
Regresia polinomială: importanță, implementare pas cu pas
Publicat: 2021-01-29Cuprins
Introducere
În acest vast domeniu al Machine Learning, care ar fi primul algoritm pe care majoritatea dintre noi l-am fi studiat? Da, este regresia liniară. Fiind în mare parte primul program și algoritm pe care cineva l-ar fi învățat în primele zile de programare de învățare automată, regresia liniară are propria importanță și putere cu un tip de date liniar.
Ce se întâmplă dacă setul de date pe care îl întâlnim nu este separabil liniar? Ce se întâmplă dacă modelul de regresie liniară nu este capabil să derive vreun fel de relație între variabilele independente și dependente?
Există un alt tip de regresie cunoscut sub numele de regresie polinomială. Adevărat numelui său, regresia polinomială este un algoritm de regresie care modelează relația dintre variabila dependentă (y) și variabila independentă (x) ca un polinom de gradul al n-lea. În acest articol, vom înțelege algoritmul și matematica din spatele regresiei polinomiale împreună cu implementarea sa în Python.
Ce este regresia polinomială?
După cum a fost definit mai devreme, regresia polinomială este un caz special de regresie liniară în care o ecuație polinomială cu un grad specificat (n) se potrivește datelor neliniare care formează o relație curbilinie între variabilele dependente și independente.
y= b 0 +b 1 x 1 + b 2 x 1 2 + b 3 x 1 3 +…… b n x 1 n
Aici,

y este variabila dependentă (variabila de ieșire)
x1 este variabila independentă (predictori)
b 0 este părtinirea
b 1 , b 2 , ….b n sunt ponderile din ecuația de regresie.
Pe măsură ce gradul ecuației polinomiale ( n ) devine mai mare, ecuația polinomială devine mai complicată și există posibilitatea ca modelul să aibă tendința de a se supraadapta, ceea ce va fi discutat în partea ulterioară.
Compararea ecuațiilor de regresie
Regresie liniară simplă ===> y= b0+b1x
Regresie liniară multiplă ===> y= b0+b1x1+ b2x2+ b3x3+…… bnxn
Regresie polinomială ===> y= b0+b1x1+ b2x12+ b3x13+…… bnx1n
Din cele trei ecuații de mai sus, vedem că există mai multe diferențe subtile în ele. Regresia liniară simplă și multiplă sunt diferite de ecuația regresiei polinomiale prin faptul că are un grad de numai 1. Regresia liniară multiplă constă din mai multe variabile x1, x2 și așa mai departe. Deși ecuația de regresie polinomială are o singură variabilă x1, are un grad n care o diferențiază de celelalte două.
Nevoia de regresie polinomială
Din diagramele de mai jos putem vedea că în prima diagramă, se încearcă să se potrivească o linie liniară pe setul dat de puncte de date neliniare. Se înțelege că devine foarte dificil ca o linie dreaptă să formeze o relație cu aceste date neliniare. Din acest motiv, atunci când antrenăm modelul, funcția de pierdere crește, provocând eroarea mare.
Pe de altă parte, atunci când aplicăm regresia polinomială, este clar că linia se potrivește bine pe punctele de date. Aceasta înseamnă că ecuația polinomială care se potrivește cu punctele de date derivă un fel de relație între variabilele din setul de date. Astfel, pentru astfel de cazuri în care punctele de date sunt aranjate într-o manieră neliniară, avem nevoie de modelul de regresie polinomială.
Implementarea regresiei polinomiale în Python
De aici, vom construi un model de învățare automată în Python, implementând regresia polinomială. Vom compara rezultatele obținute cu regresia liniară și regresia polinomială. Să înțelegem mai întâi problema pe care o vom rezolva cu regresia polinomială.
Descrierea problemei
În acest sens, luați în considerare cazul unui Start-up care dorește să angajeze mai mulți candidați dintr-o companie. Există diferite locuri de muncă pentru diferite posturi în companie. Start-up-ul are detalii despre salariul pentru fiecare rol din compania anterioară. Astfel, atunci când un candidat își menționează salariul anterior, HR-ul start-up-ului trebuie să îl verifice cu datele existente. Astfel, avem două variabile independente care sunt Poziția și Nivelul. Variabila dependentă (ieșire) este Salariul care trebuie prezis utilizând regresia polinomială.
