
Cum se implementează clasificarea în Machine Learning?
Publicat: 2021-03-12Aplicarea învățării automate în diverse domenii a crescut cu pasi în ultimii ani și continuă să o facă. Una dintre cele mai populare sarcini ale modelului de învățare automată este recunoașterea obiectelor și separarea lor în clasele lor desemnate.
Aceasta este metoda de clasificare care este una dintre cele mai populare aplicații ale Machine Learning. Clasificarea este folosită pentru a separa o cantitate imensă de date într-un set de valori discrete care pot fi binare, cum ar fi 0/1, Da/Nu, sau cu mai multe clase, cum ar fi animale, mașini, păsări etc.
În articolul următor, vom înțelege conceptul de clasificare în Machine Learning, tipurile de date implicate și vom vedea unii dintre cei mai populari algoritmi de clasificare utilizați în Machine Learning pentru a clasifica mai multe date.
Cuprins
Ce este învățarea supravegheată?
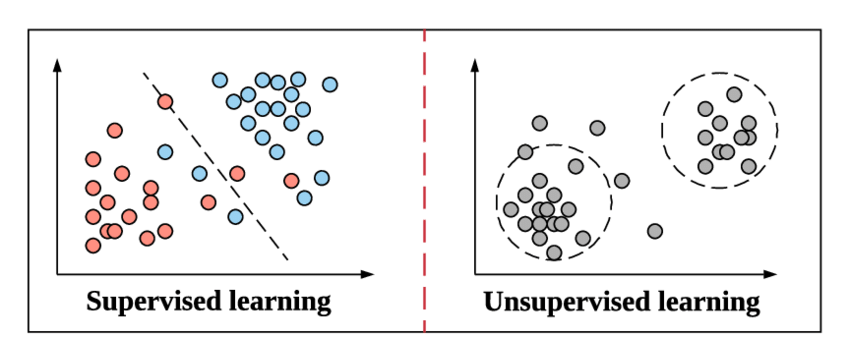
Pe măsură ce ne pregătim să pătrundem în conceptul de clasificare și tipurile sale, să ne reîmprospătăm rapid cu ce se înțelege prin învățare supravegheată și cum diferă de cealaltă metodă de învățare nesupravegheată în învățarea automată.
Să înțelegem acest lucru luând un exemplu simplu de la ora noastră de fizică din liceu. Să presupunem că există o problemă simplă care implică o nouă metodă. Dacă ni se prezintă o întrebare la care trebuie să rezolvăm folosind aceeași metodă, nu ne-am referi cu toții la un exemplu de problemă cu aceeași metodă și nu am încerca să o rezolvăm. Odată ce suntem încrezători în această metodă, nu trebuie să ne referim la ea din nou și să continuăm să o rezolvăm.
Sursă

Acesta este același mod în care funcționează învățarea supravegheată în învățarea automată. Se învață prin exemplu. Pentru a rămâne și mai simplu, în Învățare Supervizată, toate datele sunt alimentate cu etichetele lor corespunzătoare și, prin urmare, în timpul procesului de instruire, modelul de învățare automată compară rezultatul pentru anumite date cu rezultatul real al acelorași date și încearcă să minimizați eroarea atât între valoarea estimată, cât și cea reală.
Algoritmii de clasificare pe care îi vom parcurge în acest articol urmează această metodă de învățare supravegheată, de exemplu, detectarea spamului și recunoașterea obiectelor.
Învățarea nesupravegheată este un pas de mai sus în care datele nu sunt alimentate cu etichetele sale. Este responsabilitatea și eficiența modelului de învățare automată să obțină modele din date și să dea rezultatul. Algoritmii de grupare urmează această metodă de învățare nesupravegheată.
Ce este clasificarea?
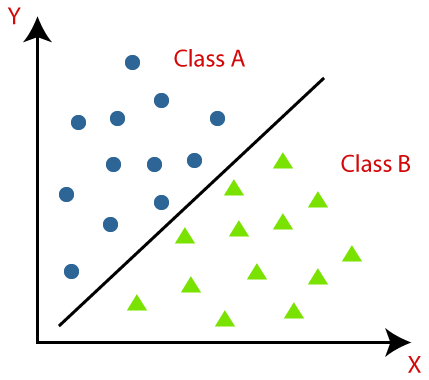
Clasificarea este definită ca recunoașterea, înțelegerea și gruparea obiectelor sau datelor în clase prestabilite. Prin categorizarea datelor înainte de procesul de antrenament al modelului Machine Learning, putem folosi diverși algoritmi de clasificare pentru a clasifica datele în mai multe clase. Spre deosebire de regresie, o problemă de clasificare este atunci când variabila de ieșire este o categorie, cum ar fi „Da” sau „Nu” sau „Boală” sau „Fără boală”.
