
HTTP/3: Îmbunătățiri de performanță (Partea 2)
Publicat: 2022-03-10Bine ați revenit la această serie despre noul protocol HTTP/3. În partea 1, am analizat de ce avem nevoie exact de HTTP/3 și de protocolul QUIC de bază și care sunt principalele caracteristici noi.
În această a doua parte, vom mări îmbunătățirile de performanță pe care QUIC și HTTP/3 le aduc la masa pentru încărcarea paginilor web. Cu toate acestea, vom fi, de asemenea, oarecum sceptici cu privire la impactul la care ne putem aștepta de la aceste noi funcții în practică.
După cum vom vedea, QUIC și HTTP/3 au într-adevăr un potențial mare de performanță web, dar în principal pentru utilizatorii din rețele lente . Dacă vizitatorul tău obișnuit se află într-o rețea rapidă prin cablu sau celulară, probabil că nu va beneficia atât de mult de noile protocoale. Cu toate acestea, rețineți că, chiar și în țările și regiunile cu uplink-uri în mod obișnuit rapide, cei mai lenți 1% până la 10% din publicul dvs. (așa-numitele percentile 99 sau 90 ) pot câștiga în continuare mult. Acest lucru se datorează faptului că HTTP/3 și QUIC ajută în principal la rezolvarea problemelor oarecum neobișnuite, dar cu potențial de mare impact, care pot apărea pe internetul de astăzi.
Această parte este puțin mai tehnică decât prima, deși descarcă majoritatea lucrurilor cu adevărat profunde către surse externe, concentrându-se pe explicarea de ce contează aceste lucruri pentru dezvoltatorul web obișnuit.
- Partea 1: Istoria HTTP/3 și conceptele de bază
Acest articol se adresează persoanelor care nu cunosc HTTP/3 și protocoalele în general și discută în principal elementele de bază. - Partea 2: Caracteristici de performanță HTTP/3
Acesta este mai profund și mai tehnic. Oamenii care cunosc deja elementele de bază pot începe aici. - Partea 3: Opțiuni practice de implementare HTTP/3
Acest al treilea articol din serie explică provocările implicate în implementarea și testarea dvs. HTTP/3. Acesta detaliază cum și dacă ar trebui să vă schimbați paginile web și resursele.
Un primer despre viteză
Discuția despre performanță și „viteză” poate deveni rapid complexă, deoarece multe aspecte subiacente contribuie la încărcarea „încet” a unei pagini web. Deoarece aici avem de-a face cu protocoale de rețea, ne vom uita în principal la aspectele rețelei, dintre care două sunt cele mai importante: latența și lățimea de bandă.
Latența poate fi definită aproximativ ca timpul necesar pentru a trimite un pachet de la punctul A (să zicem, client) la punctul B (server) . Este limitat fizic de viteza luminii sau, practic, de cât de repede pot circula semnalele în fire sau în aer liber. Aceasta înseamnă că latența depinde adesea de distanța fizică, din lumea reală, dintre A și B.
Pe pământ, aceasta înseamnă că latențele tipice sunt conceptual mici, între aproximativ 10 și 200 de milisecunde. Cu toate acestea, acesta este doar un singur mod: răspunsurile la pachete trebuie să revină. Latența în două sensuri este adesea numită timp dus-întors (RTT) .
Datorită funcțiilor precum controlul congestiei (vezi mai jos), vom avea adesea nevoie de câteva călătorii dus-întors pentru a încărca chiar și un singur fișier. Ca atare, chiar și latențe mici, mai mici de 50 de milisecunde, se pot adăuga întârzieri considerabile. Acesta este unul dintre principalele motive pentru care există rețelele de livrare de conținut (CDN-uri): plasează serverele mai aproape fizic de utilizatorul final pentru a reduce latența și, astfel, întârzie cât mai mult posibil.
Prin urmare, lățimea de bandă se poate spune că este numărul de pachete care pot fi trimise în același timp . Acest lucru este puțin mai dificil de explicat, deoarece depinde de proprietățile fizice ale mediului (de exemplu, frecvența utilizată a undelor radio), numărul de utilizatori din rețea și, de asemenea, dispozitivele care interconectează diferite subrețele (deoarece acestea de obicei poate procesa doar un anumit număr de pachete pe secundă).
O metaforă des folosită este aceea a unei țevi folosite pentru transportul apei. Lungimea conductei este latența, în timp ce lățimea conductei este lățimea de bandă. Pe Internet, totuși, avem de obicei o serie lungă de conducte conectate , dintre care unele pot fi mai largi decât altele (ducând la așa-numitele blocaje la cele mai înguste legături). Ca atare, lățimea de bandă de la un capăt la altul dintre punctele A și B este adesea limitată de cele mai lente subsecțiuni.
Deși o înțelegere perfectă a acestor concepte nu este necesară pentru restul acestei postări, ar fi bine să existe o definiție comună la nivel înalt. Pentru mai multe informații, vă recomand să consultați excelentul capitol al lui Ilya Grigorik despre latență și lățime de bandă din cartea sa High Performance Browser Networking .
Controlul congestiei
Un aspect al performanței este despre cât de eficient poate un protocol de transport să folosească lățimea de bandă completă (fizică) a unei rețele (adică, aproximativ, câte pachete pe secundă pot fi trimise sau primite). La rândul său, aceasta afectează cât de repede pot fi descărcate resursele unei pagini. Unii susțin că QUIC face asta cumva mult mai bine decât TCP, dar nu este adevărat.
Știați?
O conexiune TCP, de exemplu, nu începe doar să trimită date la lățimea de bandă completă, deoarece acest lucru ar putea duce la supraîncărcarea (sau congestionarea) rețelei. Acest lucru se datorează faptului că, așa cum am spus, fiecare legătură de rețea are doar o anumită cantitate de date pe care le poate procesa (fizic) în fiecare secundă. Dă-i mai mult și nu există altă opțiune decât să renunți la pachetele excesive, ceea ce duce la pierderea pachetelor .
După cum sa discutat în partea 1, pentru un protocol de încredere precum TCP, singura modalitate de a vă recupera de la pierderea pachetelor este prin retransmiterea unei noi copii a datelor, care durează o călătorie dus-întors. În special în rețelele cu latență mare (să zicem, cu un RTT de peste 50 de milisecunde), pierderea pachetelor poate afecta serios performanța.
O altă problemă este că nu știm de la început cât va fi lățimea de bandă maximă . Depinde adesea de un blocaj undeva în conexiunea end-to-end, dar nu putem prezice sau ști unde va fi acest lucru. De asemenea, Internetul nu are mecanisme (încă) pentru a semnala capacitățile de legătură înapoi la punctele finale.
În plus, chiar dacă am cunoaște lățimea de bandă fizică disponibilă, asta nu ar însemna că le-am putea folosi pe toate noi înșine. Mai mulți utilizatori sunt activi în mod obișnuit într-o rețea simultan, fiecare dintre aceștia având nevoie de o cotă echitabilă din lățimea de bandă disponibilă.
Ca atare, o conexiune nu știe câtă lățime de bandă poate utiliza în siguranță sau în mod corect, iar această lățime de bandă se poate modifica pe măsură ce utilizatorii se alătură, părăsesc și utilizează rețeaua. Pentru a rezolva această problemă, TCP va încerca în mod constant să descopere lățimea de bandă disponibilă în timp, utilizând un mecanism numit controlul congestiei .
La începutul conexiunii, trimite doar câteva pachete (în practică, variind între 10 și 100 de pachete, sau aproximativ 14 și 140 KB de date) și așteaptă o călătorie dus-întors până când receptorul trimite înapoi confirmări ale acestor pachete. Dacă toate sunt recunoscute, aceasta înseamnă că rețeaua poate gestiona acea rată de trimitere și putem încerca să repetăm procesul, dar cu mai multe date (în practică, rata de trimitere se dublează de obicei cu fiecare iterație).
