
Apache Kafka: архитектура, концепции, функции и приложения
Опубликовано: 2021-03-09Kafka была запущена в 2011 году благодаря LinkedIn. С тех пор он стал свидетелем невероятного роста до такой степени, что большинство компаний, перечисленных в Fortune 500, теперь используют его. Это масштабируемый, надежный и высокопроизводительный продукт, способный обрабатывать большие объемы потоковых данных. Но разве это единственная причина его невероятной популярности? Ну нет. Мы даже не начали описывать его функции, качество, которое он производит, и простоту, которую он предоставляет пользователям.
Мы углубимся в это позже. Давайте сначала разберемся, что такое Кафка и где она используется.
Оглавление
Что такое Апач Кафка?
Apache Kafka — это программное обеспечение для потоковой обработки с открытым исходным кодом, целью которого является обеспечение высокой пропускной способности и низкой задержки при управлении данными в реальном времени. Написанный на Java и Scala, Kafka обеспечивает устойчивость с помощью микросервисов в памяти и играет неотъемлемую роль в поддержании событий доставки для служб потоковой передачи сложных событий, также известных как CEP или системы автоматизации.
Это исключительно универсальная, отказоустойчивая распределенная система, которая позволяет таким компаниям, как Uber, управлять сопоставлением пассажиров и водителей. Он также предоставляет данные в режиме реального времени и упреждающее обслуживание продуктов для умного дома British Gas, а также помогает LinkedIn отслеживать несколько услуг в режиме реального времени.
Kafka, часто используемая в архитектуре потоковой передачи данных в реальном времени для предоставления аналитики в реальном времени, представляет собой быструю, надежную, масштабируемую систему обмена сообщениями с публикацией и подпиской. Apache Kafka можно использовать вместо традиционной MOM благодаря превосходной совместимости и гибкой архитектуре, которая позволяет отслеживать вызовы службы или данные датчиков IoT.
Kafka прекрасно работает с Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink и Apache Spark для приема, исследования, анализа и обработки потоковых данных в режиме реального времени. Посредники Kafka также облегчают последующие отчеты с малой задержкой в Hadoop или Spark. У Kafka также есть дочерний проект под названием Kafka Stream, который работает как эффективный инструмент для анализа в реальном времени.

Архитектура и компоненты Kafka
Kafka используется для потоковой передачи данных в реальном времени на несколько систем-получателей. Kafka работает как центральный уровень для разделения конвейеров данных в реальном времени. Он не находит большого применения в прямых вычислениях. Он наиболее совместим с системами быстрой подачи, работающими в режиме реального времени или на основе оперативных данных, для потоковой передачи значительного объема данных для анализа пакетных данных.
Фреймворки Storm, Flink, Spark и CEP — это несколько систем данных, с которыми Kafka работает для выполнения аналитики в реальном времени, создания резервных копий, аудита и многого другого. Его также можно интегрировать с платформами больших данных или системами баз данных, такими как RDBMS, Cassandra, Spark и т. д., для анализа данных, создания отчетов и т. д.
На приведенной ниже диаграмме показана экосистема Kafka:
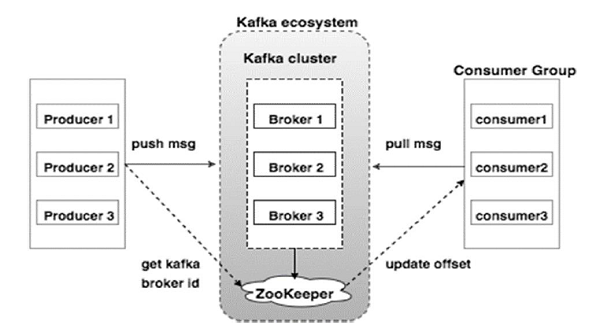
Источник
Вот различные компоненты экосистемы Kafka, как показано на диаграмме архитектуры Kafka:
1. Кафка Брокер
Kafka эмулирует кластер, состоящий из нескольких серверов, каждый из которых известен как «брокер». Любая связь между клиентами и серверами осуществляется по высокопроизводительному протоколу TCP. Он включает в себя более одного брокера без сохранения состояния для обработки большой нагрузки. Один брокер Kafka способен управлять несколькими лаками операций чтения и записи каждую секунду без ущерба для производительности. Они используют ZooKeeper для обслуживания кластеров и выбора лидера брокера.
2. Кафка Зоопарк
Как упоминалось выше, ZooKeeper отвечает за управление брокерами Kafka. Любое новое добавление или сбой брокера в экосистеме Kafka доводится до сведения производителя или потребителя через ZooKeeper.
3. Продюсеры Кафки
Они отвечают за отправку данных брокерам. Производители не полагаются на брокеров, чтобы подтвердить получение сообщения. Вместо этого они определяют, сколько брокер может обрабатывать и соответственно отправлять сообщения.

