
Создание комнатного детектора для устройств IoT на Mac OS
Опубликовано: 2022-03-10Знание того, в какой комнате вы находитесь, позволяет использовать различные приложения IoT — от включения света до переключения телеканалов. Итак, как мы можем определить момент, когда вы и ваш телефон находитесь на кухне, в спальне или в гостиной? С сегодняшним массовым оборудованием существует множество возможностей:
Одним из решений является оснащение каждой комнаты Bluetooth-устройством . Как только ваш телефон окажется в пределах досягаемости устройства Bluetooth, ваш телефон будет знать, в какой комнате он находится, на основе устройства Bluetooth. Однако обслуживание множества устройств Bluetooth сопряжено со значительными накладными расходами — от замены батарей до замены неисправных устройств. Кроме того, близость к Bluetooth-устройству не всегда является решением: если вы находитесь в гостиной, у стены, общей с кухней, кухонная техника не должна начать взбивать еду.
Другое, хотя и непрактичное решение — использование GPS . Однако имейте в виду, что GPS плохо работает в помещении, где множество стен, других сигналов и других препятствий наносят ущерб точности GPS.
Вместо этого наш подход заключается в использовании всех сетей Wi-Fi в пределах досягаемости, даже тех, к которым не подключен ваш телефон. Вот как: рассмотрите силу WiFi A на кухне; скажем, 5. Поскольку между кухней и спальней есть стена, мы можем разумно ожидать, что мощность WiFi A в спальне будет разной; скажем, 2. Мы можем использовать эту разницу, чтобы предсказать, в какой комнате мы находимся. Более того: сеть Wi-Fi B от нашего соседа может быть обнаружена только из гостиной, но фактически невидима из кухни. Это делает предсказание еще проще. В общем, список всех Wi-Fi в пределах досягаемости дает нам много информации.
Этот метод имеет явные преимущества:
- не требует дополнительного оборудования;
- полагаясь на более стабильные сигналы, такие как WiFi;
- хорошо работает там, где другие методы, такие как GPS, слабы.
Чем больше стен, тем лучше, так как чем сильнее различаются сильные стороны сети Wi-Fi, тем легче классифицировать комнаты. Вы создадите простое настольное приложение, которое собирает данные, учится на них и предсказывает, в какой комнате вы находитесь в любой момент времени.
Дальнейшее чтение на SmashingMag:
- Расцвет интеллектуального диалогового пользовательского интерфейса
- Приложения машинного обучения для дизайнеров
- Как создать прототип IoT: создание оборудования
- Дизайн для Интернета эмоциональных вещей
Предпосылки
Для этого урока вам понадобится Mac OSX. Хотя код может применяться к любой платформе, мы предоставим инструкции по установке зависимостей только для Mac.
- Mac OS X
- Homebrew — менеджер пакетов для Mac OSX. Для установки скопируйте и вставьте команду в brew.sh
- Установка NodeJS 10.8.0+ и npm
- Установка Python 3.6+ и pip. См. первые 3 раздела «Как установить virtualenv, Установка с помощью pip и Управление пакетами».
Шаг 0: Настройка рабочей среды
Ваше настольное приложение будет написано на NodeJS. Однако для использования более эффективных вычислительных библиотек, таких как numpy , код обучения и прогнозирования будет написан на Python. Для начала мы настроим вашу среду и установим зависимости. Создайте новый каталог для размещения вашего проекта.
mkdir ~/riotПерейдите в каталог.
cd ~/riotИспользуйте pip для установки диспетчера виртуальной среды Python по умолчанию.
sudo pip install virtualenv Создайте виртуальную среду Python3.6 с именем riot .
virtualenv riot --python=python3.6Активируйте виртуальную среду.
source riot/bin/activate Вашему приглашению теперь предшествует (riot) . Это означает, что мы успешно вошли в виртуальную среду. Установите следующие пакеты с помощью pip :
-
numpy: эффективная библиотека линейной алгебры -
scipy: научная вычислительная библиотека, реализующая популярные модели машинного обучения.
