
Conversie imagine în text cu React și Tesseract.js (OCR)
Publicat: 2022-03-10Datele sunt coloana vertebrală a fiecărei aplicații software, deoarece scopul principal al unei aplicații este de a rezolva problemele umane. Pentru a rezolva problemele umane, este necesar să avem câteva informații despre ele.
Astfel de informații sunt reprezentate ca date, în special prin calcul. Pe web, datele sunt colectate în mare parte sub formă de texte, imagini, videoclipuri și multe altele. Uneori, imaginile conțin texte esențiale care sunt menite a fi procesate pentru a atinge un anumit scop. Aceste imagini au fost în mare parte procesate manual, deoarece nu exista nicio modalitate de a le procesa programatic.
Incapacitatea de a extrage text din imagini a fost o limitare a procesării datelor pe care am experimentat-o direct la ultima mea companie. Trebuia să procesăm cardurile cadou scanate și trebuia să o facem manual, deoarece nu puteam extrage text din imagini.
În cadrul companiei exista un departament numit „Operațiuni” care era responsabil cu confirmarea manuală a cardurilor cadou și creditarea conturilor utilizatorilor. Deși aveam un site web prin care utilizatorii se conectau cu noi, procesarea cardurilor cadou s-a efectuat manual în culise.
La acea vreme, site-ul nostru web era construit în principal cu PHP (Laravel) pentru backend și JavaScript (jQuery și Vue) pentru frontend. Stack-ul nostru tehnic a fost suficient de bun pentru a lucra cu Tesseract.js, cu condiția ca problema să fie considerată importantă de către conducere.
Am fost dispus să rezolv problema dar nu a fost necesar să rezolv problema judecând din punctul de vedere al afacerii sau al conducerii. După ce am părăsit compania, am decis să fac câteva cercetări și să încerc să găsesc posibile soluții. În cele din urmă, am descoperit OCR.
Ce este OCR?
OCR înseamnă „Optical Character Recognition” sau „Optical Character Reader”. Este folosit pentru a extrage texte din imagini.
Evoluția OCR poate fi urmărită la mai multe invenții, dar Optophone, „Gismo”, scanerul plat CCD, Newton MesssagePad și Tesseract sunt invențiile majore care duc recunoașterea caracterelor la un alt nivel de utilitate.
Deci, de ce să folosiți OCR? Ei bine, recunoașterea optică a caracterelor rezolvă o mulțime de probleme, dintre care una m-a declanșat să scriu acest articol. Mi-am dat seama că abilitatea de a extrage texte dintr-o imagine asigură o mulțime de posibilități precum:
- Regulament
Fiecare organizație trebuie să reglementeze activitățile utilizatorilor din anumite motive. Regulamentul ar putea fi folosit pentru a proteja drepturile utilizatorilor și a-i proteja de amenințări sau escrocherii.
Extragerea textelor dintr-o imagine permite unei organizații să prelucreze informații textuale despre o imagine pentru reglementare, mai ales atunci când imaginile sunt furnizate de unii dintre utilizatori.
De exemplu, o reglementare asemănătoare Facebook a numărului de texte de pe imaginile utilizate pentru reclame poate fi realizată cu OCR. De asemenea, ascunderea conținutului sensibil pe Twitter este posibilă și prin OCR. - Posibilitate de căutare
Căutarea este una dintre cele mai frecvente activități, în special pe internet. Algoritmii de căutare se bazează în mare parte pe manipularea textelor. Cu recunoașterea optică a caracterelor, este posibil să recunoașteți caracterele de pe imagini și să le utilizați pentru a oferi utilizatorilor rezultate relevante ale imaginii. Pe scurt, imaginile și videoclipurile pot fi căutate acum cu ajutorul OCR. - Accesibilitate
A avea texte pe imagini a fost întotdeauna o provocare pentru accesibilitate și este regula de bază să aveți puține texte pe o imagine. Cu OCR, cititorii de ecran pot avea acces la textele de pe imagini pentru a oferi o experiență necesară utilizatorilor săi. - Automatizarea procesării datelor Prelucrarea datelor este în mare parte automatizată pentru scară. A avea texte pe imagini este o limitare a procesării datelor, deoarece textele nu pot fi procesate decât manual. Recunoașterea optică a caracterelor (OCR) face posibilă extragerea de texte de pe imagini în mod programatic, asigurând astfel automatizarea procesării datelor, mai ales atunci când are legătură cu procesarea textelor pe imagini.
