
Strategii pentru proiecte fără cap cu sisteme de management al conținutului structurat
Publicat: 2022-03-10Acesta este ghidul pe care mi-aș dori să îl am în ultimii doi ani când rulez proiecte cu sisteme de management al conținutului (CMS) fără cap. Am fost dezvoltator, consultant în experiența utilizatorului și tehnologie, manager de proiect, arhitect informațional și autor. Diferitele pălării m-au făcut să realizez că, chiar dacă avem așa-numitele CMS-uri „fără cap” de ceva vreme, mai există o cale de gândit cum să le folosim cel mai bine.
Ne aflăm acum într-un loc în care mulți dintre noi se bazează pe cadrele JavaScript pentru lucrul frontal, folosind sisteme de proiectare făcute din componente și compoziții, mai degrabă decât doar implementând layout-uri de pagină plate. Există multă tracțiune către JAMstacks și aplicațiile izomorfe/universale care rulează atât pe server, cât și pe client. Ultima piesă a puzzle-ului este modul în care gestionăm tot conținutul.
CMS-urile tradiționale adaugă API-uri pentru a difuza conținut prin solicitări de rețea și format JSON. În plus, CMS-urile „fără cap” au apărut pentru a difuza exclusiv conținut prin intermediul API-urilor. Argumentul meu în acest articol este că ar trebui să petrecem mai puțin timp vorbind despre „fără cap” și mai mult despre „conținut structurat” . Pentru că aceasta este calitatea esențială a acestor sisteme. Există o mulțime de implicații pentru ambarcațiunile noastre implicate de aceste sisteme și mai avem un drum de parcurs în ceea ce privește descoperirea tiparelor bune despre cum ar trebui să ne ocupăm de aceste tehnologii.
Venind la consultanța tehnologică dintr-o experiență în științe umaniste, am învățat multe despre cum să organizez și să lucrez cu proiecte web care au o abordare centrată pe conținut - atât cu noile CMS-uri bazate pe API, cât și cu cele tradiționale. Am ajuns să apreciez cum să încep devreme cu conținutul live real dintr-un CMS; a face acest lucru într-un cadru interdisciplinar nu numai că a făcut posibilă descoperirea complexităților într-o etapă anterioară, dar oferă, de asemenea, agenție tuturor celor implicați și oferă oportunități de a reflecta asupra provocărilor și posibilităților tehnologiei și designului în sensul său cel mai larg.
WordPress fără cap
Toată lumea știe că, dacă un site web este lent, utilizatorii îl vor abandona. Să aruncăm o privire mai atentă la elementele de bază ale creării unui WordPress decuplat. Citiți un articol înrudit →
În acest articol, voi sugera câteva strategii globale, cu câteva exemple concrete, din lumea reală, despre cum să vă gândiți la lucrul cu conținut structurat. La momentul scrierii, tocmai am început să lucrez pentru o companie SaaS care oferă un astfel de serviciu de management al conținutului, pentru găzduirea conținutului livrat prin API-uri. Voi face referiri la el, atât din cauza experienței mele anterioare cu el în proiecte în care am fost implicat ca consultant, cât și pentru că cred că ilustrează în mod adecvat punctele pe care vreau să le fac. Așa că luați în considerare acest lucru un fel de declinare a răspunderii.
Acestea fiind spuse, mă gândesc să scriu acest articol de câțiva ani și m-am străduit să îl fac aplicabil oricarei platforme pe care alegeți să mergeți. Așa că, fără alte prelungiri, să sărim cu douăzeci de ani înapoi în timp pentru a înțelege puțin mai mult unde ne aflăm astăzi.
Primele mișcări cu standardele web
La începutul anilor 2000, mișcarea Web Standards a inspirat un domeniu pentru a-și schimba modurile de lucru. Dintr-o abordare „în primul rând aspectul”, ne-au îndreptat atenția către modul în care conținutul de pe o pagină ar trebui marcat semantic folosind HTML: meniul unui site web nu este un <table> , este un <nav> ; Un titlu nu este un <b> , este un <h1> . A fost un pas semnificativ către gândirea diferitelor roluri pe care le joacă conținutul web pentru a ajuta utilizatorii să-l găsească, să-l identifice și să-l asume.
