
Instrumente de date cantitative pentru designeri UX
Publicat: 2022-03-10Mulți designeri UX se tem oarecum de date, considerând că acestea necesită cunoștințe profunde de statistică și matematică. Deși acest lucru poate fi adevărat pentru știința datelor avansate, nu este adevărat pentru analiza datelor de cercetare de bază cerută de majoritatea designerilor UX. Întrucât trăim într-o lume din ce în ce mai bazată pe date, alfabetizarea de bază a datelor este utilă pentru aproape orice profesionist - nu doar pentru designerii UX.
Aaron Gitlin, designer de interacțiuni la Google, susține că mulți designeri nu sunt încă bazați pe date:
„În timp ce multe companii se promovează ca fiind bazate pe date, majoritatea designerilor sunt conduși de instinct, colaborare și metode de cercetare calitativă.”
- Aaron Gitlin, „Devenirea unui designer care cunoaște datele”
Cu acest articol, aș dori să ofer designerilor UX cunoștințele și instrumentele necesare pentru a încorpora datele în rutina lor zilnică.
Dar mai întâi, câteva concepte de date
În acest articol voi vorbi despre date structurate, adică date care pot fi reprezentate într-un tabel, cu rânduri și coloane. Datele nestructurate, fiind un subiect în sine, sunt mai greu de analizat, așa cum a subliniat Devin Pickell (specialist în marketing de conținut la G2 Crowd, scriind despre date și analiză) în articolul său „Structured vs Unstructured Data – What’s the Difference?”. Dacă datele structurate pot fi reprezentate sub formă de tabel, conceptele principale sunt:
Setul de date
Întregul set de date pe care intenționăm să-l analizăm. Acesta ar putea fi, de exemplu, un tabel Excel. Un alt format popular pentru stocarea seturilor de date este fișierul cu valori separate prin virgulă (CSV). Fișierele CSV sunt fișiere text simple utilizate pentru a stoca informații de tip tabel. Fiecare rând CSV corespunde unui rând din tabel, iar fiecare rând CSV are valori separate (în mod natural) prin virgule, care corespund celulelor din tabel.
Punct de date
Un singur rând dintr-un tabel de set de date este un punct de date. În acest fel, un set de date este o colecție de puncte de date.
Variabila de date
O singură valoare dintr-un rând de puncte de date reprezintă o variabilă de date - mai simplu, o celulă de tabel. Putem avea două tipuri de variabile de date: variabile calitative și variabile cantitative. Variabilele calitative (cunoscute și ca variabile categoriale) au un set discret de valori, cum ar fi color = red/green/blue . Variabilele cantitative au valori numerice, cum ar fi height = 167 . O variabilă cantitativă, spre deosebire de una calitativă, poate lua orice valoare.
Crearea proiectului nostru de date
Acum cunoaștem elementele de bază, este timpul să ne murdărim mâinile și să creăm primul nostru proiect de date. Scopul proiectului este de a analiza un set de date parcurgând întregul flux de date de import, procesare și reprezentare a datelor. În primul rând, ne vom alege setul de date, apoi vom descărca și instala instrumentele pentru analiza datelor.
Set de date pentru mașini
În scopul acestui articol, am ales un set de date auto, deoarece este simplu și intuitiv. Analiza datelor va confirma pur și simplu ceea ce știm deja despre mașini – ceea ce este în regulă, deoarece ne concentrăm pe fluxul de date și pe instrumente.
Putem descărca un set de date pentru mașini second hand de la Kaggle, una dintre cele mai mari surse de seturi de date gratuite. Mai întâi va trebui să vă înregistrați.
După descărcarea fișierului, deschideți-l și aruncați o privire. Este un fișier CSV foarte mare, dar ar trebui să înțelegeți esența. O linie din acest fișier va arăta astfel:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3După cum puteți vedea, acest punct de date are mai multe variabile separate prin virgule. Deoarece acum avem setul de date, să vorbim puțin despre instrumente.
Instrumentele de comerț
Vom folosi limbajul R și RStudio pentru a analiza setul de date. R este o limbă foarte populară și ușor de învățat, folosită nu numai de oamenii de știință de date, ci și de oameni de pe piețele financiare, medicină și multe alte domenii. RStudio este mediul în care sunt dezvoltate proiectele R și există o versiune gratuită, care este mai mult decât suficientă pentru nevoile noastre ca designeri UX.
