
Пример байесовской сети [с графическим представлением]
Опубликовано: 2021-01-29Оглавление
Введение
В статистике вероятностные модели используются для определения взаимосвязи между переменными и могут использоваться для расчета вероятностей каждой переменной. Во многих задачах имеется большое количество переменных. В таких случаях полностью условные модели требуют огромного количества данных для охвата каждого случая функций вероятности, которые может быть трудно вычислить в режиме реального времени. Было предпринято несколько попыток упростить расчеты условной вероятности, такие как наивный байесовский метод, но, тем не менее, он оказался неэффективным, поскольку резко сокращает несколько переменных.
Единственный способ — разработать модель, которая сможет сохранить условные зависимости между случайными величинами и условную независимость в других случаях. Это приводит нас к концепции байесовских сетей. Эти байесовские сети помогают нам эффективно визуализировать вероятностную модель для каждой области и изучать взаимосвязь между случайными величинами в виде удобного для пользователя графика.
Изучите курс машинного обучения в лучших университетах мира. Заработайте программы Masters, Executive PGP или Advanced Certificate Programs, чтобы ускорить свою карьеру.
Что такое байесовские сети?
По определению, байесовские сети представляют собой тип вероятностной графической модели, которая использует байесовские выводы для вычислений вероятности. Он представляет набор переменных и их условные вероятности с помощью направленного ациклического графа (DAG). Они в первую очередь подходят для рассмотрения произошедшего события и прогнозирования вероятности того, что какая-либо из нескольких возможных известных причин является способствующим фактором.
Источник
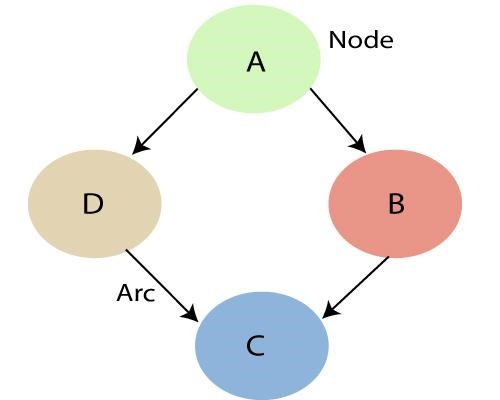
Как упоминалось выше, используя отношения, заданные байесовской сетью, мы можем получить совместное распределение вероятностей (JPF) с условными вероятностями. Каждый узел на графике представляет собой случайную величину, а дуга (или направленная стрелка) представляет отношение между узлами. Они могут носить как непрерывный, так и дискретный характер.

На приведенной выше диаграмме A, B, C и D представлены 4 случайные величины, представленные узлами, заданными в сети графа. Для узла B A является его родительским узлом, а C — его дочерним узлом. Узел C не зависит от узла A.
Прежде чем мы приступим к реализации байесовской сети, необходимо понять несколько основ вероятности.
Локальная марковская собственность
Байесовские сети удовлетворяют свойству, известному как локальное марковское свойство. В нем говорится, что узел условно независим от своих не-потомков, учитывая его родителей. В приведенном выше примере P(D|A, B) равно P(D|A), потому что D не зависит от своего непотомка B. Это свойство помогает нам упростить совместное распределение. Локальное марковское свойство приводит нас к понятию марковского случайного поля, которое представляет собой случайное поле вокруг переменной, которая, как говорят, следует марковским свойствам.
Условная возможность
В математике условная вероятность события А — это вероятность того, что событие А произойдет при условии, что другое событие В уже произошло. Проще говоря, p(A | B) — это вероятность наступления события A при условии, что произошло событие B. Однако между A и B существует два типа событийных возможностей. Они могут быть либо зависимыми событиями, либо независимыми событиями. В зависимости от их типа существует два разных способа расчета условной вероятности.
- Поскольку A и B являются зависимыми событиями, условная вероятность рассчитывается как P (A | B) = P (A и B) / P (B)
- Если A и B являются независимыми событиями, то выражение для условной вероятности дается как P (A | B) = P (A)
Совместное распределение вероятностей
Прежде чем мы перейдем к примеру байесовских сетей, давайте разберемся с концепцией совместного распределения вероятностей. Рассмотрим 3 переменные a1, a2 и a3. По определению, вероятности всех различных возможных комбинаций a1, a2 и a3 называются его Совместным распределением вероятностей.