Mișcarea Web Standards a introdus argumentul că marcajul semantic a îmbunătățit accesibilitatea, ceea ce i-a îmbunătățit și clasarea în rezultatele căutării Google. De asemenea, a marcat o schimbare în modul în care ne gândim la conținutul web . Site-ul dvs. nu mai era singurul loc în care era reprezentat conținutul dvs. De asemenea, a trebuit să vă gândiți la modul în care paginile dvs. web au fost prezentate în alte contexte vizuale, cum ar fi în rezultatele căutării sau cititoarele de ecran. Acest lucru a fost alimentat ulterior de rețelele sociale și de previzualizările încorporate ale linkurilor partajate. Mentalitatea sa schimbat de la modul în care ar trebui să arate conținutul la ceea ce ar trebui să însemne . Aceasta se întâmplă să fie, de asemenea, cheia pentru a lucra cu conținut structurat.
Odată cu adoptarea dispozitivelor de buzunar conectate la Internet, web-ul a devenit dintr-o dată un concurent serios în aplicații. Concurența, însă, a fost în mare parte pentru ochii utilizatorului final. Multe organizații încă mai trebuiau să distribuie informații despre produsele și serviciile lor atât în aplicațiile lor, cât și în diferitele lor prezențe web. În același timp, web-ul s-a maturizat, iar JavaScript și AJAX au facilitat conectarea diferitelor surse de conținut prin intermediul API-urilor. Astăzi, avem GraphQL și instrumente care simplifică preluarea conținutului și gestionarea stării. Și astfel, bucățile puzzle-ului tehnologic încep să cadă la locul lor.
„Creați o dată, publicați peste tot”
Deși este descrisă în mare parte ca o „schimbare tehnologică”, încorporarea conținutului în încărcăturile utile JSON (călătorind de-a lungul tuburilor HTTP) are un impact enorm asupra modului în care gândim conținutul digital și fluxurile de lucru din jur. În unele privințe, deja a făcut-o. În urmă cu aproape zece ani, invitatul de la National Public Radio (NPR) Daniel Jacobson a scris pe blogul programableweb.com despre abordarea lor, rezumată în acronimul COPE, care înseamnă „Create Once, Publish Everywhere”. În articol, el introduce un sistem de management al conținutului care furnizează conținut la mai multe interfețe digitale printr-un API - nu printr-o mașină de randare HTML - așa cum făceau majoritatea CMS-urilor la acea vreme (și probabil acum).
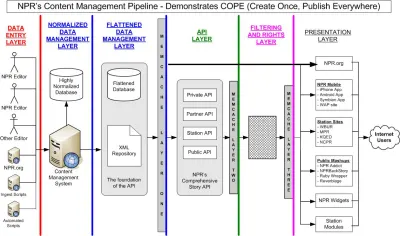
„Stratul de gestionare a datelor” COPE al NPR este ceea ce ar deveni noțiunea de „un CMS fără cap”. În primele zile ale COPE, acesta a fost realizat prin structurarea conținutului în XML. Astăzi, JSON a devenit formatul de date dominant pentru transferul de date prin API-uri, inclusiv dispozitive Internet of Things și alte sisteme din afara web. Dacă doriți să faceți schimb de conținut cu chatbot, interfețe vocale și chiar software pentru prototipuri vizuale, de foarte multe ori vorbiți HTTP cu accent JSON.
„Anularea” termenului „CMS fără cap”
Potrivit Google Trends, căutările pentru „CMS fără cap” au câștigat popularitate până în 2015, adică la șase ani după articolul COPE al NPR. Termenul „fără cap” (cel puțin în legătură cu tehnologia digitală și nu cu aristocrația franceză de la sfârșitul secolului al XVIII-lea), a fost folosit mai mult timp pentru a vorbi despre sisteme care rulează fără o interfață grafică de utilizator.
Notă : S-ar putea argumenta că o interfață de linie de comandă este într-adevăr „grafică”, cum ar fi software-ul de pe servere sau medii de testare (dar să păstrăm asta pentru alt articol).
Sunt de două ori să numesc aceste noi CMS-uri „fără cap”. Le-am putea numi la fel de bine „policefalice” – ceea ce are multe capete. Ele sunt Hidrele și Cerbusele CMS-urilor. „Headless” definește, de asemenea, aceste sisteme prin capacitatea care le lipsește (adică, un motor șablon pentru randarea paginilor web), în loc să le definească prin adevărata lor putere: făcând posibilă structurarea conținutului fără constrângerile web. Acestea fiind spuse, de astăzi, multe dintre soluțiile din această categorie ar putea fi numite și „Nearly Headless Nick”. Pentru că interfața de editare este încă strâns legată de sistem. „Fără cap” lor apare din lipsa unui motor de șabloane, adică a mașinii care produce markup din conținut.
Notă : Cu siguranță aș folosi un CMS numit „Mimsy-Porpington” (cunoscut din universul Harry Potter).
