
15 întrebări și răspunsuri la interviu de învățare automată pentru 2022
Publicat: 2021-01-08Ești cineva care dorește să facă o carieră de succes în învățare automată? Dacă da, grozav pentru tine!
Dar mai întâi trebuie să te pregătești pentru spărgătorul de gheață – interviul ML.
Deoarece procesul de pregătire pentru un interviu poate fi copleșitor, am decis să intervenim – iată o listă organizată cu 15 întrebări cele mai frecvente în interviurile de învățare automată!
- Care este diferența dintre Deep Learning și Machine Learning?
În timp ce învățarea automată implică aplicarea și utilizarea algoritmilor avansați pentru a analiza datele, a descoperi tiparele ascunse din date și a învăța din acestea și, în sfârșit, a aplica informațiile învățate pentru a lua decizii de afaceri informate. În ceea ce privește Deep Learning, este un subset al Machine Learning care implică utilizarea rețelelor neuronale artificiale care se inspiră din structura rețelei neuronale a creierului uman. Deep Learning este utilizat pe scară largă în detectarea caracteristicilor.
- Definire – Precizie și rechemare.
Precizia sau Valoarea Predictivă Pozitivă măsoară sau mai precis prezice numărul de pozitive adevărate revendicate de un model în comparație cu numărul de pozitive pe care le pretinde de fapt.
Rechemarea sau rata pozitivă adevărată se referă la numărul de elemente pozitive declarate de un model în comparație cu numărul real de elemente pozitive prezente în datele.

Alăturați-vă Cursului de învățare automată online de la cele mai bune universități din lume – Master, Programe Executive Postuniversitare și Program de Certificat Avansat în ML și AI pentru a vă accelera cariera.
- Explicați termenii „bias” și „varianță”. '
În timpul procesului de instruire, eroarea așteptată a unui algoritm de învățare este în general clasificată sau descompusă în două părți – părtinire și varianță. În timp ce „bias” este o situație de eroare cauzată de utilizarea unor ipoteze simple în algoritmul de învățare, „varianța” denotă o eroare cauzată din cauza complexității acelui algoritm de învățare în analiza datelor. Bias măsoară proximitatea clasificatorului mediu creat de algoritmul de învățare față de funcția țintă, iar varianța măsoară în funcție de cât de mult variază predicția algoritmului de învățare pentru diferite seturi de date de antrenament.
- Cum funcționează o curbă ROC?
Curba ROC sau caracteristica de funcționare a receptorului este o reprezentare grafică a variației dintre ratele pozitive adevărate și ratele pozitive fals la diferite praguri. Este un instrument fundamental pentru evaluarea testului de diagnostic și este adesea folosit ca o reprezentare a compromisului dintre sensibilitatea modelului (pozitive adevărate) și probabilitatea declanșării alarmelor false (pozitive false).
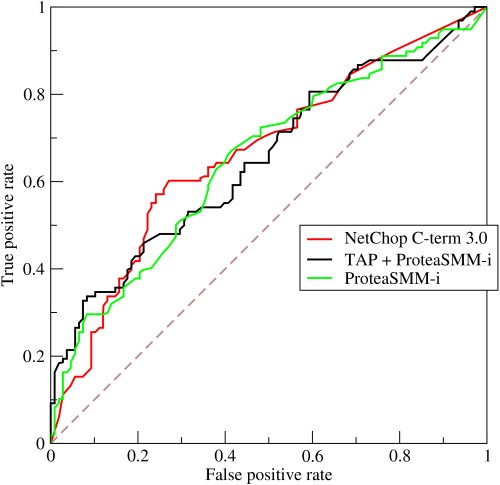
Sursă
- Curba ilustrează compromisul dintre sensibilitate și specificitate - dacă sensibilitatea crește, specificitatea va scădea.
- Dacă curba mărginește mai mult spre axa din stânga și partea de sus a spațiului ROC, testul este de obicei mai precis. Cu toate acestea, dacă curba se apropie de diagonala de 45 de grade a spațiului ROC, testul este mai puțin precis sau mai fiabil.
- Panta liniei tangente la un punct de tăiere indică raportul de probabilitate (LR) pentru acea valoare particulară a testului.
- Aria de sub curbă măsoară precizia testului.