Если P[a1,a2, a3,….., an] является JPD следующих переменных от a1 до an, то существует несколько способов расчета совместного распределения вероятностей как комбинации различных терминов, таких как,
P[a1,a2,a3,…..,an] = P[a1 | a2, a3,….., an] * P[a2, a3,….., an]
= Р[а1 | a2, a3,….., an] * P[a2 | a3,….., an].….P[an-1|an] * P[an]
Обобщая приведенное выше уравнение, мы можем записать совместное распределение вероятностей как
P(X i |X i-1 ,………, X n ) = P(X i |Родители(X i ))
Пример байесовских сетей
Давайте теперь разберемся с механизмом байесовских сетей и их преимуществами на простом примере. В этом примере давайте представим, что нам дали задание смоделировать оценки студента ( m ) за экзамен, который он только что сдал. Из приведенного ниже графика байесовской сети видно, что оценки зависят от двух других переменных. Они есть,
- Уровень экзамена ( e ) — эта дискретная переменная обозначает сложность экзамена и имеет два значения (0 для легкого и 1 для сложного).
- Уровень IQ ( i ) - представляет уровень коэффициента интеллекта учащегося, а также имеет дискретный характер и имеет два значения (0 для низкого и 1 для высокого).
Кроме того, уровень IQ учащегося также приводит нас к другой переменной, которая представляет собой показатель способностей учащегося ( s ). Теперь, имея оценки, которые студент набрал, он может обеспечить себе поступление в тот или иной вуз. Распределение вероятности поступления ( а ) в университет также приведено ниже.

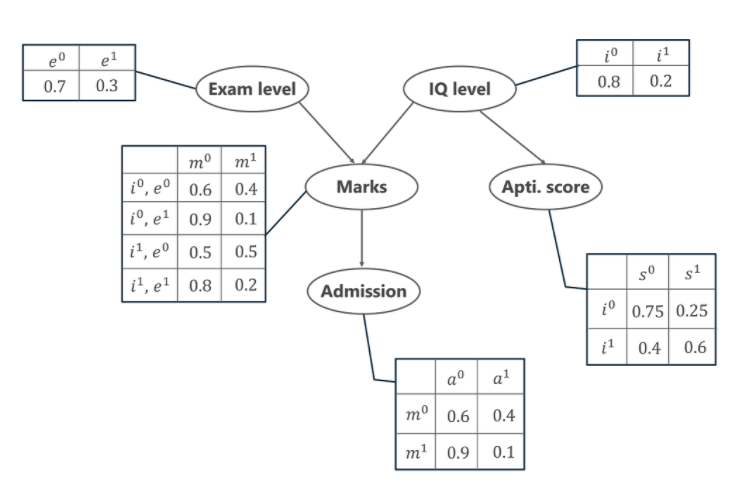
На приведенном выше графике мы видим несколько таблиц, представляющих значения распределения вероятностей для заданных 5 переменных. Эти таблицы называются Таблицами условных вероятностей или CPT. Ниже приведены несколько свойств CPT:
- Сумма значений CPT в каждой строке должна быть равна 1, поскольку все возможные случаи для конкретной переменной являются исчерпывающими (представляющими все возможности).
- Если переменная, которая по своей природе является булевой, имеет k логических родителей, то в CPT она имеет 2K значений вероятности.
Возвращаясь к нашей проблеме, давайте сначала перечислим все возможные события, происходящие в приведенной выше таблице.
- Уровень экзамена (e)
- Уровень интеллекта (я)
- Оценка способностей (с)
- Оценки (м)
- Прием (а)
Эти пять переменных представлены в виде направленного ациклического графа (DAG) в формате байесовской сети с их таблицами условной вероятности. Теперь, чтобы рассчитать совместное распределение вероятностей 5 переменных, формула дается формулой,
P[a, m, i, e, s] = P(a | m) . Р(т | я, е) . Пи) . Р(е) . П (с | я)
Из приведенной выше формулы
- P(a | m) обозначает условную вероятность поступления студента на основании оценок, полученных им на экзамене.
- P(m | i, e) представляет собой оценки, которые студент наберет, учитывая его уровень IQ и сложность уровня экзамена.
- P(i) и P(e) представляют вероятность уровня IQ и уровня экзамена.
