
Partajarea datelor între mai multe servere prin AWS S3
Publicat: 2022-03-10Când se oferă o anumită funcționalitate pentru procesarea unui fișier încărcat de utilizator, fișierul trebuie să fie disponibil procesului pe toată durata execuției. O operație simplă de încărcare și salvare nu prezintă probleme. Cu toate acestea, dacă în plus fișierul trebuie manipulat înainte de a fi salvat, iar aplicația rulează pe mai multe servere în spatele unui echilibrator de încărcare, atunci trebuie să ne asigurăm că fișierul este disponibil pentru orice server care rulează procesul de fiecare dată.
De exemplu, o funcționalitate în mai mulți pași „Încărcați avatarul utilizatorului” poate solicita utilizatorului să încarce un avatar la pasul 1, să-l decupeze la pasul 2 și, în sfârșit, să îl salveze la pasul 3. După ce fișierul este încărcat pe un server la pasul 1, fișierul trebuie să fie disponibil oricărui server care gestionează cererea pentru pașii 2 și 3, care pot fi sau nu același pentru pasul 1.
O abordare naivă ar fi să copiați fișierul încărcat la pasul 1 pe toate celelalte servere, astfel încât fișierul să fie disponibil pe toate. Cu toate acestea, această abordare nu este doar extrem de complexă, ci și imposibilă: de exemplu, dacă site-ul rulează pe sute de servere, din mai multe regiuni, atunci nu poate fi realizată.
O posibilă soluție este activarea „sesiunilor sticky” pe echilibrul de încărcare, care va atribui întotdeauna același server pentru o anumită sesiune. Apoi, pașii 1, 2 și 3 vor fi gestionați de același server, iar fișierul încărcat pe acest server la pasul 1 va fi în continuare acolo pentru pașii 2 și 3. Cu toate acestea, sesiunile sticky nu sunt pe deplin de încredere: dacă se află între pașii 1 și 2 acel server s-a prăbușit, apoi echilibratorul de încărcare va trebui să aloce un alt server, perturbând funcționalitatea și experiența utilizatorului. De asemenea, atribuirea întotdeauna aceluiași server pentru o sesiune poate duce, în circumstanțe speciale, la timpi de răspuns mai lenți de la un server supraîncărcat.
O soluție mai adecvată este păstrarea unei copii a fișierului într-un depozit accesibil tuturor serverelor. Apoi, după ce fișierul este încărcat pe server la pasul 1, acest server îl va încărca în depozit (sau, alternativ, fișierul ar putea fi încărcat în depozit direct de la client, ocolind serverul); pasul 2 de manipulare a serverului va descărca fișierul din depozit, îl va manipula și îl va încărca din nou acolo; și în cele din urmă, pasul 3 de manipulare a serverului îl va descărca din depozit și îl va salva.
În acest articol, voi descrie această ultimă soluție, bazată pe o aplicație WordPress care stochează fișiere pe Amazon Web Services (AWS) Simple Storage Service (S3) (o soluție de stocare a obiectelor în cloud pentru stocarea și preluarea datelor), care funcționează prin AWS SDK.
Nota 1: Pentru o funcționalitate simplă, cum ar fi decuparea avatarurilor, o altă soluție ar fi ocolirea completă a serverului și implementarea acestuia direct în cloud prin funcțiile Lambda. Dar, deoarece acest articol este despre conectarea unei aplicații care rulează pe server cu AWS S3, nu luăm în considerare această soluție.
Nota 2: Pentru a utiliza AWS S3 (sau orice alt serviciu AWS) va trebui să avem un cont de utilizator. Amazon oferă aici un nivel gratuit timp de 1 an, care este suficient de bun pentru a experimenta cu serviciile lor.
Nota 3: Există pluginuri terță parte pentru încărcarea fișierelor din WordPress pe S3. Un astfel de plugin este WP Media Offload (versiunea simplă este disponibilă aici), care oferă o caracteristică excelentă: transferă fără probleme fișierele încărcate în Biblioteca Media într-o găleată S3, care permite decuplarea conținutului site-ului (cum ar fi tot ce se află sub /wp-content/uploads) din codul aplicației. Prin decuplarea conținutului și a codului, putem să implementăm aplicația noastră WordPress folosind Git (altfel nu putem, deoarece conținutul încărcat de utilizator nu este găzduit în depozitul Git) și să găzduim aplicația pe mai multe servere (în caz contrar, fiecare server ar trebui să păstreze o copie a întregului conținut încărcat de utilizator.)
