
Clasificarea imaginilor în CNN: Tot ce trebuie să știți
Publicat: 2021-02-25Cuprins
Introducere
În timp ce parcurgeți feedul Facebook, v-ați întrebat vreodată cum oamenii dintr-o fotografie de grup sunt etichetați automat de software-ul Facebook? În spatele fiecărei interfețe interactive de utilizator a Facebook pe care o vedeți, există un algoritm complex și puternic care este folosit pentru a recunoaște și a eticheta fiecare imagine încărcată de noi pe platforma de socializare. Cu fiecare imagine a noastră, ajutăm doar la îmbunătățirea eficienței algoritmului. Da, Clasificarea imaginilor este unul dintre cei mai folosiți algoritmi unde vedem aplicarea Inteligenței Artificiale.
În ultima vreme, rețelele neuronale convoluționale (CNN) a devenit unul dintre cei mai puternici susținători ai învățării profunde. O aplicație populară a acestor rețele convoluționale este Clasificarea imaginilor. În acest tutorial, vom parcurge elementele de bază ale rețelelor neuronale convoluționale, vom vedea diferitele straturi implicate în construirea unui model CNN și, în final, vom vizualiza un exemplu de sarcină de clasificare a imaginilor.
Clasificarea imaginilor
Înainte de a intra în detaliile învățării profunde și ale rețelelor neuronale convoluționale, să înțelegem elementele de bază ale clasificării imaginilor. În general, Clasificarea imaginii este definită ca sarcina în care dăm o imagine ca intrare pentru un model construit folosind un algoritm specific care scoate clasa sau probabilitatea clasei căreia îi aparține imaginea. Acest proces în care etichetăm o imagine pentru o anumită clasă se numește Învățare Supervizată.
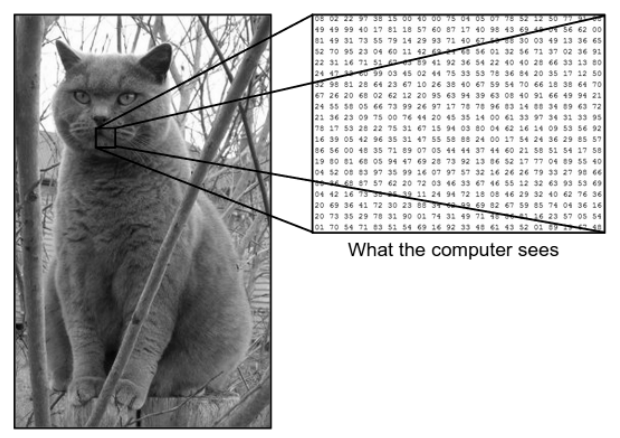
Există o diferență uriașă între modul în care vedem o imagine și modul în care mașina (computerul) vede aceeași imagine. Pentru noi, suntem capabili să vizualizăm imaginea și să o caracterizăm în funcție de culoare și dimensiune. Pe de altă parte, pentru mașină, tot ce poate vedea sunt numere. Numerele care sunt văzute se numesc pixeli.
Fiecare pixel are o valoare între 0 și 255. Prin urmare, cu aceste date numerice, mașina necesită niște pași de preprocesare pentru a deriva unele modele sau caracteristici specifice care să distingă o imagine de cealaltă. Rețelele neuronale convoluționale ne ajută să construim algoritmi capabili să obțină modelul specific din imagini.
Ce vedem noi vs ceea ce vede computerul
 Sursa – Diferența dintre computer și ochiul uman
Sursa – Diferența dintre computer și ochiul uman

Învățare profundă pentru clasificarea imaginilor
Acum că am înțeles ce este Clasificarea imaginilor, să vedem cum o putem implementa folosind inteligența artificială. Pentru aceasta, folosim metodele populare de Deep Learning. Deep Learning este un subset al inteligenței artificiale care utilizează seturi mari de date de imagini pentru a recunoaște și a deriva modele din diferite imagini pentru a diferenția între diferitele clase prezente în setul de date de imagine.
