
Cum mă ajută site-ul meu bazat pe API să călătoresc prin lume
Publicat: 2022-03-10(Acesta este o postare sponsorizată.) Recent, am decis să-mi reconstruiesc site-ul personal, pentru că avea șase ani și părea – vorbind politicos – puțin „învechit”. Scopul a fost să includ câteva informații despre mine, o zonă de blog, o listă cu proiectele mele recente și evenimentele viitoare.
Pe măsură ce lucrez cu clienții din când în când, a existat un lucru cu care nu am vrut să mă ocup - bazele de date ! Anterior, am creat site-uri WordPress pentru toți cei care doreau să o fac. Partea de programare a fost de obicei distractivă pentru mine, dar lansările, mutarea bazelor de date în medii diferite și publicarea efectivă au fost întotdeauna enervante. Furnizorii de găzduire ieftini oferă doar interfețe web slabe pentru a configura baze de date MySQL, iar un acces FTP pentru a încărca fișiere a fost întotdeauna partea cea mai rea. Nu am vrut să mă ocup de asta pentru site-ul meu personal.
Deci cerințele pe care le aveam pentru reproiectare au fost:
- O stivă de tehnologie actualizată bazată pe tehnologii JavaScript și front-end.
- O soluție de gestionare a conținutului pentru editarea conținutului de oriunde.
- Un site performant cu rezultate rapide.
În acest articol vreau să vă arăt ce am construit și cum site-ul meu s-a dovedit în mod surprinzător a fi însoțitorul meu de zi cu zi.
Definirea unui model de conținut
Publicarea lucrurilor pe web pare a fi ușoară. Alegeți un sistem de gestionare a conținutului (CMS) care oferă un editor WYSIWYG ( What You See I s What You G et) pentru fiecare pagină de care aveți nevoie și toți editorii pot gestiona conținutul cu ușurință. Asta e, nu?
După ce am construit mai multe site-uri web pentru clienți, de la cafenele mici la startup-uri în creștere, mi-am dat seama că editorul sfânt WYSIWYG nu este întotdeauna ghințul de argint pe care îl căutăm cu toții. Aceste interfețe urmăresc să faciliteze construirea de site-uri web, dar aici vine ideea:
Construirea de site-uri web nu este ușoară
Pentru a construi și edita conținutul unui site web fără a-l sparge constant, trebuie să aveți cunoștințe intime de HTML și cel puțin să înțelegeți un pic de CSS. Nu este ceva la care te poți aștepta de la editorii tăi.
Am văzut layout-uri complexe oribile construite cu editori WYSIWYG și nu pot începe să numesc toate situațiile în care totul se destramă, deoarece sistemul este prea fragil. Aceste situații duc la lupte și disconfort în care toate părțile se învinovățesc reciproc pentru ceva ce era inevitabil. Am încercat întotdeauna să evit aceste situații și să creez medii confortabile și stabile pentru editori, pentru a evita e-mailurile furioase care strigă: „Ajutor! Totul este stricat.”
Conținutul structurat vă scutește de unele probleme
Am învățat destul de repede că oamenii rar rup lucrurile atunci când împart tot conținutul necesar site-ului în mai multe bucăți, fiecare legată între ele fără să mă gândesc la vreo reprezentare. În WordPress, acest lucru poate fi realizat folosind tipuri de postări personalizate. Fiecare tip de postare personalizată poate include mai multe proprietăți cu propriul câmp de text ușor de înțeles. Am îngropat complet conceptul de gândire în pagini .
Treaba mea a fost să conectez piesele de conținut și să construiesc pagini web din aceste blocuri de conținut. Acest lucru a însemnat că editorii au putut face doar puține modificări vizuale, dacă nu există, pe site-urile lor web. Ei erau responsabili pentru conținut și numai pentru conținut. Schimbările vizuale trebuiau făcute de mine — nu toată lumea putea stila site-ul și am putea evita un mediu fragil. Acest concept s-a simțit ca un mare compromis și a fost de obicei bine primit.
Mai târziu, am descoperit că ceea ce făceam era să definesc un model de conținut. Rachel Lovinger definește, în excelentul său articol „Content Modelling: A Master Skill”, un model de conținut după cum urmează:
„Un model de conținut documentează toate tipurile diferite de conținut pe care le veți avea pentru un anumit proiect. Conține definiții detaliate ale elementelor fiecărui tip de conținut și ale relațiilor dintre ele.”
Începând cu modelarea conținutului a funcționat bine pentru majoritatea clienților, cu excepția unuia.
„Ștefan, nu vă definesc schema bazei de date!”
Ideea acestui singur proiect a fost de a construi un site web masiv care ar trebui să creeze mult trafic organic prin furnizarea de tone de conținut - în toate variantele afișate în mai multe pagini și locuri diferite. Am organizat o întâlnire pentru a discuta despre strategia noastră de abordare a acestui proiect.
