
Cum să alegeți o metodă de selectare a caracteristicilor pentru învățarea automată
Publicat: 2021-06-22Cuprins
Selectarea caracteristicilor Introducere
O mulțime de caracteristici sunt utilizate de un model de învățare automată, dintre care doar câteva dintre ele sunt importante. Există o acuratețe redusă a modelului dacă sunt utilizate caracteristici inutile pentru a antrena un model de date. În plus, există o creștere a complexității modelului și o scădere a capacității de generalizare, rezultând un model părtinitor. Zicala „uneori mai puțin este mai bine” se potrivește bine cu conceptul de învățare automată. Problema s-a confruntat de mulți utilizatori, când le este dificil să identifice setul de caracteristici relevante din datele lor și să ignore toate seturile irelevante de caracteristici. Caracteristicile mai puțin importante sunt denumite astfel încât să nu contribuie la variabila țintă.
Prin urmare, unul dintre procesele importante este selectarea caracteristicilor în învățarea automată . Scopul este de a selecta cel mai bun set posibil de caracteristici pentru dezvoltarea unui model de învățare automată. Există un impact uriaș asupra performanței modelului prin selecția caracteristicilor. Alături de curățarea datelor, selectarea caracteristicilor ar trebui să fie primul pas în proiectarea unui model.
Selectarea caracteristicilor din Machine Learning poate fi rezumată ca
- Selectarea automată sau manuală a acelor caracteristici care contribuie cel mai mult la variabila de predicție sau la rezultat.
- Prezența unor caracteristici irelevante ar putea duce la o precizie scăzută a modelului, deoarece va învăța din caracteristicile irelevante.
Beneficiile selectării caracteristicilor
- Reduce supraadaptarea datelor: un număr mai mic de date duce la o redundanță mai mică. Prin urmare, există mai puține șanse de a lua decizii cu privire la zgomot.
- Îmbunătățește acuratețea modelului: cu șanse mai mici de a induce în eroare datele, precizia modelului este crescută.
- Timpul de antrenament este redus: eliminarea caracteristicilor irelevante reduce complexitatea algoritmului deoarece sunt prezente doar mai puține puncte de date. Prin urmare, algoritmii se antrenează mai repede.
- Complexitatea modelului este redusă cu o mai bună interpretare a datelor.
Metode supravegheate și nesupravegheate de selecție a caracteristicilor
Obiectivul principal al algoritmilor de selecție a caracteristicilor este de a selecta un set de cele mai bune caracteristici pentru dezvoltarea modelului. Metodele de selecție a caracteristicilor în învățarea automată pot fi clasificate în metode supravegheate și nesupravegheate.
- Metoda supravegheată: metoda supravegheată este utilizată pentru selectarea caracteristicilor din datele etichetate și, de asemenea, utilizată pentru clasificarea caracteristicilor relevante. Prin urmare, există o eficiență crescută a modelelor care sunt construite.
- Metoda nesupravegheată : această metodă de selecție a caracteristicilor este utilizată pentru datele neetichetate.
Lista metodelor sub metode supravegheate
Metodele supravegheate de selecție a caracteristicilor în învățarea automată pot fi clasificate în

1. Metode de ambalare
Acest tip de algoritm de selecție a caracteristicilor evaluează procesul de performanță al caracteristicilor pe baza rezultatelor algoritmului. Cunoscut și ca algoritmul lacom, antrenează algoritmul folosind un subset de caracteristici în mod iterativ. Criteriile de oprire sunt de obicei definite de persoana care antrenează algoritmul. Adăugarea și eliminarea caracteristicilor din model au loc pe baza pregătirii prealabile a modelului. Orice tip de algoritm de învățare poate fi aplicat în această strategie de căutare. Modelele sunt mai precise în comparație cu metodele de filtrare.
Tehnicile utilizate în metodele Wrapper sunt:
- Selectare directă : Procesul de selecție înainte este un proces iterativ în care sunt adăugate noi caracteristici care îmbunătățesc modelul după fiecare iterație. Începe cu un set gol de caracteristici. Iterația continuă și se oprește până când este adăugată o caracteristică care nu îmbunătățește și mai mult performanța modelului.