- Explicați diferența dintre erorile de tip 1 și tip 2?
Eroarea de tip 1 este o eroare fals pozitivă care „pretinde” că un incident a avut loc atunci când, de fapt, nu s-a întâmplat nimic. Cel mai bun exemplu de eroare fals pozitivă este o alarmă falsă de incendiu – alarma începe să sune când nu există incendiu. Spre deosebire de aceasta, o eroare de tip 2 este o eroare fals negativă care „pretinde” că nu s-a întâmplat nimic atunci când ceva s-a întâmplat cu siguranță. Ar fi o eroare de tip 2 să-i spui unei femei însărcinate că nu poartă un copil.
- De ce Bayes este numit „Naive Bayes?”
Naive Bayes este denumit „naiv” deoarece, deși are multe aplicații practice, se bazează pe presupunerea că este imposibil de găsit în datele din viața reală - toate caracteristicile dintr-un set de date sunt cruciale, independente și egale. În abordarea Naive Bayes, probabilitatea condiționată este calculată ca produsul pur al probabilităților componentelor individuale, implicând astfel independența completă a caracteristicilor. Din păcate, această presupunere nu poate fi niciodată îndeplinită într-un scenariu din lumea reală.
- Ce se înțelege prin termenul „Suprafitting”? Îl poți evita? Dacă da, cum?
De obicei, în timpul procesului de instruire, un model este alimentat cu cantități mari de date. Pe parcursul procesului, datele încep să învețe chiar și din informațiile inexacte și zgomotul prezent în setul de date eșantion. Acest lucru creează o influență negativă asupra performanței modelului asupra datelor noi, adică modelul nu poate clasifica cu acuratețe noi instanțe/date în afară de cele ale setului de antrenament. Acest lucru este cunoscut sub numele de supraajustare.
Da, este posibil să se evite supraadaptarea. Iată cum:
- Adunați mai multe date (din surse disparate) pentru a antrena modelul cu mostre diferite.
- Aplicați metode de ansamblu (de exemplu, Random Forest) care utilizează abordarea însacării pentru a minimiza variația predicțiilor juxtapunând rezultatele mai multor arbori de decizie pe diferite unități ale setului de date.
- Asigurați-vă că utilizați tehnici de validare încrucișată.
- Numiți cele două metode utilizate pentru calibrare în Învățare supravegheată.
Cele două metode de calibrare din învățarea supervizată sunt – Calibrarea Platt și Regresia izotonică. Ambele metode sunt concepute special pentru clasificarea binară.
- De ce tăiați un arbore de decizie?
Arborii de decizie trebuie tăiați pentru a scăpa de ramurile cu abilități predictive slabe. Acest lucru ajută la minimizarea coeficientului de complexitate al modelului Arborele de decizie și la optimizarea acurateței sale predictive. Tunderea se poate face fie de sus în jos, fie de jos în sus. Tăierea cu erori reduse, tăierea complexității costurilor, tăierea complexității erorilor și tăierea cu erori minime sunt unele dintre cele mai utilizate metode de tăiere a arborelui de decizie.

- Ce se înțelege prin scor F1?
În termeni simpli, scorul F1 este o măsură a performanței unui model – o medie a preciziei și a reamintirii unui model, cu rezultate apropiate de 1 fiind cele mai bune și cele apropiate de 0 fiind cele mai proaste. Scorul F1 poate fi folosit în testele de clasificare care nu acordă importanță negative adevărate.
- Faceți diferența între un algoritm generativ și un algoritm discriminativ.
În timp ce un algoritm generativ învață categoriile de date, un algoritm discriminativ învață distincția dintre diferitele categorii de date. Când vine vorba de sarcini de clasificare, modelele discriminative depășesc de obicei modelele generative.
- Ce este învățarea prin ansamblu?
Ensemble Learning utilizează o combinație de algoritmi de învățare pentru a optimiza performanța predictivă a modelelor. În această metodă, mai multe modele, cum ar fi clasificatorii sau experții, sunt atât generate strategic, cât și combinate pentru a preveni supraadaptarea în modele. Este folosit mai ales pentru a îmbunătăți predicția, clasificarea, aproximarea funcției, performanța etc. a unui model.
- Definiți „Trucul nucleului”.
