
Альтернативный голосовой интерфейс для голосовых помощников
Опубликовано: 2022-03-10Для большинства людей первое, что приходит на ум при мысли о голосовых пользовательских интерфейсах, — это голосовые помощники, такие как Siri, Amazon Alexa или Google Assistant. Фактически, помощники — это единственный контекст, в котором большинство людей когда-либо использовали голос для взаимодействия с компьютерной системой.
В то время как голосовые помощники сделали голосовые пользовательские интерфейсы общедоступными, парадигма помощника не является единственным и даже не лучшим способом использования, проектирования и создания голосовых пользовательских интерфейсов.
В этой статье я рассмотрю проблемы, от которых страдают голосовые помощники, и представлю новый подход к голосовым пользовательским интерфейсам, который я называю прямым голосовым взаимодействием.
Голосовые помощники — это голосовые чат-боты
Голосовой помощник — это часть программного обеспечения, которое использует естественный язык вместо значков и меню в качестве пользовательского интерфейса. Помощники обычно отвечают на вопросы и часто активно пытаются помочь пользователю.
Вместо простых транзакций и команд помощники имитируют человеческий разговор и двунаправленно используют естественный язык в качестве модальности взаимодействия, что означает, что он одновременно получает ввод от пользователя и отвечает пользователю, используя естественный язык.
Первыми помощниками стали диалоговые системы вопросов-ответов. Одним из первых примеров является программа Clippy от Microsoft, которая, как известно, пыталась помочь пользователям Microsoft Office, давая им инструкции, основанные на том, что, по ее мнению, пользователь пытался выполнить. В настоящее время типичным вариантом использования парадигмы помощника являются чат-боты, часто используемые для поддержки клиентов в чате.
Голосовые помощники, с другой стороны, — это чат-боты, которые используют голос вместо набора текста и текста . Пользовательский ввод — это не выбор или текст, а речь, и ответ системы также произносится вслух. Эти помощники могут быть общими помощниками, такими как Google Assistant или Alexa, которые могут разумно ответить на множество вопросов, или индивидуальными помощниками, созданными для специальной цели, такой как заказ еды в ресторане быстрого питания.
Хотя часто пользовательский ввод состоит из одного или двух слов и может быть представлен в виде выбора вместо фактического текста, по мере развития технологии диалоги будут более открытыми и сложными . Первой отличительной чертой чат-ботов и помощников является использование естественного языка и стиля разговора вместо значков, меню и стиля транзакций, которые определяют типичное взаимодействие с пользователем мобильного приложения или веб-сайта.
Рекомендуемая литература : Создание простого чат-бота с искусственным интеллектом с помощью Web Speech API и Node.js
Второй определяющей характеристикой, которая вытекает из ответов на естественном языке, является иллюзия личности. Тон, качество и язык, которые использует система, определяют как опыт помощника, иллюзию сопереживания и восприимчивости к обслуживанию, так и его личность. Идея хорошего помощника похожа на взаимодействие с реальным человеком .
Поскольку голос является для нас наиболее естественным способом общения, это может звучать потрясающе, но есть две основные проблемы с использованием ответов на естественном языке. Одна из этих проблем, связанная с тем, насколько хорошо компьютеры могут имитировать людей, может быть решена в будущем с развитием технологий разговорного ИИ , но проблема того, как человеческий мозг обрабатывает информацию, — это человеческая проблема, которую невозможно решить в обозримом будущем. Давайте рассмотрим эти проблемы далее.
Две проблемы с ответами на естественном языке
Голосовые пользовательские интерфейсы — это, конечно, пользовательские интерфейсы, использующие голос в качестве модальности. Но голосовая модальность может использоваться в обоих направлениях: для ввода информации от пользователя и вывода информации из системы обратно пользователю. Например, некоторые лифты используют синтез речи для подтверждения выбора пользователя после того, как пользователь нажмет кнопку. Позже мы обсудим голосовые пользовательские интерфейсы, которые используют голос только для ввода информации и используют традиционные графические пользовательские интерфейсы для отображения информации обратно пользователю.
Голосовые помощники, с другой стороны, используют голос как для ввода, так и для вывода . У этого подхода есть две основные проблемы:
Проблема № 1: Имитация человека терпит неудачу
Как люди, у нас есть врожденная склонность приписывать человеческие черты нечеловеческим объектам. Мы видим черты человека в проплывающем облаке или смотрим на бутерброд, и кажется, что он улыбается нам. Это называется антропоморфизм .

Это явление относится и к помощникам, и оно вызывается их ответами на естественном языке. В то время как графический пользовательский интерфейс может быть построен несколько нейтрально, человек не может не начать думать о том, принадлежит ли чей-то голос молодому или пожилому человеку, мужчине или женщине. Из-за этого пользователь почти начинает думать, что помощник действительно человек.