În acest fel, rata de trimitere continuă să crească până când unele pachete nu sunt confirmate (ceea ce indică pierderea pachetelor și congestionarea rețelei). Această primă fază este de obicei numită „pornire lentă”. La detectarea pierderii pachetelor, TCP reduce rata de trimitere și (după un timp) începe să crească din nou rata de trimitere, deși în trepte (mult) mai mici. Această logică de reducere-apoi-creștere se repetă pentru fiecare pierdere de pachet ulterior. În cele din urmă, aceasta înseamnă că TCP va încerca constant să-și atingă cota de bandă ideală și corectă. Acest mecanism este ilustrat în figura 1.
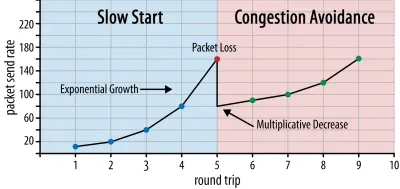
Aceasta este o explicație extrem de simplificată a controlului congestiei. În practică, sunt în joc mulți alți factori, cum ar fi bufferbloat-ul, fluctuația RTT-urilor din cauza congestiei și faptul că mai mulți expeditori concurenți trebuie să obțină partea echitabilă a lățimii de bandă. Ca atare, există mulți algoritmi diferiți de control al congestionării și încă mulți sunt inventați astăzi, niciunul nu funcționează optim în toate situațiile.
În timp ce controlul congestiei TCP îl face robust, înseamnă, de asemenea, că durează ceva timp pentru a atinge ratele de trimitere optime , în funcție de RTT și lățimea de bandă disponibilă reală. Pentru încărcarea paginilor web, această abordare cu pornire lentă poate afecta, de asemenea, valori precum prima vopsea plină de conținut, deoarece doar o cantitate mică de date (de la zeci la câteva sute de KB) poate fi transferată în primele călătorii dus-întors. (Este posibil să fi auzit recomandarea de a menține datele critice la mai puțin de 14 KB.)
Alegerea unei abordări mai agresive ar putea duce astfel la rezultate mai bune pe rețelele cu lățime de bandă mare și cu latență mare, mai ales dacă nu vă pasă de pierderea ocazională de pachete. Aici am văzut din nou multe interpretări greșite despre cum funcționează QUIC.
După cum sa discutat în partea 1, QUIC, în teorie, suferă mai puțin de pierderea pachetelor (și blocarea head-of-line (HOL) aferentă) deoarece tratează pierderea de pachete pe fluxul de octeți al fiecărei resurse în mod independent. În plus, QUIC rulează peste User Datagram Protocol (UDP), care, spre deosebire de TCP, nu are încorporată o funcție de control al congestiei; vă permite să încercați să trimiteți la orice rată doriți și nu retransmite datele pierdute.
Acest lucru a condus la multe articole care susțin că QUIC, de asemenea, nu utilizează controlul congestiei, că QUIC poate începe să trimită date la o rată mult mai mare prin UDP (bazându-se pe eliminarea blocării HOL pentru a face față pierderii de pachete), de aceea QUIC este mult mai rapid decât TCP.
În realitate, nimic mai departe de adevăr: QUIC utilizează de fapt tehnici de gestionare a lățimii de bandă foarte asemănătoare cu TCP . De asemenea, începe cu o rată de trimitere mai mică și o crește în timp, folosind recunoașterile ca mecanism cheie pentru măsurarea capacității rețelei. Acest lucru se datorează (printre alte motive) pentru că QUIC trebuie să fie de încredere pentru a fi util pentru ceva precum HTTP, pentru că trebuie să fie corect cu alte conexiuni QUIC (și TCP!) și pentru că eliminarea blocării HOL nu face de fapt ajută la pierderea pachetelor atât de bine (cum vom vedea mai jos).
Cu toate acestea, asta nu înseamnă că QUIC nu poate fi (puțin) mai inteligent în ceea ce privește modul în care gestionează lățimea de bandă decât TCP. Acest lucru se datorează în principal faptului că QUIC este mai flexibil și mai ușor de evoluat decât TCP . După cum am spus, algoritmii de control al congestionării evoluează încă în prezent și probabil că va trebui, de exemplu, să modificăm lucrurile pentru a profita la maximum de 5G.
Cu toate acestea, TCP este implementat de obicei în nucleul sistemului de operare (OS), un mediu sigur și mai restrâns, care pentru majoritatea sistemelor de operare nu este nici măcar open source. Ca atare, reglarea logicii de congestie este de obicei realizată doar de câțiva dezvoltatori selectați, iar evoluția este lentă.
În schimb, majoritatea implementărilor QUIC se fac în prezent în „spațiul utilizatorului” (unde rulăm de obicei aplicații native) și sunt făcute open source, în mod explicit pentru a încuraja experimentarea de către un grup mult mai larg de dezvoltatori (după cum a arătat deja, de exemplu, Facebook ).
Un alt exemplu concret este propunerea de extindere a frecvenței de confirmare întârziată pentru QUIC. În timp ce, în mod implicit, QUIC trimite o confirmare pentru fiecare 2 pachete primite, această extensie permite punctelor finale să confirme, de exemplu, la fiecare 10 pachete. S-a demonstrat că acest lucru oferă avantaje mari de viteză pe rețelele prin satelit și cu lățime de bandă foarte mare, deoarece suprasarcina de transmitere a pachetelor de confirmare este redusă. Adăugarea unei astfel de extensii pentru TCP ar dura mult timp pentru a fi adoptată, în timp ce pentru QUIC este mult mai ușor de implementat.
Ca atare, ne putem aștepta ca flexibilitatea lui QUIC să conducă la mai multe experimente și la algoritmi mai buni de control al congestiei în timp, care ar putea, la rândul lor, să fie, de asemenea, portați înapoi în TCP pentru a-l îmbunătăți.
Știați?
RFC 9002 oficial QUIC Recovery specifică utilizarea algoritmului de control al congestiei NewReno. Deși această abordare este robustă, este, de asemenea, oarecum depășită și nu mai este utilizată pe scară largă în practică. Deci, de ce este în QUIC RFC? Primul motiv este că atunci când a fost lansat QUIC, NewReno a fost cel mai recent algoritm de control al congestiei care a fost în sine standardizat. Algoritmii mai avansați, cum ar fi BBR și CUBIC, fie nu sunt încă standardizați, fie au devenit recent RFC.
Al doilea motiv este că NewReno este o configurare relativ simplă. Deoarece algoritmii au nevoie de câteva ajustări pentru a face față diferențelor QUIC față de TCP, este mai ușor să explicați aceste modificări pe un algoritm mai simplu. Ca atare, RFC 9002 ar trebui citit mai degrabă ca „cum să adaptezi un algoritm de control al congestiei la QUIC”, mai degrabă decât „acesta este lucrul pe care ar trebui să-l folosești pentru QUIC”. Într-adevăr, majoritatea implementărilor QUIC la nivel de producție au făcut implementări personalizate atât pentru Cubic, cât și pentru BBR.
Merită să repetăm că algoritmii de control al congestiei nu sunt specifici TCP sau QUIC ; ele pot fi utilizate prin oricare dintre protocolul și speranța este că progresele în QUIC își vor găsi în cele din urmă drumul către stivele TCP.
Știați?
Rețineți că, lângă controlul congestiei este un concept înrudit numit controlul fluxului. Aceste două caracteristici sunt adesea confundate în TCP, deoarece se spune că ambele folosesc „fereastra TCP” , deși există de fapt două ferestre: fereastra de congestie și fereastra de primire TCP. Controlul fluxului, totuși, intră în joc mult mai puțin pentru cazul de utilizare al încărcării paginilor web care ne interesează, așa că îl vom omite aici. Sunt disponibile informații mai aprofundate.
Ce înseamnă totul?
