
Începeți cu Node: o introducere în API-uri, HTTP și ES6+ JavaScript
Publicat: 2022-03-10Probabil că ați auzit despre Node.js ca fiind un „tim de rulare JavaScript asincron construit pe motorul JavaScript V8 al Chrome” și că „folosește un model I/O care nu blochează, bazat pe evenimente, care îl face ușor și eficient”. Dar pentru unii, aceasta nu este cea mai mare dintre explicații.
Ce este Node în primul rând? Ce înseamnă exact ca Node să fie „asincron” și cum diferă asta de „sincron”? Oricum, care este sensul „controlat de evenimente” și „neblocare” și cum se încadrează Node în imaginea de ansamblu a aplicațiilor, rețelelor de internet și serverelor?
Vom încerca să răspundem la toate aceste întrebări și la multe altele de-a lungul acestei serii, în timp ce aruncăm o privire aprofundată asupra funcționării interioare a Node, aflăm despre Protocolul de transfer hipertext, API-uri și JSON și vom construi propriul nostru API Bookshelf folosind MongoDB, Express, Lodash, Mocha și ghidon.
Ce este Node.js
Node este doar un mediu sau timp de rulare în care să rulați JavaScript normal (cu diferențe minore) în afara browserului. Îl putem folosi pentru a construi aplicații desktop (cu cadre precum Electron), pentru a scrie servere web sau de aplicații și multe altele.
Blocare/Neblocare și sincron/asincron
Să presupunem că facem un apel la baza de date pentru a prelua proprietăți despre un utilizator. Apelul va dura, iar dacă cererea se „blochează”, înseamnă că va bloca execuția programului nostru până când apelul este complet. În acest caz, am făcut o solicitare „sincronă”, deoarece a ajuns să blocheze firul.
Deci, o operație sincronă blochează un proces sau un fir până când acea operație este completă, lăsând firul într-o „stare de așteptare”. O operație asincronă , pe de altă parte, este neblocantă . Permite execuția firului de execuție să continue, indiferent de timpul necesar pentru finalizarea operației sau de rezultatul cu care se finalizează și nicio parte a firului de execuție nu intră în stare de așteptare în niciun moment.
Să ne uităm la un alt exemplu de apel sincron care blochează un fir. Să presupunem că construim o aplicație care compară rezultatele a două API-uri meteo pentru a găsi diferența lor procentuală de temperatură. Într-o manieră de blocare, facem un apel la Weather API One și așteptăm rezultatul. Odată ce obținem un rezultat, apelăm Weather API Two și așteptăm rezultatul acestuia. Nu vă faceți griji în acest moment dacă nu sunteți familiarizat cu API-urile. Le vom acoperi într-o secțiune viitoare. Pentru moment, gândiți-vă doar la un API ca mijlocul prin care două computere pot comunica între ele.
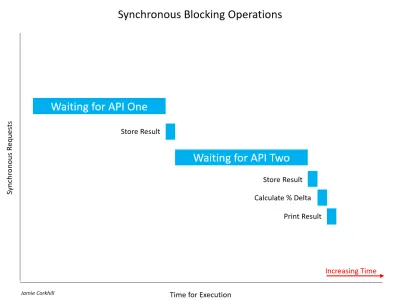
Permiteți-mi să remarc, este important să recunosc că nu toate apelurile sincrone sunt neapărat blocate. Dacă o operație sincronă poate reuși să se finalizeze fără a bloca firul de execuție sau a provoca o stare de așteptare, a fost neblocată. De cele mai multe ori, apelurile sincrone vor fi blocate, iar timpul necesar pentru finalizare va depinde de o varietate de factori, cum ar fi viteza serverelor API-ului, viteza de descărcare a conexiunii la internet a utilizatorului final etc.
În cazul imaginii de mai sus, a trebuit să așteptăm destul de mult pentru a prelua primele rezultate din API One. După aceea, a trebuit să așteptăm la fel de mult pentru a obține un răspuns de la API Two. În timp ce aștepta ambele răspunsuri, utilizatorul ar observa că aplicația noastră se blochează - interfața de utilizare s-ar bloca literalmente - și asta ar fi rău pentru experiența utilizatorului.
În cazul unui apel neblocant, am avea ceva de genul acesta:

Puteți vedea clar cât de repede am încheiat execuția. În loc să așteptăm API One și apoi să așteptăm API Two, am putea aștepta ca ambele să se finalizeze în același timp și să ne obținem rezultatele cu aproape 50% mai rapid. Observați, odată ce am sunat la API One și am început să așteptăm răspunsul său, am sunat și API Two și am început să așteptăm răspunsul său în același timp cu One.
În acest moment, înainte de a trece la exemple mai concrete și tangibile, este important de menționat că, pentru ușurință, termenul „Sincron” este în general scurtat la „Sincron”, iar termenul „Asincron” este în general scurtat la „Asincron”. Veți vedea această notație folosită în numele metodelor/funcțiilor.
Funcții de apel invers
S-ar putea să vă întrebați, „dacă putem gestiona un apel asincron, de unde știm când acel apel este încheiat și avem un răspuns?” În general, transmitem ca argument metodei noastre asincrone o funcție de apel invers, iar metoda respectivă va „apela înapoi” acea funcție mai târziu cu un răspuns. Folosesc funcțiile ES5 aici, dar ne vom actualiza la standardele ES6 mai târziu.
function asyncAddFunction(a, b, callback) { callback(a + b); //This callback is the one passed in to the function call below. } asyncAddFunction(2, 4, function(sum) { //Here we have the sum, 2 + 4 = 6. }); O astfel de funcție se numește „Funcție de ordin superior”, deoarece ia o funcție (reapelul nostru) ca argument. Alternativ, o funcție de apel invers ar putea să preia un obiect de eroare și un obiect de răspuns ca argumente și să le prezinte atunci când funcția asincronă este completă. Vom vedea asta mai târziu cu Express. Când am apelat asyncAddFunction(...) , veți observa că am furnizat o funcție de apel invers pentru parametrul de apel invers din definiția metodei. Această funcție este o funcție anonimă (nu are nume) și este scrisă folosind Sintaxa expresiei . Definiția metodei, pe de altă parte, este o instrucțiune de funcție. Nu este anonim pentru că are de fapt un nume (adică „asyncAddFunction”).
Unii pot observa confuzie, deoarece, în definiția metodei, furnizăm un nume, acesta fiind „callback”. Cu toate acestea, funcția anonimă transmisă ca al treilea parametru către asyncAddFunction(...) nu știe despre nume și, prin urmare, rămâne anonimă. De asemenea, nu putem executa acea funcție la un moment ulterior după nume, ar trebui să trecem din nou prin funcția de apelare asincronă pentru a o declanșa.
Ca exemplu de apel sincron, putem folosi metoda Node.js readFileSync(...) . Din nou, ne vom muta la ES6+ mai târziu.
var fs = require('fs'); var data = fs.readFileSync('/example.txt'); // The thread will be blocked here until complete.Dacă am face acest lucru în mod asincron, am introduce o funcție de apel invers care s-ar declanșa când operația asincronă ar fi finalizată.
var fs = require('fs'); var data = fs.readFile('/example.txt', function(err, data) { //Move on, this will fire when ready. if(err) return console.log('Error: ', err); console.log('Data: ', data); // Assume var data is defined above. }); // Keep executing below, don't wait on the data. Dacă nu ați văzut niciodată return folosită în acest mod înainte, spunem doar să opriți execuția funcției, astfel încât să nu imprimăm obiectul de date dacă obiectul de eroare este definit. De asemenea, am fi putut doar să încapsulăm instrucțiunea log într-o clauză else .