Crearea găleții
La crearea compartimentului, trebuie să acordăm atenție numelui compartimentului: fiecare nume al compartimentului trebuie să fie unic la nivel global în rețeaua AWS, așa că, deși am dori să numim compartimentul nostru ceva simplu, cum ar fi „avatare”, acest nume poate fi deja luat. , atunci putem alege ceva mai distinctiv, cum ar fi „avatars-name-of-my-company”.
Va trebui, de asemenea, să selectăm regiunea în care se află găleata (regiunea este locația fizică în care se află centrul de date, cu locații în toată lumea.)
Regiunea trebuie să fie aceeași cu cea în care este implementată aplicația noastră, astfel încât accesarea S3 în timpul execuției procesului să fie rapidă. În caz contrar, este posibil ca utilizatorul să fie nevoit să aștepte câteva secunde de la încărcarea/descărcarea unei imagini către/dinspre o locație îndepărtată.
Notă: Este logic să folosim S3 ca soluție de stocare a obiectelor în cloud doar dacă folosim și serviciul Amazon pentru servere virtuale pe cloud, EC2, pentru rularea aplicației. Dacă, în schimb, ne bazăm pe o altă companie pentru găzduirea aplicației, cum ar fi Microsoft Azure sau DigitalOcean, atunci ar trebui să folosim și serviciile lor de stocare a obiectelor în cloud. În caz contrar, site-ul nostru va suferi o suprasolicitare din cauza transferului de date între rețelele diferitelor companii.
În capturile de ecran de mai jos vom vedea cum să creăm găleata în care să încărcați avatarele utilizatorului pentru decupare. Mai întâi ne îndreptăm către tabloul de bord S3 și facem clic pe „Creare bucket”:
Apoi introducem numele găleții (în acest caz, „avatars-smashing”) și alegem regiunea („UE (Frankfurt)”):
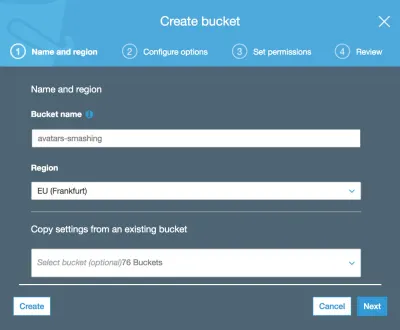
Numai numele grupului și regiunea sunt obligatorii. Pentru pașii următori putem păstra opțiunile implicite, așa că facem clic pe „Next” până când în sfârșit facem clic pe „Create bucket”, iar cu asta vom avea bucket-ul creat.
Configurarea permisiunilor utilizatorului
Când ne conectăm la AWS prin SDK, ni se va cere să introducem acreditările noastre de utilizator (o pereche de ID-ul cheii de acces și cheia de acces secretă), pentru a valida că avem acces la serviciile și obiectele solicitate. Permisiunile utilizatorului pot fi foarte generale (un rol de „admin” poate face totul) sau foarte granulare, acordând doar permisiunea operațiunilor specifice necesare și nimic altceva.
