
Vă prezentăm API-ul bazat pe componente
Publicat: 2022-03-10Acest articol a fost actualizat pe 31 ianuarie 2019 pentru a reacționa la feedback-ul cititorilor. Autorul a adăugat capabilități de interogare personalizate la API-ul bazat pe componente și descrie cum funcționează .
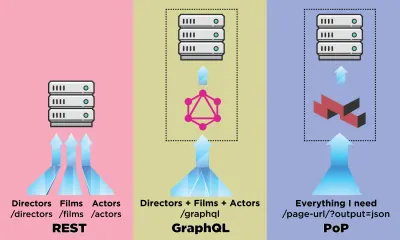
Un API este canalul de comunicare pentru o aplicație pentru a încărca date de pe server. În lumea API-urilor, REST a fost cea mai consacrată metodologie, dar în ultima perioadă a fost umbrită de GraphQL, care oferă avantaje importante față de REST. În timp ce REST necesită mai multe solicitări HTTP pentru a prelua un set de date pentru a reda o componentă, GraphQL poate interoga și regăsi astfel de date într-o singură solicitare, iar răspunsul va fi exact ceea ce este necesar, fără a prelua datele în exces, așa cum se întâmplă de obicei în ODIHNĂ.
În acest articol, voi descrie un alt mod de preluare a datelor pe care l-am proiectat și numit „PoP” (și open source aici), care extinde ideea de a prelua date pentru mai multe entități într-o singură solicitare introdusă de GraphQL și o ia un pas mai departe, adică în timp ce REST preia datele pentru o resursă și GraphQL preia datele pentru toate resursele dintr-o componentă, API-ul bazat pe componente poate prelua datele pentru toate resursele din toate componentele într-o singură pagină.
Folosirea unui API bazat pe componente are cel mai mult sens atunci când site-ul web este construit folosind componente, adică atunci când pagina web este compusă iterativ din componente care împachetează alte componente până când, în partea de sus, obținem o singură componentă care reprezintă pagina. De exemplu, pagina web prezentată în imaginea de mai jos este construită cu componente, care sunt conturate cu pătrate:
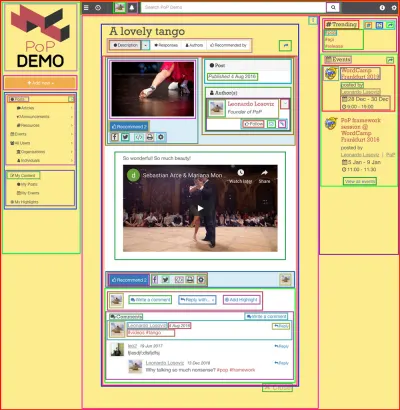
Un API bazat pe componente este capabil să facă o singură cerere către server, solicitând datele pentru toate resursele din fiecare componentă (precum și pentru toate componentele din pagină), ceea ce se realizează prin păstrarea relațiilor dintre componente în structura API în sine.
Printre altele, această structură oferă următoarele mai multe beneficii:
- O pagină cu mai multe componente va declanșa o singură solicitare în loc de multe;
- Datele partajate între componente pot fi preluate o singură dată din DB și imprimate o singură dată în răspuns;
- Poate reduce foarte mult – chiar și elimina complet – nevoia unui depozit de date.
Le vom explora în detaliu pe parcursul articolului, dar, mai întâi, să explorăm ce componente sunt de fapt și cum putem construi un site bazat pe astfel de componente și, în sfârșit, să explorăm cum funcționează un API bazat pe componente.
Lectură recomandată : A GraphQL Primer: De ce avem nevoie de un nou tip de API
Construirea unui șantier prin componente
O componentă este pur și simplu un set de bucăți de cod HTML, JavaScript și CSS puse împreună pentru a crea o entitate autonomă. Acest lucru poate apoi înfășura alte componente pentru a crea structuri mai complexe și poate fi învelit în sine de alte componente. O componentă are un scop, care poate varia de la ceva foarte elementar (cum ar fi un link sau un buton) până la ceva foarte elaborat (cum ar fi un carusel sau un dispozitiv de încărcare a imaginilor cu drag-and-drop). Componentele sunt cele mai utile atunci când sunt generice și permit personalizarea prin proprietăți injectate (sau „recuzită”), astfel încât să poată servi o gamă largă de cazuri de utilizare. În cel mai mare caz, site-ul în sine devine o componentă.
Termenul „componentă” este adesea folosit pentru a se referi atât la funcționalitate, cât și la design. De exemplu, în ceea ce privește funcționalitatea, cadrele JavaScript, cum ar fi React sau Vue, permit crearea de componente pe partea clientului, care sunt capabile să se auto-renda (de exemplu, după ce API-ul preia datele necesare) și să folosească elemente de recuzită pentru a seta valorile de configurare pe componente împachetate, permițând reutilizarea codului. În ceea ce privește designul, Bootstrap a standardizat modul în care arată și se simt site-urile prin intermediul bibliotecii sale de componente front-end și a devenit o tendință sănătoasă pentru echipe de a crea sisteme de design pentru a-și menține site-urile, ceea ce permite diferiților membri ai echipei (designeri și dezvoltatori, dar și marketeri și vânzători) să vorbească o limbă unificată și să exprime o identitate consistentă.