Provocarea majoră cu care se confruntă Deep Learning este că, pentru o bază de date uriașă, durează foarte mult timp și are un cost de calcul ridicat. Cu toate acestea, rețelele neuronale convoluționale, care este un tip de algoritm de învățare profundă, abordează bine această problemă.
Rețele neuronale convoluționale
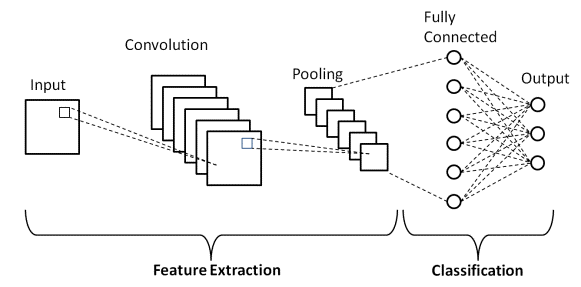
În Deep Learning, rețelele neuronale convoluționale sunt o clasă de rețele neuronale profunde care sunt utilizate în principal în imaginile vizuale. Ele sunt o arhitectură specială a rețelelor neuronale artificiale (ANN) care a fost propusă în 1998 de Yann LeCunn. Rețelele neuronale convoluționale constau din două părți.
Prima parte este formată din straturile Convoluționale și straturile Pooling în care are loc procesul de extracție a caracteristicilor principale. În a doua parte, straturile Fully Connected și Dense efectuează câteva transformări neliniare asupra caracteristicilor extrase și acționează ca parte clasificatoare. Aflați CNN pentru clasificarea imaginilor.
Luați în considerare exemplul de imagine de mai sus a ceea ce văd omul și mașina. După cum vedem, computerul vede o serie de pixeli. De exemplu, dacă dimensiunea imaginii este 500×500, atunci dimensiunea matricei va fi 500x500x3. Aici, 500 de standuri pentru fiecare înălțime și lățime, 3 standuri pentru canalul RGB, unde fiecare canal de culoare este reprezentat de o matrice separată. Intensitatea pixelilor variază de la 0 la 255.
Acum, pentru Clasificarea imaginilor, computerul va căuta caracteristicile la nivelul de bază. În opinia noastră, ca oameni, aceste trăsături de bază ale pisicii sunt urechile, nasul și mustața. În timp ce pentru computer, aceste caracteristici la nivel de bază sunt curburele și limitele. În acest fel, folosind mai multe straturi diferite, cum ar fi straturile Convoluționale și straturile Pooling, computerul extrage caracteristicile de nivel de bază din imagini.
În modelul rețelei neuronale convoluționale, există mai multe tipuri de straturi, cum ar fi:
- Strat de intrare
- Stratul convoluțional
- Strat de pooling
- Strat complet conectat
- Strat de ieșire
- Funcții de activare
Să parcurgem pe scurt fiecare dintre straturi înainte de a intra în aplicarea lui în Clasificarea imaginilor.
Strat de intrare
Din nume, înțelegem că acesta este stratul în care imaginea de intrare va fi alimentată în modelul CNN. În funcție de cerințele noastre, putem remodela imaginea la diferite dimensiuni, cum ar fi (28,28,3)
Stratul convoluțional
Apoi vine cel mai important strat care constă dintr-un filtru (cunoscut și ca nucleu) cu o dimensiune fixă. Operația matematică de Convoluție se realizează între imaginea de intrare și filtru. Aceasta este etapa în care majoritatea caracteristicilor de bază, cum ar fi marginile ascuțite și curbele, sunt extrase din imagine și, prin urmare, acest strat este cunoscut și sub numele de strat extractor de caracteristici.