Am vrut să definesc toate paginile și modelele de conținut care ar trebui incluse. Nu a contat ce widget minuscul sau ce bară laterală avea în minte clientul, am vrut să fie clar definit. Scopul meu a fost să creez o structură solidă de conținut care să facă posibilă furnizarea unei interfețe ușor de utilizat pentru editori și să ofere date reutilizabile pentru a le afișa în orice format posibil.
S-a dovedit că ideea acestui proiect nu era foarte clară și nu am putut obține răspunsuri la toate întrebările mele. Liderul de proiect nu a înțeles că ar trebui să începem cu modelarea adecvată a conținutului (nu cu design și dezvoltare). Pentru el, acestea au fost doar o tonă de pagini. Conținutul duplicat și zonele de text uriașe pentru a adăuga o cantitate masivă de text, nu părea să fie o problemă. În mintea lui, întrebările pe care le aveam despre structură erau tehnice și nu ar trebui să-și facă griji pentru ele. Ca să scurtez o poveste, nu eu am făcut proiectul.
Important este că modelarea conținutului nu se referă la baze de date.
Este vorba despre a vă face conținutul accesibil și pregătit pentru viitor. Dacă nu puteți defini nevoile pentru conținutul dvs. la lansarea proiectului, va fi foarte greu, dacă nu imposibil, să îl reutilizați mai târziu.
Modelarea corectă a conținutului este cheia site-urilor web prezente și viitoare.
Contentful: Un CMS fără cap
Era clar că am vrut să urmăresc un model de conținut bun și pentru site-ul meu. Cu toate acestea, mai era un lucru. Nu am vrut să mă ocup de stratul de stocare pentru a construi noul meu site web, așa că am decis să folosesc Contentful, un CMS fără cap, la care lucrez (declinare completă a răspunderii!) în prezent. „Headless” înseamnă că acest serviciu oferă o interfață web pentru a gestiona conținutul din cloud și oferă un API care îmi va returna datele în format JSON. Alegerea acestui CMS m-a ajutat să fiu productiv imediat, deoarece aveam un API disponibil în câteva minute și nu trebuia să mă ocup de nicio configurație de infrastructură. Contentful oferă, de asemenea, un plan gratuit, care este perfect pentru proiecte mici, cum ar fi site-ul meu personal.
Un exemplu de interogare pentru a obține toate postările de blog arată astfel:
<a href="https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post">https://cdn.contentful.com/spaces/space_id/entries?access_token=access_token&content_type=post</a>Și răspunsul, într-o versiune prescurtată, arată astfel:
{ "sys": { "type": "Array" }, "total": 7, "skip": 0, "limit": 100, "items": [ { "sys": { "space": {...}, "id": "455OEfg1KUskygWUiKwmkc", "type": "Entry", "createdAt": "2016-07-29T11:53:52.596Z", "updatedAt": "2016-11-09T21:07:19.118Z", "revision": 12, "contentType": {...}, "locale": "en-US" }, "fields": { "title": "How to React to Changing Environments Using matchMedia", "excerpt": "...", "slug": "how-to-react-to-changing-environments-using-match-media", "author": [...], "body": "...", "date": "2014-12-26T00:00+02:00", "comments": true, "externalUrl": "https://4waisenkinder.de/blog/2014/12/26/handle-environment-changes-via-window-dot-matchmedia/" }, {...}, {...}, {...}, {...}, {...}, {...} ] } }Partea grozavă despre Contentful este că este grozav la modelarea conținutului, ceea ce aveam nevoie. Folosind interfața web furnizată, pot defini rapid toate elementele de conținut necesare. Definiția unui anumit model de conținut în Contentful se numește tip de conținut. Un lucru grozav de subliniat aici este capacitatea de a modela relațiile dintre elementele de conținut. De exemplu, pot conecta cu ușurință un autor cu o postare pe blog. Acest lucru poate duce la arbori de date structurate, care sunt perfecte pentru a fi reutilizate pentru diferite cazuri de utilizare.
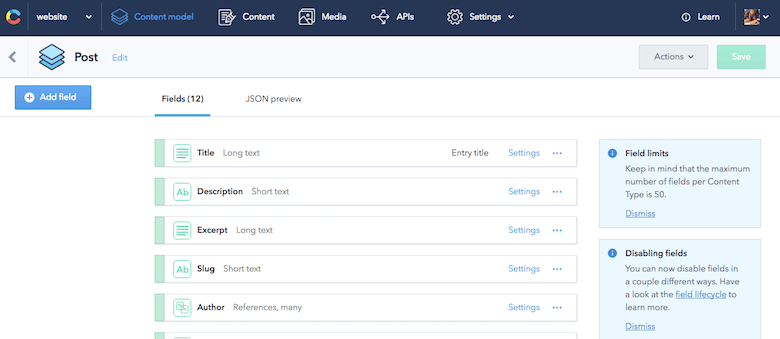
Așadar, mi-am configurat modelul de conținut fără să mă gândesc la paginile pe care aș dori să le construiesc în viitor.
