
Menținerea rapidă a Node.js: instrumente, tehnici și sfaturi pentru realizarea de servere Node.js de înaltă performanță
Publicat: 2022-03-10Dacă ați construit ceva cu Node.js destul de mult, atunci fără îndoială ați experimentat durerea problemelor neașteptate de viteză. JavaScript este un limbaj asincron cu evenimente. Acest lucru poate face dificilă raționamentul despre performanță, așa cum va deveni evident. Popularitatea crescândă a Node.js a expus nevoia de instrumente, tehnici și gândire potrivite constrângerilor JavaScript de pe server.
Când vine vorba de performanță, ceea ce funcționează în browser nu se potrivește neapărat cu Node.js. Deci, cum ne asigurăm că implementarea Node.js este rapidă și potrivită scopului? Să trecem printr-un exemplu practic.
Instrumente
Node este o platformă foarte versatilă, dar una dintre aplicațiile predominante este crearea de procese în rețea. Ne vom concentra pe profilarea celor mai comune dintre acestea: serverele web HTTP.
Vom avea nevoie de un instrument care poate exploda un server cu o mulțime de solicitări în timp ce măsoară performanța. De exemplu, putem folosi AutoCannon:
npm install -g autocannonAlte instrumente bune de evaluare comparativă HTTP includ Apache Bench (ab) și wrk2, dar AutoCannon este scris în Node, oferă o presiune de încărcare similară (sau uneori mai mare) și este foarte ușor de instalat pe Windows, Linux și Mac OS X.
După ce am stabilit o măsurare a performanței de bază, dacă decidem că procesul nostru ar putea fi mai rapid, vom avea nevoie de o modalitate de a diagnostica problemele cu procesul. Un instrument excelent pentru diagnosticarea diferitelor probleme de performanță este Node Clinic, care poate fi instalat și cu npm:
npm install -g clinicAceasta instalează de fapt o suită de instrumente. Vom folosi Clinic Doctor și Clinic Flame (un înveliș în jurul valorii de 0x) pe măsură ce mergem.
Notă : Pentru acest exemplu practic, vom avea nevoie de Node 8.11.2 sau mai mare.
Codul
Cazul nostru exemplu este un server REST simplu cu o singură resursă: o sarcină utilă JSON mare expusă ca o rută GET la /seed/v1 . Serverul este un folder de app care constă dintr-un fișier package.json (în funcție de restify 7.1.0 ), un fișier index.js și un fișier util.js.
Fișierul index.js pentru serverul nostru arată astfel:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) Acest server este reprezentativ pentru cazul obișnuit de servire a conținutului dinamic stocat în cache de client. Acest lucru se realizează cu middleware-ul etagger , care calculează un antet ETag pentru cea mai recentă stare a conținutului.
Fișierul util.js oferă piese de implementare care ar fi utilizate în mod obișnuit într-un astfel de scenariu, o funcție pentru a prelua conținutul relevant dintr-un backend, middleware-ul etag și o funcție de marcare temporală care furnizează marcaje temporale minut cu minut:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }În niciun caz, nu luați acest cod ca exemplu de bune practici! Există mai multe mirosuri de cod în acest fișier, dar le vom localiza pe măsură ce măsurăm și profilăm aplicația.
Pentru a obține sursa completă pentru punctul nostru de plecare, serverul lent poate fi găsit aici.
Profilare
Pentru profilare avem nevoie de două terminale, unul pentru pornirea aplicației, iar celălalt pentru testarea acesteia.
Într-un terminal, în cadrul app , folderul putem rula:
node index.jsÎntr-un alt terminal îl putem profila astfel:
autocannon -c100 localhost:3000/seed/v1Acest lucru va deschide 100 de conexiuni simultane și va bombarda serverul cu solicitări timp de zece secunde.
Rezultatele ar trebui să fie similare cu următoarele (test de rulare 10s @ https://localhost:3000/seed/v1 — 100 de conexiuni):
| Stat | Mediu | Stdev | Max |
|---|---|---|---|
| Latență (ms) | 3086,81 | 1725,2 | 5554 |
| Req/Sec | 23.1 | 19.18 | 65 |
| octeți/sec | 237,98 kB | 197,7 kB | 688,13 kB |
Rezultatele vor varia în funcție de mașină. Cu toate acestea, având în vedere că un server Node.js „Hello World” este ușor capabil de treizeci de mii de solicitări pe secundă pe acea mașină care a produs aceste rezultate, 23 de solicitări pe secundă cu o latență medie de peste 3 secunde este dezastruos.