Componentarea unui site este o modalitate foarte sensibilă de a face site-ul să devină mai ușor de întreținut. Site-urile care utilizează cadre JavaScript, cum ar fi React și Vue, sunt deja bazate pe componente (cel puțin pe partea client). Utilizarea unei biblioteci de componente precum Bootstrap nu face ca site-ul să fie neapărat bazat pe componente (ar putea fi un blob mare de HTML), cu toate acestea, încorporează conceptul de elemente reutilizabile pentru interfața cu utilizatorul.
Dacă site-ul este un blob mare de HTML, pentru a-l componente trebuie să împărțim aspectul într-o serie de modele recurente, pentru care trebuie să identificăm și să catalogăm secțiunile din pagină pe baza similitudinii lor de funcționalitate și stiluri și să le spargem. secțiunile în straturi, cât mai granulare posibil, încercând ca fiecare strat să fie concentrat pe un singur scop sau acțiune și, de asemenea, încercând să potriviți straturi comune în diferite secțiuni.
Notă : „Designul atomic” al lui Brad Frost este o metodologie excelentă pentru identificarea acestor modele comune și construirea unui sistem de proiectare reutilizabil.
Prin urmare, construirea unui site prin componente este asemănătoare cu jocul cu LEGO. Fiecare componentă este fie o funcționalitate atomică, fie o compoziție a altor componente, fie o combinație a celor două.
După cum se arată mai jos, o componentă de bază (un avatar) este compusă iterativ din alte componente până la obținerea paginii web în partea de sus:

Specificația API bazată pe componente
Pentru API-ul bazat pe componente pe care l-am proiectat, o componentă se numește „modul”, așa că de acum încolo termenii „component” și „modul” sunt folosiți interschimbabil.
Relația dintre toate modulele care se împachetează reciproc, de la modulul de sus până la ultimul nivel, se numește „ierarhia componentelor”. Această relație poate fi exprimată printr-o matrice asociativă (o matrice de cheie => proprietate) pe partea serverului, în care fiecare modul își indică numele ca atribut cheie și modulele sale interioare sub modules de proprietate. Apoi, API-ul codifică pur și simplu această matrice ca obiect JSON pentru consum:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }Relația dintre module este definită într-un mod strict de sus în jos: un modul înglobează alte module și știe cine sunt, dar nu știe - și nu-i pasă - care module îl împachetează.
De exemplu, în codul JSON de mai sus, module module-level1 știe că include module module-level11 -level11 și module-level12 și, în mod tranzitiv, știe, de asemenea, că include module-level121 ; dar modulul module-level11 nu-i pasă cine îl împachetează, prin urmare nu este conștient de module-level1 .
Având structura bazată pe componente, acum putem adăuga informațiile reale cerute de fiecare modul, care sunt clasificate fie în setări (cum ar fi valorile de configurare și alte proprietăți) și date (cum ar fi ID-urile obiectelor bazei de date interogate și alte proprietăți) , și plasate în consecință sub intrările modulesettings și moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } În continuare, API-ul va adăuga datele obiectului bazei de date. Aceste informații nu sunt plasate sub fiecare modul, ci într-o secțiune comună numită databases de date, pentru a evita duplicarea informațiilor atunci când două sau mai multe module diferite preiau aceleași obiecte din baza de date.
În plus, API-ul reprezintă datele obiectului bazei de date într-o manieră relațională, pentru a evita duplicarea informațiilor atunci când două sau mai multe obiecte diferite ale bazei de date sunt legate de un obiect comun (cum ar fi două postări având același autor). Cu alte cuvinte, datele obiectului bazei de date sunt normalizate.
Lectură recomandată : Construirea unui formular de contact fără server pentru site-ul dvs. static
Structura este un dicționar, organizat mai întâi sub fiecare tip de obiect și al doilea ID obiect, din care putem obține proprietățile obiectului:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }Acest obiect JSON este deja răspunsul de la API-ul bazat pe componente. Formatul său este o specificație în sine: atâta timp cât serverul returnează răspunsul JSON în formatul necesar, clientul poate consuma API-ul independent de modul în care este implementat. Prin urmare, API-ul poate fi implementat în orice limbă (care este una dintre frumusețile GraphQL: fiind o specificație și nu o implementare reală, ia permis să devină disponibil într-o multitudine de limbi.)
Notă : Într-un articol viitor, voi descrie implementarea mea a API-ului bazat pe componente în PHP (care este cel disponibil în repo).
Exemplu de răspuns API
De exemplu, răspunsul API de mai jos conține o ierarhie de componente cu două module, page => post-feed , unde modul post-feed preia postări de blog. Vă rugăm să rețineți următoarele:
- Fiecare modul știe care sunt obiectele sale interogate din proprietatea
dbobjectids(ID-urile4și9pentru postările de blog) - Fiecare modul cunoaște tipul de obiect pentru obiectele interogate din proprietățile
dbkeys(datele fiecărei postări se găsesc subposts, iar datele autorului postării, corespunzătoare autorului cu ID-ul dat subauthorproprietății postării , se găsesc subusers) - Deoarece datele obiectului bazei de date sunt relaționale,
authorproprietății conține ID-ul obiectului autor în loc să imprime direct datele autorului.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }Diferențele Preluarea datelor de la API-uri bazate pe resurse, pe schemă și pe componente
Să vedem cum se compară un API bazat pe componente, cum ar fi PoP, la preluarea datelor, cu un API bazat pe resurse, cum ar fi REST, și cu un API bazat pe schemă, cum ar fi GraphQL.