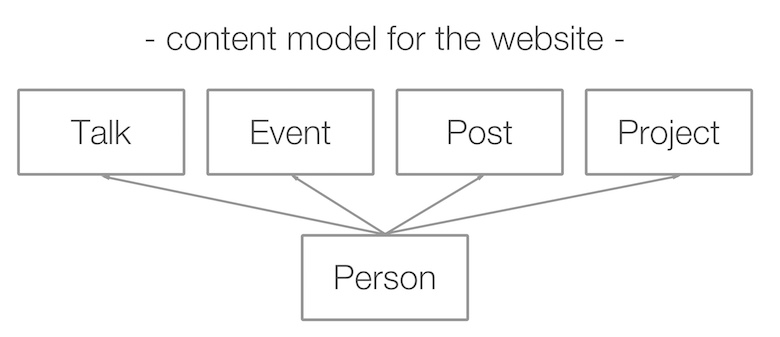
Următorul pas a fost să-mi dau seama ce vreau să fac cu aceste date. L-am întrebat pe un designer pe care îl cunoșteam și el a venit cu o pagină de index a site-ului cu următoarea structură.
Redarea paginilor HTML folosind Node.js
Acum a venit partea dificilă. Până acum, nu am avut de-a face cu stocarea și bazele de date, ceea ce a fost o mare realizare pentru mine. Deci, cum îmi pot crea site-ul web când am disponibil doar un API?
Prima mea abordare a fost abordarea do-it-yourself. Am început să scriu un script Node.js simplu, care ar prelua datele și ar reda ceva HTML din ele.
Redarea tuturor fișierelor HTML în avans a îndeplinit una dintre cerințele mele principale. HTML static poate fi servit foarte rapid.
Deci, să aruncăm o privire la scriptul pe care l-am folosit.
'use strict'; const contentful = require('contentful'); const template = require('lodash.template'); const fs = require('fs'); // create contentful client with particular credentials const client = contentful.createClient({ space: 'your_space_id', accessToken: 'your_token' }); // cache templates to not read // them over and over again const TEMPLATES = { index : template(fs.readFileSync(`${__dirname}/templates/index.html`)) }; // fetch all the data Promise.all([ // get posts client.getEntries({content_type: 'content_type_post_id'}), // get events client.getEntries({content_type: 'content_type_event_id'}), // get projects client.getEntries({content_type: 'content_type_project_id'}), // get talk client.getEntries({content_type: 'content_type_talk_id'}), // get specific person client.getEntries({'sys.id': 'person_id'}) ]) .then(([posts, events, projects, talks, persons]) => { const renderedHTML = TEMPLATES.index({ posts, events, projects, talks, person : persons.items[0] }) fs.writeFileSync(`${__dirname}/build/index.html`, renderedHTML); console.log('Rendered HTML'); }) .catch(console.error); <!doctype html> <html lang="en"> <head> <!-- ... --> </head> <body> <!-- ... --> <h2>Posts</h2> <ul> <% posts.items.forEach( function( talk ) { %> <li><%- talk.fields.title %> <% }) %> </ul> <!-- ... --> </body> </html>Aceasta a funcționat bine. Mi-aș putea construi site-ul web dorit într-un mod complet flexibil, luând toate deciziile cu privire la structura și funcționalitatea fișierului. Redarea diferitelor tipuri de pagini cu seturi de date complet diferite nu a fost deloc o problemă. Toți cei care au luptat împotriva regulilor și structurii unui CMS existent care este livrat cu redare HTML știe că libertatea completă poate fi un lucru excelent. În special, atunci când modelul de date devine mai complex în timp, incluzând multe relații, flexibilitatea dă roade.
În acest script Node.js, este creat un client Contentful SDK și toate datele sunt preluate folosind metoda client getEntries . Toate metodele oferite de client sunt bazate pe promisiuni, ceea ce facilitează evitarea apelurilor profund imbricate. Pentru șabloane, am decis să folosesc motorul de șabloane al lui lodash. În cele din urmă, pentru citirea și scrierea fișierelor, Node.js oferă modulul nativ fs , care apoi este folosit pentru a citi șabloanele și a scrie HTML-ul randat.
Cu toate acestea, a existat un dezavantaj la această abordare; era foarte dezgolit. Chiar și atunci când această metodă a fost complet flexibilă, a fost ca și cum ai reinventa roata. Ceea ce construiam era practic un generator de site static și există deja o mulțime de ele. Era timpul să o luăm de la capăt.
