
A GraphQL Primer: Evoluția designului API (Partea 2)
Publicat: 2022-03-10În partea 1, am analizat modul în care API-urile au evoluat în ultimele decenii și modul în care fiecare a lăsat locul următorului. Am vorbit, de asemenea, despre unele dintre dezavantajele particulare ale utilizării REST pentru dezvoltarea clienților mobile. În acest articol, vreau să văd încotro pare să se îndrepte designul API al clientului mobil - cu un accent deosebit pe GraphQL.
Există, desigur, o mulțime de oameni, companii și proiecte care au încercat să abordeze deficiențele REST de-a lungul anilor: HAL, Swagger/OpenAPI, OData JSON API și zeci de alte proiecte mai mici sau interne au căutat să pună ordine în lumea REST fără specificații. În loc să iau lumea așa cum este și să propun îmbunătățiri progresive sau să încerc să adun suficiente piese disparate pentru a face din REST ceea ce am nevoie, aș vrea să încerc un experiment de gândire. Având în vedere tehnicile care au funcționat și nu au funcționat în trecut, aș dori să iau constrângerile de astăzi și limbajele noastre mult mai expresive pentru a încerca să schițez API-ul pe care ni-l dorim. Să lucrăm de la experiența dezvoltatorului înapoi și nu de la implementare înainte (mă uit la tine SQL).
Trafic HTTP minim
Știm că costul fiecărei solicitări de rețea (HTTP/1) este ridicat pentru câteva măsuri, de la latență la durata de viață a bateriei. În mod ideal, clienții noului nostru API vor avea nevoie de o modalitate de a cere toate datele de care au nevoie în cât mai puține călătorii dus-întors.
Sarcini utile minime
De asemenea, știm că clientul mediu are resurse limitate, în lățime de bandă, CPU și memorie, așa că scopul nostru ar trebui să fie să trimitem doar informațiile de care clientul nostru are nevoie. Pentru a face acest lucru, probabil că vom avea nevoie de o modalitate prin care clientul poate solicita anumite date.
Citibil uman
Am aflat din zilele SOAP că un API nu este ușor de interacționat, oamenii se vor strâmba la mențiunea lui. Echipele de inginerie doresc să folosească aceleași instrumente pe care ne-am bazat de ani de zile, cum ar fi curl , wget și Charles și fila de rețea a browserelor noastre.
Bogat în scule
Un alt lucru pe care l-am învățat de la XML-RPC și SOAP este că contractele client/server și sistemele de tip, în special, sunt uimitor de utile. Dacă este posibil, orice nou API ar avea ușurința unui format precum JSON sau YAML, cu capacitatea de introspecție a unor contracte mai structurate și mai sigure de tip.
Păstrarea raționamentului local
De-a lungul anilor, am ajuns să cădem de acord asupra unor principii directoare în modul de organizare a bazelor de cod mari - principalul fiind „separarea preocupărilor”. Din păcate, pentru majoritatea proiectelor, acest lucru tinde să se defecteze sub forma unui nivel centralizat de acces la date. Dacă este posibil, diferite părți ale unei aplicații ar trebui să aibă opțiunea de a-și gestiona propriile nevoi de date împreună cu celelalte funcționalități ale acesteia.
Deoarece proiectăm un API centrat pe client, să începem cu cum ar putea arăta preluarea datelor într-un API ca acesta. Dacă știm că trebuie să facem ambele călătorii minime dus-întors și că trebuie să fim capabili să filtram câmpurile pe care nu le dorim, avem nevoie de o modalitate de a parcurge seturi mari de date și de a solicita doar părțile din acestea care sunt utilă nouă. Un limbaj de interogare pare că s-ar potrivi bine aici.
