пошел ва-банк на JAMstack, и в итоге нам пришлось перенести довольно большое количество сайтов из сервиса, поэтому мы хотим быть уверены, что все варианты использования будут по-прежнему отображаться. солидная поддержка. Прямо сейчас, похоже, это так, и бессерверные рабочие процессы, предоставляемые Fauna, на самом деле могут неплохо дополнить более традиционное приложение.
На данный момент мы провели функциональное исследование, и единственный способ узнать, является ли это решение жизнеспособным, — это сесть и написать код. В среде агентства мы не можем просто выделить недели из графика, чтобы люди оценили несколько решений. Такова природа работы в агентстве, а не в среде SaaS . В последнем случае вы можете создать несколько прототипов, чтобы попытаться найти правильное решение. В агентстве у вас будет несколько дней, чтобы поэкспериментировать, или, может быть, возможность заняться побочным проектом, но в целом нам действительно нужно сузить это до одной или двух технологий на данном этапе, а затем приложить пальцы к клавиатуре.

Опыт разработчиков
Оценка опыта новой технологии, пожалуй, самая сложная из трех областей, поскольку она по своей природе субъективна. Он также будет иметь вариативность от команды к команде. Например, если вы спросите программиста Ruby, программиста Python и программиста Rust об их мнении о различных функциях языка, вы получите множество ответов. Итак, прежде чем вы начнете оценивать опыт, вы должны сначала решить, какие характеристики наиболее важны для вашей команды в целом.

Я думаю, что для агентств есть два основных узких места , связанных с опытом разработчиков:
- Время установки и настройки
- обучаемость
Оба они по-разному влияют на долгосрочную жизнеспособность новой технологии. Синхронизация временных команд разработчиков в агентстве может стать головной болью. Общеизвестно, что агентствам сложно работать с инструментами, требующими больших затрат на установку и настройку. Другой — обучаемость и то, насколько легко разработчикам развивать новую технологию. Мы рассмотрим их более подробно и объясним, почему они являются моей основой, когда я начинаю оценивать опыт разработчиков.
Время установки и конфигурация
У агентств, как правило, мало терпения и времени на настройку. Что касается меня, я люблю острые инструменты с эргономичным дизайном, которые позволяют мне быстро приступить к работе над бизнес-задачей. Несколько лет назад я работал в компании SaaS, у которой была сложная локальная установка, которая включала множество конфигураций и часто терпела неудачу в случайных точках в процессе установки. После того, как вы были настроены, общепринятым было ничего не трогать и надеяться, что вы не пробудете в компании достаточно долго, чтобы снова настроить его на другой машине. Я встречал разработчиков, которым очень нравилось настраивать каждую маленькую часть своей установки emacs, и они ничего не думали о том, чтобы потерять несколько часов из-за сломанной локальной среды.
В целом, я обнаружил, что инженеры агентства пренебрегают подобными вещами в своей повседневной работе. Дома они могут возиться с этими типами инструментов, но когда у них крайний срок, нет ничего лучше инструментов, которые просто работают. В агентствах мы, как правило, предпочитаем изучать несколько новых вещей, которые хорошо и последовательно работают, а не иметь возможность настраивать каждую часть технологии по личному вкусу каждого человека.
Одна вещь, которая хороша в работе с облачной платформой, которая не является открытым исходным кодом, заключается в том, что они полностью владеют установкой и конфигурацией. Хотя недостатком этого является привязка к поставщику, преимуществом является то, что эти типы инструментов часто делают то, для чего они настроены, хорошо. Нет необходимости возиться со средами, локальными настройками и конвейерами развертывания. Нам также приходится принимать меньше решений.
Это неотъемлемая привлекательность бессерверных приложений . Бессерверные решения в целом больше зависят от проприетарных сервисов и инструментов. Мы жертвуем гибкостью хостинга и исходного кода, чтобы получить большую стабильность и сосредоточиться на проблемах бизнес-сферы, которые мы пытаемся решить. Я также отмечу, что когда я оцениваю технологию и у меня возникает ощущение, что может потребоваться миграция с платформы, это часто с самого начала является плохим признаком.
В случае с базами данных настройка «установил и забыл» идеальна при работе с клиентами, где потребности базы данных могут быть неоднозначными. У нас были клиенты, которые не были уверены, насколько популярной будет программа или приложение. У нас были клиенты, с которыми мы технически не заключали контракт на поддержку таким образом, но, тем не менее, в панике звонили нам, когда им нужно было, чтобы мы масштабировали их базу данных или приложение.
