
Predicția pieței de valori folosind învățarea automată [Implementare pas cu pas]
Publicat: 2021-02-26Cuprins
Introducere
Predicția și analiza pieței de valori sunt unele dintre cele mai complicate sarcini de făcut. Există mai multe motive pentru aceasta, cum ar fi volatilitatea pieței și atât de mulți alți factori dependenți și independenți pentru a decide valoarea unei anumite acțiuni pe piață. Acești factori fac foarte dificil pentru orice analist de bursă să prezică creșterea și scăderea cu grade ridicate de precizie.
Cu toate acestea, odată cu apariția învățării automate și a algoritmilor săi robusti, cele mai recente analize de piață și evoluții de predicție a pieței de valori au început să încorporeze astfel de tehnici în înțelegerea datelor bursiere.
Pe scurt, algoritmii de învățare automată sunt folosiți pe scară largă de multe organizații în analiza și estimarea valorilor stocurilor. Acest articol va trece printr-o implementare simplă de analiză și predicție a valorilor stocurilor unui magazin online popular la nivel mondial, folosind mai mulți algoritmi de învățare automată în Python.
Declarație problemă
Înainte de a intra în implementarea programului pentru a prezice valorile bursiere, să vizualizăm datele la care vom lucra. Aici, vom analiza valoarea acțiunilor Microsoft Corporation (MSFT) de la National Association of Securities Dealers Automated Quotations (NASDAQ). Datele privind valoarea stocului vor fi prezentate sub forma unui fișier separat prin virgulă (.csv), care poate fi deschis și vizualizat folosind Excel sau o foaie de calcul.
MSFT are acțiunile înregistrate în NASDAQ și își actualizează valorile în fiecare zi lucrătoare a pieței de valori. Rețineți că piața nu permite tranzacționarea să aibă loc sâmbăta și duminica; prin urmare, există un decalaj între cele două date. Pentru fiecare dată, se notează valoarea de deschidere a stocului, cea mai mare și cea mai mică valoare a stocului respectiv în aceleași zile, împreună cu valoarea de închidere la sfârșitul zilei.
Valoarea de închidere ajustată arată valoarea acțiunilor după ce dividendele sunt afișate (prea tehnic!). În plus, este dat și volumul total al acțiunilor de pe piață. Cu aceste date, depinde de munca unui Machine Learning/Data Scientist să studieze datele și să implementeze mai mulți algoritmi care pot extrage modele din istoricul stocului Microsoft Corporation. date.

Memoria pe termen lung
Pentru a dezvolta un model de învățare automată care să prezică prețurile acțiunilor Microsoft Corporation, vom folosi tehnica memoriei pe termen scurt și lung (LSTM). Sunt folosite pentru a face mici modificări la informații prin înmulțiri și adunări. Prin definiție, memoria pe termen lung (LSTM) este o arhitectură de rețea neuronală recurentă artificială (RNN) utilizată în învățarea profundă.
Spre deosebire de rețelele neuronale de tip feed-forward standard, LSTM are conexiuni de feedback. Poate procesa puncte de date individuale (cum ar fi imagini) și secvențe întregi de date (cum ar fi vorbire sau video). Pentru a înțelege conceptul din spatele LSTM, să luăm un exemplu simplu de recenzie online de către clienți a unui telefon mobil.
Să presupunem că vrem să cumpărăm telefonul mobil, de obicei ne referim la recenziile de pe net ale utilizatorilor certificați. În funcție de gândirea și contribuțiile lor, decidem dacă mobilul este bun sau rău și apoi îl cumpărăm. Pe măsură ce citim recenziile, căutăm cuvinte cheie precum „uimitor”, „cameră bună”, „cea mai bună baterie de rezervă” și mulți alți termeni legați de un telefon mobil.
Avem tendința de a ignora cuvintele uzuale în limba engleză precum „it”, „gave”, „this”, etc. Astfel, atunci când decidem dacă cumpărăm sau nu telefonul mobil, ne amintim doar aceste cuvinte cheie definite mai sus. Cel mai probabil, uităm celelalte cuvinte.