Diagnosticarea
Descoperirea zonei cu probleme
Putem diagnostica aplicația cu o singură comandă, datorită comenzii Clinic Doctor –on-port. În folderul app rulăm:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsAcest lucru va crea un fișier HTML care se va deschide automat în browserul nostru când profilarea este finalizată.
Rezultatele ar trebui să arate cam așa:
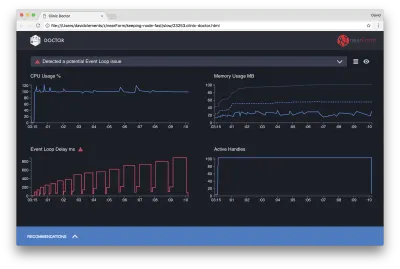
Doctorul ne spune că probabil am avut o problemă cu bucla de evenimente.
Împreună cu mesajul din partea de sus a interfeței de utilizare, putem vedea, de asemenea, că diagrama Buclă de evenimente este roșie și arată o întârziere în continuă creștere. Înainte de a aprofunda ce înseamnă acest lucru, să înțelegem mai întâi efectul pe care problema diagnosticată îl are asupra celorlalte valori.
Putem vedea că CPU este în mod constant la sau peste 100%, deoarece procesul lucrează din greu pentru a procesa cererile din coadă. Motorul JavaScript al Node (V8) folosește de fapt două nuclee CPU în acest caz, deoarece mașina este multi-core și V8 utilizează două fire. Unul pentru bucla de evenimente și celălalt pentru Garbage Collection. Când vedem că CPU crește cu până la 120% în unele cazuri, procesul colectează obiecte legate de solicitările gestionate.
Vedem acest lucru corelat în graficul Memory. Linia continuă din diagrama Memorie este valoarea Heap Used. De fiecare dată când există o creștere a CPU, vedem o scădere a liniei Heap Used, care arată că memoria este dealocată.
Handlele active nu sunt afectate de întârzierea buclei de evenimente. Un mâner activ este un obiect care reprezintă fie I/O (cum ar fi un socket sau mâner de fișier), fie un temporizator (cum ar fi un setInterval ). Am instruit AutoCannon să deschidă 100 de conexiuni ( -c100 ). Mânerele active rămân un număr constant de 103. Celelalte trei sunt mânere pentru STDOUT, STDERR și mânerul pentru serverul însuși.
Dacă facem clic pe panoul Recomandări din partea de jos a ecranului, ar trebui să vedem ceva de genul următor:
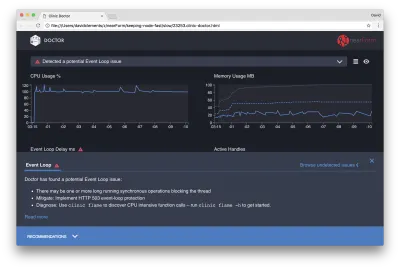
Atenuare pe termen scurt
Analiza cauzei principale a problemelor grave de performanță poate dura timp. În cazul unui proiect implementat în direct, merită să adăugați protecție la supraîncărcare serverelor sau serviciilor. Ideea protecției la suprasarcină este de a monitoriza întârzierea buclei de evenimente (printre altele) și de a răspunde cu „503 Service Unavailable” dacă este depășit un prag. Acest lucru permite unui echilibrator de încărcare să treacă la alte instanțe sau, în cel mai rău caz, înseamnă că utilizatorii vor trebui să se reîmprospăteze. Modulul de protecție împotriva supraîncărcării poate oferi acest lucru cu o supraîncărcare minimă pentru Express, Koa și Restify. Cadrul Hapi are o setare de configurare a încărcării care oferă aceeași protecție.
Înțelegerea zonei cu probleme
După cum explică scurta explicație din Clinic Doctor, dacă bucla de evenimente este întârziată la nivelul pe care îl observăm, este foarte probabil ca una sau mai multe funcții să „blocheze” bucla de evenimente.
Cu Node.js, este deosebit de important să recunoaștem această caracteristică JavaScript primară: evenimentele asincrone nu pot avea loc până când codul în curs de execuție nu este finalizat.
Acesta este motivul pentru care un setTimeout nu poate fi precis.
