
Crearea unui serviciu Pub/Sub la nivel intern folosind Node.js și Redis
Publicat: 2022-03-10Lumea de astăzi funcționează în timp real. Fie că este vorba de tranzacționarea stocurilor sau de comandă de alimente, consumatorii de astăzi se așteaptă la rezultate imediate. De asemenea, cu toții ne așteptăm să știm lucrurile imediat, fie că este vorba de știri sau de sport. Zero, cu alte cuvinte, este noul erou.
Acest lucru se aplică și dezvoltatorilor de software - probabil unii dintre cei mai nerăbdători oameni! Înainte de a mă scufunda în povestea BrowserStack, ar fi neglijent din partea mea să nu ofer câteva informații despre Pub/Sub. Pentru cei dintre voi care sunt familiarizați cu elementele de bază, nu ezitați să săriți peste următoarele două paragrafe.
Multe aplicații de astăzi se bazează pe transferul de date în timp real. Să ne uităm mai atent la un exemplu: rețelele sociale. Precum Facebook și Twitter generează feed-uri relevante , iar tu (prin aplicația lor) le consumi și spioni prietenii tăi. Ei realizează acest lucru cu o funcție de mesagerie, în care, dacă un utilizator generează date, acestea vor fi postate pentru ca alții să le consume într-o clipă. Orice întârzieri semnificative și utilizatorii se vor plânge, utilizarea va scădea și, dacă persistă, va înceta. Mizele sunt mari, la fel și așteptările utilizatorilor. Deci, cum servicii precum WhatsApp, Facebook, TD Ameritrade, Wall Street Journal și GrubHub acceptă volume mari de transferuri de date în timp real?
Toate folosesc o arhitectură software similară la un nivel înalt numit model „Publish-Subscribe”, denumit în mod obișnuit Pub/Sub.
„În arhitectura software, publish–subscribe este un model de mesagerie în care expeditorii de mesaje, numiți editori, nu programează mesajele pentru a fi trimise direct către anumiți receptori, numiți abonați, ci, în schimb, clasifică mesajele publicate în clase fără a cunoaște care abonați, dacă oricare, poate exista. În mod similar, abonații își exprimă interesul față de una sau mai multe clase și primesc doar mesaje care prezintă interes, fără a cunoaște care editori, dacă există, există.”
— Wikipedia
Plictisit de definitie? Înapoi la povestea noastră.
La BrowserStack, toate produsele noastre acceptă (într-un fel sau altul) software-ul cu o componentă substanțială de dependență în timp real - fie că ei automatizează jurnalele de testare, capturile de ecran de browser proaspăt făcute sau streamingul mobil de 15 fps.
În astfel de cazuri, dacă un singur mesaj scade, un client poate pierde informații vitale pentru prevenirea unei erori . Prin urmare, a trebuit să ne mărim pentru cerințe variate de dimensiune a datelor. De exemplu, cu serviciile de înregistrare a dispozitivelor la un moment dat, pot fi 50 MB de date generate sub un singur mesaj. Dimensiuni ca aceasta ar putea bloca browserul. Ca să nu mai vorbim de faptul că sistemul BrowserStack ar trebui să se extindă pentru produse suplimentare în viitor.
Deoarece dimensiunea datelor pentru fiecare mesaj diferă de la câțiva octeți la până la 100 MB, aveam nevoie de o soluție scalabilă care să poată susține o multitudine de scenarii. Cu alte cuvinte, am căutat o sabie care să poată tăia toate prăjiturile. În acest articol, voi discuta de ce, cum și rezultatele construirii serviciului nostru Pub/Sub intern.
Prin prisma problemei din lumea reală a BrowserStack, veți obține o înțelegere mai profundă a cerințelor și a procesului de construire a propriului dvs. Pub/Sub .
Nevoia noastră de un serviciu Pub/Sub
BrowserStack are peste 100 de milioane de mesaje, fiecare dintre ele fiind undeva între aproximativ 2 octeți și peste 100 MB. Acestea sunt transmise în întreaga lume în orice moment, toate la viteze diferite de internet.
Cei mai mari generatori de aceste mesaje, după dimensiunea mesajului, sunt produsele noastre BrowserStack Automate. Ambele au tablouri de bord în timp real care afișează toate cererile și răspunsurile pentru fiecare comandă a unui test de utilizator. Deci, dacă cineva execută un test cu 100 de solicitări în care dimensiunea medie cerere-răspuns este de 10 octeți, acesta transmite 1×100×10 = 1000 octeți.