Acesta este același mod în care funcționează algoritmul de memorie pe termen scurt. Își amintește doar informațiile relevante și le folosește pentru a face predicții ignorând datele nerelevante. În acest fel, trebuie să construim un model LSTM care recunoaște în esență doar datele esențiale despre acel stoc și omite valorile aberante ale acestuia.
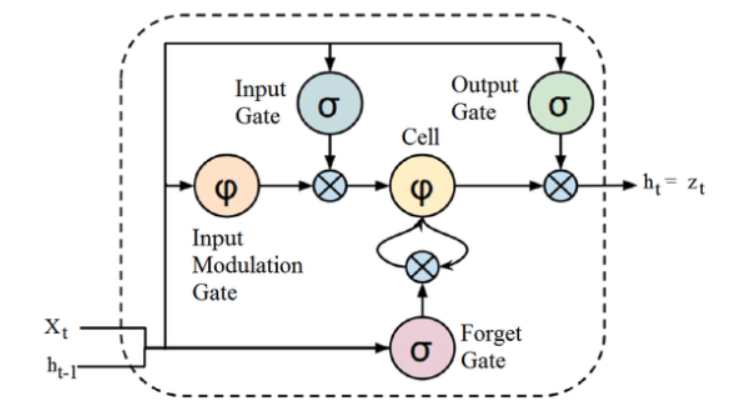
Sursă
Deși structura de mai sus a unei arhitecturi LSTM poate părea intrigantă la început, este suficient să ne amintim că LSTM este o versiune avansată a rețelelor neuronale recurente care păstrează memoria pentru a procesa secvențe de date. Poate elimina sau adăuga informații la starea celulei, atent reglate de structuri numite porți.
Unitatea LSTM cuprinde o celulă, o poartă de intrare, o poartă de ieșire și o poartă uitare. Celula își amintește valorile pe intervale de timp arbitrare, iar cele trei porți reglează fluxul de informații în și în afara celulei.
Implementarea programului
Vom trece la partea în care am folosit LSTM pentru a estima valoarea stocului folosind Machine Learning în Python.
Pasul 1 – Importarea bibliotecilor
După cum știm cu toții, primul pas este importarea bibliotecilor care sunt necesare pentru a preprocesa datele stoc ale Microsoft Corporation și celelalte biblioteci necesare pentru construirea și vizualizarea rezultatelor modelului LSTM. Pentru aceasta, vom folosi biblioteca Keras în cadrul TensorFlow. Modulele necesare sunt importate individual din biblioteca Keras.
#Importul bibliotecilor
importa panda ca PD
import NumPy ca np
%matplotlib inline
import matplotlib. pyplot ca plt
import matplotlib
din sklearn. Preprocesare import MinMaxScaler
din Keras. straturi import LSTM, Dense, Dropout
din sklearn.model_selection import TimeSeriesSplit
din sklearn.metrics import mean_squared_error, r2_score
import matplotlib. date ca mandate
din sklearn. Preprocesare import MinMaxScaler
din sklearn import linear_model
din Keras. Modele de import secvenţial
din Keras. Straturi import Dense
import Keras. Backend ca K
din Keras. Reapelurile importă EarlyStopping
din Keras. Optimizatorii îl importă pe Adam
din Keras. Modelele import load_model
din Keras. Straturi import LSTM
din Keras. utils.vis_utils import plot_model
Pasul 2 – Obținerea vizualizării datelor
Folosind biblioteca cititorului de date Pandas, vom încărca datele stoc ale sistemului local ca fișier cu valoare separată prin virgulă (.csv) și le vom stoca într-un cadru de date pandas. În cele din urmă, vom vizualiza și datele.
#Obțineți setul de date
df = pd.read_csv(„MicrosoftStockData.csv”,na_values=['null'],index_col='Data', parse_dates=True, infer_datetime_format=True)
df.head()
Obțineți certificare AI online de la cele mai bune universități din lume – Master, Programe Executive Postuniversitare și Program de Certificat Avansat în ML și AI pentru a vă accelera cariera.
Pasul 3 - Imprimați forma DataFrame și verificați valorile nule.
În acest încă un pas crucial, imprimăm mai întâi forma setului de date. Pentru a ne asigura că nu există valori nule în cadrul de date, le verificăm. Prezența valorilor nule în setul de date tinde să cauzeze probleme în timpul antrenamentului, deoarece acestea acționează ca valori aberante provocând o variație largă în procesul de instruire.