4. Потребители Кафки
Потребители Kafka обязаны вести учет количества сообщений, потребляемых смещением раздела. Подтверждение сообщения означает, что сообщения, отправленные до того, как они были использованы. Чтобы убедиться, что у брокера есть буфер байтов, готовых для отправки потребителю, потребитель инициирует асинхронный запрос на извлечение. ZooKeeper играет определенную роль в поддержании значения смещения при пропуске или перемотке сообщения.
Механизм Kafka включает отправку сообщений между приложениями в распределенных системах. Kafka использует журнал фиксации, который при подписке публикует данные, представленные в различных потоковых приложениях. Отправитель отправляет сообщения в Kafka, а получатель получает сообщения из потока, распространяемого Kafka.
Сообщения собраны в темы — эффективное обсуждение Кафки. Данная тема представляет собой организованный поток данных, основанный на определенном типе или классификации. Производитель пишет сообщения для чтения потребителями, которые основаны на теме.
Каждой теме дается уникальное имя. Любое сообщение из данной темы, отправленное отправителем, получают все пользователи, которые настраиваются на эту тему. После публикации данные в теме не могут быть обновлены или изменены.
Особенности Кафки.
- Kafka состоит из журнала постоянной фиксации, который позволяет подписаться на него и впоследствии публиковать данные в нескольких системах или приложениях реального времени.
- Это дает приложениям возможность контролировать эти данные по мере их поступления. Streams API в Apache Kafka — это мощная и легкая библиотека, которая упрощает пакетную обработку данных «на лету».
- Это Java-приложение, которое позволяет регулировать рабочий процесс и значительно снижает потребность в обслуживании.
- Kafka функционирует как «хранилище правды», распределяя данные по нескольким узлам, обеспечивая развертывание данных через несколько систем данных.
- Журнал фиксации Kafka делает его надежной системой хранения. Kafka создает реплики/резервные копии раздела, которые помогают предотвратить потерю данных (правильная конфигурация может привести к нулевой потере данных). Это также предотвращает сбои сервера и повышает надежность Kafka.
- Темы в Kafka имеют тысячи разделов, что позволяет обрабатывать произвольное количество данных и выполнять большие нагрузки.
- Kafka зависит от ядра ОС для быстрого перемещения данных. Эти кластеры информации зашифрованы сквозным шифрованием от производителя к файловой системе и конечному потребителю.
- Пакетная обработка в Kafka повышает эффективность сжатия данных и снижает задержку ввода-вывода.
Приложения Кафки
Многие компании, которые ежедневно работают с большими объемами данных, используют Kafka.

- LinkedIn использует Kafka для отслеживания активности пользователей и показателей производительности. Twitter объединяет его со Storm, чтобы включить структуру потоковой обработки.
- Square использует Kafka для облегчения перемещения всех системных событий в другие центры обработки данных Square. Сюда входят журналы, пользовательские события и метрики.
- Другие популярные компании, которые пользуются преимуществами Kafka, включают Netflix, Spotify, Uber, Tumblr, CloudFlare и PayPal.
Почему вы должны изучать Apache Kafka?
Kafka — отличная платформа для потоковой передачи событий , которая может эффективно обрабатывать, отслеживать и отслеживать данные в реальном времени. Его отказоустойчивая и масштабируемая архитектура обеспечивает интеграцию данных с малой задержкой, что приводит к высокой пропускной способности потоковых событий. Kafka значительно сокращает «время окупаемости» данных.
Он работает как базовая система, предоставляющая информацию организациям путем устранения «журналов» вокруг данных. Это позволяет специалистам по данным и специалистам легко получать доступ к информации в любой момент времени.
По этим причинам многие ведущие компании выбирают эту потоковую платформу, и поэтому кандидаты с квалификацией в Apache Kafka пользуются большим спросом.
Если вы хотите узнать больше о Кафке и больших данных, вам следует ознакомиться с дипломом PG UpGrad по специализации разработки программного обеспечения в области больших данных , который предлагает более 7 тематических исследований и проектов, а также наставничество от преподавателей и отраслевых экспертов мирового уровня. 13-месячная программа охватывает 14 языков программирования и обучает обработке данных, MapReduce, хранению данных, обработке в реальном времени, обработке больших данных в облаке и другим навыкам.
Ознакомьтесь с другими нашими курсами по программной инженерии на upGrad.