Nu trebuie să punem întrebări cu privire la datele noastre în același mod în care faci cu o bază de date, așa că un limbaj imperativ precum SQL pare instrumentul greșit. De fapt, obiectivele noastre principale sunt să traversăm relațiile preexistente și să limităm câmpurile pe care ar trebui să le putem face cu ceva relativ simplu și declarativ. Industria s-a stabilit destul de bine pe JSON pentru date non-binare, așa că să începem cu un limbaj de interogare declarativ asemănător JSON. Ar trebui să putem descrie datele de care avem nevoie, iar serverul ar trebui să returneze JSON care să conțină acele câmpuri.

Un limbaj de interogare declarativ îndeplinește cerințele atât pentru încărcături utile minime, cât și pentru trafic HTTP minim, dar există un alt beneficiu care ne va ajuta cu un alt obiectiv de proiectare. Multe limbaje declarative, interogări și altele, pot fi manipulate eficient ca și cum ar fi date. Dacă proiectăm cu atenție, limbajul nostru de interogare va permite dezvoltatorilor să separe cererile mari și să le recombine în orice mod care ar avea sens pentru proiectul lor. Folosirea unui limbaj de interogare ca acesta ne-ar ajuta să ne îndreptăm spre obiectivul nostru final de conservare a raționamentului local.
Există o mulțime de lucruri interesante pe care le poți face odată ce interogările tale devin „date”. De exemplu, puteți intercepta toate solicitările și le puteți grupa în mod similar cu cum se actualizează un DOM virtual în loturi, puteți utiliza, de asemenea, un compilator pentru a extrage interogările mici în timpul construcției pentru a pre-cache datele sau ați putea construi un sistem de cache sofisticat. ca Apollo Cache.
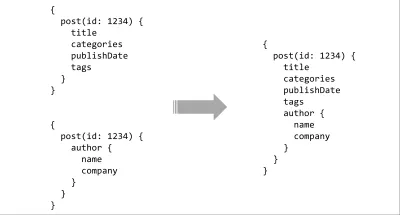
Ultimul articol din lista de dorințe API este instrumentele. Obținem deja o parte din acestea utilizând un limbaj de interogare, dar puterea reală vine atunci când îl asociați cu un sistem de tip. Cu o schemă tastată simplă pe server, există posibilități aproape nesfârșite pentru instrumente bogate. Interogările pot fi analizate static și validate în raport cu contractul, integrările IDE pot oferi indicii sau auto-completare, compilatorii pot face optimizări în timpul construirii interogărilor sau mai multe scheme pot fi îmbinate împreună pentru a forma o suprafață API adiacentă.

Proiectarea unui API care îmbină un limbaj de interogare și un sistem de tip poate suna ca o propunere dramatică, dar oamenii au experimentat acest lucru, sub diferite forme, de ani de zile. XML-RPC a solicitat răspunsuri tipizate la mijlocul anilor 90, iar succesorul său, SOAP, a dominat ani de zile! Mai recent, există lucruri precum abstracția MongoDB de la Meteor, Horizon de la RethinkDB (RIP), uimitorul Falcor de la Netflix, pe care îl folosesc pentru Netflix.com de ani de zile, iar ultimul este GraphQL de la Facebook. Pentru restul acestui eseu, mă voi concentra pe GraphQL, deoarece, în timp ce alte proiecte precum Falcor fac lucruri similare, comunitatea pare să o favorizeze în mod covârșitor.
Ce este GraphQL?
În primul rând, trebuie să spun că am mințit puțin. API-ul pe care l-am construit mai sus a fost GraphQL. GraphQL este doar un sistem de tip pentru datele dvs., un limbaj de interogare pentru a le parcurge - restul sunt doar detalii. În GraphQL, vă descrieți datele ca un grafic al interconexiunilor, iar clientul vă solicită în mod special subsetul de date de care are nevoie. Se vorbește și se scrie mult despre toate lucrurile incredibile pe care le permite GraphQL, dar conceptele de bază sunt foarte ușor de gestionat și necomplicate.