Acum să luăm în considerare imaginea de ansamblu, deoarece - desigur - nu rulăm doar un test pe zi. Peste aproximativ 850.000 de teste BrowserStack Automate și App Automate sunt rulate cu BrowserStack în fiecare zi. Și da, avem în medie aproximativ 235 de cereri-răspuns pe test. Deoarece utilizatorii pot face capturi de ecran sau pot cere surse de pagină în Selenium, dimensiunea medie a cererii-răspuns este de aproximativ 220 de octeți.
Deci, revenind la calculatorul nostru:
850.000×235×220 = 43.945.000.000 de octeți (aprox.) sau doar 43,945 GB pe zi
Acum să vorbim despre BrowserStack Live și App Live. Cu siguranță îl avem pe Automate ca câștigător în ceea ce privește dimensiunea datelor. Cu toate acestea, produsele Live preiau conducerea când vine vorba de numărul de mesaje transmise. Pentru fiecare test live, aproximativ 20 de mesaje sunt transmise în fiecare minut în care se întoarce. Efectuăm aproximativ 100.000 de teste live, fiecare test având o medie de aproximativ 12 minute, ceea ce înseamnă:
100.000×12×20 = 24.000.000 de mesaje pe zi
Acum, pentru partea minunată și remarcabilă: construim, rulăm și menținem aplicația pentru acest pusher numit cu 6 instanțe t1.micro de ec2. Costul rulării serviciului? Aproximativ 70 USD pe lună .
Alegerea de a construi vs. Cumpărare
În primul rând: ca startup, ca majoritatea celorlalți, am fost întotdeauna încântați să construim lucruri în interior. Dar am evaluat în continuare câteva servicii de acolo. Cerințele principale pe care le aveam au fost:
- Fiabilitate și stabilitate,
- Performanță ridicată și
- Eficiența costurilor.
Să lăsăm criteriile cost-eficiență deoparte, deoarece nu mă pot gândi la niciun serviciu extern care să costă sub 70 USD pe lună (trimite-mi pe Twitter dacă cunoști unul care o face!). Deci răspunsul nostru acolo este evident.
În ceea ce privește fiabilitatea și stabilitatea, am găsit companii care au furnizat Pub/Sub ca serviciu cu un SLA de funcționare de peste 99,9%, dar au fost atașate multe T&C. Problema nu este atât de simplă pe cât credeți, mai ales când luați în considerare vastele terenuri ale internetului deschis care se află între sistem și client. Oricine este familiarizat cu infrastructura de internet știe că conectivitatea stabilă este cea mai mare provocare. În plus, cantitatea de date trimisă depinde de trafic. De exemplu, o conductă de date care este la zero timp de un minut poate să se spargă în următorul. Serviciile care oferă o fiabilitate adecvată în astfel de momente de explozie sunt rare (Google și Amazon).
Performanța pentru proiectul nostru înseamnă obținerea și trimiterea de date către toate nodurile de ascultare la o latență aproape de zero . La BrowserStack, utilizăm servicii cloud (AWS) împreună cu găzduirea în comun. Cu toate acestea, editorii și/sau abonații noștri ar putea fi plasați oriunde. De exemplu, poate implica un server de aplicații AWS care generează date de jurnal foarte necesare sau terminale (mașini la care utilizatorii se pot conecta în siguranță pentru testare). Revenind la problema Internetului deschis, dacă ar fi să ne reducem riscul, ar trebui să ne asigurăm că Pub/Sub-ul nostru folosește cele mai bune servicii de gazdă și AWS.
O altă cerință esențială a fost capacitatea de a transmite toate tipurile de date (octeți, text, date media ciudate etc.). Cu toate acestea, nu avea sens să ne bazăm pe o soluție terță parte pentru a ne susține produsele. La rândul nostru, am decis să ne reînvie spiritul de startup, suflecându-ne mânecile pentru a ne codifica propria soluție.

Construirea soluției noastre
Pub/Sub prin design înseamnă că va exista un editor care va genera și trimite date, iar un Abonat care le va accepta și le va procesa. Acest lucru este similar cu un radio: un canal de radio difuzează (publică) conținut peste tot într-un interval. În calitate de abonat, puteți decide dacă să vă conectați la acel canal și să ascultați (sau să vă opriți complet radioul).