În schimb, fac conținut disponibil printr-un API, oferindu-vă astfel mai multă flexibilitate pentru cum, ce și unde doriți să afișați și să utilizați acest conținut. Acest lucru îi face însoțitorii perfecti pentru cadrele de front-end JavaScript populare, cum ar fi React, Angular și Vue. Și, în ciuda pretenției de a putea livra conținut pe „site-uri web, aplicații și dispozitive”, majoritatea dintre ele sunt încă limitate de modul în care funcționează conținutul web. Acest lucru este cel mai vizibil în modul în care majoritatea gestionează textul îmbogățit - stocându-l fie ca HTML, fie ca Markdown.
CMS-urile tradiționale au început, de asemenea, să adauge API-uri oarecum generice pe lângă sistemele lor de randare a șablonului și numesc acest lucru „decuplat” ca o modalitate de a se distinge de proaspeții lor concurenți. „Toate acestea și API-urile, de asemenea!”* este afirmația. Unele dintre aceste CMS-uri sunt, de asemenea, destul de agnostice când vine vorba de modelarea conținutului. De exemplu, Craft CMS, nu face aproape deloc presupuneri despre modelul dvs. de conținut atunci când îl instalați pentru prima dată. De asemenea, Wordpress se îndreaptă către utilizarea API-urilor pentru livrarea de conținut. Bănuiesc că decalajul dintre vechii jucători din domeniul CMS și cei noi se va restrânge pe măsură ce mergem mai departe.
Cu toate acestea, plasarea managementului conținutului în spatele API-urilor (în loc de un randament HTML) este un pas important către modalități mai sofisticate de lucru într-o epocă în care textul, imaginile, videoclipurile și media ale unei organizații sunt digitizate și expuse utilizatorilor și clienților interni și externi. Este timpul, totuși, să trecem de la definirea capacităților lor de redare frontend lipsite, la ceea ce pot face cu adevărat pentru noi: oferiți-ne o modalitate de a lucra cu conținut structurat . Deci, ar trebui să le numim „Sisteme de management al conținutului structurat”? Ca în „Nu, Bob, acesta nu este CMS-ul tău obișnuit. Acesta este un SCMS, credeți-mă, va fi un lucru.”
Nu este vorba despre capete, ci despre conținut structurat
Cea mai radicală schimbare pe care o impune Sistemele de management al conținutului structurat (SCMS) este îndepărtarea de la aranjarea conținutului conform unei ierarhii a paginii, în cazul în care sunteți liber să structurați conținutul în orice scop considerați potrivit. Evitarea conținutului duplicat este un avantaj clar, deoarece crește fiabilitatea și scade sarcina administrativă (nu trebuie să faceți față conținutului duplicat pe mai multe canale). Cu alte cuvinte: Creați o dată, publicați peste tot . Dacă trebuie să actualizați o singură dată descrierea produsului - într-un singur sistem - și se actualizează oriunde produsul dvs. este expus utilizatorului, acesta este în mod clar un avantaj.
În timp ce furnizorii SCMS folosesc frecvent „site-ul dvs. și o aplicație” pentru a justifica gândirea diferită asupra structurii paginii, nu trebuie să treceți râul pentru a obține beneficii dintr-o structură de conținut structurată. Odată cu popularitatea cadrelor JavaScript, este din ce în ce mai comun să construiți site-uri web ca o compoziție de componente individuale, care pot fi „umplute” cu conținut diferit în funcție de stare și context. Este posibil să aveți un card de produs care apare în mai multe contexte diferite în aplicația dvs. web. Observăm că dezvoltarea web modernă se îndepărtează de la setarea documentelor și a paginilor la compunerea componentelor în funcție de un amestec de input de utilizator, algoritmi și personalizare.
Aceste tendințe privind modul în care sunt realizate sistemele de proiectare și modul în care suntem încurajați să lucrăm în echipă prin procese de testare, învățare și iterare, fac ca domeniul managementului conținutului să fie pregătit pentru câteva moduri noi de gândire. Au apărut unele modele, dar mai avem multe drumuri de parcurs. Prin urmare, pe baza experienței mele de a lucra în echipe și proiecte care au pus conținutul în prim-plan și ca acum parte a unei echipe care construiește un serviciu pentru acesta (și vă îndemn să fiți conștienți de orice părtinire aici), vreau să să prezinte câteva strategii care cred că pot fi utile și să creeze puncte pentru discuții ulterioare.