QUIC este încă legat de legile fizicii și de nevoia de a fi amabil cu alți expeditori de pe Internet. Aceasta înseamnă că nu va descărca în mod magic resursele site-ului dvs. mult mai repede decât TCP. Cu toate acestea, flexibilitatea QUIC înseamnă că experimentarea cu noi algoritmi de control al congestiei va deveni mai ușoară, ceea ce ar trebui să îmbunătățească lucrurile în viitor atât pentru TCP, cât și pentru QUIC.
Configurarea conexiunii 0-RTT
Un al doilea aspect de performanță este despre câte călătorii dus-întors sunt necesare înainte de a putea trimite date HTTP utile (de exemplu, resurse de pagină) la o nouă conexiune. Unii susțin că QUIC este cu două până la trei călătorii dus-întors mai rapide decât TCP + TLS, dar vom vedea că este într-adevăr doar unul.
Știați?
După cum am spus în partea 1, o conexiune efectuează de obicei una (TCP) sau două (TCP + TLS) strângeri de mână înainte ca cererile și răspunsurile HTTP să poată fi schimbate. Aceste strângeri de mână schimbă parametri inițiali pe care atât clientul, cât și serverul trebuie să-i cunoască pentru, de exemplu, a cripta datele.
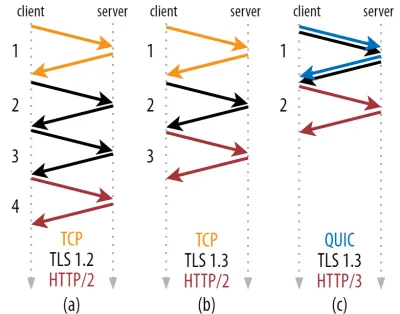
După cum puteți vedea în figura 2 de mai jos, fiecare strângere de mână individuală durează cel puțin o călătorie dus-întors (TCP + TLS 1.3, (b)) și uneori două (TLS 1.2 și anterior (a)). Acest lucru este ineficient, deoarece avem nevoie de cel puțin două călătorii dus-întors de timp de așteptare pentru strângere de mână (overhead) înainte de a putea trimite prima cerere HTTP, ceea ce înseamnă să așteptăm cel puțin trei călătorii dus-întors pentru ca primele date de răspuns HTTP (săgeata roșie care se întoarce) să vină. in. În rețelele lente, aceasta poate însemna o supraîncărcare de 100 până la 200 de milisecunde.
S-ar putea să vă întrebați de ce strângerea de mână TCP + TLS nu poate fi pur și simplu combinată, făcută în aceeași călătorie dus-întors. Deși acest lucru este posibil din punct de vedere conceptual (QUIC face exact asta), lucrurile nu au fost proiectate inițial astfel, deoarece trebuie să putem folosi TCP cu și fără TLS pe deasupra. Cu alte cuvinte, TCP pur și simplu nu acceptă trimiterea de lucruri non-TCP în timpul strângerii de mână. Au existat eforturi pentru a adăuga acest lucru cu extensia TCP Fast Open; totuși, așa cum sa discutat în partea 1, acest lucru s-a dovedit a fi dificil de implementat la scară.
Din fericire, QUIC a fost conceput de la început având în vedere TLS și, ca atare, combină atât transportul, cât și strângerile de mână criptografice într-un singur mecanism. Aceasta înseamnă că strângerea de mână QUIC va dura doar o singură călătorie dus-întors în total, care este o călătorie dus-întors mai puțin decât TCP + TLS 1.3 (vezi figura 2c de mai sus).
S-ar putea să fii confuz, pentru că probabil ai citit că QUIC este cu două sau chiar trei călătorii dus-întors mai rapide decât TCP, nu doar una. Acest lucru se datorează faptului că majoritatea articolelor iau în considerare doar cel mai rău caz (TCP + TLS 1.2, (a)), fără a menționa faptul că TCP + TLS modern 1.3, de asemenea, iau „doar” două călătorii dus-întors ((b) este rar afișat). Deși o creștere a vitezei dintr-o călătorie dus-întors este plăcută, nu este deloc uimitor. În special în rețelele rapide (să zicem, mai puțin de 50 de milisecunde RTT), acest lucru va fi abia vizibil , deși rețelele lente și conexiunile la servere îndepărtate ar profita puțin mai mult.
În continuare, s-ar putea să vă întrebați de ce trebuie să așteptăm strângerea de mână. De ce nu putem trimite o solicitare HTTP în prima călătorie dus-întors? Acest lucru se datorează în principal pentru că, dacă am face-o, atunci prima solicitare ar fi trimisă necriptată , care poate fi citită de orice interlocutor pe fir, ceea ce, evident, nu este grozav pentru confidențialitate și securitate. Ca atare, trebuie să așteptăm finalizarea strângerii de mână criptografice înainte de a trimite prima solicitare HTTP. Sau noi?
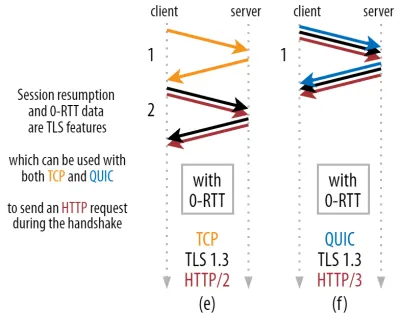
Aici este folosit un truc inteligent în practică. Știm că utilizatorii revin adesea paginile web în scurt timp de la prima lor vizită. Ca atare, putem folosi conexiunea criptată inițială pentru a porni oa doua conexiune în viitor. Mai simplu spus, cândva în timpul vieții sale, prima conexiune este folosită pentru a comunica în siguranță noi parametri criptografici între client și server. Acești parametri pot fi apoi utilizați pentru a cripta a doua conexiune încă de la început, fără a fi nevoie să așteptați finalizarea procesului de strângere de mână TLS complet. Această abordare se numește „reluare a sesiunii” .
Permite o optimizare puternică: acum putem trimite în siguranță prima noastră solicitare HTTP împreună cu strângerea de mână QUIC/TLS, economisind încă o călătorie dus-întors ! În ceea ce privește TLS 1.3, acest lucru elimină efectiv timpul de așteptare al strângerii de mână TLS. Această metodă este adesea numită 0-RTT (deși, desigur, este nevoie de încă o călătorie dus-întors pentru ca datele de răspuns HTTP să înceapă să sosească).
Atât reluarea sesiunii, cât și 0-RTT sunt, din nou, lucruri pe care le-am văzut adesea explicate greșit ca fiind caracteristici specifice QUIC. În realitate, acestea sunt de fapt caracteristici TLS care erau deja prezente într-o anumită formă în TLS 1.2 și sunt acum pe deplin în TLS 1.3.
Cu alte cuvinte, după cum puteți vedea în figura 3 de mai jos, putem obține beneficiile de performanță ale acestor funcții peste TCP (și, prin urmare, de asemenea, HTTP/2 și chiar HTTP/1.1) de asemenea! Vedem că, chiar și cu 0-RTT, QUIC este încă cu o singură călătorie dus-întors mai rapid decât o stivă TCP + TLS 1.3 care funcționează optim. Afirmația că QUIC este cu trei călătorii dus-întors mai rapidă vine din compararea figurii 2 (a) cu figura 3 (f), ceea ce, după cum am văzut, nu este cu adevărat corect.
Partea cea mai proastă este că atunci când folosește 0-RTT, QUIC nici măcar nu poate folosi atât de bine călătoria dus-întors câștigată din cauza securității. Pentru a înțelege acest lucru, trebuie să înțelegem unul dintre motivele pentru care există strângerea de mână TCP. În primul rând, permite clientului să se asigure că serverul este de fapt disponibil la adresa IP dată înainte de a-i trimite date de nivel superior.
