
Как создать парсер продуктов Amazon с помощью Node.js
Опубликовано: 2022-03-10Вы когда-нибудь были в ситуации, когда вам необходимо хорошо знать рынок определенного продукта? Возможно, вы запускаете какое-то программное обеспечение и вам нужно знать, как его оценить. Или, возможно, у вас уже есть собственный продукт на рынке, и вы хотите посмотреть, какие функции добавить для конкурентного преимущества. Или, может быть, вы просто хотите купить что-то для себя и убедиться, что вы получите максимальную отдачу от затраченных средств.
Все эти ситуации объединяет одно: для принятия правильного решения нужны точные данные . На самом деле, есть еще одна вещь, которую они разделяют. Все сценарии могут выиграть от использования парсера.
Веб-скрапинг — это практика извлечения больших объемов веб-данных с помощью программного обеспечения. Так что, по сути, это способ автоматизировать утомительный процесс нажатия «копировать», а затем «вставить» 200 раз. Конечно, бот может сделать это за то время, пока вы читаете это предложение, так что это не только менее скучно, но и намного быстрее.
Но животрепещущий вопрос: зачем кому-то парсить страницы Amazon?
Вы собираетесь узнать! Но прежде всего, я хотел бы прямо сейчас кое-что прояснить — хотя акт очистки общедоступных данных является законным, у Amazon есть некоторые меры, чтобы предотвратить это на своих страницах. Поэтому я призываю вас всегда помнить о веб-сайте при очистке, стараться не повредить его и следовать этическим принципам.
Рекомендуемая литература : «Руководство по этичному анализу динамических веб-сайтов с помощью Node.js и Puppeteer» Андреаса Альтхаймера.
Почему вы должны извлекать данные о продуктах Amazon
Будучи крупнейшим интернет-магазином на планете, можно с уверенностью сказать, что если вы хотите что-то купить, вы, вероятно, можете купить это на Amazon. Таким образом, само собой разумеется, насколько велика сокровищница данных на веб-сайте.
При очистке сети ваш главный вопрос должен заключаться в том, что делать со всеми этими данными. Хотя существует множество индивидуальных причин, все сводится к двум важным вариантам использования: оптимизации ваших продуктов и поиску лучших предложений.
“
Начнем с первого сценария. Если вы не разработали действительно инновационный новый продукт, скорее всего, вы уже можете найти что-то похожее на Amazon. Очистка этих страниц продуктов может принести вам бесценные данные, такие как:
- Ценовая стратегия конкурентов
Таким образом, вы можете скорректировать свои цены, чтобы они были конкурентоспособными, и понять, как другие проводят рекламные акции; - Мнения клиентов
Чтобы увидеть, что больше всего волнует вашу будущую клиентскую базу и как улучшить их опыт; - Наиболее распространенные функции
Чтобы увидеть, что предлагают ваши конкуренты, чтобы узнать, какие функции имеют решающее значение, а какие можно оставить на потом.
По сути, на Amazon есть все необходимое для глубокого анализа рынка и продукта. Благодаря этим данным вы будете лучше подготовлены к разработке, запуску и расширению линейки продуктов.
Второй сценарий может относиться как к бизнесу, так и к обычным людям. Идея очень похожа на то, что я упоминал ранее. Вы можете просмотреть цены, характеристики и обзоры всех продуктов, которые вы можете выбрать, и, таким образом, вы сможете выбрать тот, который предлагает наибольшие преимущества по самой низкой цене. В конце концов, кто не любит хорошую сделку?
Не все продукты заслуживают такого внимания к деталям, но это может иметь огромное значение для дорогих покупок. К сожалению, хотя преимущества очевидны, со скрейпингом Amazon связано много трудностей.
Проблемы очистки данных о продуктах Amazon
Не все веб-сайты одинаковы. Как правило, чем сложнее и распространеннее веб-сайт, тем сложнее его парсить. Помните, я сказал, что Amazon — самый известный сайт электронной коммерции? Что ж, это делает его чрезвычайно популярным и достаточно сложным.