Ca regulă generală, cu cât permisiunile acordate sunt mai specifice, cu atât mai bine, pentru a evita problemele de securitate . Când creăm noul utilizator, va trebui să creăm o politică, care este un simplu document JSON care listează permisiunile care trebuie acordate utilizatorului. În cazul nostru, permisiunile noastre de utilizator vor acorda acces la S3, pentru bucket „avatars-smashing”, pentru operațiunile „Put” (pentru încărcarea unui obiect), „Get” (pentru descărcarea unui obiect) și „List” ( pentru listarea tuturor obiectelor din găleată), rezultând următoarea politică:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Put*", "s3:Get*", "s3:List*" ], "Resource": [ "arn:aws:s3:::avatars-smashing", "arn:aws:s3:::avatars-smashing/*" ] } ] }În capturile de ecran de mai jos, putem vedea cum să adăugați permisiuni de utilizator. Trebuie să mergem la tabloul de bord Identity and Access Management (IAM):
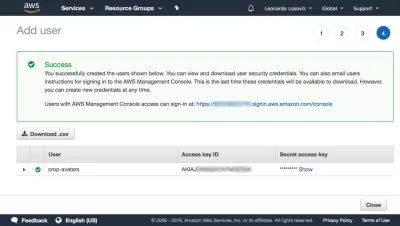
În tabloul de bord, facem clic pe „Utilizatori” și imediat după „Adăugați utilizator”. În pagina Adaugă utilizator, alegem un nume de utilizator („crop-avatars”) și bifăm „Acces programatic” ca tip de acces, care va furniza ID-ul cheii de acces și cheia de acces secretă pentru conectarea prin SDK:
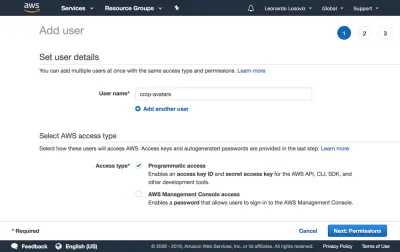
Facem apoi clic pe butonul „Următorul: Permisiuni”, facem clic pe „Atașați direct politicile existente” și facem clic pe „Creați politică”. Aceasta va deschide o filă nouă în browser, cu pagina Creare politică. Facem clic pe fila JSON și introducem codul JSON pentru politica definită mai sus:
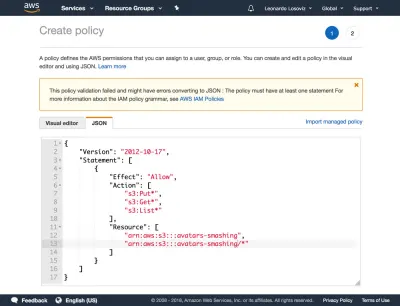
Apoi facem clic pe Examinare politică, îi dăm un nume („CropAvatars”) și, în final, facem clic pe Creare politică. După ce a fost creată politica, revenim la fila anterioară, selectăm politica CropAvatars (poate fi necesar să reîmprospătăm lista de politici pentru a o vedea), facem clic pe Următorul: Revizuire și, în final, pe Creare utilizator. După ce se face acest lucru, putem descărca în sfârșit ID-ul cheii de acces și cheia secretă de acces (vă rugăm să rețineți că aceste acreditări sunt disponibile pentru acest moment unic; dacă nu le copiem sau le descarcăm acum, va trebui să creăm o nouă pereche ):

Conectarea la AWS prin SDK
SDK-ul este disponibil într-o multitudine de limbi. Pentru o aplicație WordPress, avem nevoie de SDK-ul pentru PHP care poate fi descărcat de aici, iar instrucțiunile despre cum să o instalăm sunt aici.
Odată ce avem găleata creată, acreditările utilizatorului pregătite și SDK-ul instalat, putem începe să încărcăm fișiere pe S3.
Încărcarea și descărcarea fișierelor
Pentru comoditate, definim acreditările utilizatorului și regiunea ca constante în fișierul wp-config.php:
define ('AWS_ACCESS_KEY_ID', '...'); // Your access key id define ('AWS_SECRET_ACCESS_KEY', '...'); // Your secret access key define ('AWS_REGION', 'eu-central-1'); // Region where the bucket is located. This is the region id for "EU (Frankfurt)" În cazul nostru, implementăm funcționalitatea crop avatar, pentru care avatarurile vor fi stocate în găleata „avatars-smashing”. Cu toate acestea, în aplicația noastră este posibil să avem câteva alte compartimente pentru alte funcționalități, necesitând executarea acelorași operațiuni de încărcare, descărcare și listare a fișierelor. Prin urmare, implementăm metodele comune pe o clasă abstractă AWS_S3 și obținem intrările, cum ar fi numele găleții definit prin funcția get_bucket , în clasele copil de implementare.