- Digitalizarea Materialelor Imprimate
Totul devine digital și mai sunt încă o mulțime de documente de digitalizat. Cecurile, certificatele și alte documente fizice pot fi acum digitizate cu ajutorul recunoașterii optice a caracterelor.
Aflarea tuturor utilizărilor de mai sus mi-a adâncit interesele, așa că am decis să merg mai departe punând o întrebare:
„Cum pot folosi OCR pe web, în special într-o aplicație React?”
Această întrebare m-a condus la Tesseract.js.
Ce este Tesseract.js?
Tesseract.js este o bibliotecă JavaScript care compilează Tesseract original de la C la JavaScript WebAssembly, făcând astfel OCR accesibil în browser. Motorul Tesseract.js a fost scris inițial în ASM.js și ulterior a fost portat pe WebAssembly, dar ASM.js încă servește ca rezervă în unele cazuri când WebAssembly nu este acceptat.
După cum se menționează pe site-ul web Tesseract.js, acesta acceptă mai mult de 100 de limbi , orientare automată a textului și detectarea scripturilor, o interfață simplă pentru citirea paragrafelor, cuvintelor și casetelor de delimitare a caracterelor.
Tesseract este un motor optic de recunoaștere a caracterelor pentru diferite sisteme de operare. Este un software gratuit, lansat sub licența Apache. Hewlett-Packard a dezvoltat Tesseract ca software proprietar în anii 1980. A fost lansat ca sursă deschisă în 2005, iar dezvoltarea sa a fost sponsorizată de Google din 2006.
Cea mai recentă versiune, versiunea 4, a Tesseract a fost lansată în octombrie 2018 și conține un nou motor OCR care utilizează un sistem de rețea neuronală bazat pe Long Short-Term Memory (LSTM) și este menit să producă rezultate mai precise.
Înțelegerea API-urilor Tesseract
Pentru a înțelege cu adevărat cum funcționează Tesseract, trebuie să defalcăm unele dintre API-urile sale și componentele lor. Conform documentației Tesseract.js, există două moduri de a aborda utilizarea acestuia. Mai jos este prima abordare și defalcarea acesteia:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } Metoda de recognize ia imaginea ca prim argument, limba (care poate fi multiplă) ca al doilea argument și { logger: m => console.log(me) } ca ultimul argument. Formatele de imagine acceptate de Tesseract sunt jpg, png, bmp și pbm care pot fi furnizate numai ca elemente (img, video sau pânză), obiect fișier ( <input> ), obiect blob, cale sau URL către o imagine și imagine codificată în base64 . (Citiți aici pentru mai multe informații despre toate formatele de imagine pe care le poate gestiona Tesseract.)
Limba este furnizată ca șir, cum ar fi eng . Semnul + ar putea fi folosit pentru a concatena mai multe limbi ca în eng+chi_tra . Argumentul limbajului este utilizat pentru a determina datele limbajului antrenat care vor fi utilizate în procesarea imaginilor.
Notă : Veți găsi aici toate limbile disponibile și codurile acestora.
{ logger: m => console.log(m) } este foarte util pentru a obține informații despre progresul unei imagini în curs de procesare. Proprietatea logger preia o funcție care va fi apelată de mai multe ori pe măsură ce Tesseract procesează o imagine. Parametrul funcției de înregistrare ar trebui să fie un obiect cu workerId , jobId , status și progress ca proprietăți:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress este un număr între 0 și 1 și este în procente pentru a arăta progresul unui proces de recunoaștere a imaginii.
Tesseract generează automat obiectul ca parametru al funcției de înregistrare, dar poate fi furnizat și manual. Pe măsură ce are loc un proces de recunoaștere, proprietățile obiectului de logger sunt actualizate de fiecare dată când funcția este apelată . Deci, poate fi folosit pentru a afișa o bară de progres al conversiei, pentru a modifica o parte a unei aplicații sau pentru a obține orice rezultat dorit.
result din codul de mai sus este rezultatul procesului de recunoaștere a imaginii. Fiecare dintre proprietățile result are proprietatea bbox ca coordonatele x/y ale casetei lor de delimitare.