Spre deosebire de analogia radio, în care datele sunt gratuite pentru toți și oricine poate decide să se acorde, în scenariul nostru digital avem nevoie de autentificare, ceea ce înseamnă că datele generate de editor ar putea fi doar pentru un anumit client sau abonat.
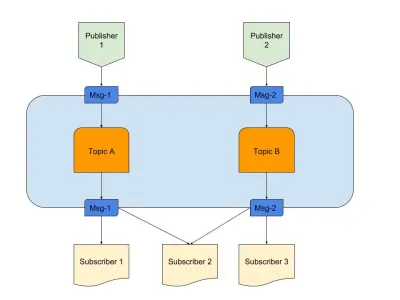
Mai sus este o diagramă care oferă un exemplu de Pub/Sub bun cu:
- Editorii
Aici avem doi editori care generează mesaje bazate pe o logică predefinită. În analogia noastră radio, aceștia sunt jocheii noștri radio care creează conținutul. - Subiecte
Sunt două aici, adică există două tipuri de date. Putem spune că acestea sunt canalele noastre de radio 1 și 2. - Abonați
Avem trei care citesc fiecare date despre un anumit subiect. Un lucru de observat este că Abonatul 2 citește din mai multe subiecte. În analogia noastră radio, aceștia sunt oamenii care sunt reglați pe un canal de radio.
Să începem să înțelegem cerințele necesare pentru serviciu.
- O componentă cu evenimente
Acest lucru se activează numai atunci când există ceva de pus. - Stocare tranzitorie
Acest lucru păstrează datele persistente pentru o perioadă scurtă de timp, astfel încât, dacă abonatul este lent, mai are o fereastră pentru a le consuma. - Reducerea latenței
Conectarea a două entități printr-o rețea cu hopuri și distanță minime.
Am ales o stivă de tehnologie care a îndeplinit cerințele de mai sus:
- Node.js
Pentru că de ce nu? Eventual, nu am avea nevoie de procesare grea a datelor, plus că este ușor de integrat. - Redis
Acceptă date perfect de scurtă durată. Are toate capabilitățile de a iniția, actualiza și expira automat. De asemenea, solicită mai puțină sarcină aplicației.
Node.js pentru conectivitate logică de afaceri
Node.js este un limbaj aproape perfect atunci când vine vorba de scrierea de cod care încorporează IO și evenimente. Problema noastră specială a avut ambele, făcând această opțiune cea mai practică pentru nevoile noastre.
Cu siguranță alte limbaje precum Java ar putea fi mai optimizate, sau un limbaj precum Python oferă scalabilitate. Cu toate acestea, costul începerii cu aceste limbi este atât de mare încât un dezvoltator ar putea termina scrierea codului în Node în aceeași durată.
Sincer să fiu, dacă serviciul ar fi avut șansa de a adăuga funcții mai complicate, am fi putut să ne uităm la alte limbi sau la o stivă completă. Dar aici este o căsătorie făcută în rai. Iată pachetul nostru.json :
{ "name": "Pusher", "version": "1.0.0", "dependencies": { "bstack-analytics": "*****", // Hidden for BrowserStack reasons. :) "ioredis": "^2.5.0", "socket.io": "^1.4.4" }, "devDependencies": {}, "scripts": { "start": "node server.js" } }Foarte simplu spus, credem în minimalism, mai ales când vine vorba de scrierea codului. Pe de altă parte, am fi putut folosi biblioteci precum Express pentru a scrie cod extensibil pentru acest proiect. Cu toate acestea, instinctele noastre de startup au decis să transmită acest lucru și să-l păstreze pentru următorul proiect. Instrumente suplimentare pe care le-am folosit:
- ioredis
Aceasta este una dintre cele mai acceptate biblioteci pentru conectivitatea Redis cu Node.js folosită de companii, inclusiv Alibaba. - socket.io
Cea mai bună bibliotecă pentru conectivitate grațioasă și alternativă cu WebSocket și HTTP.
Redis pentru stocare tranzitorie
Redis, ca serviciu, este foarte fiabil și configurabil. În plus, există mulți furnizori de servicii gestionate de încredere pentru Redis, inclusiv AWS. Chiar dacă nu doriți să utilizați un furnizor, Redis este ușor de început.