Să presupunem că IMDB are o pagină cu două componente care trebuie să preia date: „Regizor recomandat” (care arată o descriere a lui George Lucas și o listă a filmelor sale) și „Filme recomandate pentru tine” (care arată filme precum Star Wars: Episode I). — Amenințarea fantomă și Terminator ). Ar putea arata asa:
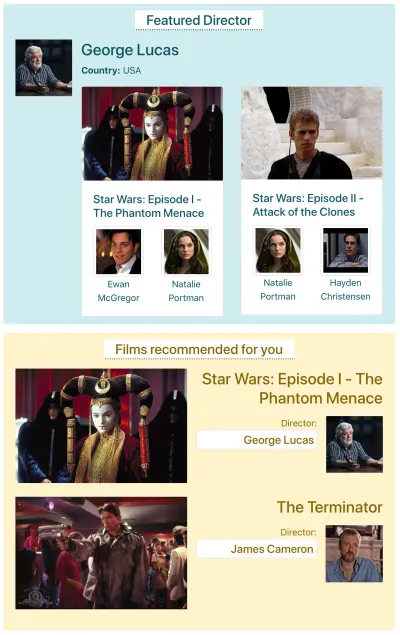
Să vedem câte solicitări sunt necesare pentru a prelua datele prin fiecare metodă API. Pentru acest exemplu, componenta „Regizor recomandat” aduce un rezultat („George Lucas”), din care preia două filme ( Star Wars: Episode I — The Phantom Menace și Star Wars: Episode II — Attack of the Clones ) și pentru fiecare film doi actori („Ewan McGregor” și „Natalie Portman” pentru primul film și „Natalie Portman” și „Hayden Christensen” pentru al doilea film). Componenta „Filme recomandate pentru tine” aduce două rezultate ( Star Wars: Episode I — The Phantom Menace și The Terminator ), iar apoi îi aduce pe regizori („George Lucas” și, respectiv, „James Cameron”).
Folosind REST pentru a reda componenta featured-director , este posibil să avem nevoie de următoarele 7 solicitări (acest număr poate varia în funcție de câte date sunt furnizate de fiecare punct final, adică cât de mult a fost implementată suprapreluare):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL permite, prin scheme puternic tipizate, să preia toate datele necesare într-o singură cerere per componentă. Interogarea de a prelua date prin GraphQL pentru componenta featuredDirector arată astfel (după ce am implementat schema corespunzătoare):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }Și produce următorul răspuns:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }Și interogarea pentru componenta „Filme recomandate pentru tine” produce următorul răspuns:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP va emite o singură solicitare pentru a prelua toate datele pentru toate componentele din pagină și va normaliza rezultatele. Punctul final care urmează să fie apelat este pur și simplu același cu adresa URL pentru care trebuie să obținem datele, adăugând doar un parametru suplimentar output=json pentru a indica aducerea datelor în format JSON în loc să le imprimăm ca HTML:
GET - /url-of-the-page/?output=json Presupunând că structura modulului are un modul superior numit page care conține modulele featured-director și films-recommended-for-you vou , iar acestea au, de asemenea, submodule, ca acesta:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"Singurul răspuns JSON returnat va arăta astfel:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }Să analizăm modul în care aceste trei metode se compară între ele, în ceea ce privește viteza și cantitatea de date recuperate.
Viteză
Prin REST, nevoia de a prelua 7 solicitări doar pentru a reda o componentă poate fi foarte lent, mai ales pe conexiuni de date mobile și instabile. Prin urmare, saltul de la REST la GraphQL reprezintă o mare parte pentru viteză, deoarece suntem capabili să redăm o componentă cu o singură solicitare.
PoP, deoarece poate prelua toate datele pentru mai multe componente într-o singură solicitare, va fi mai rapid pentru redarea mai multor componente simultan; cu toate acestea, cel mai probabil nu este nevoie de acest lucru. Faptul ca componentele să fie redate în ordine (așa cum apar în pagină), este deja o practică bună, iar pentru acele componente care apar sub fold, cu siguranță nu se grăbește să le redate. Prin urmare, atât API-urile bazate pe schemă, cât și cele bazate pe componente sunt deja destul de bune și net superioare unui API bazat pe resurse.
Cantitatea de date
La fiecare solicitare, datele din răspunsul GraphQL pot fi duplicate: actrița „Natalie Portman” este preluată de două ori în răspunsul de la prima componentă, iar când luăm în considerare producția comună pentru cele două componente, putem găsi și date partajate, cum ar fi filmul Războiul Stelelor: Episodul I – Amenințarea Fantomă .
PoP, pe de altă parte, normalizează datele bazei de date și le imprimă o singură dată, cu toate acestea, suportă supraîncărcarea tipăririi structurii modulului. Prin urmare, în funcție de cererea specială care are date duplicate sau nu, fie API-ul bazat pe schemă, fie API-ul bazat pe componente va avea o dimensiune mai mică.
În concluzie, un API bazat pe schemă, cum ar fi GraphQL și un API bazat pe componente, cum ar fi PoP, sunt la fel de bune în ceea ce privește performanța și sunt superioare unui API bazat pe resurse, cum ar fi REST.
Lectură recomandată : Înțelegerea și utilizarea API-urilor REST
Proprietăți particulare ale unui API bazat pe componente
Dacă un API bazat pe componente nu este neapărat mai bun în ceea ce privește performanța decât un API bazat pe schemă, s-ar putea să vă întrebați, atunci ce încerc să obțin cu acest articol?