В прошлом нам всегда приходилось учитывать такие вещи, как избыточность, репликация данных и сегментирование для масштабирования, когда мы создавали наши SOW. Попытка охватить каждый сценарий и в то же время подготовиться к тому, чтобы переместить полный список дел в случае, если база данных не масштабируется, — это невозможная ситуация, к которой нужно подготовиться. В конце концов, бессерверная база данных упрощает эту задачу.
Вы никогда не потеряете данные , вам не нужно беспокоиться о репликации данных по сети, а также о предоставлении большой базы данных и компьютера для ее запуска — все просто работает. Мы фокусируемся только на текущей бизнес-задаче, техническая архитектура и масштаб всегда будут под контролем. Для нашей команды разработчиков это огромная победа; у нас меньше пожарных учений, мониторинга и переключения контекста.
обучаемость
Существует классическая мера пользовательского опыта, которая, я думаю, применима к опыту разработчиков, а именно обучаемость . При проектировании для определенного пользовательского опыта мы не просто смотрим на то, кажется ли что-то очевидным или легким с первого раза. Технология просто более сложна, чем это большую часть времени. Важно то, насколько легко новый пользователь может изучить и освоить систему.
Когда дело доходит до технических инструментов, особенно мощных, было бы слишком много просить об нулевой кривой обучения . Обычно мы ищем отличную документацию для наиболее распространенных вариантов использования и чтобы эти знания можно было легко и быстро использовать в проекте. Потерять немного времени на изучение первого проекта с технологией — это нормально. После этого мы должны увидеть повышение эффективности с каждым последующим проектом.
Что я ищу конкретно здесь, так это то, как мы можем использовать знания и шаблоны, которые мы уже знаем, чтобы помочь сократить кривую обучения. Например, в случае с бессерверными базами данных не потребуется практически никакого обучения для их настройки в облаке и развертывания. Когда дело доходит до использования базы данных, мне нравится, когда мы все еще можем использовать все годы освоения реляционных баз данных и применять эти знания к нашей новой установке. В этом случае мы учимся использовать новый инструмент, но это не заставляет нас переосмысливать наше моделирование данных с нуля.

В качестве примера этого при использовании Firebase, MongoDB и DynamoDB мы обнаружили, что он поощряет денормализованные данные , а не пытается объединить разные документы. Это создало много когнитивных трений при моделировании наших данных, поскольку нам нужно было думать с точки зрения шаблонов доступа, а не бизнес-сущностей. С другой стороны, эта фауна позволила нам использовать наши многолетние знания в области отношений, а также наше предпочтение нормализованным данным, когда дело дошло до моделирования данных.
Часть, к которой нам пришлось привыкнуть, заключалась в использовании индексов и нового языка запросов для объединения этих частей. В целом, я обнаружил, что сохранение концепций, являющихся частью более крупных парадигм проектирования программного обеспечения, облегчает команде разработчиков задачу обучения и адаптации.
Как мы узнаем, что команда принимает и любит новую технологию? Я думаю, что лучший знак — это когда мы задаемся вопросом, интегрируется ли этот инструмент с упомянутой новой технологией? Когда новая технология достигает такого уровня желательности и удовольствия, что команда ищет способы внедрить ее в большее количество проектов, это хороший признак того, что у вас есть победитель.
Бизнес
В этом разделе мы должны рассмотреть, как новая технология отвечает потребностям нашего бизнеса . К ним относятся такие вопросы, как:
- Насколько легко его можно оценить и интегрировать в наши планы поддержки?
- Можем ли мы легко передать его клиентам?
- Можно ли при необходимости подключить клиентов к этому инструменту?
- Сколько времени этот инструмент на самом деле экономит, если вообще экономит?
Развитие бессерверной парадигмы хорошо подходит агентствам. Когда мы говорим о базах данных и DevOps, потребность в специалистах по этим направлениям в агентствах ограничена. Часто мы передаем проект, когда мы с ним закончили, или поддерживаем его в долгосрочной перспективе с ограниченными возможностями. Мы склонны отдавать предпочтение инженерам с полным стеком, поскольку их потребности значительно превышают потребности DevOps. Если бы мы наняли инженера DevOps, он, вероятно, потратил бы несколько часов на развертывание проекта и еще много часов зависал бы в ожидании пожара.
В связи с этим у нас всегда есть готовые подрядчики DevOps , но мы не набираем сотрудников на эти должности на полную ставку. Это означает, что мы не можем полагаться на то, что инженер DevOps будет готов к неожиданной проблеме. Что касается нас, мы знаем, что можем получить более высокие ставки на хостинг, обратившись напрямую к AWS, но мы также знаем, что, используя Heroku, мы можем положиться на наш существующий персонал для устранения большинства проблем. Если у нас нет клиента, которого нам нужно поддерживать в долгосрочной перспективе с конкретными внутренними потребностями, мы предпочитаем по умолчанию использовать управляемые платформы как услугу.