În majoritatea problemelor de învățare automată, odată ce setul de date este încărcat în program, înainte de antrenament, împărțirea setului de date într-un set de antrenament și setul de testare cu un raport fix (De obicei 70% set de antrenament și 30% set de testare). Acest proces de divizare permite modelului să efectueze propagarea inversă în care încearcă să-și corecteze eroarea valorii prezise față de valoarea adevărată prin mai multe aproximări matematice.
În mod similar, înainte de a începe Clasificarea, se creează setul de date de antrenament. Algoritmul de clasificare este supus antrenamentului pe acesta în timp ce testează setul de date de testare cu fiecare iterație, cunoscută sub numele de epocă.
Sursă
Una dintre cele mai comune aplicații de algoritmi de clasificare este filtrarea e-mailurilor pentru a stabili dacă sunt „spam” sau „non-spam”. Pe scurt, putem defini Clasificarea în Machine Learning ca o formă de „Recunoaștere a modelelor” în care acești algoritmi care sunt aplicați datelor de antrenament sunt utilizați pentru a extrage mai multe modele din date (cum ar fi cuvinte similare sau secvențe de numere, sentimente etc. .).
Clasificarea este un proces de clasificare a unui set dat de date în clase; poate fi efectuată atât pe date structurate, cât și pe date nestructurate. Începe prin a prezice clasa punctelor date date. Aceste clase sunt denumite și variabile de ieșire, etichete țintă etc. Mai mulți algoritmi au funcții matematice încorporate pentru a aproxima funcția de mapare de la variabilele punctului de date de intrare la clasa țintă de ieșire. Scopul principal al clasificării este de a identifica în ce clasă/categorie se vor încadra noile date.
Tipuri de algoritmi de clasificare în învățarea automată
În funcție de tipul de date pe care se aplică algoritmii de clasificare, există două categorii largi de algoritmi, modelele liniare și neliniare.
Modele liniare
- Regresie logistică
- Suport Vector Machines (SVM)
Modele neliniare
- Clasificarea K-Nearest Neighbours (KNN).
- Kernel SVM
- Clasificarea naivă Bayes
- Clasificarea arborelui de decizie
- Clasificare aleatorie a pădurilor
În acest articol, vom trece pe scurt prin conceptul din spatele fiecărui algoritm menționați mai sus.
Evaluarea unui model de clasificare în Machine Learning
Înainte de a trece la conceptele acestor algoritmi menționate mai sus, trebuie să înțelegem cum putem evalua modelul nostru de învățare automată construit pe baza acestor algoritmi. Este esențial să evaluăm modelul nostru pentru acuratețe atât pe setul de antrenament, cât și pe setul de testare.
Pierdere de entropie încrucișată sau pierdere de log
Acesta este primul tip de funcție de pierdere pe care o vom folosi în evaluarea performanței unui clasificator a cărui ieșire este între 0 și 1. Aceasta este folosită mai ales pentru modelele de clasificare binară. Formula Log Loss este dată de,
Pierdere log = -((1 – y) * log(1 – yhat) + y * log(yhat))
Unde aceasta este valoarea prezisă și y este valoarea reală.
Matricea confuziei
O matrice de confuzie este o matrice NXN, unde N este numărul de clase care sunt prezise. Matricea de confuzie ne oferă o matrice/tabel ca rezultat și descrie performanța modelului. Constă în rezultatul predicțiilor sub forma unei matrice din care putem deriva mai multe metrici de performanță pentru a evalua modelul de clasificare. Este de forma,
| Pozitiv real | Negativ real | |
| Pozitiv prezis | Adevărat pozitiv | Fals pozitiv |
| Negativ prezis | Fals Negativ | Adevărat negativ |
Câteva dintre valorile de performanță care pot fi derivate din tabelul de mai sus sunt prezentate mai jos.
1.Acuratețea – proporția din numărul total de predicții corecte.