Strat de pooling
După efectuarea operației de convoluție, efectuăm operația de Pooling. Acest lucru este cunoscut și sub denumirea de eșantionare în cazul în care volumul spațial al imaginii este redus. De exemplu, dacă efectuăm o operațiune de Pooling cu un pas de 2 pe o imagine cu dimensiunile 28×28, atunci dimensiunea imaginii redusă la 14×14, aceasta se reduce la jumătate din dimensiunea inițială.
Strat complet conectat
Stratul complet conectat (FC) este plasat chiar înainte de ieșirea finală de clasificare a modelului CNN. Aceste straturi sunt folosite pentru a aplatiza rezultatele înainte de clasificare. Ea implică mai multe prejudecăți, greutăți și neuroni. Atașarea unui strat FC înainte de clasificare are ca rezultat un vector N-dimensional în care N este un număr de clase dintre care modelul trebuie să aleagă o clasă.
Strat de ieșire
În cele din urmă, stratul de ieșire constă dintr-o etichetă care este în mare parte codificată prin utilizarea metodei de codificare one-hot.
Funcția de activare
Aceste funcții de activare sunt nucleul oricărui model de rețea neuronală convoluțională. Aceste funcții sunt utilizate pentru a determina ieșirea unei rețele neuronale. Pe scurt, determină dacă un anumit neuron ar trebui activat („declanșat”) sau nu. Acestea sunt de obicei funcții neliniare care sunt efectuate pe semnalele de intrare. Această ieșire transformată este apoi trimisă ca intrare către următorul strat de neuroni. Există mai multe funcții de activare, cum ar fi Sigmoid, ReLU, Leaky ReLU, TanH și Softmax.
Arhitectura de bază CNN
Sursa : Arhitectura de bază CNN
După cum sa definit mai devreme, diagrama prezentată mai sus este arhitectura de bază a unui model de rețea neuronală convoluțională. Acum că suntem pregătiți cu elementele de bază ale clasificării imaginilor și CNN, să ne aruncăm acum în aplicarea acesteia cu o problemă în timp real. Aflați mai multe despre arhitectura de bază CNN.
Implementarea rețelelor neuronale convoluționale
Acum că am înțeles elementele de bază ale clasificării imaginilor și rețelelor neuronale convoluționale, să vizualizăm implementarea acesteia în TensorFlow/Keras cu codare Python. În aceasta, vom construi un model simplu de rețea neuronală convoluțională cu o arhitectură LeNet de bază, vom antrena modelul pe un set de antrenament și un set de testare și, în final, vom obține acuratețea modelului pe datele setului de testare.
Set de probleme
În acest articol pentru construirea și antrenarea modelului de rețea neuronală convoluțională, vom folosi faimosul set de date Fashion MNIST. MNIST înseamnă Institutul Național de Standarde și Tehnologie Modificat. Fashion-MNIST este un set de date de imagini ale articolelor Zalando, constând dintr-un set de antrenament de 60.000 de exemple și un set de testare de 10.000 de exemple. Fiecare exemplu este o imagine în tonuri de gri 28×28, asociată cu o etichetă din 10 clase.

Fiecare exemplu de instruire și test este atribuit uneia dintre următoarele etichete:
0 – Tricou/top
1 – Pantalon
2 – Pulover
3 – Rochie
4 – Haina
5 – Sandal
6 – Cămașă
7 – Adidași
8 – Geanta
9 – Botine
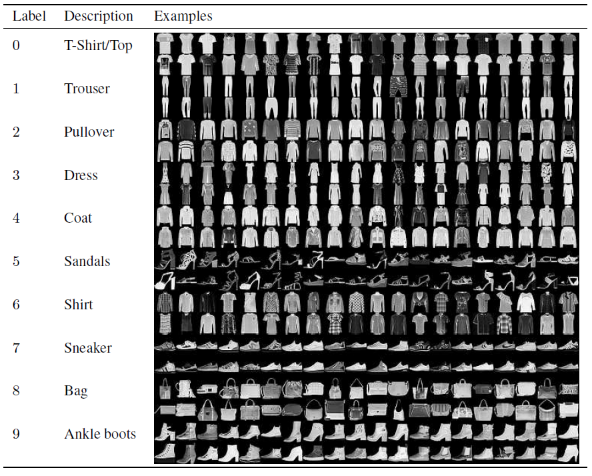
Sursa : Fashion MNIST Dataset Images
Cod program
Pasul 1 – Importarea bibliotecilor
Primul pas pentru construirea oricărui model Deep Learning este să importați bibliotecile care sunt necesare pentru program. În exemplul nostru, deoarece folosim cadrul TensorFlow, vom importa biblioteca Keras și, de asemenea, alte biblioteci importante, cum ar fi numărul pentru calcul și matplotlib pentru trasarea graficelor.
