
Coborâre gradient în regresia logistică [Explicat pentru începători]
Publicat: 2021-01-08În acest articol, vom discuta despre foarte popularul algoritm de coborâre a gradientului în regresia logistică. Ne vom uita la ceea ce este regresia logistică, apoi ne vom muta treptat drumul către ecuația pentru regresia logistică, funcția sa de cost și, în sfârșit, algoritmul de coborâre a gradientului.
Cuprins
Ce este regresia logistică?
Regresia logistică este pur și simplu un algoritm de clasificare utilizat pentru a prezice categorii discrete, cum ar fi prezicerea dacă un e-mail este „spam” sau „nu este spam”; prezicerea dacă o cifră dată este un „9” sau „nu 9” etc. Acum, privind numele, trebuie să vă gândiți, de ce este numită Regresie?
Motivul este că ideea de regresie logistică a fost dezvoltată prin modificarea câtorva elemente ale algoritmului de regresie liniară de bază utilizat în problemele de regresie.
Regresia logistică poate fi aplicată și problemelor de clasificare cu mai multe clase (mai mult de două clase). Deși, se recomandă utilizarea acestui algoritm numai pentru problemele de clasificare binară.
Funcția sigmoidă
Problemele de clasificare nu sunt probleme cu funcții liniare. Ieșirea este limitată la anumite valori discrete, de exemplu, 0 și 1 pentru o problemă de clasificare binară. Nu are sens ca o funcție liniară să prezică valorile noastre de ieșire mai mari decât 1 sau mai mici de 0. Deci avem nevoie de o funcție adecvată pentru a reprezenta valorile noastre de ieșire.
Funcția sigmoidă ne rezolvă problema. Cunoscută și sub denumirea de Funcție Logistică, este o funcție în formă de S care mapează orice număr cu valoare reală la intervalul (0,1), ceea ce o face foarte utilă în transformarea oricărei funcție aleatoare într-o funcție bazată pe clasificare. O funcție sigmoidă arată astfel:

Funcția sigmoidă
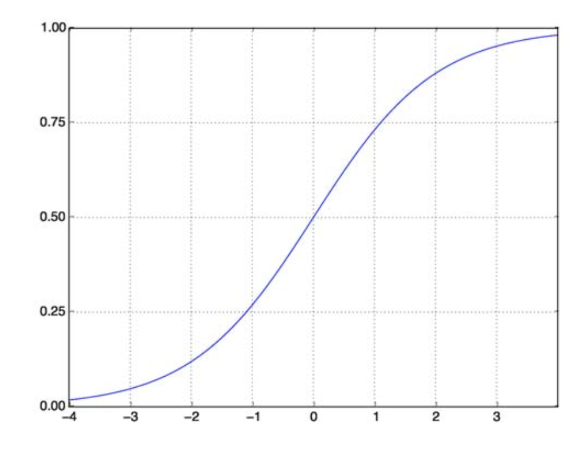
sursă
Acum forma matematică a funcției sigmoid pentru vectorul parametrizat și vectorul de intrare X este:
(z) = 11+exp(-z) unde z = TX
(z) ne va oferi probabilitatea ca rezultatul să fie 1. După cum știm cu toții, valoarea probabilității variază de la 0 la 1. Acum, aceasta nu este rezultatul pe care o dorim pentru problema noastră de clasificare bazată pe discrete (doar 0 și 1). . Deci acum putem compara probabilitatea prezisă cu 0,5. Dacă probabilitatea > 0,5, avem y=1. În mod similar, dacă probabilitatea este < 0,5, avem y=0.
