
Un primer GraphQL: De ce avem nevoie de un nou tip de API (Partea 1)
Publicat: 2022-03-10În această serie, vreau să vă prezint GraphQL. Până la sfârșit, ar trebui să înțelegeți nu doar ce este, ci și originile sale, dezavantajele sale și elementele de bază ale modului de lucru cu el. În acest prim articol, mai degrabă decât să trec la implementare, vreau să trec peste cum și de ce am ajuns la GraphQL (și la instrumente similare) analizând lecțiile învățate din ultimii 60 de ani de dezvoltare a API-ului, de la RPC până acum. La urma urmei, așa cum a descris Mark Twain plin de culoare, nu există idei noi.
"Nu există o idee nouă. Este imposibil. Pur și simplu luăm o mulțime de idei vechi și le punem într-un fel de caleidoscop mental."
— Mark Twain în „Propia autobiografie a lui Mark Twain: capitolele din The North American Review”
Dar mai întâi trebuie să mă adresez elefantului din cameră. Lucrurile noi sunt întotdeauna interesante, dar se pot simți și epuizante. Poate că ai auzit despre GraphQL și te-ai gândit: „De ce...” Alternativ, poate te-ai gândit ceva mai mult de genul „De ce îmi pasă de o nouă tendință de design API? REST este... bine.” Acestea sunt întrebări legitime, așa că permiteți-mi să vă ajut să explic de ce ar trebui să acordați atenție acesteia.
Introducere
Beneficiile aducerii de noi instrumente echipei dumneavoastră trebuie să fie cântărite în raport cu costurile acesteia. Sunt o mulțime de lucruri de măsurat. Există timpul necesar pentru a învăța, timpul de conversie elimină dezvoltarea caracteristicilor, cheltuielile generale pentru întreținerea a două sisteme. Cu costuri atât de mari, orice tehnologie nouă trebuie să fie mai bună, mai rapidă sau mai productivă cu o sumă uriașă. Îmbunătățirile trepte, deși sunt interesante, pur și simplu nu merită investiția. Tipurile de API-uri despre care vreau să vorbesc, în special GraphQL, sunt în opinia mea un mare pas înainte și oferă beneficii mai mult decât suficiente pentru a justifica costul.
În loc să explorați mai întâi caracteristicile, este util să le puneți în context și să înțelegeți cum au apărut. Pentru a face acest lucru, voi începe cu o scurtă recapitulare a istoriei API-urilor.
RPC
RPC a fost, probabil, primul model API major, iar originile sale se întorc până la calculul timpuriu la mijlocul anilor '60. La acea vreme, computerele erau încă atât de mari și scumpe încât noțiunea de dezvoltare a aplicațiilor bazată pe API, așa cum ne gândim noi, era în mare parte doar teoretică. Constrângeri precum lățimea de bandă/latența, puterea de calcul, timpul de calcul partajat și proximitatea fizică i-au forțat pe ingineri să gândească mai degrabă în termeni de sisteme distribuite decât de servicii care expun date. De la ARPANET în anii 60, până la mijlocul anilor 90 cu lucruri precum CORBA și RMI Java, majoritatea computerelor au interacționat între ele folosind Remote Procedure Calls (RPC), care este un model de interacțiune client-server în care un client provoacă o procedură. (sau metoda) de executat pe un server la distanță.
Există o mulțime de lucruri frumoase despre RPC. Principiul său principal este să permită unui dezvoltator să trateze codul într-un mediu la distanță ca și cum ar fi într-unul local, deși mult mai lent și mai puțin fiabil, ceea ce creează continuitate în sisteme altfel distincte și disparate. La fel ca multe lucruri care au apărut ARPANET, a fost înaintea timpului, deoarece acest tip de continuitate este ceva pentru care încă ne străduim atunci când lucrăm cu acțiuni nesigure și asincrone, cum ar fi accesul la DB și apelurile de servicii externe.
