
7 cei mai folosiți algoritmi de învățare automată în Python despre care ar trebui să știți
Publicat: 2021-03-04Învățarea automată este o ramură a inteligenței artificiale (AI) care se ocupă cu algoritmii de computer utilizați pentru orice date. Se concentrează pe învățarea automată din datele care sunt introduse în el și ne oferă rezultate prin îmbunătățirea predicțiilor anterioare de fiecare dată.
Cuprins
Topul algoritmilor de învățare automată utilizați în Python
Mai jos sunt câțiva dintre cei mai buni algoritmi de învățare automată utilizați în Python, împreună cu fragmente de cod care arată implementarea lor și vizualizările limitelor de clasificare.
1. Regresia liniară
Regresia liniară este una dintre cele mai frecvent utilizate tehnici de învățare automată supravegheată. După cum sugerează și numele, această regresie încearcă să modeleze relația dintre două variabile folosind o ecuație liniară și potrivind acea linie la datele observate. Această tehnică este utilizată pentru a estima valori reale continue, cum ar fi vânzările totale efectuate sau costul caselor.
Linia de cea mai bună potrivire se mai numește și linie de regresie. Este dat de următoarea ecuație:
Y = a*X + b
unde Y este variabila dependentă, a este panta, X este variabila independentă și b este valoarea interceptării. Coeficienții a și b sunt obținuți prin minimizarea pătratului diferenței acelei distanțe dintre diferitele puncte de date și ecuația dreptei de regresie.

# set de date sintetice pentru regresie simplă
din sklearn.datasets import make_regression
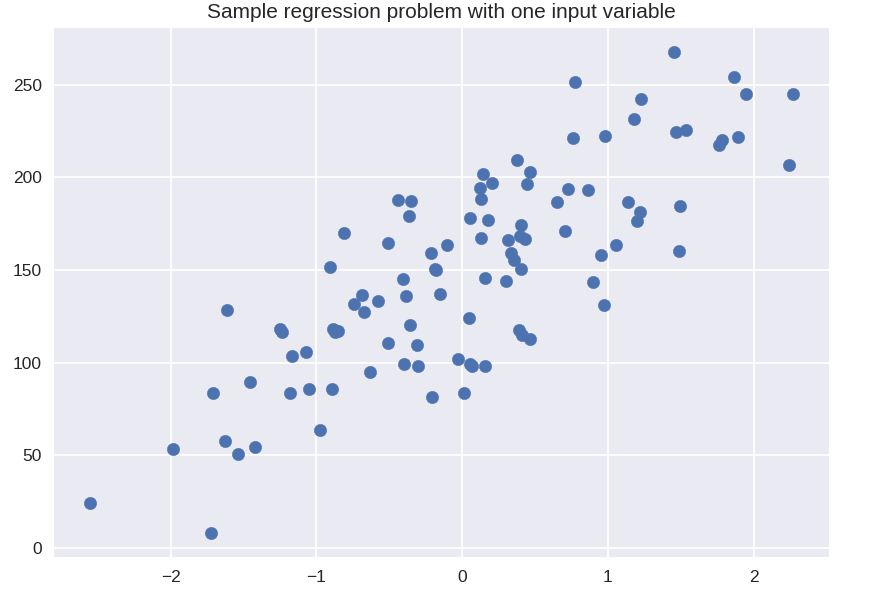
plt.figure()
plt.title(„Problemă de regresie eșantion cu o variabilă de intrare”)
X_R1, y_R1 = make_regression( n_samples = 100, n_features = 1, n_informative = 1, bias = 150.0, noise = 30, random_state = 0 )
plt.scatter( X_R1, y_R1, marker = 'o', s = 50 )
plt.show()
din sklearn.linear_model import LinearRegression
X_train, X_test, y_train, y_test = tren_test_split( X_R1, y_R1,
stare_aleatorie = 0)
linreg = LinearRegression().fit( X_train, y_train )
print('coeff model liniar (w): {}'.format( linreg.coef_ ) )