Este probabil ca unii designeri UX să folosească Excel pentru fluxul de lucru al datelor. Dacă asta înseamnă că, încercați R - există șanse mari să vă placă, deoarece este ușor de învățat și mai flexibil și mai puternic decât Excel. Adăugarea lui R la trusa de instrumente va face diferența.
Instalarea instrumentelor
În primul rând, trebuie să descarcăm și să instalăm R și RStudio. Ar trebui să instalați mai întâi R, apoi RStudio. Procesele de instalare atât pentru R, cât și pentru RStudio sunt simple și directe.
Configurarea proiectului
Odată ce instalarea este finalizată, creați un folder de proiect - l-am numit used-cars-prj . În acel folder, creați un subdosar numit data , apoi copiați fișierul setului de date (descărcat din Kaggle) în acel folder și redenumiți-l în used-cars.csv . Acum reveniți la folderul nostru de proiect ( used-cars-prj ) și creați un fișier text simplu numit used-cars.r . Ar trebui să ajungeți cu aceeași structură ca în captura de ecran de mai jos.
Acum avem structura de foldere, putem deschide RStudio și crea un nou proiect R. Alegeți Proiect nou... din meniul Fișier și selectați a doua opțiune, Director existent . Apoi selectați directorul proiectului ( used-cars-prj ). În cele din urmă, apăsați butonul Creare proiect și ați terminat. Odată creat proiectul, deschideți used-cars.r în RStudio - acesta este fișierul în care vom adăuga tot codul nostru R.
Import de date
Vom adăuga prima noastră linie în used-cars.r , pentru citirea datelor din fișierul used-cars.csv . Rețineți că fișierele CSV sunt doar fișiere text simplu utilizate pentru stocarea datelor. Prima noastră linie de cod R va arăta astfel:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") Ar putea părea puțin intimidant, dar chiar nu este - apropo, aceasta este cea mai complexă linie din întregul articol. Ceea ce avem aici este funcția read.csv , care ia trei parametri.
Primul parametru este fișierul de citit, în cazul nostru used-cars.csv , care se află în folderul de date . Al doilea parametru, stringsAsFactors=FALSE este setat pentru a se asigura că șirurile precum „BMW” sau „Audi” nu sunt convertite în factori (jargonul R pentru date categorice) - după cum vă amintiți, variabilele calitative sau categoriale pot avea doar valori discrete, cum ar fi red/green/blue . În cele din urmă, al treilea parametru, sep="," specifică tipul de separator folosit pentru a separa valorile în fișierul CSV: o virgulă.
După citirea fișierului CSV, datele sunt stocate în obiectul cadru de date cars . Un cadru de date este o structură de date bidimensională (cum ar fi un tabel Excel), care este foarte utilă în R pentru a manipula datele. După introducerea liniei și rularea acesteia, va fi creat un cadru de date pentru cars . Dacă te uiți în cadranul din dreapta sus în RStudio, vei observa cadrul de date al cars , în secțiunea Date din fila Mediu . Dacă faceți dublu clic pe mașini , se va deschide o nouă filă în cadranul din stânga sus al RStudio și va prezenta cadrul de date pentru cars . După cum v-ați putea aștepta, arată ca un tabel Excel.
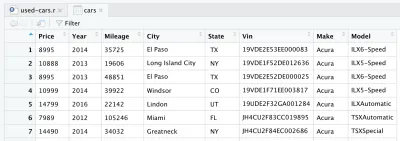
Acestea sunt de fapt datele brute pe care le-am descărcat de la Kaggle. Dar, deoarece dorim să efectuăm o analiză a datelor, trebuie să ne procesăm mai întâi setul de date.