La fel ca asyncAddFunction(...) , codul din spatele funcției fs.readFile(...) ar fi ceva de genul:
function readFile(path, callback) { // Behind the scenes code to read a file stream. // The data variable is defined up here. callback(undefined, data); //Or, callback(err, undefined); }Permiteți-ne să privim o ultimă implementare a unui apel de funcție asincronă. Acest lucru va ajuta la consolidarea ideii ca funcțiile de apel invers să fie declanșate la un moment ulterior în timp și ne va ajuta să înțelegem execuția unui program tipic Node.js.
setTimeout(function() { // ... }, 1000); Metoda setTimeout(...) preia o funcție de apel invers pentru primul parametru care va fi declanșată după ce a avut loc numărul de milisecunde specificat ca al doilea argument.
Să ne uităm la un exemplu mai complex:
console.log('Initiated program.'); setTimeout(function() { console.log('3000 ms (3 sec) have passed.'); }, 3000); setTimeout(function() { console.log('0 ms (0 sec) have passed.'); }, 0); setTimeout(function() { console.log('1000 ms (1 sec) has passed.'); }, 1000); console.log('Terminated program');Ieșirea pe care o primim este:
Initiated program. Terminated program. 0 ms (0 sec) have passed. 1000 ms (1 sec) has passed. 3000 ms (3 sec) have passed. Puteți vedea că prima instrucțiune de jurnal rulează conform așteptărilor. Instantaneu, ultima instrucțiune de jurnal este tipărită pe ecran, deoarece aceasta se întâmplă înainte ca 0 secunde să fi depășit după al doilea setTimeout(...) . Imediat după aceea, se execută a doua, a treia și prima metodă setTimeout(...) .
Dacă Node.js nu a fost neblocant, am vedea prima instrucțiune de jurnal, am aștepta 3 secunde pentru a vedea următoarea, am vedea instantaneu pe a treia ( setTimeout(...) și apoi ar trebui să așteptăm încă una). al doilea pentru a vedea ultimele două instrucțiuni de jurnal. Natura neblocantă a lui Node face ca toate cronometrele să înceapă numărătoarea inversă din momentul în care programul este executat, mai degrabă decât în ordinea în care sunt tastate. Poate doriți să căutați API-urile Node, Callstack și Event Loop pentru mai multe informații despre modul în care funcționează Node sub capotă.
Este important să rețineți că doar pentru că vedeți o funcție de apel invers nu înseamnă neapărat că există un apel asincron în cod. Am numit metoda asyncAddFunction(…) de mai sus „async”, deoarece presupunem că operațiunea durează timp - cum ar fi efectuarea unui apel către un server. În realitate, procesul de adăugare a două numere nu este asincron și, prin urmare, acesta ar fi de fapt un exemplu de utilizare a unei funcții de apel invers într-un mod care nu blochează de fapt firul.
Promisiuni peste apeluri inverse
Reapelurile pot deveni rapid dezordonate în JavaScript, în special apelurile multiple imbricate. Suntem familiarizați cu transmiterea unui callback ca argument unei funcții, dar Promises ne permit să atașăm sau să atașăm un callback la un obiect returnat de la o funcție. Acest lucru ne-ar permite să gestionăm mai multe apeluri asincrone într-un mod mai elegant.
De exemplu, să presupunem că efectuăm un apel API, iar funcția noastră, nu atât de numită „ makeAPICall(...) ”, primește o adresă URL și un apel invers.
Funcția noastră, makeAPICall(...) , ar fi definită ca
function makeAPICall(path, callback) { // Attempt to make API call to path argument. // ... callback(undefined, res); // Or, callback(err, undefined); depending upon the API's response. }și l-am numi cu:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); // ... }); Dacă dorim să facem un alt apel API folosind răspunsul de la primul, ar trebui să imbricați ambele apeluri inverse. Să presupunem că trebuie să injectez proprietatea userName din obiectul res1 în calea celui de-al doilea apel API. Am avea:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); makeAPICall('/newExample/' + res1.userName, function(err2, res2) { if(err2) return console.log('Error: ', err2); console.log(res2); }); }); Notă : Metoda ES6+ pentru a injecta proprietatea res1.userName , mai degrabă decât concatenarea șirurilor, ar fi să folosești „Șabloane șiruri”. În acest fel, în loc să ne încapsulăm șirul în ghilimele ( ' , sau " ), am folosi backtick-uri ( ` ). situate sub tasta Escape de pe tastatură. Apoi, am folosi notația ${} pentru a încorpora orice expresie JS în interior În cele din urmă, calea noastră anterioară ar fi: /newExample/${res.UserName} , înfășurată în backticks.
Este clar de văzut că această metodă de imbricare a apelurilor poate deveni rapid destul de inelegantă, așa-numita „JavaScript Pyramid of Doom”. Sărind, dacă am folosi promisiuni mai degrabă decât apeluri inverse, am putea refactoriza codul nostru din primul exemplu ca atare:
makeAPICall('/example').then(function(res) { // Success callback. // ... }, function(err) { // Failure callback. console.log('Error:', err); }); Primul argument al funcției then() este callback-ul nostru de succes, iar al doilea argument este callback-ul eșec. Alternativ, am putea pierde al doilea argument la .then( .then() și, în schimb, să apelăm .catch() . Argumentele pentru .then() sunt opționale, iar apelarea .catch() ar fi echivalentă cu .then(successCallback, null) .
Folosind .catch() , avem:
makeAPICall('/example').then(function(res) { // Success callback. // ... }).catch(function(err) { // Failure Callback console.log('Error: ', err); });De asemenea, putem restructura acest lucru pentru lizibilitate:
makeAPICall('/example') .then(function(res) { // ... }) .catch(function(err) { console.log('Error: ', err); }); Este important de reținut că nu putem doar să punem un apel .then() la orice funcție și să ne așteptăm să funcționeze. Funcția pe care o apelăm trebuie să returneze de fapt o promisiune, o promisiune care va declanșa .then() când acea operație asincronă este finalizată. În acest caz, makeAPICall(...) va face treaba, lansând fie blocul then() fie blocul catch() când este finalizat.
Pentru a face ca makeAPICall(...) să returneze o Promisiune, atribuim o funcție unei variabile, unde acea funcție este constructorul Promise. Promisiunile pot fi fie îndeplinite , fie respinse , unde îndeplinite înseamnă că acțiunea legată de promisiunea s-a încheiat cu succes, iar respinsă însemnând contrariul. Odată ce promisiunea este fie îndeplinită, fie respinsă, spunem că s-a stabilit și, în timp ce așteptăm ca aceasta să se rezolve, poate în timpul unui apel asincron, spunem că promisiunea este în așteptare .
Constructorul Promise ia ca argument o funcție de apel invers, care primește doi parametri — resolve și reject , pe care îi vom apela la un moment ulterior în timp pentru a declanșa fie callback-ul de succes în .then() , fie eșecul .then() callback sau .catch() , dacă este furnizat.