pip install numpy==1.14.3 scipy ==1.1.0С настройкой рабочего каталога мы начнем с настольного приложения, которое записывает все сети WiFi в пределах досягаемости. Эти записи будут представлять собой обучающие данные для вашей модели машинного обучения. Как только у нас будут данные, вы напишете классификатор наименьших квадратов, обученный на сигналах WiFi, собранных ранее. Наконец, мы будем использовать модель наименьших квадратов, чтобы предсказать комнату, в которой вы находитесь, на основе доступных сетей Wi-Fi.
Шаг 1: Начальное настольное приложение
На этом этапе мы создадим новое настольное приложение, используя Electron JS. Для начала мы возьмем менеджер пакетов Node npm и утилиту загрузки wget .
brew install npm wgetДля начала мы создадим новый проект Node.
npm init Вам будет предложено ввести имя пакета, а затем номер версии. Нажмите ENTER , чтобы принять имя по умолчанию riot и версию по умолчанию 1.0.0 .
package name: (riot) version: (1.0.0) Это запрашивает описание проекта. Добавьте любое непустое описание. Ниже описание room detector
description: room detector Вам будет предложено указать точку входа или основной файл, из которого будет запускаться проект. Введите app.js
entry point: (index.js) app.js Вам будет предложено ввести команду test command и git repository . Нажмите ENTER , чтобы пока пропустить эти поля.
test command: git repository: Это подскажет вам keywords и author . Заполните любые значения, которые вы хотели бы. Ниже мы используем iot , wifi для ключевых слов и John Doe для автора.
keywords: iot,wifi author: John Doe Это запрашивает лицензию. Нажмите ENTER , чтобы принять значение ISC по умолчанию.
license: (ISC) На этом этапе npm предложит вам краткую информацию. Ваш вывод должен быть похож на следующий.
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } Нажмите ENTER , чтобы принять. Затем npm создает package.json . Перечислите все файлы для перепроверки.
lsЭто выведет единственный файл в этом каталоге вместе с папкой виртуальной среды.
package.json riotУстановите зависимости NodeJS для нашего проекта.
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save Начните с main.js из Electron Quick Start, загрузив файл, используя приведенную ниже. Следующий аргумент -O переименовывает main.js в app.js
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js Откройте app.js в nano или в вашем любимом текстовом редакторе.
nano app.js В строке 12 измените index.html на static/index.html , так как мы создадим каталог static для хранения всех HTML-шаблонов.
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. Сохраните изменения и выйдите из редактора. Ваш файл должен соответствовать исходному коду файла app.js Теперь создайте новый каталог для размещения наших HTML-шаблонов.
mkdir staticЗагрузите таблицу стилей, созданную для этого проекта.
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css Откройте static/index.html в nano или в вашем любимом текстовом редакторе. Начните со стандартной структуры HTML.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>Сразу после названия добавьте ссылку на шрифт Montserrat, связанный с Google Fonts и таблицей стилей.
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> Между main тегами добавьте слот для предполагаемого названия комнаты.
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>Теперь ваш сценарий должен точно соответствовать следующему. Выйдите из редактора.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>Теперь измените файл пакета, чтобы он содержал команду запуска.
nano package.json Сразу после строки 7 добавьте команду start с псевдонимом electron . . Не забудьте добавить запятую в конце предыдущей строки.
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, Сохранить и выйти. Теперь вы готовы запустить свое настольное приложение в Electron JS. Используйте npm для запуска вашего приложения.
npm startВаше настольное приложение должно соответствовать следующему.

На этом ваше начальное настольное приложение завершено. Чтобы выйти, вернитесь к своему терминалу и нажмите CTRL+C. На следующем шаге мы будем записывать сети Wi-Fi и сделаем утилиту записи доступной через пользовательский интерфейс настольного приложения.