// Load the SDK and import the AWS objects require 'vendor/autoload.php'; use Aws\S3\S3Client; use Aws\Exception\AwsException; // Definition of an abstract class abstract class AWS_S3 { protected function get_bucket() { // The bucket name will be implemented by the child class return ''; } } Clasa S3Client expune API-ul pentru interacțiunea cu S3. O instanțiem numai atunci când este necesar (prin inițializare leneșă) și salvăm o referință la el sub $this->s3Client pentru a continua să folosim aceeași instanță:
abstract class AWS_S3 { // Continued from above... protected $s3Client; protected function get_s3_client() { // Lazy initialization if (!$this->s3Client) { // Create an S3Client. Provide the credentials and region as defined through constants in wp-config.php $this->s3Client = new S3Client([ 'version' => '2006-03-01', 'region' => AWS_REGION, 'credentials' => [ 'key' => AWS_ACCESS_KEY_ID, 'secret' => AWS_SECRET_ACCESS_KEY, ], ]); } return $this->s3Client; } } Când avem de-a face cu $file în aplicația noastră, această variabilă conține calea absolută către fișierul de pe disc (de exemplu /var/app/current/wp-content/uploads/users/654/leo.jpg ), dar când încărcăm fișierul fișier la S3 nu ar trebui să stocăm obiectul pe aceeași cale. În special, trebuie să eliminăm bitul inițial referitor la informațiile de sistem ( /var/app/current ) din motive de securitate și, opțional, putem elimina bitul /wp-content (din moment ce toate fișierele sunt stocate în acest folder, aceasta este informație redundantă ), păstrând doar calea relativă către fișier ( /uploads/users/654/leo.jpg ). În mod convenabil, acest lucru poate fi atins prin eliminarea tot ce urmează după WP_CONTENT_DIR din calea absolută. Funcțiile get_file și get_file_relative_path de mai jos comută între căile absolute și relative ale fișierului:
abstract class AWS_S3 { // Continued from above... function get_file_relative_path($file) { return substr($file, strlen(WP_CONTENT_DIR)); } function get_file($file_relative_path) { return WP_CONTENT_DIR.$file_relative_path; } }Când încărcăm un obiect în S3, putem stabili cui i se acordă acces la obiect și tipul de acces, realizat prin permisiunile ACL (Acces Control List). Cele mai comune opțiuni sunt să păstrați fișierul privat (ACL => „privat”) și să îl faceți accesibil pentru citire pe internet (ACL => „public-read”). Deoarece va trebui să solicităm fișierul direct de la S3 pentru a-l arăta utilizatorului, avem nevoie de ACL => „public-read”:
abstract class AWS_S3 { // Continued from above... protected function get_acl() { return 'public-read'; } }În cele din urmă, implementăm metodele pentru a încărca un obiect și a descărca un obiect din compartimentul S3:
abstract class AWS_S3 { // Continued from above... function upload($file) { $s3Client = $this->get_s3_client(); // Upload a file object to S3 $s3Client->putObject([ 'ACL' => $this->get_acl(), 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SourceFile' => $file, ]); } function download($file) { $s3Client = $this->get_s3_client(); // Download a file object from S3 $s3Client->getObject([ 'Bucket' => $this->get_bucket(), 'Key' => $this->get_file_relative_path($file), 'SaveAs' => $file, ]); } }Apoi, în clasa copil de implementare definim numele găleții:
class AvatarCropper_AWS_S3 extends AWS_S3 { protected function get_bucket() { return 'avatars-smashing'; } } În cele din urmă, pur și simplu instanțiem clasa pentru a încărca avatarele în, sau a descărca de pe S3. În plus, atunci când trecem de la pașii 1 la 2 și 2 la 3, trebuie să comunicăm valoarea $file . Putem face acest lucru prin trimiterea unui câmp „file_relative_path” cu valoarea căii relative a $file printr-o operație POST (nu trecem calea absolută din motive de securitate: nu este nevoie să includem „/var/www/current ” informații pe care să le vadă cei din afară):
// Step 1: after the file was uploaded to the server, upload it to S3. Here, $file is known $avatarcropper = new AvatarCropper_AWS_S3(); $avatarcropper->upload($file); // Get the file path, and send it to the next step in the POST $file_relative_path = $avatarcropper->get_file_relative_path($file); // ... // -------------------------------------------------- // Step 2: get the $file from the request and download it, manipulate it, and upload it again $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_POST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Do manipulation of the file // ... // Upload the file again to S3 $avatarcropper->upload($file); // -------------------------------------------------- // Step 3: get the $file from the request and download it, and then save it $avatarcropper = new AvatarCropper_AWS_S3(); $file_relative_path = $_REQUEST['file_relative_path']; $file = $avatarcropper->get_file($file_relative_path); $avatarcropper->download($file); // Save it, whatever that means // ...Afișarea fișierului direct de la S3
Dacă vrem să afișăm starea intermediară a fișierului după manipulare la pasul 2 (ex. avatarul utilizatorului după cropped), atunci trebuie să facem referire la fișier direct din S3; URL-ul nu a putut indica fișierul de pe server, deoarece, din nou, nu știm ce server va gestiona acea cerere.