În al doilea rând, și în mod crucial aici, permite serverului să se asigure că clientul care deschide conexiunea este de fapt cine și unde spun că este înainte de a-i trimite date. Dacă vă amintiți cum am definit o conexiune cu 4-tuplu în partea 1, veți ști că clientul este identificat în principal prin adresa sa IP. Și aceasta este problema: adresele IP pot fi falsificate !
Să presupunem că un atacator solicită un fișier foarte mare prin HTTP prin QUIC 0-RTT. Cu toate acestea, își falsifică adresa IP, făcând să pară ca și cum solicitarea 0-RTT a venit de la computerul victimei lor. Acest lucru este prezentat în figura 4 de mai jos. Serverul QUIC nu are nicio modalitate de a detecta dacă IP-ul a fost falsificat, deoarece acesta este primul pachet(e) pe care îl vede de la acel client.

Dacă serverul începe pur și simplu să trimită fișierul mare înapoi la IP-ul falsificat, ar putea ajunge să supraîncărce lățimea de bandă a rețelei victimei (mai ales dacă atacatorul ar face multe dintre aceste solicitări false în paralel). Rețineți că răspunsul QUIC ar fi abandonat de către victimă, deoarece nu se așteaptă la date primite, dar asta nu contează: rețeaua lor trebuie încă să proceseze pachetele!
Acest lucru se numește atac de reflectare, sau amplificare, și este o modalitate semnificativă prin care hackerii execută atacuri distribuite de refuzare a serviciului (DDoS). Rețineți că acest lucru nu se întâmplă atunci când este utilizat 0-RTT peste TCP + TLS, tocmai pentru că strângerea de mână TCP trebuie să se finalizeze mai întâi înainte ca cererea 0-RTT să fie trimisă împreună cu strângerea de mână TLS.
Ca atare, QUIC trebuie să fie conservator în răspunsul la solicitările 0-RTT, limitând câte date trimite ca răspuns până când clientul a fost verificat ca fiind un client real și nu o victimă. Pentru QUIC, această cantitate de date a fost setată la trei ori mai mare decât suma primită de la client.
Cu alte cuvinte, QUIC are un „factor de amplificare” maxim de trei, care a fost stabilit a fi un compromis acceptabil între utilitatea performanței și riscul de securitate (mai ales în comparație cu unele incidente care au avut un factor de amplificare de peste 51.000 de ori). Deoarece clientul trimite mai întâi doar unul sau două pachete, răspunsul 0-RTT al serverului QUIC va fi limitat la doar 4 până la 6 KB (inclusiv alte QUIC și TLS overhead!), ceea ce este ceva mai puțin impresionant.
În plus, alte probleme de securitate pot duce, de exemplu, la „atacuri de reluare”, care limitează tipul de solicitare HTTP pe care o puteți face. De exemplu, Cloudflare permite numai cereri HTTP GET fără parametri de interogare în 0-RTT. Acestea limitează și mai mult utilitatea 0-RTT.
Din fericire, QUIC are opțiuni pentru a face acest lucru puțin mai bun. De exemplu, serverul poate verifica dacă 0-RTT provine de la un IP cu care a avut o conexiune validă înainte. Cu toate acestea, acest lucru funcționează numai dacă clientul rămâne în aceeași rețea (limitând oarecum caracteristica de migrare a conexiunii QUIC). Și chiar dacă funcționează, răspunsul lui QUIC este încă limitat de logica de pornire lentă a controlorului de congestie, despre care am discutat mai sus; deci, nu există o creștere suplimentară masivă a vitezei în afară de o călătorie dus-întors salvată.
Știați?
Este interesant de observat că limita de amplificare de trei ori a lui QUIC contează și pentru procesul normal de strângere de mână non-0-RTT din figura 2c. Aceasta poate fi o problemă dacă, de exemplu, certificatul TLS al serverului este prea mare pentru a încăpea între 4 și 6 KB. În acest caz, ar trebui să fie împărțit, a doua bucată trebuind să aștepte trimiterea celei de-a doua călătorii dus-întors (după ce vin confirmările primelor pachete, indicând că IP-ul clientului nu a fost falsificat). În acest caz, strângerea de mână a lui QUIC ar putea ajunge totuși să facă două călătorii dus-întors , egale cu TCP + TLS! Acesta este motivul pentru care pentru QUIC, tehnici precum compresia certificatelor vor fi foarte importante.
Știați?
Este posibil ca anumite setări avansate să poată atenua aceste probleme suficient pentru a face 0-RTT mai util. De exemplu, serverul ar putea să-și amintească câtă lățime de bandă a avut un client disponibil ultima dată când a fost văzut, făcându-l mai puțin limitat de pornirea lentă a controlului congestiei pentru reconectarea clienților (fără falsificare). Acest lucru a fost investigat în mediul academic și există chiar și o extindere propusă în QUIC pentru a face acest lucru. Mai multe companii fac deja acest tip de lucru pentru a accelera și TCP.
O altă opțiune ar fi ca clienții să trimită mai mult de unul sau două pachete (de exemplu, trimiterea a încă 7 pachete cu padding), astfel încât limita de trei ori se traduce într-un răspuns mai interesant de 12 până la 14 KB, chiar și după migrarea conexiunii. Am scris despre asta într-una din lucrările mele.
În cele din urmă, serverele QUIC (care se comportă greșit) ar putea crește în mod intenționat limita de trei ori dacă simt că este cumva sigur să facă acest lucru sau dacă nu le pasă de potențialele probleme de securitate (la urma urmei, nu există nicio poliție de protocol care să împiedice acest lucru).
Ce înseamnă toate acestea?
Configurarea mai rapidă a conexiunii QUIC cu 0-RTT este într-adevăr mai mult o micro-optimizare decât o nouă caracteristică revoluționară. În comparație cu o configurație de ultimă oră TCP + TLS 1.3, ar economisi maximum o călătorie dus-întors. Cantitatea de date care pot fi trimise efectiv în prima călătorie dus-întors este limitată suplimentar de o serie de considerente de securitate.
Ca atare, această caracteristică va străluci în cea mai mare parte fie dacă utilizatorii dvs. se află pe rețele cu latență foarte mare (de exemplu, rețele de satelit cu RTT-uri de peste 200 de milisecunde), fie dacă de obicei nu trimiteți multe date. Câteva exemple ale acestora din urmă sunt site-urile web cu cache foarte mare, precum și aplicațiile cu o singură pagină care preiau periodic mici actualizări prin intermediul API-urilor și al altor protocoale, cum ar fi DNS-over-QUIC. Unul dintre motivele pentru care Google a văzut rezultate foarte bune 0-RTT pentru QUIC a fost că l-a testat pe pagina sa de căutare deja puternic optimizată, unde răspunsurile la interogare sunt destul de mici.
În alte cazuri, veți câștiga doar câteva zeci de milisecunde în cel mai bun caz, chiar mai puțin dacă utilizați deja un CDN (ceea ce ar trebui să faceți dacă vă pasă de performanță!).
Migrarea conexiunii
O a treia caracteristică de performanță face QUIC mai rapid la transferul între rețele, păstrând intacte conexiunile existente . Deși acest lucru funcționează într-adevăr, acest tip de schimbare a rețelei nu se întâmplă atât de des și conexiunile trebuie totuși să-și reseteze ratele de trimitere.
După cum sa discutat în partea 1, ID-urile de conexiune (CID) ale QUIC îi permit să efectueze migrarea conexiunii la schimbarea rețelelor . Am ilustrat acest lucru cu un client care trece de la o rețea Wi-Fi la 4G în timp ce descărca un fișier mare. Pe TCP, acea descărcare ar putea trebui să fie anulată, în timp ce pentru QUIC ar putea continua.
