
Архитектура Apache Kafka: полное руководство для начинающих [2022]
Опубликовано: 2021-12-23Прежде чем мы углубимся в детали архитектуры Apache Kafka, уместно пролить свет на то, почему Kafka вообще попала в заголовки. Начнем с того, что Apache Kafka в основном находит применение в архитектурах потоковой передачи данных в реальном времени для обеспечения аналитики в реальном времени. Надежная, быстрая, масштабируемая и отказоустойчивая система обмена сообщениями публикации и подписки Kafka имеет варианты использования для таких вещей, как отслеживание данных датчиков IoT или отслеживание вызовов службы.
Такие компании, как LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal и многие другие, используют Apache Kafka для обработки потоковых данных в реальном времени. Например, LinkedIn, где возникла Kafka, использует его для отслеживания операционных показателей и данных о деятельности. Точно так же для Netflix Apache Kafka является стандартом де-факто для обмена сообщениями, обработки событий и потоковой обработки.
Изучите онлайн-курсы по разработке программного обеспечения в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Полезность Apache Kafka лучше ценится при понимании архитектуры Apache Kafka и ее базовых компонентов. Итак, давайте рассмотрим детали архитектуры Кафки.
Оглавление
Фундаментальные концепции архитектуры Кафки
Следующие понятия являются основными для понимания архитектуры Apache Kafka:
1. Темы
Темы Kafka определяют каналы, по которым передаются данные. Таким образом, производители публикуют сообщения в темах, а потребители читают сообщения из тем, на которые они подписаны. Количество тем, созданных в кластере Kafka, не ограничено, и каждая тема определяется уникальным именем.

2. Брокеры
Брокеры — это серверы в кластере Kafka, которые работают как контейнеры и содержат несколько тем с отдельными разделами. Уникальный целочисленный идентификатор идентифицирует брокеров в кластере Kafka, и подключение к любому из этих брокеров означает подключение ко всему кластеру.
3. Перегородки
Темы Kafka разделены на множество частей, известных как разделы. Разделы разделены по порядку и позволяют нескольким потребителям параллельно читать данные из определенной темы. Разделы темы распределены по нескольким серверам в кластере Kafka, и каждый сервер управляет данными и запросами для своего множества разделов. Сообщения достигают брокера и ключа, а ключ определяет раздел, в который будет отправлено конкретное сообщение. Следовательно, сообщения с одним и тем же ключом отправляются в один и тот же раздел. В случае, если ключ не указан, решение о разделе принимается в соответствии с подходом циклического перебора.
4. Реплики
В Kafka реплики похожи на резервные копии разделов, чтобы гарантировать отсутствие потери данных в случае запланированного отключения или сбоя. Другими словами, реплики — это копии разделов.
5. Смещение разделов
Поскольку сообщения или записи в Kafka назначаются разделам, каждая запись снабжена смещением, указывающим ее положение в разделе. Таким образом, значение смещения, связанное с записью, облегчает ее идентификацию в разделе. Смещение раздела имеет значение только в пределах этого конкретного раздела, и, поскольку записи добавляются к концам раздела, более старые записи будут иметь более низкие значения смещения.
6. Продюсеры
Производители Kafka публикуют сообщения в одной или нескольких темах и отправляют данные в кластер Kafka. Как только производитель публикует сообщение в теме Kafka, брокер получает сообщение и добавляет его в определенный раздел. Затем производители могут выбрать раздел, в котором они хотят опубликовать свое сообщение.
7. Потребители и группы потребителей
Потребители читают сообщения из кластера Kafka. Когда потребитель готов получить сообщение, данные извлекаются из брокера. Потребители принадлежат к группе потребителей, и каждый потребитель в определенной группе отвечает за чтение подмножества разделов каждой темы, на которую он подписан.