Iată un exemplu despre cum arată asta:
var examplePromise = new Promise(function(resolve, reject) { // Do whatever we are going to do and then make the appropiate call below: resolve('Happy!'); // — Everything worked. reject('Sad!'); // — We noticed that something went wrong. }):Apoi, putem folosi:
examplePromise.then(/* Both callback functions in here */); // Or, the success callback in .then() and the failure callback in .catch(). Observați, totuși, că examplePromise nu poate accepta niciun argument. Așa ceva înfrânge scopul, așa că putem returna o promisiune.
function makeAPICall(path) { return new Promise(function(resolve, reject) { // Make our async API call here. if (/* All is good */) return resolve(res); //res is the response, would be defined above. else return reject(err); //err is error, would be defined above. }); } Promisiunile strălucesc cu adevărat pentru a îmbunătăți structura și, ulterior, eleganța codului nostru cu conceptul de „Promise Chaining”. Acest lucru ne-ar permite să returnăm o nouă Promisiune în interiorul unei clauze .then() , astfel încât să putem atașa un al doilea .then() după aceea, care ar declanșa apelul corespunzătoare din a doua promisiune.
Refactorizând apelul nostru cu mai multe adrese URL API de mai sus cu Promises, obținem:
makeAPICall('/example').then(function(res) { // First response callback. Fires on success to '/example' call. return makeAPICall(`/newExample/${res.UserName}`); // Returning new call allows for Promise Chaining. }, function(err) { // First failure callback. Fires if there is a failure calling with '/example'. console.log('Error:', err); }).then(function(res) { // Second response callback. Fires on success to returned '/newExample/...' call. console.log(res); }, function(err) { // Second failure callback. Fire if there is a failure calling with '/newExample/...' console.log('Error:', err); }); Observați că mai întâi apelăm makeAPICall('/example') . Aceasta returnează o promisiune și așadar atașăm un .then() . În acel then() , returnăm un nou apel la makeAPICall(...) , care, în sine, după cum am văzut mai devreme, returnează o promisiune, permițându-ne să înlănțuim un nou .then() după primul.
La fel ca mai sus, putem restructura acest lucru pentru a fi lizibil și elimina apelurile de eșec pentru o clauză generică catch() all. Apoi, putem urma principiul DRY (Nu te repeta) și trebuie să implementăm o singură dată gestionarea erorilor.
makeAPICall('/example') .then(function(res) { // Like earlier, fires with success and response from '/example'. return makeAPICall(`/newExample/${res.UserName}`); // Returning here lets us chain on a new .then(). }) .then(function(res) { // Like earlier, fires with success and response from '/newExample'. console.log(res); }) .catch(function(err) { // Generic catch all method. Fires if there is an err with either earlier call. console.log('Error: ', err); }); Rețineți că apelurile de succes și eșec din .then() se declanșează numai pentru starea Promisiei individuale căreia îi corespunde .then() . Blocul catch , totuși, va prinde orice erori care se declanșează în oricare dintre .then() s.
ES6 Const vs. Let
În toate exemplele noastre, am folosit funcții ES5 și vechiul cuvânt cheie var . În timp ce milioane de linii de cod încă rulează astăzi folosind acele metode ES5, este util să ne actualizăm la standardele actuale ES6+ și vom refactoriza o parte din codul nostru de mai sus. Să începem cu const și let .
Ați putea fi obișnuit să declarați o variabilă cu cuvântul cheie var :
var pi = 3.14;Cu standardele ES6+, am putea face și asta
let pi = 3.14;sau
const pi = 3.14; unde const înseamnă „constant” — o valoare care nu poate fi reatribuită mai târziu. (Cu excepția proprietăților obiectului - vom acoperi asta în curând. De asemenea, variabilele declarate const nu sunt imuabile, doar referința la variabilă este.)
În JavaScript vechi, blocați domenii, cum ar fi cele din if , while , {} . for , etc. nu au afectat var în niciun fel, iar acest lucru este destul de diferit de limbajele mai tipizate static precum Java sau C++. Adică, domeniul de aplicare al lui var este întreaga funcție care înglobează - și aceasta ar putea fi globală (dacă este plasată în afara unei funcții) sau locală (dacă este plasată într-o funcție). Pentru a demonstra acest lucru, vedeți următorul exemplu:
function myFunction() { var num = 5; console.log(num); // 5 console.log('--'); for(var i = 0; i < 10; i++) { var num = i; console.log(num); //num becomes 0 — 9 } console.log('--'); console.log(num); // 9 console.log(i); // 10 } myFunction();Ieșire:
5 --- 0 1 2 3 ... 7 8 9 --- 9 10 Lucrul important de observat aici este că definirea unui nou număr de var num în interiorul domeniului for a afectat direct numărul de var num în afara și deasupra for . Acest lucru se datorează faptului că domeniul de aplicare al lui var este întotdeauna cel al funcției de încadrare, și nu un bloc.
Din nou, în mod implicit, var i inside for() este implicit în domeniul de aplicare a myFunction și astfel putem accesa i în afara buclei și obținem 10.
În ceea ce privește atribuirea de valori variabilelor, let este echivalent cu var , doar că let are blocarea domeniului și astfel anomaliile care au apărut cu var mai sus nu se vor întâmpla.
function myFunction() { let num = 5; console.log(num); // 5 for(let i = 0; i < 10; i++) { let num = i; console.log('--'); console.log(num); // num becomes 0 — 9 } console.log('--'); console.log(num); // 5 console.log(i); // undefined, ReferenceError } Privind cuvântul cheie const , puteți vedea că obținem o eroare dacă încercăm să-i reatribuim:
const c = 299792458; // Fact: The constant "c" is the speed of light in a vacuum in meters per second. c = 10; // TypeError: Assignment to constant variable. Lucrurile devin interesante atunci când atribuim o variabilă const unui obiect:
const myObject = { name: 'Jane Doe' }; // This is illegal: TypeError: Assignment to constant variable. myObject = { name: 'John Doe' }; // This is legal. console.log(myObject.name) -> John Doe myObject.name = 'John Doe'; După cum puteți vedea, doar referința din memorie la obiectul atribuit unui obiect const este imuabilă, nu valoarea lui sine.
Funcții săgeți ES6
S-ar putea să fii obișnuit să creezi o funcție ca aceasta:
function printHelloWorld() { console.log('Hello, World!'); }Cu funcțiile săgeată, asta ar deveni:
const printHelloWorld = () => { console.log('Hello, World!'); };Să presupunem că avem o funcție simplă care returnează pătratul unui număr:
const squareNumber = (x) => { return x * x; } squareNumber(5); // We can call an arrow function like an ES5 functions. Returns 25.Puteți vedea că, la fel ca în cazul funcțiilor ES5, putem lua argumente cu paranteze, putem folosi instrucțiuni de returnare normale și putem apela funcția la fel ca oricare alta.
Este important de reținut că, în timp ce parantezele sunt necesare dacă funcția noastră nu acceptă argumente (cum ar fi printHelloWorld() de mai sus), putem elimina parantezele dacă ia doar una, astfel încât definiția anterioară squareNumber() poate fi rescrisă ca:
const squareNumber = x => { // Notice we have dropped the parentheses for we only take in one argument. return x * x; }Dacă alegeți să încapsulați un singur argument între paranteze sau nu, este o chestiune de gust personal și probabil veți vedea dezvoltatorii care folosesc ambele metode.