print( 'interceptarea modelului liniar (b): {:.3f}'z.format( linreg.intercept_ ) )
print('Scor R-squared (antrenament): {:.3f}'.format( linreg.score( X_train, y_train ) ) )
print( 'Scor R-pătrat (test): {:.3f}'.format( linreg.score( X_test, y_test ) ) )
Ieșire
coeff model liniar (w): [ 45,71]
interceptarea modelului liniar (b): 148,446
Scorul R-pătrat (antrenament): 0,679
Scorul R-pătrat (test): 0,492
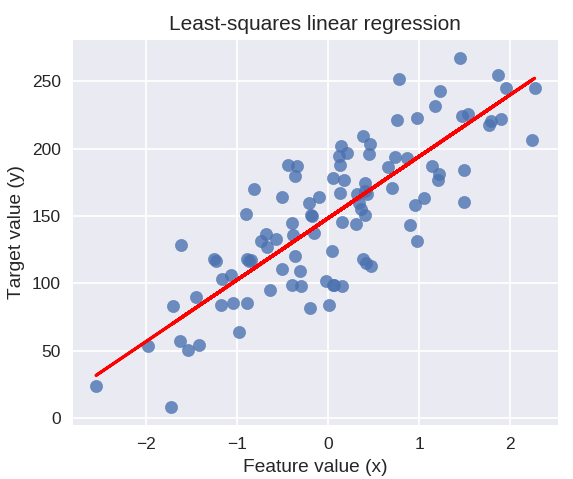
Următorul cod va desena linia de regresie potrivită pe graficul punctelor noastre de date.
plt.figure( figsize = ( 5, 4 ) )
plt.scatter( X_R1, y_R1, marker = „o”, s = 50, alfa = 0,8)
plt.plot( X_R1, linreg.coef_ * X_R1 + linreg.intercept_, 'r-' )
plt.title('Regresia liniară cu cele mai mici pătrate')
plt.xlabel('Valoarea caracteristicii (x)')
plt.ylabel( 'Valoarea țintă (y)' )
plt.show()
Pregătirea unui set de date comun pentru explorarea tehnicilor de clasificare
Următoarele date vor fi folosite pentru a arăta diferiții algoritmi de clasificare care sunt cel mai frecvent utilizați în învățarea automată în Python.
Setul de date UCI Mushroom este stocat în mushrooms.csv.
Notebook %matplotlib
importa panda ca pd
import numpy ca np
import matplotlib.pyplot ca plt
din sklearn.decomposition import PCA
din sklearn.model_selection import train_test_split
df = pd.read_csv( 'readonly/mushrooms.csv' )
df2 = pd.get_dummies( df )
df3 = df2.sample( frac = 0,08 )
X = df3.iloc[:, 2:]
y = df3.iloc[:, 1]
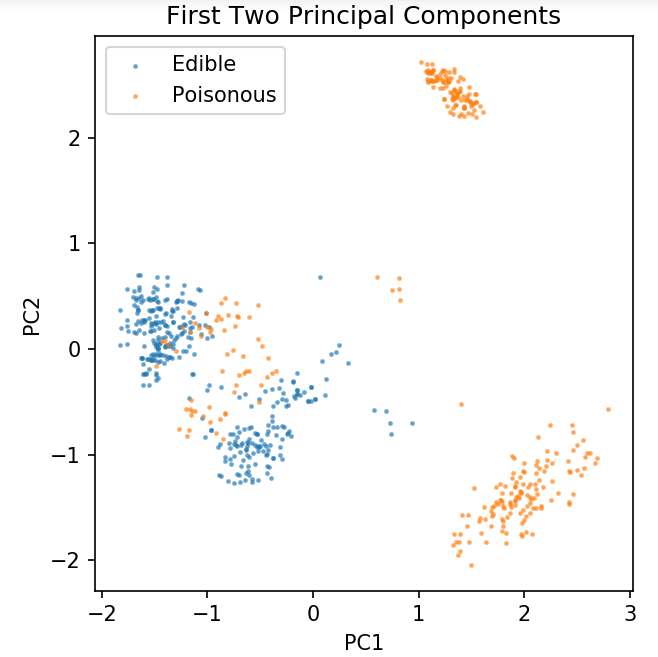
pca = PCA( n_componente = 2 ).fit_transform( X )
X_train, X_test, y_train, y_test = train_test_split( pca, y, random_state = 0 )
plt.figure( dpi = 120 )
plt.scatter( pca[y.values == 0, 0], pca[y.values == 0, 1], alfa = 0,5, etichetă = „Comestibil”, s = 2)
plt.scatter( pca[y.values == 1, 0], pca[y.values == 1, 1], alfa = 0,5, label = „Otrăvitor”, s = 2)
plt.legend()
plt.title( 'Set de date ciuperci\nPrimele două componente principale' )
plt.xlabel( 'PC1' )
plt.ylabel( 'PC2' )
plt.gca().set_aspect('egal')
Vom folosi funcția definită mai jos pentru a obține limitele de decizie ale diferitelor clasificatoare pe care le vom folosi pe setul de date ciuperci.