Iată proprietățile obiectului result , semnificațiile sau utilizările acestora:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: tot textul recunoscut ca șir. -
lines: o matrice a fiecărei linii de text recunoscute. -
words: o serie de fiecare cuvânt recunoscut. -
symbols: o matrice cu fiecare dintre caracterele recunoscute. -
paragraphs: o matrice a fiecărui paragraf recunoscut. Vom discuta despre „încredere” mai târziu în acest articol.
Tesseract poate fi folosit și mai imperativ ca în:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();Această abordare este legată de prima abordare, dar cu implementări diferite.
createWorker(options) creează un lucrător web sau un proces copil nod care creează un lucrător Tesseract. Lucrătorul ajută la configurarea motorului Tesseract OCR. Metoda load() încarcă scripturile de bază Tesseract, loadLanguage() încarcă orice limbă furnizată ca șir, initialize() se asigură că Tesseract este complet gata de utilizare și apoi metoda de recunoaștere este utilizată pentru a procesa imaginea furnizată. Metoda terminate() oprește lucrătorul și curăță totul.
Notă : Vă rugăm să verificați documentația API-urilor Tesseract pentru mai multe informații.
Acum, trebuie să construim ceva pentru a vedea cu adevărat cât de eficient este Tesseract.js.
Ce vom construi?
Vom construi un extractor PIN pentru cardul cadou, deoarece extragerea PIN-ului dintr-un card cadou a fost problema care a condus la această aventură de scris în primul rând.
Vom construi o aplicație simplă care extrage PIN-ul dintr-un card cadou scanat . Pe măsură ce mi-am propus să construiesc un simplu extractor de carduri cadou, vă voi prezenta câteva dintre provocările cu care m-am confruntat de-a lungul liniei, soluțiile pe care le-am oferit și concluzia mea bazată pe experiența mea.
- Accesați codul sursă →
Mai jos este imaginea pe care o vom folosi pentru testare, deoarece are unele proprietăți realiste care sunt posibile în lumea reală.

Vom extrage AQUX-QWMB6L-R6JAU de pe card. Asadar, haideti sa începem.
Instalarea lui React și Tesseract
Există o întrebare la care trebuie să vă ocupați înainte de a instala React și Tesseract.js și întrebarea este de ce să folosiți React cu Tesseract? Practic, putem folosi Tesseract cu Vanilla JavaScript, orice biblioteci JavaScript sau cadre precum React, Vue și Angular.
Utilizarea React în acest caz este o preferință personală. Inițial, am vrut să folosesc Vue, dar am decis să merg cu React pentru că sunt mai familiarizat cu React decât cu Vue.
Acum, să continuăm cu instalările.
Pentru a instala React cu create-react-app, trebuie să rulați codul de mai jos:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jssau
npm install tesseract.jsAm decis să merg cu yarn pentru a instala Tesseract.js, deoarece nu am putut instala Tesseract cu npm, dar yarn și-a făcut treaba fără stres. Puteți utiliza npm, dar vă recomand să instalați Tesseract cu fire judecând din experiența mea.
Acum, să începem serverul nostru de dezvoltare rulând codul de mai jos:
yarn startsau
npm startDupă rularea yarn start sau npm start, browserul dvs. implicit ar trebui să deschidă o pagină web care arată ca mai jos:

De asemenea, puteți naviga la localhost:3000 în browser, cu condiția ca pagina să nu fie lansată automat.
După instalarea React și Tesseract.js, ce urmează?
Configurarea unui formular de încărcare
În acest caz, vom ajusta pagina de pornire (App.js) pe care tocmai am vizualizat-o în browser pentru a conține formularul de care avem nevoie:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App Partea din codul de mai sus care necesită atenția noastră în acest moment este funcția handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } În funcție, URL.createObjectURL preia un fișier selectat prin event.target.files[0] și creează o adresă URL de referință care poate fi utilizată cu etichete HTML, cum ar fi img, audio și video. Am folosit setImagePath pentru a adăuga adresa URL la stare. Acum, adresa URL poate fi accesată cu imagePath .
<img src={imagePath} className="App-logo" alt="image"/> Am setat atributul src al imaginii la {imagePath} pentru a o previzualiza în browser înainte de a o procesa.