- Selectarea/eliminarea înapoi: procesul este un proces iterativ care începe cu toate caracteristicile. După fiecare iterație, caracteristicile cu cea mai mică semnificație sunt eliminate din setul de caracteristici inițiale. Criteriul de oprire pentru iterație este atunci când performanța modelului nu se îmbunătățește în continuare odată cu eliminarea caracteristicii. Acești algoritmi sunt implementați în pachetul mlxtend.
- Eliminare bidirecțională : Ambele metode de selecție înainte și tehnica de eliminare inversă sunt aplicate simultan în metoda de eliminare bidirecțională pentru a ajunge la o soluție unică.
- Selecția exhaustivă a caracteristicilor: este, de asemenea, cunoscută sub numele de abordarea forței brute pentru evaluarea subseturilor de caracteristici. Se creează un set de subseturi posibile și se construiește un algoritm de învățare pentru fiecare subset. Se alege acel subset al cărui model oferă cele mai bune performanțe.
- Eliminarea caracteristicilor recursive (RFE): Metoda este numită a fi lacomă deoarece selectează caracteristici luând în considerare recursiv setul din ce în ce mai mic de caracteristici. Un set inițial de caracteristici este folosit pentru antrenamentul estimatorului și importanța lor este obținută folosind feature_importance_attribute. Apoi este urmată de eliminarea celor mai puțin importante caracteristici, lăsând în urmă doar numărul necesar de caracteristici. Algoritmii sunt implementați în pachetul scikit-learn.
Figura 4: Un exemplu de cod care arată tehnica de eliminare recursivă a caracteristicilor
2. Metode încorporate
Metodele de selectare a caracteristicilor încorporate în învățarea automată au un anumit avantaj față de metodele de filtrare și de înveliș prin includerea interacțiunii cu caracteristicile și, de asemenea, menținând un cost de calcul rezonabil. Tehnicile utilizate în metodele încorporate sunt:
- Regularizare: Supraadaptarea datelor este evitată de către model prin adăugarea unei penalizări la parametrii modelului. Se adaugă coeficienți cu penalizarea rezultând ca unii coeficienți să fie zero. Prin urmare, acele caracteristici care au un coeficient zero sunt eliminate din setul de caracteristici. Abordarea selecției caracteristicilor folosește rețele Lasso (regularizare L1) și rețele elastice (regularizare L1 și L2).
- SMLR (Sparse Multinomial Logistic Regression): Algoritmul implementează o regularizare rară prin ARD prior (Automatic relevance determination) pentru regresia logistică multinațională clasică. Această regularizare estimează importanța fiecărei caracteristici și reduce dimensiunile care nu sunt utile pentru predicție. Implementarea algoritmului se face în SMLR.
- ARD (Automatic Relevance Determination Regression): algoritmul va muta ponderile coeficientului spre zero și se bazează pe o regresie Bayesian Ridge. Algoritmul poate fi implementat în scikit-learn.
- Importanța pădurii aleatoare: Acest algoritm de selecție a caracteristicilor este o agregare a unui număr specificat de arbori. Strategiile bazate pe arbore din acest algoritm se clasifică pe baza creșterii impurității unui nod sau a scăderii impurității (impuritate Gini). Sfârșitul arborilor este format din nodurile cu cea mai mică scădere a impurității, iar începutul arborilor este format din nodurile cu cea mai mare scădere a impurității. Prin urmare, caracteristicile importante pot fi selectate prin tăierea arborelui de sub un anumit nod.
3. Metode de filtrare
Metodele sunt aplicate în timpul etapelor de preprocesare. Metodele sunt destul de rapide și ieftine și funcționează cel mai bine în eliminarea caracteristicilor duplicate, corelate și redundante. În loc să se aplice orice metode de învățare supravegheată, importanța caracteristicilor este evaluată pe baza caracteristicilor lor inerente. Costul de calcul al algoritmului este mai mic în comparație cu metodele wrapper de selecție a caracteristicilor. Cu toate acestea, dacă nu sunt prezente suficiente date pentru a deriva corelația statistică dintre caracteristici, rezultatele ar putea fi mai proaste decât metodele de înveliș. Prin urmare, algoritmii sunt utilizați peste date cu dimensiuni mari, ceea ce ar duce la un cost de calcul mai mare dacă s-ar aplica metodele wrapper.