Alegerea unui generator de site static real
Generatorii celebri de site-uri statice, de exemplu, Jekyll sau Middleman, se ocupă de obicei cu fișierele Markdown care vor fi redate în HTML. Editorii lucrează cu acestea, iar site-ul web este construit folosind o comandă CLI. Această abordare a eșuat însă una dintre cerințele mele inițiale. Am vrut să pot edita site-ul oriunde aș fi, fără să mă bazez pe fișierele aflate pe computerul meu privat.

Prima mea idee a fost să redau aceste fișiere Markdown folosind API-ul. Deși acest lucru ar fi funcționat, nu s-a părut corect. Redarea fișierelor Markdown pentru a le transforma în HTML mai târziu au fost încă doi pași care nu oferă un avantaj mare în comparație cu soluția mea inițială.
Din fericire, există integrări Contentful, de exemplu, Metalsmith și Middleman. M-am decis pe Metalsmith pentru acest proiect, deoarece este scris în Node.js și nu am vrut să aduc o dependență Ruby.
Metalsmith transformă fișierele dintr-un folder sursă și le redă într-un folder destinație. Aceste fișiere nu trebuie neapărat să fie fișiere Markdown. Îl poți folosi și pentru transpilarea Sass sau pentru optimizarea imaginilor. Nu există limite și este cu adevărat flexibil.
Folosind integrarea Contentful, am reușit să definesc unele fișiere sursă care au fost luate ca fișiere de configurare și apoi am putut prelua tot ce era necesar din API.
--- title: Blog contentful: content_type: content_type_id entry_filename_pattern: ${ fields.slug } entry_template: article.html order: '-fields.date' filter: include: 5 layout: blog.html description: >- Recent articles by Stefan Judis. --- Acest exemplu de configurare redă zona de postare a blogului cu un fișier părinte blog.html , inclusiv răspunsul la cererea API, dar redă și mai multe pagini copil folosind șablonul article.html . Numele fișierelor pentru paginile copil sunt definite prin entry_filename_pattern .
După cum vedeți, cu așa ceva, îmi pot construi paginile cu ușurință. Această configurare a funcționat perfect pentru a se asigura că toate paginile depind de API.
Conectați serviciul cu proiectul dvs
Singura parte care lipsea era conectarea site-ului cu serviciul CMS și redarea acestuia atunci când se edita orice conținut. Soluția pentru această problemă - webhook-uri, cu care este posibil să fiți deja familiarizat dacă utilizați servicii precum GitHub.
Webhook-urile sunt solicitări făcute de software ca serviciu către un punct final definit anterior, care vă anunță că s-a întâmplat ceva. GitHub, de exemplu, vă poate trimite un ping înapoi când cineva a deschis o cerere de extragere într-unul dintre depozitele dvs. În ceea ce privește managementul conținutului, același principiu îl putem aplica și aici. Ori de câte ori se întâmplă ceva cu conținutul, trimiteți ping la un punct final și faceți un anumit mediu să reacționeze la acesta. În cazul nostru, acest lucru ar însemna să redați din nou HTML-ul folosind metalsmith.
Pentru a accepta webhook-uri, am folosit și o soluție JavaScript. Furnizorul de găzduire ales de mine (Uberspace) face posibilă instalarea Node.js și utilizarea JavaScript pe partea serverului.
const http = require('http'); const exec = require('child_process').exec; const server = http.createServer((req, res) => { res.setHeader('Content-Type', 'text/plain'); // check for secret header // to not open up this endpoint for everybody if (req.headers.secret === 'YOUR_SECRET') { res.end('ok'); // wait for the CDN to // invalidate the data setTimeout(() => { // execute command exec('npm start', { cwd: __dirname }, (error) => { if (error) { return console.log(error); } console.log('Rebuilt success'); }); }, 1000 * 120 ); } else { res.end('Not allowed'); } }); console.log('Started server at 8000'); server.listen(8000); Acest script pornește un server HTTP simplu pe portul 8000. Verifică cererile primite pentru un antet adecvat pentru a se asigura că este webhook-ul de la Contentful. Dacă cererea este confirmată ca webhook, comanda predefinită npm start este executată pentru a reda toate paginile HTML. S-ar putea să vă întrebați de ce există un timeout. Acest lucru este necesar pentru a întrerupe acțiunile pentru un moment până când datele din cloud sunt invalidate, deoarece datele stocate sunt servite de la un CDN.
În funcție de mediul dvs., este posibil ca acest server HTTP să nu fie accesibil pe internet. Site-ul meu este servit folosind un server Apache, așa că a trebuit să adaug o regulă de rescriere internă pentru a face serverul nod care rulează accesibil pe internet.