Conversia imaginilor selectate în texte
Pe măsură ce am prins calea către imaginea selectată, putem trece calea imaginii către Tesseract.js pentru a extrage texte din ea.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default AppAdăugăm funcția „handleClick” la „App.js și conține API Tesseract.js care ia calea către imaginea selectată. Tesseract.js preia „imagePath”, „limbaj”, „un obiect de setare”.
Butonul de mai jos este adăugat la formular pentru a apela „handClick”, care declanșează conversia imagine-în-text de fiecare dată când se face clic pe butonul.
<button onClick={handleClick} style={{height:50}}> convert to text</button>Când procesarea are succes, accesăm atât „încrederea”, cât și „textul” din rezultat. Apoi, adăugăm „text” la starea cu „setText(text)”.
Adăugând la <p> {text} </p> , afișăm textul extras.
Este evident că „textul” este extras din imagine, dar ce este încrederea?
Încrederea arată cât de precisă este conversia. Nivelul de încredere este între 1 și 100. 1 înseamnă cel mai rău, în timp ce 100 reprezintă cel mai bun în ceea ce privește acuratețea. Poate fi folosit și pentru a determina dacă un text extras trebuie acceptat ca corect sau nu.
Atunci întrebarea este ce factori pot afecta scorul de încredere sau acuratețea întregii conversii? Este afectat în mare parte de trei factori majori - calitatea și natura documentului utilizat, calitatea scanării create din document și abilitățile de procesare ale motorului Tesseract.
Acum, să adăugăm codul de mai jos la „App.css” pentru a stila puțin aplicația.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }Iată rezultatul primului meu test :
Rezultatul în Firefox
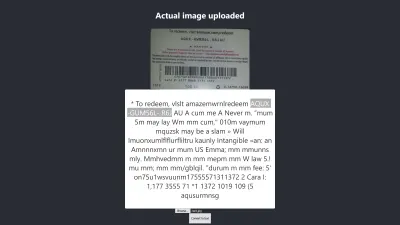
Nivelul de încredere al rezultatului de mai sus este de 64. Este de remarcat faptul că imaginea cardului cadou este de culoare închisă și afectează cu siguranță rezultatul pe care îl obținem.

Dacă aruncați o privire mai atentă la imaginea de mai sus, veți vedea că pinul de pe card este aproape exact în textul extras. Nu este exact pentru că cardul cadou nu este chiar clar.
Oh, așteptați! Cum va arăta în Chrome?
Rezultatul în Chrome
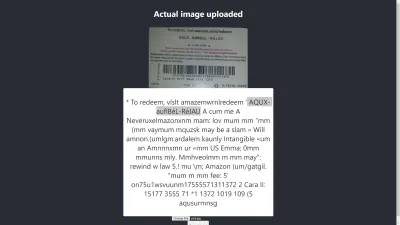
Ah! Rezultatul este și mai rău în Chrome. Dar de ce este rezultatul în Chrome diferit de Mozilla Firefox? Diferitele browsere gestionează imaginile și profilurile lor de culoare în mod diferit. Aceasta înseamnă că o imagine poate fi redată diferit în funcție de browser . Prin furnizarea imaginii.date pre- image.data către Tesseract, este probabil să producă un rezultat diferit în diferite browsere, deoarece image.data diferite sunt furnizate către Tesseract, în funcție de browserul utilizat. Preprocesarea unei imagini, așa cum vom vedea mai târziu în acest articol, va ajuta la obținerea unui rezultat consistent.
Trebuie să fim mai precisi, astfel încât să putem fi siguri că primim sau oferim informațiile corecte. Așa că trebuie să o ducem puțin mai departe.
Să încercăm mai mult să vedem dacă putem atinge scopul în final.
Testarea preciziei
Există o mulțime de factori care afectează o conversie imagine în text cu Tesseract.js. Majoritatea acestor factori gravitează în jurul naturii imaginii pe care dorim să o procesăm, iar restul depinde de modul în care motorul Tesseract gestionează conversia.
Intern, Tesseract preprocesează imaginile înainte de conversia OCR reală, dar nu oferă întotdeauna rezultate precise.
Ca o soluție, putem preprocesa imaginile pentru a obține conversii precise. Putem binariza, inversa, dilata, declina sau redimensionăm o imagine pentru a o preprocesa pentru Tesseract.js.