De-a lungul deceniilor, a existat o cantitate enormă de cercetări cu privire la modul de a permite dezvoltatorilor să încorporeze un comportament asincron ca acesta în fluxul tipic al unui program; dacă ar exista lucruri precum Promises, Futures și ScheduledTasks disponibile la momentul respectiv, este posibil ca peisajul nostru API să arate diferit.
Un alt lucru grozav despre RPC este că, deoarece nu este constrâns de structura datelor, pot fi scrise metode foarte specializate pentru clienții care solicită și preiau exact informațiile necesare, ceea ce poate duce la o supraîncărcare minimă a rețelei și sarcini utile mai mici.
Există, totuși, lucruri care fac RPC dificil. În primul rând, continuitatea necesită context . RPC, prin proiectare, creează destul de multe cupluri între sistemele locale și cele de la distanță - pierzi granițele dintre codul local și cel de la distanță. Pentru unele domenii, acest lucru este în regulă sau chiar preferat ca în SDK-urile client, dar pentru API-urile în care codul clientului nu este bine înțeles, poate fi considerabil mai puțin flexibil decât ceva mai orientat către date.
Totuși, mai important este potențialul de proliferare a metodelor API . În teorie, un serviciu RPC expune un mic API atent care se poate ocupa de orice sarcină. În practică, un număr mare de puncte finale externe se pot acumula fără prea multă structură. Este nevoie de o cantitate enormă de disciplină pentru a preveni suprapunerea API-urilor și dublarea în timp, pe măsură ce membrii echipei vin și pleacă și proiectele pivotează.
Este adevărat că, cu instrumente adecvate și modificări de documentare, precum cele pe care le-am menționat, pot fi gestionate, dar în timpul meu de scris software am întâlnit puține servicii de auto-documentare și disciplinate, așa că, pentru mine, acesta este un pic un hering roșu.
SĂPUN
Următorul tip important de API care a apărut a fost SOAP, care s-a născut la sfârșitul anilor 90 la Microsoft Research. SOAP ( Protocolul de acces la obiect simplu) este o specificație de protocol ambițioasă pentru comunicarea bazată pe XML între aplicații. Ambiția declarată a SOAP a fost de a aborda unele dintre dezavantajele practice ale RPC, în special XML-RPC, prin crearea unei fundații bine structurate pentru servicii web complexe. De fapt, asta însemna doar adăugarea unui sistem de tip comportamental la XML. Din păcate, a creat mai multe impedimente decât a rezolvat, așa cum demonstrează faptul că foarte puține puncte finale SOAP sunt scrise astăzi.
„SOAP este ceea ce majoritatea oamenilor ar considera un succes moderat.”
— Don Box
SOAP a avut niște lucruri bune pentru el, în ciuda verbozității sale insuportabile și a numelor teribile. Contractele executorii din WSDL și WADL (pronunțat „wizdle” și „waddle”) între client și server garantau rezultate previzibile, sigure de tip, iar WSDL putea fi folosit pentru a genera documentație sau pentru a crea integrări cu IDE-uri și alte instrumente.
Marea revelație a SOAP cu privire la evoluția API a fost introducerea treptată și posibil neintenționată a apelurilor mai orientate spre resurse. Punctele finale SOAP vă permit să solicitați date cu o structură predeterminată, mai degrabă decât să vă gândiți la metodele necesare pentru a genera datele (presupunând că sunt scrise astfel).
Cel mai important dezavantaj al SOAP este că este atât de proligent; este aproape imposibil de utilizat fără multe unelte . Aveți nevoie de instrumente pentru a scrie teste, instrumente pentru a inspecta răspunsurile de la un server și instrumente pentru a analiza toate datele. Multe sisteme mai vechi încă folosesc SOAP, dar cerința de instrumente o face prea greoaie pentru majoritatea proiectelor noi, iar numărul de octeți necesari pentru structura XML îl face o alegere proastă pentru a servi dispozitive mobile sau sisteme distribuite discutabile.
Pentru mai multe informații, merită să citiți specificațiile SOAP, precum și istoria surprinzător de interesantă a SOAP de la Don Box, unul dintre membrii echipei inițiale.