# add node endpoint to enable webhooks RewriteRule ^rerender/(.*) https://localhost:8000/$1 [P]Datele API-First și structurate: cei mai buni prieteni pentru totdeauna
În acest moment, am putut să-mi gestionez toate datele în cloud, iar site-ul meu ar reacționa în consecință după modificări.
Repetiție peste tot
A fi pe drumuri este o parte importantă a vieții mele, așa că a fost necesar să am informații, cum ar fi locația unui anumit loc sau hotelul pe care l-am rezervat, chiar la îndemâna mea - de obicei stocate într-o foaie de calcul Google. Acum, informațiile au fost răspândite pe o foaie de calcul, mai multe e-mailuri, calendarul meu, precum și pe site-ul meu.
A trebuit să recunosc, am creat o mulțime de duplicare a datelor în fluxul meu zilnic.
Momentul datelor structurate
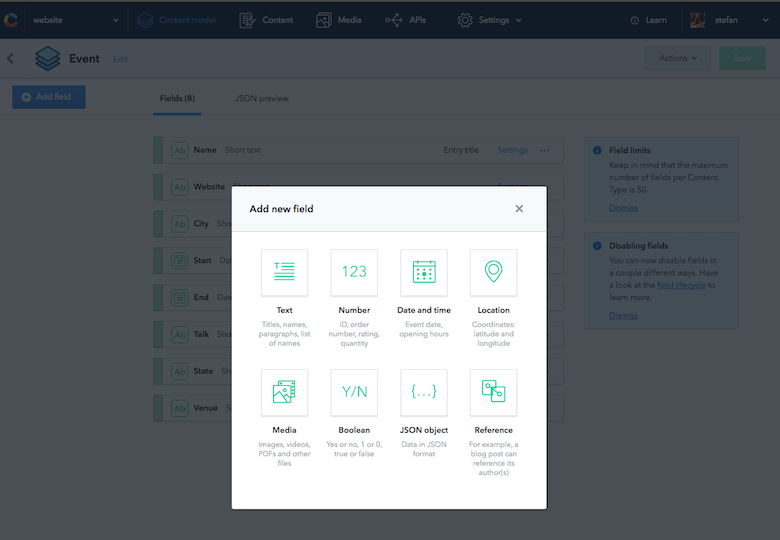
Am visat la o singură sursă de adevăr, (de preferință pe telefonul meu) pentru a vedea rapid ce evenimente urmează, dar și pentru a obține informații suplimentare despre hoteluri și locații. Evenimentele enumerate pe site-ul meu nu aveau toate informațiile în acest moment, dar este foarte ușor să adăugați câmpuri noi la un tip de conținut în Contentful. Deci, am adăugat câmpurile necesare la tipul de conținut „Eveniment”.
Introducerea acestor informații în CMS-ul site-ului meu nu a fost niciodată intenția mea, deoarece nu ar trebui să fie afișate online, dar accesul lor prin intermediul unui API m-a făcut să realizez că acum aș putea face lucruri complet diferite cu aceste date.
Construirea unei aplicații native cu JavaScript
Crearea de aplicații pentru mobil este un subiect de ani de zile și există mai multe abordări în acest sens. Aplicațiile web progresive (PWA) sunt un subiect deosebit de fierbinte în aceste zile. Folosind Service Workers și un Web App Manifest, este posibil să construiți experiențe complete asemănătoare unei aplicații, de la o pictogramă pe ecranul de pornire la un comportament offline gestionat folosind tehnologii web.
Există un dezavantaj de menționat. Aplicațiile web progresive sunt în creștere, dar nu sunt încă complet acolo. Lucrătorii de servicii, de exemplu, nu sunt acceptați astăzi pe Safari și sunt doar „în considerare” din partea Apple până acum. Acesta a fost un deal-breaker pentru mine, deoarece am vrut să am o aplicație compatibilă offline și pe iPhone.
Așa că am căutat alternative. Un prieten de-al meu era foarte interesat de NativeScript și îmi tot povestea despre această tehnologie destul de nouă. NativeScript este un cadru open source pentru construirea de aplicații mobile cu adevărat native cu JavaScript, așa că am decis să-l încerc.
Cunoașterea NativeScript
Configurarea NativeScript durează ceva timp, deoarece trebuie să instalați o mulțime de lucruri de dezvoltat pentru mediile mobile native. Veți fi ghidat prin procesul de instalare atunci când instalați instrumentul de linie de comandă NativeScript pentru prima dată folosind npm install nativescript -g .
Apoi, puteți utiliza comenzile de schelă pentru a configura proiecte noi: tns create MyNewApp
Cu toate acestea, nu asta am făcut. Scanam documentația și am dat peste un exemplu de aplicație de gestionare a alimentelor construită în NativeScript. Așa că am luat această aplicație, am săpat în cod și am modificat-o pas cu pas, adaptându-l nevoilor mele.
