
Ce este Machine Learning cu Java? Cum să-l implementăm?
Publicat: 2021-03-10Cuprins
Ce este Machine Learning?
Învățarea automată este o divizie a inteligenței artificiale care învață din datele, exemplele și experiențele disponibile pentru a imita comportamentul și inteligența umană. Un program creat folosind învățarea automată poate construi logica de la sine, fără ca un om să fie nevoie să scrie manual codul.
Totul a început cu Testul Turing, la începutul anilor 1950, când Alan Turning a concluzionat că pentru ca un computer să aibă inteligență reală, ar trebui să manipuleze sau să convingă un om că este și el om. Învățarea automată este un concept relativ vechi, dar abia astăzi acest domeniu emergent este supus realizării, deoarece computerele pot procesa algoritmi complexi. Algoritmii de învățare automată au evoluat în ultimul deceniu pentru a include abilități de calcul complexe care, la rândul lor, au condus la o îmbunătățire a capacităților lor de imitare.
Aplicațiile de învățare automată au crescut, de asemenea, într-un ritm alarmant. De la asistență medicală, finanțe, analiză și educație, până la producție, marketing și operațiuni guvernamentale, fiecare industrie a înregistrat o creștere semnificativă a calității și eficienței după implementarea tehnologiilor de învățare automată. Au existat îmbunătățiri calitative pe scară largă în întreaga lume, ceea ce a condus la cererea de profesioniști în învățarea automată.
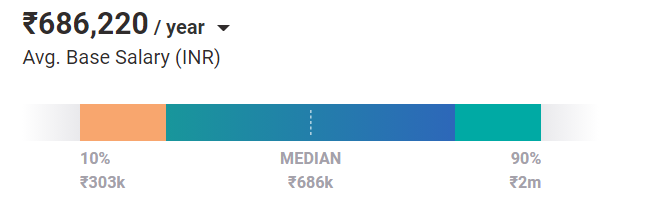
În medie, inginerii de învățare automată merită astăzi un salariu de 686.220 INR/an. Și acesta este cazul unei poziții entry-level. Cu experiență și abilități, aceștia pot câștiga până la 2 milioane INR/an în India.
Tipuri de algoritmi de învățare automată
Algoritmii de învățare automată sunt de trei tipuri:
1. Învățare supravegheată : în acest tip de învățare, seturile de date de antrenament ghidează un algoritm pentru a face predicții sau decizii analitice precise. Utilizează învățarea din seturile de date de antrenament anterioare pentru a procesa date noi. Iată câteva exemple de modele de învățare automată de învățare supravegheată:

- Regresie liniara
- Regresie logistică
- Arborele de decizie
2. Învățare nesupravegheată : în acest tip de învățare, un model de învățare automată învață din informații neetichetate. Utilizează gruparea datelor prin gruparea obiectelor sau înțelegerea relației dintre ele sau exploatarea proprietăților lor statistice pentru a efectua analize. Exemple de algoritmi de învățare nesupravegheată sunt:
- K înseamnă grupare
- Gruparea ierarhică
3. Învățare prin consolidare : Acest proces se bazează pe lovire și încercare. Învață prin interacțiunea cu spațiul sau cu un mediu. Un algoritm RL învață din experiențele sale anterioare interacționând cu mediul și determinând cel mai bun curs de acțiune.
Cum se implementează Machine Learning cu Java?
Java este printre cele mai importante limbaje de programare utilizate pentru implementarea algoritmilor de învățare automată. Majoritatea bibliotecilor sale sunt open-source, oferind suport extins pentru documentare, întreținere ușoară, comercializare și lizibilitate ușoară.
În funcție de popularitate, iată primele 10 biblioteci de învățare automată utilizate pentru implementarea învățării automate în Java.
1. ADAMS
Advanced-Data Mining And Machine Learning System sau ADAMS este preocupat de construirea unui sistem de flux de lucru nou și flexibil și de a gestiona procese complexe din lumea reală. ADAMS folosește o arhitectură de tip arbore pentru a gestiona fluxul de date în loc să facă conexiuni manuale de intrare-ieșire.
Elimină orice nevoie de conexiuni explicite. Se bazează pe principiul „mai puțin este mai mult” și efectuează regăsire, vizualizare și vizualizări bazate pe date. ADAMS este expert în procesarea datelor, în fluxul de date, gestionarea bazelor de date, scripting și documentare.
2. JavaML
JavaML oferă o varietate de algoritmi ML și data mining care sunt scrise pentru Java pentru a sprijini inginerii de software, programatori, oamenii de știință de date și cercetătorii. Fiecare algoritm are o interfață comună care este ușor de utilizat și are suport extins pentru documentație, chiar dacă nu există GUI.