ODIHNĂ
În cele din urmă, am ajuns la modelul de design API de zi: REST. REST, introdus într-o teză de doctorat de Roy Fielding în 2000, a înclinat pendulul într-o direcție complet diferită. REST este, în multe privințe, antiteza SOAP și privindu-le unul lângă altul te face să simți că disertația lui a fost un pic de furie.
SOAP folosește HTTP ca un transport prost și își construiește structura în corpul cererii și răspunsului. REST, pe de altă parte, elimină contractele client-server, instrumentele, XML și anteturile personalizate, înlocuindu-le cu semantica HTTP, deoarece structura alege să folosească verbele HTTP care interacționează cu date și URI-uri care fac referire la o resursă într-o ierarhie de date.
| SĂPUN | ODIHNĂ | |
|---|---|---|
| Verbe HTTP | GET, PUT, POST, PATCH, DELETE | |
| Format de date | XML | Ce vrei tu |
| Contracte client/server | Toată ziua în fiecare zi! | Cine are nevoie de acestea |
| Tip System | JavaScript are un scurt nesemnat, nu? | |
| URL-uri | Descrieți operațiunile | Resurse numite |
REST schimbă complet și explicit designul API de la modelarea interacțiunilor la simpla modelare a datelor unui domeniu. Fiind pe deplin orientat către resurse atunci când lucrați cu un API REST, nu mai trebuie să știți sau să vă pese de ce este nevoie pentru a prelua o anumită bucată de date; nici nu trebuie să știți nimic despre implementarea serviciilor de backend.

Nu numai că simplitatea a fost un avantaj pentru dezvoltatori, dar, deoarece adresele URL reprezintă informații stabile, este ușor de stocat în cache, apatridia face ușoară scalarea orizontală și, deoarece modelează datele mai degrabă decât să anticipeze nevoile consumatorilor, poate reduce dramatic suprafața API-urilor. .
REST este grozav, iar omniprezența sa este un succes uimitor, dar, la fel ca toate soluțiile care au apărut înainte, REST nu este lipsit de defecte. Pentru a vorbi concret despre unele dintre deficiențele sale, să trecem peste un exemplu de bază. Să presupunem că trebuie să construim pagina de destinație a unui blog care afișează o listă de postări de blog și numele autorului acestora.
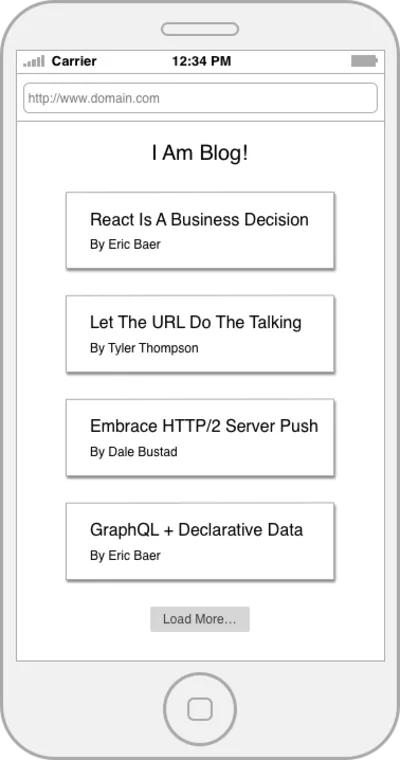
Să scriem codul care poate prelua datele paginii de pornire dintr-un API REST simplu. Vom începe cu câteva funcții care înglobează resursele noastre.
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);Acum, hai să orchestrăm!
const getPostWithAuthor = postId => { return getPost(postId) .then(post => getAuthor(post.author)) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(postIds => { const postDetails = postIds.map(getPostWithAuthor); return Promise.all(postDetails); }) };Deci, codul nostru va face următoarele:
- Preluați toate postările;
- Preluați detaliile despre fiecare postare;
- Preluați resursa de autor pentru fiecare postare.