Funcția de cost
Acum că avem predicțiile noastre discrete, este timpul să verificăm dacă predicțiile noastre sunt într-adevăr corecte sau nu. Pentru a face asta, avem o funcție de cost. Funcția de cost este doar însumarea tuturor erorilor făcute în predicții în întregul set de date. Desigur, nu putem folosi funcția de cost folosită în regresia liniară. Deci, noua funcție de cost pentru regresia logistică este:
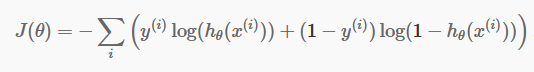 sursă
sursă
Nu vă fie frică de ecuație. Este foarte simplu. Pentru fiecare iterație i , se calculează eroarea pe care am făcut-o în predicția noastră și apoi se adună toate erorile pentru a defini funcția noastră de cost J().
Cei doi termeni din paranteză sunt de fapt pentru cele două cazuri: y=0 și y=1. Când y=0, primul termen dispare și ne rămâne doar al doilea termen. În mod similar, când y=1, al doilea termen dispare și ne rămâne doar primul termen.
Algoritmul de coborâre a gradientului
Am calculat cu succes funcția noastră de cost. Dar trebuie să minimizăm pierderea pentru a face un algoritm de predicție bun. Pentru a face asta, avem algoritmul de coborâre a gradientului.
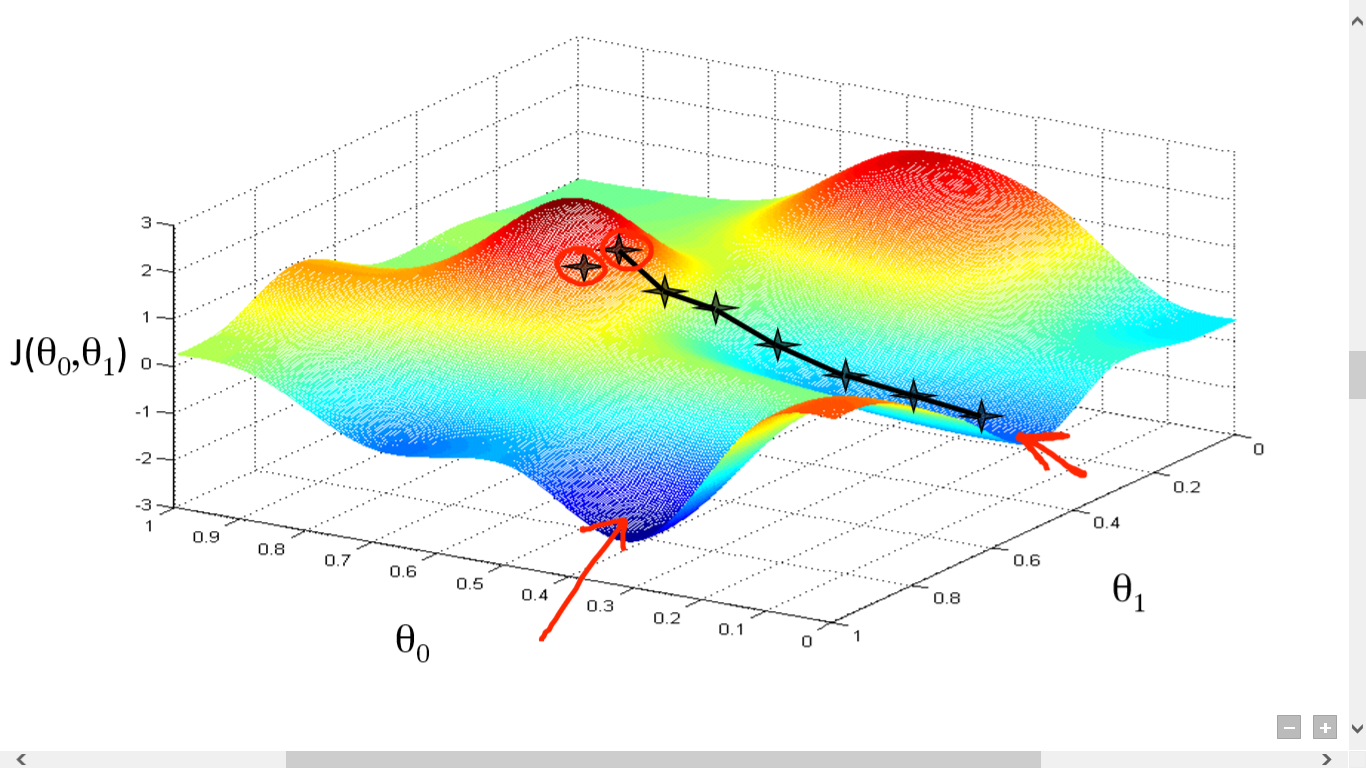 sursă
sursă
Aici am trasat un grafic între J() și . Obiectivul nostru este să găsim punctul cel mai profund (minimul global) al acestei funcții. Acum, punctul cel mai adânc este unde J() este minim.