Tehnicile utilizate în metodele de filtrare sunt :
- Câștig de informații : câștigul de informații se referă la cât de multă informație este obținută din caracteristici pentru a identifica valoarea țintă. Apoi măsoară reducerea valorilor entropiei. Câștigul de informații al fiecărui atribut este calculat luând în considerare valorile țintă pentru selecția caracteristicilor.
- Testul Chi-pătrat : Metoda Chi-pătrat (X 2 ) este în general utilizată pentru a testa relația dintre două variabile categorice. Testul este utilizat pentru a identifica dacă există o diferență semnificativă între valorile observate de la diferite atribute ale setului de date și valoarea sa așteptată. O ipoteză nulă afirmă că nu există asociere între două variabile.
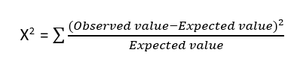
Sursă
Formula pentru testul Chi-pătrat
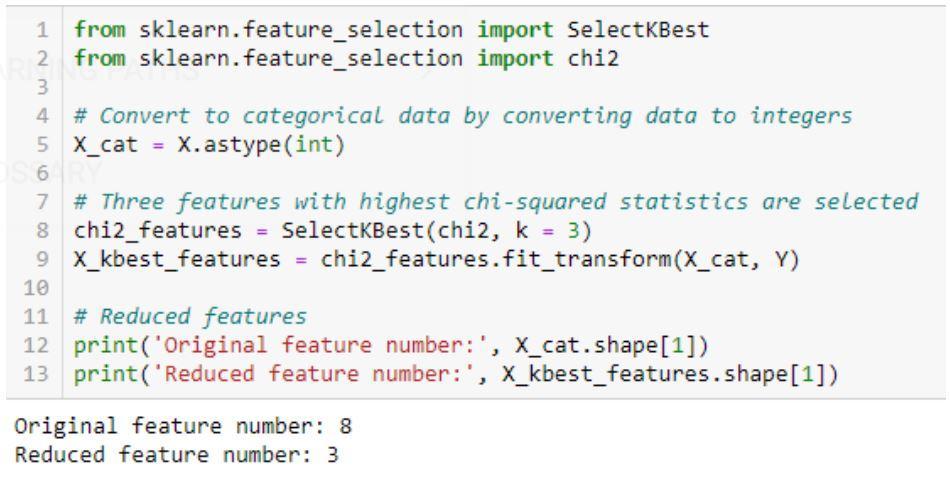
Implementarea algoritmului Chi-Squared: sklearn, scipy
Un exemplu de cod pentru testul Chi-pătrat
Sursă
- CFS (Selectare caracteristică bazată pe corelație): metoda urmează „ Implementarea CFS (selecție caracteristică bazată pe corelație): scikit-feature
Alăturați-vă cursurilor de AI și ML online de la cele mai bune universități din lume – Master, Programe Executive Postuniversitare și Programul de Certificat Avansat în ML și AI pentru a vă accelera cariera.
- FCBF (Fast corelation-based filter): Comparativ cu metodele de Relief și CFS menționate mai sus, metoda FCBF este mai rapidă și mai eficientă. Inițial, calculul incertitudinii simetrice este efectuat pentru toate caracteristicile. Folosind aceste criterii, caracteristicile sunt apoi sortate și caracteristicile redundante sunt eliminate.
Incertitudine simetrică= câștigul de informații al lui x | y împărțit la suma entropiilor lor. Implementarea FCBF: skfeature
- Scorul Fischer: Rația Fischer (FIR) este definită ca distanța dintre mediile eșantionului pentru fiecare clasă pe caracteristică împărțită la variațiile acestora. Fiecare caracteristică este selectată în mod independent în funcție de scorurile lor în conformitate cu criteriul Fisher. Acest lucru duce la un set suboptim de caracteristici. Un scor Fisher mai mare denotă o caracteristică mai bine selectată.
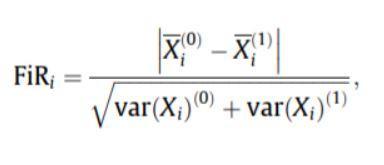
Sursă
Formula pentru scorul Fischer
Implementarea scorului Fisher: scikit-feature
Ieșirea codului care arată tehnica scorului Fisher
Sursă
Coeficientul de corelație al lui Pearson: este o măsură de cuantificare a asocierii dintre cele două variabile continue. Valorile coeficientului de corelație variază de la -1 la 1 care definește direcția relației dintre variabile.