Во-первых, Amazon знает, как действуют парсинг-боты, поэтому на сайте предусмотрены контрмеры. А именно, если парсер следует предсказуемой схеме, отправляя запросы через фиксированные промежутки времени, быстрее, чем это может сделать человек, или с почти идентичными параметрами, Amazon заметит и заблокирует IP-адрес. Прокси могут решить эту проблему, но они мне не понадобились, так как в примере мы не будем парсить слишком много страниц.
Далее, Amazon намеренно использует различные структуры страниц для своих продуктов. То есть, если вы проверите страницы на наличие разных продуктов, есть большая вероятность, что вы обнаружите существенные различия в их структуре и атрибутах. Причина этого довольно проста. Вам нужно адаптировать код парсера для конкретной системы , и если вы используете тот же скрипт на новом типе страниц, вам придется переписывать его части. Таким образом, они, по сути, заставляют вас больше работать ради данных.
Наконец, Amazon — это огромный веб-сайт. Если вы хотите собрать большие объемы данных, запуск программного обеспечения для парсинга на вашем компьютере может занять слишком много времени для ваших нужд. Эта проблема усугубляется еще и тем фактом, что слишком быстрое движение приведет к блокировке вашего парсера. Итак, если вы хотите быстро получить кучу данных, вам понадобится по-настоящему мощный парсер.
Что ж, хватит говорить о проблемах, давайте сосредоточимся на решениях!
Как создать веб-скрейпер для Amazon
Для простоты мы будем использовать пошаговый подход к написанию кода. Не стесняйтесь работать параллельно с гидом.
Ищем нужные нам данные
Итак, вот сценарий: через несколько месяцев я переезжаю на новое место, и мне понадобится пара новых полок для книг и журналов. Я хочу знать все свои варианты и получить как можно более выгодную сделку. Итак, давайте зайдем на рынок Амазон, поищем «полки» и посмотрим, что у нас получится.
URL-адрес для этого поиска и страница, которую мы будем очищать, находятся здесь.
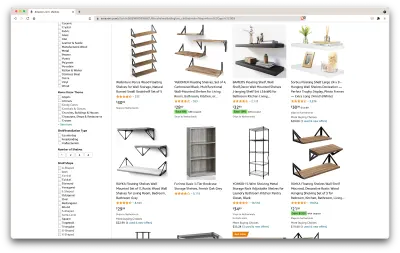
Хорошо, давайте подведем итоги того, что у нас есть. Просто взглянув на страницу, мы можем получить хорошее представление о:
- как выглядят полки;
- что входит в комплект;
- как клиенты их оценивают;
- их цена;
- ссылка на товар;
- предложение более дешевой альтернативы для некоторых предметов.
Это больше, чем мы могли просить!
Получить необходимые инструменты
Прежде чем переходить к следующему шагу, убедитесь, что у нас установлены и настроены все следующие инструменты.
- Хром
Мы можем скачать его отсюда. - VSCode
Следуйте инструкциям на этой странице, чтобы установить его на конкретное устройство. - Node.js
Прежде чем начать использовать Axios или Cheerio, нам нужно установить Node.js и диспетчер пакетов Node. Самый простой способ установить Node.js и NPM — получить один из установщиков из официального источника Node.Js и запустить его.
Теперь давайте создадим новый проект NPM. Создайте новую папку для проекта и выполните следующую команду:
npm init -yЧтобы создать парсер, нам нужно установить пару зависимостей в нашем проекте:
- Черио
Библиотека с открытым исходным кодом, которая помогает нам извлекать полезную информацию, анализируя разметку и предоставляя API для управления полученными данными. Cheerio позволяет нам выбирать теги HTML-документа с помощью селекторов:$("div"). Этот специальный селектор помогает нам выбрать все элементы<div>на странице. Чтобы установить Cheerio, выполните следующую команду в папке проектов:
npm install cheerio- Аксиос
Библиотека JavaScript, используемая для отправки HTTP-запросов из Node.js.
npm install axiosПроверить исходный код страницы
На следующих шагах мы узнаем больше о том, как информация организована на странице. Идея состоит в том, чтобы лучше понять, что мы можем извлечь из нашего источника.