Preprocesarea imaginii este multă muncă sau un domeniu extins în sine. Din fericire, P5.js a oferit toate tehnicile de preprocesare a imaginii pe care dorim să le folosim. În loc să reinventez roata sau să folosim întreaga bibliotecă doar pentru că vrem să folosim o mică parte din ea, le-am copiat pe cele de care avem nevoie. Toate tehnicile de preprocesare a imaginii sunt incluse în preprocess.js.
Ce este binarizarea?
Binarizarea este conversia pixelilor unei imagini în alb sau negru. Dorim să binarizăm cardul cadou anterior pentru a verifica dacă acuratețea va fi mai bună sau nu.
Anterior, am extras câteva texte dintr-un card cadou, dar PIN-ul țintă nu era atât de precis pe cât ne-am dorit. Deci, este nevoie să găsim o altă modalitate de a obține un rezultat precis.
Acum, vrem să binarizăm cardul cadou , adică vrem să-i convertim pixelii în alb-negru, astfel încât să putem vedea dacă se poate atinge un nivel mai bun de precizie sau nu.
Funcțiile de mai jos vor fi folosite pentru binarizare și sunt incluse într-un fișier separat numit preprocess.js.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageCe face codul de mai sus?
Introducem pânza pentru a păstra datele unei imagini pentru a aplica unele filtre, pentru a preprocesa imaginea, înainte de a o trece către Tesseract pentru conversie.
Prima funcție preprocessImage este localizată în preprocess.js și pregătește pânza pentru utilizare prin obținerea pixelilor acestuia. Funcția thresholdFilter binarizează imaginea prin conversia pixelilor acesteia în alb sau negru .
Să apelăm la preprocessImage pentru a vedea dacă textul extras din cardul cadou anterior poate fi mai precis.
Până când actualizăm App.js, ar trebui să arate acum ca codul următor:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppMai întâi, trebuie să importam „preprocessImage” din „preprocess.js” cu codul de mai jos:
import preprocessImage from './preprocess'; Apoi, adăugăm o etichetă canvas în formular. Setăm atributul ref atât al etichetelor canvas, cât și al etichetelor img la { canvasRef } și respectiv { imageRef } . Refurile sunt folosite pentru a accesa pânza și imaginea din componenta App. Luăm atât pânza, cât și imaginea cu „useRef” ca în:
const canvasRef = useRef(null); const imageRef = useRef(null);În această parte a codului, îmbinăm imaginea cu pânza, deoarece putem preprocesa doar o pânză în JavaScript. Apoi îl convertim într-o adresă URL de date cu „jpeg” ca format de imagine.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");„dataUrl” este transmis către Tesseract ca imagine care trebuie procesată.
Acum, să verificăm dacă textul extras va fi mai precis.
Testul #2

Imaginea de mai sus arată rezultatul în Firefox. Este evident că partea întunecată a imaginii a fost schimbată în albă, dar preprocesarea imaginii nu duce la un rezultat mai precis. Este și mai rău.
Prima conversie are doar două caractere incorecte, dar aceasta are patru caractere incorecte. Am încercat chiar să schimb nivelul pragului, dar fără rezultat. Nu obținem un rezultat mai bun nu pentru că binarizarea este proastă, ci pentru că binarizarea imaginii nu fixează natura imaginii într-un mod potrivit pentru motorul Tesseract.
Să verificăm cum arată și în Chrome:

Obținem același rezultat.
După obținerea unui rezultat mai rău prin binarizarea imaginii, este nevoie să verificăm alte tehnici de preprocesare a imaginii pentru a vedea dacă putem rezolva problema sau nu. Deci, vom încerca în continuare dilatarea, inversarea și estomparea.
Să obținem doar codul pentru fiecare dintre tehnicile din P5.js, așa cum este folosit de acest articol. Vom adăuga tehnicile de procesare a imaginii la preprocess.js și le vom folosi unul câte unul. Este necesar să înțelegem fiecare dintre tehnicile de preprocesare a imaginii pe care dorim să le folosim înainte de a le folosi, așa că le vom discuta mai întâi.
Ce este dilatarea?