#Print Dataframe shape and Check for Null Values
print(„Forma cadru de date: „, forma df.)
print(„Valoare nulă prezentă: „, df.IsNull().values.any())
>> Forma cadrului de date: (7334, 6)
>>Valoare nulă prezentă: fals
| Data | Deschis | Înalt | Scăzut | Închide | Adj Close | Volum |
| 1990-01-02 | 0,605903 | 0,616319 | 0,598090 | 0,616319 | 0,447268 | 53033600 |
| 1990-01-03 | 0,621528 | 0,626736 | 0,614583 | 0,619792 | 0,449788 | 113772800 |
| 1990-01-04 | 0,619792 | 0,638889 | 0,616319 | 0,638021 | 0,463017 | 125740800 |
| 1990-01-05 | 0,635417 | 0,638889 | 0,621528 | 0,622396 | 0,451678 | 69564800 |
| 1990-01-08 | 0,621528 | 0,631944 | 0,614583 | 0,631944 | 0,458607 | 58982400 |
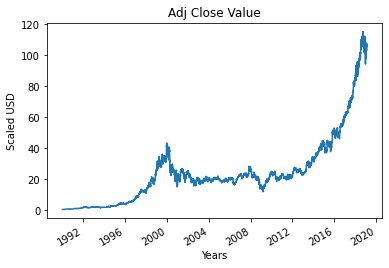
Pasul 4 – Trasarea valorii de închidere ajustată adevărată
Valoarea finală de ieșire care trebuie prezisă folosind modelul de învățare automată este valoarea de închidere ajustată. Această valoare reprezintă valoarea de închidere a acțiunilor în ziua respectivă de tranzacționare pe bursă.
#Tratați valoarea True Adj Close
df['Adj Close'].plot()
Pasul 5 – Setarea variabilei țintă și selectarea caracteristicilor
În pasul următor, atribuim coloana de ieșire variabilei țintă. În acest caz, este valoarea relativă ajustată a acțiunilor Microsoft. În plus, selectăm și caracteristicile care acționează ca variabilă independentă pentru variabila țintă (variabilă dependentă). Pentru a ține seama de scopul antrenamentului, alegem patru caracteristici, care sunt:

- Deschis
- Înalt
- Scăzut
- Volum
#Setați variabila țintă
output_var = PD.DataFrame(df['Adj Close'])
#Selectarea caracteristicilor
caracteristici = [„Deschis”, „Ridicat”, „Scăzut”, „Volum”]
Pasul 6 – Scalare
Pentru a reduce costul de calcul al datelor din tabel, vom reduce valorile stocurilor la valori între 0 și 1. În acest fel, toate datele în număr mare se reduc, reducând astfel utilizarea memoriei. De asemenea, putem obține mai multă acuratețe prin reducerea dimensiunii, deoarece datele nu sunt răspândite în valori extraordinare. Aceasta este realizată de clasa MinMaxScaler a bibliotecii sci-kit-learn.
#Scalarea
scaler = MinMaxScaler()
feature_transform = scaler.fit_transform(df[caracteristici])
feature_transform= pd.DataFrame(columns=features, data=feature_transform, index=df.index)
feature_transform.head()
| Data | Deschis | Înalt | Scăzut | Volum |
| 1990-01-02 | 0,000129 | 0,000105 | 0,000129 | 0,064837 |
| 1990-01-03 | 0,000265 | 0,000195 | 0,000273 | 0,144673 |
| 1990-01-04 | 0,000249 | 0,000300 | 0,000288 | 0,160404 |
| 1990-01-05 | 0,000386 | 0,000300 | 0,000334 | 0,086566 |
| 1990-01-08 | 0,000265 | 0,000240 | 0,000273 | 0,072656 |
După cum am menționat mai sus, vedem că valorile variabilelor caracteristice sunt reduse la valori mai mici în comparație cu valorile reale date mai sus.
Pasul 7 – Împărțirea la un set de antrenament și un set de testare.
