
Tutorial de învățare automată: Învață ML de la zero
Publicat: 2022-02-17Implementarea soluțiilor de inteligență artificială (AI) și de învățare automată (ML) continuă să avanseze diferite procese de afaceri , îmbunătățirea experienței clienților fiind cazul de utilizare de top.
Astăzi, învățarea automată are o gamă largă de aplicații, iar cele mai multe dintre ele sunt tehnologii pe care le întâlnim zilnic. De exemplu, Netflix sau platforme OTT similare folosesc machine learning pentru a personaliza sugestiile pentru fiecare utilizator. Deci, dacă un utilizator urmărește frecvent thrillere criminale sau le caută, sistemul de recomandare bazat pe ML al platformei va începe să sugereze mai multe filme de gen similar. De asemenea, Facebook și Instagram personalizează feedul unui utilizator pe baza postărilor cu care interacționează frecvent.
În acest tutorial de învățare automată Python , ne vom scufunda în elementele de bază ale învățării automate . De asemenea, am inclus un scurt tutorial de învățare profundă pentru a prezenta conceptul începătorilor.
Cuprins
Ce este Machine Learning?
Termenul de „învățare automată” a fost inventat în 1959 de Arthur Samuel, un pionierat în domeniul jocurilor pe computer și al inteligenței artificiale.
Învățarea automată este un subset al inteligenței artificiale. Se bazează pe conceptul că software-ul (programele) pot învăța din date, pot descifra modele și pot lua decizii cu interferențe umane minime. Cu alte cuvinte, ML este un domeniu al științei computaționale care permite unui utilizator să alimenteze o cantitate enormă de date unui algoritm și să pună sistemul să analizeze și să ia decizii bazate pe date pe baza datelor de intrare. Prin urmare, algoritmii ML nu se bazează pe un model predeterminat și în schimb „învață” în mod direct informațiile din datele furnizate.
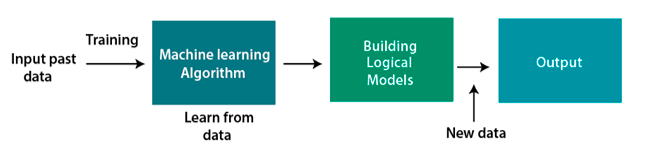
Sursă

Iată un exemplu simplificat -
Cum scriem un program care identifică florile în funcție de culoare, forma petale sau alte proprietăți? În timp ce cea mai evidentă modalitate ar fi de a crea reguli de identificare stricte, o astfel de abordare nu va face ca regulile ideale să fie aplicabile în toate cazurile. Cu toate acestea, învățarea automată necesită o strategie mai practică și mai robustă și, în loc să facă reguli predeterminate, antrenează sistemul alimentându-i cu date (imagini) cu diferite flori. Deci, data viitoare când sistemului i se arată un trandafir și o floarea soarelui, le poate clasifica pe cele două pe baza experienței anterioare.
Citiți Cum să învățați învățarea automată – pas cu pas
Tipuri de învățare automată
Clasificarea învățării automate se bazează pe modul în care un algoritm învață să devină mai precis în prezicerea rezultatelor. Astfel, există trei abordări de bază ale învățării automate: învățarea supravegheată, învățarea nesupravegheată și învățarea prin întărire.
Învățare supravegheată
În învățarea automată supravegheată, algoritmii sunt furnizați cu date de antrenament etichetate. În plus, utilizatorul definește variabilele pe care dorește să le evalueze algoritmul; variabilele țintă sunt variabilele pe care vrem să le prezicem, iar caracteristicile sunt variabilele care ne ajută să anticipăm ținta. Așadar, este mai degrabă ca și cum am arăta algoritmului imaginea unui pește și spunem „este un pește”, apoi arătăm o broască și indicăm că este o broască. Apoi, când algoritmul a fost antrenat pe suficiente date despre pești și broaște, va învăța să facă diferența între ele.