#TensorFlow – Importul bibliotecilor
import numpy ca np
import matplotlib.pyplot ca plt
%matplotlib inline
import tensorflow ca tf
din tensorflow import Keras
Pasul 2 - Obținerea și împărțirea setului de date
Odată ce am importat bibliotecile, următorul pas este descărcarea setului de date și împărțirea setului de date Fashion MNIST în 60.000 de date de antrenament și 10.000 de date de testare respective. Din fericire, keras ne oferă o funcție predefinită pentru a importa setul de date Fashion MNIST și le putem împărți în linia următoare folosind o linie simplă de cod care se înțelege de la sine.
#TensorFlow – Obținerea și împărțirea setului de date
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
Pasul 3 - Vizualizarea datelor
Pe măsură ce setul de date este descărcat împreună cu imaginile și etichetele lor corespunzătoare, pentru a fi mai clar pentru utilizator, se recomandă întotdeauna să vizualizați datele, astfel încât să putem înțelege tipul de date cu care avem de-a face la construirea Neuralului convoluțional. Modelul de rețea în consecință. Aici, cu acest simplu bloc de cod prezentat mai jos, vom vizualiza primele 3 imagini ale setului de date de antrenament care este amestecat aleatoriu.
#TensorFlow – Vizualizarea datelor
def imshowTensorFlow(img):
plt.imshow(img, cmap='gri')
print(„Etichetă:”, img[0])
imshowTensorFlow(train_images_tf[0])
Etichetă: 9 Etichetă: 0 Etichetă: 3


Imaginea de mai sus și etichetele lor pot fi verificate cu etichetele care sunt date în detaliile setului de date Fashion MNIST de mai sus. Din aceasta, deducem că imaginea noastră de date este o imagine în tonuri de gri cu o înălțime de 28 de pixeli și o lățime de 28 de pixeli.
Prin urmare, modelul poate fi construit cu o dimensiune de intrare de (28,28,1), unde 1 reprezintă imaginea în tonuri de gri.
Pasul 4 – Construirea modelului
După cum am menționat mai sus, în acest articol vom construi o rețea neuronală convoluțională simplă cu arhitectura LeNet. LeNet este o structură de rețea neuronală convoluțională propusă de Yann LeCun și colab. în 1989. În general, LeNet se referă la LeNet-5 și este o simplă rețea neuronală convoluțională.