Nu vreau să mă scufund prea adânc în proces, dar nu a durat mult să construiesc o listă de căutare bună cu toate informațiile pe care mi le-am dorit.
NativeScript se joacă foarte bine împreună cu Angular 2, pe care nu am vrut să-l încerc de data aceasta, deoarece descoperirea lui NativeScript mi s-a părut destul de mare. În NativeScript trebuie să scrieți „Vizualizări”. Fiecare vizualizare constă dintr-un fișier XML care definește aspectul de bază și JavaScript și CSS opțional. Toate acestea sunt definite într-un singur folder per vizualizare.
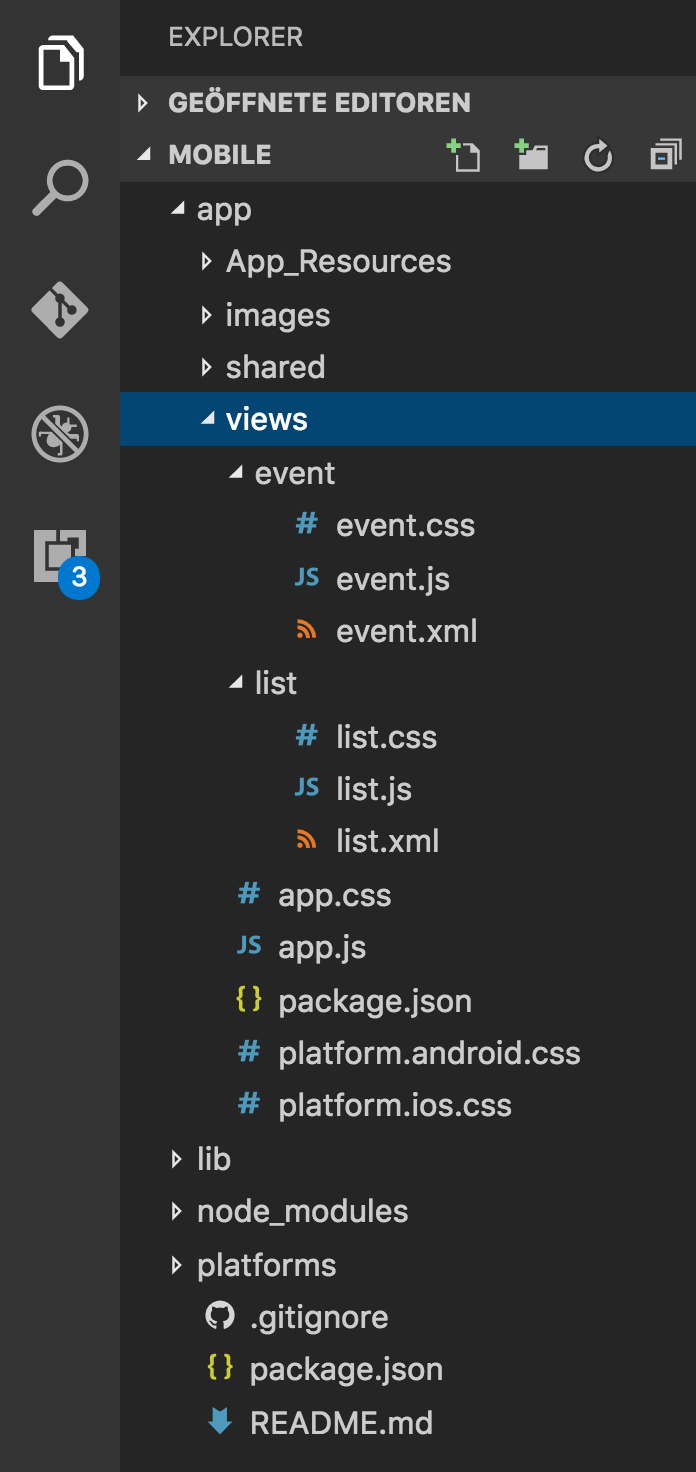
Redarea unei liste simple poate fi realizată cu un șablon XML ca acesta:
<!-- call JavaScript function when ready --> <Page loaded="loaded"> <ActionBar title="All Travels" /> <!-- make it scrollable when going too big --> <ScrollView> <!-- iterate over the entries in context --> <ListView items="{{ entries }}"> <ListView.itemTemplate> <Label text="{{ fields.name }}" textWrap="true" class="headline"/> </ListView.itemTemplate> </ListView> </ScrollView> </Page> Primul lucru care se întâmplă aici este definirea unui element de pagină. În interiorul acestei pagini, am definit un ActionBar pentru a-i oferi aspectul clasic Android, precum și un titlu adecvat. Construirea de lucruri pentru medii native poate fi puțin dificilă uneori. De exemplu, pentru a obține un comportament de defilare funcțional, trebuie să utilizați un „ScrollView”. Ultimul lucru este să repet pur și simplu peste evenimentele mele folosind un ListView . În general, s-a părut destul de simplu!