8. Лидер и последователь
В каждом разделе Kafka есть один сервер, играющий роль лидера. Лидер выполняет все задачи чтения и записи для этого конкретного раздела. С другой стороны, работа ведомого состоит в том, чтобы копировать данные ведущего. Когда лидер в определенном разделе выходит из строя, один из узлов-последователей берет на себя роль лидера. У раздела может не быть ни одного или много последователей.
Следующая диаграмма представляет собой упрощенное представление взаимосвязей между компонентами архитектуры Apache Kafka, рассмотренными выше.
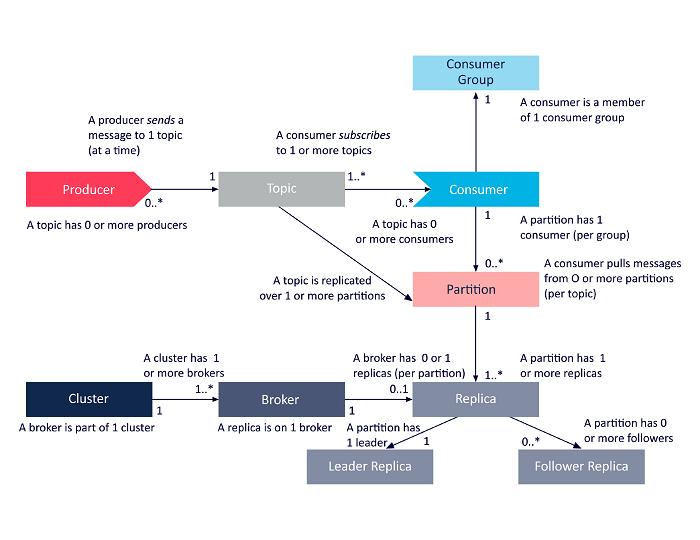
Источник
Архитектура кластера Apache Kafka
Вот подробный обзор основных архитектурных компонентов Kafka:

1. Брокеры Кафки
Кластеры Kafka обычно содержат несколько узлов, известных как брокеры. Брокеры поддерживают баланс нагрузки. Каждый брокер Kafka может обрабатывать сотни и тысячи операций чтения и записи каждую секунду. Брокер выступает в качестве лидера для одного конкретного раздела. У лидера есть один или несколько последователей, при этом данные о лидере реплицируются среди последователей этого конкретного раздела.
Последователи должны быть в курсе данных лидера. Лидер, в свою очередь, отслеживает синхронизированных с ним последователей. Если ведомый не догоняет лидера или уже мертв, он удаляется из списка синхронизированных реплик, связанного с конкретным лидером. Новый лидер избирается из числа последователей после смерти лидера, и ZooKeeper наблюдает за выборами. Поскольку брокеры не имеют состояния, ZooKeeper поддерживает состояние своего кластера. Узлы в кластере отправляют сообщения пульса ZooKeeper, чтобы сообщить последнему, что они активны.
2. Продюсеры Кафки
Производители Kafka напрямую отправляют данные брокерам, которые играют роль лидера для определенного раздела. Брокеры или узлы кластеров Kafka помогают производителям отправлять прямые сообщения. Они делают это, отвечая на запросы метаданных о том, какие серверы работают, и о текущем статусе руководителей разделов темы, что позволяет производителю соответствующим образом направлять свои запросы. Производитель решает, в каком разделе он хочет публиковать сообщения. Сообщения в Kafka отправляются пакетами, называемыми пакетами записей. Производители собирают сообщения в памяти и отправляют их пакетами либо по истечении фиксированного периода времени, либо после накопления определенного количества сообщений.
3. Потребители Кафки
Потребители Kafka отправляют запросы брокерам, обозначая разделы, которые он хочет использовать. Потребитель указывает смещение раздела в своем запросе и получает часть журнала (начиная с позиции смещения) от брокера. Журнал содержит записи за настраиваемый период, известный как период хранения.
Потребители также могут повторно потреблять данные, если журнал содержит данные. Потребители Kafka работают по принципу вытягивания, что означает, что брокеры не сразу передают данные потребителям. Вместо этого сначала потребители отправляют запросы брокерам, сигнализируя о том, что они готовы использовать данные. Следовательно, система на основе вытягивания гарантирует, что потребители не будут перегружены сообщениями и смогут наверстать упущенное, если они отстают.
