
Создайте приложение для создания закладок с помощью FaunaDB, Netlify и 11ty
Опубликовано: 2022-03-10Революция JAMstack (JavaScript, API и разметка) в самом разгаре. Статические сайты безопасны, быстры, надежны и с ними интересно работать. В основе JAMstack лежат генераторы статических сайтов (SSG), которые хранят ваши данные в виде плоских файлов: Markdown, YAML, JSON, HTML и т. д. Иногда такое управление данными может быть слишком сложным. Иногда нам все еще нужна база данных.
Имея это в виду, Netlify — хост статического сайта и FaunaDB — бессерверная облачная база данных — сотрудничали, чтобы упростить объединение обеих систем.
Почему сайт закладок?
JAMstack отлично подходит для многих профессиональных применений, но одним из моих любимых аспектов этого набора технологий является его низкий порог входа для личных инструментов и проектов.
На рынке есть много хороших продуктов для большинства приложений, которые я мог бы придумать, но ни один из них не был бы точно настроен для меня. Ни один из них не дал бы мне полный контроль над моим контентом. Ни один из них не обходится без затрат (денежных или информационных).
Имея это в виду, мы можем создавать свои собственные мини-сервисы, используя методы JAMstack. В этом случае мы создадим сайт для хранения и публикации любых интересных статей, с которыми я сталкиваюсь при ежедневном чтении книг о технологиях.
Я провожу много времени за чтением статей, которыми поделились в Твиттере. Когда мне нравится один, я нажимаю значок «сердце». Затем, в течение нескольких дней, почти невозможно найти с наплывом новых фаворитов. Я хочу построить что-то максимально близкое к легкости «сердца», но принадлежащее мне и контролируемое мной.
Как мы собираемся это сделать? Я рад, что вы спросили.
Заинтересованы в получении кода? Вы можете получить его на Github или просто развернуть прямо в Netlify из этого репозитория! Посмотрите на готовый продукт здесь.
Наши технологии
Хостинг и бессерверные функции: Netlify
Для хостинга и бессерверных функций мы будем использовать Netlify. В качестве дополнительного бонуса, благодаря упомянутому выше новому сотрудничеству, интерфейс командной строки Netlify — «Netlify Dev» — будет автоматически подключаться к FaunaDB и сохранять наши ключи API в качестве переменных среды.
База данных: ФаунаDB
FaunaDB — это «бессерверная» база данных NoSQL. Мы будем использовать его для хранения данных наших закладок.
Генератор статических сайтов: 11ty
Я большой сторонник HTML. Из-за этого в учебнике не будет использоваться внешний JavaScript для рендеринга наших закладок. Вместо этого мы будем использовать 11ty в качестве генератора статических сайтов. 11ty имеет встроенную функциональность данных, которая позволяет получать данные из API так же просто, как написать пару коротких функций JavaScript.
Ярлыки iOS
Нам понадобится простой способ размещения данных в нашей базе данных. В этом случае мы будем использовать приложение iOS Shortcuts. Его также можно преобразовать в букмарклет JavaScript для Android или настольного компьютера.
Настройка FaunaDB через Netlify Dev
Если вы уже зарегистрировались в FaunaDB или вам нужно создать новую учетную запись, самый простой способ установить связь между FaunaDB и Netlify — через интерфейс командной строки Netlify: Netlify Dev. Вы можете найти полные инструкции от FaunaDB здесь или следовать ниже.
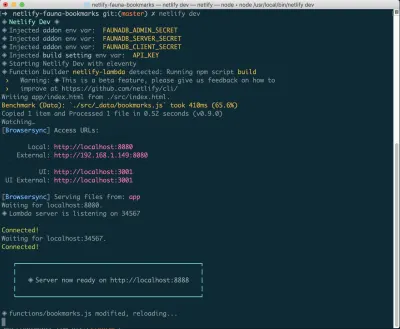
Если у вас это еще не установлено, вы можете запустить следующую команду в Терминале:
npm install netlify-cli -gИз каталога вашего проекта выполните следующие команды:
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account Как только все это подключено, вы можете запустить netlify dev в своем проекте. Это запустит все настроенные нами сценарии сборки, а также подключится к службам Netlify и FaunaDB и захватит все необходимые переменные среды. Удобно!
Создание наших первых данных
Отсюда мы войдем в FaunaDB и создадим наш первый набор данных. Мы начнем с создания новой базы данных под названием «bookmarks». Внутри базы данных у нас есть коллекции, документы и индексы.