Mai jos, adăugăm funcția get_file_url($file) care obține adresa URL pentru acel fișier în S3. Dacă utilizați această funcție, vă rugăm să vă asigurați că ACL-ul fișierelor încărcate este „citit public” sau, în caz contrar, nu va fi accesibil utilizatorului.
abstract class AWS_S3 { // Continue from above... protected function get_bucket_url() { $region = $this->get_region(); // North Virginia region is simply "s3", the others require the region explicitly $prefix = $region == 'us-east-1' ? 's3' : 's3-'.$region; // Use the same scheme as the current request $scheme = is_ssl() ? 'https' : 'http'; // Using the bucket name in path scheme return $scheme.'://'.$prefix.'.amazonaws.com/'.$this->get_bucket(); } function get_file_url($file) { return $this->get_bucket_url().$this->get_file_relative_path($file); } }Apoi, putem pur și simplu să obținem adresa URL a fișierului pe S3 și să imprimăm imaginea:
printf( "<img src='%s'>", $avatarcropper->get_file_url($file) );Listarea fișierelor
Dacă în aplicația noastră dorim să permitem utilizatorului să vadă toate avatarele încărcate anterior, putem face acest lucru. Pentru aceasta, introducem funcția get_file_urls care listează adresa URL pentru toate fișierele stocate pe o anumită cale (în termenii S3, se numește prefix):
abstract class AWS_S3 { // Continue from above... function get_file_urls($prefix) { $s3Client = $this->get_s3_client(); $result = $s3Client->listObjects(array( 'Bucket' => $this->get_bucket(), 'Prefix' => $prefix )); $file_urls = array(); if(isset($result['Contents']) && count($result['Contents']) > 0 ) { foreach ($result['Contents'] as $obj) { // Check that Key is a full file path and not just a "directory" if ($obj['Key'] != $prefix) { $file_urls[] = $this->get_bucket_url().$obj['Key']; } } } return $file_urls; } }Apoi, dacă stocăm fiecare avatar sub calea „/users/${user_id}/“, prin trecerea acestui prefix vom obține lista tuturor fișierelor:
$user_id = get_current_user_id(); $prefix = "/users/${user_id}/"; foreach ($avatarcropper->get_file_urls($prefix) as $file_url) { printf( "<img src='%s'>", $file_url ); }Concluzie
În acest articol, am explorat cum să folosim o soluție de stocare a obiectelor în cloud pentru a acționa ca un depozit comun pentru a stoca fișiere pentru o aplicație implementată pe mai multe servere. Pentru soluție, ne-am concentrat pe AWS S3 și am continuat să arătăm pașii necesari pentru a fi integrat în aplicație: crearea compartimentului, configurarea permisiunilor utilizatorului și descărcarea și instalarea SDK-ului. În cele din urmă, am explicat cum să evitați capcanele de securitate în aplicație și am văzut exemple de cod care demonstrează cum să efectuați cele mai de bază operațiuni pe S3: încărcarea, descărcarea și listarea fișierelor, care abia necesitau câteva linii de cod fiecare. Simplitatea soluției arată că integrarea serviciilor cloud în aplicație nu este dificilă și poate fi realizată și de către dezvoltatori care nu au foarte multă experiență în cloud.