- Pragul de variație: caracteristicile a căror variație nu îndeplinește pragul specific sunt eliminate. Caracteristicile care au varianță zero sunt eliminate prin această metodă. Ipoteza luată în considerare este că caracteristicile cu varianță mai mare sunt probabil să conțină mai multe informații.
Figura 15: Un exemplu de cod care arată implementarea pragului Variance
- Diferența medie absolută (MAD): Metoda calculează media absolută
diferență față de valoarea medie.
Un exemplu de cod și rezultatul acestuia care arată implementarea Diferenței medii absolute (MAD)
Sursă
- Raportul de dispersie: Raportul de dispersie este definit ca raportul dintre media aritmetică (AM) și cea dintre media geometrică (GM) pentru o anumită caracteristică. Valoarea sa variază de la +1 la ∞ ca AM ≥ GM pentru o anumită caracteristică.
Un raport de dispersie mai mare implică o valoare mai mare a lui Ri și, prin urmare, o caracteristică mai relevantă. În schimb, când Ri este aproape de 1, indică o caracteristică de relevanță scăzută.
- Dependența reciprocă: Metoda este utilizată pentru a măsura dependența reciprocă dintre două variabile. Informațiile obținute de la o variabilă pot fi utilizate pentru a obține informații pentru cealaltă variabilă.
- Scorul Laplacian: Datele din aceeași clasă sunt adesea apropiate unele de altele. Importanța unei caracteristici poate fi evaluată prin puterea sa de conservare a localității. Scorul Laplacian pentru fiecare caracteristică este calculat. Cele mai mici valori determină dimensiuni importante. Implementarea scorului Laplacian: scikit-feature.
Concluzie
Selectarea caracteristicilor în procesul de învățare automată poate fi rezumată ca fiind unul dintre pașii importanți către dezvoltarea oricărui model de învățare automată. Procesul algoritmului de selecție a caracteristicilor duce la reducerea dimensionalității datelor cu eliminarea caracteristicilor care nu sunt relevante sau importante pentru modelul luat în considerare. Caracteristicile relevante ar putea accelera timpul de antrenament al modelelor, rezultând performanțe ridicate.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Programul Executive PG de la IIIT-B și upGrad în Învățare automată și IA, care este conceput pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, IIIT -B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
Prin ce este diferită metoda de filtrare de metoda învelișului?
Metoda wrapper ajută la măsurarea cât de utile sunt caracteristicile bazate pe performanța clasificatorului. Metoda de filtrare, pe de altă parte, evaluează calitățile intrinseci ale caracteristicilor folosind statistici univariate mai degrabă decât performanța de validare încrucișată, ceea ce implică faptul că ei judecă relevanța caracteristicilor. Ca rezultat, metoda wrapper este mai eficientă, deoarece optimizează performanța clasificatorului. Cu toate acestea, din cauza proceselor de învățare repetate și a validării încrucișate, tehnica wrapperului este mai costisitoare din punct de vedere computațional decât metoda filtrului.
Ce este selecția directă secvențială în Machine Learning?
Este un fel de selecție secvențială a caracteristicilor, deși este mult mai costisitoare decât selecția filtrului. Este o tehnică de căutare lacomă care selectează în mod iterativ caracteristicile pe baza performanței clasificatorului pentru a descoperi subsetul ideal de caracteristici. Începe cu un subset de caracteristici gol și continuă să adauge o caracteristică în fiecare rundă. Această caracteristică este aleasă dintr-un grup de caracteristici care nu se află în subsetul nostru de caracteristici și este cea care are ca rezultat cea mai bună performanță a clasificatorului atunci când este combinată cu celelalte.
Care sunt limitările utilizării metodei de filtrare pentru selectarea caracteristicilor?
Abordarea filtrului este mai puțin costisitoare din punct de vedere computațional decât metodele de selectare a învelișului și a caracteristicilor încorporate, dar are unele dezavantaje. În cazul abordărilor univariate, această strategie ignoră frecvent interdependența caracteristicilor în timp ce selectează caracteristicile și evaluează fiecare caracteristică în mod independent. În comparație cu celelalte două metode de selectare a caracteristicilor, aceasta poate duce uneori la performanțe de calcul slabe.