2. Valoare sau Precizie Predictivă Pozitivă – proporția de cazuri pozitive identificate corect.
3. Valoarea predictivă negativă – proporția de cazuri negative identificate corect.
4. Sensibilitate sau Rechemare – proporția de cazuri pozitive reale care sunt identificate corect.
5. Specificitate – proporția de cazuri negative reale care sunt corect identificate.
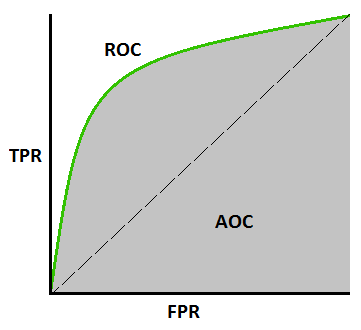
Curba AUC-ROC –
Aceasta este o altă metrică de curbă importantă care evaluează orice model de învățare automată. Curba ROC înseamnă Curba caracteristicilor de funcționare a receptorului, iar AUC înseamnă Area Under the Curve. Curba ROC este reprezentată grafic cu TPR și FPR, unde TPR (True Positive Rate) pe axa Y și FPR (False Positive Rate) pe axa X. Acesta arată performanța modelului de clasificare la diferite praguri.
Sursă
1. Regresia logistică
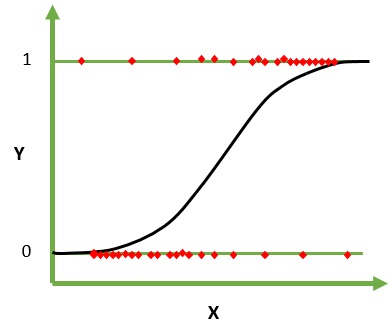
Regresia logistică este un algoritm de învățare automată pentru clasificare. În acest algoritm, probabilitățile care descriu rezultatele posibile ale unui singur studiu sunt modelate folosind o funcție logistică. Se presupune că variabilele de intrare sunt numerice și au o distribuție Gaussiană (curba clopot).
Funcția logistică, numită și funcție sigmoidă, a fost folosită inițial de statisticieni pentru a descrie creșterea populației în ecologie. Funcția sigmoidă este o funcție matematică utilizată pentru a mapa valorile prezise la probabilități. Regresia logistică are o curbă în formă de S și poate lua valori între 0 și 1, dar niciodată exact la acele limite.

Sursă
Regresia logistică este folosită în primul rând pentru a prezice un rezultat binar, cum ar fi Da/Nu și un succes/eșec. Variabilele independente pot fi categorice sau numerice, dar variabila dependentă este întotdeauna categorică. Formula pentru regresia logistică este dată de,
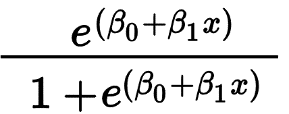
Unde e reprezintă curba în formă de S care are valori între 0 și 1.
2. Suport mașini Vector
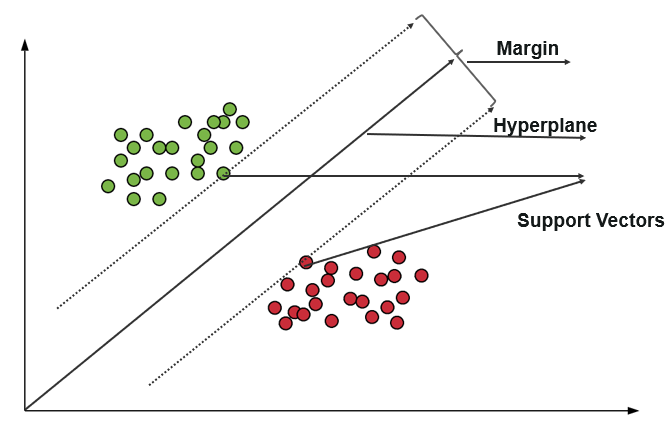
O mașină vectorială de suport (SVM) folosește algoritmi pentru a antrena și clasifica datele în grade de polaritate, ducându-le la un grad dincolo de predicția X/Y. În SVM, linia care este folosită pentru a separa clasele este denumită Hyperplane. Punctele de date de pe fiecare parte a Hiperplanului cel mai apropiat de Hiperplan se numesc Vectori de Suport, utilizați pentru a trasa linia de delimitare.
Această Mașină Vector Suport în Clasificare reprezintă datele de antrenament ca puncte de date într-un spațiu în care multe categorii sunt separate în categoriile Hyperplane. Când intră un punct nou, acesta este clasificat prin prezicerea în ce categorie se încadrează și aparțin unui anumit spațiu.
Sursă
Scopul principal al mașinii Support Vector este de a maximiza marja dintre cei doi Support Vectori.
Alăturați-vă cursului ML online de la cele mai bune universități din lume – Master, Programe Executive Postuniversitare și Program de Certificat Avansat în ML și AI pentru a vă accelera cariera.