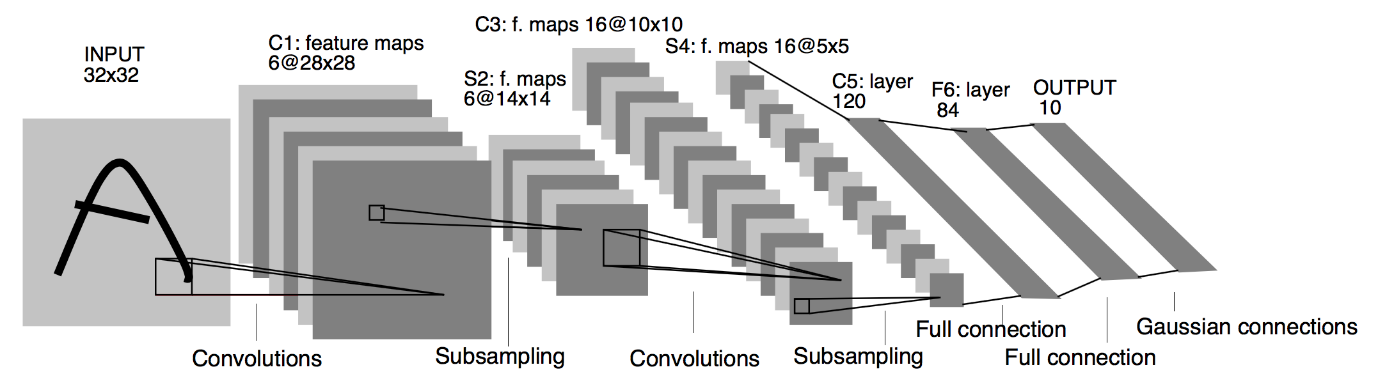
Sursa : Arhitectura LeNet
Din diagrama de arhitectură dată mai sus a modelului LeNet CNN, vedem că există 5+2 straturi. Primul și al doilea strat sunt un strat Convoluțional urmat de un strat Pooling. Din nou, al treilea și al patrulea strat constau dintr-un strat Convoluțional și un strat de Pooling. Ca rezultat al acestor operațiuni, dimensiunea imaginii de intrare de la 28×28 se reduce la 7×7.
Al cincilea strat al modelului LeNet este stratul complet conectat, care aplatizează ieșirea stratului anterior. Urmat de două straturi Dense, stratul final de ieșire al modelului CNN constă dintr-o funcție de activare Softmax cu 10 unități. Funcția Softmax prezice o probabilitate de clasă pentru fiecare dintre cele 10 clase ale setului de date Fashion MNIST.
#TensorFlow – Construirea modelului
model = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), filters=6, kernel_size=5, strides=1, padding=”same”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=”same”, activation=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, activation=tf.nn.relu),
keras.layers.Dense(84, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
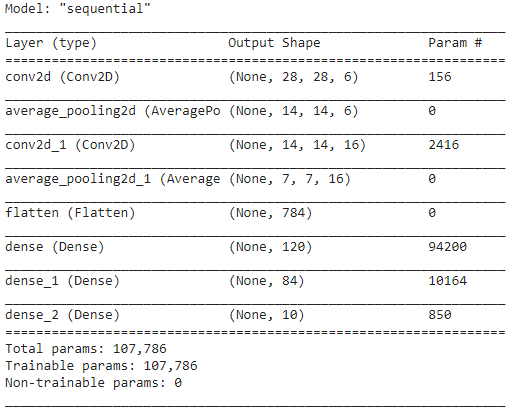
Pasul 5 – Rezumatul modelului
Odată ce straturile modelului LeNet sunt finalizate, putem trece la compilarea modelului și a vizualiza o versiune rezumată a modelului CNN proiectat.
#TensorFlow – Rezumatul modelului
model.compile(loss=keras.loss.categorical_crossentropy,
optimizator='adam',
metrics=['acc'])
model.summary()
În acest sens, deoarece rezultatul final are mai mult de 2 clase (10 clase), folosim crossentropia categorială ca funcție de pierdere și Adam Optimizer pentru modelul nostru construit. Rezumatul modelului este prezentat mai jos.
Pasul 6 – Antrenarea modelului
În sfârșit, ajungem la partea în care începem procesul de instruire a modelului LeNet CNN. În primul rând, remodelăm setul de date de antrenament și îl normalizăm la valori mai mici prin împărțirea cu 255,0 pentru a reduce costul de calcul. Apoi etichetele de antrenament sunt convertite dintr-un vector de clasă întreagă într-o matrice de clasă binară. De exemplu, eticheta 3 este convertită în [0, 0, 0, 1, 0, 0, 0, 0, 0]
#TensorFlow – Antrenarea modelului
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
La sfârșitul antrenamentului după 30 de epoci, obținem precizia finală a antrenamentului și pierderea ca,
Epoca 30/30
1875/1875 [==============================] – 4s 2ms/pas – pierdere: 0,0421 – acc: 0,9850
Precizie la antrenament: 98,294997215271 %
Pierdere la antrenament: 0,04584110900759697
Pasul 7 – Prezicerea rezultatelor
În cele din urmă, odată ce am terminat cu procesul nostru de antrenament al modelului CNN, vom potrivi același model pe setul de date de testare și vom prezice acuratețea a 10.000 de imagini de testare.