În cele din urmă, dacă vrem să returnăm implicit doar o expresie, ca și în cazul squareNumber(...) de mai sus, putem pune instrucțiunea return în conformitate cu semnătura metodei:
const squareNumber = x => x * x;Acesta este,
const test = (a, b, c) => expressioneste la fel ca
const test = (a, b, c) => { return expression }Rețineți că atunci când utilizați prescurtarea de mai sus pentru a returna implicit un obiect, lucrurile devin obscure. Ce oprește JavaScript să creadă că parantezele în care trebuie să ne încapsulăm obiectul nu sunt corpul nostru funcțional? Pentru a ocoli acest lucru, înfășurăm parantezele obiectului în paranteze. Acest lucru permite JavaScript în mod explicit să știe că într-adevăr returnăm un obiect și nu definim doar un corp.
const test = () => ({ pi: 3.14 }); // Spaces between brackets are a formality to make the code look cleaner.Pentru a ajuta la consolidarea conceptului de funcții ES6, vom refactoriza o parte din codul nostru anterior, permițându-ne să comparăm diferențele dintre ambele notații.
asyncAddFunction(...) , de mai sus, ar putea fi refactorizat din:
function asyncAddFunction(a, b, callback){ callback(a + b); }la:
const aysncAddFunction = (a, b, callback) => { callback(a + b); };sau chiar la:
const aysncAddFunction = (a, b, callback) => callback(a + b); // This will return callback(a + b).Când apelăm funcția, am putea trece o funcție săgeată pentru apel invers:
asyncAddFunction(10, 12, sum => { // No parentheses because we only take one argument. console.log(sum); }Este clar să vedem cum această metodă îmbunătățește lizibilitatea codului. Pentru a vă arăta doar un caz, putem să luăm vechiul nostru exemplu bazat pe ES5 Promise de mai sus și să îl refactorăm pentru a folosi funcțiile săgeților.
makeAPICall('/example') .then(res => makeAPICall(`/newExample/${res.UserName}`)) .then(res => console.log(res)) .catch(err => console.log('Error: ', err)); Acum, există câteva avertismente cu funcții de săgeată. În primul rând, ei nu leagă this cuvânt cheie. Să presupunem că am următorul obiect:
const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } S-ar putea să vă așteptați la un apel către Person.greeting() va returna „Hi. Numele meu este John Doe.” În schimb, obținem: „Bună. Numele meu este nedefinit.” Acest lucru se datorează faptului că funcțiile săgeată nu au this și, prin urmare, încercarea de a utiliza this în interiorul unei funcții săgeată este implicit la this din domeniul de aplicare, iar domeniul de aplicare al obiectului Person este window , în browser sau module.exports în Nodul.
Pentru a demonstra acest lucru, dacă folosim din nou același obiect, dar setăm proprietatea name a global this la ceva de genul „Jane Doe”, atunci this.name în funcția săgeată returnează „Jane Doe”, deoarece global this se află în care include domeniul de aplicare sau este părintele obiectului Person .
this.name = 'Jane Doe'; const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting(); // Hi. My name is Jane DoeAcest lucru este cunoscut sub numele de „Lexical Scoping” și îl putem ocoli folosind așa-numita „Sintaxă scurtă”, care este locul în care pierdem două puncte și săgeata pentru a ne refactoriza obiectul ca atare:
const Person = { name: 'John Doe', greeting() { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting() //Hi. My name is John Doe.Clasele ES6
Deși JavaScript nu a acceptat niciodată clase, le puteți emula oricând cu obiecte ca cele de mai sus. EcmaScript 6 oferă suport pentru clase care utilizează class și cuvintele cheie new :
class Person { constructor(name) { this.name = name; } greeting() { console.log(`Hi. My name is ${this.name}.`); } } const person = new Person('John'); person.greeting(); // Hi. My name is John. Funcția constructor este apelată automat când se utilizează cuvântul cheie new , în care putem trece argumente pentru a configura inițial obiectul. Acest lucru ar trebui să fie familiar oricărui cititor care are experiență cu limbaje de programare orientate pe obiecte mai tipizate static, cum ar fi Java, C++ și C#.
Fără a intra în prea multe detalii despre conceptele POO, o altă astfel de paradigmă este „moștenirea”, care este de a permite unei clase să moștenească de la alta. O clasă numită Car , de exemplu, va fi foarte generală - conținând metode precum „stop”, „start”, etc., după cum au nevoie toate mașinile. Un subset al clasei numit SportsCar , atunci, ar putea moșteni operațiuni fundamentale de la Car și poate suprascrie orice lucru personalizat de care are nevoie. Am putea desemna o astfel de clasă astfel:
class Car { constructor(licensePlateNumber) { this.licensePlateNumber = licensePlateNumber; } start() {} stop() {} getLicensePlate() { return this.licensePlateNumber; } // … } class SportsCar extends Car { constructor(engineRevCount, licensePlateNumber) { super(licensePlateNumber); // Pass licensePlateNumber up to the parent class. this.engineRevCount = engineRevCount; } start() { super.start(); } stop() { super.stop(); } getLicensePlate() { return super.getLicensePlate(); } getEngineRevCount() { return this.engineRevCount; } } Puteți vedea clar că cuvântul cheie super ne permite să accesăm proprietăți și metode din clasa părinte sau super.
Evenimente JavaScript
Un eveniment este o acțiune care are loc la care aveți capacitatea de a răspunde. Să presupunem că construiți un formular de conectare pentru aplicația dvs. Când utilizatorul apasă butonul „Trimite”, puteți reacționa la acel eveniment printr-un „gestionar de evenimente” din codul dvs. - de obicei o funcție. Când această funcție este definită ca handler de evenimente, spunem că „înregistrăm un handler de evenimente”. Managerul de evenimente pentru clicul butonului de trimitere va verifica probabil formatarea intrării furnizate de utilizator, o va igieniza pentru a preveni atacuri precum injecțiile SQL sau Cross Site Scripting (vă rugăm să rețineți că niciun cod de pe partea clientului nu poate fi luat în considerare vreodată În siguranță. Dezinfectați întotdeauna datele de pe server - nu aveți încredere în nimic din browser), apoi verificați dacă acea combinație de nume de utilizator și parolă iese dintr-o bază de date pentru a autentifica un utilizator și a le oferi un simbol.
Deoarece acesta este un articol despre Node, ne vom concentra pe modelul de evenimente Node.
Putem folosi modulul de events de la Node pentru a emite și a reacționa la evenimente specifice. Orice obiect care emite un eveniment este o instanță a clasei EventEmitter .
Putem emite un eveniment apelând metoda emit() și ascultăm acel eveniment prin metoda on() , ambele fiind expuse prin clasa EventEmitter .
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); Cu myEmitter acum o instanță a clasei EventEmitter , putem accesa emit() și on() :
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', () => { console.log('The "someEvent" event was fired (emitted)'); }); myEmitter.emit('someEvent'); // This will call the callback function above. Al doilea parametru pentru myEmitter.on() este funcția de apel invers care se va declanșa atunci când evenimentul este emis - acesta este handlerul de evenimente. Primul parametru este numele evenimentului, care poate fi orice ne place, deși este recomandată convenția de denumire camelCase.
În plus, handlerul de evenimente poate lua orice număr de argumente, care sunt transmise atunci când evenimentul este emis:
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', (data) => { console.log(`The "someEvent" event was fired (emitted) with data: ${data}`); }); myEmitter.emit('someEvent', 'This is the data payload'); Folosind moștenirea, putem expune metodele emit() și on() de la „EventEmitter” la orice clasă. Acest lucru se face prin crearea unei clase Node.js și folosind cuvântul cheie rezervat extends pentru a moșteni proprietățile disponibile pe EventEmitter :
const EventEmitter = require('events'); class MyEmitter extends EventEmitter { // This is my class. I can emit events from a MyEmitter object. } Să presupunem că construim un program de notificare a coliziunii vehiculelor care primește date de la giroscoape, accelerometre și manometre de pe carcasa mașinii. Când un vehicul se ciocnește cu un obiect, acești senzori externi vor detecta accidentul, executând funcția de collide(...) și transmitând acestuia datele agregate ale senzorului ca un obiect JavaScript frumos. Această funcție va emite un eveniment de collision , notificând vânzătorul despre accident.