1. Abordați conținutul în echipe multidisciplinare
Cred că este un lucru din trecut faptul că un designer grafic poate preda pagini învechite, perfect pixeli unui dezvoltator de front-end a cărui responsabilitate a fost să „implementeze” designul. Acum realizăm sisteme de proiectare constând din componente mai mici, dispuse în compoziții care vin cu mai multe stări posibile din cutie. De cele mai multe ori, aceste componente trebuie să fie rezistente la intrarea generată de utilizator, ceea ce înseamnă că, cu cât introduceți mai devreme conținut live în proces, cu atât mai bine. Responsabilitatea unui dezvoltator de front-end nu este de a reproduce viziunea unui designer grafic ; este de a manevra un domeniu complex al modului în care browserele redă HTML, CSS și JavaScript, asigurându-ne că interfețele cu utilizatorul sunt receptive, accesibile și performante.
Când lucram ca consultant tehnologic la Netlife (o companie de consultanță specializată în experiența utilizatorului), am văzut că se făceau pași grozavi către colaborarea între dezvoltatori, designeri și cercetătorii utilizatori. Chiar dacă editorii noștri de conținut au fost întotdeauna implicați în proiect de la început, contribuțiile lor nu au intrat în fluxul de lucru de proiectare, în principal din cauza fricțiunilor tehnice.
Blocajul a fost adesea un CMS moștenit pe care nu l-am putut atinge sau că a fost nevoie de timp pentru a construi structura conținutului, deoarece depindea de aspectul designului. Acest lucru a dus adesea la dublarea muncii: am realizat un prototip HTML, adesea bazat pe conținutul analizat din fișierele Markdown, care a trebuit să fie reimplementat în stiva CMS atunci când testarea utilizatorului a fost încheiată și toată lumea a fost perfect fericită. . Acesta a fost adesea un proces costisitor, deoarece limitările din CMS au fost descoperite târziu în proces. De asemenea, creează presiune asupra tuturor pieselor pentru a „a face bine de prima dată” și a lăsat mai puțin spațiu pentru genul de experimentare pe care l-ați dori într-un proiect de design.
Munca multidisciplinară necesită sisteme Nimble
Trecerea la un SCMS în care a durat câteva minute pentru a codifica un model de conținut (unde câmpurile și API-ul erau gata instantaneu) ne-a dat procesul peste cap - și în bine. Îmi amintesc că am stat cu editorul de conținut al noului u4.no în primele zile ale proiectului. Vorbind despre cum au lucrat și ar dori să lucreze cu conținutul lor. Mai degrabă rapid, ne-am tradus concluziile în obiecte JavaScript simple care au fost transformate instantaneu într-un mediu de editare în browser. Găsirea unor titluri și descrieri utile pentru titluri. Am vorbit despre modul în care doreau fragmente de text pe care le-ar putea reutiliza în diferite pagini și contexte, pe care le-au numit intern „pepite”, pe care apoi le-am creat atunci și acolo.
Permiterea acestui tip de explorare la începutul dezvoltării proiectului – un editor de conținut și un dezvoltator care vorbesc împreună în timp ce interfața era realizată în fața noastră – sa simțit puternic. Știind că putem continua să proiectăm interfața în React în timp ce ea și colegii ei au început să lucreze cu conținutul. Și să nu ne facem griji să ne pictăm într-un colț, așa cum făceam adesea cu CMS-urile în care structura era strâns legată de modul în care trebuia să codificați partea frontală a acesteia.
Un sistem de conținut ar trebui să permită experimentarea și iterația
Pe lângă proiectele de reproiectare creative, un sistem pentru conținut structurat ar trebui să vă permită, de asemenea, să vă îmbunătățiți, să testați și să repetați conținutul ca parte a întregului sistem de design. Designerii UX ar trebui să poată realiza rapid prototipuri cu conținut real folosind instrumente precum Sketch sau Framer X. Ar trebui să puteți crește managementul conținutului cu măsurători cantitative, fie că este vorba de scale de lizibilitate sau de modul în care conținutul funcționează acolo unde este utilizat.
Notă : Am folosit termenul „UX designeri” de mai sus, în ciuda faptului că toți ar trebui – într-un fel – să ne raportăm la procesul de a crea experiențe bune pentru utilizator. Cu toții suntem designeri UX în diferitele noastre linii de design.
Lucrul cu conținut structurat necesită puțină obișnuință dacă sunteți obișnuit să introduceți conținut WYSIWYG direct pe aspectul paginii dvs. web. Cu toate acestea, se pretează la o conversație care este mai în concordanță cu modul în care se mișcă domeniul designului digital. Conținutul structurat permite unei echipe de designeri, dezvoltatori, editori de conținut, cercetători de utilizatori și manageri de proiect să se gândească în mod colectiv la modul în care ar trebui să funcționeze un sistem pentru a sprijini nevoile și obiectivele strategice ale utilizatorilor. Acest lucru necesită, de asemenea, să vă gândiți diferit la modul în care se structurează conținutul, ceea ce ne duce la următoarea strategie.