Dilatarea înseamnă adăugarea de pixeli la limitele obiectelor dintr-o imagine pentru a o face mai lată, mai mare sau mai deschisă. Tehnica „dilatare” este folosită pentru a preprocesa imaginile noastre pentru a crește luminozitatea obiectelor de pe imagini. Avem nevoie de o funcție pentru a dilata imaginile folosind JavaScript, astfel încât fragmentul de cod pentru a dilata o imagine este adăugat la preprocess.js.
Ce este Blur?
Încețoșarea înseamnă netezirea culorilor unei imagini prin reducerea clarității acesteia. Uneori, imaginile au puncte/petice mici. Pentru a elimina acele patch-uri, putem estompa imaginile. Fragmentul de cod pentru a estompa o imagine este inclus în preprocess.js.
Ce este inversiunea?
Inversarea înseamnă schimbarea zonelor luminoase ale unei imagini într-o culoare închisă și zonele întunecate într-o culoare deschisă. De exemplu, dacă o imagine are un fundal negru și un prim plan alb, o putem inversa astfel încât fundalul ei să fie alb și primul plan negru. Am adăugat, de asemenea, fragmentul de cod pentru a inversa o imagine în preprocess.js.
După ce am adăugat dilate , invertColors și blurARGB la „preprocess.js”, acum le putem folosi pentru a preprocesa imaginile. Pentru a le folosi, trebuie să actualizăm funcția inițială „preprocessImage” în preprocess.js:
preprocessImage(...) arată acum astfel:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } În preprocessImage de mai sus, aplicăm patru tehnici de preprocesare unei imagini: blurARGB() pentru a elimina punctele de pe imagine, dilate() pentru a crește luminozitatea imaginii, invertColors() pentru a schimba culoarea de prim plan și de fundal a imaginii și thresholdFilter() pentru a converti imaginea în alb-negru, ceea ce este mai potrivit pentru conversia Tesseract.
ThresholdFilter thresholdFilter() ia image.data și level ca parametri. level este folosit pentru a seta cât de albă sau neagră ar trebui să fie imaginea. Am determinat nivelul thresholdFilter și raza blurRGB prin încercare și eroare, deoarece nu suntem siguri cât de albă, întunecată sau netedă ar trebui să fie imaginea pentru ca Tesseract să producă un rezultat excelent.
Testul #3
Iată noul rezultat după aplicarea a patru tehnici:

Imaginea de mai sus reprezintă rezultatul pe care îl obținem atât în Chrome, cât și în Firefox.
Hopa! Rezultatul este teribil.
În loc să folosim toate cele patru tehnici, de ce nu folosim doar două dintre ele odată?
Da! Putem folosi pur și simplu tehnicile invertColors și thresholdFilter pentru a converti imaginea în alb-negru și pentru a comuta primul plan și fundalul imaginii. Dar de unde știm ce și ce tehnici să combinăm? Știm ce să combinăm în funcție de natura imaginii pe care dorim să o preprocesăm.
De exemplu, o imagine digitală trebuie convertită în alb-negru, iar o imagine cu petice trebuie să fie estompată pentru a elimina punctele/peticele. Ceea ce contează cu adevărat este să înțelegem pentru ce este folosită fiecare dintre tehnici.
Pentru a folosi invertColors și thresholdFilter , trebuie să comentăm atât blurARGB , cât și dilate în preprocessImage :
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }Testul #4
Acum, iată noul rezultat:

Rezultatul este încă mai rău decât cel fără nicio preprocesare. După ce am ajustat fiecare dintre tehnicile pentru această imagine particulară și pentru alte imagini, am ajuns la concluzia că imaginile cu natură diferită necesită tehnici de preprocesare diferite.
Pe scurt, utilizarea Tesseract.js fără preprocesarea imaginii a produs cel mai bun rezultat pentru cardul cadou de mai sus. Toate celelalte experimente cu preprocesarea imaginii au dat rezultate mai puțin precise.
Problema
Inițial, am vrut să extrag codul PIN de pe orice card cadou Amazon, dar nu am reușit să realizez asta, deoarece nu are rost să potrivesc un PIN inconsecvent pentru a obține un rezultat consistent. Deși este posibil să se proceseze o imagine pentru a obține un PIN precis, totuși o astfel de preprocesare va fi inconsecventă în momentul în care este utilizată o altă imagine cu natură diferită.
Cel mai bun rezultat produs
Imaginea de mai jos prezintă cel mai bun rezultat produs de experimente.