Шаг 2: Запишите сети WiFi
На этом шаге вы напишете скрипт NodeJS, который записывает мощность и частоту всех сетей Wi-Fi в пределах досягаемости. Создайте каталог для ваших скриптов.
mkdir scripts Откройте scripts/observe.js в nano или в вашем любимом текстовом редакторе.
nano scripts/observe.jsИмпортируйте утилиту Wi-Fi NodeJS и объект файловой системы.
var wifi = require('node-wifi'); var fs = require('fs'); Определите функцию record , которая принимает обработчик завершения.
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } Внутри новой функции инициализируйте утилиту wifi. Установите для iface значение null, чтобы инициализировать случайный интерфейс Wi-Fi, так как это значение в настоящее время не имеет значения.
function record(n, completion, hook) { wifi.init({ iface : null }); }Определите массив, который будет содержать ваши образцы. Образцы — это обучающие данные, которые мы будем использовать для нашей модели. Образцы в этом конкретном руководстве представляют собой списки сетей Wi-Fi в пределах досягаемости и связанных с ними сильных сторон, частот, имен и т. д.
function record(n, completion, hook) { ... samples = [] } Определите рекурсивную функцию startScan , которая будет асинхронно инициировать сканирование Wi-Fi. По завершении асинхронное сканирование Wi-Fi будет рекурсивно вызывать startScan .
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } В wifi.scan проверьте наличие ошибок или пустых списков сетей и перезапустите сканирование, если это так.
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });Добавьте базовый вариант рекурсивной функции, который вызывает обработчик завершения.
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });Выведите обновление прогресса, добавьте к списку образцов и выполните рекурсивный вызов.
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); В конце вашего файла вызовите функцию record с обратным вызовом, который сохраняет образцы в файл на диске.
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();Дважды проверьте, что ваш файл соответствует следующему:
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();Сохранить и выйти. Запустите скрипт.
node scripts/observe.jsВаш вывод будет соответствовать следующему, с переменным количеством сетей.
* [INFO] Collected sample 1 with 39 networks Изучите только что собранные образцы. Передавайте в json_pp , чтобы красиво распечатать JSON, и передавайте в заголовок, чтобы просмотреть первые 16 строк.
cat samples.json | json_pp | head -16Ниже приведен пример выходных данных для сети 2,4 ГГц.
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },На этом скрипт сканирования Wi-Fi NodeJS завершается. Это позволяет нам просматривать все сети Wi-Fi в пределах досягаемости. На следующем шаге вы сделаете этот сценарий доступным из настольного приложения.
Шаг 3. Подключите сценарий сканирования к настольному приложению
На этом этапе вы сначала добавите кнопку в настольное приложение для запуска сценария. Затем вы обновите пользовательский интерфейс настольного приложения в соответствии с ходом выполнения скрипта.
Откройте static/index.html .
nano static/index.htmlВставьте кнопку «Добавить», как показано ниже.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> Сохранить и выйти. Откройте static/add.html .
nano static/add.htmlВставьте следующее содержимое.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> Сохранить и выйти. Снова откройте scripts/observe.js .
nano scripts/observe.js Под функцией cli определите новую функцию пользовательского ui .
function cli() { ... } // start new code function ui() { } // end new code cli();Обновите статус настольного приложения, чтобы указать, что функция запущена.
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }Разделите данные на обучающие и проверочные наборы данных.
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } Все еще в обратном вызове completion запишите оба набора данных на диск.
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } Вызовите record с соответствующими обратными вызовами, чтобы записать 20 сэмплов и сохранить сэмплы на диск.
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } Наконец, при необходимости вызовите функции cli и ui . Начните с удаления cli(); вызов в нижней части файла.
function ui() { ... } cli(); // remove me Проверьте, доступен ли объект документа глобально. Если нет, скрипт запускается из командной строки. В этом случае вызовите функцию cli . Если это так, сценарий загружается из настольного приложения. В этом случае привяжите прослушиватель кликов к функции пользовательского ui .