2. S-ar putea să nu aveți nevoie de un ordin de ciocan
Una dintre cele mai notabile schimbări pentru mulți este că sistemele pentru conținut structurat sunt orientate spre colecții și liste de documente și nu ierarhii asemănătoare folderelor care reflectă structurile de navigare a site-ului web. Aceste structuri încetează să mai aibă sens de îndată ce o parte din conținut urmează să fie utilizată în alte contexte - fie că este vorba de chatbot, mass-media tipărită sau alte site-uri web. CMS-urile tradiționale au încercat să atenueze acest lucru permițând blocuri de conținut reutilizabile, dar acestea trebuie totuși să fie plasate în aspectul paginii și greoaie de raționat prin intermediul API-urilor.
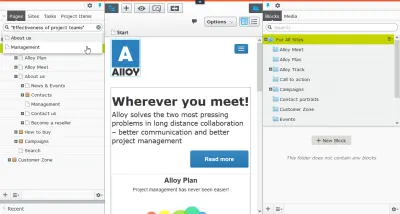
Fiecare pagină la propriu
După cum este prezentat în Modelul de bază, atunci când unul dintre referenții dvs. principale este fie Google, fie distribuirea pe rețelele sociale, ar trebui să considerați fiecare pagină o pagină de destinație. Și dacă te uiți la distribuția vizualizărilor de pagină, vei observa că unele dintre paginile tale sunt mult mai populare decât altele. Cu excepția cazului în care sunteți un site de știri, acestea tind să nu fie știrile, ci cele care permit utilizatorului să realizeze tot ceea ce spera să obțină pe site-ul dvs. Ele sunt locul unde se desfășoară de fapt afacerile.

Conținutul dvs. digital ar trebui să fie în serviciul intersecției propriilor obiective strategice și a obiectivelor individuale ale utilizatorilor dvs. Când agenția digitală Bengler (predecesorul lui sanity.io) a realizat noul site web pentru oma.eu, nu au structurat conținutul după o ierarhie elaborată de pagini. Au realizat tipuri de conținut care reflectă realitatea organizațională de zi cu zi, adică după proiecte , persoane și publicații . De fapt, site-ul web OMA este aproape complet plat din punct de vedere al ierarhiei de conținut, iar prima pagină este generată dintr-un amestec de reguli algoritmice și editoriale.
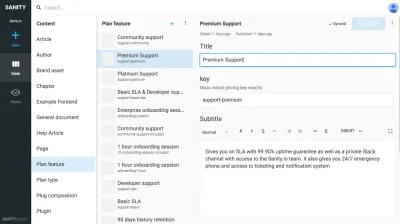
Deci, cum să procedez? Cred că o combinație de gândire la conținutul dvs. ca o reflectare a modului în care modelul mental al organizației dvs. și a ceea ce trebuie să fie acesta pentru a fi util pentru orice au nevoie utilizatorii dvs. de el.
Iată un exemplu de bază: atunci când construiți o pagină de angajați, probabil că ar trebui să începeți cu un tip de conținut numit person . O persoană poate avea un nume, informații de contact, o imagine, diferite roluri organizaționale și o scurtă biografie. Un document de persoană poate fi reutilizat în liste de contacte, linii de autor ale articolului, interfețe de asistență prin chat și insigne de acces la construcție. Poate că aveți deja un sistem intern care știe cine sunt acești oameni și care vine cu un API? Grozav, atunci sincronizează-te cu asta.
Nu vă pierdeți într-o groapă ontologică de iepure
Este util să revenim la modul în care Google indexează paginile web și la modul în care încearcă să indexeze informațiile din lume. De aceea, cheltuiesc timp și efort pe date legate (RDFa, microformat, JSON-LD). Dacă adnotați paginile dvs. web cu elemente JSON-LD, veți apărea mai vizibil în rezultatele căutării. De asemenea, este relevant atunci când informațiile dvs. ar trebui să fie rostite de asistenții vocali și afișate într-o interfață de utilizare a asistentului. Dacă conținutul dvs. este deja structurat și ușor disponibil într-un API, vă va fi relativ ușor să îl implementați în aceste microformate.
Totuși, nu sunt sigur că aș recomanda să accesați ontologiile schema.org și diverse resurse de date legate, cel puțin nu în scopuri de editor. Te poți pierde rapid într-o groapă de iepure încercând să faci structuri platonice perfecte acolo unde se potrivește totul.