Mai întâi, totuși, luați în considerare cât de des se întâmplă de fapt acest tip de scenariu. S-ar putea să credeți că acest lucru se întâmplă și atunci când vă deplasați între punctele de acces Wi-Fi dintr-o clădire sau între turnuri celulare în timp ce sunteți pe drum. Cu toate acestea, în acele setări (dacă sunt făcute corect), dispozitivul dvs. își va păstra IP-ul intact, deoarece tranziția între stațiile de bază fără fir se face la un nivel de protocol inferior. Ca atare, apare doar atunci când vă deplasați între rețele complet diferite , ceea ce aș spune că nu se întâmplă atât de des.
În al doilea rând, ne putem întreba dacă acest lucru funcționează și pentru alte cazuri de utilizare, în afară de descărcări mari de fișiere și videoconferințe live și streaming. Dacă încărcați o pagină web în momentul exact al comutării rețelei, poate fi necesar să solicitați din nou unele dintre resursele (mai târziu).
Cu toate acestea, încărcarea unei pagini durează de obicei de ordinul secundelor, astfel încât să coincidă cu un comutator de rețea nu va fi, de asemenea, foarte frecventă. În plus, pentru cazurile de utilizare în care aceasta este o problemă presantă, alte măsuri de atenuare sunt de obicei deja aplicate . De exemplu, serverele care oferă descărcări mari de fișiere pot accepta solicitări de interval HTTP pentru a permite descărcări reluabile.
Deoarece, de obicei, există o perioadă de suprapunere între oprirea rețelei 1 și rețeaua 2 care devine disponibilă, aplicațiile video pot deschide mai multe conexiuni (1 per rețea), sincronizându-le înainte ca vechea rețea să dispară complet. Utilizatorul va observa în continuare comutatorul, dar nu va renunța în întregime la fluxul video.
În al treilea rând, nu există nicio garanție că noua rețea va avea la fel de multă lățime de bandă disponibilă ca cea veche. Ca atare, chiar dacă conexiunea conceptuală este păstrată intactă, serverul QUIC nu poate continua să trimită date la viteze mari. În schimb, pentru a evita supraîncărcarea noii rețele, aceasta trebuie să resetați (sau cel puțin să scadă) rata de trimitere și să reînceapă în faza de pornire lentă a controlorului de congestie.
Deoarece această rată de trimitere inițială este de obicei prea scăzută pentru a suporta cu adevărat lucruri precum streaming video, veți observa unele pierderi de calitate sau sughițuri, chiar și pe QUIC. Într-un fel, migrarea conexiunii se referă mai mult la prevenirea schimbării contextului de conectare și a supraîncărcării pe server decât la îmbunătățirea performanței.
Știați?
Rețineți că, așa cum sa discutat pentru 0-RTT mai sus, putem concepe câteva tehnici avansate pentru a îmbunătăți migrarea conexiunii. De exemplu, putem, din nou, să încercăm să ne amintim cât de multă lățime de bandă a fost disponibilă pe o anumită rețea data trecută și să încercăm să creștem mai repede la acel nivel pentru o nouă migrare. În plus, ne-am putea imagina nu doar comutarea între rețele, ci folosirea ambelor în același timp. Acest concept se numește multipath și îl discutăm mai detaliat mai jos.
Până acum, am vorbit în principal despre migrarea conexiunii active, în care utilizatorii se deplasează între diferite rețele. Există, însă, și cazuri de migrare pasivă a conexiunii, în care o anumită rețea schimbă ea însăși parametrii. Un bun exemplu în acest sens este relegarea traducerii adresei de rețea (NAT). Deși o discuție completă despre NAT nu intră în domeniul de aplicare al acestui articol, înseamnă în principal că numerele de port ale conexiunii se pot schimba în orice moment, fără avertisment. Acest lucru se întâmplă, de asemenea, mult mai des pentru UDP decât TCP în majoritatea routerelor.
Dacă se întâmplă acest lucru, CID-ul QUIC nu se va modifica și majoritatea implementărilor vor presupune că utilizatorul se află în continuare pe aceeași rețea fizică și, prin urmare, nu va reseta fereastra de congestie sau alți parametri. QUIC include, de asemenea, unele caracteristici, cum ar fi PING-uri și indicatori de timeout, pentru a preveni acest lucru, deoarece acest lucru se întâmplă de obicei pentru conexiunile de lungă durată.
Am discutat în partea 1 că QUIC nu folosește doar un singur CID din motive de securitate. În schimb, schimbă CID-urile atunci când efectuează migrarea activă. În practică, este și mai complicat, deoarece atât clientul, cât și serverul au liste separate de CID-uri, (numite CID-uri sursă și destinație în QUIC RFC). Acest lucru este ilustrat în figura 5 de mai jos.
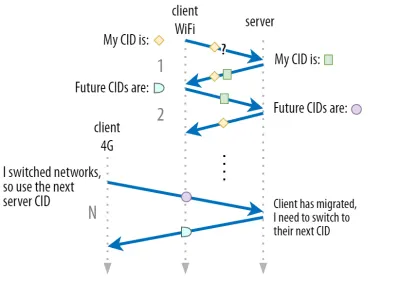
Acest lucru se face pentru a permite fiecărui punct final să aleagă propriul format și conținut CID , care, la rândul său, este crucial pentru a permite logica avansată de rutare și echilibrare a încărcăturii. Odată cu migrarea conexiunii, echilibratorii de încărcare nu mai pot doar să se uite la 4-tuplu pentru a identifica o conexiune și a o trimite la serverul back-end corect. Cu toate acestea, dacă toate conexiunile QUIC ar folosi CID-uri aleatorii, acest lucru ar crește considerabil cerințele de memorie la echilibratorul de încărcare, deoarece ar trebui să stocheze mapările CID-urilor pe serverele back-end. În plus, acest lucru încă nu ar funcționa cu migrarea conexiunii, deoarece CID-urile se schimbă la noi valori aleatorii.
Ca atare, este important ca serverele back-end QUIC implementate în spatele unui echilibrator de încărcare să aibă un format previzibil al CID-urilor lor, astfel încât echilibratorul de încărcare să poată obține serverul back-end corect din CID, chiar și după migrare. Unele opțiuni pentru a face acest lucru sunt descrise în documentul propus de IETF. Pentru a face totul posibil, serverele trebuie să poată alege propriul CID, ceea ce nu ar fi posibil dacă inițiatorul conexiunii (care, pentru QUIC, este întotdeauna clientul) ar alege CID-ul. Acesta este motivul pentru care există o împărțire între CID-urile client și server în QUIC.

Ce înseamnă toate acestea?
Astfel, migrarea conexiunii este o caracteristică situațională. Testele inițiale efectuate de Google, de exemplu, arată îmbunătățiri procentuale scăzute pentru cazurile sale de utilizare. Multe implementări QUIC nu implementează încă această caracteristică. Chiar și cei care o fac, de obicei, o vor limita la clienții și aplicațiile mobile și nu la echivalentele lor desktop. Unii oameni sunt chiar de părere că funcția nu este necesară, deoarece deschiderea unei noi conexiuni cu 0-RTT ar trebui să aibă proprietăți de performanță similare în majoritatea cazurilor.
Totuși, în funcție de cazul dvs. de utilizare sau de profilul de utilizator, ar putea avea un impact mare. Dacă site-ul sau aplicația dvs. este folosită cel mai des în timp ce sunteți în mișcare (de exemplu, ceva de genul Uber sau Google Maps), atunci probabil ați beneficia mai mult decât dacă utilizatorii dvs. ar sta de obicei în spatele unui birou. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
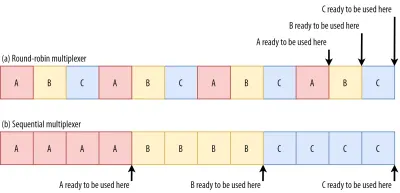
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
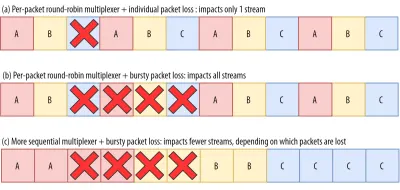
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
Ce înseamnă toate acestea?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
Performanță UDP și TLS
Un al cincilea aspect de performanță al QUIC și HTTP/3 este despre cât de eficient și de performanță pot crea și trimite pachete în rețea. Vom vedea că utilizarea de către QUIC a UDP și a criptării grele poate face un pic mai lent decât TCP (dar lucrurile se îmbunătățesc).
