
Руководство по линейной регрессии с использованием Scikit [с примерами]
Опубликовано: 2021-06-18Алгоритмы контролируемого обучения обычно бывают двух типов: регрессия и классификация с прогнозированием непрерывных и дискретных выходных данных.
В следующей статье будет обсуждаться линейная регрессия и ее реализация с использованием одной из самых популярных библиотек машинного обучения Python, библиотеки Scikit-learn. В библиотеке Python доступны инструменты для машинного обучения и статистических моделей для классификации, регрессии, кластеризации и уменьшения размерности. Написанная на языке программирования Python, библиотека построена на библиотеках Python NumPy, SciPy и Matplotlib.
Оглавление
Линейная регрессия
Линейная регрессия выполняет задачу регрессии в рамках метода обучения с учителем. На основе независимых переменных прогнозируется целевое значение. Метод в основном используется для прогнозирования и выявления взаимосвязи между переменными.
В алгебре термин линейность означает линейную связь между переменными. Выводится прямая линия между переменными в двумерном пространстве.
Если линия представляет собой график между независимыми переменными на оси X и зависимыми переменными на оси Y, прямая линия получается с помощью линейной регрессии, которая лучше всего соответствует точкам данных.
Уравнение прямой имеет вид

Y = мх + б
Где b = перехват
m = наклон линии
Следовательно, с помощью линейной регрессии
- Наиболее оптимальные значения точки пересечения и наклона определяются в двух измерениях.
- Переменные x и y не меняются, поскольку они являются функциями данных и, следовательно, остаются неизменными.
- Можно управлять только значениями точки пересечения и наклона.
- Может существовать несколько прямых линий, основанных на значениях наклона и точки пересечения, однако с помощью алгоритма линейной регрессии несколько линий подгоняются к точкам данных, и возвращается линия с наименьшей ошибкой.
Линейная регрессия с Python
Для реализации линейной регрессии в python необходимо применять соответствующие пакеты вместе с его функциями и классами. Пакет NumPy в Python имеет открытый исходный код и позволяет выполнять несколько операций над массивами, как одиночными, так и многомерными массивами.
Еще одна широко используемая библиотека в Python — Scikit-learn, которая используется для решения задач машинного обучения.
Scikit-learn
Библиотека Scikit-learn предлагает разработчикам алгоритмы, основанные как на контролируемом, так и на неконтролируемом обучении. Библиотека Python с открытым исходным кодом предназначена для задач машинного обучения.
Исследователи данных могут импортировать данные, предварительно обрабатывать их, строить графики и прогнозировать данные с помощью scikit-learn.
Дэвид Курнапо впервые разработал scikit-learn в 2007 году, и за последние десятилетия библиотека росла.
Инструменты, предоставляемые scikit-learn:
- Регрессия: включает логистическую регрессию и линейную регрессию.
- Классификация: включает метод K-ближайших соседей.
- Выбор модели
- Кластеризация: включает как K-Means++, так и K-Means
- Предварительная обработка
Преимущества библиотеки:
- Изучение и реализация библиотеки просты.
- Это библиотека с открытым исходным кодом и, следовательно, бесплатная.
- Аспекты машинного обучения могут быть скрыты, включая глубокое обучение.
- Это мощный и универсальный пакет.
- Библиотека имеет подробную документацию.
- Один из наиболее часто используемых наборов инструментов для машинного обучения.
Импорт scikit-learn
Сначала необходимо установить scikit-learn через pip или conda.
- Требования: 64-битная версия python 3 с установленными библиотеками NumPy и Scipy. Также для визуализации графиков данных требуется matplotlib.
Команда установки: pip install -U scikit-learn
Затем проверьте, завершена ли установка
Установка Numpy, Scipy и matplotlib
Установка может быть подтверждена через:
Источник
Линейная регрессия через Scikit-learn
Реализация линейной регрессии с помощью пакета scikit-learn включает следующие шаги.
- Необходимые пакеты и классы должны быть импортированы.
- Данные необходимы для работы, а также для выполнения соответствующих преобразований.
- Модель регрессии должна быть создана и приспособлена к существующим данным.
- Данные подбора модели должны быть проверены, чтобы проанализировать, является ли созданная модель удовлетворительной.
- Прогнозы должны быть сделаны посредством применения модели.
Пакет NumPy и класс LinearRegression должны быть импортированы из sklearn.linear_model.

Источник
Все функции, необходимые для линейной регрессии sklearn , присутствуют для окончательной реализации линейной регрессии. Класс sklearn.linear_model.LinearRegression используется для выполнения регрессионного анализа (как линейного, так и полиномиального) и прогнозирования.
Для любых алгоритмов машинного обучения и линейной регрессии scikit , необходимо сначала импортировать набор данных. В Scikit-learn доступны три варианта получения данных:
- Наборы данных, такие как классификация радужной оболочки или набор регрессии для цен на жилье в Бостоне.
- Наборы данных реального мира можно загрузить из Интернета напрямую с помощью предопределенных функций Scikit-learn.