Dar de unde provin aceste intrări care sunt folosite în vizualizare? Se pare că există un obiect de context partajat care poate fi folosit pentru asta. Când citiți XML pentru vizualizare, este posibil să fi observat deja că pagina are un set de atribute loaded . Prin setarea acestui atribut, îi spun vizualizării să apeleze o anumită funcție JavaScript atunci când pagina este încărcată.
Această funcție JavaScript este definită în fișierul JS în funcție. Poate fi accesibil prin simpla exportare folosind exports.something . Pentru a adăuga legarea de date, tot ce trebuie să facem este să setăm un nou Observable la proprietatea paginii bindingContext . Observabilele din NativeScript emit evenimente propertyChange care sunt necesare pentru a reacționa la modificările de date din interiorul „vizualizărilor”, dar nu trebuie să vă faceți griji pentru asta, deoarece funcționează din nou.
const context = new Observable({ entries: null}); const fetchModule = require('fetch'); // export loaded to be called from // List.xml when everything is loaded exports.loaded = (args) => { const page = args.object; page.bindingContext = context; fetchModule.fetch( `https://cdn.contentful.com/spaces/${config.space}/entries?access_token=${config.cda.token}&content_type=event&order=fields.start`, { method: "GET", headers: { 'Content-Type': 'application/json' } } ) .then(response => response.json()) .then(response => context.set('entries', response.items)); } Ultimul lucru este să preluați datele și să le setați în context. Acest lucru se poate face folosind modulul de fetch NativeScript. Aici, puteți vedea rezultatul.
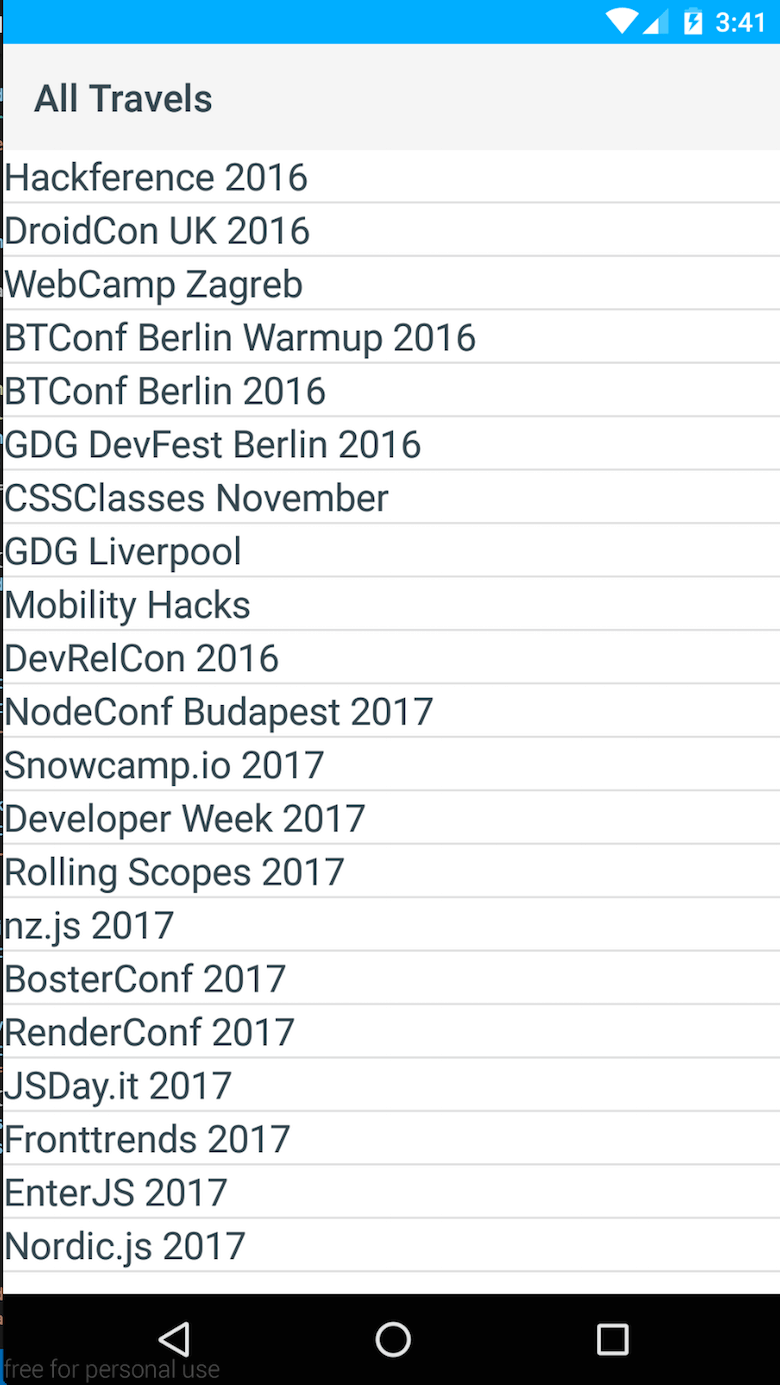
Deci, după cum puteți vedea, construirea unei liste simple folosind NativeScript nu este chiar dificilă. Mai târziu, am extins aplicația cu o altă vizualizare, precum și cu funcționalități suplimentare pentru a deschide adresele date în Google Maps și vizualizările web pentru a vedea site-urile web ale evenimentelor.
