
Clasificator KNN pentru învățare automată: tot ce trebuie să știți
Publicat: 2021-09-28Îți amintești vremea când inteligența artificială (AI) era doar un concept limitat la romane și filme SF? Ei bine, datorită progresului tehnologic, AI este ceva cu care trăim acum în fiecare zi. De când Alexa și Siri sunt la dispoziție și apelează la platformele OTT care „alege manual” filmele pe care am dori să le vizionam, AI a devenit aproape la ordinea zilei și este aici să spună pentru viitorul previzibil.
Toate acestea sunt posibile datorită algoritmilor ML avansați. Astăzi, vom vorbi despre un astfel de algoritm ML util, Clasificatorul K-NN.
O ramură a inteligenței artificiale și a informaticii, învățarea automată folosește date și algoritmi pentru a imita înțelegerea umană, îmbunătățind treptat acuratețea algoritmilor. Învățarea automată implică antrenarea algoritmilor pentru a face predicții sau clasificări și pentru a descoperi informații cheie care conduc la luarea deciziilor strategice în cadrul companiilor și aplicațiilor.
Algoritmul KNN (k-nearest neighbour) este un algoritm fundamental de învățare automată supravegheat, utilizat pentru a rezolva declarațiile problemelor de regresie și clasificare. Deci, haideți să descoperim mai multe despre K-NN Classifier.
Cuprins
Învățare automată supravegheată versus nesupravegheată
Învățarea supravegheată și nesupravegheată sunt două abordări de bază ale științei datelor și este pertinent să cunoaștem diferența înainte de a intra în detaliile KNN.
Învățarea supravegheată este o abordare de învățare automată care utilizează seturi de date etichetate pentru a ajuta la prezicerea rezultatelor. Astfel de seturi de date sunt concepute pentru a „supraveghea” sau antrena algoritmii pentru a prezice rezultate sau a clasifica datele cu acuratețe. Prin urmare, intrările și ieșirile etichetate permit modelului să învețe în timp, îmbunătățind în același timp acuratețea.

Învățarea supravegheată implică două tipuri de probleme – clasificarea și regresia. În problemele de clasificare , algoritmii alocă datele de testare în categorii discrete, cum ar fi separarea pisicilor de câini.
Un exemplu semnificativ din viața reală ar fi clasificarea e-mailurilor spam într-un folder separat de căsuța dvs. de e-mail. Pe de altă parte, metoda de regresie a învățării supravegheate antrenează algoritmi pentru a înțelege relația dintre variabilele independente și dependente. Utilizează diferite puncte de date pentru a prezice valori numerice, cum ar fi proiectarea veniturilor din vânzări pentru o afacere.
Învățarea nesupravegheată , dimpotrivă, folosește algoritmi de învățare automată pentru analiza și gruparea seturi de date neetichetate. Astfel, nu este nevoie de intervenția umană („nesupravegheată”) pentru ca algoritmii să identifice modele ascunse în date.
Modelele de învățare nesupravegheată au trei aplicații principale – asociere, grupare și reducerea dimensionalității. Cu toate acestea, nu vom intra în detalii, deoarece este în afara domeniului nostru de discuție.
K-Cel mai apropiat vecin (KNN)
K-Nearest Neighbor sau algoritmul KNN este un algoritm de învățare automată bazat pe modelul de învățare supravegheată. Algoritmul K-NN funcționează presupunând că lucruri similare există aproape unele de altele. Prin urmare, algoritmul K-NN utilizează similaritatea caracteristicilor dintre noile puncte de date și punctele din setul de antrenament (cazuri disponibile) pentru a prezice valorile noilor puncte de date. În esență, algoritmul K-NN atribuie o valoare celui mai recent punct de date în funcție de cât de mult seamănă cu punctele din setul de antrenament. Algoritmul K-NN își găsește aplicație atât în probleme de clasificare, cât și în probleme de regresie, dar este utilizat în principal pentru probleme de clasificare.
Iată un exemplu pentru a înțelege clasificatorul K-NN.