În această secțiune, voi încerca să vă conving că un astfel de API are un potențial incredibil, oferind mai multe caracteristici care sunt foarte de dorit, făcându-l un competitor serios în lumea API-urilor. Descriu și demonstrez fiecare dintre caracteristicile sale extraordinare unice mai jos.
Datele care trebuie preluate din baza de date pot fi deduse din ierarhia componentelor
Când un modul afișează o proprietate dintr-un obiect DB, este posibil ca modulul să nu știe sau să nu-i pese de ce obiect este; tot ceea ce îi pasă este să definească ce proprietăți de la obiectul încărcat sunt necesare.
De exemplu, luați în considerare imaginea de mai jos. Un modul încarcă un obiect din baza de date (în acest caz, o singură postare), iar apoi modulele sale descendente vor afișa anumite proprietăți ale obiectului, cum ar fi title și content :
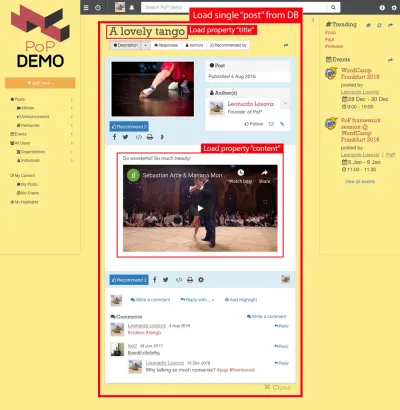
Prin urmare, de-a lungul ierarhiei componentelor, modulele de „încărcare de date” vor fi însărcinate cu încărcarea obiectelor interogate (modulul care încarcă un singur post, în acest caz), iar modulele sale descendente vor defini ce proprietăți din obiectul DB sunt necesare ( title și content , în acest caz).
Preluarea tuturor proprietăților necesare pentru obiectul DB se poate face automat prin parcurgerea ierarhiei componentelor: pornind de la modulul de încărcare a datelor, iterăm toate modulele sale descendente până la atingerea unui nou modul de încărcare a datelor, sau până la sfârșitul arborelui; la fiecare nivel obținem toate proprietățile necesare, apoi îmbinăm toate proprietățile și le interogăm din baza de date, toate o singură dată.
În structura de mai jos, modulul single-post preia rezultatele din DB (postul cu ID 37), iar submodulele post-title și post-content definesc proprietățile de încărcat pentru obiectul DB interogat ( title și respectiv content ); submodulele post-layout și fetch-next-post-button nu necesită câmpuri de date.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"Interogarea de executat este calculată automat din ierarhia componentelor și câmpurile de date necesare ale acestora, conținând toate proprietățile necesare tuturor modulelor și submodulelor acestora:
SELECT title, content FROM posts WHERE id = 37 Prin preluarea proprietăților pentru a le prelua direct din module, interogarea va fi actualizată automat ori de câte ori ierarhia componentelor se schimbă. Dacă, de exemplu, adăugăm apoi submodulul post-thumbnail , care necesită o thumbnail de câmp de date:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"Apoi interogarea este actualizată automat pentru a prelua proprietatea suplimentară:
SELECT title, content, thumbnail FROM posts WHERE id = 37Deoarece am stabilit ca datele obiectului bazei de date să fie recuperate într-o manieră relațională, putem aplica această strategie și între relațiile dintre obiectele bazei de date în sine.
Luați în considerare imaginea de mai jos: Pornind de la post tipului de obiect și deplasându-ne în jos în ierarhia componentelor, va trebui să schimbăm tipul de obiect DB la user și comment , corespunzătoare autorului postării și, respectiv, fiecare dintre comentariile postării, și apoi, pentru fiecare comentariu, trebuie să schimbe încă o dată tipul de obiect la user corespunzător autorului comentariului.
Trecerea de la un obiect de bază de date la un obiect relațional (eventual schimbarea tipului de obiect, ca în post => author care trece de la post la user , sau nu, ca în author => adepți care trec de la user la user ) este ceea ce eu numesc „schimbarea de domenii ”.
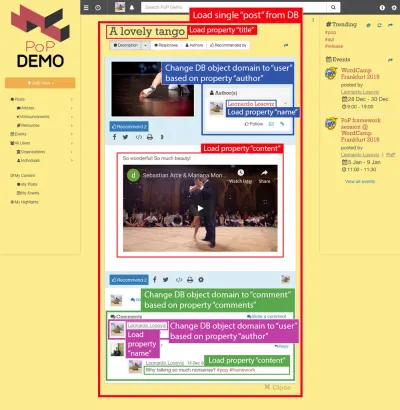
După trecerea la un domeniu nou, de la acel nivel la ierarhia componentelor în jos, toate proprietățile necesare vor fi supuse noului domeniu:
-
nameeste preluat de la obiectuluser(reprezentând autorul postării), -
contenteste preluat din obiectulcomment(reprezentând fiecare dintre comentariile postării), -
nameeste preluat de la obiectuluser(reprezentând autorul fiecărui comentariu).
Traversând ierarhia componentelor, API-ul știe când trece la un nou domeniu și, în mod corespunzător, actualizează interogarea pentru a prelua obiectul relațional.