Newsflash : Nu va fi niciodată, pentru că lumea este un loc dezordonat și pentru că oamenii gândesc diferit la lucruri.
Este mai important să vă structurați conținutul într-un sistem care are sens intuitiv și care se pretează să fie adaptat pe măsură ce nevoile se schimbă. Acesta este motivul pentru care este important să începeți cu modelarea conținutului încă de la începutul procesului de proiectare și dezvoltare - trebuie să aflați cum trebuie utilizat.
Rezumat din realitate, nu din convențiile CMS
Poate fi tentant să urmezi orice convenții cu care vine CMS-ul tău. Vă amintiți cum vă va oferi Wordpress „Postări” și „Pagini” și dintr-o dată totul trebuie să fie încadrat în acele cutii? Un câmp de text îmbogățit WYSIWYG este flexibil prin faptul că vă permite să introduceți orice, dar conținutul nu va fi structurat și ușor de adaptat - este flexibil o singură dată. Dar aveți nevoie de un loc pentru a începe maparea unui model de conținut. Sugestia mea este să începeți cu a vorbi cu oamenii, adică cu autorii și cititorii.
Cum vorbesc oamenii despre conținut în interior? Cum numesc oamenii lucruri diferite? Ai putea desfășura un exercițiu de listare gratuită, o metodă folosită de etnografi pentru a mapa taxonomiile populare. De exemplu, puteți întreba:
„Numiți diferitele tipuri de conținut din organizația noastră.”
Sau, la un nivel mai specific:
„Puteți numi diferitele tipuri de rapoarte pe care le avem în această organizație?”
Ideea acestui sondaj este de a dezvălui taxonomiile internalizate pe care oamenii le poartă, și nu opiniile sau sentimentele lor despre lucruri (ceva care tinde adesea să deraieze procesele de proiectare). Nu trebuie să-i întrebi pe mulți înainte de a avea o listă destul de exhaustivă din care poți lucra. Probabil veți descoperi că părți din lista dvs. provin din convențiile din CMS-ul dvs. actual (este bine să știți dacă doriți să faceți unele remodelări). Acum ar trebui să discutați cu editorul și să încercați să stabiliți ce trebuie să facă conținutul.
Câteva întrebări pe care le puteți pune ar putea fi următoarele:
- Trebuie să utilizați acest conținut în mai multe locuri? Unde?
- Care sunt relațiile diferite dintre tipurile de conținut?
- Unde avem nevoie ca conținutul să fie afișat astăzi și mâine?
- În ce moduri avem nevoie de sortare a conținutului? Comandarea se poate face algoritmic, de către utilizator sau trebuie să fie manual?
- Există sisteme sau baze de date în alte sisteme cu care ne putem sincroniza pentru a preveni duplicarea?
- Unde vrem să trăiască conținutul canonic? Ar trebui SCMS să fie sursa pentru acesta sau doar să sporească conținutul existent, de exemplu, o copie de marketing pentru produsele care trăiesc într-un sistem de management al produselor?
Acest lucru nu înseamnă că trebuie să aruncați arhitectura tradițională a informațiilor cu apa de baie acum călduță. Încă mai are sens să aveți articole ca tip de conținut, dacă articolele fac parte din realitatea de conținut a organizației dvs. Dar poate că nu prea aveți nevoie de convenția abstractă a categoriilor , pentru că modul în care aceste articole au referințe la tipul de servicii sau produse din ele. Și această relație permite interogarea acestor articole în circumstanțe în care are sens, fără a solicita ca cineva să aibă „gestionarea categoriei de articole” ca parte a fișei postului.
Articolul este, de asemenea, ceea ce face dificilă decuplarea completă a conținutului de stratul de prezentare. Suntem atât de obișnuiți să ne gândim la aspectul și stilul articolului, dar într-o epocă în care se așteaptă să vă găzduiți propriul conținut pe propriul domeniu și apoi să îl distribuiți pe platforme precum medium.com, deja ați renunțat. control asupra prezentării vizuale. Acest lucru ne duce la următoarea strategie.
3. Contextele de prezentare sunt, de asemenea, tipuri de conținut
Fii gata de reproiectare
Vrei să poți să te adaptezi și să schimbi rapid și structura de navigare a site-ului tău web, fără a fi nevoie să reconstruiești întreaga arhitectură de conținut sau să lupți împotriva unei interfețe stricte asemănătoare unui folder. De asemenea, doriți să puteți avea o ierarhie de conținut, pentru că uneori are sens, iar uneori devine mai adânc decât două niveluri, unde majoritatea interfețelor din departamentul de CMS-uri API-first nu reușesc să ofere mult ajutor.