- Набор данных может быть сгенерирован случайным образом для сопоставления с определенным шаблоном с помощью генератора данных Scikit-learn.
Какой бы вариант ни был выбран, необходимо импортировать наборы данных модуля.

импортировать sklearn.datasets как наборы данных
1. Классификационный набор ирисов
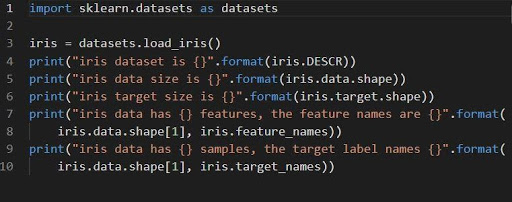
радужная оболочка = наборы данных.load_iris()
Набор данных iris хранится в виде поля данных двумерного массива n_samples * n_features. Его импорт осуществляется как объект словаря. Он содержит все необходимые данные вместе с метаданными.
Функции DESCR, shape и _names можно использовать для получения описаний и форматирования данных. Печать результатов функции отобразит информацию о наборе данных, которая может понадобиться при работе с набором данных радужной оболочки.
Следующий код загрузит информацию о наборе данных радужной оболочки.
Источник
2. Генерация регрессионных данных
Если встроенные данные не требуются, то данные могут быть сгенерированы посредством распределения, которое можно выбрать.
Генерация данных регрессии с набором из 1 информативного признака и 1 признака.
X, Y = наборы данных.make_regression(n_features=1, n_informative=1)
Сгенерированные данные сохраняются в наборе 2D-данных с объектами x и y. Характеристики генерируемых данных можно изменить, изменив параметры функции make_regression.
В этом примере параметры информативных функций и признаков изменены со значения по умолчанию 10 на 1.
Другими рассматриваемыми параметрами являются выборки и цели , в которых контролируется количество отслеживаемых переменных цели и выборки.
- Функции, которые предоставляют полезную информацию для алгоритмов ML, называются информативными функциями, а те, которые бесполезны, называются информативными функциями.
3. Графические данные
Данные отображаются с использованием библиотеки matplotlib. Во-первых, необходимо импортировать matplotlib.
Импортировать matplotlib.pyplot как plt
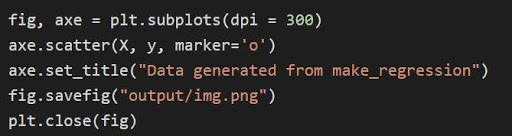
Приведенный выше график построен через matplotlib через код
Источник
В приведенном выше коде:
- Переменные кортежа распаковываются и сохраняются как отдельные переменные в строке 1 кода. Таким образом, отдельные атрибуты можно манипулировать и сохранять.
- Набор данных x, y используется для создания диаграммы рассеивания по линии 2. При наличии параметра маркера в matplotlib визуальные эффекты улучшаются путем пометки точек данных точкой (o).
- Заголовок сгенерированного сюжета задается через строку 3.
- Фигуру можно сохранить как файл изображения .png, после чего текущая фигура будет закрыта.
График регрессии, созданный с помощью приведенного выше кода,
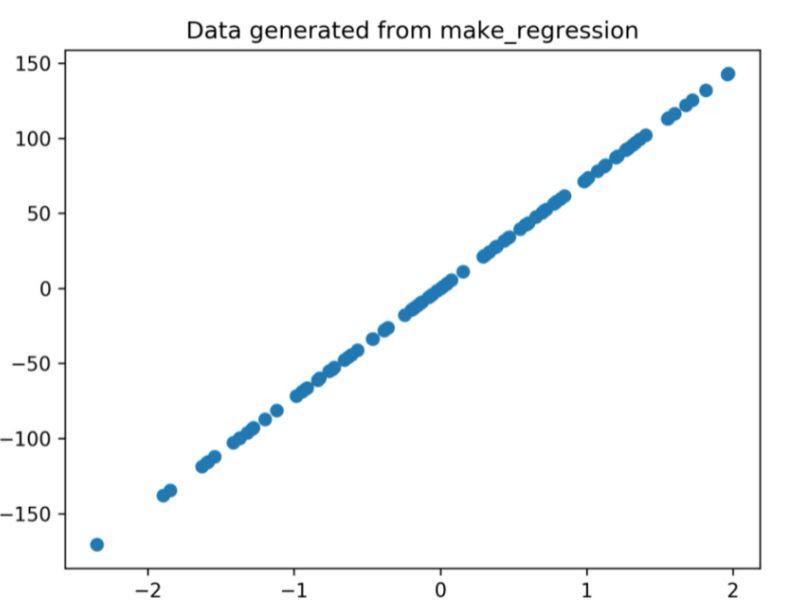
Рисунок 1: График регрессии, сгенерированный из приведенного выше кода.
4. Реализация алгоритма линейной регрессии
Используя выборочные данные о ценах на жилье в Бостоне, алгоритм линейной регрессии Scikit-learn реализуется в следующем примере. Как и в других алгоритмах машинного обучения, набор данных импортируется, а затем обучается с использованием предыдущих данных.