Lucrul frumos este că acest lucru este destul de ușor de raționat, bine organizat și limitele conceptuale ale fiecărei resurse sunt bine trasate. Dezastrul aici este că tocmai am făcut opt solicitări de rețea, dintre care multe au loc în serie.
GET /posts GET /posts/234 GET /posts/456 GET /posts/17 GET /posts/156 GET /author/9 GET /author/4 GET /author/7 GET /author/2 Da, ați putea critica acest exemplu, sugerând că API-ul ar putea avea un punct final paginat /posts , dar care este împărțirea părului. Faptul rămâne că deseori aveți o colecție de apeluri API care să depindă unul de celălalt pentru a reda o aplicație sau o pagină completă.
Dezvoltarea de clienți și servere REST este cu siguranță mai bună decât ceea ce a fost înainte, sau cel puțin mai multă dovadă idioată, dar multe s-au schimbat în cele două decenii de la lucrarea lui Fielding. La acea vreme, toate computerele erau din plastic bej; acum sunt din aluminiu! Serios, totuși, 2000 a fost aproape de apogeul exploziei în computerele personale. În fiecare an, procesoarele își dublau viteza, iar rețelele deveneau mai rapide la un ritm incredibil. Pătrunderea pe piață a internetului a fost de aproximativ 45%, fără unde să meargă decât în creștere.
Apoi, în jurul anului 2008, computerul mobil a devenit mainstream. Cu mobilul, am regresat efectiv un deceniu în ceea ce privește viteza/performanța peste noapte. În 2017, avem aproape 80% penetrare internă și peste 50% globală a smartphone-urilor și este momentul să ne regândim unele dintre ipotezele noastre despre designul API.
Punctele slabe ale REST
Următoarea este o privire critică asupra REST din perspectiva unui dezvoltator de aplicații client, în special a unuia care lucrează pe mobil. API-urile în stil GraphQL și GraphQL nu sunt noi și nu rezolvă problemele care nu sunt la îndemâna dezvoltatorilor REST. Cea mai semnificativă contribuție a GraphQL este capacitatea sa de a rezolva aceste probleme în mod sistematic și cu un nivel de integrare care nu este ușor disponibil în altă parte. Cu alte cuvinte, este o soluție „cu baterii incluse”.
Autorii principali ai REST, inclusiv Fielding, au publicat o lucrare la sfârșitul anului 2017 (Reflecții asupra stilului arhitectural REST și „Principled Design of the Modern Web Architecture”) reflectând asupra a două decenii de REST și a numeroaselor modele pe care le-a inspirat. Este scurt și merită absolut citit pentru oricine este interesat de designul API.
Având un context istoric și o aplicație de referință, să ne uităm la cele trei puncte slabe principale ale REST.
REST este discutabil
Serviciile REST tind să fie cel puțin oarecum „chatty”, deoarece este nevoie de mai multe călătorii dus-întors între client și server pentru a obține suficiente date pentru a reda o aplicație. Această cascadă de solicitări are un impact devastator asupra performanței, în special pe mobil. Revenind la exemplul blogului, chiar și în cel mai bun scenariu cu un telefon nou și o rețea fiabilă cu o conexiune 4G, ați cheltuit aproape 0,5 secunde doar pentru o latență înainte de descărcarea primului octet de date.
Latență 4G de 55 ms * 8 solicitări = 440 ms overhead
O altă problemă cu serviciile conversaționale este că, în multe cazuri, este nevoie de mai puțin timp pentru a descărca o solicitare mare decât multe cereri mici. Performanța redusă a cererilor mici este adevărată din mai multe motive, inclusiv TCP Slow Start, lipsa compresiei antetului și eficiența gzip-ului și, dacă sunteți curios despre asta, vă recomand cu căldură să citiți Rețeaua de browser de înaltă performanță a lui Ilya Grigorik. Blogul MaxCDN are și o imagine de ansamblu grozavă.