Однако мы, люди, очень хорошо умеем распознавать подделки . Как ни странно, чем ближе что-то становится похоже на человека, тем больше нас начинают беспокоить мелкие отклонения. Есть чувство жуткости по отношению к чему-то, что пытается быть похожим на человека, но не совсем ему соответствует. В робототехнике и компьютерной анимации это называется «зловещей долиной».

Чем лучше и человечнее мы пытаемся сделать помощника, тем более жутким и разочаровывающим может быть пользовательский опыт, когда что-то пойдет не так. Каждый, кто пробовал помощников, вероятно, сталкивался с проблемой ответа на что-то, что кажется идиотским или даже грубым.
Зловещая долина голосовых помощников создает проблему качества взаимодействия с пользователем, которую трудно решить. На самом деле тест Тьюринга (названный в честь знаменитого математика Алана Тьюринга) считается пройденным, когда оценщик-человек, демонстрирующий разговор между двумя агентами, не может различить, кто из них машина, а кто человек. До сих пор он никогда не был пройден.
Это означает, что парадигма помощника обещает человеческое обслуживание , которое никогда не может быть выполнено, и пользователь обязательно разочаруется. Успешный опыт только усугубляет возможное разочарование, поскольку пользователь начинает доверять своему человекоподобному помощнику.
Проблема 2: последовательные и медленные взаимодействия
Вторая проблема голосовых помощников заключается в том, что пошаговый характер ответов на естественном языке вызывает задержку взаимодействия. Это связано с тем, как наш мозг обрабатывает информацию.
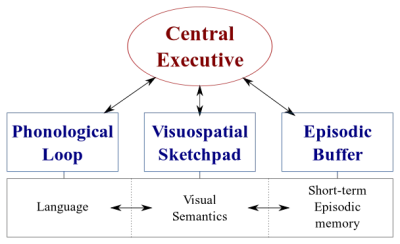
В нашем мозгу есть два типа систем обработки данных:
- Лингвистическая система , обрабатывающая речь;
- Зрительно- пространственная система , специализирующаяся на обработке визуальной и пространственной информации.
Эти две системы могут работать параллельно, но обе системы одновременно обрабатывают только одну вещь . Вот почему вы можете одновременно говорить и водить машину, но не можете писать сообщения и водить машину, потому что оба этих действия происходят в зрительно-пространственной системе.

Точно так же, когда вы разговариваете с голосовым помощником, помощник должен молчать, и наоборот. Это создает пошаговый разговор , в котором другая сторона всегда полностью пассивна.
Однако подумайте о сложной теме, которую вы хотите обсудить с другом. Вероятно, вы бы обсудили это лицом к лицу, а не по телефону, верно? Это потому, что в разговоре лицом к лицу мы используем невербальное общение, чтобы дать визуальную обратную связь в реальном времени нашему собеседнику. Это создает двунаправленную петлю обмена информацией и позволяет обеим сторонам одновременно активно участвовать в разговоре.
Помощники не дают визуальную обратную связь в реальном времени. Они полагаются на технологию конечной точки, которая определяет, когда пользователь перестал говорить, и отвечает только после этого. И когда они отвечают, они не получают никаких данных от пользователя в то же время. Игра полностью однонаправленная и пошаговая.
В двунаправленном разговоре лицом к лицу в реальном времени обе стороны могут немедленно реагировать как на визуальные, так и на языковые сигналы. При этом используются различные системы обработки информации человеческого мозга, и разговор становится более плавным и эффективным.
Голосовые помощники застряли в однонаправленном режиме, потому что они используют естественный язык как в качестве входных, так и выходных каналов. Хотя голос в четыре раза быстрее, чем набор текста для ввода, он значительно медленнее усваивается, чем чтение. Поскольку информацию необходимо обрабатывать последовательно , этот подход хорошо работает только для простых команд, таких как «выключить свет», которые не требуют большого количества выходных данных от помощника.

Ранее я обещал обсудить голосовые пользовательские интерфейсы, которые используют голос только для ввода данных от пользователя. Этот тип голосовых пользовательских интерфейсов выигрывает от лучших сторон голосовых пользовательских интерфейсов — естественности, скорости и простоты использования — но не страдает от плохих сторон — сверхъестественной долины и последовательных взаимодействий.
Рассмотрим эту альтернативу.
Лучшая альтернатива голосовому помощнику
Решение для преодоления этих проблем в голосовых помощниках состоит в том, чтобы отказаться от ответов на естественном языке и заменить их визуальной обратной связью в реальном времени. Переключение обратной связи на визуальную позволит пользователю давать и получать обратную связь одновременно. Это позволит приложению реагировать, не прерывая пользователя и обеспечивая двунаправленный поток информации. Поскольку информационный поток является двунаправленным, его пропускная способность больше.