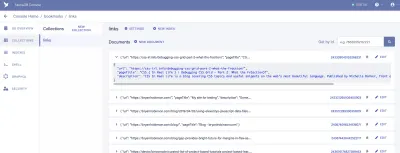
Коллекция — это категоризированная группа данных. Каждая часть данных принимает форму документа. Документ — это «отдельная изменяемая запись в базе данных FaunaDB», согласно документации Fauna. Вы можете думать о коллекциях как о традиционной таблице базы данных, а о документе — как о строке.
Для нашего приложения нам нужна одна коллекция, которую мы назовем «ссылки». Каждый документ в коллекции «ссылки» будет простым объектом JSON с тремя свойствами. Для начала мы добавим новый документ, который будем использовать для построения нашей первой выборки данных.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }Это создает основу для информации, которую нам нужно будет извлечь из наших закладок, а также предоставляет нам наш первый набор данных для добавления в наш шаблон.
Если вы похожи на меня, вы хотите сразу же увидеть плоды своего труда. Давайте что-нибудь на странице!
Установка 11ty и загрузка данных в шаблон
Так как мы хотим, чтобы закладки отображались в HTML, а не извлекались браузером, нам нужно что-то для рендеринга. Есть много отличных способов сделать это, но из-за простоты и мощности я люблю использовать генератор статических сайтов 11ty.
Поскольку 11ty — это генератор статических сайтов на JavaScript, мы можем установить его через NPM.
npm install --save @11ty/eleventy Из этой установки мы можем запустить eleventy или eleventy --serve в нашем проекте, чтобы начать работу.
Netlify Dev часто определяет 11ty как требование и запускает для нас команду. Чтобы выполнить эту работу и убедиться, что мы готовы к развертыванию, мы также можем создать команды «serve» и «build» в нашем package.json .
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }Файлы данных 11ty
Большинство генераторов статических сайтов имеют встроенную идею «файла данных». Обычно это файлы JSON или YAML, которые позволяют добавлять дополнительную информацию на ваш сайт.
В 11ty вы можете использовать файлы данных JSON или файлы данных JavaScript. Используя файл JavaScript, мы можем выполнять вызовы API и возвращать данные непосредственно в шаблон.
По умолчанию 11ty хочет, чтобы файлы данных хранились в каталоге _data . Затем вы можете получить доступ к данным, используя имя файла в качестве переменной в ваших шаблонах. В нашем случае мы создадим файл по адресу _data/bookmarks.js и получим к нему доступ через имя переменной {{ bookmarks }} .
Если вы хотите углубиться в настройку файлов данных, вы можете прочитать примеры в документации 11ty или ознакомиться с этим руководством по использованию файлов данных 11ty с API Meetup.
Файл будет модулем JavaScript. Итак, чтобы что-то заработало, нам нужно экспортировать либо наши данные, либо функцию. В нашем случае мы экспортируем функцию.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } Давайте сломаем это. Здесь у нас есть две функции, выполняющие основную работу: mapBookmarks() и getBookmarks() .
Функция getBookmarks() будет получать наши данные из нашей базы данных FaunaDB, а mapBookmarks() возьмет массив закладок и реструктурирует его, чтобы он лучше работал с нашим шаблоном.
Давайте углубимся в getBookmarks() .
getBookmarks()
Во-первых, нам нужно установить и инициализировать экземпляр драйвера JavaScript FaunaDB.
npm install --save faunadbТеперь, когда мы его установили, давайте добавим его в начало нашего файла данных. Этот код взят прямо из документации Fauna.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); После этого мы можем создать нашу функцию. Мы начнем с создания нашего первого запроса, используя встроенные методы драйвера. Этот первый фрагмент кода вернет ссылки на базу данных, которые мы можем использовать для получения полных данных для всех наших ссылок с закладками. Мы используем метод Paginate в качестве помощника для управления состоянием курсора, если мы решим разбить данные на страницы перед передачей их 11ty. В нашем случае мы просто вернем все ссылки.
В этом примере я предполагаю, что вы установили и подключили FaunaDB через Netlify Dev CLI. Используя этот процесс, вы получаете локальные переменные среды секретов FaunaDB. Если вы не установили его таким образом или не используете netlify dev в своем проекте, вам понадобится пакет, такой как dotenv , для создания переменных среды. Вам также потребуется добавить переменные среды в конфигурацию вашего сайта Netlify, чтобы развертывание работало позже.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })Этот код вернет массив всех наших ссылок в справочной форме. Теперь мы можем создать список запросов для отправки в нашу базу данных.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) Отсюда нам просто нужно очистить возвращенные данные. Вот где mapBookmarks() !
mapBookmarks()
В этой функции мы имеем дело с двумя аспектами данных.