Această problemă nu este tehnic cu REST, ci cu HTTP, în special HTTP/1. HTTP/2 rezolvă aproape problema conversației, indiferent de stilul API și are suport larg în clienți precum browsere și SDK-uri native. Din păcate, lansarea a fost lentă din partea API. Printre primele 10.000 de site-uri web, adoptarea este de aproximativ 20% (și în creștere) la sfârșitul anului 2017. Chiar și Node.js, spre surprinderea mea, a primit suport HTTP/2 în lansarea lor 8.x. Dacă aveți capacitatea, vă rugăm să vă actualizați infrastructura! Între timp, să nu ne oprim, deoarece aceasta este doar o parte a ecuației.
Lăsând la o parte HTTP, ultima parte a motivului pentru care este importantă conversația, are legătură cu modul în care funcționează dispozitivele mobile și, în special, radiourile lor. Pe scurt și pe scurt, operarea radioului este una dintre părțile cu cel mai mare consum de baterie ale unui telefon, astfel încât sistemul de operare îl oprește cu fiecare ocazie. Nu numai că pornirea radioului consumă bateria, dar adaugă și mai multă suprasarcină la fiecare solicitare.
TMI (supracărcarea)
Următoarea problemă cu serviciile în stil REST este că trimite mai multe informații decât este necesar. În exemplul nostru de blog, tot ce ne trebuie este titlul fiecărei postări și numele autorului acesteia, care reprezintă doar aproximativ 17% din ceea ce a fost returnat. Aceasta este o pierdere de 6 ori pentru o sarcină utilă foarte simplă. Într-un API din lumea reală, acest tip de suprasarcină poate fi enorm. Site-urile de comerț electronic, de exemplu, reprezintă adesea un singur produs ca mii de linii de JSON. La fel ca problema conversației, serviciile REST pot gestiona acest scenariu astăzi folosind „seturi de câmpuri rare” pentru a include sau exclude în mod condiționat părți ale datelor. Din păcate, suportul pentru acest lucru este neregulat, incomplet sau problematic pentru memorarea în cache în rețea.
Instrumente și introspecție
Ultimul lucru care le lipsește API-urilor REST sunt mecanismele de introspecție. Fără niciun contract cu informații despre tipurile de returnare sau structura unui punct final, nu există nicio modalitate de a genera documentație în mod fiabil, de a crea instrumente sau de a interacționa cu datele. Este posibil să lucrați în cadrul REST pentru a rezolva această problemă în diferite grade. Proiectele care implementează complet OpenAPI, OData sau JSON API sunt adesea curate, bine specificate și, în diferite măsuri, bine documentate, dar backend-urile ca acesta sunt rare. Chiar și Hypermedia, un fruct relativ scăzut, în ciuda faptului că a fost promovat la discuțiile conferinței de zeci de ani, încă nu este des făcut bine, dacă este deloc.
Concluzie
Fiecare dintre tipurile de API este defectuos, dar fiecare model este. Această scriere nu este o judecată a temeiului fenomenal pe care giganții din software le-au pus, doar pentru a fi o evaluare sobră a fiecăruia dintre aceste modele, aplicate în forma lor „pură” din perspectiva unui dezvoltator client. Sper că, în loc să ieși din această gândire, un tipar precum REST sau RPC este rupt, să poți scăpa gândindu-te la modul în care fiecare a făcut compromisuri și la domeniile în care o organizație de inginerie și-ar putea concentra eforturile pentru a-și îmbunătăți propriile API-uri .
În următorul articol, voi explora GraphQL și modul în care își propune să abordeze unele dintre problemele pe care le-am menționat mai sus. Inovația în GraphQL și instrumente similare este în nivelul lor de integrare și nu în implementarea lor. Vă rugăm, dacă dvs. sau echipa dvs. nu căutați un API „baterii incluse”, luați în considerare ceva de genul noii specificații OpenAPI care poate ajuta la construirea unei baze mai puternice astăzi!
Dacă ți-a plăcut acest articol (sau dacă l-ai urât) și vrei să-mi dai feedback, te rog să mă găsești pe Twitter ca @ebaerbaerbaer sau LinkedIn la ericjbaer.