Este destul de simplu și simplu de implementat în comparație cu alți algoritmi de clustering. Caracteristicile sale de bază includ manipularea datelor, documentarea, gestionarea bazelor de date, clasificarea datelor, gruparea, selectarea caracteristicilor și așa mai departe.
Alăturați-vă Cursului de învățare automată online de la cele mai bune universități din lume – Master, Programe Executive Postuniversitare și Program de Certificat Avansat în ML și AI pentru a vă accelera cariera.
3. WEKA
Weka este, de asemenea, o bibliotecă open-source de învățare automată, scrisă pentru Java, care acceptă învățarea profundă. Acesta oferă un set de algoritmi de învățare automată și găsește o utilizare extinsă în extragerea datelor, pregătirea datelor, gruparea datelor, vizualizarea datelor și regresia, printre alte operațiuni de date.
Exemplu: vom demonstra acest lucru folosind un set mic de date despre diabet.
Pasul 1 : Încărcați datele folosind Weka
| import weka.core.Instances; import weka.core.converters.ConverterUtils.DataSource; clasă publică principal { public static void main(String[] args) aruncă excepție { // Specificarea sursei de date DataSource dataSource = new DataSource(“data.arff”); // Se încarcă setul de date Instanțe dataInstances = dataSource.getDataSet(); // Afișarea numărului de instanțe log.info(„Numărul de instanțe încărcate este: ” + dataInstances.numInstances()); log.info(„date:” + dataInstances.toString()); } } |
Pasul 2: setul de date are 768 de instanțe. Trebuie să accesăm numărul de atribute, adică 9.
| log.info(„Numărul de atribute (funcții) din setul de date: ” + dataInstances.numAttributes()); |
Pasul 3 : Trebuie să determinăm coloana țintă înainte de a construi un model și de a găsi numărul de clase.
| // Identificarea indexului etichetei dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Obținerea numărului de log.info(„Numărul de clase: ” + dataInstances.numClasses()); |
Pasul 4 : Acum vom construi modelul folosind un clasificator de arbore simplu, J48.
| // Crearea unui clasificator de arbore de decizie J48 treeClassifier = nou J48(); treeClassifier.setOptions(new String[] { “-U” }); treeClassifier.buildClassifier(dataInstances); |
Codul de mai sus evidențiază cum să creați un arbore netăiat care constă din instanțe de date necesare pentru antrenamentul modelului. Odată ce structura arborelui este tipărită după antrenamentul modelului, putem determina modul în care regulile au fost construite intern.
| plas <= 127 | masa <= 26,4 | | preg <= 7: testat_negativ (117,0/1,0) | | preg > 7 | | | masa <= 0: testat_pozitiv (2,0) | | | masa > 0: testat_negativ (13,0) | masa > 26,4 | | vârsta <= 28: testat_negativ (180,0/22,0) | | vârsta > 28 | | | plas <= 99: testat_negativ (55,0/10,0) | | | plas > 99 | | | | pedi <= 0,56: testat_negativ (84,0/34,0) | | | | pedi > 0,56 | | | | | preg <= 6 | | | | | | vârsta <= 30: testat_pozitiv (4,0) | | | | | | vârsta > 30 | | | | | | | vârsta <= 34: testat_negativ (7,0/1,0) | | | | | | | vârsta > 34 | | | | | | | | masa <= 33,1: testat_pozitiv (6,0) | | | | | | | | masa > 33,1: testat_negativ (4,0/1,0) | | | | | preg > 6: testat_pozitiv (13,0) plas > 127 | masa <= 29,9 | | plas <= 145: testat_negativ (41,0/6,0) | | plas > 145 | | | vârsta <= 25: testat_negativ (4,0) | | | vârsta > 25 | | | | vârsta <= 61 | | | | | masa <= 27,1: testat_pozitiv (12,0/1,0) | | | | | masa > 27,1 | | | | | | pres <= 82 | | | | | | | pedi <= 0,396: testat_pozitiv (8,0/1,0) | | | | | | | pedi > 0,396: testat_negativ (3,0)  | | | | | | pres > 82: testat_negativ (4.0) | | | | vârsta > 61: testat_negativ (4,0) | masa > 29,9 | | plas <= 157 | | | pres <= 61: testat_pozitiv (15,0/1,0) | | | pres > 61 | | | | vârsta <= 30: testat_negativ (40,0/13,0) | | | | vârsta > 30: testat_pozitiv (60,0/17,0) | | plas > 157: testat_pozitiv (92.0/12.0) Număr de frunze: 22 Dimensiunea copacului: 43 |
4. Apache Mahaut
Mahaut este o colecție de algoritmi care ajută la implementarea învățării automate folosind Java. Este un cadru de algebră liniară scalabil, cu ajutorul căruia dezvoltatorii pot efectua activități de matematică și statisticieni. De obicei, este folosit de oamenii de știință de date, inginerii de cercetare și profesioniștii în analiză pentru a construi aplicații pregătite pentru întreprindere. Scalabilitatea și flexibilitatea sa le permit utilizatorilor să implementeze clustering de date, sisteme de recomandare și să creeze aplicații performante de învățare automată rapid și ușor.