def plot_mushroom_boundary( X, y, fitted_model ):
plt.figure( figsize = (9,8, 5), dpi = 100 )
pentru i, plot_type în enumerate( ['Delimitare de decizie', 'Probabilităţi de decizie'] ):
plt.subplot( 1, 2, i + 1 )
mesh_step_size = 0,01 # dimensiune pas în plasă
x_min, x_max = X[:, 0].min() – .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() – .1, X[:, 1].max() + .1
xx, yy = np.meshgrid( np.arange( x_min, x_max, mesh_step_size ), np.arange( y_min, y_max, mesh_step_size ) )
dacă i == 0:
Z = fitted_model.predict( np.c_[xx.ravel(), yy.ravel()] )
altceva:
încerca:
Z = fitted_model.predict_proba( np.c_[xx.ravel(), yy.ravel()] )[:, 1]
cu exceptia:
plt.text( 0.4, 0.5, 'Probabilități indisponibile', horizontalalignment = 'center', verticalalignment = 'center', transform = plt.gca().transAxes, fontsize = 12 )
plt.axis( 'off' )
pauză
Z = Z.reformă(xx.formă)
plt.scatter( X[y.values == 0, 0], X[y.values == 0, 1], alfa = 0,4, etichetă = „Comestibil”, s = 5)
plt.scatter( X[y.values == 1, 0], X[y.values == 1, 1], alfa = 0,4, etichetă = „Posionous”, s = 5)
plt.imshow( Z, interpolare = 'cel mai apropiat', cmap = 'RdYlBu_r', alpha = 0,15, extent = ( x_min, x_max, y_min, y_max ), origine = 'inferioară' )
plt.title( plot_type + '\n' + str( fitted_model ).split( '(' )[0] + ' Precizia testului: ' + str( np.round( fitted_model.score( X, y ), 5 ) ) )
plt.gca().set_aspect('egal');
plt.tight_layout()
plt.subplots_adjust( sus = 0,9, jos = 0,08, wspace = 0,02)
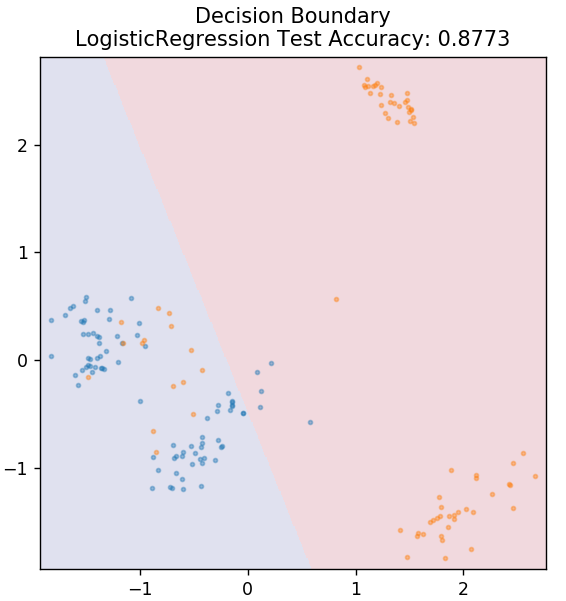
2. Regresia logistică
Spre deosebire de regresia liniară, regresia logistică se ocupă cu estimarea valorilor discrete (valori binare 0/1, adevărat/fals, da/nu). Această tehnică se mai numește și regresie logit. Acest lucru se datorează faptului că prezice probabilitatea unui eveniment utilizând o funcție logit pentru a antrena datele date. Valoarea sa este întotdeauna între 0 și 1 (deoarece calculează o probabilitate).