Sursă
În imaginea de mai sus, valoarea de intrare este o creatură cu asemănări atât cu o pisică, cât și cu un câine. Cu toate acestea, dorim să-l clasificăm fie într-o pisică, fie într-un câine. Deci, putem folosi algoritmul K-NN pentru această clasificare. Modelul K-NN va găsi asemănări între noul set de date (intrare) și imaginile disponibile de pisici și câini (setul de date de dresaj). Ulterior, modelul va pune noul punct de date fie în categoria pisici, fie în categoria câine, pe baza celor mai asemănătoare caracteristici.
La fel, categoria A (puncte verzi) și categoria B (puncte portocalii) au exemplul grafic de mai sus. Avem și un nou punct de date (punct albastru) care se va încadra în oricare dintre categorii. Putem rezolva această problemă de clasificare folosind un algoritm K-NN și putem identifica noua categorie de puncte de date.
Definirea proprietăților algoritmului K-NN
Următoarele două proprietăți definesc cel mai bine algoritmul K-NN:
- Este un algoritm de învățare leneș, deoarece în loc să învețe imediat din setul de antrenament, algoritmul K-NN stochează setul de date și se antrenează din setul de date în momentul clasificării.
- K-NN este, de asemenea, un algoritm non-parametric , ceea ce înseamnă că nu face ipoteze despre datele de bază.
Funcționarea algoritmului K-NN
Acum, să aruncăm o privire la următorii pași pentru a înțelege cum funcționează algoritmul K-NN.
Pasul 1: Încărcați datele de antrenament și de testare.
Pasul 2: Alegeți cele mai apropiate puncte de date, adică valoarea lui K.
Pasul 3: Calculați distanța K numărului de vecini (distanța dintre fiecare rând de date de antrenament și datele de testare). Metoda euclidiană este cel mai frecvent utilizată pentru calcularea distanței.
Pasul 4: Luați K vecini cei mai apropiați pe baza distanței euclidiene calculate.
Pasul 5: Printre cei mai apropiați vecini K, numărați numărul de puncte de date din fiecare categorie.
Pasul 6: Alocați noile puncte de date acelei categorii pentru care numărul de vecini este maxim.
Pasul 7: Sfârșit. Modelul este acum gata.
Alăturați-vă cursurilor de inteligență artificială online de la cele mai bune universități din lume – masterat, programe executive postuniversitare și program de certificat avansat în ML și AI pentru a vă accelera cariera.
Alegerea valorii lui K
K este un parametru critic în algoritmul K-NN. Prin urmare, trebuie să ținem cont de câteva puncte înainte de a decide asupra unei valori a lui K.
Utilizarea curbelor de eroare este o metodă comună pentru a determina valoarea lui K. Imaginea de mai jos arată curbele de eroare pentru diferite valori K pentru datele de testare și antrenament.


Sursă
În exemplul grafic de mai sus, eroarea trenului este zero la K=1 în datele de antrenament, deoarece cel mai apropiat vecin de punct este punctul însuși. Cu toate acestea, eroarea testului este mare chiar și la valori scăzute ale lui K. Aceasta se numește varianță mare sau supraadaptare a datelor. Eroarea de test se reduce pe măsură ce creștem valoarea lui K., Dar după o anumită valoare a lui K, vedem că eroarea de test crește din nou, numită bias sau underfitting. Astfel, eroarea datelor de testare este inițial mare din cauza variației, ulterior scade și se stabilizează, iar odată cu creșterea suplimentară a valorii lui K, eroarea testului crește din nou din cauza părtinirii.
Prin urmare, valoarea lui K la care eroarea testului se stabilizează și este scăzută este luată drept valoare optimă a lui K. Luând în considerare curba de eroare de mai sus, K=8 este valoarea optimă.
Un exemplu pentru a înțelege funcționarea algoritmului K-NN
Luați în considerare un set de date care a fost reprezentat după cum urmează:

Sursă
Să presupunem că există un nou punct de date (punct negru) la (60,60) pe care trebuie să-l clasificăm fie în clasa violet, fie în roșu. Vom folosi K=3, ceea ce înseamnă că noul punct de date va găsi trei puncte de date cele mai apropiate, două în clasa roșie și unul în clasa violet.
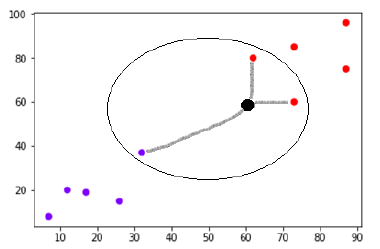
Sursă
Cei mai apropiați vecini se determină prin calcularea distanței euclidiene dintre două puncte. Iată o ilustrație pentru a arăta cum se face calculul.

Sursă
Acum, deoarece doi (din cei trei) dintre cei mai apropiați vecini ai noului punct de date (punct negru) se află în clasa roșie, noul punct de date va fi de asemenea atribuit clasei roșii.
Alăturați-vă Cursului de învățare automată online de la cele mai bune universități din lume – Master, Programe Executive Postuniversitare și Program de Certificat Avansat în ML și AI pentru a vă accelera cariera.
K-NN ca clasificator (implementare în Python)
Acum că am avut o explicație simplificată a algoritmului K-NN, să trecem prin implementarea algoritmului K-NN în Python. Ne vom concentra doar pe K-NN Classifier.
Pasul 1: importați pachetele Python necesare.