Во-первых, мы получаем бесплатную дату и время в FaunaDB. Для любых созданных данных существует свойство временной метки ( ts ). Он не отформатирован таким образом, чтобы удовлетворил фильтр даты по умолчанию в Liquid, так что давайте это исправим.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } После этого мы можем создать новый объект для наших данных. В этом случае у него будет свойство time , и мы будем использовать оператор Spread, чтобы деструктурировать наш объект data , чтобы все они жили на одном уровне.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }Вот наши данные перед нашей функцией:
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }Вот наши данные после нашей функции:

{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }Теперь у нас есть хорошо отформатированные данные, готовые для нашего шаблона!
Напишем простой шаблон. Мы пройдемся по нашим закладкам и проверим, что у каждой есть pageTitle и url -адрес, чтобы не выглядеть глупо.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>Теперь мы получаем и отображаем данные из FaunaDB. Давайте на минутку задумаемся о том, как хорошо, что это отображает чистый HTML и нет необходимости получать данные на стороне клиента!
Но этого недостаточно, чтобы сделать это приложение полезным для нас. Давайте придумаем лучший способ, чем добавление закладки в консоль FaunaDB.
Введите функции Netlify
Надстройка Netlify «Функции» — это один из самых простых способов развертывания лямбда-функций AWS. Поскольку нет этапа настройки, он идеально подходит для проектов «сделай сам», когда вы просто хотите написать код.
Эта функция будет жить по URL-адресу в вашем проекте, который выглядит следующим образом: https://myproject.com/.netlify/functions/bookmarks при условии, что файл, который мы создаем в нашей папке функций, называется bookmarks.js .
Основной поток
- Передайте URL-адрес в качестве параметра запроса URL-адресу нашей функции.
- Используйте функцию для загрузки URL-адреса и очистки заголовка и описания страницы, если они доступны.
- Отформатируйте детали для FaunaDB.
- Отправьте подробности в нашу коллекцию FaunaDB.
- Восстановите сайт.
Требования
У нас есть несколько пакетов, которые нам понадобятся, когда мы создадим это. Мы будем использовать интерфейс командной строки netlify-lambda для локального создания наших функций. request-promise — это пакет, который мы будем использовать для создания запросов. Cheerio.js — это пакет, который мы будем использовать для извлечения определенных элементов с запрашиваемой страницы (например, jQuery для Node). И, наконец, нам понадобится FaunaDb (который уже должен быть установлен.
npm install --save netlify-lambda request-promise cheerioКак только это будет установлено, давайте настроим наш проект для сборки и обслуживания функций локально.
Мы изменим наши сценарии «сборки» и «обслуживания» в нашем package.json , чтобы они выглядели следующим образом:
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } Предупреждение. Произошла ошибка драйвера NodeJS Fauna при компиляции с помощью Webpack, который функции Netlify используют для сборки. Чтобы обойти это, нам нужно определить файл конфигурации для Webpack. Вы можете сохранить следующий код в новый или существующий webpack.config.js .
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; После того, как этот файл существует, когда мы используем команду netlify-lambda , нам нужно указать ей запуститься из этой конфигурации. Вот почему наши сценарии «обслуживания» и «сборки» используют значение --config для этой команды.
Функция
Чтобы сохранить наш основной файл функций как можно более чистым, мы создадим наши функции в отдельном каталоге bookmarks и импортируем их в наш основной файл функций.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
Функция getDetails() примет URL-адрес, переданный из нашего экспортированного обработчика. Оттуда мы перейдем к сайту по этому URL-адресу и захватим соответствующие части страницы, чтобы сохранить их в качестве данных для нашей закладки.
Начнем с запроса необходимых нам пакетов NPM:
const rp = require('request-promise'); const cheerio = require('cheerio'); Затем мы будем использовать модуль request-promise , чтобы вернуть строку HTML для запрошенной страницы и передать ее в cheerio , чтобы получить интерфейс, очень похожий на jQuery.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }Отсюда нам нужно получить заголовок страницы и метаописание. Для этого мы будем использовать селекторы, как в jQuery.
Примечание. В этом коде мы используем 'head > title' в качестве селектора, чтобы получить заголовок страницы. Если вы не укажете это, вы можете получить теги <title> внутри всех SVG на странице, что далеко не идеально.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }Имея данные на руках, пришло время отправить нашу закладку в нашу коллекцию в FaunaDB!
saveBookmark(details)
Для нашей функции сохранения мы хотим передать детали, полученные из getDetails , а также URL-адрес в виде отдельного объекта. Оператор Spread снова наносит удар!
const savedResponse = await saveBookmark({url, ...details}); В нашем файле create.js нам также нужно потребовать и настроить наш драйвер FaunaDB. Это должно выглядеть очень знакомо из нашего файла данных 11ty.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });Как только мы избавимся от этого, мы можем кодировать.