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }Сохранить и выйти. Создайте каталог для хранения наших данных.
mkdir dataЗапустите настольное приложение.
npm startВы увидите следующую домашнюю страницу. Нажмите «Добавить комнату».
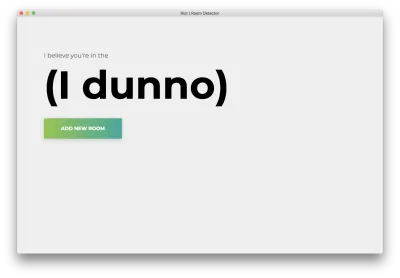
Вы увидите следующую форму. Введите имя комнаты. Запомните это имя, так как мы будем использовать его позже. Нашим примером будет bedroom .
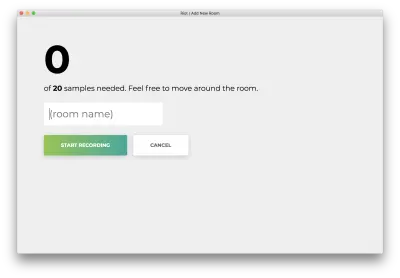
Нажмите «Начать запись», и вы увидите следующий статус «Прослушивание Wi-Fi…».
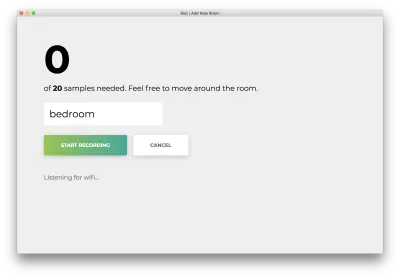
Как только все 20 образцов будут записаны, ваше приложение будет соответствовать следующему. Статус будет «Готово».

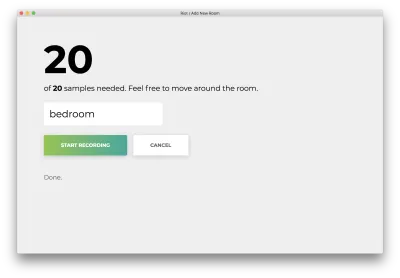
Нажмите на неправильное название «Отмена», чтобы вернуться на домашнюю страницу, которая соответствует следующему.
Теперь мы можем сканировать сети Wi-Fi из пользовательского интерфейса рабочего стола, что сохранит все записанные образцы в файлы на диске. Далее мы обучим готовый алгоритм машинного обучения — метод наименьших квадратов на собранных вами данных.
Шаг 4: Напишите сценарий обучения Python
На этом этапе мы напишем обучающий скрипт на Python. Создайте каталог для ваших учебных утилит.
mkdir model Откройте model/train.py
nano model/train.py В верхней части файла импортируйте вычислительную библиотеку numpy и scipy для ее модели наименьших квадратов.
import numpy as np from scipy.linalg import lstsq import json import sysСледующие три утилиты будут обрабатывать загрузку и настройку данных из файлов на диске. Начните с добавления вспомогательной функции, которая сглаживает вложенные списки. Вы будете использовать это, чтобы сгладить список списка образцов.
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) Добавьте вторую утилиту, загружающую образцы из указанных файлов. Этот метод абстрагируется от того факта, что сэмплы разбросаны по нескольким файлам, возвращая только один генератор для всех сэмплов. Для каждого из образцов метка является индексом файла. например, если вы вызываете get_all_samples('a.json', 'b.json') , все образцы в a.json будут иметь метку 0, а все образцы в b.json будут иметь метку 1.
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, labelЗатем добавьте утилиту, которая кодирует семплы, используя модель мешка слов. Вот пример: Предположим, мы собираем две выборки.
- сеть Wi-Fi A с силой 10 и сеть Wi-Fi B с силой 15
- сеть Wi-Fi B с силой 20 и сеть Wi-Fi C с силой 25.
Эта функция создаст список из трех чисел для каждого из образцов: первое значение — мощность сети Wi-Fi A, второе — для сети B, а третье — для C. По сути, формат имеет вид [A, B, C ].
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] Используя все три утилиты выше, мы синтезируем коллекцию семплов и их меток. Соберите все образцы и метки, используя get_all_samples . Определите согласованный ordering форматов для горячего кодирования всех сэмплов, а затем примените к семплам кодирование one_hot . Наконец, создайте данные и пометьте матрицы X и Y соответственно.
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, orderingЭти функции завершают конвейер данных. Затем мы абстрагируемся от предсказания и оценки модели. Начните с определения метода прогнозирования. Первая функция нормализует выходные данные нашей модели, так что сумма всех значений равна 1 и все значения неотрицательны; это гарантирует, что выход является действительным распределением вероятностей. Второй оценивает модель.
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)Затем оцените точность модели. Первая строка запускает прогноз с использованием модели. Второй подсчитывает количество раз, когда предсказанные и истинные значения совпадают, а затем нормализует общее количество выборок.
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy На этом мы завершаем наши утилиты прогнозирования и оценки. После этих утилит определите main функцию, которая будет собирать набор данных, обучать и оценивать. Начните с чтения списка аргументов из командной строки sys.argv ; это комнаты для включения в обучение. Затем создайте большой набор данных из всех указанных комнат.
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)Примените однократное кодирование к этикеткам. Горячее кодирование похоже на описанную выше модель мешка слов; мы используем эту кодировку для обработки категориальных переменных. Скажем, у нас есть 3 возможных метки. Вместо маркировки 1, 2 или 3 мы маркируем данные [1, 0, 0], [0, 1, 0] или [0, 0, 1]. В этом уроке мы не будем объяснять, почему однократное кодирование важно. Обучите модель и оцените как обучающий, так и проверочный наборы.
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)Распечатайте обе точности и сохраните модель на диск.
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() В конце файла запустите main функцию.
if __name__ == '__main__': main()Сохранить и выйти. Дважды проверьте, что ваш файл соответствует следующему:
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() Сохранить и выйти. Вспомните название комнаты, использованное выше при записи 20 сэмплов. Используйте это имя вместо bedroom ниже. Наш пример — bedroom . Мы используем -W ignore для игнорирования предупреждений об ошибке LAPACK.
python -W ignore model/train.py bedroomПоскольку мы собрали обучающие образцы только для одной комнаты, вы должны увидеть 100% точность обучения и проверки.
Train accuracy (100.0%), Validation accuracy (100.0%)Далее мы свяжем этот сценарий обучения с настольным приложением.
Шаг 5: Свяжите скрипт поезда
На этом этапе мы будем автоматически переобучать модель всякий раз, когда пользователь собирает новую партию образцов. Откройте scripts/observe.js .
nano scripts/observe.js Сразу после импорта fs импортируйте генератор дочерних процессов и утилиты.
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); В функции ui добавьте следующий вызов для retrain обучения в конце обработчика завершения.
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } После функции пользовательского ui добавьте следующую функцию retrain . Это порождает дочерний процесс, который запустит скрипт Python. По завершении процесс вызывает обработчик завершения. В случае сбоя он зарегистрирует сообщение об ошибке.
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } Сохранить и выйти. Откройте scripts/utils.js .
nano scripts/utils.js Добавьте следующую утилиту для получения всех наборов данных в data/ .
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }Сохранить и выйти. Для завершения этого шага физически переместитесь в новое место. В идеале между вашим первоначальным местоположением и вашим новым местоположением должна быть стена. Чем больше барьеров, тем лучше будет работать ваше настольное приложение.
Еще раз запустите настольное приложение.
npm startКак и прежде, запустите обучающий скрипт. Нажмите «Добавить комнату».
Введите имя комнаты, которое отличается от названия вашей первой комнаты. Мы будем использовать living room .
Нажмите «Начать запись», и вы увидите следующий статус «Прослушивание Wi-Fi…».
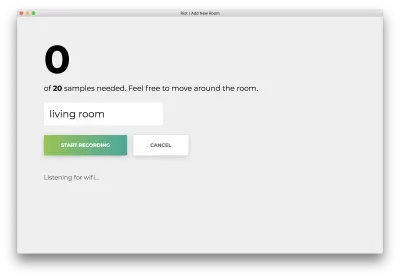
Как только все 20 образцов будут записаны, ваше приложение будет соответствовать следующему. Статус будет «Готово. Модель переподготовки…”
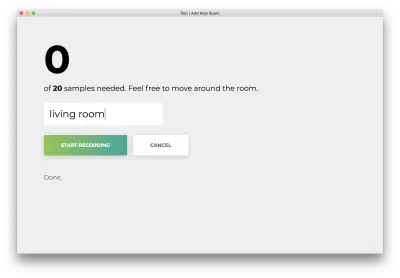
На следующем этапе мы воспользуемся этой переобученной моделью, чтобы прогнозировать комнату, в которой вы находитесь, на лету.
Шаг 6: Напишите сценарий оценки Python
На этом этапе мы загрузим параметры предварительно обученной модели, просканируем сети Wi-Fi и предскажем комнату на основе сканирования.
Откройте model/eval.py .
nano model/eval.pyИмпортируйте библиотеки, используемые и определенные в нашем последнем скрипте.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate Определите утилиту для извлечения имен всех наборов данных. Эта функция предполагает, что все наборы данных хранятся в data/ как <dataset>_train.json и <dataset>_test.json .
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) Определите main функцию и начните с загрузки параметров, сохраненных из сценария обучения.
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')Создайте набор данных и предскажите.
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))Вычислите показатель достоверности на основе разницы между двумя верхними вероятностями.
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) Наконец, извлеките категорию и распечатайте результат. Чтобы завершить скрипт, вызовите функцию main .
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Сохранить и выйти. Дважды проверьте, соответствует ли ваш код следующему (исходный код):
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()Далее мы подключим этот оценочный скрипт к настольному приложению. Настольное приложение будет постоянно запускать сканирование Wi-Fi и обновлять пользовательский интерфейс с помощью прогнозируемой комнаты.
Шаг 7: подключите оценку к настольному приложению
На этом этапе мы обновим пользовательский интерфейс с отображением «уверенности». Затем связанный скрипт NodeJS будет постоянно выполнять сканирование и прогнозирование, соответствующим образом обновляя пользовательский интерфейс.
Откройте static/index.html .
nano static/index.htmlДобавьте строку для уверенности сразу после заголовка и перед кнопками.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> Сразу после main , но до конца body , добавьте новый скрипт predict.js .
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> Сохранить и выйти. Откройте scripts/predict.js .
nano scripts/predict.jsИмпортируйте необходимые утилиты NodeJS для файловой системы, утилит и генератора дочерних процессов.
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; Определите функцию predict , которая вызывает отдельный процесс узла для обнаружения сетей Wi-Fi и отдельный процесс Python для прогнозирования помещения.
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }После запуска обоих процессов добавьте обратные вызовы в процесс Python как для успехов, так и для ошибок. Обратный вызов успеха регистрирует информацию, вызывает обратный вызов завершения и обновляет пользовательский интерфейс с прогнозом и уверенностью. Обратный вызов ошибки регистрирует ошибку.
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } Определите основную функцию для рекурсивного вызова функции predict навсегда.
function main() { f = function() { predict(f) } predict(f) } main();В последний раз откройте настольное приложение, чтобы увидеть прогноз в реальном времени.
npm startПримерно каждую секунду будет выполняться сканирование, и интерфейс будет обновляться с учетом последней достоверности и прогнозируемой комнаты. Поздравления; вы завершили простой комнатный детектор на основе всех сетей Wi-Fi в радиусе действия.
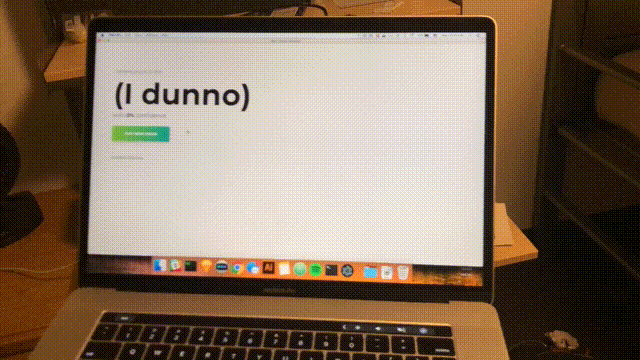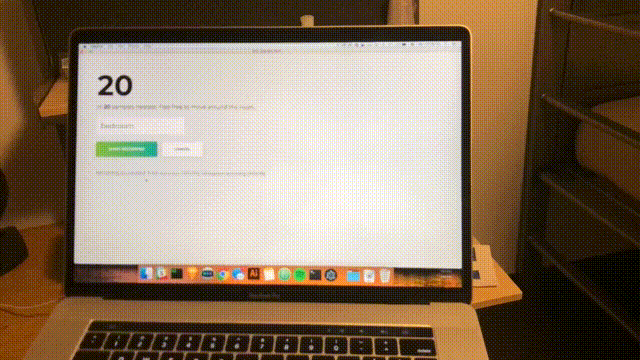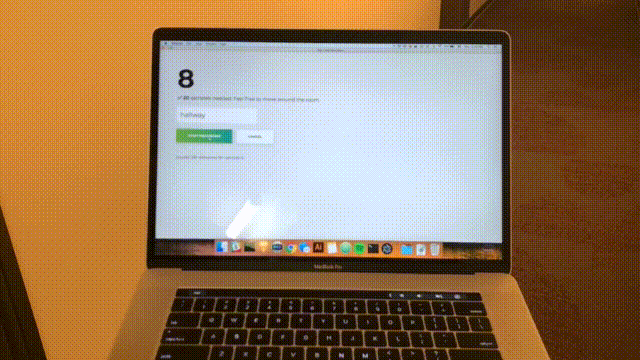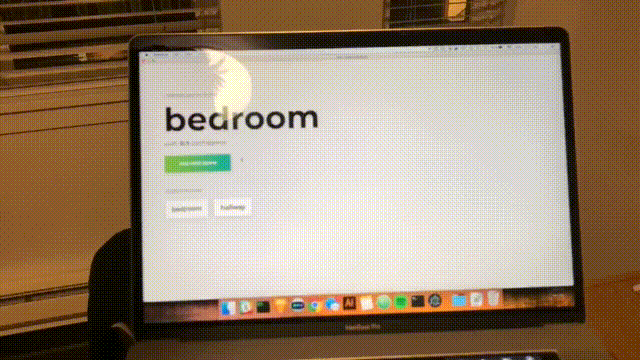
Заключение
В этом руководстве мы создали решение, использующее только ваш рабочий стол для определения вашего местоположения в здании. Мы создали простое настольное приложение с использованием Electron JS и применили простой метод машинного обучения ко всем сетям Wi-Fi в пределах досягаемости. Это прокладывает путь для приложений Интернета вещей без необходимости в массивах устройств, обслуживание которых требует больших затрат (стоимость не в деньгах, а в плане времени и разработки).
Примечание . Полностью исходный код можно увидеть на Github.
Со временем вы можете обнаружить, что метод наименьших квадратов на самом деле не работает впечатляюще. Попробуйте найти два места в одной комнате или встаньте в дверях. Наименьшие квадраты будут большими, неспособными различать крайние случаи. Можем ли мы сделать лучше? Оказывается, мы можем, и в будущих уроках мы будем использовать другие методы и основы машинного обучения для повышения производительности. Этот учебник служит быстрой испытательной площадкой для будущих экспериментов.