const EventEmitter = require('events'); class Vehicle extends EventEmitter { collide(collisionStatistics) { this.emit('collision', collisionStatistics) } } const myVehicle = new Vehicle(); myVehicle.on('collision', collisionStatistics => { console.log('WARNING! Vehicle Impact Detected: ', collisionStatistics); notifyVendor(collisionStatistics); }); myVehicle.collide({ ... }); Acesta este un exemplu complicat, deoarece am putea doar să punem codul în handler-ul de evenimente în cadrul funcției de coliziune a clasei, dar demonstrează cum funcționează totuși modelul de evenimente Node. Rețineți că unele tutoriale vor arăta metoda util.inherits() de a permite unui obiect să emită evenimente. Acesta a fost depreciat în favoarea claselor ES6 și extends .
Managerul de pachete Node
Când programați cu Node și JavaScript, va fi destul de comun să auziți despre npm . Npm este un manager de pachete care face exact asta - permite descărcarea pachetelor terțe care rezolvă problemele comune în JavaScript. Există și alte soluții, cum ar fi Yarn, Npx, Grunt și Bower, dar în această secțiune, ne vom concentra doar pe npm și cum puteți instala dependențe pentru aplicația dvs. printr-o interfață simplă de linie de comandă (CLI) folosind-o.
Să începem simplu, cu doar npm . Vizitați pagina de pornire NpmJS pentru a vedea toate pachetele disponibile de la NPM. Când începeți un nou proiect care va depinde de pachetele NPM, va trebui să rulați npm init prin terminalul din directorul rădăcină al proiectului. Vi se vor pune o serie de întrebări care vor fi folosite pentru a crea un fișier package.json . Acest fișier stochează toate dependențele dvs. - module de care depinde aplicația dvs. pentru a funcționa, scripturi - comenzi terminale predefinite pentru a rula teste, a construi proiectul, a porni serverul de dezvoltare etc. și multe altele.
Pentru a instala un pachet, pur și simplu rulați npm install [package-name] --save . Indicatorul de save va asigura că pachetul și versiunea acestuia sunt conectate în fișierul package.json . De la versiunea 5 a npm , dependențele sunt salvate implicit, așa că --save poate fi omis. Veți observa, de asemenea, un nou folder node_modules , care conține codul pachetului pe care tocmai l-ați instalat. Acesta poate fi, de asemenea, scurtat la doar npm i [package-name] . Ca o notă utilă, folderul node_modules nu ar trebui să fie niciodată inclus într-un depozit GitHub din cauza dimensiunii sale. Ori de câte ori clonați un repo din GitHub (sau orice alt sistem de gestionare a versiunilor), asigurați-vă că executați comanda npm install pentru a ieși și a prelua toate pachetele definite în fișierul package.json , creând automat directorul node_modules . De asemenea, puteți instala un pachet la o anumită versiune: npm i [package-name]@1.10.1 --save , de exemplu.
Eliminarea unui pachet este similară cu instalarea unuia: npm remove [package-name] .
De asemenea, puteți instala un pachet la nivel global. Acest pachet va fi disponibil pentru toate proiectele, nu doar pentru cel la care lucrați. Faceți acest lucru cu -g după npm i [package-name] . Acesta este utilizat în mod obișnuit pentru CLI, cum ar fi Google Firebase și Heroku. În ciuda ușurinței pe care o prezintă această metodă, este în general considerată o practică proastă să instalați pachetele la nivel global, deoarece acestea nu sunt salvate în fișierul package.json și, dacă un alt dezvoltator încearcă să vă folosească proiectul, nu vor obține toate dependențele necesare de la npm install .
API-uri și JSON
API-urile sunt o paradigmă foarte comună în programare și chiar dacă abia începi în cariera ta de dezvoltator, API-urile și utilizarea lor, în special în dezvoltarea web și mobilă, vor apărea probabil mai des decât nu.
Un API este o interfață de programare a aplicației și, în principiu, este o metodă prin care două sisteme decuplate pot comunica între ele. În termeni mai tehnici, un API permite unui sistem sau program de calculator (de obicei un server) să primească cereri și să trimită răspunsuri adecvate (către un client, cunoscut și ca gazdă).
Să presupunem că construiți o aplicație meteo. Aveți nevoie de o modalitate de a geocoda adresa unui utilizator într-o latitudine și longitudine și apoi o modalitate de a obține vremea actuală sau prognozată în acea locație specială.
As a developer, you want to focus on building your app and monetizing it, not putting the infrastructure in place to geocode addresses or placing weather stations in every city.
Luckily for you, companies like Google and OpenWeatherMap have already put that infrastructure in place, you just need a way to talk to it — that is where the API comes in. While, as of now, we have developed a very abstract and ambiguous definition of the API, bear with me. We'll be getting to tangible examples soon.
Now, it costs money for companies to develop, maintain, and secure that aforementioned infrastructure, and so it is common for corporations to sell you access to their API. This is done with that is known as an API key, a unique alphanumeric identifier associating you, the developer, with the API. Every time you ask the API to send you data, you pass along your API key. The server can then authenticate you and keep track of how many API calls you are making, and you will be charged appropriately. The API key also permits Rate-Limiting or API Call Throttling (a method of throttling the number of API calls in a certain timeframe as to not overwhelm the server, preventing DOS attacks — Denial of Service). Most companies, however, will provide a free quota, giving you, as an example, 25,000 free API calls a day before charging you.
Up to this point, we have established that an API is a method by which two computer programs can communicate with each other. If a server is storing data, such as a website, and your browser makes a request to download the code for that site, that was the API in action.
Let us look at a more tangible example, and then we'll look at a more real-world, technical one. Suppose you are eating out at a restaurant for dinner. You are equivalent to the client, sitting at the table, and the chef in the back is equivalent to the server.
Since you will never directly talk to the chef, there is no way for him/her to receive your request (for what order you would like to make) or for him/her to provide you with your meal once you order it. We need someone in the middle. In this case, it's the waiter, analogous to the API. The API provides a medium with which you (the client) may talk to the server (the chef), as well as a set of rules for how that communication should be made (the menu — one meal is allowed two sides, etc.)
Now, how do you actually talk to the API (the waiter)? You might speak English, but the chef might speak Spanish. Is the waiter expected to know both languages to translate? What if a third person comes in who only speaks Mandarin? What then? Well, all clients and servers have to agree to speak a common language, and in computer programming, that language is JSON, pronounced JAY-sun, and it stands for JavaScript Object Notation.
At this point, we don't quite know what JSON looks like. It's not a computer programming language, it's just, well, a language, like English or Spanish, that everyone (everyone being computers) understands on a guaranteed basis. It's guaranteed because it's a standard, notably RFC 8259 , the JavaScript Object Notation (JSON) Data Interchange Format by the Internet Engineering Task Force (IETF).