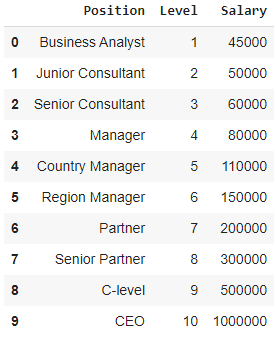
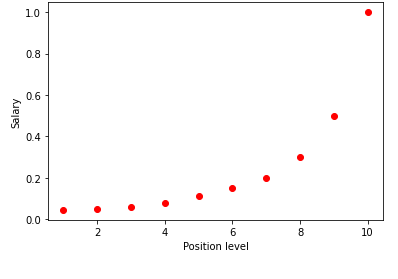
La vizualizarea tabelului de mai sus într-un grafic, vedem că datele sunt de natură neliniară. Cu alte cuvinte, pe măsură ce nivelul crește, salariul crește la o rată mai mare, oferindu-ne astfel o curbă așa cum se arată mai jos.
Pasul 1: Preprocesarea datelorPrimul pas în construirea oricărui model de învățare automată este să importați bibliotecile. Aici, avem doar trei biblioteci de bază de importat. După aceasta, setul de date este importat din depozitul meu GitHub și sunt atribuite variabilele dependente și variabilele independente. Variabilele independente sunt stocate în variabila X, iar variabila dependentă este stocată în variabila y.
import numpy ca np
import matplotlib.pyplot ca plt
importa panda ca pd
set de date = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalaries_Data.csv')
X = set de date.iloc[:, 1:-1].valori
y = set de date.iloc[:, -1].valori
Aici, în termenul [:, 1:-1], primele două puncte reprezintă faptul că toate rândurile trebuie luate, iar termenul 1:-1 indică faptul că coloanele care trebuie incluse sunt de la prima coloană la penultima coloană, care este dată de -1.
Pasul 2: Modelul de regresie liniarăÎn pasul următor, vom construi un model de regresie liniară multiplă și îl vom folosi pentru a prezice datele salariale din variabilele independente. Pentru aceasta, clasa LinearRegression este importată din biblioteca sklearn. Acesta este apoi ajustat pe variabilele X și y în scopuri de instruire.

din sklearn.linear_model import LinearRegression
regresor = LinearRegression()
regresor.fit(X, y)
Odată construit modelul, la vizualizarea rezultatelor, obținem următorul grafic.
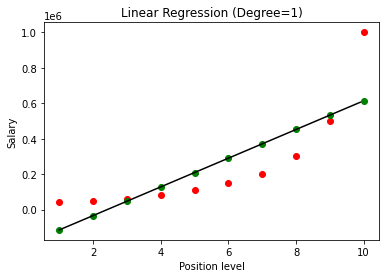
După cum se vede în mod clar, încercând să potriviți o linie dreaptă pe un set de date neliniar, nu există nicio relație care să fie derivată de modelul de învățare automată. Astfel, trebuie să alegem regresia polinomială pentru a obține o relație între variabile.
Pasul 3: Modelul de regresie polinomialăÎn acest pas următor, vom potrivi un model de regresie polinomială pe acest set de date și vom vizualiza rezultatele. Pentru aceasta, importăm o altă clasă din modulul sklearn numit PolynomialFeatures în care dăm gradul ecuației polinomiale de construit. Apoi clasa LinearRegression este folosită pentru a potrivi ecuația polinomială la setul de date.
din sklearn.preprocessing import PolynomialFeatures
din sklearn.linear_model import LinearRegression
poly_reg = PolinomialFeatures(grad = 2)
X_poly = poly_reg.fit_transform(X)
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
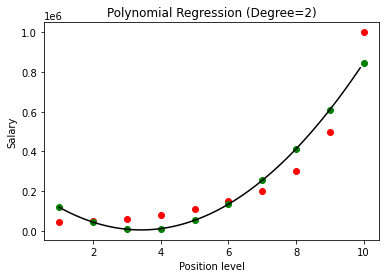
În cazul de mai sus, am dat ca gradul ecuației polinomiale să fie egal cu 2. La trasarea graficului, vedem că există un fel de curbă care este derivată, dar există totuși o mare abatere de la datele reale (în roșu ) și punctele curbei prezise (în verde). Astfel, în pasul următor vom crește gradul polinomului la numere mai mari, cum ar fi 3 și 4 și apoi îl vom compara unul cu celălalt.