Procesarea datelor
Prin procesare, înțelegem eliminarea, transformarea sau adăugarea de informații la setul nostru de date, pentru a ne pregăti pentru tipul de analiză pe care dorim să o facem. Avem datele într-un obiect cadru de date, așa că acum trebuie să instalăm biblioteca dplyr , o bibliotecă puternică pentru manipularea datelor. Pentru a instala biblioteca în mediul nostru R, trebuie să scriem următoarea linie în partea de sus a fișierului nostru R.
install.packages("dplyr")Apoi, pentru a adăuga biblioteca la proiectul nostru curent, vom folosi următoarea linie:
library(dplyr) Odată ce biblioteca dplyr a fost adăugată la proiectul nostru, putem începe procesarea datelor. Avem un set de date foarte mare și avem nevoie doar de datele care reprezintă același producător și model de mașină, pentru a corela asta cu prețul. Vom folosi următorul cod R pentru a păstra numai datele referitoare la BMW Seria 3 și pentru a elimina restul. Desigur, puteți alege orice alt producător și model din setul de date și vă puteți aștepta să aveți aceleași caracteristici de date.
cars <- cars %>% filter(Make == "BMW", Model == "3")Acum avem un set de date mai ușor de gestionat, deși conține încă mai mult de 11.000 de puncte de date, care se potrivește scopului pe care ne-am propus: să analizăm prețul mașinilor, distribuția de vârstă și kilometraj, precum și corelațiile dintre ele. Pentru aceasta, trebuie să păstrăm numai coloanele „Preț”, „An” și „Kilometraj” și să le eliminăm pe restul - acest lucru se face cu următoarea linie.
cars <- cars %>% select(Price, Year, Mileage)După eliminarea altor coloane, cadrul nostru de date va arăta astfel:

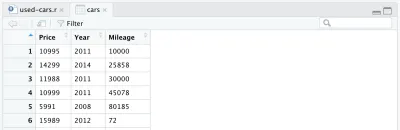
Mai este o schimbare pe care dorim să o aducem setului nostru de date: să înlocuim anul de fabricație cu vârsta mașinii. Putem adăuga următoarele două rânduri, primul pentru a calcula vârsta, al doilea pentru a schimba numele coloanei.
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)În cele din urmă, cadrul complet de date procesate arată astfel:
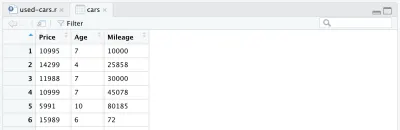
În acest moment, codul nostru R va arăta ca următorul și asta este tot pentru procesarea datelor. Acum putem vedea cât de ușor și puternic este limbajul R. Am procesat setul de date inițial destul de dramatic cu doar câteva linii de cod.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Analiza datelor
Datele noastre sunt acum în forma corectă, așa că putem merge să facem niște diagrame. După cum sa menționat deja, ne vom concentra pe două aspecte: distribuția variabilelor individuale și corelațiile dintre acestea. Distribuția variabilă ne ajută să înțelegem ce este considerat un preț mediu sau ridicat pentru o mașină uzată - sau procentul de mașini peste un anumit preț. Același lucru este valabil și pentru vechimea și kilometrajul mașinilor. Pe de altă parte, corelațiile sunt utile pentru a înțelege modul în care variabile precum vârsta și kilometrajul sunt legate între ele.
Acestea fiind spuse, vom folosi două tipuri de vizualizare a datelor: histograme pentru distribuția variabilă și diagrame de dispersie pentru corelații.
Distribuția prețurilor
Trasarea histogramei prețului mașinii în limbajul R este la fel de ușor ca aceasta:
hist(cars$Price)Un mic sfat: dacă sunteți în RStudio puteți rula codul linie cu linie; de exemplu, în cazul nostru, trebuie să rulați doar linia de mai sus pentru a afișa histograma. Nu este necesar să rulați tot codul din nou, deoarece l-ați rulat deja o dată. Histograma ar trebui să arate astfel:
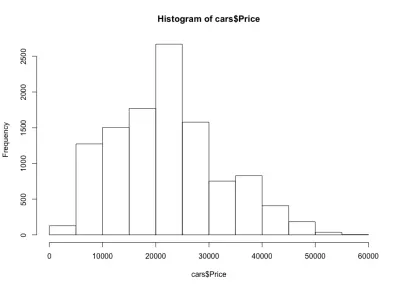
Dacă ne uităm la histogramă, observăm o distribuție în formă de clopot a prețurilor mașinilor, ceea ce ne așteptam. Majoritatea mașinilor se încadrează în intervalul de mijloc și avem din ce în ce mai puține pe măsură ce ne deplasăm pe fiecare parte. Aproape 80% dintre mașini sunt între 10.000 USD și 30.000 USD, iar noi avem maximum mai mult de 2.500 de mașini între 20.000 USD și 25.000 USD. În partea stângă avem probabil în jur de 150 de mașini sub 5.000 USD, iar în partea dreaptă și mai puține. Putem vedea cu ușurință cât de utile sunt astfel de diagrame pentru a obține informații despre date.