Învățare nesupravegheată
Învățarea automată nesupravegheată implică algoritmi care învață din date de antrenament neetichetate. Deci, există doar caracteristicile (variabile de intrare) și nicio variabilă țintă. Problemele de învățare nesupravegheate includ gruparea, unde variabilele de intrare cu aceleași caracteristici sunt grupate și asociate pentru a descifra relații semnificative în setul de date. Un exemplu de grupare este gruparea oamenilor în fumători și nefumători. Dimpotrivă, a descoperi că clienții care folosesc smartphone-uri vor cumpăra și huse de telefon este o asociere.
Consolidarea învățării
Învățarea prin consolidare este o tehnică bazată pe feed-uri în care modelele de învățare automată învață să ia o serie de decizii pe baza feedback-ului pe care îl primesc pentru acțiunile lor. Pentru fiecare acțiune bună, mașina primește feedback pozitiv, iar pentru fiecare acțiune proastă, primește o penalizare sau feedback negativ. Deci, spre deosebire de învățarea automată supravegheată, un model consolidat învață automat folosind feedback în loc de orice date etichetate.
Citiți, de asemenea, Ce este învățarea automată și de ce contează
De ce să folosiți Python pentru Machine Learning?
Proiectele de învățare automată diferă de proiectele software tradiționale prin aceea că primele implică seturi distincte de abilități, stive de tehnologie și cercetare profundă. Prin urmare, implementarea unui proiect de învățare automată de succes necesită un limbaj de programare care este stabil, flexibil și oferă instrumente robuste. Python oferă totul, așa că vedem în mare parte proiecte de învățare automată bazate pe Python.
Independenta platformei
Popularitatea lui Python se datorează în mare măsură faptului că este un limbaj independent de platformă și este acceptat de majoritatea platformelor, inclusiv Windows, macOS și Linux. Astfel, dezvoltatorii pot crea programe executabile de sine stătătoare pe o singură platformă și le pot distribui către alte sisteme de operare fără a necesita un interpret Python. Prin urmare, modelele de instruire automată devin mai ușor de gestionat și mai ieftine.

Simplitate și flexibilitate
În spatele fiecărui model de învățare automată se află algoritmi și fluxuri de lucru complexe care pot fi intimidante și copleșitoare pentru utilizatori. Dar, codul concis și ușor de citit al lui Python permite dezvoltatorilor să se concentreze pe modelul de învățare automată în loc să se îngrijoreze de aspectele tehnice ale limbajului. În plus, Python este ușor de învățat și poate gestiona sarcini complicate de învățare automată, ceea ce duce la construirea și testarea rapidă a prototipurilor.
O selecție largă de cadre și biblioteci
Python oferă o selecție extinsă de cadre și biblioteci care reduc semnificativ timpul de dezvoltare. Astfel de biblioteci au coduri pre-scrise pe care dezvoltatorii le folosesc pentru a îndeplini sarcinile generale de programare. Repertoriul de instrumente software Python include Scikit-learn, TensorFlow și Keras pentru învățare automată, Pandas pentru analiza de date cu scop general, NumPy și SciPy pentru analiza datelor și calcul științific, Seaborn pentru vizualizarea datelor și multe altele.
Învățați și Preprocesarea datelor în Machine Learning: 7 pași simpli de urmat
Pași pentru implementarea unui proiect de învățare automată Python
Dacă sunteți nou în învățarea automată, cel mai bun mod de a vă împăca cu un proiect este să enumerați pașii cheie pe care trebuie să îi acoperiți. Odată ce aveți pașii, îi puteți folosi ca șablon pentru seturile de date ulterioare, completând golurile și modificând fluxul de lucru pe măsură ce treceți în etapele avansate.
Iată o prezentare generală a modului de implementare a unui proiect de învățare automată cu Python:
- Defineste problema.
- Instalați Python și SciPy.
- Încărcați setul de date.
- Rezumați setul de date.
- Vizualizați setul de date.
- Evaluați algoritmi.
- A face predictii.
- Prezentați rezultate.
Ce este o rețea de învățare profundă?
Rețelele de învățare profundă sau rețelele neuronale profunde (DNN) sunt o ramură a învățării automate bazată pe imitarea creierului uman. DNN-urile cuprind unități care combină mai multe intrări pentru a produce o singură ieșire. Ei sunt analogi cu neuronii biologici care primesc semnale multiple prin sinapse și trimit un singur flux de potențial de acțiune în neuronul său.