De exemplu, încercați să rulați următoarele în DevTools sau în Node REPL al unui browser:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() Măsurarea timpului rezultată nu va fi niciodată de 100 ms. Probabil va fi în intervalul de la 150 ms la 250 ms. setTimeout a programat o operație asincronă ( console.timeEnd ), dar codul care se execută în prezent nu a fost încă finalizat; mai sunt două rânduri. Codul care se execută în prezent este cunoscut sub numele de „bifă”. Pentru ca bifa să se completeze, Math.random trebuie apelat de zece milioane de ori. Dacă acest lucru durează 100 ms, atunci timpul total înainte de a se rezolva timeout-ul va fi de 200 ms (plus oricât de mult îi ia funcției setTimeout pentru a pune în coadă timeout-ul în prealabil, de obicei câteva milisecunde).
Într-un context de pe partea serverului, dacă o operațiune din bifa curentă durează mult timp pentru a finaliza, cererile nu pot fi gestionate, iar preluarea datelor nu poate avea loc deoarece codul asincron nu va fi executat până la finalizarea bifului curent. Aceasta înseamnă că codul costisitor din punct de vedere computațional va încetini toate interacțiunile cu serverul. Prin urmare, este recomandat să împărțiți munca intensă a resurselor în procese separate și să le apelați de pe serverul principal, acest lucru va evita cazurile în care pe ruta rar folosită, dar scumpă, încetinește performanța altor rute utilizate frecvent, dar ieftine.
Serverul de exemplu are un cod care blochează bucla de evenimente, așa că următorul pas este localizarea codului respectiv.
Analizand
O modalitate de a identifica rapid codul cu performanțe slabe este crearea și analizarea unui grafic de flacără. Un grafic de flacără reprezintă apelurile de funcții ca blocuri așezate unul peste celălalt - nu în timp, ci în ansamblu. Motivul pentru care se numește „grafic de flacără” este că folosește în mod obișnuit o schemă de culori portocalie spre roșu, unde cu cât un bloc este mai roșu, cu atât o funcție este mai „fierbinte”, adică cu atât este mai probabil să blocheze bucla de evenimente. Captarea datelor pentru un grafic de flacără se realizează prin eșantionarea procesorului - ceea ce înseamnă că este luată un instantaneu al funcției care este în curs de executare și al stivei sale. Căldura este determinată de procentul de timp în timpul profilării în care o anumită funcție se află în partea de sus a stivei (de exemplu, funcția în curs de executare) pentru fiecare probă. Dacă nu este ultima funcție care a fost apelată vreodată în acea stivă, atunci este probabil să blocheze bucla de evenimente.
Să folosim clinic flame pentru a genera un grafic de flacără al aplicației exemplu:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsRezultatul ar trebui să se deschidă în browserul nostru cu ceva de genul următor:
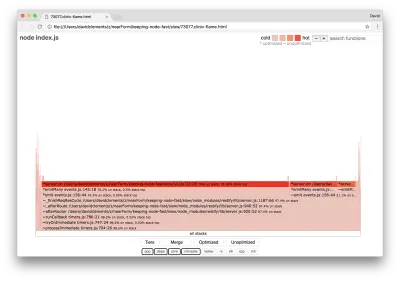
Lățimea unui bloc reprezintă cât timp a petrecut pe CPU în general. Se pot observa trei stive principale care ocupă cel mai mult timp, toate evidențiind server.on drept cea mai tare funcție. De fapt, toate cele trei stive sunt la fel. Acestea diferă deoarece în timpul profilării funcțiile optimizate și neoptimizate sunt tratate ca cadre de apel separate. Funcțiile prefixate cu un * sunt optimizate de motorul JavaScript, iar cele prefixate cu un ~ sunt neoptimizate. Dacă starea optimizată nu este importantă pentru noi, putem simplifica și mai mult graficul apăsând butonul Merge. Acest lucru ar trebui să conducă la o vedere similară cu următoarea:
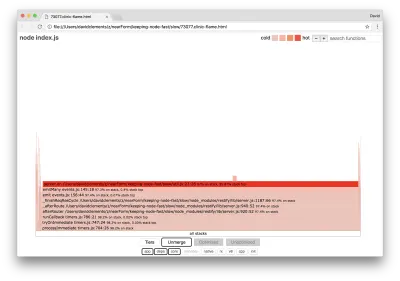
De la început, putem deduce că codul ofensator se află în fișierul util.js al codului aplicației.