Cota logarită a rezultatelor este construită ca o combinație liniară a variabilei predictoare, după cum urmează:
cote = p / (1 – p) = probabilitatea ca evenimentul să se producă sau probabilitatea ca evenimentul să nu se producă
ln( cote ) = ln( p / (1 – p) )
logit( p ) = ln( p / (1 – p) ) = b0 + b1X1 + b2X2 + b3X3 + … + bkXk
unde p este probabilitatea prezenței unei caracteristici.
din sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
Obțineți certificare de inteligență artificială online de la cele mai bune universități din lume – masterat, programe executive postuniversitare și program de certificat avansat în ML și AI pentru a vă accelera cariera.
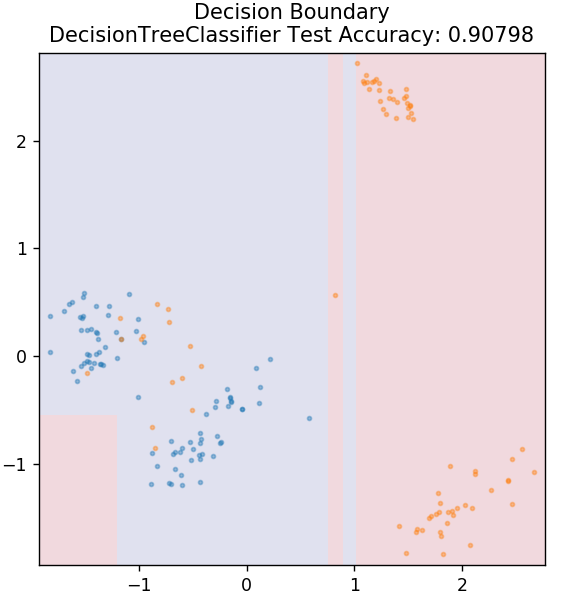
3. Arborele de decizie
Acesta este un algoritm foarte popular care poate fi utilizat pentru a clasifica atât variabilele continue, cât și cele discrete ale datelor. La fiecare pas, datele sunt împărțite în mai multe seturi omogene pe baza unor atribute/condiții de divizare.

din sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier( max_depth = 3 )
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
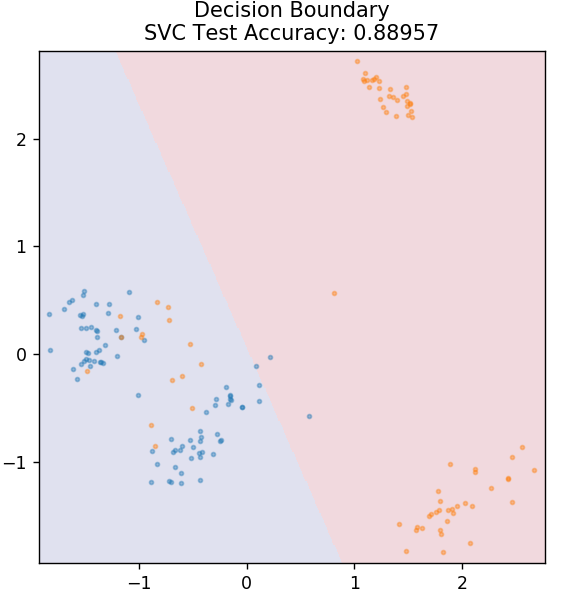
4. SVM
SVM este prescurtarea pentru Support Vector Machines. Aici ideea de bază este clasificarea punctelor de date folosind hiperplanuri pentru separare. Scopul este de a afla un astfel de hiperplan care are distanța maximă (sau marja) între punctele de date ale ambelor clase sau categorii.