#TensorFlow – Compararea rezultatelor
predictions = model.predict(test_images_tensorflow)
corect = 0
pentru i, pred în enumerate(predicții):
dacă np.argmax(pred) == test_labels_tf[i]:
corect += 1
print('Testează Precizia modelului pe {} imagini de testare: {}% cu TensorFlow'.format(test_images_tf.shape[0],100 * corect/test_images_tf.shape[0]))
Rezultatul pe care îl obținem este,
Precizia de testare a modelului pe cele 10000 de imagini de testare: 90,67% cu TensorFlow
Cu aceasta, ajungem la finalul programului de construire a unui model de clasificare a imaginilor cu rețele neuronale convoluționale.
Citește și: Idei de proiecte de învățare automată
Concluzie
Astfel, în acest tutorial despre implementarea clasificării imaginilor în CNN, am înțeles conceptele de bază din spatele clasificării imaginilor, rețelelor neuronale convoluționale împreună cu implementarea acesteia în limbajul de programare Python cu framework TensorFlow.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Diploma PG de la IIIT-B și upGrad în Învățare automată și AI, care este concepută pentru profesioniști care lucrează și oferă peste 450 de ore de formare riguroasă, peste 30 de studii de caz și sarcini, IIIT- B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Care model CNN este considerat a fi cel mai optim pentru clasificarea imaginilor?
Cel mai bun model CNN pentru clasificarea imaginilor este VGG-16, care înseamnă Very Deep Convolutional Networks for Large-Scale Image Recognition. VGG, care a fost conceput ca un CNN profund, depășește liniile de bază pentru o gamă largă de sarcini și seturi de date în afara ImageNet. Caracteristica distinctivă a modelului este că, atunci când a fost creat, s-a acordat mai multă atenție încorporării unor straturi de convoluție excelente, mai degrabă decât să se concentreze pe adăugarea unui număr mare de hiperparametri. Are un total de 16 straturi, 5 blocuri, iar fiecare bloc are un strat de pooling maxim, ceea ce o face o rețea destul de mare.
Care sunt dezavantajele utilizării modelelor CNN pentru clasificarea imaginilor?
Când vine vorba de clasificarea imaginilor, modelele CNN au un mare succes. Cu toate acestea, există mai multe dezavantaje în utilizarea CNN-urilor. Dacă imaginea de identificat este înclinată sau rotită, modelul CNN are probleme la identificarea cu precizie a imaginii. Când CNN vizualizează imaginile, nu există reprezentări interne ale componentelor și ale conexiunilor lor parțial-întreg. În plus, dacă modelul CNN care urmează să fie folosit include numeroase straturi convoluționale, procesul de clasificare va dura mult timp.
De ce este preferată utilizarea modelului CNN față de ANN pentru datele de imagine ca intrare?
Combinând filtre sau transformări, CNN poate învăța multe straturi de reprezentări de caracteristici pentru fiecare imagine furnizată ca intrare. Supraadaptarea este redusă, deoarece numărul de parametri pe care rețeaua trebuie să învețe în CNN este substanțial mai mic decât în rețelele neuronale multistrat. Când se utilizează ANN, rețelele neuronale pot învăța o reprezentare unică a imaginii, dar, în cazul imaginilor complexe, ANN nu va oferi vizualizări sau clasificări îmbunătățite, deoarece nu poate învăța dependențele de pixeli existente în imaginile de intrare.