Funcția slow este, de asemenea, un handler de evenimente: funcțiile care conduc la funcție fac parte din modulul de events de bază, iar server.on este un nume alternativ pentru o funcție anonimă furnizată ca funcție de gestionare a evenimentelor. De asemenea, putem vedea că acest cod nu este în aceeași bifă cu codul care se ocupă de fapt de cerere. Dacă ar fi, funcțiile din modulele de bază http , net și stream ar fi în stivă.
Astfel de funcții de bază pot fi găsite prin extinderea altor părți, mult mai mici, ale graficului flăcării. De exemplu, încercați să utilizați intrarea de căutare din partea dreaptă sus a interfeței de utilizare pentru a căuta send (numele ambelor metode interne restify și http ). Ar trebui să fie în partea dreaptă a graficului (funcțiile sunt sortate alfabetic):
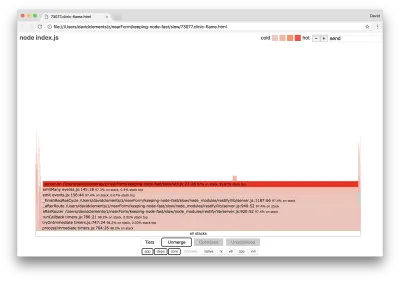
Observați cât de mici sunt comparativ toate blocurile de manipulare HTTP reale.

Putem face clic pe unul dintre blocurile evidențiate cu cyan, care se va extinde pentru a afișa funcții precum writeHead și write în fișierul http_outgoing.js (parte a bibliotecii http de bază Node):
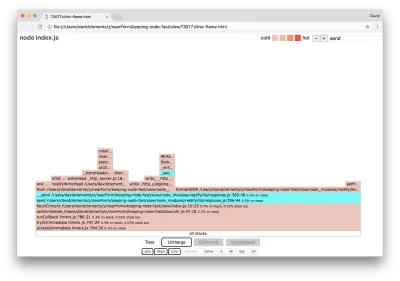
Putem face clic pe toate stivele pentru a reveni la vizualizarea principală.
Punctul cheie aici este că, deși funcția server.on nu este în aceeași bifă cu codul real de gestionare a cererilor, încă afectează performanța generală a serverului prin întârzierea execuției unui cod altfel performant.
Depanare
Din graficul flacără știm că funcția problematică este handlerul de evenimente transmis către server.on în fișierul util.js.
Hai să aruncăm o privire:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) Este bine cunoscut faptul că criptografia tinde să fie costisitoare, la fel ca serializarea ( JSON.stringify ), dar de ce nu apar în graficul flăcării? Aceste operațiuni sunt în mostrele capturate, dar sunt ascunse în spatele filtrului cpp . Dacă apăsăm butonul cpp , ar trebui să vedem ceva de genul următor:
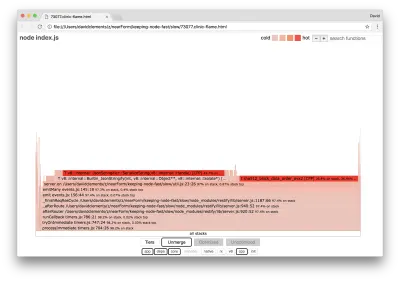
Instrucțiunile interne V8 legate atât de serializare, cât și de criptare sunt acum afișate ca cele mai bune stive și ca ocupă cea mai mare parte a timpului. Metoda JSON.stringify apelează direct codul C++; Acesta este motivul pentru care nu vedem o funcție JavaScript. În cazul criptografiei, funcții precum createHash și update sunt în date, dar sunt fie aliniate (ceea ce înseamnă că dispar în vizualizarea îmbinată) sau prea mici pentru a fi redate.
Odată ce începem să raționăm despre codul din funcția etagger , poate deveni rapid evident că este prost proiectat. De ce luăm instanța server din contextul funcției? Au loc multe hashing, sunt toate acestea necesare? De asemenea, nu există suport pentru antetul If-None-Match în implementare, ceea ce ar atenua o parte din încărcarea în unele scenarii din lumea reală, deoarece clienții ar face doar o solicitare principală pentru a determina prospețimea.
Să ignorăm toate aceste puncte pentru moment și să validăm constatarea că munca efectivă efectuată în server.on este într-adevăr blocajul. Acest lucru poate fi realizat prin setarea codului server.on la o funcție goală și prin generarea unui nou flamegraph.
Modificați funcția etagger la următoarele:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } Funcția de ascultare a evenimentelor transmisă server.on este acum o opțiune fără opțiune.