De exemplu, dacă trebuie să arătăm date de la autorul postării, stivuirea submodulului post-author va schimba domeniul de la acel nivel de la post la user corespunzător, iar de la acest nivel în jos obiectul DB încărcat în contextul transmis modulului este utilizatorul. Apoi, submodulele user-name și user-avatar sub post-author vor încărca proprietățile name și avatar sub obiectul user :
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"Rezultă următoarea interogare:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idÎn rezumat, configurând fiecare modul în mod corespunzător, nu este nevoie să scrieți interogarea pentru a prelua date pentru un API bazat pe componente. Interogarea este produsă automat din structura ierarhiei componente în sine, obținându-se ce obiecte trebuie încărcate de modulele de încărcare a datelor, câmpurile de preluat pentru fiecare obiect încărcat definit la fiecare modul descendent și comutarea de domeniu definită la fiecare modul descendent.
Adăugarea, eliminarea, înlocuirea sau modificarea oricărui modul va actualiza automat interogarea. După executarea interogării, datele preluate vor fi exact ceea ce este necesar - nimic mai mult sau mai puțin.
Observarea datelor și calcularea proprietăților suplimentare
Pornind de la modulul de încărcare a datelor în jos în ierarhia componentelor, orice modul poate observa rezultatele returnate și poate calcula elemente de date suplimentare pe baza acestora, sau valori feedback , care sunt plasate sub intrarea moduledata .
De exemplu, modulul fetch-next-post-button poate adăuga o proprietate care indică dacă există mai multe rezultate de preluat sau nu (pe baza acestei valori de feedback, dacă nu există mai multe rezultate, butonul va fi dezactivat sau ascuns):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }Cunoașterea implicită a datelor necesare scade complexitatea și face ca conceptul de „punct final” să devină învechit
După cum se arată mai sus, API-ul bazat pe componente poate prelua exact datele necesare, deoarece are modelul tuturor componentelor de pe server și ce câmpuri de date sunt necesare pentru fiecare componentă. Apoi, poate face implicită cunoașterea câmpurilor de date solicitate.

Avantajul este că definirea ce date este cerută de componentă poate fi actualizată doar pe partea de server, fără a fi nevoie să redistribuiți fișierele JavaScript, iar clientul poate fi prost, cerând serverului să furnizeze orice date de care are nevoie. , scăzând astfel complexitatea aplicației pe partea client.
În plus, apelarea API-ului pentru a prelua datele pentru toate componentele pentru o anumită adresă URL poate fi efectuată pur și simplu prin interogarea acelei adrese URL plus adăugarea parametrului suplimentar output=json pentru a indica returnarea datelor API în loc de imprimarea paginii. Prin urmare, URL-ul devine propriul punct final sau, considerat într-un mod diferit, conceptul de „punct final” devine învechit.
Preluarea subseturi de date: datele pot fi preluate pentru module specifice, găsite la orice nivel al ierarhiei componentelor
Ce se întâmplă dacă nu trebuie să preluăm datele pentru toate modulele dintr-o pagină, ci pur și simplu datele pentru un anumit modul începând de la orice nivel al ierarhiei componentelor? De exemplu, dacă un modul implementează un derulare infinit, atunci când derulăm în jos trebuie să obținem doar date noi pentru acest modul, și nu pentru celelalte module de pe pagină.
Acest lucru poate fi realizat prin filtrarea ramurilor ierarhiei componentelor care vor fi incluse în răspuns, pentru a include proprietăți doar începând de la modulul specificat și a ignora tot ce este deasupra acestui nivel. În implementarea mea (pe care o voi descrie într-un articol următor), filtrarea este activată prin adăugarea parametrului modulefilter=modulepaths la adresa URL, iar modulul (sau modulele) selectat este indicat printr-un parametru modulepaths[] , unde „calea modulului ” este lista de module pornind de la modulul cel mai de sus la modulul specific (ex. module1 => module2 => module3 are calea modulului [ module1 , module2 , module3 ] și este transmis ca parametru URL ca module1.module2.module3 ) .
De exemplu, în ierarhia componentelor de mai jos fiecare modul are o intrare dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Apoi, solicitarea adresei URL a paginii web adăugând parametri modulefilter=modulepaths și modulepaths[]=module1.module2.module5 va produce următorul răspuns:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] În esență, API-ul începe să încarce date pornind de la module1 => module2 => module5 . De aceea module6 , care intră sub module5 , aduce și datele sale, în timp ce module3 și module4 nu.
În plus, putem crea filtre de module personalizate pentru a include un set pre-aranjat de module. De exemplu, apelarea unei pagini cu modulefilter=userstate poate imprima numai acele module care necesită starea utilizatorului pentru a le reda în client, cum ar fi modulele module3 și module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] Informațiile despre care sunt modulele de pornire sunt incluse în secțiunea requestmeta , sub intrare filteredmodules , ca o serie de căi de module:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }Această caracteristică permite implementarea unei aplicații necomplicate de o singură pagină, în care cadrul site-ului este încărcat la cererea inițială:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] Dar, de la ei încolo, putem adăuga parametrul modulefilter=page la toate adresele URL solicitate, eliminând cadrul și aducând numai conținutul paginii:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] Similar cu userstate și page descrise mai sus pentru filtrele de module, putem implementa orice filtru de modul personalizat și putem crea experiențe bogate pentru utilizatori.
Modulul este propriul său API
După cum se arată mai sus, putem filtra răspunsul API pentru a prelua date pornind de la orice modul. În consecință, fiecare modul poate interacționa cu el însuși de la client la server doar adăugând calea modulului la adresa URL a paginii web în care a fost inclus.