- P(s | i) — это условная вероятность оценки способностей учащегося с учетом его уровня IQ.
Рассчитав следующие вероятности, мы можем найти Совместное распределение вероятностей всей байесовской сети.
Расчет совместного распределения вероятностей
Давайте теперь рассчитаем JPD для двух случаев.
Случай 1: Рассчитайте вероятность того, что, несмотря на сложность экзамена, студенту с низким уровнем IQ и низким баллом способностей удастся сдать экзамен и обеспечить поступление в университет.
Исходя из приведенной выше постановки задачи, совместное распределение вероятностей можно записать следующим образом:
Р[а=1, м=1, я=0, е=1, с=0]
Из приведенных выше таблиц условной вероятности значения для заданных условий вводятся в формулу и рассчитываются, как показано ниже.
P[a=1, m=1, i=0, e=0, s=0] = P(a=1 | m=1) . P(m=1 | i=0, e=1) . Р(я=0) . Р(е=1) . Р(с=0 | я=0)
= 0,1 * 0,1 * 0,8 * 0,3 * 0,75
= 0,0018
Случай 2: В другом случае подсчитайте вероятность того, что у студента высокий уровень IQ и оценка способностей, экзамен прост, но не сдан и не обеспечивает поступление в университет.
Формула для JPD дается
Р[а=0, м=0, я=1, е=0, с=1]
Таким образом,
P[a=0, m=0, i=1, e=0, s=1]= P(a=0 | m=0) . P(m=0 | i=1, e=0) . Р(я=1) . Р(е=0) . P(s=1 | я=1)
= 0,6 * 0,5 * 0,2 * 0,7 * 0,6
= 0,0252
Таким образом, мы можем использовать байесовские сети и таблицы вероятностей для расчета вероятности различных возможных событий.
Читайте также: Идеи и темы проекта машинного обучения
Заключение
Существует бесчисленное множество приложений для байесовских сетей в фильтрации спама, семантическом поиске, поиске информации и многом другом. Например, по данному симптому мы можем предсказать вероятность возникновения заболевания при наличии нескольких других факторов, способствующих заболеванию. Таким образом, в этой статье представлена концепция байесовской сети вместе с ее реализацией на реальном примере.
Если вам интересно освоить машинное обучение и искусственный интеллект, повысьте свою карьеру с помощью расширенного курса по машинному обучению и искусственному интеллекту в IIIT-B и Ливерпульском университете Джона Мура.
Как реализуются байесовские сети?
Байесовская сеть — это графическая модель, в которой каждый из узлов представляет случайные величины. Каждый узел соединен с другими узлами направленными дугами. Каждая дуга представляет собой условное распределение вероятностей родителей для детей. Направленные ребра представляют влияние родителя на его потомков. Узлы обычно представляют некоторые объекты реального мира, а дуги представляют некоторые физические или логические отношения между ними. Байесовские сети используются во многих приложениях, таких как автоматическое распознавание речи, классификация документов/изображений, медицинская диагностика и робототехника.
Почему байесовская сеть важна?
Как мы знаем, байесовская сеть является важной частью машинного обучения и статистики. Он используется в интеллектуальном анализе данных и научных открытиях. Байесовская сеть представляет собой ориентированный ациклический граф (DAG), узлы которого представляют собой случайные величины, а дуги представляют прямое влияние. Байесовская сеть используется в различных приложениях, таких как анализ текста, обнаружение мошенничества, обнаружение рака, распознавание изображений и т. д. В этой статье мы обсудим рассуждения в байесовских сетях. Байесовская сеть — важный инструмент для анализа прошлого, прогнозирования будущего и повышения качества принимаемых решений. Байесовская сеть берет свое начало в статистике, но в настоящее время ее используют все профессионалы, включая ученых-исследователей, аналитиков по исследованию операций, промышленных инженеров, специалистов по маркетингу, бизнес-консультантов и даже менеджеров.
Что такое разреженная байесовская сеть?
Разреженная байесовская сеть (SBN) — это особый вид байесовской сети, в которой условное распределение вероятностей представляет собой разреженный граф. Может быть уместно использовать SBN, когда количество переменных велико и/или количество наблюдений невелико. В общем, байесовские сети наиболее полезны, когда вы заинтересованы в объяснении наблюдения или события с учетом ряда факторов.