Ниже приведена упрощенная схема архитектуры Apache Kafka:
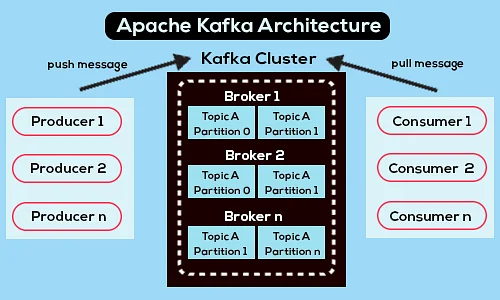
Источник
Узнайте больше об Apache Kafka.
API-архитектура Apache Kafka
Apache Kafka имеет четыре основных API: Streams API, Connector API, Producer API и Consumer API. Давайте посмотрим, какую роль каждый из них должен сыграть в расширении возможностей Apache Kafka:
1. API потоков
Streams API Kafka позволяет приложению обрабатывать данные с использованием алгоритма обработки потоков. С помощью Streams API приложения могут получать входные потоки из одной или нескольких тем, обрабатывать их с помощью операций с потоками, создавать выходные потоки и, в конечном итоге, отправлять их в одну или несколько тем. Таким образом, Streams API упрощает преобразование входных потоков в выходные потоки.
2. API коннектора
API соединителя Kafka полезен для создания, запуска и управления повторно используемыми производителями и потребителями, которые связывают темы Kafka с существующими системами данных или приложениями. Например, коннектор к реляционной базе данных может фиксировать все обновления и обеспечивать доступность изменений в теме Kafka.

3. API производителя
Producer API Kafka позволяет приложениям публиковать поток записей в темах Kafka.
4. Потребительский API
Потребительский API Kafka Позволяет приложениям подписываться на темы Kafka. Это также позволяет приложениям обрабатывать потоки записей, созданные для этих тем Kafka.
Путь вперед
Архитектура Apache Kafka — лишь крошечная часть обширного репертуара инструментов и языков, с которыми имеют дело разработчики программного обеспечения. Предположим, вы начинающий разработчик программного обеспечения со склонностью к большим данным. В этом случае вы можете сделать первый шаг к своим целям с помощью программы upGrad Executive PG в области разработки программного обеспечения — специализация в области больших данных .
Вот обзор программы с некоторыми ключевыми моментами:
- Executive PGP от IIIT Bangalore с сертификатами в области науки о данных и облачной инфраструктуры
- Онлайн-сессии и живые лекции с более чем 400 часами контента
- 7+ кейсов и проектов
- 14+ языков и инструментов программирования
- Карьерная поддержка на 360 градусов
- Партнерские и отраслевые сети
Зарегистрируйтесь, чтобы узнать больше о курсе!
Для чего используется Кафка?
Apache Kafka в основном используется для создания конвейеров потоковой передачи данных в реальном времени и приложений, адаптирующихся к этим потокам данных. Он позволяет хранить и анализировать данные в реальном времени и исторические данные за счет комбинации обмена сообщениями, хранения и потоковой обработки.
Кафка — это фреймворк?
Apache Kafka — это программное обеспечение с открытым исходным кодом, которое предоставляет платформу для хранения, чтения и анализа потоковых данных. Поскольку Kafka имеет открытый исходный код, ее можно использовать бесплатно, и многие разработчики и пользователи вносят свой вклад в новые функции, обновления и поддержку новых пользователей.
Зачем нужны потоки Kafka?
Kafka Streams — это клиентская библиотека для создания микросервисов и потоковых приложений, где входные и выходные данные хранятся в кластере Apache Kafka. С одной стороны, он предлагает преимущества кластерной технологии Apache Kafka на стороне сервера. С другой стороны, это упрощает написание и развертывание стандартных приложений Scala и Java на стороне клиента.