În primul rând, am discutat deja că utilizarea UDP de către QUIC a fost mai mult despre flexibilitate și implementare decât despre performanță. Acest lucru este evidențiat și mai mult de faptul că, până de curând, trimiterea pachetelor QUIC prin UDP era de obicei mult mai lentă decât trimiterea pachetelor TCP. Acest lucru se datorează parțial locului și modului în care aceste protocoale sunt implementate de obicei (a se vedea figura 9 de mai jos).
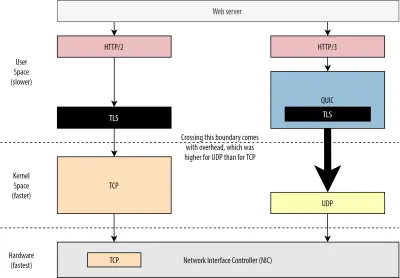
După cum sa discutat mai sus, TCP și UDP sunt de obicei implementate direct în nucleul rapid al sistemului de operare. În schimb, implementările TLS și QUIC sunt în mare parte în spațiul utilizatorului mai lent (rețineți că acest lucru nu este cu adevărat necesar pentru QUIC - se face în mare parte pentru că este mult mai flexibil). Acest lucru face ca QUIC să fie deja puțin mai lent decât TCP.
În plus, atunci când trimitem date din software-ul nostru pentru spațiul utilizatorului (de exemplu, browsere și servere web), trebuie să transmitem aceste date nucleului sistemului de operare , care apoi utilizează TCP sau UDP pentru a le pune efectiv în rețea. Transmiterea acestor date se face folosind API-uri kernel (apeluri de sistem), care implică o anumită sumă de suprasarcină per apel API. Pentru TCP, aceste costuri generale au fost mult mai mici decât pentru UDP.
Acest lucru se datorează faptului că, din punct de vedere istoric, TCP a fost folosit mult mai mult decât UDP. Ca atare, de-a lungul timpului, multe optimizări au fost adăugate la implementările TCP și la API-urile kernelului pentru a reduce la minimum costurile generale de trimitere și primire a pachetelor. Multe controlere de interfață de rețea (NIC) au chiar și caracteristici de descărcare hardware încorporate pentru TCP. UDP, însă, nu a fost la fel de norocos, deoarece utilizarea sa mai limitată nu a justificat investiția în optimizări suplimentare. În ultimii cinci ani, acest lucru s-a schimbat, din fericire, iar majoritatea sistemelor de operare au adăugat de atunci și opțiuni optimizate pentru UDP .
În al doilea rând, QUIC are o mulțime de costuri generale, deoarece criptează fiecare pachet individual . Acest lucru este mai lent decât utilizarea TLS peste TCP, deoarece acolo puteți cripta pachetele în bucăți (până la aproximativ 16 KB sau 11 pachete o dată), ceea ce este mai eficient. Acesta a fost un compromis conștient făcut în QUIC, deoarece criptarea în bloc poate duce la propriile forme de blocare HoL.
Spre deosebire de primul punct, unde am putea adăuga API-uri suplimentare pentru a face UDP (și astfel QUIC) mai rapid, aici, QUIC va avea întotdeauna un dezavantaj inerent față de TCP + TLS. Cu toate acestea, acest lucru este, de asemenea, destul de ușor de gestionat în practică, de exemplu, cu biblioteci de criptare optimizate și metode inteligente care permit ca anteturile pachetelor QUIC să fie criptate în bloc.
Drept urmare, în timp ce primele versiuni QUIC ale Google erau încă de două ori mai lente decât TCP + TLS, lucrurile s-au îmbunătățit cu siguranță de atunci. De exemplu, în testele recente, stiva QUIC puternic optimizată de la Microsoft a reușit să obțină 7,85 Gbps, comparativ cu 11,85 Gbps pentru TCP + TLS pe același sistem (deci aici, QUIC este cu aproximativ 66% mai rapid ca TCP + TLS).
Acest lucru se întâmplă cu actualizările recente de Windows, care au făcut UDP mai rapid (pentru o comparație completă, debitul UDP pe acel sistem a fost de 19,5 Gbps). Cea mai optimizată versiune a stivei QUIC de la Google este în prezent cu aproximativ 20% mai lentă decât TCP + TLS. Testele anterioare efectuate de Fastly pe un sistem mai puțin avansat și cu câteva trucuri pretind chiar performanțe egale (aproximativ 450 Mbps), arătând că, în funcție de cazul de utilizare, QUIC poate concura cu siguranță TCP.
Cu toate acestea, chiar dacă QUIC a fost de două ori mai lent decât TCP + TLS, nu este chiar atât de rău. În primul rând, procesarea QUIC și TCP + TLS nu este de obicei cel mai greu lucru care se întâmplă pe un server, deoarece trebuie să se execute și altă logică (să zicem, HTTP, caching, proxy etc.). Ca atare, de fapt nu veți avea nevoie de două ori mai multe servere pentru a rula QUIC (totuși, este puțin neclar cât de mult impact va avea într-un centru de date real, deoarece niciuna dintre marile companii nu a lansat date despre asta).
În al doilea rând, există încă o mulțime de oportunități de optimizare a implementărilor QUIC în viitor. De exemplu, în timp, unele implementări QUIC se vor muta (parțial) în nucleul sistemului de operare (la fel ca TCP) sau îl vor ocoli (unele o fac deja, cum ar fi MsQuic și Quant). De asemenea, ne putem aștepta ca hardware-ul specific QUIC să devină disponibil.
Totuși, probabil că vor exista unele cazuri de utilizare pentru care TCP + TLS va rămâne opțiunea preferată. De exemplu, Netflix a indicat că probabil că nu se va muta la QUIC în curând, după ce a investit foarte mult în configurații personalizate FreeBSD pentru a-și transmite videoclipurile prin TCP + TLS.
În mod similar, Facebook a spus că QUIC va fi probabil utilizat în principal între utilizatorii finali și marginea CDN-ului , dar nu între centrele de date sau între nodurile de margine și serverele de origine, din cauza supraîncărcării sale mai mari. În general, scenariile cu lățime de bandă foarte mare vor continua probabil să favorizeze TCP + TLS, mai ales în următorii câțiva ani.
Știați?
Optimizarea stivelor de rețea este o gaură profundă și tehnică a cărei cele de mai sus doar zgârie suprafața (și ratează multe nuanțe). Dacă sunteți suficient de curajos sau dacă doriți să știți ce înseamnă termeni precumGRO/GSO,SO_TXTIME, kernel bypass șisendmmsg()șirecvmmsg(), vă pot recomanda câteva articole excelente despre optimizarea QUIC de către Cloudflare și Fastly, de asemenea ca o prezentare extinsă a codului de la Microsoft și o discuție aprofundată de la Cisco. În cele din urmă, un inginer Google a oferit o prezentare foarte interesantă despre optimizarea implementării lor QUIC în timp.
Ce înseamnă toate acestea?
Utilizarea specială de către QUIC a protocoalelor UDP și TLS a făcut-o din trecut mult mai lent decât TCP + TLS. Cu toate acestea, de-a lungul timpului, au fost aduse (și vor continua să fie implementate) câteva îmbunătățiri care au redus oarecum decalajul. Cu toate acestea, probabil că nu veți observa aceste discrepanțe în cazurile de utilizare tipice ale încărcării paginilor web, dar vă pot da bătăi de cap dacă mențineți ferme de servere mari.