Sper că îmi veți scuza excesul de entuziasm, dar cu adevărat nu pot sublinia suficient cât de minunată este această caracteristică. Când creăm o componentă, nu trebuie să creăm un API pentru a merge alături de ea pentru a prelua date (REST, GraphQL sau orice altceva), deoarece componenta este deja capabilă să vorbească cu ea însăși pe server și să se încarce singur. date — este complet autonomă și autoservitoare .
Fiecare modul de încărcare a datelor exportă adresa URL pentru a interacționa cu aceasta sub intrarea dataloadsource din secțiunea datasetmodulemeta :
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }Preluarea datelor este decuplată între module și DRY
Pentru a-mi spune că preluarea datelor într-un API bazat pe componente este foarte decuplată și DRY ( Nu repetați-vă singur), va trebui mai întâi să arăt cum într-un API bazat pe schemă, cum ar fi GraphQL , este mai puțin decuplat și nu USCAT.
În GraphQL, interogarea de preluare a datelor trebuie să indice câmpurile de date pentru componentă, care pot include subcomponente, iar acestea pot include și subcomponente și așa mai departe. Apoi, componenta cea mai de sus trebuie să știe ce date sunt necesare pentru fiecare dintre subcomponentele sale, pentru a prelua acele date.
De exemplu, redarea componentei <FeaturedDirector> poate necesita următoarele subcomponente:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> În acest scenariu, interogarea GraphQL este implementată la nivelul <FeaturedDirector> . Apoi, dacă subcomponenta <Film> este actualizată, solicitând titlul prin proprietatea filmTitle în loc de title , va trebui actualizată și interogarea din componenta <FeaturedDirector> pentru a oglindi aceste informații noi (GraphQL are un mecanism de versiune care poate trata cu această problemă, dar mai devreme sau mai târziu ar trebui să actualizăm informațiile). Acest lucru produce complexitate de întreținere, care ar putea fi dificil de gestionat atunci când componentele interioare se schimbă adesea sau sunt produse de dezvoltatori terți. Prin urmare, componentele nu sunt complet decuplate unele de altele.
În mod similar, putem dori să redăm direct componenta <Film> pentru un anumit film, pentru care apoi trebuie să implementăm și o interogare GraphQL la acest nivel, pentru a prelua datele pentru film și actorii săi, care adaugă cod redundant: porțiuni de aceeași interogare va trăi la diferite niveluri ale structurii componente. Deci GraphQL nu este DRY .
Deoarece un API bazat pe componente știe deja cum componentele sale se îmbină reciproc în propria sa structură, atunci aceste probleme sunt complet evitate. În primul rând, clientul poate solicita pur și simplu datele necesare de care are nevoie, oricare ar fi aceste date; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
În API-ul bazat pe componente, totuși, putem folosi cu ușurință relațiile dintre modulele deja descrise în API pentru a cupla modulele împreună. Deși inițial vom avea acest răspuns:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }După adăugarea Instagram, vom avea răspunsul actualizat:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } Și doar prin iterarea tuturor valorilor din modulesettings["share-on-social-media"].modules , componenta <ShareOnSocialMedia> poate fi actualizată pentru a afișa componenta <InstagramShare> fără a fi nevoie să redistribuiți niciun fișier JavaScript. Prin urmare, API-ul acceptă adăugarea și eliminarea modulelor fără a compromite codul din alte module, atingând un grad mai mare de modularitate.
Cache/magazin de date nativ pe partea clientului
Datele recuperate ale bazei de date sunt normalizate într-o structură de dicționar și standardizate astfel încât, pornind de la valoarea de pe dbobjectids , orice bucată de date din bazele de databases poate fi atinsă doar urmând calea către aceasta așa cum este indicată prin intrările dbkeys , indiferent de modul în care a fost structurat. . Prin urmare, logica de organizare a datelor este deja nativă a API-ului în sine.
Putem beneficia de această situație în mai multe moduri. De exemplu, datele returnate pentru fiecare solicitare pot fi adăugate într-o memorie cache pe partea clientului care conține toate datele solicitate de utilizator pe parcursul sesiunii. Prin urmare, este posibil să evitați adăugarea unui depozit de date extern, cum ar fi Redux, la aplicație (mă refer la manipularea datelor, nu la alte caracteristici precum Undo/Redo, mediul de colaborare sau depanarea în timp).
De asemenea, structura bazată pe componente promovează stocarea în cache: ierarhia componentelor nu depinde de URL, ci de ce componente sunt necesare în acel URL. În acest fel, două evenimente din /events/1/ și /events/2/ vor împărtăși aceeași ierarhie a componentelor, iar informațiile despre ce module sunt necesare pot fi reutilizate peste ele. Ca o consecință, toate proprietățile (altele decât datele bazei de date) pot fi stocate în cache pe client după preluarea primului eveniment și reutilizate de atunci, astfel încât să fie preluate numai datele bazei de date pentru fiecare eveniment ulterior și nimic altceva.
Extensibilitate și reutilizare
Secțiunea databases de date a API-ului poate fi extinsă, permițând clasificarea informațiilor sale în subsecțiuni personalizate. În mod implicit, toate datele obiectului bazei de date sunt plasate sub intrarea primary , cu toate acestea, putem crea și intrări personalizate unde să plasăm proprietăți specifice obiectului DB.