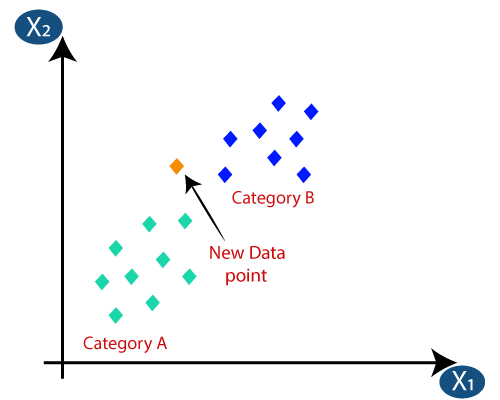
3. Clasificarea K-Nearest Neighbours (KNN).
Clasificarea KNN este unul dintre cei mai simpli algoritmi de clasificare, dar este foarte utilizat datorită eficienței sale ridicate și ușurinței de utilizat. În această metodă, întregul set de date este stocat inițial în mașină. Apoi, se alege o valoare – k, care reprezintă numărul de vecini. În acest fel, atunci când un nou punct de date este adăugat la setul de date, este nevoie de votul majoritar al etichetei k celei mai apropiate clase a vecinilor noului punct de date. Cu acest vot, noul punct de date este adăugat la acea clasă particulară cu cel mai mare vot.
Sursă
4. Kernel SVM
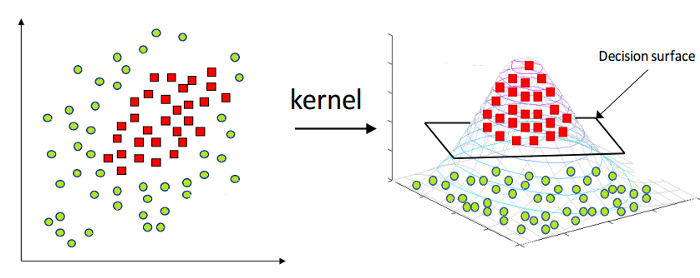
După cum s-a menționat mai sus, mașina vectorială de suport liniar poate fi aplicată numai datelor liniare în natură. Cu toate acestea, toate datele din lume nu sunt separabile liniar. Prin urmare, trebuie să dezvoltăm o mașină vectorială de suport pentru a lua în considerare datele care sunt, de asemenea, separabile neliniar. Aici vine trucul Kernel, cunoscut și sub numele de Kernel Support Vector Machine sau Kernel SVM.
În Kernel SVM, selectăm un nucleu, cum ar fi RBF sau Gaussian Kernel. Toate punctele de date sunt mapate la o dimensiune superioară, unde devin separabile liniar. În acest fel, putem crea o graniță de decizie între diferitele clase ale setului de date.
Sursă
Prin urmare, în acest fel, folosind conceptele de bază ale suportului Vector Machines, putem proiecta un Kernel SVM pentru neliniar.
5. Clasificarea naiv Bayes
Clasificarea Naive Bayes are rădăcinile sale aparținând Teoremei Bayes, presupunând că toate variabilele (caracteristicile) independente ale setului de date sunt independente. Ele au o importanță egală în prezicerea rezultatului. Această ipoteză a teoremei Bayes dă numele de „Naiv”. Este folosit pentru diverse sarcini, cum ar fi filtrarea spam-ului și alte domenii de clasificare a textului. Naive Bayes calculează posibilitatea ca un punct de date să aparțină sau nu într-o anumită categorie.
Formula clasificării naive Bayes este dată de:
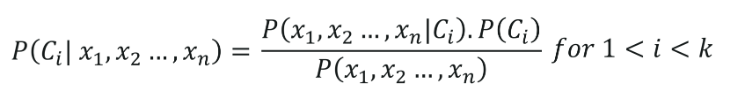
6. Clasificarea arborelui de decizie
Un arbore de decizie este un algoritm de învățare supravegheat care este perfect pentru probleme de clasificare, deoarece poate ordona clase la un nivel precis. Funcționează sub forma unei organigrame în care separă punctele de date la fiecare nivel. Structura finală arată ca un copac cu noduri și frunze.

Sursă
Un nod de decizie va avea două sau mai multe ramuri, iar o frunză reprezintă o clasificare sau o decizie. În exemplul de mai sus de Arbore de Decizie, punând mai multe întrebări, se creează o diagramă de flux, care ne ajută să rezolvăm problema simplă de a prezice dacă mergem sau nu pe piață.