5. Deeplearning4j
Deeplearning4j este o bibliotecă de programare care este scrisă în Java și oferă suport extins pentru învățarea profundă. Este un cadru open-source care combină rețele neuronale profunde și învățare de consolidare profundă pentru a servi operațiunilor de afaceri. Este compatibil cu Scala, Kotlin, Apache Spark, Hadoop și alte limbaje JVM și cadre de calcul de date mari.
Este de obicei folosit pentru a detecta tipare și emoții în voce, vorbire și text scris. Acesta servește ca un instrument de bricolaj care poate descoperi discrepanțe în tranzacții și poate gestiona mai multe sarcini. Este o bibliotecă distribuită de calitate comercială, care are documentație API detaliată datorită naturii sale open source.
Iată un exemplu despre cum puteți implementa învățarea automată folosind Deeplearning4j.
Exemplu : Folosind Deeplearning4j, vom construi un model de rețea neuronală Convolution (CNN) pentru a clasifica cifrele scrise de mână cu ajutorul bibliotecii MNIST.
Pasul 1 : Încărcați setul de date pentru a-și afișa dimensiunea.
| DataSetIterator MNISTTrain = nou MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = nou MnistDataSetIterator(batchSize,false,seed); |
Pasul 2 : Asigurați-vă că setul de date ne oferă zece etichete unice.
| log.info(„Numărul total de etichete găsite în setul de date de antrenament” + MNISTTrain.totalOutcomes()); log.info(„Numărul total de etichete găsite în setul de date de testare” + MNISTest.totalOutcomes()); |
Pasul 3 : Acum, vom configura arhitectura modelului folosind două straturi de convoluție împreună cu un strat aplatizat pentru a afișa rezultatul.
Există opțiuni în Deeplearning4j care vă permit să inițializați schema de greutate.
| // Construirea modelului CNN MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .sămânță(sămânță) // sămânță aleatorie .l2(0,0005) // regularizare .weightInit(WeightInit.XAVIER) // inițializarea schemei de greutate .updater(new Adam(1e-3)) // Setarea algoritmului de optimizare .listă() .layer(nou ConvolutionLayer.Builder(5, 5) //Setarea pasului, dimensiunea nucleului și funcția de activare. .nIn(nCanale) .stride(1,1) .nOut(20) .activare(Activare.IDENTITATE) .construi()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // reduce eșantionarea convoluției .kernelSize(2,2) .stride(2,2) .construi()) .layer(nou ConvolutionLayer.Builder(5, 5) // Setarea pasului, dimensiunea nucleului și funcția de activare. .stride(1,1) .nOut(50) .activare(Activare.IDENTITATE) .construi()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // reduce eșantionarea convoluției .kernelSize(2,2) .stride(2,2) .construi()) .layer(nou DenseLayer.Builder().activare(Activare.RELU) .nOut(500).build()) .layer(nou OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(outputNum) .activare(Activare.SOFTMAX) .construi()) // stratul final de ieșire este 28×28 cu o adâncime de 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .construi(); |
Pasul 4 : După ce am configurat arhitectura, vom inițializa modul și setul de date de antrenament și vom începe antrenamentul modelului.
| Model MultiLayerNetwork = nou MultiLayerNetwork(conf); // inițializați greutățile modelului. model.init(); log.info(„Pasul 2: începeți antrenamentul modelului”); //Setarea unui ascultător la fiecare 10 iterații și evaluarea pe set de testare pentru fiecare epocă model.setListeners(noul ScoreIterationListener(10), nou EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Antrenarea modelului model.fit(MNISTTrain, nEpochs); |
Pe măsură ce începe pregătirea modelului, veți avea matricea de confuzie a preciziei clasificării.