Pentru a face aceste concepte mai concrete și pentru a ajuta la ilustrarea modului în care GraphQL încearcă să abordeze unele dintre problemele din partea 1, restul acestei postări va construi un API GraphQL care poate alimenta blogul în partea 1 a acestei serii. Înainte de a intra în cod, există câteva lucruri despre GraphQL de reținut.
GraphQL este o specificație (nu o implementare)
GraphQL este doar o specificație. Acesta definește un sistem de tipuri împreună cu un limbaj simplu de interogare și asta este tot. Primul lucru care reiese din acest lucru este că GraphQL nu este, în niciun fel, legat de o anumită limbă. Există peste două duzini de implementări în orice, de la Haskell la C++, dintre care JavaScript este doar una. La scurt timp după anunțarea specificațiilor, Facebook a lansat o implementare de referință în JavaScript, dar, din moment ce nu o folosesc intern, implementările în limbaje precum Go și Clojure pot fi chiar mai bune sau mai rapide.
Specificațiile GraphQL nu menționează clienți sau date
Dacă citiți specificațiile, veți observa că două lucruri lipsesc în mod evident. În primul rând, dincolo de limbajul de interogare, nu se menționează integrările clienților. Instrumente precum Apollo, Relay, Loka și altele asemenea sunt posibile datorită designului GraphQL, dar nu sunt în niciun caz parte sau necesare pentru utilizarea acestuia. În al doilea rând, nu se menționează un anumit nivel de date. Același server GraphQL poate, și face frecvent, să preia date dintr-un set eterogen de surse. Poate solicita date stocate în cache de la Redis, poate face o căutare a adresei din API-ul USPS și poate apela microservicii bazate pe protobuff, iar clientul nu va ști niciodată diferența.
Dezvăluirea progresivă a complexității
Pentru mulți oameni, GraphQL a lovit o intersecție rară a puterii și simplității. Face o treabă fantastică de a face lucrurile simple simple și cele grele posibile. Obținerea unui server care rulează și difuzarea datelor tastate prin HTTP poate fi doar câteva linii de cod în aproape orice limbă pe care o puteți imagina.
De exemplu, un server GraphQL poate include un API REST existent, iar clienții săi pot obține date cu solicitări GET obișnuite, așa cum ați interacționa cu alte servicii. Puteți vedea un demo aici. Sau, dacă proiectul are nevoie de un set mai sofisticat de instrumente, este posibil să utilizați GraphQL pentru a face lucruri precum autentificare la nivel de câmp, abonamente pub/sub sau interogări pre-compilate/cache.
Un exemplu de aplicație
Scopul acestui exemplu este de a demonstra puterea și simplitatea GraphQL în ~70 de linii de JavaScript, nu de a scrie un tutorial extins. Nu voi intra în prea multe detalii despre sintaxă și semantică, dar tot codul de aici poate fi rulat și există un link către o versiune descărcabilă a proiectului la sfârșitul articolului. Dacă după ce ați trecut prin asta, doriți să sapi puțin mai adânc, am o colecție de resurse pe blogul meu care vă vor ajuta să construiți servicii mai mari și mai robuste.
Pentru demonstrație, voi folosi JavaScript, dar pașii sunt foarte similari în orice limbă. Să începem cu câteva exemple de date folosind uimitorul Mocky.io.
Autorii
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }Postări
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] Primul pas este crearea unui nou proiect cu express și middleware-ul express-graphql .

bash npm init -y && npm install --save graphql express express-graphql Și pentru a crea un fișier index.js cu un server expres.
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); Pentru a începe să lucrăm cu GraphQL, putem începe prin a modela datele în API-ul REST. Într-un fișier nou numit schema.js adăugați următoarele:
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); Codul de mai sus mapează tipurile din răspunsurile JSON ale API-ului nostru la tipurile GraphQL. Un GraphQLObjectType corespunde unui Object JavaScript, un GraphQLString corespunde unui String JavaScript și așa mai departe. Singurul tip special căruia trebuie să acordați atenție este GraphQLSchema de pe ultimele rânduri. GraphQLSchema este exportul la nivel de rădăcină al unui GraphQL - punctul de pornire pentru interogări pentru a traversa graficul. În acest exemplu de bază, definim doar query ; aici ați defini mutațiile (scrierile) și abonamentele.