В настоящее время основными вариантами использования голосовых помощников являются установка будильника, воспроизведение музыки, проверка погоды и задавание простых вопросов. Все это задачи с низкими ставками , которые не слишком расстраивают пользователя в случае неудачи.
Как однажды написал Дэвид Пирс из Wall Street Journal :
«Я не могу себе представить бронирование авиабилетов или управление своим бюджетом с помощью голосового помощника или отслеживание своей диеты, выкрикивая ингредиенты в мой динамик».
— Дэвид Пирс из Wall Street Journal
Это информационно-тяжелые задачи, которые нужно выполнить правильно.
Однако в конечном итоге голосовой пользовательский интерфейс выйдет из строя. Главное — покрыть это как можно быстрее. Много ошибок происходит при наборе текста на клавиатуре или даже в разговоре лицом к лицу. Однако это совсем не расстраивает, так как пользователь может восстановиться, просто щелкнув клавишу Backspace и повторив попытку или запросив разъяснения.
Это быстрое восстановление после ошибок позволяет пользователю быть более эффективным и не заставляет его вступать в странный разговор с помощником.
Прямое голосовое взаимодействие
В большинстве приложений действия выполняются посредством манипулирования графическими элементами на экране, касания или смахивания (на сенсорных экранах), щелчков мышью и/или нажатия кнопок на клавиатуре. Голосовой ввод может быть добавлен в качестве дополнительной опции или способа управления этими графическими элементами. Этот тип взаимодействия можно назвать прямым голосовым взаимодействием .
Разница между прямым голосовым взаимодействием и помощниками заключается в том, что вместо того, чтобы просить аватара, помощника, выполнить задачу, пользователь напрямую манипулирует графическим пользовательским интерфейсом с помощью голоса.
«Разве это не семантика?», — спросите вы. Если вы собираетесь разговаривать с компьютером, имеет ли значение, говорите ли вы напрямую с компьютером или через виртуальную персону? В обоих случаях вы просто разговариваете с компьютером!
Да, разница тонкая, но критическая. При нажатии кнопки или пункта меню в GUI ( графическом пользовательском интерфейсе) совершенно очевидно, что мы работаем с машиной. Иллюзии человека нет. Заменив этот щелчок голосовой командой, мы улучшаем взаимодействие человека с компьютером. С другой стороны, с парадигмой помощника мы создаем ухудшенную версию взаимодействия человека с человеком и, следовательно, путешествуем в зловещую долину.
Объединение голосовых функций с графическим пользовательским интерфейсом также дает возможность использовать возможности различных модальностей. Хотя пользователь может использовать голос для управления приложением, он также может использовать традиционный графический интерфейс. Это позволяет пользователю легко переключаться между прикосновением и голосом и выбирать наилучший вариант в зависимости от контекста и задачи.
Например, голос — очень эффективный способ ввода богатой информации. Выбор между несколькими допустимыми альтернативами, касание или щелчок, вероятно, лучше. Затем пользователь может вместо набора текста и просмотра сказать что-то вроде: «Покажи мне рейсы из Лондона в Нью-Йорк с вылетом завтра» и выбрать лучший вариант из списка с помощью касания.
Теперь вы можете спросить: «Хорошо, это выглядит великолепно, так почему же мы раньше не видели примеров таких голосовых пользовательских интерфейсов? Почему крупные технологические компании не создают инструменты для чего-то подобного?» Ну, наверное, тому много причин. Одна из причин заключается в том, что текущая парадигма голосового помощника, вероятно, является для них лучшим способом использовать данные, которые они получают от конечных пользователей. Другая причина связана с тем, как построена их голосовая технология.
Хорошо работающий голосовой пользовательский интерфейс требует двух отдельных частей:
- Распознавание речи , превращающее речь в текст;
- Компоненты понимания естественного языка , которые извлекают смысл из этого текста.
Вторая часть — это волшебство, превращающее высказывания «Выключите свет в гостиной» и «Пожалуйста, выключите свет в гостиной» в одно и то же действие.
Рекомендуемая литература : Как создать собственное действие для Google Home с помощью API.AI
Если вы когда-либо использовали помощника с дисплеем (например, Siri или Google Assistant), вы, вероятно, заметили, что вы получаете стенограмму почти в реальном времени, но после того, как вы перестали говорить, проходит несколько секунд, прежде чем система фактически выполняет запрошенное вами действие. Это связано с тем, что распознавание речи и понимание естественного языка происходят последовательно.
Давайте посмотрим, как это можно изменить.
Понимание разговорной речи в реальном времени: секретный соус к более эффективным голосовым командам
То, насколько быстро приложение реагирует на ввод данных пользователем, является основным фактором общего пользовательского опыта приложения. Самым важным нововведением оригинального iPhone был чрезвычайно отзывчивый и реактивный сенсорный экран. Не менее важна способность голосового пользовательского интерфейса мгновенно реагировать на голосовой ввод .