De exemplu, dacă componenta „Filme recomandate pentru tine” descrisă mai devreme arată o listă cu prietenii utilizatorului conectat care au vizionat acest film sub proprietatea friendsWhoWatchedFilm pe obiectul DB film , deoarece această valoare se va modifica în funcție de persoana conectată. utilizator, apoi salvăm această proprietate sub o intrare userstate , așa că atunci când utilizatorul se deconectează, ștergem doar această ramură din baza de date stocată în cache a clientului, dar toate datele primary rămân în continuare:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }În plus, până la un anumit punct, structura răspunsului API poate fi reorientată. În special, rezultatele bazei de date pot fi tipărite într-o structură de date diferită, cum ar fi o matrice în loc de dicționarul implicit.
De exemplu, dacă tipul de obiect este unul singur (de exemplu films ), acesta poate fi formatat ca o matrice pentru a fi alimentat direct într-o componentă typeahead:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]Suport pentru programare orientată pe aspecte
Pe lângă preluarea datelor, API-ul bazat pe componente poate posta și date, cum ar fi pentru crearea unei postări sau adăugarea unui comentariu, și poate executa orice fel de operație, cum ar fi conectarea sau deconectarea utilizatorului, trimiterea de e-mailuri, înregistrarea în jurnal, analize, și așa mai departe. Nu există restricții: orice funcționalitate furnizată de CMS-ul de bază poate fi invocată printr-un modul — la orice nivel.
De-a lungul ierarhiei componentelor, putem adăuga orice număr de module, iar fiecare modul își poate executa propria operație. Prin urmare, nu toate operațiunile trebuie să fie neapărat legate de acțiunea așteptată a cererii, cum ar fi atunci când faceți o operație POST, PUT sau DELETE în REST sau trimiteți o mutație în GraphQL, dar pot fi adăugate pentru a oferi funcționalități suplimentare, cum ar fi trimiterea unui e-mail către administrator atunci când un utilizator creează o nouă postare.
Deci, prin definirea ierarhiei componentelor prin fișiere de injecție de dependență sau de configurare, se poate spune că API-ul suportă programarea orientată pe aspecte, „o paradigmă de programare care își propune să crească modularitatea permițând separarea preocupărilor transversale”.
Lectură recomandată : Protejarea site-ului dvs. cu politica de funcții
Securitate sporită
Numele modulelor nu sunt neapărat fixe atunci când sunt tipărite în ieșire, dar pot fi scurtate, alterate, schimbate aleatoriu sau (pe scurt) făcute variabile în orice mod dorit. Deși s-a gândit inițial pentru scurtarea ieșirii API (astfel încât denumirile modulelor carousel-featured-posts sau drag-and-drop-user-images ar putea fi scurtate la o notație de bază 64, cum ar fi a1 , a2 și așa mai departe, pentru mediul de producție ), această caracteristică permite schimbarea frecventă a numelor modulelor în răspunsul de la API din motive de securitate.
De exemplu, numele de intrare sunt denumite implicit ca modul corespunzător; apoi, module numite nume de username și password , care urmează să fie redate în client ca <input type="text" name="{input_name}"> și respectiv <input type="password" name="{input_name}"> , pot fi setate diferite valori aleatorii pentru numele lor de intrare (cum ar fi zwH8DSeG și QBG7m6EF astăzi și c3oMLBjo și c46oVgN6 mâine), ceea ce face mai dificilă pentru spammeri și roboții să vizeze site-ul.
Versatilitate prin modele alternative
Imbricarea modulelor permite ramificarea la un alt modul pentru a adăuga compatibilitate pentru un anumit mediu sau tehnologie, sau pentru a schimba unele stiluri sau funcționalități, apoi revenirea la ramura originală.
De exemplu, să presupunem că pagina web are următoarea structură:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" În acest caz, am dori ca site-ul web să funcționeze și pentru AMP, cu toate acestea, modulele module2 , module4 și module5 nu sunt compatibile cu AMP. Putem ramifica aceste module în module similare, compatibile cu AMP module2AMP , module4AMP și module5AMP , după care continuăm să încărcăm ierarhia componentelor originale, astfel încât numai aceste trei module sunt înlocuite (și nimic altceva):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"Acest lucru face destul de ușor generarea de ieșiri diferite dintr-o singură bază de cod, adăugând fork-uri doar ici și acolo, după cum este necesar, și întotdeauna acoperite și limitate la module individuale.
Ora demonstrației
Codul care implementează API-ul așa cum este explicat în acest articol este disponibil în acest depozit open-source.
Am implementat API-ul PoP sub https://nextapi.getpop.org în scopuri demonstrative. Site-ul web rulează pe WordPress, deci permalinkurile URL sunt cele tipice pentru WordPress. După cum sa menționat mai devreme, prin adăugarea parametrului output=json la ele, aceste adrese URL devin propriile lor puncte finale API.
Site-ul este susținut de aceeași bază de date de pe site-ul web PoP Demo, astfel încât o vizualizare a ierarhiei componentelor și a datelor preluate se poate face interogând aceeași adresă URL pe acest alt site web (de exemplu, vizitând https://demo.getpop.org/u/leo/ explică datele de pe https://nextapi.getpop.org/u/leo/?output=json ).
Linkurile de mai jos demonstrează API-ul pentru cazurile descrise mai devreme:
- Pagina principală, o singură postare, un autor, o listă de postări și o listă de utilizatori.
- Un eveniment, care se filtrează dintr-un anumit modul.
- O etichetă, module de filtrare care necesită starea utilizatorului și filtrare pentru a aduce doar o pagină dintr-o aplicație cu o singură pagină.