Să defalcăm partea configurabilă. Am început cu configurația obișnuită master-slave, dar Redis vine și cu moduri cluster sau sentinelă. Fiecare mod are propriile sale avantaje.
Dacă am putea partaja datele într-un fel, un cluster Redis ar fi cea mai bună alegere. Dar dacă am partajat datele prin orice euristică, avem mai puțină flexibilitate, deoarece euristica trebuie urmărită în . Mai puține reguli, mai mult control este bine pentru viață!
Redis Sentinel funcționează cel mai bine pentru noi, deoarece căutarea datelor se face într-un singur nod, conectându-se la un moment dat în timp, în timp ce datele nu sunt fragmentate. Aceasta înseamnă, de asemenea, că, chiar dacă se pierd mai multe noduri, datele sunt încă distribuite și prezente în alte noduri. Deci ai mai mult HA și mai puține șanse de pierdere. Desigur, acest lucru i-a eliminat pe profesioniști de la a avea un cluster, dar cazul nostru de utilizare este diferit.
Arhitectură la 30000 de picioare
Diagrama de mai jos oferă o imagine la nivel foarte înalt a modului în care funcționează tablourile de bord Automate și App Automate. Vă amintiți sistemul în timp real pe care îl aveam din secțiunea anterioară?
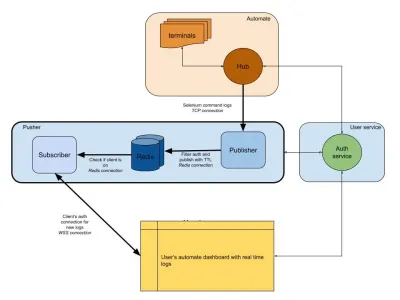
În diagrama noastră, fluxul nostru principal de lucru este evidențiat cu margini mai groase. Secțiunea „automatizare” constă din:
- Terminale
Compus din versiunile originale de Windows, OSX, Android sau iOS pe care le obțineți în timp ce testați pe BrowserStack. - Hub
Punctul de contact pentru toate testele dvs. Selenium și Appium cu BrowserStack.
Secțiunea „Servicii pentru utilizatori” de aici este gardianul nostru, asigurându-se că datele sunt trimise și salvate pentru persoana potrivită. Este și gardianul nostru de securitate. Secțiunea „împingere” încorporează miezul a ceea ce am discutat în acest articol. Este format din suspecții obișnuiți, inclusiv:
- Redis
Stocarea noastră tranzitorie pentru mesaje, unde, în cazul nostru, jurnalele automatizate sunt stocate temporar. - Editor
Aceasta este practic entitatea care obține date de la hub. Toate răspunsurile la cerere sunt capturate de această componentă care scrie în Redis cusession_idca canal. - Abonat
Aceasta citește datele de la Redis generate pentrusession_id. Este, de asemenea, serverul web pentru clienții care se conectează prin WebSocket (sau HTTP) pentru a obține date și apoi le trimite clienților autentificați.
În cele din urmă, avem secțiunea de browser a utilizatorului, reprezentând o conexiune WebSocket autentificată pentru a ne asigura că sunt trimise jurnalele session_id . Acest lucru permite JS front-end să îl analizeze și să îl înfrumusețeze pentru utilizatori.
Similar cu serviciul de jurnal, avem aici un pusher care este folosit pentru alte integrări de produse. În loc de session_id , folosim o altă formă de ID pentru a reprezenta acel canal. Toate acestea funcționează din împingător!
Concluzie (TLDR)
Am avut un succes considerabil în construirea Pub/Sub. Pentru a rezuma de ce l-am construit intern:
- Se cântărește mai bine pentru nevoile noastre;
- Mai ieftin decât serviciile externalizate;
- Control total asupra arhitecturii generale.
Ca să nu mai vorbim că JS se potrivește perfect pentru acest tip de scenariu. Bucla de evenimente și cantitatea masivă de IO este ceea ce are nevoie problema! JavaScript este magia unui singur pseudo thread.
Evenimentele și Redis ca sistem simplifică lucrurile pentru dezvoltatori, deoarece puteți obține date dintr-o sursă și le puteți împinge în alta prin Redis. Așa că l-am construit.
Dacă utilizarea se încadrează în sistemul dvs., vă recomand să faceți același lucru!