Interesant este că sistemele de management al conținutului pentru chatbot tind să folosească structuri ierarhice similare pentru aranjarea arborilor de intenții și a fluxurilor de dialog. Acest lucru înseamnă că ierarhiile de conținut joacă roluri diferite pe diferite canale, dar adesea oferă modalități de navigare prin conținut. O modalitate de a aborda acest lucru este să creați tipuri pentru navigare, în care puteți aranja conținutul după referințe și fie să construiți rute pentru pagini web, meniuri sau căi pentru interfețele conversaționale.
Sfat de relație
Referințele (sau relațiile) sunt ceea ce face posibil un sistem pentru conținut structurat și este într-adevăr miezul a tot ceea ce avem de-a face atunci când vine vorba de conținut pe web (este motivul pentru care se numește metaforic web în primul rând). A putea face referințe între biți de conținut este un lucru foarte puternic, dar poate fi și costisitor în ceea ce privește modul în care backend-urile sunt capabile să scrie și să recupereze astfel de date. Deci, este posibil să trebuiască să gândiți diferit dacă aveți o multitudine de documente, deoarece scara rareori vine gratuit.
De asemenea, merită să luați în considerare faptul că nu aveți întotdeauna nevoie de o referință explicită pentru a asocia datele; de cele mai multe ori se poate face prin criterii care au legătură cu conținutul, de exemplu „dați-mi toate persoanele și toate clădirile din această geolocalizare”. Clădirea și persoanele nu trebuie să aibă o referință explicită una la alta, atâta timp cât este implicită într-un câmp de locație pentru ambele tipuri de conținut.
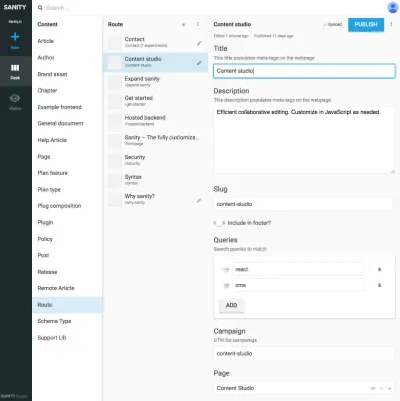
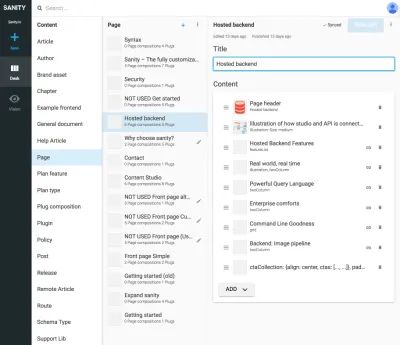
Referințele dintre tipurile de prezentare și alte tipuri de conținut sunt utile atunci când nu puteți lăsa în seama unui algoritm din stratul de prezentare să unească datele. Poate părea puțin greoi să desenezi în mod explicit aceste tipuri de prezentare și să faci compoziții ale conținutului referit, dar este o soluție la o problemă pe care o vei întâlni adesea cu SCMS-urile: este greu de știut unde este utilizat conținutul. Prin includerea tipurilor de navigare, veți lega în mod explicit conținutul de prezentare, dar nu doar una. Acest lucru face posibilă rațiunea de a lucra cu structurile de navigare independent de conținutul la care conduc.
De exemplu, în capturi de ecran am legat Google Experiments de tipul de rute , permițând adăugarea mai multor pagini compuse din referințe la conținut, ceea ce înseamnă că putem rula teste A/B fără duplicare a conținutului aproape deloc. Deoarece primim și un avertisment dacă încercăm să ștergem conținutul care este referit de alte documente, acest mod de structurare ne va împiedica să ștergem ceva ce nu ar trebui.
Relațiile între tipurile de conținut sunt o sabie cu două tăișuri. Mărește sustenabilitatea și este esențială pentru a evita dublarea. Pe de altă parte, vă puteți tăia cu ușurință deoarece creați dependențe între conținut, care (dacă nu sunt transparente) pot duce la modificări neintenționate pe canalele în care sunt afișate datele dvs. De exemplu, ar fi rău dacă am putea elimina o „pagină” folosită de o „rută” fără avertisment.
Acest lucru ne conduce la următoarea strategie, care (de acord!) este parțial dincolo de puterea utilizatorului obișnuit de astăzi, deoarece are de-a face cu modul în care sunt arhitecturate diferitele sisteme. Totuși, merită să ne gândim.