Caracteristici HTTP/3
Până acum, am vorbit în principal despre noile funcții de performanță în QUIC versus TCP. Cu toate acestea, cum rămâne cu HTTP/3 versus HTTP/2? După cum sa discutat în partea 1, HTTP/3 este cu adevărat HTTP/2-over-QUIC și, ca atare, nu au fost introduse funcții noi reale, mari în noua versiune. Acest lucru este spre deosebire de trecerea de la HTTP/1.1 la HTTP/2, care a fost mult mai mare și a introdus noi funcții, cum ar fi compresia antetului, prioritizarea fluxului și împingerea serverului. Toate aceste caracteristici sunt încă în HTTP/3, dar există câteva diferențe importante în modul în care sunt implementate sub capotă.
Acest lucru se datorează în mare parte modului în care funcționează eliminarea de către QUIC a blocării HoL. După cum am discutat, o pierdere a fluxului B nu mai implică faptul că fluxurile A și C vor trebui să aștepte retransmisiile lui B, așa cum au făcut prin TCP. Ca atare, dacă A, B și C au trimis fiecare un pachet QUIC în acea ordine, datele lor ar putea fi livrate (și procesate de) browser ca A, C, B! Cu alte cuvinte, spre deosebire de TCP, QUIC nu mai este ordonat în totalitate în diferite fluxuri!
Aceasta este o problemă pentru HTTP/2, care s-a bazat într-adevăr pe ordonarea strictă a TCP în proiectarea multor caracteristici ale sale, care utilizează mesaje speciale de control intercalate cu bucăți de date. În QUIC, aceste mesaje de control ar putea ajunge (și pot fi aplicate) în orice ordine, potențial chiar făcând ca funcțiile să facă opusul a ceea ce era intenționat! Detaliile tehnice sunt, din nou, inutile pentru acest articol, dar prima jumătate a acestei lucrări ar trebui să vă dea o idee despre cât de stupid poate deveni acest lucru.
Ca atare, mecanica internă și implementările caracteristicilor au trebuit să se schimbe pentru HTTP/3. Un exemplu concret este compresia antetului HTTP , care reduce supraîncărcarea antetelor HTTP mari repetate (de exemplu, cookie-uri și șiruri user-agent). În HTTP/2, acest lucru a fost realizat utilizând configurația HPACK, în timp ce pentru HTTP/3 acest lucru a fost reluat la QPACK mai complex. Ambele sisteme oferă aceeași caracteristică (adică compresia antetului), dar în moduri destul de diferite. Câteva discuții tehnice profunde excelente și diagrame pe acest subiect pot fi găsite pe blogul Litespeed.
Ceva similar este adevărat pentru caracteristica de prioritizare care conduce logica de multiplexare a fluxului și despre care am discutat pe scurt mai sus. În HTTP/2, acest lucru a fost implementat folosind o configurație complexă „arborele de dependență”, care a încercat în mod explicit să modeleze toate resursele paginii și interrelațiile lor (mai multe informații găsiți în discuția „Ghidul final pentru prioritizarea resurselor HTTP”). Folosirea acestui sistem direct prin QUIC ar duce la unele configurații de arbore potențial foarte greșite, deoarece adăugarea fiecărei resurse la arbore ar fi un mesaj de control separat.
În plus, această abordare s-a dovedit a fi inutil de complexă, ceea ce duce la multe erori de implementare și ineficiențe și performanțe slabe pe multe servere. Ambele probleme au determinat ca sistemul de prioritizare să fie reproiectat pentru HTTP/3 într-un mod mult mai simplu. Această configurare mai simplă face ca unele scenarii avansate să fie dificil sau imposibil de aplicat (de exemplu, transferarea traficului de la mai mulți clienți pe o singură conexiune), dar permite totuși o gamă largă de opțiuni pentru optimizarea încărcării paginilor web.
În timp ce, din nou, cele două abordări oferă aceeași caracteristică de bază (ghidând multiplexarea fluxului), speranța este că configurarea mai ușoară a HTTP/3 va face mai puține erori de implementare.
În cele din urmă, există server push . Această caracteristică permite serverului să trimită răspunsuri HTTP fără a aștepta mai întâi o solicitare explicită pentru acestea. În teorie, acest lucru ar putea oferi câștiguri excelente de performanță. În practică, însă, sa dovedit a fi greu de utilizat corect și implementat în mod inconsecvent. Ca rezultat, probabil chiar va fi eliminat din Google Chrome.
Cu toate acestea, este încă definită ca o caracteristică în HTTP/3 (deși puține implementări o acceptă). În timp ce funcționarea sa internă nu s-a schimbat la fel de mult ca cele două caracteristici anterioare, și el a fost adaptat pentru a funcționa în jurul ordonării nedeterministe a QUIC. Din păcate, totuși, acest lucru va ajuta puțin pentru a rezolva unele dintre problemele sale de lungă durată.
Ce înseamnă toate acestea?
După cum am spus anterior, cea mai mare parte a potențialului HTTP/3 provine din QUIC-ul de bază, nu HTTP/3 în sine. Deși implementarea internă a protocolului este foarte diferită de cea a HTTP/2, caracteristicile sale de performanță la nivel înalt și modul în care pot și ar trebui utilizate au rămas aceleași.
Evoluții viitoare de urmărit
În această serie, am subliniat în mod regulat că o evoluție mai rapidă și o flexibilitate mai mare sunt aspecte de bază ale QUIC (și, prin extensie, HTTP/3). Ca atare, nu ar trebui să fie surprinzător faptul că oamenii lucrează deja la noi extensii și aplicații ale protocoalelor. Mai jos sunt enumerate principalele pe care probabil le veți întâlni undeva în continuare:
Redirecționarea erorilor
Acest scop al acestei tehnici este, din nou, de a îmbunătăți rezistența QUIC la pierderea de pachete . Face acest lucru prin trimiterea de copii redundante ale datelor (deși codate și comprimate inteligent, astfel încât acestea să nu fie la fel de mari). Apoi, dacă se pierde un pachet, dar sosesc datele redundante, nu mai este necesară o retransmisie.
Aceasta a fost inițial o parte a Google QUIC (și unul dintre motivele pentru care oamenii spun că QUIC este bun împotriva pierderii de pachete), dar nu este inclus în versiunea standardizată QUIC 1, deoarece impactul său asupra performanței nu a fost încă dovedit. Totuși, cercetătorii efectuează acum experimente active cu acesta și îi puteți ajuta folosind aplicația PQUIC-FEC Download Experiments.Multipath QUIC
Am discutat anterior despre migrarea conexiunii și cum poate ajuta atunci când treceți de la, de exemplu, Wi-Fi la cel mobil. Totuși, asta nu implică și că am putea folosi atât Wi-Fi, cât și cel mobil în același timp ? Utilizarea concomitentă a ambelor rețele ne-ar oferi mai multă lățime de bandă disponibilă și robustețe sporită! Acesta este conceptul principal din spatele multipath.
Acesta este, din nou, ceva cu care Google a experimentat, dar care nu a ajuns în versiunea 1 a QUIC din cauza complexității sale inerente. Cu toate acestea, cercetătorii au arătat de atunci potențialul său ridicat și ar putea ajunge în versiunea 2 a QUIC. Rețineți că există și căi multiple TCP, dar a durat aproape un deceniu pentru a deveni practic utilizabil.Date nesigure prin QUIC și HTTP/3
După cum am văzut, QUIC este un protocol complet de încredere. Cu toate acestea, deoarece rulează peste UDP, care nu este de încredere, putem adăuga o funcție la QUIC pentru a trimite și date nesigure. Acest lucru este subliniat în extensia de datagramă propusă. Desigur, nu ați dori să utilizați acest lucru pentru a trimite resurse ale paginii web, dar ar putea fi util pentru lucruri precum jocuri și streaming video live. În acest fel, utilizatorii vor beneficia de toate beneficiile UDP, dar cu criptarea la nivel QUIC și controlul congestiei (opțional).WebTransport
Browserele nu expun TCP sau UDP direct JavaScript, în principal din cauza problemelor de securitate. În schimb, trebuie să ne bazăm pe API-uri la nivel HTTP, cum ar fi Fetch și pe protocoalele WebSocket și WebRTC ceva mai flexibile. Cel mai nou din această serie de opțiuni se numește WebTransport, care vă permite în principal să utilizați HTTP/3 (și, prin extensie, QUIC) într-un mod mai la nivel scăzut (deși poate reveni și la TCP și HTTP/2 dacă este necesar). ).