Să rulăm din nou clinic flame :
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsAceasta ar trebui să producă un grafic al flăcării similar cu următorul:
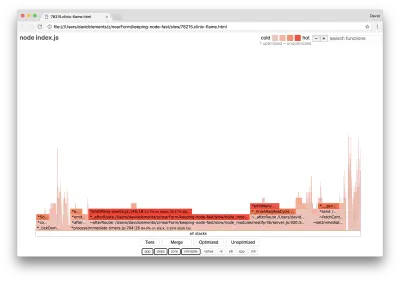
Acest lucru arată mai bine și ar fi trebuit să observăm o creștere a cererii pe secundă. Dar de ce este atât de fierbinte codul care emite evenimentul? Ne-am aștepta în acest moment ca codul de procesare HTTP să ocupe cea mai mare parte a timpului CPU, nu se execută nimic în evenimentul server.on .
Acest tip de blocaj este cauzat de o funcție care este executată mai mult decât ar trebui.
Următorul cod suspect din partea de sus a util.js poate fi un indiciu:
require('events').defaultMaxListeners = Infinity Să eliminăm această linie și să începem procesul nostru cu --trace-warnings :
node --trace-warnings index.jsDacă facem profil cu AutoCannon în alt terminal, așa:
autocannon -c100 localhost:3000/seed/v1Procesul nostru va scoate ceva similar cu:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node ne spune că o mulțime de evenimente sunt atașate obiectului server . Acest lucru este ciudat, deoarece există un boolean care verifică dacă evenimentul a fost atașat și apoi revine devreme, în esență, făcând attachAfterEvent un nu-op după ce primul eveniment este atașat.
Să aruncăm o privire la funcția attachAfterEvent :
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } Verificarea condiționată este greșită! Verifică dacă attachAfterEvent este adevărat în loc de afterEventAttached . Aceasta înseamnă că un nou eveniment este atașat instanței de server la fiecare solicitare și apoi toate evenimentele atașate anterioare sunt declanșate după fiecare solicitare. Hopa!
Optimizarea
Acum că am descoperit zonele cu probleme, să vedem dacă putem face serverul mai rapid.
Fructe cu agățare joasă
Să punem înapoi codul de ascultător server.on (în loc de o funcție goală) și să folosim numele boolean corect în verificarea condiționată. Funcția noastră etagger arată după cum urmează:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }Acum ne verificăm soluția prin profilare din nou. Porniți serverul într-un singur terminal:
node index.jsApoi profilați cu AutoCannon:
autocannon -c100 localhost:3000/seed/v1 Ar trebui să vedem rezultate undeva în intervalul unei îmbunătățiri de 200 de ori (test de rulare 10s @ https://localhost:3000/seed/v1 — 100 de conexiuni):
| Stat | Mediu | Stdev | Max |
|---|---|---|---|
| Latență (ms) | 19.47 | 4.29 | 103 |
| Req/Sec | 5011.11 | 506,2 | 5487 |
| octeți/sec | 51,8 MB | 5,45 MB | 58,72 MB |
Este important să echilibrăm potențialele reduceri ale costurilor serverului cu costurile de dezvoltare. Trebuie să definim, în propriile noastre contexte situaționale, cât de departe trebuie să mergem în optimizarea unui proiect. În caz contrar, poate fi prea ușor să depui 80% din efort în 20% din îmbunătățirile de viteză. Constrângerile proiectului justifică acest lucru?
În unele scenarii, ar putea fi potrivit să obținem o îmbunătățire de 200 de ori cu un fruct care agăță jos și să numiți o zi. În altele, este posibil să dorim să facem implementarea noastră cât de repede posibil. Depinde cu adevărat de prioritățile proiectului.
O modalitate de a controla cheltuirea resurselor este stabilirea unui obiectiv. De exemplu, îmbunătățirea de 10 ori sau 4000 de solicitări pe secundă. Este cel mai logic să te bazezi pe nevoile afacerii. De exemplu, dacă costurile serverului sunt cu 100% peste buget, ne putem stabili un obiectiv de îmbunătățire de două ori.
Ducând-o mai departe
Dacă producem un nou grafic de flacără al serverului nostru, ar trebui să vedem ceva similar cu următorul:
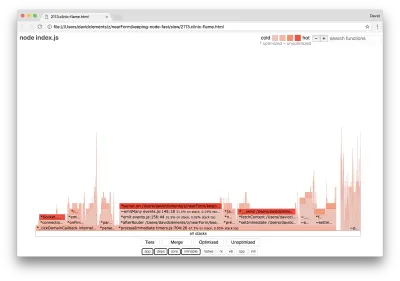
Ascultătorul de evenimente este încă blocajul, încă ocupă o treime din timpul CPU în timpul profilării (lățimea este de aproximativ o treime din întregul grafic).