În continuare, vom adăuga schema la serverul nostru expres în fișierul index.js . Pentru a face acest lucru, vom adăuga middleware-ul express-graphql și îi vom transmite schema.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); În acest moment, deși nu returnăm nicio dată, avem un server GraphQL funcțional care oferă schema sa clienților. Pentru a ușura pornirea aplicației, vom adăuga, de asemenea, un script de pornire la package.json .
"scripts": { "start": "nodemon index.js" }, Rularea proiectului și accesarea https://localhost:5000/ ar trebui să arate un explorator de date numit GraphiQL. GraphiQL se va încărca în mod implicit atâta timp cât antetul HTTP Accept nu este setat la application/json . Apelarea aceleiași adrese URL cu fetch sau cURL folosind application/json va returna un rezultat JSON. Simțiți-vă liber să vă jucați cu documentația încorporată și să scrieți o interogare.

Singurul lucru care rămâne de făcut pentru a finaliza serverul este să conectați datele de bază în schemă. Pentru a face acest lucru, trebuie să definim funcțiile de resolve . În GraphQL, o interogare este rulată de sus în jos apelând o funcție de resolve pe măsură ce traversează arborele. De exemplu, pentru următoarea interogare:
query homepage { posts { title } } GraphQL va apela mai întâi posts.resolve(parentData) , apoi posts.title.resolve(parentData) . Să începem prin a defini soluția pe lista noastră de postări de blog.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); Folosesc pachetul isomorphic-fetch aici pentru a face o solicitare HTTP, deoarece demonstrează frumos cum să returnați o Promisiune de la un resolver, dar puteți folosi orice doriți. Această funcție va returna o serie de postări la tipul Blog. Funcția de rezolvare implicită pentru implementarea JavaScript a GraphQL este parentData.<fieldName> . De exemplu, soluția implicită de rezolvare pentru câmpul Numele autorului ar fi:
rawAuthorObject => rawAuthorObject.nameAcest solutor unic de suprascriere ar trebui să furnizeze datele pentru întregul obiect post. Încă trebuie să definim soluția pentru Autor, dar dacă rulați o interogare pentru a prelua datele necesare pentru pagina de pornire, ar trebui să vedeți că funcționează.
Deoarece atributul autor din API-ul nostru de postări este doar ID-ul autorului, atunci când GraphQL caută un Object care definește numele și compania și găsește un String, va returna pur și simplu null . Pentru a conecta Autorul, trebuie să ne schimbăm schema Post pentru a arăta astfel:
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });Acum, avem un server GraphQL complet funcțional, care include un API REST. Sursa completă poate fi descărcată de pe acest link Github sau poate fi rulată de pe acest launchpad GraphQL.
S-ar putea să vă întrebați despre instrumentele pe care va trebui să le utilizați pentru a consuma un punct final GraphQL ca acesta. Există o mulțime de opțiuni precum Relay și Apollo, dar pentru a începe, cred că abordarea simplă este cea mai bună. Dacă te-ai jucat mult cu GraphiQL, s-ar putea să fi observat că are o adresă URL lungă. Această adresă URL este doar o versiune codificată URI a interogării dvs. Pentru a construi o interogare GraphQL în JavaScript, puteți face ceva de genul acesta:
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);Sau, dacă doriți, puteți copia și lipi adresa URL direct din GraphiQL astfel:
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageDeoarece avem un punct final GraphQL și o modalitate de a-l folosi, îl putem compara cu API-ul nostru RESTish. Codul pe care trebuia să-l scriem pentru a ne prelua datele folosind un API RESTish arăta astfel:
Folosind un API RESTish
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };Utilizarea unui API GraphQL
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);În rezumat, am folosit GraphQL pentru a:
- Reduceți nouă solicitări (lista de postări, patru postări pe blog și autorul fiecărei postări).
