
Top 10 comenzi Hadoop [cu utilizări]
Publicat: 2021-01-29În această epocă, cu cantități uriașe de date, devine esențial să se ocupe de ele. Datele care provin de la organizațiile cu clienți în creștere sunt mult mai mari decât le poate stoca orice instrument tradițional de gestionare a datelor. Ne lasă cu întrebarea de a gestiona seturi mai mari de date, care ar putea varia de la gigaocteți la petaocteți, fără a utiliza un singur computer mare sau instrument tradițional de gestionare a datelor.
Aici este locul în care cadrul Apache Hadoop atrage atenția. Înainte de a aborda implementarea comenzii Hadoop, să înțelegem pe scurt cadrul Hadoop și importanța acestuia.
Cuprins
Ce este Hadoop?
Hadoop este folosit în mod obișnuit de marile organizații de afaceri pentru a rezolva diverse probleme, de la stocarea de GB mari (Gigabytes) de date în fiecare zi până la operațiuni de calcul pe date.
Definit în mod tradițional ca un cadru de software open-source folosit pentru stocarea datelor și aplicațiile de procesare, Hadoop se evidențiază destul de mult față de majoritatea instrumentelor tradiționale de gestionare a datelor. Îmbunătățește puterea de calcul și extinde limita de stocare a datelor prin adăugarea de câteva noduri în cadru, făcându-l foarte scalabil. În plus, datele și procesele de aplicație sunt protejate împotriva diferitelor defecțiuni hardware.
Hadoop urmează o arhitectură master-slave pentru a distribui și stoca date folosind MapReduce și HDFS. După cum este prezentat în figura de mai jos, arhitectura este adaptată într-un mod definit pentru a efectua operațiuni de gestionare a datelor folosind patru noduri primare, și anume Nume, Date, Master și Slave. Componentele de bază ale Hadoop sunt construite direct deasupra cadrului. Alte componente se integrează direct cu segmentele.
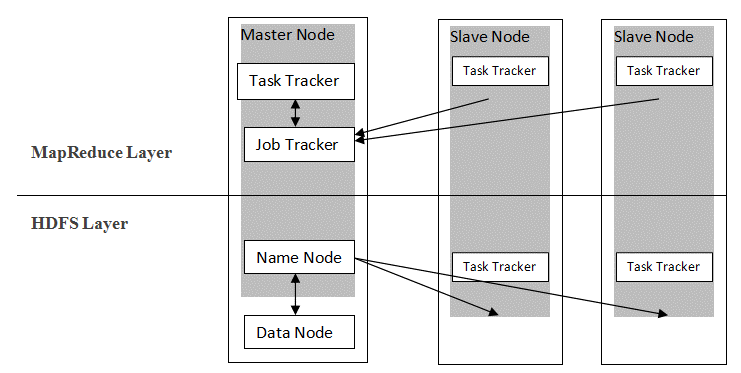 Sursă
Sursă

Comenzi Hadoop
Caracteristicile majore ale cadrului Hadoop arată o natură coerentă și devine mai ușor de utilizat atunci când vine vorba de gestionarea datelor mari prin învățarea comenzilor Hadoop. Mai jos sunt câteva comenzi Hadoop convenabile care permit efectuarea diferitelor operațiuni, cum ar fi gestionarea și procesarea fișierelor clusterelor HDFS. Această listă de comenzi este adesea necesară pentru a obține anumite rezultate ale procesului.
1. Hadoop Touchz
hadoop fs -touchz /directory/filename
Această comandă permite utilizatorului să creeze un fișier nou în clusterul HDFS. „Directorul” din comandă se referă la numele directorului în care utilizatorul dorește să creeze noul fișier, iar „nume fișier” înseamnă numele noului fișier care va fi creat la finalizarea comenzii.
2. Comanda de testare Hadoop
hadoop fs -test -[defsz] <cale>
Această comandă specială îndeplinește scopul de a testa existența unui fișier în clusterul HDFS. Caracterele din „[defsz]” din comandă trebuie modificate după cum este necesar. Iată o scurtă descriere a acestor personaje:
- d -> Verifică dacă este un director sau nu
- e -> Verifică dacă este o cale sau nu
- f -> Verifică dacă este un fișier sau nu
- s -> Verifică dacă este o cale goală sau nu
- r -> Verifică existența căii și permisiunea de citire
- w -> Verifică existența căii și permisiunea de scriere
- z -> Verifică dimensiunea fișierului
3. Comanda text Hadoop
hadoop fs -text <src>
Comanda text este deosebit de utilă pentru a afișa fișierul zip alocat în format text. Funcționează prin procesarea fișierelor sursă și furnizarea conținutului său într-un format de text simplu decodat.
4. Hadoop Find Command
hadoop fs -find <cale> … <expresie>