În mod esențial, va include capacitatea de a utiliza date nesigure prin HTTP/3 (a se vedea punctul anterior), ceea ce ar trebui să facă lucruri precum jocurile destul de ușor de implementat în browser. Pentru apelurile API normale (JSON), veți folosi, desigur, în continuare Fetch, care va folosi automat HTTP/3 atunci când este posibil. WebTransport este încă în discuții intense în acest moment, așa că nu este încă clar cum va arăta în cele din urmă. Dintre browsere, doar Chromium lucrează în prezent la o implementare publică a dovezii de concept.Streaming video DASH și HLS
Pentru videoclipuri non-live (gândiți-vă la YouTube și Netflix), browserele folosesc de obicei protocoalele Dynamic Adaptive Streaming prin HTTP (DASH) sau HTTP Live Streaming (HLS). Ambele înseamnă practic că vă codificați videoclipurile în bucăți mai mici (de la 2 până la 10 secunde) și niveluri de calitate diferite (720p, 1080p, 4K etc.).
În timpul rulării, browserul estimează cea mai înaltă calitate pe care o poate gestiona rețeaua dvs. (sau cea mai optimă pentru un anumit caz de utilizare) și solicită fișierele relevante de la server prin HTTP. Deoarece browserul nu are acces direct la stiva TCP (așa cum este implementat de obicei în kernel), ocazional face câteva greșeli în aceste estimări sau durează ceva timp pentru a reacționa la schimbarea condițiilor rețelei (ducând la blocaje video) .
Deoarece QUIC este implementat ca parte a browserului, acest lucru ar putea fi îmbunătățit destul de mult, oferind estimatorilor de streaming acces la informații de protocol de nivel scăzut (cum ar fi ratele de pierdere, estimările lățimii de bandă etc.). Alți cercetători au experimentat amestecarea datelor fiabile și nesigure pentru streaming video, cu unele rezultate promițătoare.Alte protocoale decât HTTP/3
Având în vedere că QUIC este un protocol de transport de uz general, ne putem aștepta ca multe protocoale de nivel de aplicație care rulează acum peste TCP să fie rulate și peste QUIC. Unele lucrări în curs includ DNS-over-QUIC, SMB-over-QUIC și chiar SSH-over-QUIC. Deoarece aceste protocoale au de obicei cerințe foarte diferite față de HTTP și încărcarea paginilor web, îmbunătățirile de performanță ale QUIC despre care am discutat ar putea funcționa mult mai bine pentru aceste protocoale.
Ce înseamnă toate acestea?
QUIC versiunea 1 este doar începutul . Multe funcții avansate orientate spre performanță pe care Google le-a experimentat anterior nu au ajuns în această primă iterație. Totuși, scopul este de a evolua rapid protocolul, introducând noi extensii și caracteristici la o frecvență înaltă. Ca atare, în timp, QUIC (și HTTP/3) ar trebui să devină în mod clar mai rapid și mai flexibil decât TCP (și HTTP/2).
Concluzie
În această a doua parte a seriei, am discutat despre numeroasele caracteristici și aspecte de performanță diferite ale HTTP/3 și în special QUIC. Am văzut că, deși majoritatea acestor funcții par foarte de impact, în practică s-ar putea să nu aducă prea mult pentru utilizatorul obișnuit în cazul de utilizare al încărcării paginilor web pe care l-am luat în considerare.
De exemplu, am văzut că utilizarea de către QUIC a UDP nu înseamnă că poate folosi brusc mai multă lățime de bandă decât TCP și nici nu înseamnă că vă poate descărca resursele mai rapid. Funcția 0-RTT, adesea lăudată, este într-adevăr o micro-optimizare care vă scutește de o călătorie dus-întors, în care puteți trimite aproximativ 5 KB (în cel mai rău caz).
Eliminarea blocării HoL nu funcționează bine dacă există o pierdere de pachete în rafală sau când încărcați resurse care blochează randamentul. Migrarea conexiunii este foarte situațională, iar HTTP/3 nu are caracteristici noi majore care ar putea să o facă mai rapidă decât HTTP/2.
Ca atare, s-ar putea să vă așteptați să vă recomand să omiteți HTTP/3 și QUIC. De ce să te deranjezi, nu? Cu toate acestea, cu siguranță nu voi face așa ceva! Chiar dacă aceste noi protocoale s-ar putea să nu ajute prea mult utilizatorii din rețelele rapide (urbane), noile caracteristici au cu siguranță potențialul de a avea un mare impact pentru utilizatorii cu mobilitate ridicată și pentru persoanele din rețele lente.
Chiar și pe piețele occidentale, cum ar fi Belgia mea, unde avem în general dispozitive rapide și acces la rețele celulare de mare viteză, aceste situații pot afecta 1% până la 10% din baza dvs. de utilizatori, în funcție de produs. Un exemplu este cineva dintr-un tren care încearcă cu disperare să caute o informație critică pe site-ul dvs. web, dar trebuie să aștepte 45 de secunde pentru a se încarca. Știu cu siguranță că am fost în acea situație, dorindu-mi ca cineva să fi instalat QUIC pentru a mă scoate din ea.
Cu toate acestea, există și alte țări și regiuni în care lucrurile stau încă mult mai rău. Acolo, utilizatorul mediu ar putea să semene mult mai mult cu cel mai lent 10% din Belgia, iar cel mai lent 1% ar putea să nu ajungă niciodată să vadă o pagină încărcată. În multe părți ale lumii, performanța web este o problemă de accesibilitate și incluziune.
Acesta este motivul pentru care nu ar trebui să ne testăm paginile pe propriul hardware (ci să folosim și un serviciu precum Webpagetest) și, de asemenea, de ce ar trebui să implementați cu siguranță QUIC și HTTP/3 . Mai ales dacă utilizatorii dvs. sunt adesea în mișcare sau este puțin probabil să aibă acces la rețele celulare rapide, aceste noi protocoale ar putea face o lume de diferență, chiar dacă nu observați prea multe pe MacBook Pro cu cablu. Pentru mai multe detalii, recomand cu căldură postarea lui Fastly despre această problemă.
Dacă acest lucru nu vă convinge pe deplin, atunci luați în considerare că QUIC și HTTP/3 vor continua să evolueze și să devină mai rapid în anii următori. Obținerea unei experiențe timpurii cu protocoalele va da roade pe drum, permițându-vă să beneficiați de avantajele noilor funcții cât mai curând posibil. În plus, QUIC impune cele mai bune practici de securitate și confidențialitate în fundal, de care beneficiază toți utilizatorii de pretutindeni.
În sfârșit convins? Apoi continuați cu partea 3 a seriei pentru a citi despre cum puteți folosi noile protocoale în practică.
- Partea 1: Istoria HTTP/3 și conceptele de bază
Acest articol se adresează persoanelor care nu cunosc HTTP/3 și protocoalele în general și discută în principal elementele de bază. - Partea 2: Caracteristici de performanță HTTP/3
Acesta este mai profund și mai tehnic. Oamenii care cunosc deja elementele de bază pot începe aici. - Partea 3: Opțiuni practice de implementare HTTP/3
Acest al treilea articol din serie explică provocările implicate în implementarea și testarea dvs. HTTP/3. Acesta detaliază cum și dacă ar trebui să vă schimbați paginile web și resursele.