
Биномиальное распределение в Python с примерами из реального мира [2022]
Опубликовано: 2021-01-09Значение вероятности и статистики в области науки о данных огромно, поскольку искусственный интеллект и машинное обучение в значительной степени зависят от них. Мы используем модели процессов нормального распределения каждый раз, когда проводим A/B-тестирование и инвестиционное моделирование.
Однако биномиальное распределение в Python применяется несколькими способами для выполнения нескольких процессов. Но прежде чем приступить к работе с биномиальным распределением в Python , вам необходимо узнать о биномиальном распределении в целом и его использовании в повседневной жизни. Если вы новичок и хотите узнать больше о науке о данных, ознакомьтесь с нашим курсом по науке о данных от лучших университетов.
Оглавление
Что такое Биномиальное распределение ?
Вы когда-нибудь подбрасывали монету? Если у вас есть, то вы должны знать о равной вероятности выпадения орла или решки. Но как насчет вероятности выпадения семи решек за десять подбрасываний монеты? Именно здесь биномиальное распределение может помочь в расчете результатов каждого броска и, таким образом, в определении вероятности выпадения семи решек при десяти бросках монеты.
Суть распределения вероятностей исходит из дисперсии любого события. Для каждого набора из десяти подбрасываемых монет вероятность выпадения орла и решки может составлять от одного до десяти раз, равно и вероятно. Неопределенность результата (также известная как дисперсия) помогает генерировать распределение полученных результатов.
Другими словами, биномиальное распределение — это процесс, в котором возможны только два исхода: истина или ложь. Следовательно, он имеет одинаковую вероятность обоих результатов для всех событий, поскольку каждый раз выполняются одни и те же действия. Есть только одно условие... Шаги должны быть полностью независимы друг от друга, а результаты могут быть или не быть равновероятными.
Следовательно, функция вероятности биномиального распределения:
f f( k k , n n, p p) = P r Pr( k k; n n, p p) = P r Pr ( X X = k k) =
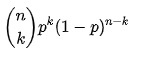
Источник
Где,
![]() = п п! k k !( n n!- k k!)
= п п! k k !( n n!- k k!)
Здесь n = общее количество испытаний
p = вероятность успеха
k = целевое количество успехов
Биномиальное распределение в Python
Для биномиального распределения через Python вы можете создать отдельную случайную переменную из функции binom.rvs(), где «n» определяется как общая частота испытаний, а «p» равна вероятности успеха.
Вы также можете перемещать распределение с помощью функции loc, а размер определяет частоту повторения действия в серии. Добавление random_state может помочь в поддержании воспроизводимости.
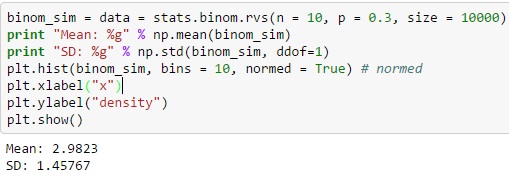
Источник
Реальные примеры биномиального распределения в Python
Есть гораздо больше событий (крупнее, чем подбрасывание монеты), которые могут быть обработаны биномиальным распределением в Python. Некоторые варианты использования могут помочь отслеживать и повышать рентабельность инвестиций (возврат инвестиций) для больших и малых компаний. Вот как:

- Подумайте о колл-центре, где каждый сотрудник получает в среднем 50 звонков в день.
- Вероятность конверсии по каждому звонку равна 4%.
- Средняя выручка компании от каждой такой конверсии составляет 20 долларов США.
- Если вы проанализируете 100 таких сотрудников, которые получают 200 долларов в день, то
п = 50
р = 4%
Код может генерировать вывод следующим образом:
- Средний коэффициент конверсии для каждого сотрудника = 2,13
- Стандартное отклонение конверсий для каждого сотрудника колл-центра = 1,48.
- Валовая конверсия = 213
- Получение валового дохода = 21 300 долларов США.
- Общие расходы = 20 000 долларов США.
- Валовая прибыль = 1300 долларов США
Модели биномиального распределения и другие распределения вероятностей могут только предсказать приближение, которое может быть близко к реальному миру с точки зрения параметров действия, «n» и «p». Это помогает нам понять и определить наши приоритетные области и повысить общие шансы на повышение производительности и эффективности.
Читайте также: 13 интересных идей и тем для проектов по структуре данных для начинающих
Что дальше?
Если вам интересно узнать о науке о данных, ознакомьтесь с программой IIIT-B & upGrad Executive PG по науке о данных , которая создана для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, 1 -на-1 с отраслевыми наставниками, более 400 часов обучения и помощи в трудоустройстве в ведущих фирмах.
В чем разница между дискретным распределением вероятностей и непрерывным распределением вероятностей?
Дискретное распределение вероятностей или просто дискретное распределение вычисляет вероятности случайной величины, которая может быть дискретной. Например, если мы подбросим монету дважды, вероятные значения случайной величины X, обозначающей общее количество выпавших орлов, будут {0, 1, 2}, а не любое случайное значение. Бернулли, биномиальное, гипергеометрическое — вот некоторые примеры дискретного распределения вероятностей. С другой стороны, непрерывное распределение вероятностей обеспечивает вероятность случайного значения, которое может быть любым случайным числом. Например, значение случайной величины X, обозначающей рост жителей города, может быть любым числом, например 161,2, 150,9 и т. д. Нормальный, T Стьюдента, хи-квадрат — вот некоторые из примеров непрерывного распределения.
Каково значение вероятности в науке о данных?
Поскольку наука о данных занимается изучением данных, вероятность играет здесь ключевую роль. Следующие причины описывают, почему вероятность является неотъемлемой частью науки о данных: Она помогает аналитикам и исследователям делать прогнозы на основе наборов данных. Такого рода оценочные результаты являются основой для дальнейшего анализа данных. Вероятность также используется при разработке алгоритмов, используемых в моделях машинного обучения. Это помогает анализировать наборы данных, используемые для обучения моделей. Это позволяет вам количественно оценивать данные и получать такие результаты, как производные, среднее значение и распределение. Все результаты, достигнутые с помощью вероятности, в конечном итоге суммируют данные. Эта сводка также помогает выявить существующие выбросы в наборах данных.
Объясните гипергеометрическое распределение. В каком случае оно имеет тенденцию к биномиальному распределению?
успехов по количеству попыток без какой-либо замены. Допустим, у нас есть сумка, полная красных и зеленых шаров, и мы должны найти вероятность вытащить зеленый шар за 5 попыток, но каждый раз, когда мы выбираем мяч, мы не возвращаем его обратно в мешок. Это удачный пример гипергеометрического распределения.
При больших N вычислить гипергеометрическое распределение очень сложно, но при малых N оно в этом случае стремится к биномиальному распределению.