- Reduceți cantitatea de date trimise cu un procent semnificativ.
- Utilizați instrumente incredibile pentru dezvoltatori pentru a crea interogările noastre.
- Scrieți un cod mult mai curat în clientul nostru.
Defecte în GraphQL
Deși cred că hype-ul este justificat, nu există niciun glonț de argint și, oricât de grozav este GraphQL, nu este lipsit de defecte.
Integritatea datelor
GraphQL pare uneori un instrument care a fost creat special pentru date bune. Adesea funcționează cel mai bine ca un fel de poartă, îmbinând servicii disparate sau tabele extrem de normalizate. Dacă datele care revin de la serviciile pe care le consumați sunt dezordonate și nestructurate, adăugarea unui canal de transformare a datelor sub GraphQL poate fi o adevărată provocare. Scopul unei funcții de rezolvare GraphQL este doar propriile sale date și ale copiilor săi. Dacă o sarcină de orchestrare necesită acces la datele unui frate sau al unui părinte din arbore, poate fi deosebit de dificil.
Gestionarea erorilor complexe
O solicitare GraphQL poate rula un număr arbitrar de interogări, iar fiecare interogare poate atinge un număr arbitrar de servicii. Dacă orice parte a cererii eșuează, în loc să eșueze întreaga cerere, GraphQL, în mod implicit, returnează date parțiale. Datele parțiale sunt probabil alegerea potrivită din punct de vedere tehnic și pot fi incredibil de utile și eficiente. Dezavantajul este că gestionarea erorilor nu mai este la fel de simplă precum verificarea codului de stare HTTP. Acest comportament poate fi dezactivat, dar, de cele mai multe ori, clienții ajung să aibă cazuri de eroare mai sofisticate.
Memorarea în cache
Deși este adesea o idee bună să folosiți interogări GraphQL statice, pentru organizații precum Github care permit interogări arbitrare, stocarea în cache în rețea cu instrumente standard precum Varnish sau Fastly nu va mai fi posibilă.
Cost ridicat al procesorului
Analizarea, validarea și verificarea tipului unei interogări este un proces legat de CPU, care poate duce la probleme de performanță în limbaje cu un singur thread, cum ar fi JavaScript.
Aceasta este doar o problemă pentru evaluarea interogărilor de rulare.
Gânduri de închidere
Funcțiile GraphQL nu sunt o revoluție – unele dintre ele există de aproape 30 de ani. Ceea ce face ca GraphQL să fie puternic este că nivelul de lustruire, integrare și ușurință în utilizare îl fac mai mult decât suma părților sale.
Multe dintre lucrurile pe care le realizează GraphQL pot fi realizate, cu efort și disciplină, folosind REST sau RPC, dar GraphQL aduce API-uri de ultimă generație pentru numărul enorm de proiecte care nu au timp, resurse sau instrumente pentru a face acest lucru ele însele. De asemenea, este adevărat că GraphQL nu este un glonț de argint, dar defectele sale tind să fie minore și bine înțelese. Ca cineva care a construit un server GraphQL destul de complicat, pot spune cu ușurință că beneficiile depășesc cu ușurință costul.
Acest eseu se concentrează aproape în întregime pe motivul pentru care există GraphQL și pe problemele pe care le rezolvă. Dacă acest lucru v-a stârnit interesul de a afla mai multe despre semantica sa și despre cum să o utilizați, vă încurajez să învățați în orice mod funcționează cel mai bine pentru dvs., fie că este vorba de bloguri, youtube sau pur și simplu citind sursa (How To GraphQL este deosebit de bun).
Dacă ți-a plăcut acest articol (sau dacă l-ai urât) și vrei să-mi dai feedback, te rog să mă găsești pe Twitter ca @ebaerbaerbaer sau LinkedIn la ericjbaer.