- O serie de locații, pentru a alimenta un tip înainte.
- Modele alternative pentru pagina „Cine suntem”: Normal, Printable, Embedable.
- Schimbarea numelor modulelor: original vs mutilat.
- Informații de filtrare: numai setările modulului, datele modulului plus datele bazei de date.
Concluzie
Un API bun este o piatră de temelie pentru a crea aplicații fiabile, ușor de întreținut și puternice. În acest articol, am descris conceptele care alimentează un API bazat pe componente care, cred, este un API destul de bun și sper că v-am convins și pe voi.
Până acum, proiectarea și implementarea API-ului a implicat mai multe iterații și a durat mai mult de cinci ani - și nu este încă complet gata. Cu toate acestea, este într-o stare destul de decentă, nu este gata pentru producție, ci ca un alfa stabil. În aceste zile, încă lucrez la el; lucrând la definirea specificației deschise, implementarea straturilor suplimentare (cum ar fi randarea) și scrierea documentației.
Într-un articol viitor, voi descrie cum funcționează implementarea mea a API-ului. Până atunci, dacă aveți vreo părere despre asta, indiferent dacă este pozitiv sau negativ, mi-ar plăcea să vă citesc comentariile de mai jos.
Actualizare (31 ianuarie): Capabilități de interogare personalizate
Alain Schlesser a comentat că un API care nu poate fi interogat personalizat de la client este lipsit de valoare, ducându-ne înapoi la SOAP, ca atare, nu poate concura nici cu REST, nici cu GraphQL. După ce am gândit câteva zile în comentariul său, a trebuit să recunosc că are dreptate. Cu toate acestea, în loc să resping API-ul bazat pe componente ca pe un efort bine-intenționat, dar nu chiar acolo, am făcut ceva mult mai bun: am ajuns să implementez capacitatea de interogare personalizată pentru el. Și funcționează ca un farmec!
În următoarele link-uri, datele pentru o resursă sau o colecție de resurse sunt preluate așa cum se face de obicei prin REST. Cu toate acestea, prin fields parametri putem specifica și ce date specifice să recuperăm pentru fiecare resursă, evitând extragerea sau preluarea insuficientă a datelor:
- O singură postare și o colecție de postări care adaugă parametri
fields=title,content,datetime - Un utilizator și o colecție de utilizatori care adaugă parametri
fields=name,username,description
Linkurile de mai sus demonstrează preluarea datelor numai pentru resursele interogate. Dar relațiile lor? De exemplu, să presupunem că vrem să recuperăm o listă de postări cu câmpurile "title" și "content" , comentariile fiecărei postări cu câmpurile "content" și "date" și autorul fiecărui comentariu cu câmpurile "name" și "url" . Pentru a realiza acest lucru în GraphQL, vom implementa următoarea interogare:
query { post { title content comments { content date author { name url } } } } Pentru implementarea API-ului bazat pe componente, am tradus interogarea în expresia „sintaxă punct” corespunzătoare, care poate fi apoi furnizată prin fields parametri . Interogând pe o resursă „post”, această valoare este:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url Sau poate fi simplificat, folosind | pentru a grupa toate câmpurile aplicate la aceeași resursă:
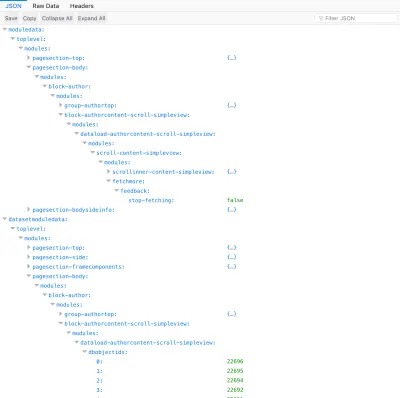
fields=title|content,comments.content|date,comments.author.name|urlCând executăm această interogare pe o singură postare, obținem exact datele necesare pentru toate resursele implicate:
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } Prin urmare, putem interoga resursele într-o manieră REST și putem specifica interogări bazate pe schemă într-o manieră GraphQL și vom obține exact ceea ce este necesar, fără a prelua sau a prelua datele excesive și a normaliza datele din baza de date, astfel încât să nu fie duplicate date. În mod favorabil, interogarea poate include orice număr de relații, imbricate în adâncime, iar acestea sunt rezolvate cu timp de complexitate liniară: cel mai rău caz de O(n+m), unde n este numărul de noduri care schimbă domeniul (în acest caz 2: comments and comments.author ) și m este numărul de rezultate preluate (în acest caz 5: 1 post + 2 comentarii + 2 utilizatori) și cazul mediu de O(n). (Acest lucru este mai eficient decât GraphQL, care are un timp de complexitate polinomial O(n^c) și suferă de creșterea timpului de execuție pe măsură ce crește adâncimea nivelului).
În cele din urmă, acest API poate aplica, de asemenea, modificatori atunci când interogând date, de exemplu pentru filtrarea resurselor care sunt preluate, așa cum se poate face prin GraphQL. Pentru a realiza acest lucru, API-ul se așează pur și simplu deasupra aplicației și poate utiliza convenabil funcționalitatea acesteia, astfel încât nu este nevoie să reinventați roata. De exemplu, adăugarea parametrilor filter=posts&searchfor=internet va filtra toate postările care conțin "internet" dintr-o colecție de postări.
Implementarea acestei noi caracteristici va fi descrisă într-un articol viitor.