Metoda Kernel Trick implică utilizarea funcțiilor kernelului care pot opera într-un spațiu de caracteristici implicite și de dimensiuni mai mari, fără a fi nevoie să calculeze coordonatele punctelor din acea dimensiune în mod explicit. Funcțiile kernelului calculează produsele interioare dintre imaginile tuturor perechilor de date prezente într-un spațiu caracteristic. Această procedură este mai ieftină din punct de vedere computațional în comparație cu calculul explicit al coordonatelor și este cunoscută sub numele de Kernel Trick.
- Cum ar trebui să gestionați datele lipsă sau corupte dintr-un set de date?
Pentru a găsi datele lipsă/corupte dintr-un set de date, trebuie fie să renunțați la rândurile și coloanele, fie să le înlocuiți cu alte valori. Biblioteca Pandas are două metode excelente de a găsi date lipsă/corupte – isnull() și dropna(). Ambele funcții sunt concepute special pentru a vă ajuta să găsiți rândurile/coloanele de date cu date lipsă/corupte și să eliminați acele valori.
- Ce este un tabel Hash?
Un tabel hash este o structură de date care creează o matrice asociativă, în care o cheie este mapată la anumite valori folosind o funcție hash. Tabelele hash sunt utilizate mai ales în indexarea bazelor de date.
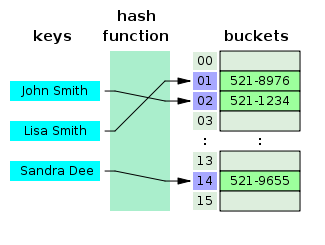
Sursă
Această listă de întrebări este menită doar să vă prezinte elementele de bază ale învățării automate și, sincer, aceste douăzeci de întrebări sunt doar o picătură în mare. Învățarea automată avansează pe măsură ce vorbim și, prin urmare, cu timpul, vor apărea noi concepte. Prin urmare, cheia pentru a-ți obține interviurile ML constă în a găzdui un dorință constantă de a învăța și de a îmbunătăți abilitățile. Așadar, începeți și flagelează Internetul, citiți jurnale, alăturați-vă comunităților online, participați la conferințe și seminarii ML - există atât de multe moduri de a învăța.
Pentru a intra într-o organizație mare, este esențial un certificat de la o instituție de renume. Consultați programul Executive PG al IIIT-B în Machine Learning și AI și obțineți asistență pentru locuri de muncă de la firmele de top ML și AI.
Care sunt limitările învățării prin ansamblu?
Abordările de ansamblu pot ajuta la reducerea varianței și la dezvoltarea unor modele mai robuste. Cu toate acestea, există anumite dezavantaje în utilizarea tehnicilor de ansamblu, cum ar fi lipsa de explicabilitate și performanță. Mai mult, rețineți că eficacitatea ansamblurilor provine din capacitatea lor de a agrega mai multe modele care se concentrează pe diferite aspecte ale problemei. Cu toate acestea, au o perioadă de prognoză mai lungă, deoarece este posibil să aveți nevoie de prognoze de la sute de modele. Chiar dacă au proiecții mai bune, câștigul în precizie poate să nu merite.
Cât timp este nevoie pentru a învăța Machine Learning?
Când vine vorba de Machine Learning, tehnologiile complexe utilizate pentru același lucru ar putea să sperie cu ușurință oamenii. Cu toate acestea, înțelegerea ei pas cu pas nu este dificilă. Experiența anterioară în statistică, matematică avansată și așa mai departe vă va ajuta, fără îndoială, să înțelegeți rapid toate conceptele. Cu toate acestea, deoarece mediul educațional și abilitățile variază de la o persoană la alta, un individ poate învăța ML în trei săptămâni, în timp ce altul poate avea nevoie de un an.
Cum este folosită învățarea automată în viața noastră de zi cu zi?
Gmail clasifică e-mailurile ca fiind esențiale, sortându-le ca Principale, Promoții, Sociale și Actualizare folosind Machine Learning. Companiile folosesc rețelele neuronale pentru a detecta tranzacțiile frauduloase pe baza unor date precum cea mai recentă frecvență a tranzacțiilor, valoarea tranzacției și tipul de comerciant. Detectoarele de plagiat folosesc și învățarea automată. Când vine vorba de inginerie ML, este nevoie de aproximativ șase luni pentru a finaliza.