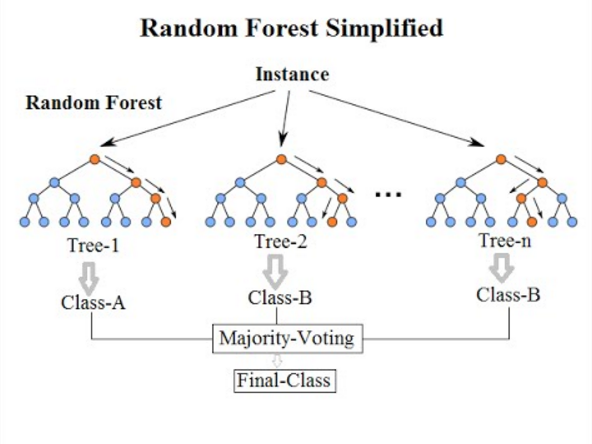
7. Clasificarea aleatorie a pădurilor
Venind la ultimul algoritm de clasificare din această listă, Pădurea aleatorie este doar o extensie a algoritmului arborelui decizional. O pădure aleatorie este o metodă de învățare prin ansamblu cu mai mulți arbori de decizie. Funcționează în același mod ca cel al Arborilor de decizie.
Sursă
Algoritmul forestier aleatoriu este o avansare a algoritmului arborelui decizional existent, care suferă de o problemă majoră de „ suprafitting ”. De asemenea, este considerat a fi mai rapid și mai precis în comparație cu algoritmul arborelui decizional.
Citește și: Idei și subiecte pentru proiecte de învățare automată
Concluzie
Astfel, în acest articol despre Metodele de învățare automată pentru clasificare, am înțeles elementele de bază ale clasificării și învățării supravegheate, tipurilor și metricilor de evaluare ale modelelor de clasificare și, în sfârșit, un rezumat al tuturor modelelor de clasificare cele mai frecvent utilizate în învățarea automată.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Programul Executive PG de la IIIT-B și upGrad în Învățare automată și IA, care este conceput pentru profesioniști care lucrează și oferă peste 450 de ore de formare riguroasă, peste 30 de studii de caz și sarcini, IIIT -B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Î1. Ce algoritmi sunt cei mai folosiți în învățarea automată?
Învățarea automată folosește mulți algoritmi diferiți, care pot fi clasificați pe scară largă în trei tipuri majore - algoritmi de învățare supravegheată, algoritmi de învățare nesupravegheată și algoritmi de învățare prin întărire. Acum, pentru a restrânge și a numi câțiva dintre algoritmii cei mai des utilizați, cei care trebuie menționați sunt regresia liniară, regresia logistică, SVM, arbori de decizie, algoritmul forestier aleatoriu, kNN, teoria Naive Bayes, K-Means, reducerea dimensionalității, și algoritmi de creștere a gradientului. Algoritmii XGBoost, GBM, LightGBM și CatBoost merită o mențiune specială în algoritmii de creștere a gradientului. Acești algoritmi pot fi aplicați pentru a rezolva aproape orice tip de problemă de date.
Q2. Ce este clasificarea și regresia în învățarea automată?
Atât algoritmii de clasificare, cât și cei de regresie sunt utilizați pe scară largă în învățarea automată. Cu toate acestea, există multe diferențe între ele, care în cele din urmă determină utilizarea sau scopul lor. Principala diferență este că, în timp ce algoritmii de clasificare sunt utilizați pentru a clasifica sau prezice valori discrete, cum ar fi bărbat-femeie sau adevărat-fals, algoritmii de regresie sunt utilizați pentru a prognoza valori continue, nediscrete, cum ar fi salariul, vârsta, prețul etc. Arbori de decizie, pădurea aleatoare, Kernel SVM și regresia logistică sunt unii dintre cei mai obișnuiți algoritmi de clasificare, în timp ce regresia liniară simplă și multiplă, regresia vectorială de suport, regresia polinomială și regresia arborelui de decizie sunt unii dintre cei mai populari algoritmi de regresie utilizați în învățarea automată.
Q3. Care sunt premisele pentru a învăța învățarea automată?
Pentru a începe cu învățarea automată, nu trebuie să fii un matematician competent sau un programator expert. Cu toate acestea, având în vedere vastitatea domeniului, poate fi intimidant atunci când sunteți pe cale să începeți călătoria dvs. de învățare automată. În astfel de cazuri, cunoașterea condițiilor prealabile vă poate ajuta cu un început fără probleme. Condițiile preliminare sunt în esență abilitățile de bază pe care trebuie să le dobândiți pentru a înțelege conceptele de învățare automată. Deci, în primul rând, asigurați-vă că învățați cum să codificați folosind Python. În continuare, o înțelegere de bază a statisticii și matematicii, în special algebra liniară și calculul multivariabil, va fi un avantaj suplimentar.