Testul #5

Textele de pe imagine și cele extrase sunt total aceleași. Conversia are o precizie de 100%. Am încercat să reproduc rezultatul, dar am reușit să-l reproduc doar când am folosit imagini cu natură similară.
Observație și lecții
- Unele imagini care nu sunt preprocesate pot da rezultate diferite în browsere diferite . Această afirmație este evidentă în primul test. Rezultatul în Firefox este diferit de cel din Chrome. Cu toate acestea, preprocesarea imaginilor ajută la obținerea unui rezultat consistent în alte teste.
- Culoarea neagră pe un fundal alb tinde să dea rezultate gestionabile. Imaginea de mai jos este un exemplu de rezultat precis fără nicio preprocesare . De asemenea, am reușit să obțin același nivel de precizie prin preprocesarea imaginii, dar mi-a luat o mulțime de ajustări, ceea ce a fost inutil.
Conversia este 100% precisă.
- Un text cu o dimensiune mare a fontului tinde să fie mai precis.
- Fonturile cu margini curbate tind să încurce Tesseract. Cel mai bun rezultat pe care l-am obținut a fost obținut când am folosit Arial (font).
- În prezent, OCR nu este suficient de bun pentru automatizarea conversiei imagine în text, mai ales când este necesar un nivel de precizie de peste 80%. Cu toate acestea, poate fi folosit pentru a face procesarea manuală a textelor pe imagini mai puțin stresantă prin extragerea textelor pentru corectare manuală.
- În prezent, OCR nu este suficient de bun pentru a transmite informații utile cititorilor de ecran pentru accesibilitate . Furnizarea de informații inexacte unui cititor de ecran poate induce cu ușurință în eroare sau distrage atenția utilizatorilor.
- OCR este foarte promițător, deoarece rețelele neuronale fac posibilă învățarea și îmbunătățirea. Învățarea profundă va face din OCR un schimbător de joc în viitorul apropiat .
- Luarea deciziilor cu încredere. Un scor de încredere poate fi folosit pentru a lua decizii care pot avea un impact semnificativ asupra aplicațiilor noastre. Scorul de încredere poate fi folosit pentru a determina dacă se acceptă sau se respinge un rezultat. Din experiența și experimentul meu, mi-am dat seama că orice scor de încredere sub 90 nu este cu adevărat util. Dacă trebuie doar să extrag niște pini dintr-un text, mă voi aștepta la un scor de încredere între 75 și 100 și orice lucru sub 75 va fi respins .
În cazul în care am de-a face cu texte fără a fi nevoie să extrag vreo parte din ele, voi accepta cu siguranță un scor de încredere între 90 și 100, dar voi resping orice scor mai mic. De exemplu, o acuratețe de 90 și peste va fi de așteptat dacă vreau să digitizez documente precum cecuri, o ciornă istorică sau ori de câte ori este necesară o copie exactă. Dar un scor care este între 75 și 90 este acceptabil atunci când o copie exactă nu este importantă, cum ar fi obținerea codului PIN de la un card cadou. Pe scurt, un scor de încredere ajută la luarea deciziilor care au impact asupra aplicațiilor noastre.
Concluzie
Având în vedere limitarea procesării datelor cauzată de textele de pe imagini și dezavantajele asociate cu aceasta, recunoașterea optică a caracterelor (OCR) este o tehnologie utilă de îmbrățișat. Deși OCR are limitările sale, este foarte promițător datorită utilizării rețelelor neuronale.
De-a lungul timpului, OCR își va depăși majoritatea limitărilor cu ajutorul învățării profunde, dar înainte de atunci, abordările evidențiate în acest articol pot fi utilizate pentru a trata extragerea textului din imagini, cel puțin, pentru a reduce dificultățile și pierderile asociate cu manualul. prelucrare — mai ales din punct de vedere al afacerilor.
Acum este rândul tău să încerci OCR pentru a extrage texte din imagini. Noroc!
Lectură suplimentară
- P5.js
- Preprocesare în OCR
- Îmbunătățirea calității rezultatelor
- Utilizarea JavaScript pentru a preprocesa imagini pentru OCR
- OCR în browser cu Tesseract.js
- O istorie rapidă a recunoașterii optice a caracterelor
- Viitorul OCR este Deep Learning
- Cronologia recunoașterii optice a caracterelor