Ce câștiguri suplimentare pot fi obținute și merită făcute modificările (împreună cu perturbările asociate acestora?
Cu o implementare optimizată, care este totuși puțin mai restrânsă, pot fi atinse următoarele caracteristici de performanță (Running 10s test @ https://localhost:3000/seed/v1 — 10 conexiuni):
| Stat | Mediu | Stdev | Max |
|---|---|---|---|
| Latență (ms) | 0,64 | 0,86 | 17 |
| Req/Sec | 8330,91 | 757,63 | 8991 |
| octeți/sec | 84,17 MB | 7,64 MB | 92,27 MB |
Deși o îmbunătățire de 1,6 ori este semnificativă, este discutabil dacă efortul, modificările și întreruperea codului necesare pentru a crea această îmbunătățire sunt justificate în funcție de situație. Mai ales în comparație cu îmbunătățirea de 200 de ori a implementării originale cu o singură remediere a erorilor.
Pentru a realiza această îmbunătățire, a fost folosită aceeași tehnică iterativă de profil, generare flamegraph, analiză, depanare și optimizare pentru a ajunge la serverul optimizat final, al cărui cod poate fi găsit aici.
Modificările finale pentru a ajunge la 8000 req/s au fost:
- Nu construiți obiecte și apoi serializați, construiți direct un șir de JSON;
- Folosiți ceva unic despre conținut pentru a-i defini Etag, mai degrabă decât să creați un hash;
- Nu hash adresa URL, folosește-o direct ca cheie.
Aceste modificări sunt puțin mai implicate, puțin mai perturbatoare pentru baza de cod și lasă middleware-ul etagger puțin mai puțin flexibil, deoarece pune sarcina pe traseul de a furniza valoarea Etag . Dar realizează un plus de 3000 de solicitări pe secundă pe mașina de profilare.
Să aruncăm o privire la un grafic de flacără pentru aceste îmbunătățiri finale:
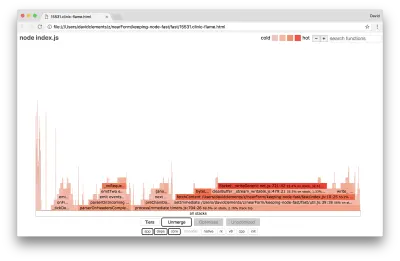
Cea mai fierbinte parte a graficului flăcării este parte a nucleului Node, în modulul net . Acest lucru este ideal.
Prevenirea problemelor de performanță
Pentru a completa, iată câteva sugestii despre modalități de a preveni problemele de performanță înainte de implementare.
Utilizarea instrumentelor de performanță ca puncte de control informale în timpul dezvoltării poate filtra erorile de performanță înainte de a ajunge în producție. Se recomandă ca AutoCannon și Clinic (sau echivalente) să facă parte din instrumentele de dezvoltare de zi cu zi.
Când cumpărați un cadru, aflați care este politica sa privind performanța. Dacă cadrul nu acordă prioritate performanței, atunci este important să verificați dacă aceasta se aliniază cu practicile de infrastructură și cu obiectivele de afaceri. De exemplu, Restify a investit în mod clar (de la lansarea versiunii 7) în îmbunătățirea performanței bibliotecii. Cu toate acestea, dacă costul scăzut și viteza mare sunt o prioritate absolută, luați în considerare Fastify, care a fost măsurat ca fiind cu 17% mai rapid de un colaborator Restify.
Atenție la alte opțiuni de bibliotecă cu impact larg - luați în considerare în special înregistrarea în jurnal. Pe măsură ce dezvoltatorii rezolvă problemele, aceștia pot decide să adauge rezultate suplimentare de jurnal pentru a ajuta la depanarea problemelor legate în viitor. Dacă se folosește un logger neperformant, acesta poate sugruma performanța în timp, după moda fabulei broaștei în fierbere. Loggerul pino este cel mai rapid logger JSON delimitat de noua linie disponibil pentru Node.js.
În cele din urmă, amintiți-vă întotdeauna că bucla de evenimente este o resursă partajată. Un server Node.js este în cele din urmă constrâns de cea mai lentă logică din calea cea mai fierbinte.