Even without formal knowledge of what JSON actually is and what it looks like (we'll see in an upcoming article in this series), we can go ahead introduce a technical example operating on the Internet today that employs APIs and JSON. APIs and JSON are not just something you can choose to use, it's not equivalent to one out of a thousand JavaScript frameworks you can pick to do the same thing. It is THE standard for data exchange on the web.
Suppose you are building a travel website that compares prices for aircraft, rental car, and hotel ticket prices. Let us walk through, step-by-step, on a high level, how we would build such an application. Of course, we need our User Interface, the front-end, but that is out of scope for this article.
We want to provide our users with the lowest price booking method. Well, that means we need to somehow attain all possible booking prices, and then compare all of the elements in that set (perhaps we store them in an array) to find the smallest element (known as the infimum in mathematics.)
How will we get this data? Well, suppose all of the booking sites have a database full of prices. Those sites will provide an API, which exposes the data in those databases for use by you. You will call each API for each site to attain all possible booking prices, store them in your own array, find the lowest or minimum element of that array, and then provide the price and booking link to your user. We'll ask the API to query its database for the price in JSON, and it will respond with said price in JSON to us. We can then use, or parse, that accordingly. We have to parse it because APIs will return JSON as a string, not the actual JavaScript data type of JSON. This might not make sense now, and that's okay. We'll be covering it more in a future article.
Also, note that just because something is called an API does not necessarily mean it operates on the web and sends and receives JSON. The Java API, for example, is just the list of classes, packages, and interfaces that are part of the Java Development Kit (JDK), providing programming functionality to the programmer.
Bine. We know we can talk to a program running on a server by way of an Application Programming Interface, and we know that the common language with which we do this is known as JSON. But in the web development and networking world, everything has a protocol. What do we actually do to make an API call, and what does that look like code-wise? That's where HTTP Requests enter the picture, the HyperText Transfer Protocol, defining how messages are formatted and transmitted across the Internet. Once we have an understanding of HTTP (and HTTP verbs, you'll see that in the next section), we can look into actual JavaScript frameworks and methods (like fetch() ) offered by the JavaScript API (similar to the Java API), that actually allow us to make API calls.
HTTP And HTTP Requests
HTTP is the HyperText Transfer Protocol. It is the underlying protocol that determines how messages are formatted as they are transmitted and received across the web. Let's think about what happens when, for example, you attempt to load the home page of Smashing Magazine in your web browser.
You type the website URL (Uniform Resource Locator) in the URL bar, where the DNS server (Domain Name Server, out of scope for this article) resolves the URL into the appropriate IP Address. The browser makes a request, called a GET Request, to the Web Server to, well, GET the underlying HTML behind the site. The Web Server will respond with a message such as “OK”, and then will go ahead and send the HTML down to the browser where it will be parsed and rendered accordingly.
There are a few things to note here. First, the GET Request, and then the “OK” response. Suppose you have a specific database, and you want to write an API to expose that database to your users. Suppose the database contains books the user wants to read (as it will in a future article in this series). Then there are four fundamental operations your user may want to perform on this database, that is, Create a record, Read a record, Update a record, or Delete a record, known collectively as CRUD operations.
Let's look at the Read operation for a moment. Without incorrectly assimilating or conflating the notion of a web server and a database, that Read operation is very similar to your web browser attempting to get the site from the server, just as to read a record is to get the record from the database.
Aceasta este cunoscută ca o solicitare HTTP. Faceți o cerere către un server de undeva pentru a obține niște date și, ca atare, cererea este numită în mod corespunzător „GET”, scrierea cu majuscule fiind o modalitate standard de a desemna astfel de solicitări.
Ce zici de porțiunea Creare a CRUD? Ei bine, când vorbim despre solicitări HTTP, aceasta este cunoscută sub numele de solicitare POST. Așa cum ați putea posta un mesaj pe o platformă de socializare, ați putea posta și o nouă înregistrare într-o bază de date.
Actualizarea CRUD ne permite să folosim fie o solicitare PUT, fie PATCH pentru a actualiza o resursă. PUT-ul HTTP fie va crea o înregistrare nouă, fie o va actualiza/înlocui pe cea veche.
Să ne uităm la asta puțin mai în detaliu și apoi vom ajunge la PATCH.
Un API funcționează în general prin efectuarea de solicitări HTTP către anumite rute dintr-o adresă URL. Să presupunem că facem un API pentru a vorbi cu o bază de date care conține lista de cărți a unui utilizator. Apoi am putea vedea acele cărți la adresa URL .../books . O solicitare POST către .../books va crea o carte nouă cu orice proprietăți definiți (gândiți-vă la id, titlu, ISBN, autor, date de publicare etc.) la ruta .../books . Nu contează care este structura de date de bază care stochează toate cărțile la .../books chiar acum. Ne pasă doar că API-ul expune acel punct final (accesat prin rută) pentru a manipula datele. Propoziția anterioară a fost cheia: O solicitare POST creează o carte nouă la ...books/ traseu. Prin urmare, diferența dintre PUT și POST este că PUT va crea o carte nouă (ca și în cazul POST) dacă nu există o astfel de carte sau va înlocui o carte existentă dacă cartea există deja în structura de date menționată mai sus.
Să presupunem că fiecare carte are următoarele proprietăți: id, titlu, ISBN, autor, hasRead (boolean).
Apoi, pentru a adăuga o carte nouă, așa cum am văzut mai devreme, vom face o solicitare POST către .../books . Dacă dorim să actualizăm sau să înlocuim complet o carte, am face o solicitare PUT la .../books/id unde id este ID-ul cărții pe care dorim să o înlocuim.
În timp ce PUT înlocuiește complet o carte existentă, PATCH actualizează ceva ce are de-a face cu o anumită carte, poate modificând proprietatea booleană hasRead pe care am definit-o mai sus - așa că am face o solicitare PATCH către …/books/id , trimițând împreună noile date.
Poate fi dificil să vedem sensul acestui lucru chiar acum, pentru că până acum am stabilit totul în teorie, dar nu am văzut niciun cod tangibil care să facă de fapt o solicitare HTTP. Cu toate acestea, vom ajunge la asta în curând, acoperind GET în acest articol, și restul într-un articol viitor.
Există o ultimă operație CRUD fundamentală și se numește Delete. După cum v-ați aștepta, numele unei astfel de solicitări HTTP este „ȘTERGERE”, și funcționează la fel ca PATCH, necesitând ca ID-ul cărții să fie furnizat într-o rută.
Am învățat până acum că rutele sunt adrese URL specifice cărora le faceți o solicitare HTTP și că punctele finale sunt funcții pe care API-ul le furnizează, făcând ceva cu datele pe care le expune. Adică, punctul final este o funcție de limbaj de programare situată la celălalt capăt al rutei și execută orice solicitare HTTP pe care ați specificat-o. De asemenea, am aflat că există termeni precum POST, GET, PUT, PATCH, DELETE și alții (cunoscuți sub numele de verbe HTTP) care specifică de fapt ce solicitări faceți către API. La fel ca JSON, aceste metode de solicitare HTTP sunt standarde de Internet, așa cum sunt definite de Internet Engineering Task Force (IETF), în special, RFC 7231, Secțiunea Patru: Metode de solicitare și RFC 5789, Secțiunea a doua: Metoda de corecție, unde RFC este un acronim pentru Cerere de comentarii.
Deci, am putea face o solicitare GET la adresa URL .../books/id unde ID-ul transmis este cunoscut ca parametru. Am putea face o solicitare POST, PUT sau PATCH către .../books pentru a crea o resursă sau către .../books/id pentru a modifica/înlocui/actualiza o resursă. Și putem face și o solicitare DELETE către .../books/id pentru a șterge o anumită carte.