Линейный метод регрессии используется предприятиями, поскольку это прогностическая модель, предсказывающая связь между числовой величиной и ее переменными с выходным значением, имеющая значение в реальности.
Когда имеется журнал более ранних данных, модель лучше всего применять, поскольку она может предсказать будущие результаты того, что произойдет в будущем, если будет продолжение модели.
Математически данные могут быть приспособлены для минимизации суммы всех остатков, существующих между точками данных и прогнозируемым значением.
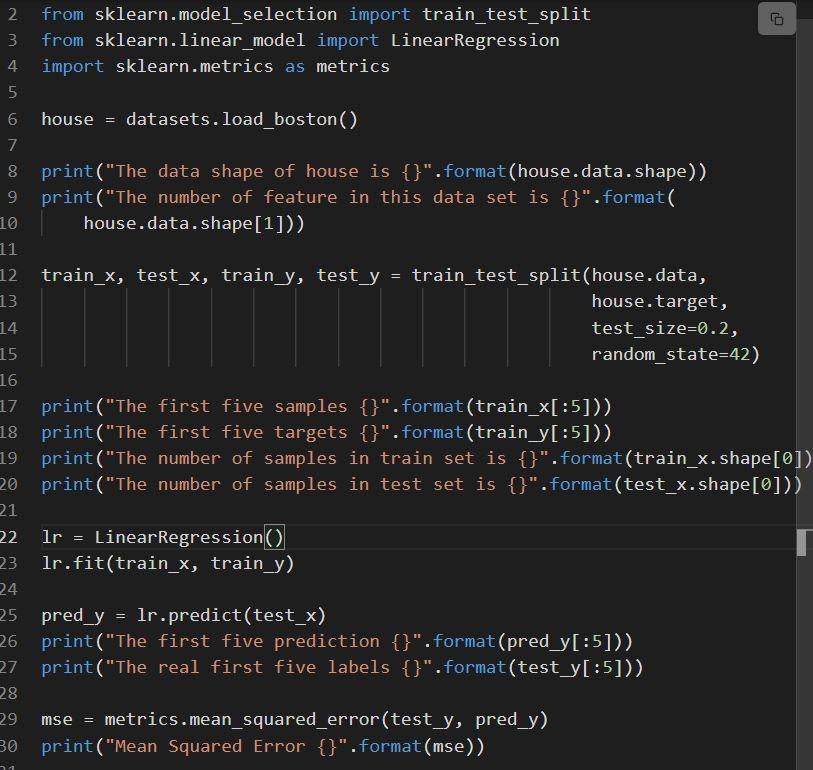
В следующем фрагменте показана реализация линейной регрессии sklearn.
Источник
Код объясняется как:
- Строка 6 загружает набор данных с именем load_boston.
- Набор данных разделен на строку 12, т. е. обучающий набор с 80% данных и тестовый набор с 20% данных.
- Создание модели линейной регрессии в строке 23 с последующим обучением.
- Производительность модели оценивается на уровне 29 посредством вызова mean_squared_error.
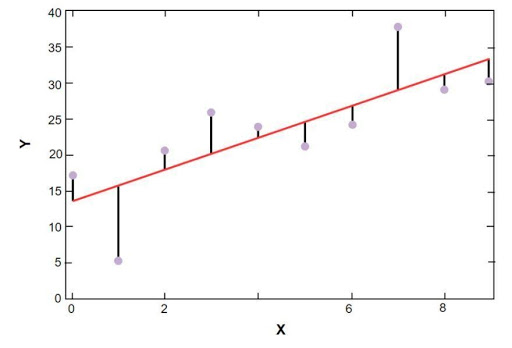
График линейной регрессии sklearn показан ниже:
Модель линейной регрессии выборочных данных о ценах на жилье в Бостоне
Источник
На приведенном выше рисунке красная линия представляет собой линейную модель, которая была решена для выборочных данных о ценах на жилье в Бостоне. Синие точки представляют исходные данные, а расстояние между красной линией и синими точками представляет собой сумму невязки. Цель модели линейной регрессии scikit-learn — уменьшить сумму остатков.
Заключение
В статье обсуждалась линейная регрессия и ее реализация с помощью пакета Python с открытым исходным кодом под названием scikit-learn. К настоящему моменту вы можете получить представление о том, как реализовать линейную регрессию с помощью этого пакета. Стоит научиться использовать библиотеку для анализа данных.
Если у вас есть интерес к дальнейшему изучению темы, например, реализации пакетов Python в машинном обучении и проблемах, связанных с ИИ, вы можете проверить курс «Магистр наук в области машинного обучения и ИИ », предлагаемый upGrad . Ориентированный на профессионалов начального уровня в возрасте от 21 до 45 лет, курс направлен на обучение студентов машинному обучению с помощью более 650 часов онлайн-обучения, более 25 тематических исследований и заданий. Курс, сертифицированный LJMU , предлагает идеальное руководство и помощь в трудоустройстве. Если у вас есть какие-либо вопросы или пожелания, оставьте нам сообщение, мы будем рады связаться с вами.