Înainte de a introduce datele în modelul de antrenament, trebuie să împărțim întregul set de date în set de antrenament și test. Modelul Machine Learning LSTM va fi instruit pe datele prezente în setul de antrenament și testat pe setul de testare pentru acuratețe și propagare inversă.
Pentru aceasta, vom folosi clasa TimeSeriesSplit a bibliotecii sci-kit-learn. Am stabilit numărul de împărțiri la 10, ceea ce denotă că 10% din date vor fi utilizate ca set de testare, iar 90% din date vor fi utilizate pentru antrenarea modelului LSTM. Avantajul utilizării acestei serii de timp este că eșantioanele de date ale serii de timp sunt observate la intervale de timp fixe.
#Splitting în set de antrenament și set de testare
timesplit=TimeSeriesSplit(n_splits=10)
pentru train_index, test_index în timesplit.split(feature_transform):
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
Pasul 8 – Prelucrarea datelor pentru LSTM
Odată ce seturile de antrenament și de testare sunt gata, putem introduce datele în modelul LSTM odată ce acesta este construit. Înainte de aceasta, trebuie să convertim datele setului de antrenament și de testare într-un tip de date pe care modelul LSTM îl va accepta. Mai întâi convertim datele de antrenament și datele de testare în matrice NumPy și apoi le remodelăm la formatul (Număr de eșantioane, 1, Număr de caracteristici), deoarece LSTM necesită ca datele să fie alimentate în formă 3D. După cum știm, numărul de eșantioane din setul de antrenament este de 90% din 7334, care este 6667, iar numărul de caracteristici este 4, setul de antrenament este remodelat la (6667, 1, 4). În mod similar, setul de testare este de asemenea remodelat.
#Procesează datele pentru LSTM
trainX =np.array(X_train)
testX =np.array(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
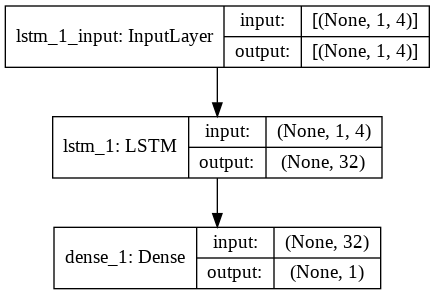
Pasul 9 – Construirea modelului LSTM
În cele din urmă, ajungem la etapa în care construim Modelul LSTM. Aici, creăm un model Keras secvențial cu un strat LSTM. Stratul LSTM are 32 de unități și este urmat de un strat dens de 1 neuron.
Utilizăm Adam Optimizer și Mean Squared Error ca funcție de pierdere pentru compilarea modelului. Aceste două sunt combinația cea mai preferată pentru un model LSTM. În plus, modelul este reprezentat și este afișat mai jos.
#Construirea modelului LSTM
lstm = secvenţial()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), activation='relu', return_sequences=False))
lstm.add(Dens(1))
lstm.compile(loss='mean_squared_error', optimizer='adam')
plot_model(lstm, show_shapes=Adevărat, show_layer_names=Adevărat)
Pasul 10 – Antrenarea modelului
În cele din urmă, antrenăm modelul LSTM proiectat mai sus pe datele de antrenament pentru 100 de epoci cu o dimensiune a lotului de 8 folosind funcția de potrivire.
#Instruire pentru modele
istoric = lstm.fit(X_train, y_train, epochs=100, batch_size=8, verbose=1, shuffle=False)
Epoca 1/100
834/834 [==============================] – 3s 2ms/pas – pierdere: 67,1211
Epoca 2/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 70,4911
Epoca 3/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 48,8155
Epoca 4/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 21,5447
Epoca 5/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 6,1709
Epoca 6/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 1,8726
Epoca 7/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 0,9380
Epoca 8/100
834/834 [==============================] – 2s 2ms/pas – pierdere: 0,6566
Epoca 9/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 0,5369
Epoca 10/100
834/834 [==============================] – 2s 2ms/pas – pierdere: 0,4761
.
.
.
.