Această comandă este utilizată în general pentru a căuta fișiere în clusterul HDFS. Scanează expresia dată în comandă cu toate fișierele din cluster și afișează fișierele care se potrivesc cu expresia definită.
Citiți: Top instrumente Hadoop
5. Comanda Hadoop Getmerge
hadoop fs -getmerge <src> <localdest>
Comanda Getmerge permite îmbinarea unuia sau a mai multor fișiere într-un director desemnat pe clusterul sistemului de fișiere HDFS. Acumulează fișierele într-un singur fișier situat în sistemul de fișiere local. „src” și „localdest” reprezintă semnificația sursă-destinație și a destinației locale.
6. Comanda Hadoop Count
hadoop fs -count [opțiuni] <cale>
La fel de evidentă ca numele său, comanda Hadoop count numără numărul de fișiere și octeți dintr-un anumit director. Există diverse opțiuni disponibile care modifică rezultatul conform cerințelor. Acestea sunt după cum urmează:
- q -> cota arată limita pentru numărul total de nume și utilizarea spațiului
- u -> afișează numai cota și utilizarea
- h -> oferă dimensiunea unui fișier
- v -> afișează antetul
7. Comanda Hadoop AppendToFile
hadoop fs -appendToFile <localsrc> <dest>
Acesta permite utilizatorului să atașeze conținutul unuia sau mai multor fișiere într-un singur fișier pe fișierul de destinație specificat în clusterul de sistem de fișiere HDFS. La executarea acestei comenzi, fișierele sursă date sunt atașate la sursa de destinație conform numelui de fișier dat în comandă.
8. Comanda Hadoop ls
hadoop fs -ls /cale
Comanda ls din Hadoop arată lista de fișiere/conținut dintr-un director specificat, adică calea. La adăugarea „R” înainte de /cale, rezultatul va afișa detalii despre conținut, cum ar fi numele, dimensiunea, proprietarul și așa mai departe pentru fiecare fișier specificat în directorul dat.
9. Comanda Hadoop mkdir
hadoop fs -mkdir /cale/nume_director
Caracteristica unică a acestei comenzi este crearea unui director în clusterul sistemului de fișiere HDFS dacă directorul nu există. În plus, dacă directorul specificat este prezent, atunci mesajul de ieșire va afișa o eroare care indică existența directorului.
10. Comanda Hadoop chmod
hadoop fs -chmod [-R] <mod> <cale>
Această comandă este utilizată atunci când este nevoie de modificarea permisiunilor de accesare a unui anumit fișier. La darea comenzii chmod, permisiunea fișierului specificat este schimbată. Cu toate acestea, este important să rețineți că permisiunea va fi modificată atunci când proprietarul fișierului execută această comandă.
Citește și: Tutorial Impala Hadoop
Concluzie
Începând cu problema importantă a stocării datelor cu care se confruntă marile organizații din lumea de astăzi, acest articol a discutat soluția pentru stocarea limitată a datelor prin introducerea Hadoop și impactul acestuia asupra efectuării operațiunilor de gestionare a datelor prin utilizarea comenzilor Hadoop. Pentru începătorii în Hadoop, este descrisă o prezentare generală a cadrului, împreună cu componentele și arhitectura acestuia.

După ce ați citit acest articol, vă puteți simți cu ușurință încrezător în cunoștințele sale în ceea ce privește cadrul Hadoop și comenzile aplicate. Certificarea PG exclusivă în Big Data de la upGrad: upGrad oferă un program de 7,5 luni specific industriei pentru Certificarea PG în Big Data în care veți organiza, analiza și interpreta Big Data cu IIIT-Bangalore.
Proiectat cu atenție pentru profesioniștii care lucrează, îi va ajuta pe studenți să dobândească cunoștințe practice și să le stimuleze intrarea în roluri de Big Data.
Repere ale programului:
- Învățarea limbilor și instrumentelor relevante
- Învățarea conceptelor avansate de programare distribuită, platforme de date mari, baze de date, algoritmi și web mining
- Un certificat acreditat de la IIIT Bangalore
- Asistență pentru plasare pentru a fi absorbit de companiile multinaționale de top
- Mentorizare 1:1 pentru a vă urmări progresul și pentru a vă ajuta în fiecare moment
- Lucrul la proiecte și sarcini live
Eligibilitate : Matematică/Inginerie software/Statistică/Analitică
Consultați celelalte cursuri ale noastre de inginerie software la upGrad.