
Ghidul suprem pentru construirea de răzuitoare web scalabile cu Scrapy
Publicat: 2022-03-10Web scraping este o modalitate de a prelua date de pe site-uri web fără a avea nevoie de acces la API-uri sau la baza de date a site-ului web. Aveți nevoie doar de acces la datele site-ului - atâta timp cât browserul dvs. poate accesa datele, veți putea să le răzuiți.
În mod realist, de cele mai multe ori ai putea să mergi manual printr-un site web și să iei datele „de mână” folosind copierea și inserarea, dar în multe cazuri, asta ți-ar lua multe ore de lucru manual, ceea ce ar putea ajunge să te coste un mult mai mult decât valorează datele, mai ales dacă ai angajat pe cineva să facă sarcina în locul tău. De ce să angajați pe cineva să lucreze la 1–2 minute pe interogare, când puteți obține un program pentru a efectua o interogare automat la fiecare câteva secunde?
De exemplu, să presupunem că doriți să întocmiți o listă cu câștigătorii Oscarului pentru cel mai bun film, împreună cu regizorul lor, actorii în rolurile principale, data lansării și durata de difuzare. Folosind Google, puteți vedea că există mai multe site-uri care vor enumera aceste filme după nume și poate câteva informații suplimentare, dar, în general, va trebui să urmați cu link-uri pentru a capta toate informațiile pe care le doriți.
Evident, ar fi nepractic și consumator de timp să parcurgeți fiecare link din 1927 până în prezent și să încercați manual să găsiți informațiile prin fiecare pagină. Cu web scraping, trebuie doar să găsim un site web cu pagini care conțin toate aceste informații și apoi să îndreptăm programul nostru în direcția corectă cu instrucțiunile potrivite.
În acest tutorial, vom folosi Wikipedia ca site-ul nostru web, deoarece conține toate informațiile de care avem nevoie și apoi vom folosi Scrapy pe Python ca instrument pentru a ne răzui informațiile.
Câteva avertismente înainte de a începe:
Data scraping implică creșterea încărcării serverului pentru site-ul pe care îl scraping, ceea ce înseamnă un cost mai mare pentru companiile care găzduiesc site-ul și o experiență de calitate mai scăzută pentru alți utilizatori ai site-ului respectiv. Calitatea serverului care rulează site-ul web, cantitatea de date pe care încercați să le obțineți și rata la care trimiteți cereri către server vor modera efectul pe care îl aveți asupra serverului. Ținând cont de acest lucru, trebuie să ne asigurăm că respectăm câteva reguli.
Majoritatea site-urilor au, de asemenea, un fișier numit robots.txt în directorul lor principal. Acest fișier stabilește reguli pentru ce directoare site-urile nu doresc să acceseze scrapers. Pagina de Termeni și condiții a unui site web vă va informa, de obicei, care este politica lor privind eliminarea datelor. De exemplu, pagina de condiții a IMDB are următoarea clauză:
Roboți și Screen Scraping: Nu puteți utiliza data mining, roboți, screen scraping sau instrumente similare de colectare și extragere a datelor pe acest site, cu excepția consimțământului nostru expres și scris, după cum este menționat mai jos.
Înainte de a încerca să obținem datele unui site web, ar trebui să verificăm întotdeauna termenii site-ului și robots.txt pentru a ne asigura că obținem date legale. Atunci când ne construim scraper-urile, trebuie să ne asigurăm că nu copleșim un server cu solicitări pe care nu le poate gestiona.
Din fericire, multe site-uri web recunosc nevoia utilizatorilor de a obține date și fac datele disponibile prin intermediul API-urilor. Dacă acestea sunt disponibile, este de obicei o experiență mult mai ușoară să obțineți date prin API decât prin scraping.
Wikipedia permite eliminarea datelor, atâta timp cât roboții nu merg „prea repede”, așa cum se specifică în robots.txt . De asemenea, oferă seturi de date descărcabile, astfel încât oamenii să poată procesa datele pe propriile lor mașini. Dacă mergem prea repede, serverele ne vor bloca automat IP-ul, așa că vom implementa cronometre pentru a ne respecta regulile.
Noțiuni introductive, instalarea bibliotecilor relevante folosind Pip
În primul rând, pentru a începe, să instalăm Scrapy.
Windows
Instalați cea mai recentă versiune de Python de pe https://www.python.org/downloads/windows/
Notă: utilizatorii Windows vor avea nevoie și de Microsoft Visual C++ 14.0, pe care îl puteți prelua din „Microsoft Visual C++ Build Tools” de aici.
De asemenea, veți dori să vă asigurați că aveți cea mai recentă versiune de pip.
În cmd.exe , tastați:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyAcest lucru va instala automat Scrapy și toate dependențele.