4. Nu puneți text îmbogățit într-un colț
Textul îmbogățit este mai mult decât HTML
Pot să înțeleg de ce HTML-ului i se acordă o asemenea prevalență în conținutul digital, dar știu că vine și din ceva; este un subset al SGML, un mod generalizat de structurare a documentelor care pot fi citite de mașină. După cum subliniază Claire L. Evans în minunata carte „Broad Band: The Untold Story of the Women who made the Internet” (2018), exista deja o comunitate vibrantă de oameni care se gândeau la documentele legate atunci când HTML a fost introdus. Propunerea lui Tim Berners-Lee a fost mult mai simplă decât multe dintre celelalte sisteme de la acea vreme, dar probabil de aceea a prins și a făcut posibil, de acum, web-ul deschis și gratuit.
Când vă aflați într-un browser pe World Wide Web, HTML este grozav. Dacă ești un scriitor care dorește să publice ceva care se termină în HTML simplu, Markdown este grozav. Dacă doriți ca conținutul dvs. text îmbogățit să fie integrat cu ușurință în ceva care nu este un browser sau într-un cadru JavaScript popular care vă permite să măriți HTML cu JavaScript în componente complexe (da, vorbim despre React și Vue.js) , a avea HTML în răspunsurile dvs. API începe să fie un pic o bătaie de cap – mai ales dacă trebuie să îl analizați.
Totuși, aproape toată lumea o face, chiar și noii copii de la bloc: am trecut prin toți vânzătorii de pe headlesscms.org și am răsfoit documentația și m-am înscris și pentru cei care nu au menționat-o. Cu două excepții, toate au stocat text îmbogățit fie ca HTML sau Markdown. Este în regulă dacă tot ce faci este să folosești Jekyll pentru a reda un site web sau dacă îți place să folosești dangerouslySetInnerHTML în React. Dar ce se întâmplă dacă doriți să vă reutilizați conținutul în interfețe care nu sunt pe web? Sau dacă doriți mai mult control și funcționalitate în editorul dvs. de text îmbogățit? Sau doriți doar să fie mai ușor să redați textul dvs. îmbogățit într-unul dintre cadrele frontend populare și ca componentele dvs. să se ocupe de diferite părți ale conținutului dvs. de text îmbogățit? Ei bine, va trebui fie să găsești o modalitate inteligentă de a analiza acel markdown sau HTML în ceea ce ai nevoie, fie, mai convenabil, să-l păstrezi mai bine în primul rând.
De exemplu, ce se întâmplă dacă doriți să trimiteți textul îmbogățit către o interfață vocală? Știm că asistenții vocali cresc în popularitate. Cele mai populare platforme pentru acești asistenți au capabilitățile de a obține textul pentru conținutul vorbit prin intermediul API-urilor. Apoi doriți să profitați de ceva precum limbajul de marcare a sintezei vorbirii. Un sistem pentru text portabil adoptă o abordare mai agnostică a textului îmbogățit, ceea ce vă permite să adaptați același conținut pentru diferite tipuri de interfețe.
Lectură recomandată : Experimentarea cu interfața SpeechSynthesis
Text portabil ca model de text bogat agnostic
Textul portabil este util și atunci când creați în principal conținut pentru web. Ce se întâmplă dacă doriți să aveți posibilitatea de a vă îngloba și de a vă mări textul cu structuri de date, cum ar fi o notă de subsol cu text îmbogățit sau un comentariu editorial integrat? Sau o expresie sau o formulare alternativă pentru cazurile de testare A/B? Markdown și HTML sunt rapid scurte și va trebui să vă bazați pe adăugarea unor etichete speciale de coduri scurte, așa cum Wordpress a rezolvat-o. With portable text, you have an agnostic representation of content structures, without having to marry a certain implementation. Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you'll also be able to take advantage of microservices and bots, such as spaCy, in order to annotate and augment your content without locking the document.
As for now, portable text isn't widely adopted, but we're seeing movements towards it. The specification isn't very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn't just used for your organization's online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it's about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can't know prior to solving the problem whether the user tasks are best solved by making carousels ( newsflash: most probably not ), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
- Is it possible, and how exactly will multi-disciplinary teams work with this system?
- How easy is it to change and migrate the content model?
- How does it deal with file and image assets?
- Has the editorial interface been user tested?
- To what extent can the system be configured and customized to special workflows and needs of the editorial team?
- How easy is it to export the content in a moveable format?
- How does the system accommodate for collaboration?
- Can content models be version controlled?
- How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile ( there's my coin for the swear jar ) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn't a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we've taken for granted for many years, but that's probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.