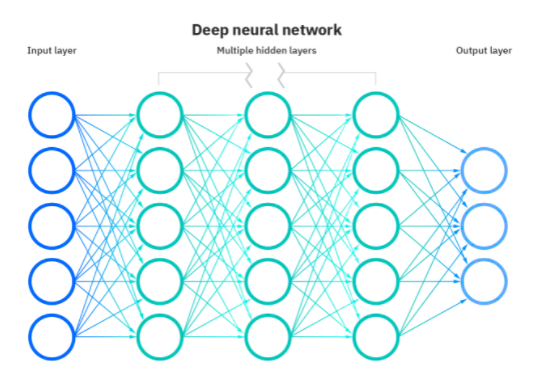
Sursă
Într-o rețea neuronală, funcționalitatea asemănătoare creierului este realizată prin straturi de noduri constând dintr-un strat de intrare, unul sau mai multe straturi ascunse și un strat de ieșire. Fiecare neuron sau nod artificial are un prag și o greutate asociate și se conectează la altul. Când ieșirea unui nod este peste valoarea de prag definită, acesta este activat și trimite date către următorul strat din rețea.
DNN-urile depind de datele de antrenament pentru a învăța și a-și ajusta precizia în timp. Ele constituie instrumente robuste de inteligență artificială, care permit clasificarea și gruparea datelor la viteze mari. Două dintre cele mai comune domenii de aplicare ale rețelelor neuronale profunde sunt recunoașterea imaginilor și recunoașterea vorbirii.
Pas înainte
Fie că este vorba de deblocarea unui smartphone cu Face ID, de răsfoirea în filme sau de căutarea unui subiect aleatoriu pe Google, consumatorii moderni, bazați pe digital, solicită recomandări inteligente și o personalizare mai bună. Indiferent de industrie sau domeniu, AI are și continuă să joace un rol semnificativ în îmbunătățirea experienței utilizatorului. În plus, simplitatea și versatilitatea Python au făcut ca dezvoltarea, implementarea și întreținerea proiectelor AI să fie convenabile și eficiente pe toate platformele.
Învață cursul ML de la cele mai bune universități din lume. Câștigă programe de master, Executive PGP sau Advanced Certificate pentru a-ți accelera cariera.
Dacă ați găsit interesant acest tutorial de învățare automată Python pentru începători, aprofundați subiectul cu Master of Science în învățare automată și AI de la upGrad . Programul online este conceput pentru profesioniștii care lucrează care doresc să învețe abilități avansate de inteligență artificială, cum ar fi NLP, învățare profundă, învățare prin consolidare și multe altele.
Repere ale cursului:
- Masterat de la LJMU
- PGP executiv de la IIIT Bangalore
- Peste 750 de ore de conținut
- Peste 40 de sesiuni live
- 12+ studii de caz și proiecte
- 11 sarcini de codare
- Acoperire aprofundată a 20 de instrumente, limbi și biblioteci
- Asistență în carieră la 360 de grade
1. Este Python bun pentru învățarea automată?
Python este unul dintre cele mai bune limbaje de programare pentru implementarea modelelor de învățare automată. Python se adresează atât dezvoltatorilor, cât și începătorilor datorită simplității, flexibilității și curbei de învățare blânde. În plus, Python este independent de platformă și are acces la biblioteci și cadre care fac construirea și testarea modelelor de învățare automată mai rapidă și mai ușoară.
2. Învățarea automată cu Python este grea?
Datorită popularității pe scară largă a Python ca limbaj de programare de uz general și adoptării acestuia în învățarea automată și în calculul științific, găsirea unui tutorial de învățare automată Python este destul de ușoară. În plus, curba blândă de învățare a lui Python, codul lizibil și precis îl face un limbaj de programare prietenos pentru începători.
3. Este AI și învățarea automată la fel?
Deși termenii AI și învățarea automată sunt adesea folosiți interschimbabil, ei nu sunt la fel. Inteligența artificială (IA) este termenul umbrelă pentru ramura informaticii care se ocupă cu mașini capabile să îndeplinească sarcini realizate de obicei de oameni. Dar învățarea automată este un subset al AI în care mașinile sunt alimentate cu date și instruite să ia decizii pe baza datelor de intrare.