O listă completă a metodelor de solicitare HTTP poate fi găsită aici.
De asemenea, este important să rețineți că, după efectuarea unei solicitări HTTP, vom primi un răspuns. Răspunsul specific este determinat de modul în care construim API-ul, dar ar trebui să primiți întotdeauna un cod de stare. Mai devreme, am spus că atunci când browserul dvs. web solicită codul HTML de la serverul web, acesta va răspunde cu „OK”. Acesta este cunoscut sub numele de Cod de stare HTTP, mai precis, HTTP 200 OK. Codul de stare specifică doar modul în care operația sau acțiunea specificată în punctul final (nu uitați, aceasta este funcția noastră care face toată munca). Codurile de stare HTTP sunt trimise înapoi de către server și probabil că sunt multe cu care sunteți familiarizat, cum ar fi 404 Not Found (resursa sau fișierul nu a putut fi găsit, aceasta ar fi ca și cum ați face o solicitare GET către .../books/id acolo unde nu există un astfel de ID.)
O listă completă a codurilor de stare HTTP poate fi găsită aici.
MongoDB
MongoDB este o bază de date NoSQL, non-relațională, similară bazei de date în timp real Firebase. Veți vorbi cu baza de date printr-un pachet Node, cum ar fi MongoDB Native Driver sau Mongoose.
În MongoDB, datele sunt stocate în JSON, care este destul de diferit de bazele de date relaționale precum MySQL, PostgreSQL sau SQLite. Ambele sunt numite baze de date, cu tabele SQL numite colecții, rânduri tabel SQL numite documente și coloane tabel SQL numite câmpuri.
Vom folosi baza de date MongoDB într-un articol viitor din această serie când vom crea primul nostru API Bookshelf. Operațiunile CRUD fundamentale enumerate mai sus pot fi efectuate pe o bază de date MongoDB.
Este recomandat să citiți documentele MongoDB pentru a afla cum să creați o bază de date live pe un cluster Atlas și să efectuați operațiuni CRUD cu driverul nativ MongoDB. În următorul articol din această serie, vom învăța cum să configurați o bază de date locală și o bază de date de producție în cloud.
Construirea unei aplicații pentru nodul de linie de comandă
Când construiți o aplicație, veți vedea mulți autori care își aruncă întreaga bază de cod la începutul articolului și apoi încearcă să explice fiecare rând ulterior. În acest text, voi adopta o abordare diferită. Voi explica codul meu linie cu linie, construind aplicația pe măsură ce mergem. Nu voi face griji cu privire la modularitate sau performanță, nu voi împărți baza de cod în fișiere separate și nu voi respecta principiul DRY și nu voi încerca să fac codul reutilizabil. Când doar învățați, este util să faceți lucrurile cât mai simple posibil și, așadar, aceasta este abordarea pe care o voi lua aici.
Să fim clari ce construim. Nu ne vom preocupa de intrarea utilizatorului și, prin urmare, nu vom folosi pachete precum Yargs. De asemenea, nu vom construi propriul nostru API. Acest lucru va apărea într-un articol ulterior din această serie, când vom folosi Express Web Application Framework. Iau această abordare pentru a nu combina Node.js cu puterea Express și a API-urilor, deoarece majoritatea tutorialelor o fac. Mai degrabă, voi oferi o metodă (din multe) prin care să apelați și să primiți date de la un API extern care utilizează o bibliotecă JavaScript terță parte. API-ul pe care îl vom apela este un Weather API, pe care îl vom accesa de la Node și îl vom transfera pe terminal, poate cu o anumită formatare, cunoscută sub numele de „pretty-printing”. Voi acoperi întregul proces, inclusiv cum să configurați API-ul și să obțineți cheia API, ai cărui pași oferă rezultate corecte din ianuarie 2019.
Vom folosi API-ul OpenWeatherMap pentru acest proiect, așa că pentru a începe, navigați la pagina de înscriere OpenWeatherMap și creați un cont cu formularul. Odată autentificat, găsiți elementul de meniu Chei API pe pagina tabloului de bord (situat aici). Dacă tocmai ați creat un cont, va trebui să alegeți un nume pentru cheia dvs. API și să apăsați „Generare”. Ar putea dura cel puțin 2 ore pentru ca noua cheie API să fie funcțională și asociată contului.
Înainte de a începe construirea aplicației, vom vizita documentația API pentru a afla cum să formatăm cheia noastră API. În acest proiect, vom specifica un cod poștal și un cod de țară pentru a obține informații despre vreme în acea locație.
Din documente, putem vedea că metoda prin care facem acest lucru este să furnizăm următoarea adresă URL:
api.openweathermap.org/data/2.5/weather?zip={zip code},{country code}În care am putea introduce date:
api.openweathermap.org/data/2.5/weather?zip=94040,usAcum, înainte de a putea obține date relevante din acest API, va trebui să furnizăm noua noastră cheie API ca parametru de interogare:
api.openweathermap.org/data/2.5/weather?zip=94040,us&appid={YOUR_API_KEY} Pentru moment, copiați acea adresă URL într-o filă nouă a browserului dvs. web, înlocuind substituentul {YOUR_API_KEY} cu cheia API pe care ați obținut-o mai devreme când v-ați înregistrat pentru un cont.
Textul pe care îl puteți vedea este de fapt JSON - limba convenită pentru web, așa cum sa discutat mai devreme.
Pentru a verifica acest lucru în continuare, apăsați Ctrl + Shift + I în Google Chrome pentru a deschide instrumentele pentru dezvoltatori Chrome, apoi navigați la fila Rețea. În prezent, nu ar trebui să existe date aici.
Pentru a monitoriza efectiv datele din rețea, reîncărcați pagina și urmăriți ca fila să fie completată cu informații utile. Faceți clic pe primul link așa cum este prezentat în imaginea de mai jos.
Odată ce faceți clic pe acel link, putem vizualiza informații specifice HTTP, cum ar fi anteturile. Anteturile sunt trimise în răspunsul de la API (puteți, de asemenea, în unele cazuri, să trimiteți propriile antete către API sau chiar să vă creați propriile antete personalizate (adesea prefixate cu x- ) pentru a le trimite înapoi atunci când vă construiți propriul API ), și conține doar informații suplimentare de care clientul sau serverul ar putea avea nevoie.
În acest caz, puteți vedea că am făcut o solicitare HTTP GET către API și a răspuns cu o stare HTTP 200 OK. De asemenea, puteți vedea că datele trimise înapoi au fost în JSON, așa cum este listat în secțiunea „Anteturi de răspuns”.
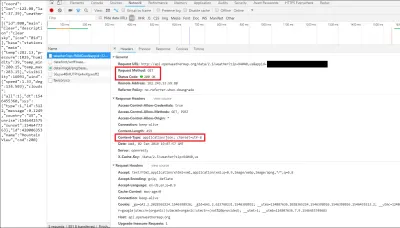
Dacă apăsați pe fila de previzualizare, puteți vedea de fapt JSON ca obiect JavaScript. Versiunea text pe care o puteți vedea în browser este un șir, deoarece JSON este întotdeauna transmis și primit pe web ca șir. De aceea trebuie să analizăm JSON în codul nostru, pentru a-l introduce într-un format mai lizibil - în acest caz (și aproape în toate cazurile) - un obiect JavaScript.