Distribuția pe vârstă
La fel ca și pentru prețurile mașinilor, vom folosi o linie similară pentru a reprezenta histograma vârstei mașinilor.
hist(cars$Age)Și iată histograma:
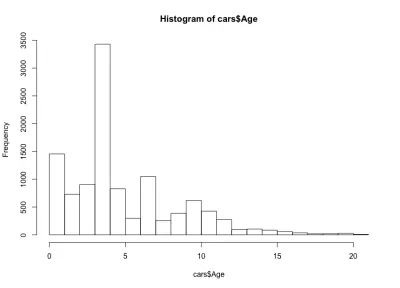
De data aceasta, histograma pare contraintuitivă - în loc de o formă simplă de clopot, avem aici patru clopote. Practic, distribuția are trei maxime locale și unul global, ceea ce este neașteptat. Ar fi interesant de văzut dacă această distribuție ciudată a vârstelor mașinilor rămâne adevărată pentru un alt producător și model de mașini. În scopul acestui articol, vom rămâne cu setul de date BMW Seria 3, dar puteți săpa mai adânc în date dacă sunteți curios. În ceea ce privește distribuția pe vârstă a mașinilor, observăm că mai mult de 90% dintre mașini au mai puțin de 10 ani, iar mai mult de 80% mai puțin de 7 ani. De asemenea, observăm că majoritatea mașinilor au mai puțin de 5 ani.
Distribuția kilometrajului
Acum, ce putem spune despre kilometraj? Desigur, ne așteptăm să avem aceeași formă de clopot pe care am avut-o la preț. Iată codul R și histograma:
hist(cars$Mileage) 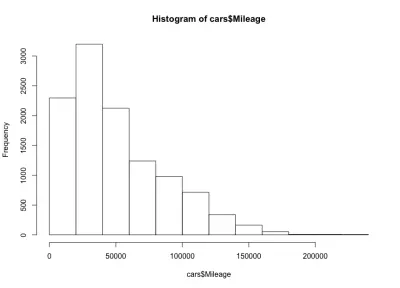
Aici avem o formă de clopot înclinată la stânga, ceea ce înseamnă că există mai multe mașini cu mai puțin kilometraj pe piață. De asemenea, observăm că majoritatea mașinilor au mai puțin de 60.000 de mile și avem un maxim de aproximativ 20.000 până la 40.000 de mile.
Corelația vârstă-preț
În ceea ce privește corelațiile, să aruncăm o privire mai atentă la corelația vârstă-preț al mașinilor. Ne-am putea aștepta ca prețul să fie corelat negativ cu vârsta - pe măsură ce vârsta unei mașini crește, prețul acesteia va scădea. Vom folosi funcția R plot pentru a afișa corelația preț-vârstă după cum urmează:
plot(cars$Age, cars$Price)Și intriga arată așa:
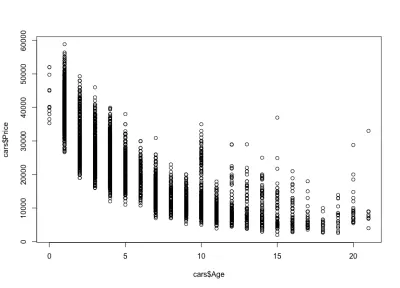
Observăm cum prețurile mașinilor scad odată cu vârsta: există mașini noi scumpe și mașini vechi mai ieftine. De asemenea, putem vedea intervalul de variație a prețului pentru orice vârstă specifică, o variație care scade odată cu vârsta mașinii. Această variație este determinată în mare măsură de kilometrajul, configurația și starea generală a mașinii. De exemplu, în cazul unei mașini de 4 ani, prețul variază între 10.000 USD și 40.000 USD.