Alegem avionul in asa fel incat sa ne ocupam de clasificarea punctelor necunoscute in viitor cu cea mai mare incredere. SVM-urile sunt utilizate în mod celebru deoarece oferă o precizie ridicată, în timp ce ocupă o putere de calcul foarte mică. SVM-urile pot fi folosite și pentru probleme de regresie.
din sklearn.svm import SVC
model = SVC( nucleu = 'liniar')
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
Checkout: Proiecte Python pe GitHub
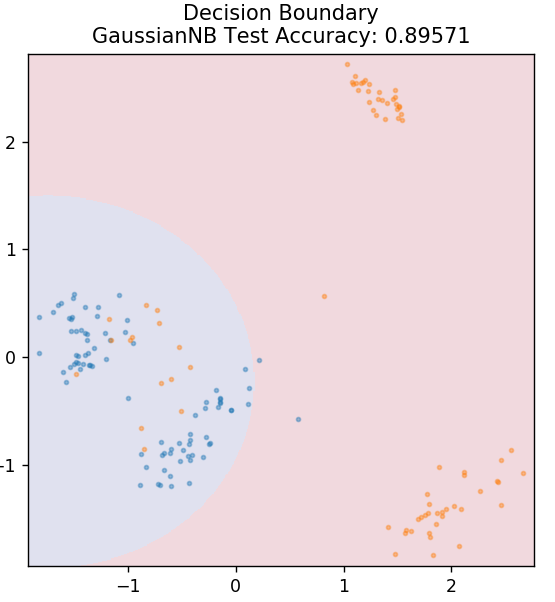
5. Bayes naiv
După cum sugerează și numele, algoritmul Naive Bayes este un algoritm de învățare supravegheat bazat pe teorema Bayes . Teorema Bayes folosește probabilități condiționate pentru a vă oferi probabilitatea unui eveniment pe baza unor cunoștințe date.
Unde, 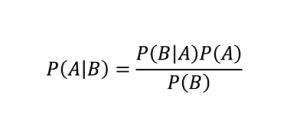
P (A | B): Probabilitatea condiționată ca evenimentul A să aibă loc, având în vedere că evenimentul B a avut deja loc. (numită și probabilitate posterioară)
P(A): Probabilitatea evenimentului A.
P(B): Probabilitatea evenimentului B.
P (B | A): Probabilitatea condiționată ca evenimentul B să aibă loc, având în vedere că evenimentul A a avut deja loc.
De ce se numește acest algoritm Naive, vă întrebați? Acest lucru se datorează faptului că presupune că toate aparițiile evenimentelor sunt independente unele de altele. Deci fiecare caracteristică definește separat clasa căreia îi aparține un punct de date, fără a avea dependențe între ele. Naive Bayes este cea mai bună alegere pentru categoriile de text. Va funcționa suficient de bine chiar și cu cantități mici de date de antrenament.
din sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
5. KNN
KNN înseamnă K-Nearest Neighbours. Este un algoritm de învățare supervizată foarte utilizat, care clasifică datele de testare în funcție de asemănările lor cu datele de antrenament clasificate anterior. KNN nu clasifică toate punctele de date în timpul antrenamentului. În schimb, doar stochează setul de date și, atunci când primește date noi, clasifică apoi acele puncte de date pe baza asemănărilor lor. Face acest lucru calculând distanța euclidiană a numărului K de vecini cei mai apropiați (aici, n_neighbors ) a acelui punct de date.
din sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier( n_neighbors = 20 )
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
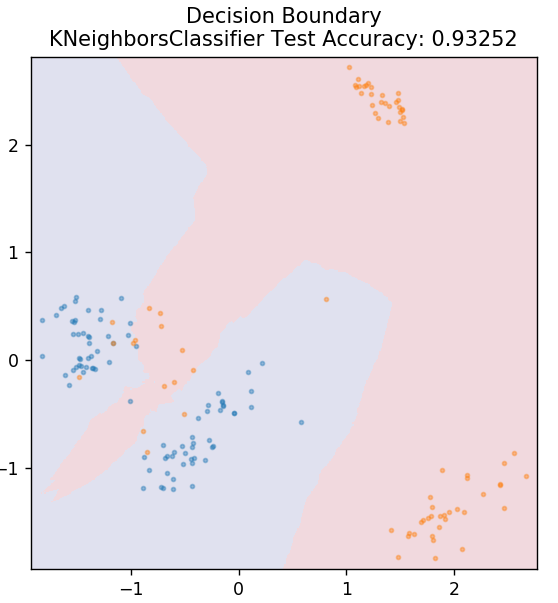
6. Pădurea aleatorie
Pădurea aleatorie este un algoritm de învățare automată foarte simplu și divers care utilizează o tehnică de învățare supravegheată. După cum puteți ghici după nume, pădurea aleatoare constă dintr-un număr mare de arbori de decizie, acționând ca un ansamblu. Fiecare arbore de decizie va determina clasa de ieșire a punctelor de date și clasa majoritară va fi aleasă ca rezultat final al modelului. Ideea aici este că mai mulți copaci care lucrează pe aceleași date vor avea tendința de a fi mai precisi în rezultate decât copacii individuali.
din sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
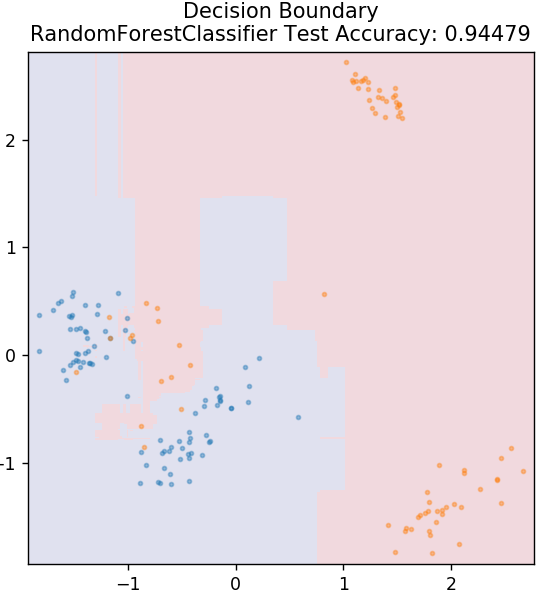
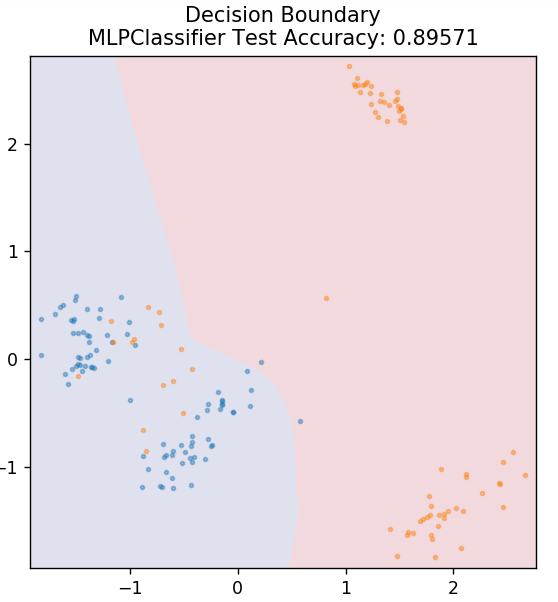
7. Perceptron cu mai multe straturi
Multi-Layer Perceptron (sau MLP) este un algoritm foarte fascinant care face parte din ramura învățării profunde. Mai precis, aparține clasei de rețele neuronale artificiale feed-forward (ANN). MLP formează o rețea de perceptroni multipli cu cel puțin trei straturi: un strat de intrare, un strat de ieșire și un strat(e) ascuns. MLP-urile sunt capabile să facă distincția între datele care sunt separabile neliniar.