Чтобы установить быстрый двунаправленный цикл обмена информацией между пользователем и пользовательским интерфейсом, графический интерфейс с поддержкой голоса должен иметь возможность мгновенно реагировать — даже на середине предложения — всякий раз, когда пользователь говорит что-то действенное. Для этого требуется метод, называемый потоковым пониманием разговорной речи .
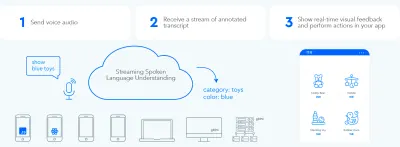
В отличие от традиционных пошаговых систем голосового помощника, которые ждут, пока пользователь перестанет говорить, прежде чем обработать запрос пользователя, системы, использующие потоковое понимание разговорной речи, активно пытаются понять намерение пользователя с того момента, как пользователь начинает говорить. Как только пользователь говорит что-то действенное, пользовательский интерфейс моментально на это реагирует.
Мгновенный ответ немедленно подтверждает, что система понимает пользователя, и побуждает его продолжать работу. Это аналог кивка или короткого «ага» в общении между людьми. Это приводит к более длинным и сложным высказываниям. Соответственно, если система не понимает пользователя или пользователь говорит неправильно, мгновенная обратная связь обеспечивает быстрое восстановление . Пользователь может сразу же исправить и продолжить или даже устно исправить себя: «Я хочу это, нет, я имел в виду, я хочу это». Вы можете сами попробовать это приложение в нашей демо-версии голосового поиска.
Как вы можете видеть в демонстрации, визуальная обратная связь в реальном времени позволяет пользователю естественным образом исправлять свои ошибки и побуждает его продолжать использовать голосовой опыт. Поскольку их не смущает виртуальная персона, они могут относиться к возможным ошибкам так же, как к опечаткам, а не как к личным оскорблениям. Опыт быстрее и естественнее , потому что информация, подаваемая пользователю, не ограничивается типичной скоростью речи около 150 слов в минуту.
Рекомендуемая литература : «Разработка голосового опыта» Линдона Серехо.
Выводы
Хотя голосовые помощники до сих пор были наиболее распространенным использованием голосовых пользовательских интерфейсов, использование ответов на естественном языке делает их неэффективными и неестественными. Голос — отличный способ ввода информации, но прослушивание речи машины не очень вдохновляет. Это большая проблема голосовых помощников.
Поэтому будущее голоса должно заключаться не в разговорах с компьютером, а в замене утомительных пользовательских задач наиболее естественным способом общения: речью . Прямые голосовые взаимодействия можно использовать для улучшения процесса заполнения форм в веб-приложениях или мобильных приложениях, для улучшения поиска и обеспечения более эффективного способа управления или навигации в приложении.
Дизайнеры и разработчики приложений постоянно ищут способы уменьшить трения в своих приложениях или веб-сайтах. Усовершенствование текущего графического пользовательского интерфейса с помощью голосовой модальности позволит в несколько раз ускорить взаимодействие с пользователем, особенно в определенных ситуациях, например, когда конечный пользователь находится на мобильном устройстве и в пути, а набор текста затруднен. На самом деле, голосовой поиск может быть в пять раз быстрее, чем традиционный пользовательский интерфейс фильтрации поиска, даже при использовании настольного компьютера.
В следующий раз, когда вы будете думать о том, как сделать определенную пользовательскую задачу в своем приложении более простой в использовании, более приятной в использовании или вы заинтересованы в увеличении числа конверсий, подумайте, можно ли точно описать эту пользовательскую задачу естественным языком. Если да, дополните пользовательский интерфейс голосовой модальностью, но не заставляйте пользователей разговаривать с компьютером.
Ресурсы
- «Voice First против мультимодальных пользовательских интерфейсов будущего», Джоан Палмитер Байорек, UXmatters.
- «Рекомендации по созданию продуктивных приложений с поддержкой голоса», Ханнес Хейкинхеймо, Speechly
- «6 причин, по которым ваши приложения с сенсорным экраном должны иметь голосовые возможности», Оттоматиас Пеура, UXmatters
- Смешивание материального и нематериального: проектирование мультимодальных интерфейсов с помощью Adobe XD, Ник Бабич, Smashing Magazine
( Adobe XD может быть для прототипирования чего-то подобного ) - «Эффективность со скоростью звука: обещание голосовых операций», Эрик Теркингтон, RAIN
- Демонстрация, демонстрирующая визуальную обратную связь в реальном времени при фильтрации голосового поиска электронной коммерции (видеоверсия)
- Speechly предоставляет инструменты разработчика для такого рода пользовательских интерфейсов.
- Альтернатива с открытым исходным кодом: voice2json