Sursă
Pasul 2: Descărcați setul de date iris din arhiva UCI Machine Learning. Link-ul său web este „https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data”
Pasul 3: Atribuiți nume de coloane setului de date.

Sursă
Pasul 4: Citiți setul de date în Pandas DataFrame.

Sursă
Pasul 5: Preprocesarea datelor se face folosind următoarele linii de script.

Sursă
Pasul 6: Împărțiți setul de date în test și tren. Codul de mai jos va împărți setul de date în 40% date de testare și 60% date de antrenament.

Sursă
Pasul 7: Scalarea datelor se face după cum urmează:

Sursă
Pasul 8: Antrenați modelul folosind clasa KNeighborsClassifier de sklearn.

Sursă
Pasul 9: Faceți o predicție folosind următorul script:

Sursă
Pasul 10: Imprimați rezultatele.

Sursă
Ieșire:

Sursă
Ce urmează? Înscrieți-vă la Programul de certificat avansat în învățare automată de la IIT Madras și upGrad
Să presupunem că aspirați să deveniți un Data Scientist sau un profesionist în învățare automată. În acest caz, Cursul avansat de certificare în Machine Learning și Cloud de la IIT Madras și upGrad este doar pentru tine!
Programul online de 12 luni este special conceput pentru profesioniștii care lucrează care doresc să stăpânească concepte în Machine Learning, Big Data Processing, Data Management, Data Warehousing, Cloud și implementarea modelelor de Machine Learning.
Iată câteva puncte importante ale cursului pentru a vă oferi o idee mai bună despre ceea ce oferă programul:
- Certificare de prestigiu acceptată la nivel global de la IIT Madras
- Peste 500 de ore de învățare, peste 20 de studii de caz și proiecte, peste 25 de sesiuni de mentorat în industrie, peste 8 sarcini de codare
- Acoperire cuprinzătoare a 7 limbaje și instrumente de programare
- 4 săptămâni de proiect capstone al industriei
- Ateliere practice practice
- Rețea offline peer-to-peer
Înscrie-te astăzi pentru a afla mai multe despre program!
Concluzie
Cu timpul, Big Data continuă să crească, iar inteligența artificială devine din ce în ce mai împletită cu viețile noastre. Ca urmare, există o creștere acută a cererii de profesioniști în știința datelor care pot valorifica puterea modelelor de învățare automată pentru a culege informații despre date și pentru a îmbunătăți procesele de afaceri critice și, în general, lumea noastră. Fără îndoială, domeniul inteligenței artificiale și al învățării automate arată într-adevăr promițător. Cu upGrad , poți fi sigur că cariera ta în învățarea automată și cloud este una plină de satisfacții!
De ce este K-NN un bun clasificator?
Avantajul principal al K-NN față de alți algoritmi de învățare automată este că putem folosi K-NN în mod convenabil pentru clasificarea multiclasă. Astfel, K-NN este cel mai bun algoritm dacă trebuie să clasificăm datele în mai mult de două categorii sau dacă datele cuprind mai mult de două etichete. În plus, este ideal pentru date neliniare și are o precizie relativ ridicată.
Care este limitarea algoritmului K-NN?
Algoritmul K-NN funcționează prin calcularea distanței dintre punctele de date. Prin urmare, este destul de evident că este un algoritm care consumă mai mult timp și va dura mai mult timp pentru a clasifica în unele cazuri. Prin urmare, este mai bine să nu folosiți prea multe puncte de date în timp ce utilizați K-NN pentru clasificarea multiclasă. Alte limitări includ stocarea în memorie mare și sensibilitatea la caracteristicile irelevante.
Care sunt aplicațiile reale ale K-NN?
K-NN are mai multe cazuri de utilizare în viața reală în învățarea automată, cum ar fi detectarea scrisului de mână, recunoașterea vorbirii, recunoașterea video și recunoașterea imaginilor. În domeniul bancar, K-NN este folosit pentru a prezice dacă o persoană este eligibilă pentru un împrumut, pe baza faptului că are caracteristici similare celor care ne plătesc. În politică, K-NN poate fi folosit pentru a clasifica potențialii alegători în diferite clase, cum ar fi „va vota pentru partidul X” sau „va vota pentru partidul Y” etc.