Fiecare neuron din straturile ascunse folosește o funcție de activare pentru a trece la stratul următor. Aici, algoritmul de backpropagation este folosit pentru a regla parametrii și, prin urmare, pentru a antrena rețeaua neuronală. Poate fi folosit mai ales pentru probleme simple de regresie.
din sklearn.neural_network import MLPClassifier
model = MLPClassifier()
model.fit( X_train, y_train )
plot_mushroom_boundary( X_test, y_test, model )
Citiți și: Idei și subiecte pentru proiecte Python
Concluzie
Putem concluziona că diferiți algoritmi de învățare automată generează limite de decizie diferite și, prin urmare, o precizie diferită are ca rezultat clasificarea aceluiași set de date.
Nu există nicio modalitate de a declara algoritmul oricui drept cel mai bun algoritm pentru toate tipurile de date în general. Învățarea automată necesită încercări și erori riguroase pentru diverși algoritmi pentru a determina ce funcționează cel mai bine pentru fiecare set de date separat. Lista algoritmilor ML nu se termină în mod evident aici. Există o mare mare de alte tehnici care așteaptă să fie explorate în biblioteca Scikit-Learn din Python. Continuă și antrenează-ți seturile de date folosind toate acestea și distrează-te!
Dacă sunteți interesat să aflați mai multe despre arbori de decizie, învățarea automată, consultați Programul Executive PG de la IIIT-B și upGrad în Învățare automată și IA, care este conceput pentru profesioniști care lucrează și oferă peste 450 de ore de formare riguroasă, peste 30 de studii de caz și misiuni, statutul de absolvenți IIIT-B, peste 5 proiecte practice practice și asistență la locul de muncă cu firme de top.
Care sunt ipotezele principale ale regresiei liniare?
Există 4 ipoteze esențiale pentru regresia liniară: liniaritate, homoscedasticitate, independență și normalitate. Liniaritatea înseamnă că relația dintre variabila independentă (X) și media variabilei dependente (Y) este considerată liniară atunci când folosim regresia liniară. Homoscedasticitatea înseamnă că variația erorilor punctelor reziduale ale graficului se presupune a fi constantă. Independența se referă la toate observațiile din datele de intrare care trebuie considerate independente unele de altele. Normalitatea înseamnă că distribuția datelor de intrare poate fi uniformă sau neuniformă, dar se presupune că este distribuită uniform în cazul regresiei liniare.
Care sunt diferențele dintre un arbore de decizie și o pădure aleatorie?
Arborele de decizie își implementează procesul de luare a deciziilor, folosind o structură de tip arbore care reprezintă rezultatele posibile pentru acțiuni specifice. Pădurea aleatorie folosește un pachet de astfel de arbori de decizie pentru a analiza datele. Prin acest proces, mai multe date vor fi folosite de către Random Forest, dar ajută la prevenirea supraadaptarii și oferă rezultate precise. Există un domeniu de supraadaptare într-un algoritm de arbore de decizie și poate oferi rezultate mai puțin precise. Un arbore de decizie este ușor de interpretat, deoarece necesită mai puține calcule, în timp ce o pădure aleatorie este greu de interpretat din cauza analizelor sale complexe.
Care sunt unele biblioteci standard utilizate pentru algoritmii de învățare automată în Python?
Python a înlocuit aproape toate celelalte limbi în învățarea automată datorită disponibilității unui număr mare de biblioteci și a regulilor de sintaxă simple. Există multe biblioteci Python pentru învățarea automată, cum ar fi Numpy, Scipy, Scikit-learn, Theono, TensorFlow, PyTorch, Matplotlib, Keras, Pandas, etc. Utilizarea funcțiilor din aceste biblioteci economisește mult timp la scrierea algoritmilor pentru fiecare sarcină; procesele consumă mai puțin timp și oferă rezultate eficiente. Aceste biblioteci au aplicații precum procesarea matricei, probleme de optimizare, extragerea datelor, analiză statistică, calcule care implică tensori, detectarea obiectelor, rețele neuronale și multe altele.