Sunt necesare două lucruri pentru a găsi punctul cel mai profund:
- Derivată – pentru a găsi direcția pasului următor.
- (Rata de învățare) – magnitudinea pasului următor
Ideea este că mai întâi selectați orice punct aleatoriu din funcție. Apoi trebuie să calculați derivata lui J()wrt . Aceasta va indica direcția minimului local. Acum înmulțiți acel gradient rezultat cu rata de învățare. Rata de învățare nu are o valoare fixă și urmează să fie decisă în funcție de probleme.
Acum, trebuie să scădeți rezultatul din pentru a obține noul .
Această actualizare a ar trebui făcută simultan pentru fiecare (i) .
Faceți acești pași în mod repetat până când ajungeți la minimul local sau global. Prin atingerea minimului global, ați obținut cea mai mică pierdere posibilă în predicția dvs.
Luarea derivatelor este simplă. Doar calculul de bază pe care trebuie să le fi făcut în liceu este suficient. Problema majoră este rata de învățare ( ). Este important și adesea dificil să ai o rată bună de învățare.
Dacă luați o rată de învățare foarte mică, fiecare pas va fi prea mic și, prin urmare, veți lua mult timp pentru a atinge minimul local.

Acum, dacă ai tendința de a lua o valoare uriașă a ratei de învățare, vei depăși minimul și nu vei mai converge niciodată. Nu există o regulă specifică pentru rata perfectă de învățare.
Trebuie să-l modificați pentru a pregăti cel mai bun model.
Ecuația pentru coborârea gradientului este:
Repetați până la convergență:
Deci, putem rezuma algoritmul de coborâre a gradientului ca:
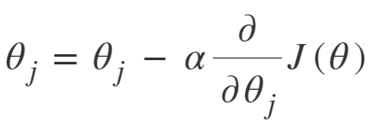
- Începeți cu aleatoriu
- Buclă până la convergență:
- Calculează Gradient
- Actualizați
- Întoarcere
Algoritmul de coborâre a gradientului stocastic
Acum, Gradient Descent Algorithm este un algoritm bun pentru reducerea la minimum a funcției de cost, în special pentru date mici și medii. Dar când trebuie să ne ocupăm de seturi de date mai mari, algoritmul de coborâre a gradientului se dovedește a fi lent în calcul. Motivul este simplu: trebuie să calculeze gradientul și să actualizeze valorile simultan pentru fiecare parametru și asta pentru fiecare exemplu de antrenament.
Așa că gândește-te la toate aceste calcule! Este masiv și, prin urmare, a fost nevoie de un algoritm de coborâre a gradientului ușor modificat, și anume – algoritmul de coborâre a gradientului stocastic (SGD).
Singura diferență pe care SGD o are cu coborârea normală a gradientului este că, în SGD, nu ne ocupăm de întreaga instanță de antrenament odată. În SGD, calculăm gradientul funcției de cost doar pentru un singur exemplu aleatoriu la fiecare iterație.
Acum, acest lucru reduce timpul necesar pentru calcule cu o marjă uriașă, în special pentru seturile de date mari. Calea parcursă de SGD este foarte întâmplătoare și zgomotoasă (deși o cale zgomotoasă ne poate oferi șansa de a atinge minimele globale).