De asemenea, puteți utiliza extensia Google Chrome „JSON View” pentru a face acest lucru automat.
Pentru a începe să construim aplicația noastră, voi deschide un terminal și voi face un nou director rădăcină și apoi cd în el. Odată înăuntru, voi crea un nou fișier app.js , voi rula npm init pentru a genera un fișier package.json cu setările implicite, apoi voi deschide Visual Studio Code.
mkdir command-line-weather-app && cd command-line-weather-app touch app.js npm init code . După aceea, voi descărca Axios, voi verifica că a fost adăugat în fișierul meu package.json și voi reține că folderul node_modules a fost creat cu succes.
În browser, puteți vedea că am făcut o solicitare GET manual, introducând manual adresa URL corespunzătoare în bara URL. Axios este ceea ce îmi va permite să fac asta în interiorul Node.
Începând de acum, tot codul următor va fi localizat în interiorul fișierului app.js , fiecare fragment fiind plasat unul după altul.
Primul lucru pe care îl voi face este să solicit pachetul Axios cu care l-am instalat mai devreme
const axios = require('axios'); Acum avem acces la Axios și putem face solicitări HTTP relevante, prin constanta axios .
În general, apelurile noastre API vor fi dinamice - în acest caz, este posibil să dorim să injectăm diferite coduri poștale și coduri de țară în adresa URL. Deci, voi crea variabile constante pentru fiecare parte a URL-ului și apoi le voi pune împreună cu șirurile de șabloane ES6. În primul rând, avem partea din adresa URL care nu se va schimba niciodată, precum și cheia API:
const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; De asemenea, voi atribui codul nostru poștal și codul țării. Deoarece nu ne așteptăm la intrarea utilizatorului și codificăm destul de greu datele, le voi face și acestea constante, deși, în multe cazuri, va fi mai util să folosiți let .
const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us';Acum trebuie să punem aceste variabile împreună într-o singură adresă URL la care să putem folosi Axios pentru a face cereri GET către:
const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Iată conținutul fișierului nostru app.js până în acest moment:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Tot ce rămâne de făcut este să folosiți efectiv axios pentru a face o solicitare GET la acea adresă URL. Pentru asta, vom folosi metoda get(url) oferită de axios .
axios.get(ENTIRE_API_URL) axios.get(...) returnează de fapt o Promisiune, iar funcția de apel invers de succes va prelua un argument de răspuns care ne va permite să accesăm răspunsul din API - același lucru pe care l-ați văzut în browser. De asemenea, voi adăuga o clauză .catch() pentru a detecta orice erori.
axios.get(ENTIRE_API_URL) .then(response => console.log(response)) .catch(error => console.log('Error', error)); Dacă rulăm acum acest cod cu node app.js în terminal, veți putea vedea răspunsul complet pe care îl primim. Cu toate acestea, să presupunem că doriți doar să vedeți temperatura pentru acel cod poștal - atunci majoritatea acestor date din răspuns nu vă sunt utile. Axios returnează de fapt răspunsul de la API în obiectul de date, care este o proprietate a răspunsului. Asta înseamnă că răspunsul de la server se află de fapt la response.data , așa că haideți să-l imprimăm în schimb în funcția de apel invers: console.log(response.data) .
Acum, am spus că serverele web se ocupă întotdeauna de JSON ca șir și asta este adevărat. S-ar putea să observați, totuși, că response.data este deja un obiect (evident prin rularea console.log(typeof response.data) ) - nu a trebuit să-l analizăm cu JSON.parse() . Asta pentru că Axios se ocupă deja de asta pentru noi în culise.
Ieșirea din terminal de la rularea console.log(response.data) poate fi formatată — „pretty-printed” — prin rularea console.log(JSON.stringify(response.data, undefined, 2)) . JSON.stringify() convertește un obiect JSON într-un șir de caractere și preia obiectul, un filtru și numărul de caractere prin care să se indenteze la imprimare. Puteți vedea răspunsul oferit de acesta:
{ "coord": { "lon": -118.24, "lat": 33.97 }, "weather": [ { "id": 800, "main": "Clear", "description": "clear sky", "icon": "01d" } ], "base": "stations", "main": { "temp": 288.21, "pressure": 1022, "humidity": 15, "temp_min": 286.15, "temp_max": 289.75 }, "visibility": 16093, "wind": { "speed": 2.1, "deg": 110 }, "clouds": { "all": 1 }, "dt": 1546459080, "sys": { "type": 1, "id": 4361, "message": 0.0072, "country": "US", "sunrise": 1546441120, "sunset": 1546476978 }, "id": 420003677, "name": "Lynwood", "cod": 200 } Acum, este clar să vedem că temperatura pe care o căutăm se află pe proprietatea main a obiectului response.data , așa că o putem accesa apelând response.data.main.temp . Să ne uităm la codul aplicației de până acum:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => console.log(response.data.main.temp)) .catch(error => console.log('Error', error));Temperatura pe care o revenim este de fapt în Kelvin, care este o scară de temperatură utilizată în general în Fizică, Chimie și Termodinamică datorită faptului că oferă un punct „zero absolut”, care este temperatura la care toate mișcările termice ale tuturor interioarelor. particulele încetează. Trebuie doar să convertim acest lucru în Fahrenheit sau Celcius cu formulele de mai jos:
F = K * 9/5 - 459,67
C = K - 273,15
Să ne actualizăm apelul de succes pentru a imprima noile date cu această conversie. De asemenea, vom adăuga o propoziție adecvată în scopul experienței utilizatorului:
axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error)); Parantezele din jurul variabilei message nu sunt necesare, ele arată pur și simplu frumos - similar cu atunci când lucrați cu JSX în React. Barele oblice inverse împiedică șirul șablon să formateze o nouă linie, iar metoda prototipului replace() String elimină spațiul alb folosind expresii regulate (RegEx). Metodele prototip toFixed() Number rotunjesc un float la un anumit număr de zecimale - în acest caz, două.
Cu asta, finalul nostru app.js arată după cum urmează:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error));Concluzie
Am învățat multe despre modul în care funcționează Node în acest articol, de la diferențele dintre cererile sincrone și asincrone, la funcții de apel invers, la noile caracteristici ES6, evenimente, manageri de pachete, API-uri, JSON și protocolul de transfer hipertext, baze de date non-relaționale. , și chiar am construit propria noastră aplicație de linie de comandă utilizând majoritatea acestor cunoștințe noi găsite.
În articolele viitoare din această serie, vom arunca o privire aprofundată asupra API-urilor Call Stack, Event Loop și Node, vom vorbi despre Cross-Origin Resource Sharing (CORS) și vom construi un complet Stack Bookshelf API utilizând baze de date, puncte finale, autentificarea utilizatorilor, jetoane, redarea șablonului pe partea de server și multe altele.
De aici, începeți să vă construiți propriile aplicații Node, citiți documentația Node, găsiți API-uri sau module Node interesante și implementați-le singur. Lumea este stridia ta și ai la îndemână acces la cea mai mare rețea de cunoștințe de pe planetă — Internetul. Folosește-l în avantajul tău.
Citiți suplimentare despre SmashingMag:
- Înțelegerea și utilizarea API-urilor REST
- Noi funcții JavaScript care vor schimba modul în care scrieți regex
- Menținerea rapidă a Node.js: instrumente, tehnici și sfaturi pentru realizarea de servere Node.js de înaltă performanță
- Construirea unui chatbot AI simplu cu API-ul Web Speech și Node.js