Iată acuratețea modelului după zece epoci de antrenament:
| =========================Matricea confuziei======================== == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
Mediul de dezvoltare a aplicațiilor KDD susținute de Index-structure sau ELKI este o colecție de algoritmi și programe încorporate utilizate pentru extragerea datelor. Scrisă în Java, este o bibliotecă open-source care cuprinde parametrii extrem de configurabili în algoritmi. Este folosit de obicei de cercetătorii și studenții pentru a obține informații despre seturile de date. După cum sugerează și numele, oferă un mediu pentru dezvoltarea de programe sofisticate de extragere a datelor și baze de date folosind o structură de index.
7. JSAT
Java Statistical Analysis Tool sau JSAT este o bibliotecă GPL3 care utilizează un cadru orientat pe obiecte pentru a ajuta utilizatorii să implementeze învățarea automată cu Java. Este folosit de obicei în scopuri de auto-educare de către studenți și dezvoltatori. În comparație cu alte biblioteci de implementare AI, JSAT are cel mai mare număr de algoritmi ML și este cel mai rapid dintre toate cadrele. Cu zero dependențe externe, este extrem de flexibil și eficient și oferă performanțe ridicate.
8. Cadrul de învățare automată Encog
Encog este scris în Java și C# și cuprinde biblioteci care ajută la implementarea algoritmilor de învățare automată. Este folosit pentru construirea de algoritmi genetici, rețele bayesiene, modele statistice precum modelul Markov ascuns și multe altele.
9. ciocan
Învățare automată pentru instrumente lingvistice sau Mallet este utilizat în procesarea limbajului natural (NLP). La fel ca majoritatea celorlalte cadre de implementare ML, Mallet oferă, de asemenea, suport pentru modelarea datelor, gruparea datelor, procesarea documentelor, clasificarea documentelor și așa mai departe.
10. Spark MLlib
Spark MLlib este folosit de companii pentru a îmbunătăți eficiența și scalabilitatea gestionării fluxului de lucru. Procesează cantități mari de date și acceptă algoritmi ML cu încărcare mare.
Checkout: Idei de proiecte de învățare automată
Concluzie
Asta ne duce la finalul articolului. Pentru mai multe informații despre conceptele de învățare automată, luați legătura cu facultatea de top de la IIIT Bangalore și Universitatea John Moores din Liverpool prin programul de Master of Science în învățare automată și AI al upGrad.
De ce ar trebui să folosim Java împreună cu Machine Learning?
Profesioniștilor în învățarea automată le va fi mai ușor să se interfațeze cu depozitele de cod curente dacă aleg Java ca limbaj de programare pentru proiectele lor. Este un limbaj de învățare automată de preferință datorită caracteristicilor precum ușurința de utilizare, servicii de pachete, interacțiune mai bună cu utilizatorul, depanare rapidă și ilustrare grafică a datelor. Java le permite dezvoltatorilor de Machine Learning să își scaleze sistemele, făcându-l o alegere excelentă pentru construirea de aplicații de Machine Learning mari și sofisticate de la zero. Mașina virtuală Java (JVM) acceptă o serie de medii de dezvoltare integrate (IDE) care permit cursanților să creeze noi instrumente rapid.
Este ușor să înveți Java?
Deoarece Java este un limbaj de nivel înalt, este ușor de înțeles. Ca cursant, nu va trebui să intri în atât de multe detalii, deoarece este un limbaj bine structurat, orientat pe obiecte, suficient de simplu pentru începători. Deoarece există numeroase proceduri care funcționează automat, le puteți stăpâni rapid. Nu trebuie să intri în detalii despre cum funcționează lucrurile acolo. Java este un limbaj de programare independent de platformă. Acesta permite unui programator să creeze o aplicație mobilă care poate fi utilizată pe orice dispozitiv. Este limbajul preferat al Internetului lucrurilor, precum și cel mai bun instrument pentru dezvoltarea aplicațiilor la nivel de întreprindere.
Ce este ADAMS și cum este util în Machine Learning?
Sistemul Advanced Data Mining and Machine Learning (ADAMS) este un motor de flux de lucru cu licență GPLv3 pentru crearea și gestionarea rapidă a fluxurilor de lucru reactive, bazate pe date, care pot fi ușor încorporate în procesele de afaceri. Motorul fluxului de lucru, care urmează principiul less is more, se află în centrul ADAMS. ADAMS folosește o structură arborescentă în loc să permită utilizatorului să aranjeze operatorii (sau actorii în jargonul ADAMS) pe o pânză și apoi să conecteze manual intrările și ieșirile. Nu sunt necesare conexiuni explicite deoarece această structură și actorii de control determină modul în care fluxul de date în proces. Reprezentarea internă a obiectelor și imbricarea suboperatorilor în cadrul operatorilor de gestionare au ca rezultat o structură arborescentă. ADAMS oferă un set divers de agenți pentru preluarea, procesarea, extragerea și afișarea datelor.