Dar este în regulă, din moment ce nu trebuie să ne îngrijorăm cu privire la calea urmată.
Trebuie doar să ajungem la o pierdere minimă într-un timp mai rapid.
Deci, putem rezuma algoritmul de coborâre a gradientului ca:
- Buclă până la convergență:
- Alegeți un singur punct de date „ i”
- Calculați Gradient peste acel singur punct
- Actualizați
- Întoarcere
Algoritm de coborâre cu gradient mini-loc
Mini-Batch Gradient Descent este o altă modificare ușoară a algoritmului Gradient Descent. Este oarecum între Coborârea Gradient Normal și Coborâre Gradient Stochastic.
Mini-Batch Gradient Descent preia doar un lot mai mic din întregul set de date și apoi minimizează pierderea pe acesta.
Acest proces este mai eficient decât cei doi algoritmi de coborâre a gradientului de mai sus. Acum, dimensiunea lotului poate fi, desigur, orice doriți.
Dar cercetătorii au arătat că este mai bine dacă îl mențineți între 1 și 100, 32 fiind cea mai bună dimensiune a lotului.
Prin urmare, dimensiunea lotului = 32 este păstrată implicit în majoritatea cadrelor.
- Buclă până la convergență:
- Alegeți un lot de puncte de date „ b ”.
- Calculați Gradient peste acel lot
- Actualizați
- Întoarcere
Concluzie
Acum aveți înțelegerea teoretică a regresiei logistice. Ați învățat cum să reprezentați matematic funcția logistică. Știți cum să măsurați eroarea prezisă folosind funcția Cost.
De asemenea, știți cum puteți minimiza această pierdere folosind algoritmul de coborâre a gradului.
În cele din urmă, știți ce variație a algoritmului de coborâre a gradientului ar trebui să alegeți pentru problema dvs. upGrad oferă o diplomă PG în Machine Learning și AI și un Master of Science în Machine Learning și AI, care vă poate ghida spre construirea unei cariere. Aceste cursuri vor explica necesitatea învățării automate și pașii suplimentari pentru a aduna cunoștințe în acest domeniu, acoperind concepte variate, de la algoritmi de coborâre a gradientului la rețele neuronale.
Ce este un algoritm de coborâre a gradientului?
Coborârea gradientului este un algoritm de optimizare pentru găsirea minimului unei funcții. Să presupunem că doriți să găsiți minimul unei funcții f(x) între două puncte (a, b) și (c, d) pe graficul lui y = f(x). Apoi coborârea gradientului implică trei pași: (1) alegeți un punct la mijloc între două puncte finale, (2) calculați gradientul ∇f(x) (3) deplasați-vă în direcția opusă gradientului, adică de la (c, d) la (a, b). Modul de a gândi la acest lucru este că algoritmul află panta funcției într-un punct și apoi se deplasează în direcția opusă pantei.
Ce este funcția sigmoidă?
Funcția sigmoidă, sau curba sigmoidă, este un tip de funcție matematică care este neliniară și foarte asemănătoare ca formă cu litera S (de unde și numele). Este folosit în cercetarea operațională, statistică și alte discipline pentru a modela anumite forme de creștere cu valoare reală. De asemenea, este utilizat într-o gamă largă de aplicații în informatică și inginerie, în special în domenii legate de rețelele neuronale și inteligența artificială. Funcțiile sigmoide sunt utilizate ca parte a intrărilor la algoritmii de învățare de întărire, care se bazează pe rețele neuronale artificiale.
Ce este algoritmul de coborâre a gradientului stocastic?
Stochastic Gradient Descent este una dintre variațiile populare ale algoritmului clasic Gradient Descent pentru a găsi minimele locale ale funcției. Algoritmul alege aleatoriu direcția în care va merge următoarea funcție pentru a minimiza valoarea și direcția se repetă până când se atinge un minim local. Obiectivul este ca, prin repetarea continuă a acestui proces, algoritmul va converge către minimul global sau local al funcției.