Linux
Mai întâi, veți dori să instalați toate dependențele:
În Terminal, introduceți:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devOdată ce totul este instalat, trebuie doar să tastați:
pip install --upgrade pipPentru a vă asigura că pip este actualizat, apoi:
pip install scrapyȘi totul este gata.
Mac
În primul rând, va trebui să vă asigurați că aveți un compilator c pe sistemul dvs. În Terminal, introduceți:
xcode-select --installDupă aceea, instalați homebrew de pe https://brew.sh/.
Actualizați variabila PATH, astfel încât pachetele homebrew să fie folosite înaintea pachetelor de sistem:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcInstalați Python:
brew install pythonȘi apoi asigurați-vă că totul este actualizat:
brew update; brew upgrade pythonDupă ce ați terminat, instalați Scrapy folosind pip:
pip install Scrapy > ## Prezentare generală despre Scrapy, cum se potrivesc piesele, analizoare, păianjeni etc.Veți scrie un scenariu numit „Pianjen” pentru ca Scrapy să ruleze, dar nu vă faceți griji, păianjenii Scrapy nu sunt deloc înfricoșători, în ciuda numelui lor. Singura asemănare pe care o au păianjenii Scrapy și păianjenii adevărați este că le place să se târască pe web.
În interiorul păianjenului este o class pe care o definiți și care îi spune lui Scrapy ce să facă. De exemplu, de unde să începeți accesarea cu crawlere, tipurile de solicitări pe care le face, cum să urmăriți linkurile din pagini și cum analizează datele. Puteți chiar să adăugați funcții personalizate pentru a procesa datele, înainte de a le scoate înapoi într-un fișier.
Pentru a începe primul nostru păianjen, trebuie să creăm mai întâi un proiect Scrapy. Pentru a face acest lucru, introduceți acest lucru în linia de comandă:
scrapy startproject oscarsAcest lucru va crea un folder cu proiectul dvs.
Vom începe cu un păianjen de bază. Următorul cod trebuie introdus într-un script Python. Deschideți un nou script python în /oscars/spiders și numiți-l oscars_spider.py
Vom importa Scrapy.
import scrapyApoi începem să ne definim clasa Păianjen. Mai întâi, setăm numele și apoi domeniile pe care păianjenul are voie să le zgârie. În cele din urmă, îi spunem păianjenului de unde să înceapă să zgârie.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']Apoi, avem nevoie de o funcție care va capta informațiile pe care le dorim. Deocamdată, vom lua doar titlul paginii. Folosim CSS pentru a găsi eticheta care poartă textul titlului și apoi o extragem. În cele din urmă, returnăm informațiile înapoi la Scrapy pentru a fi înregistrate sau scrise într-un fișier.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data Acum salvați codul în /oscars/spiders/oscars_spider.py
Pentru a rula acest spider, pur și simplu accesați linia de comandă și tastați:
scrapy crawl oscarsAr trebui să vedeți o ieșire ca aceasta:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Felicitări, ți-ai construit primul răzuitor Scrapy de bază!

Cod complet:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataEvident, vrem să facă ceva mai mult, așa că haideți să vedem cum să folosiți Scrapy pentru a analiza datele.
Mai întâi, să ne familiarizăm cu shell-ul Scrapy. Shell-ul Scrapy vă poate ajuta să vă testați codul pentru a vă asigura că Scrapy preia datele pe care le doriți.
Pentru a accesa shell-ul, introduceți acest lucru în linia de comandă:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”Acest lucru va deschide practic pagina către care ați direcționat-o și vă va permite să rulați linii individuale de cod. De exemplu, puteți vizualiza codul HTML brut al paginii tastând:
print(response.text)Sau deschideți pagina în browser-ul dvs. implicit, tastând:
view(response)Scopul nostru aici este să găsim codul care conține informațiile pe care le dorim. Deocamdată, să încercăm să luăm numai numele titlurilor filmului.
Cel mai simplu mod de a găsi codul de care avem nevoie este prin deschiderea paginii în browser și inspectarea codului. În acest exemplu, folosesc Chrome DevTools. Doar faceți clic dreapta pe orice titlu de film și selectați „inspectați”:
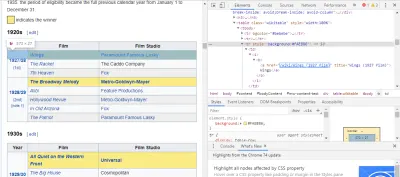
După cum puteți vedea, câștigătorii Oscarului au un fundal galben, în timp ce nominalizații au un fundal simplu. Există, de asemenea, un link către articolul despre titlul filmului, iar linkurile pentru filme se termină în film) . Acum că știm acest lucru, putem folosi un selector CSS pentru a prelua datele. În shell-ul Scrapy, tastați:
response.css(r"tr[] a[href*='film)']").extract()După cum puteți vedea, aveți acum o listă cu toți câștigătorii Oscarului pentru cel mai bun film!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']Revenind la obiectivul nostru principal, vrem o listă a câștigătorilor Oscarului pentru cel mai bun film, împreună cu regizorul lor, actorii în rolurile principale, data lansării și durata de difuzare. Pentru a face acest lucru, avem nevoie de Scrapy pentru a prelua date din fiecare dintre acele pagini de film.