Во-первых, нам нужно отформатировать наши данные в структуру данных, которую Fauna ожидает для нашего запроса. Фауна ожидает объект со свойством данных, содержащим данные, которые мы хотим сохранить.
const saveBookmark = async function(details) { const data = { data: details }; ... }Затем мы откроем новый запрос для добавления в нашу коллекцию. В этом случае мы воспользуемся нашим помощником по запросам и воспользуемся методом Create. Create() принимает два аргумента. Во-первых, это Коллекция, в которой мы хотим хранить наши данные, а во-вторых, это сами данные.
После сохранения мы возвращаем обработчику либо успех, либо неудачу.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }Давайте взглянем на полный файл Function.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
Внимательный глаз заметит, что в наш обработчик импортирована еще одна функция: rebuildSite() . Эта функция будет использовать функциональность Netlify Deploy Hook для восстановления нашего сайта из новых данных каждый раз, когда мы отправляем новое — успешное — сохранение закладки.
В настройках вашего сайта в Netlify вы можете получить доступ к настройкам сборки и развертывания и создать новый «хук сборки». У хуков есть имя, которое отображается в разделе «Развертывание», и возможность развертывания в неглавной ветке, если вы того пожелаете. В нашем случае мы назовем его «new_link» и развернем нашу основную ветку.
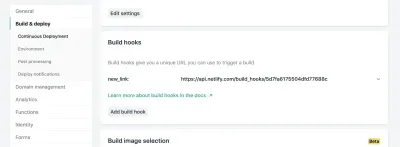
Оттуда нам просто нужно отправить запрос POST на указанный URL-адрес.
Нам нужен способ выполнения запросов, и поскольку мы уже установили request-promise , мы продолжим использовать этот пакет, потребовав его в начале нашего файла.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } Настройка ярлыка iOS
Итак, у нас есть база данных, способ отображения данных и функция добавления данных, но мы все еще не очень удобны для пользователя.
Netlify предоставляет URL-адреса для наших функций Lambda, но их не очень удобно вводить на мобильном устройстве. Мы также должны были бы передать URL в качестве параметра запроса. Это МНОГО усилий. Как мы можем сделать это с минимальными усилиями?
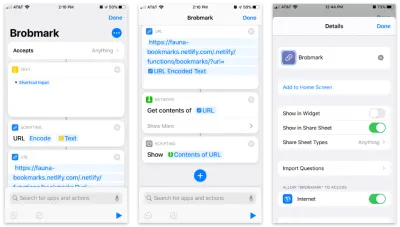
Приложение Apple Shortcuts позволяет создавать пользовательские элементы для добавления в ваш общий лист. Внутри этих ярлыков мы можем отправлять различные типы запросов данных, собранных в процессе обмена.
Вот пошаговый ярлык:
- Примите любые элементы и сохраните этот элемент в «текстовом» блоке.
- Передайте этот текст в блок «Scripting» для кодирования URL (на всякий случай).
- Передайте эту строку в блок URL-адресов с URL-адресом нашей функции Netlify и параметром запроса
url. - Из «Сети» используйте блок «Получить содержимое» для POST в JSON на наш URL.
- Необязательно: из «Сценарии» «Показать» содержимое последнего шага (для подтверждения данных, которые мы отправляем).
Чтобы получить к нему доступ из меню общего доступа, мы открываем настройки для этого ярлыка и включаем параметр «Показать в общем листе».
Начиная с iOS13, эти общие «Действия» можно добавлять в избранное и перемещать на более высокие позиции в диалоговом окне.
Теперь у нас есть работающее «приложение» для обмена закладками на нескольких платформах!
Пройти лишнюю милю!
Если вы хотите попробовать это сами, есть много других возможностей для добавления функциональности. Преимущество Интернета «сделай сам» заключается в том, что вы можете заставить такие приложения работать на вас. Вот несколько идей:
- Используйте искусственный «ключ API» для быстрой аутентификации, чтобы другие пользователи не публиковали сообщения на вашем сайте (мой использует ключ API, поэтому не пытайтесь публиковать сообщения на нем!).
- Добавьте функцию тегов для организации закладок.
- Добавьте RSS-канал для своего сайта, чтобы другие могли подписаться.
- Рассылайте еженедельные сводки по электронной почте программно для ссылок, которые вы добавили.
Действительно, нет предела возможностям, так что начинайте экспериментировать!