Un lucru de subliniat aici este că NativeScript este încă destul de nou, ceea ce înseamnă că pluginurile găsite pe npm de obicei nu au multe descărcări sau stele pe GitHub. Acest lucru m-a iritat la început, dar am folosit câteva componente native (nativescript-floatingactionbutton, nativescript-advanced-webview și nativescript-pulltorefresh) care m-au ajutat să obțin o experiență nativă și toate au funcționat perfect.
Puteți vedea rezultatul îmbunătățit aici:
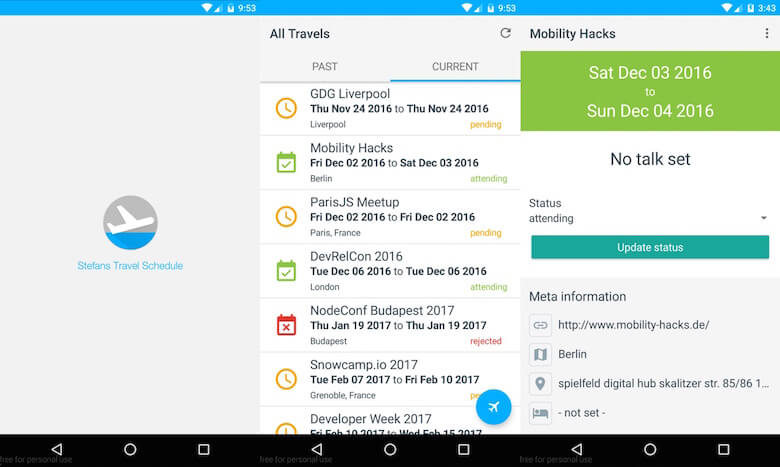
Cu cât pun mai multe funcționalități în această aplicație, cu atât mi-a plăcut mai mult și cu atât am folosit-o mai mult. Cea mai bună parte este că aș putea scăpa de duplicarea datelor, gestionând toate datele într-un singur loc, fiind suficient de flexibil pentru a le afișa pentru diferite cazuri de utilizare.
Paginile sunt ieri: trăiește conținutul structurat!
Construirea acestei aplicații mi-a arătat încă o dată că principiul de a avea date în format de pagină este de domeniul trecutului. Nu știm unde vor ajunge datele noastre – trebuie să fim pregătiți pentru un număr nelimitat de cazuri de utilizare.
Privind în urmă, ceea ce am realizat este:
- A avea un sistem de management al conținutului în cloud
- Nu trebuie să se ocupe de întreținerea bazei de date
- O stivă completă de tehnologie JavaScript
- A avea un site web static eficient
- Am o aplicație Android pentru a-mi accesa conținutul de fiecare dată și oriunde
Și cea mai importantă parte:
A avea conținutul structurat și accesibil m-a ajutat să-mi îmbunătățesc viața de zi cu zi.
Acest caz de utilizare ți se poate părea banal acum, dar când te gândești la produsele pe care le construiești în fiecare zi, există întotdeauna mai multe cazuri de utilizare pentru conținutul tău pe diferite platforme. Astăzi, acceptăm că dispozitivele mobile depășesc în sfârșit mediile desktop vechi de școală, dar platforme precum mașinile, ceasurile și chiar frigiderele își așteaptă deja lumina reflectoarelor. Nici nu mă pot gândi la cazurile de utilizare care vor veni.
Deci, haideți să încercăm să fim pregătiți și să punem conținut structurat la mijloc, pentru că la final nu este vorba despre schemele bazei de date, ci despre construirea pentru viitor.
Citiți suplimentare despre SmashingMag:
- Web Scraping cu Node.js
- Navigarea cu Sails.js: un cadru în stil MVC pentru Node.js
- 40 de icoane de călătorie pentru a vă înfrumuseța desenele
- O introducere detaliată la Webpack