Базы данных не являются исключением. Нам нравится использовать такие сервисы, как Mongo Atlas или Heroku Postgres, чтобы максимально упростить этот процесс. По мере того, как мы все больше и больше обращали внимание на бессерверные инструменты, такие как Vercel, Netlify или AWS Lambda, наши потребности в базе данных должны были развиваться вместе с этим. Бессерверные базы данных , такие как Firebase, DynamoDB и Fauna, хороши тем, что они хорошо интегрируются с бессерверными приложениями, но при этом полностью освобождают наш бизнес от подготовки и масштабирования.
Эти решения также хорошо работают для более традиционных приложений, где у нас нет бессерверного приложения, но мы все еще можем использовать бессерверную эффективность на уровне базы данных. Для бизнеса более продуктивно изучать единую базу данных, которая может применяться к обоим мирам, чем переключаться между контекстами. Это похоже на наше решение принять Node и изоморфный JavaScript (и TypeScript).
Один из недостатков, который мы обнаружили с бессерверными технологиями, — это установление цен для клиентов , для которых мы управляем этими услугами. В более традиционной архитектуре уровни с фиксированной ставкой позволяют очень легко преобразовывать их в ставки для клиентов с предсказуемыми обстоятельствами повышения и перерасхода. Когда дело доходит до безсерверных, это может быть неоднозначно. Финансисты обычно не любят слышать такие вещи, как мы берем 1/10 пенни за каждое чтение сверх 1 миллиона, и так далее и тому подобное.
Это трудно перевести в фиксированное число даже для инженеров, поскольку мы часто разрабатываем приложения, которые не уверены, каково будет их использование . Нам часто приходится создавать уровни самостоятельно, но многие переменные, которые входят в расчет стоимости лямбды, могут быть трудными для понимания. В конечном счете, для продукта SaaS эти модели ценообразования с оплатой по мере использования хороши, но для агентств бухгалтеры предпочитают более конкретные и предсказуемые цифры.
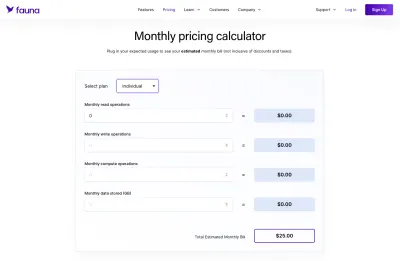
Когда дело дошло до фауны, это было определенно более неоднозначно, чем, скажем, стандартная база данных MySQL, у которой был хостинг с фиксированной ставкой для определенного количества места. Положительным моментом было то, что Fauna предоставляет хороший калькулятор, который мы смогли использовать для составления наших собственных схем ценообразования.
Другим сложным аспектом бессерверной работы может быть то, что многие из этих провайдеров не позволяют легко разбить каждое размещаемое приложение. Например, платформа Heroku делает это довольно легко, создавая новые конвейеры и команды. Мы даже можем ввести кредитную карту клиента, если он не хочет использовать наши планы хостинга. Все это также можно сделать на одной панели инструментов, поэтому нам не нужно было создавать несколько логинов.
Когда дело дошло до других бессерверных инструментов, это было намного сложнее. При оценке бессерверных баз данных Firebase поддерживает разделение платежей по проектам . В случае с Fauna или DynamoDB это невозможно, поэтому нам нужно проделать некоторую работу, чтобы отслеживать использование на их панели инструментов, и если клиент захочет покинуть наш сервис, нам придется перенести базу данных на его собственную учетную запись.
В конечном счете, бессерверные инструменты открывают большие возможности для бизнеса с точки зрения экономии затрат, управления и эффективности процессов. Однако часто они оказываются сложными для агентств, когда дело доходит до ценообразования и управления учетными записями. Это одна из областей, где нам пришлось использовать калькуляторы затрат, чтобы создать наши собственные предсказуемые уровни цен или настроить клиентов с их собственными учетными записями, чтобы они могли осуществлять платежи напрямую.
Заключение
Принятие новой технологии агентством может оказаться сложной задачей. Хотя мы находимся в уникальном положении для работы с новыми проектами с нуля, в которых есть возможности для новых технологий, мы также должны учитывать их долгосрочные инвестиции. Как они будут выступать? Будут ли наши люди работать продуктивно и получать удовольствие от их использования? Can we incorporate them into our business offering?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
Дальнейшее чтение
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience