
Создание службы централизованного ведения журналов собственными силами
Опубликовано: 2022-03-10Все мы знаем, насколько важна отладка для улучшения производительности и функций приложений. BrowserStack запускает миллион сеансов в день в высокораспределенном стеке приложений! Каждый из них включает в себя несколько движущихся частей, поскольку один сеанс клиента может охватывать несколько компонентов в нескольких географических регионах.
Без правильной структуры и инструментов процесс отладки может превратиться в кошмар. В нашем случае нам нужен был способ сбора событий, происходящих на разных этапах каждого процесса, чтобы получить более глубокое представление обо всем, что происходит во время сеанса. С нашей инфраструктурой решение этой проблемы усложнилось, поскольку каждый компонент может иметь несколько событий из своего жизненного цикла обработки запроса.
Вот почему мы разработали собственный инструмент Central Logging Service (CLS) для записи всех важных событий, зарегистрированных во время сеанса. Эти события помогают нашим разработчикам выявлять условия, при которых в сеансе что-то идет не так, и помогают отслеживать определенные ключевые показатели продукта.
Данные отладки варьируются от простых вещей, таких как задержка ответа API, до мониторинга работоспособности сети пользователя. В этой статье мы поделимся историей создания инструмента CLS, который надежно собирает 70 ГБ релевантных хронологических данных из более чем 100 компонентов в любом масштабе и с двумя инстансами M3.large EC2.
Решение построить дома
Во-первых, давайте рассмотрим, почему мы создали наш инструмент CLS собственными силами, а не использовали существующее решение. Каждый из наших сеансов отправляет в сервис в среднем 15 событий от нескольких компонентов, что составляет примерно 15 миллионов событий в день.
Нашему сервису нужна была возможность хранить все эти данные. Мы искали комплексное решение для поддержки хранения, отправки и запроса событий. Поскольку мы рассматривали сторонние решения, такие как Amplitude и Keen, наши показатели оценки включали стоимость, производительность при обработке большого количества параллельных запросов и простоту внедрения. К сожалению, мы не смогли найти вариант, отвечающий всем нашим требованиям в рамках бюджета, хотя преимущества включали бы экономию времени и минимизацию предупреждений. Хотя это потребует дополнительных усилий, мы решили разработать собственное решение самостоятельно.

Технические подробности
С точки зрения архитектуры для нашего компонента мы обозначили следующие основные требования:
- Производительность клиента
Не влияет на производительность клиента/компонента, отправляющего события. - Шкала
Способен обрабатывать большое количество запросов параллельно. - Производительность службы
Быстро обрабатывать все события, отправляемые на него. - Понимание данных
Каждое зарегистрированное событие должно иметь некоторую метаинформацию, чтобы иметь возможность однозначно идентифицировать компонент или пользователя, учетную запись или сообщение и предоставить дополнительную информацию, чтобы помочь разработчику быстрее выполнять отладку. - Опрашиваемый интерфейс
Разработчики могут запрашивать все события для определенного сеанса, помогая отлаживать определенный сеанс, создавать отчеты о работоспособности компонентов или генерировать значимую статистику производительности наших систем. - Более быстрое и простое внедрение
Простая интеграция с существующим или новым компонентом, не обременяющая команды и не отнимающая их ресурсы. - Низкие расходы
Мы небольшая команда инженеров, поэтому мы искали решение, позволяющее свести к минимуму оповещения!
Создание нашего решения CLS
Решение 1: выбор интерфейса для демонстрации
При разработке CLS мы, очевидно, не хотели потерять какие-либо данные, но мы также не хотели, чтобы производительность компонентов пострадала. Не говоря уже о дополнительном факторе предотвращения усложнения существующих компонентов, поскольку это задержит общее внедрение и выпуск. При определении нашего интерфейса мы рассмотрели следующие варианты:
- Сохранение событий в локальном Redis в каждом компоненте, поскольку фоновый процессор отправляет их в CLS. Однако для этого требуется изменение всех компонентов, а также введение Redis для компонентов, которые еще не содержали его.
- Модель издатель-подписчик, где Redis ближе к CLS. Поскольку все публикуют события, опять же у нас есть фактор компонентов, работающих по всему миру. Во время интенсивного движения это приведет к задержке компонентов. Кроме того, эта запись может периодически увеличиваться до пяти секунд (только из-за Интернета).
- Отправка событий по UDP, что оказывает меньшее влияние на производительность приложения. В этом случае данные будут отправлены и забыты, однако недостатком здесь будет потеря данных.
Интересно, что наши потери данных по UDP составили менее 0,1 процента, что было приемлемым значением для нас, чтобы рассмотреть возможность создания такого сервиса. Мы смогли убедить все команды в том, что такая сумма потерь стоила производительности, и пошли дальше, чтобы использовать интерфейс UDP, который прослушивал все отправляемые события.
Хотя одним из результатов было меньшее влияние на производительность приложения, мы столкнулись с проблемой, поскольку UDP-трафик не разрешался из всех сетей, в основном из сетей наших пользователей, из-за чего в некоторых случаях мы вообще не получали данные. В качестве обходного пути мы поддерживали регистрацию событий с помощью HTTP-запросов. Все события, поступающие со стороны пользователя, будут отправляться по HTTP, а все события, записываемые нашими компонентами, — по UDP.
Решение 2: технический стек (язык, платформа и хранилище)
Мы рубиновый магазин. Однако мы не были уверены, будет ли Ruby лучшим выбором для решения нашей конкретной задачи. Наш сервис должен был бы обрабатывать много входящих запросов, а также обрабатывать много записей. С блокировкой Global Interpreter добиться многопоточности или параллелизма в Ruby будет сложно (пожалуйста, не обижайтесь — мы любим Ruby!). Поэтому нам нужно было решение, которое помогло бы нам достичь такого параллелизма.
Мы также стремились оценить новый язык в нашем техническом стеке, и этот проект казался идеальным для экспериментов с новыми вещами. Именно тогда мы решили попробовать Golang, так как он предлагает встроенную поддержку параллелизма и облегченных потоков и подпрограмм. Каждая зарегистрированная точка данных напоминает пару «ключ-значение», где «ключ» — это событие, а «значение» — связанное с ним значение.
Но простого ключа и значения недостаточно для извлечения данных, связанных с сеансом, — для этого есть больше метаданных. Чтобы решить эту проблему, мы решили, что любое событие, которое необходимо зарегистрировать, будет иметь идентификатор сеанса вместе с его ключом и значением. Мы также добавили дополнительные поля, такие как отметка времени, идентификатор пользователя и компонент, регистрирующий данные, чтобы стало проще получать и анализировать данные.

Теперь, когда мы определились со структурой полезной нагрузки, нам нужно было выбрать хранилище данных. Мы рассматривали Elastic Search, но также хотели поддерживать запросы на обновление ключей. Это вызовет повторную индексацию всего документа, что может повлиять на производительность нашей записи. MongoDB имела больше смысла в качестве хранилища данных, поскольку было бы проще запрашивать все события на основе любого из добавляемых полей данных. Это было легко!
Решение 3: Размер БД огромен, а запросы и архивирование — отстой!
Чтобы сократить обслуживание, наша служба должна обрабатывать как можно больше событий. Учитывая скорость, с которой BrowserStack выпускает функции и продукты, мы были уверены, что количество наших событий будет увеличиваться с большей скоростью с течением времени, а это означает, что наш сервис должен продолжать работать хорошо. По мере увеличения пространства операции чтения и записи занимают больше времени, что может серьезно сказаться на производительности службы.
Первое решение, которое мы исследовали, заключалось в перемещении журналов за определенный период из базы данных (в нашем случае мы выбрали 15 дней). Для этого мы создали разные базы данных для каждого дня, что позволяет нам находить журналы старше определенного периода без необходимости сканирования всех письменных документов. Теперь мы постоянно удаляем базы данных старше 15 дней из Mongo, сохраняя, конечно, резервные копии на всякий случай.
Единственной оставшейся частью был интерфейс разработчика для запроса данных, связанных с сеансом. Честно говоря, решить эту проблему было проще всего. Мы предоставляем HTTP-интерфейс, где люди могут запрашивать события, связанные с сеансом, в соответствующей базе данных в MongoDB для любых данных, имеющих определенный идентификатор сеанса.
Архитектура
Поговорим о внутренних компонентах сервиса, учитывая следующие моменты:
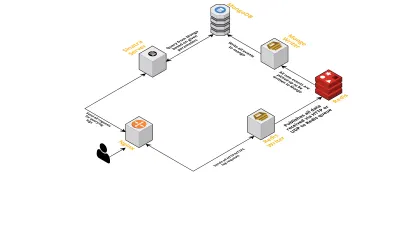
- Как обсуждалось ранее, нам нужны два интерфейса — один для прослушивания через UDP, а другой для прослушивания через HTTP. Поэтому мы построили два сервера, опять же по одному для каждого интерфейса, для прослушивания событий. Как только приходит событие, мы разбираем его, чтобы проверить, есть ли в нем обязательные поля — это идентификатор сессии, ключ и значение. Если это не так, данные удаляются. В противном случае данные передаются по каналу Go другой горутине, единственной обязанностью которой является запись в MongoDB.
- Возможной проблемой здесь является запись в MongoDB. Если запись в MongoDB выполняется медленнее, чем скорость получения данных, это создает узкое место. Это, в свою очередь, блокирует другие входящие события и приводит к потере данных. Поэтому сервер должен быстро обрабатывать входящие журналы и быть готовым к обработке предстоящих. Чтобы решить эту проблему, мы разделили сервер на две части: первая получает все события и ставит их в очередь для второй, которая обрабатывает и записывает их в MongoDB.
- Для организации очередей мы выбрали Redis. Разделив весь компонент на эти две части, мы уменьшили нагрузку на сервер, предоставив ему место для обработки большего количества журналов.
- Мы написали небольшой сервис, используя сервер Sinatra, чтобы выполнять всю работу по запросу MongoDB с заданными параметрами. Он возвращает ответ HTML/JSON разработчикам, когда им нужна информация о конкретном сеансе.
Все эти процессы успешно выполняются на одном экземпляре m3.large .
Запросы функций
Поскольку наш инструмент CLS со временем стал использоваться все шире, ему потребовались дополнительные функции. Ниже мы обсудим их и то, как они были добавлены.
Отсутствующие метаданные
Постепенно, по мере увеличения количества компонентов в BrowserStack, мы требовали от CLS большего. Например, нам нужна была возможность регистрировать события от компонентов, не имеющих идентификатора сеанса. В противном случае его получение обременит нашу инфраструктуру в виде влияния на производительность приложений и увеличения трафика на наших основных серверах.
Мы решили эту проблему, включив ведение журнала событий с использованием других ключей, таких как идентификаторы терминала и пользователя. Теперь всякий раз, когда сеанс создается или обновляется, CLS сообщает идентификатор сеанса, а также соответствующие идентификаторы пользователя и терминала. В нем хранится карта, которую можно получить в процессе записи в MongoDB. Всякий раз, когда извлекается событие, содержащее идентификатор пользователя или терминала, добавляется идентификатор сеанса.
Обработка спама (проблемы с кодом в других компонентах)
CLS также столкнулась с обычными трудностями при обработке спама. Мы часто обнаруживали развертывания в компонентах, которые генерировали огромное количество запросов, отправляемых в CLS. При этом пострадают другие журналы, так как сервер стал слишком занят для их обработки, а важные журналы были удалены.
По большей части большая часть регистрируемых данных поступала через HTTP-запросы. Чтобы контролировать их, мы включаем ограничение скорости на nginx (используя модуль limit_req_zone), который блокирует запросы с любого IP-адреса, который, как мы обнаружили, превышает определенное количество запросов за небольшой промежуток времени. Конечно, мы используем отчеты о работоспособности для всех заблокированных IP-адресов и информируем ответственные команды.
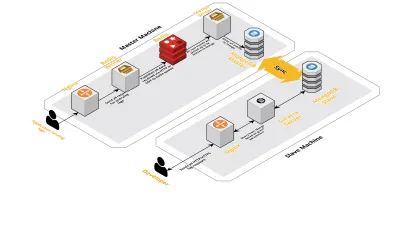
Масштаб v2
По мере того, как число наших сеансов в день увеличивалось, данные, регистрируемые в CLS, также увеличивались. Это повлияло на запросы, которые наши разработчики выполняли ежедневно, и вскоре узким местом стала сама машина. Наша установка состояла из двух основных машин, на которых работали все вышеперечисленные компоненты, а также куча скриптов для запросов к Mongo и отслеживания ключевых показателей для каждого продукта. Со временем данные на машине сильно увеличились, и скрипты стали занимать много процессорного времени. Даже после попытки оптимизировать запросы Mongo мы всегда возвращались к одним и тем же проблемам.
Чтобы решить эту проблему, мы добавили еще один компьютер для запуска сценариев отчетов о работоспособности и интерфейс для запроса этих сеансов. Процесс включал загрузку новой машины и настройку ведомого устройства Mongo, работающего на основной машине. Это помогло уменьшить всплески ЦП, которые мы наблюдали каждый день из-за этих скриптов.
Заключение
Создание службы для такой простой задачи, как регистрация данных, может усложниться по мере увеличения объема данных. В этой статье обсуждаются решения, которые мы исследовали, а также проблемы, с которыми пришлось столкнуться при решении этой проблемы. Мы экспериментировали с Golang, чтобы посмотреть, насколько хорошо он впишется в нашу экосистему, и до сих пор остались довольны. Наш выбор создать внутреннюю службу, а не платить за внешнюю, оказался на удивление эффективным с точки зрения затрат. Нам также не нужно было масштабировать нашу установку на другой компьютер до тех пор, пока объем наших сеансов не увеличился. Конечно, наш выбор при разработке CLS полностью основывался на наших требованиях и приоритетах.
Сегодня CLS обрабатывает до 15 миллионов событий каждый день, что составляет до 70 ГБ данных. Эти данные используются, чтобы помочь нам решить любые проблемы, с которыми сталкиваются наши клиенты во время любого сеанса. Мы также используем эти данные для других целей. Учитывая информацию, которую данные каждого сеанса дают о различных продуктах и внутренних компонентах, мы начали использовать эти данные для отслеживания каждого продукта. Это достигается путем извлечения ключевых показателей для всех важных компонентов.
В целом, мы добились больших успехов в создании собственного инструмента CLS. Если это имеет смысл для вас, я рекомендую вам подумать о том же!