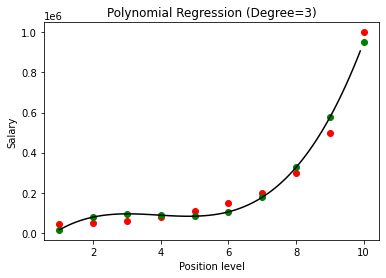
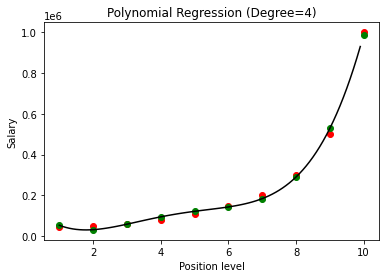
Comparând rezultatele regresiei polinomiale cu gradele 3 și 4, vedem că pe măsură ce gradul crește, modelul se antrenează bine cu datele. Astfel, putem deduce că un grad mai mare permite ecuației polinomiale să se potrivească mai precis pe datele de antrenament. Cu toate acestea, acesta este cazul perfect de supraadaptare. Astfel, devine important să alegeți valoarea lui n tocmai pentru a preveni supraadaptarea.
Ce este supraajustarea?
După cum spune și numele, supraadaptarea este denumită o situație în statistici când o funcție (sau un model de învățare automată în acest caz) se potrivește prea mult cu un set de puncte de date limitate. Acest lucru face ca funcția să funcționeze slab cu punctele de date noi.
În învățarea automată, dacă se spune că un model este supraadaptat la un anumit set de puncte de date de antrenament, atunci când același model este introdus într-un set complet nou de puncte (să zicem setul de date de testare), atunci are performanțe foarte proaste pe el, deoarece modelul de supraadaptare nu s-a generalizat bine cu datele și este doar supraadaptat la punctele de date de antrenament.
În regresia polinomială, există o șansă bună ca modelul să fie supraadaptat pe datele de antrenament, pe măsură ce gradul polinomului crește. În exemplul prezentat mai sus, vedem un caz tipic de supraadaptare în regresia polinomială care poate fi corectat doar cu o bază de încercare și eroare pentru alegerea valorii optime a gradului.
Citește și: Idei de proiecte de învățare automată
Concluzie
În concluzie, regresia polinomială este utilizată în multe situații în care există o relație neliniară între variabilele dependente și independente. Deși acest algoritm suferă de sensibilitate față de valori aberante, poate fi corectat tratându-le înainte de ajustarea liniei de regresie. Astfel, în acest articol, am fost introduși în conceptul de regresie polinomială împreună cu un exemplu de implementare a acestuia în programarea Python pe un set de date simplu.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de formare riguroasă, peste 30 de studii de caz și sarcini, IIIT- B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Învață cursul ML de la cele mai bune universități din lume. Câștigă programe de master, Executive PGP sau Advanced Certificate pentru a-ți accelera cariera.
Ce vrei să spui prin regresie liniară?
Regresia liniară este un tip de analiză numerică predictivă prin care putem afla valoarea unei variabile necunoscute cu ajutorul unei variabile dependente. De asemenea, explică legătura dintre o variabilă dependentă și una sau mai multe variabile independente. Regresia liniară este o tehnică statistică pentru a demonstra o legătură între două variabile. Regresia liniară trasează o linie de tendință dintr-un set de puncte de date. Regresia liniară poate fi folosită pentru a genera un model de predicție din date aparent aleatorii, cum ar fi diagnosticele de cancer sau prețurile acțiunilor. Există mai multe metode de calculare a regresiei liniare. Abordarea obișnuită a celor mai mici pătrate, care estimează variabile necunoscute în date și transformă vizual în suma distanțelor verticale dintre punctele de date și linia de tendință, este una dintre cele mai răspândite.
Care sunt unele dintre dezavantajele regresiei liniare?
În cele mai multe cazuri, analiza de regresie este utilizată în cercetare pentru a stabili că există o legătură între variabile. Cu toate acestea, corelația nu implică cauzalitate, deoarece o legătură între două variabile nu implică faptul că una o determină să se întâmple pe cealaltă. Chiar și o linie dintr-o regresie liniară de bază care se potrivește bine punctelor de date poate să nu asigure o relație între circumstanțe și rezultate logice. Folosind un model de regresie liniară, puteți determina dacă există sau nu vreo corelație între variabile. Vor fi necesare investigații suplimentare și analize statistice pentru a determina natura exactă a legăturii și dacă o variabilă o provoacă pe cealaltă.
Care sunt ipotezele de bază ale regresiei liniare?
În regresia liniară, există trei ipoteze cheie. Variabilele dependente și independente trebuie, în primul rând, să aibă o legătură liniară. Pentru a verifica această relație este utilizat un grafic de dispersie al variabilelor dependente și independente. În al doilea rând, ar trebui să existe o multi-colinearitate minimă sau zero între variabilele independente din setul de date. Aceasta implică faptul că variabilele independente nu sunt legate. Valoarea trebuie să fie limitată, ceea ce este determinat de cerința domeniului. Homoscedasticitatea este al treilea factor. Ipoteza că erorile sunt distribuite uniform este una dintre cele mai esențiale ipoteze.