Инструменты разработчика помогают нам в интерактивном режиме исследовать объектную модель документа (DOM) веб-сайта. Мы будем использовать инструменты разработчика в Chrome, но вы можете использовать любой удобный вам веб-браузер.
Давайте откроем его, щелкнув правой кнопкой мыши в любом месте страницы и выбрав опцию «Проверить»:
Это откроет новое окно, содержащее исходный код страницы. Как мы уже говорили ранее, мы стремимся собрать информацию с каждой полки.
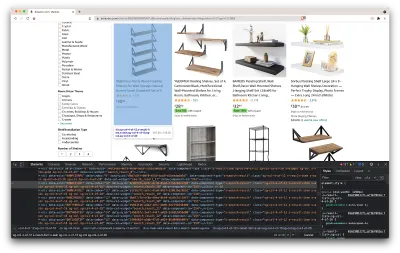
Как видно из скриншота выше, контейнеры, содержащие все данные, имеют следующие классы:
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20На следующем шаге мы будем использовать Cheerio для выбора всех элементов, содержащих нужные нам данные.

Получить данные
После того, как мы установили все представленные выше зависимости, давайте создадим новый файл index.js и введем следующие строки кода:
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); Как мы видим, мы импортируем нужные нам зависимости в первых двух строках, а затем создаем функцию fetchShelves() , которая с помощью Cheerio получает со страницы все элементы, содержащие информацию о наших продуктах.
Он выполняет итерацию по каждому из них и помещает его в пустой массив, чтобы получить результат в лучшем формате.
На данный момент функция fetchShelves() вернет только название продукта, так что давайте получим остальную информацию, которая нам нужна. Добавьте следующие строки кода после строки, в которой мы определили title переменной.
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } И замените shelves.push(title) на shelves.push(element) .
Теперь мы выбираем всю необходимую информацию и добавляем ее в новый объект с именем element . Затем каждый элемент помещается в массив shelves , чтобы получить список объектов, содержащих только те данные, которые мы ищем.
Вот как должен выглядеть объект shelf , прежде чем он будет добавлен в наш список:
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }Отформатируйте данные
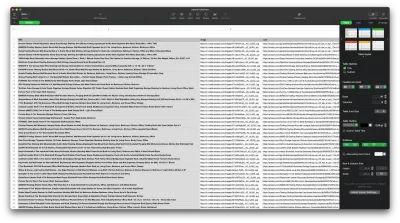
Теперь, когда нам удалось получить необходимые данные, рекомендуется сохранить их в виде файла .CSV , чтобы улучшить читаемость. После получения всех данных мы воспользуемся модулем fs , предоставленным Node.js, и сохраним новый файл с именем saved-shelves.csv в папке проекта. Импортируйте модуль fs в верхней части файла и скопируйте или напишите следующие строки кода:
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) Как мы видим, в первых трех строках мы форматируем ранее собранные данные, соединяя все значения объекта полки с помощью запятой. Затем, используя модуль fs , мы создаем файл с именем saved-shelves.csv , добавляем новую строку, содержащую заголовки столбцов, добавляем данные, которые мы только что отформатировали, и создаем функцию обратного вызова, которая обрабатывает ошибки.
Результат должен выглядеть примерно так:
Бонусные советы!
Парсинг одностраничных приложений
В настоящее время динамический контент становится стандартом, поскольку веб-сайты стали более сложными, чем когда-либо прежде. Чтобы обеспечить наилучшее взаимодействие с пользователем, разработчики должны применять различные механизмы загрузки динамического контента , что немного усложняет нашу работу. Если вы не знаете, что это значит, представьте себе браузер без графического пользовательского интерфейса. К счастью, есть Puppeteer — волшебная библиотека Node, предоставляющая высокоуровневый API для управления экземпляром Chrome по протоколу DevTools. Тем не менее, он предлагает ту же функциональность, что и браузер, но им нужно управлять программно, набрав пару строк кода. Давайте посмотрим, как это работает.