Epoca 95/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 0,4542
Epoca 96/100
834/834 [==============================] – 2s 2ms/pas – pierdere: 0,4553
Epoca 97/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 0,4565
Epoca 98/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 0,4576
Epoca 99/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 0,4588
Epoca 100/100
834/834 [==============================] – 1s 2ms/pas – pierdere: 0,4599
În sfârșit, vedem că valoarea pierderii a scăzut exponențial în timp în timpul procesului de antrenament de 100 de epoci și a ajuns la o valoare de 0,4599.
Pasul 11 – Predicția LSTM
Cu modelul nostru pregătit, este timpul să folosim modelul antrenat folosind rețeaua LSTM pe setul de testare și să prezicem valoarea de închidere adiacentă a stocului Microsoft. Aceasta se realizează prin utilizarea funcției simple de predict pe modelul lstm construit.
Predicție #LSTM
y_pred= lstm.predict(X_test)
Pasul 12 – Valoare de închidere ajustată adevărată vs. prognozată – LSTM
În cele din urmă, după cum am prezis valorile setului de testare, putem reprezenta graficul pentru a compara atât valorile adevărate ale lui Adj Close, cât și valoarea prezisă a lui Adj Close de modelul LSTM Machine Learning.
#True vs Predicted Adj Close Value – LSTM
plt.plot(y_test, label='Valoare adevărată')
plt.plot(y_pred, label='LSTM Value')
plt.title(„Predicție de LSTM”)
plt.xlabel('Scală de timp')
plt.ylabel('Scaled USD')
plt.legend()
plt.show()
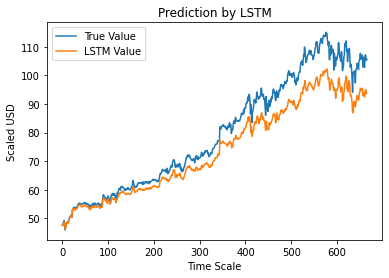
Graficul de mai sus arată că un model este detectat de modelul de rețea unic LSTM de bază construit mai sus. Prin reglarea fină a mai multor parametri și adăugarea mai multor straturi LSTM la model, putem obține o reprezentare mai precisă a valorii stocului oricărei companii date.
Concluzie
Dacă sunteți interesat să aflați mai multe despre exemple de inteligență artificială, învățare automată, consultați Programul Executive PG de la IIIT-B și upGrad în Învățare automată și IA, care este conceput pentru profesioniști care lucrează și oferă peste 450 de ore de formare riguroasă, peste 30 de studii de caz. și misiuni, statutul de absolvenți IIIT-B, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Puteți prezice piața de valori folosind învățarea automată?
Astăzi, avem o serie de indicatori care ne ajută să prezicem tendințele pieței. Cu toate acestea, nu trebuie să căutăm mai departe decât un computer de mare putere pentru a găsi cei mai precisi indicatori pentru bursa. Piața de valori este un sistem deschis și poate fi privită ca o rețea complexă. Rețeaua este formată din relațiile dintre acțiuni, companii, investitori și volumele comerciale. Folosind un algoritm de extragere a datelor, cum ar fi mașina vectorială suport, puteți aplica o formulă matematică pentru a extrage relațiile dintre aceste variabile. Bursa este acum dincolo de predicțiile umane.
Care algoritm este cel mai bun pentru predicția bursieră?
Pentru cele mai bune rezultate, ar trebui să utilizați regresia liniară. Regresia liniară este o abordare statistică care este utilizată pentru a determina relația dintre două variabile diferite. În acest exemplu, variabilele sunt prețul și timpul. În predicția bursieră, prețul este variabila independentă, iar timpul este variabila dependentă. Dacă se poate determina o relație liniară între aceste două variabile, atunci este posibil să se prezică cu exactitate valoarea stocului în orice moment în viitor.
Este predicția bursieră o problemă de clasificare sau regresie?
Înainte de a răspunde, trebuie să înțelegem ce înseamnă predicțiile bursiere. Este o problemă de clasificare binară sau o problemă de regresie? Să presupunem că vrem să prezicem viitorul unui stoc, unde viitor înseamnă următoarea zi, săptămână, lună sau an. Dacă performanța trecută a stocului la un moment dat este intrarea și viitorul este rezultatul, atunci este o problemă de regresie. Dacă performanța trecută a unei acțiuni și viitorul unei acțiuni sunt independente, atunci este o problemă de clasificare.