Va trebui să rescriem câteva lucruri și să adăugăm o nouă funcție, dar nu vă faceți griji, este destul de simplu.
Vom începe prin a iniția racleta în același mod ca înainte.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] Dar de data aceasta, două lucruri se vor schimba. În primul rând, vom importa time împreună cu scrapy , deoarece dorim să creăm un cronometru pentru a restricționa cât de repede botul se scurge. De asemenea, atunci când analizăm paginile prima dată, dorim să obținem doar o listă a linkurilor către fiecare titlu, astfel încât să putem prelua informații din acele pagini.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req Aici facem o buclă pentru a căuta fiecare link de pe pagină care se termină în film) cu fundalul galben în el și apoi unim acele linkuri împreună într-o listă de URL-uri, pe care le vom trimite la funcția parse_titles pentru a le trece mai departe. De asemenea, introducem un cronometru pentru ca acesta să solicite numai pagini la fiecare 5 secunde. Amintiți-vă, putem folosi shell-ul Scrapy pentru a testa câmpurile noastre response.css pentru a ne asigura că primim datele corecte!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data Lucrul real se realizează în funcția noastră parse_data , unde creăm un dicționar numit data și apoi completăm fiecare cheie cu informațiile pe care le dorim. Din nou, toți acești selectori au fost găsiți folosind Chrome DevTools, așa cum s-a demonstrat înainte și apoi au fost testați cu shell-ul Scrapy.
Linia finală returnează dicționarul de date înapoi la Scrapy pentru a fi stocat.
Cod complet:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataUneori vom dori să folosim proxy-uri, deoarece site-urile web vor încerca să ne blocheze încercările de scraping.
Pentru a face acest lucru, trebuie să schimbăm doar câteva lucruri. Folosind exemplul nostru, în def parse() , trebuie să-l schimbăm în următorul:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqAceasta va direcționa cererile prin serverul proxy.
Implementare și înregistrare, arată cum să gestionați efectiv un păianjen în producție
Acum este timpul să ne alergăm păianjenul. Pentru a face ca Scrapy să înceapă scraping și apoi să iasă într-un fișier CSV, introduceți următoarele în linia de comandă:
scrapy crawl oscars -o oscars.csvVeți vedea o ieșire mare și, după câteva minute, se va finaliza și veți avea un fișier CSV în folderul proiectului.
Compilarea rezultatelor, arătați cum să utilizați rezultatele compilate în pașii anteriori
Când deschideți fișierul CSV, veți vedea toate informațiile dorite (sortate pe coloane cu titluri). Este chiar atât de simplu.
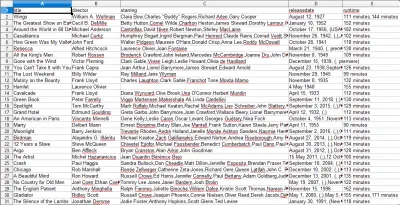
Cu data scraping, putem obține aproape orice set de date personalizat pe care îl dorim, atâta timp cât informațiile sunt disponibile public. Ce vrei să faci cu aceste date depinde de tine. Această abilitate este extrem de utilă pentru a face cercetări de piață, pentru a menține actualizate informațiile de pe un site web și multe alte lucruri.
Este destul de ușor să vă configurați propriul web scraper pentru a obține seturi de date personalizate pe cont propriu, totuși, amintiți-vă întotdeauna că ar putea exista și alte modalități de a obține datele de care aveți nevoie. Companiile investesc mult în furnizarea datelor pe care le doriți, așa că este corect să le respectăm termenii și condițiile.
Resurse suplimentare pentru a afla mai multe despre Scrapy și Web Scraping în general
- Site-ul oficial Scrapy
- Pagina GitHub a lui Scrapy
- „Cele mai bune 10 instrumente de scraping de date și instrumente de web scraping”, API-ul Scraper
- „5 Sfaturi pentru Web Scraping fără a fi blocat sau inclus pe lista neagră”, Scraper API
- Parsel, o bibliotecă Python pentru a utiliza expresii regulate pentru a extrage date din HTML.