В ранее созданном проекте установите библиотеку Puppeteer, запустив npm install puppeteer , создайте новый файл puppeteer.js и скопируйте или напишите следующие строки кода:
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() В приведенном выше примере мы создаем экземпляр Chrome и открываем новую страницу браузера, необходимую для перехода по этой ссылке. В следующей строке мы говорим безголовому браузеру ждать, пока на странице не появится элемент с классом rpBJOHq2PR60pnwJlUyP0 . Мы также указали , как долго браузер должен ждать загрузки страницы (2000 миллисекунд).
Используя метод evaluate для переменной page , мы указали Puppeteer выполнять фрагменты Javascript в контексте страницы сразу после того, как элемент был окончательно загружен. Это позволит нам получить доступ к содержимому HTML страницы и вернуть тело страницы в качестве вывода. Затем мы закрываем экземпляр Chrome, вызывая метод close для переменной chrome . Полученная работа должна состоять из всего динамически сгенерированного HTML-кода. Вот как Puppeteer может помочь нам загрузить динамический HTML-контент .
Если вам неудобно использовать Puppeteer, обратите внимание, что есть несколько альтернатив, таких как NightwatchJS, NightmareJS или CasperJS. Они немного отличаются, но, в конце концов, процесс очень похож.
Настройка заголовков user-agent
user-agent — это заголовок запроса, который сообщает веб-сайту, который вы посещаете, о себе, а именно о вашем браузере и ОС. Это используется для оптимизации контента для вашей настройки, но веб-сайты также используют его для идентификации ботов, отправляющих множество запросов, даже если это меняет IPS.
Вот как выглядит заголовок user-agent :
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36Чтобы вас не обнаружили и не заблокировали, вам следует регулярно менять этот заголовок. Соблюдайте особую осторожность, чтобы не отправлять пустой или устаревший заголовок, так как это никогда не должно произойти с рядовым пользователем, и вы будете выделяться.
Ограничение скорости
Веб-скраперы могут очень быстро собирать контент, но вам следует избегать максимальной скорости. Этому есть две причины:
- Слишком большое количество запросов в короткие сроки может замедлить работу сервера веб-сайта или даже вывести его из строя, что создаст проблемы для владельца и других посетителей. По сути, это может стать DoS-атакой.
- Без чередующихся прокси это сродни громкому объявлению о том, что вы используете бота, поскольку ни один человек не будет отправлять сотни или тысячи запросов в секунду.
Решение состоит в том, чтобы ввести задержку между вашими запросами, практика, называемая «ограничение скорости». ( Это тоже довольно просто реализовать! )
В приведенном выше примере Puppeteer перед созданием переменной body мы можем использовать метод waitForTimeout , предоставленный Puppeteer, чтобы подождать пару секунд, прежде чем делать другой запрос:
await page.waitForTimeout(3000); Где ms - это количество секунд, которое вы хотели бы подождать.
Кроме того, если мы хотим сделать то же самое для примера axios, мы можем создать обещание, которое вызывает метод setTimeout() , чтобы помочь нам дождаться желаемого количества миллисекунд:
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))Таким образом, вы можете избежать чрезмерной нагрузки на целевой сервер, а также привнести более человеческий подход к очистке веб-страниц.
Заключительные мысли
И вот оно, пошаговое руководство по созданию собственного парсера для данных о продуктах Amazon! Но помните, это была всего лишь одна ситуация. Если вы хотите парсить другой веб-сайт, вам придется сделать несколько настроек, чтобы получить какие-либо значимые результаты.
Связанное Чтение
Если вы все еще хотите увидеть больше веб-скрапинга в действии, вот несколько полезных материалов для чтения:
- «Полное руководство по парсингу веб-страниц с помощью JavaScript и Node.Js», Роберт Сфичи.
- «Расширенный парсинг веб-страниц Node.JS с помощью Puppeteer», Габриэль Чиоки.
- «Парсинг веб-страниц на Python: полное руководство по созданию парсера», Ралука Пенчук.