Corelația kilometraj-vârstă
Având în vedere corelația kilometraj-vârstă, ne-am aștepta ca kilometrajul să crească odată cu vârsta, adică o corelație pozitivă. Iată codul:
plot(cars$Mileage, cars$Age)Și iată intriga:
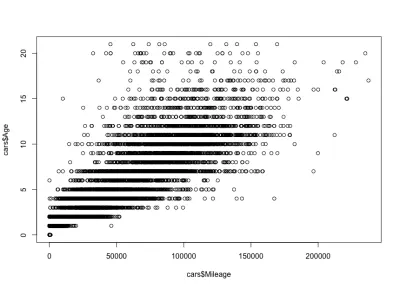
După cum puteți vedea, vârsta și kilometrajul unei mașini sunt corelate pozitiv, spre deosebire de prețul și vârsta unei mașini, care sunt corelate negativ. Avem, de asemenea, o variație estimată a kilometrajului pentru o anumită vârstă; adică mașinile de aceeași vârstă au kilometraj diferite. De exemplu, majoritatea mașinilor de 4 ani au kilometraj între 10.000 și 80.000 de mile. Dar există și valori aberante, cu un kilometraj mai mare.
Corelația kilometraj-preț
După cum era de așteptat, va exista o corelație negativă între kilometrajul mașinilor și prețul, ceea ce înseamnă că creșterea kilometrajului reduce prețul.
plot(cars$Mileage, cars$Price)Și iată intriga:
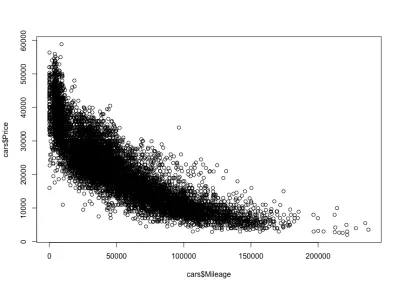
După cum ne așteptam, o corelație negativă. De asemenea, putem observa intervalul de preț brut între 3.000 USD și 50.000 USD și kilometrajul între 0 și 150.000 USD. Dacă ne uităm mai atent la forma distribuției, vedem că prețul scade mult mai repede pentru mașinile cu mai puțin kilometraj decât pentru mașinile cu mai mult kilometraj. Sunt mașini cu kilometraj aproape zero, unde prețul scade dramatic. De asemenea, peste 200.000 de mile interval - deoarece kilometrajul este foarte mare - prețul rămâne constant.
De la numere la vizualizări de date
În acest articol, am folosit două tipuri de vizualizare: histograme pentru distribuțiile de date și diagrame de dispersie pentru corelațiile de date. Histogramele sunt reprezentări vizuale care preiau valorile unei variabile de date ( numere reale) și arată cum sunt distribuite într-un interval. Am folosit funcția R hist() pentru a reprezenta o histogramă.
Diagramele de dispersie, pe de altă parte, iau perechi de numere și le reprezintă pe două axe. Diagramele de dispersie folosesc funcția plot() și oferă doi parametri: prima și a doua variabilă de date a corelației pe care dorim să o investigăm. Astfel, cele două funcții R, hist() și plot() ne ajută să traducem seturi de numere în reprezentări vizuale semnificative.
Concluzie
După ce ne-am murdarit mâinile parcurgând întregul flux de date de import, procesare și trasare a datelor, lucrurile par mult mai clare acum. Puteți aplica același flux de date oricărui nou set de date strălucitor pe care îl veți întâlni. În cercetarea utilizatorilor, de exemplu, puteți reprezenta grafic timpul pe sarcină sau distribuția erorilor și, de asemenea, puteți reprezenta un timp pe sarcină în funcție de corelarea erorilor.
Pentru a afla mai multe despre limbajul R, Quick-R este un loc bun pentru a începe, dar ați putea lua în considerare și R Bloggeri. Pentru documentația despre pachetele R, cum ar fi dplyr , puteți vizita RDocumentation. Jocul cu date poate fi distractiv, dar este și extrem de util pentru orice designer UX într-o lume bazată pe date. Pe măsură ce mai multe date sunt colectate și utilizate pentru a informa deciziile de afaceri, există o șansă crescută pentru designeri de a lucra la vizualizarea datelor sau la produse de date, unde înțelegerea naturii datelor este esențială.