
Lista de verificare a performanței front-end 2021 (PDF, pagini Apple, MS Word)
Publicat: 2022-03-10Acest ghid a fost susținut cu amabilitate de prietenii noștri de la LogRocket, un serviciu care combină monitorizarea performanței frontend , redarea sesiunii și analiza produselor pentru a vă ajuta să construiți experiențe mai bune pentru clienți. LogRocket urmărește valorile cheie, inclusiv. DOM finalizat, timpul până la primul octet, prima întârziere de intrare, CPU client și utilizarea memoriei. Obțineți o încercare gratuită a LogRocket astăzi.

Performanța web este o fiară dificilă, nu-i așa? Cum știm de fapt unde ne aflăm în ceea ce privește performanța și care sunt exact blocajele noastre de performanță? Este JavaScript scump, livrarea lentă a fonturilor web, imaginile grele sau randarea lenta? Ne-am optimizat suficient cu scuturarea copacilor, ridicarea lunetei, împărțirea codului și toate modelele de încărcare fanteziste cu observator de intersecție, hidratare progresivă, sugestii pentru clienți, HTTP/3, lucrători de servicii și - oh, - lucrători de margine? Și, cel mai important, de unde începem chiar să îmbunătățim performanța și cum stabilim o cultură a performanței pe termen lung?
Pe vremuri, performanța era adesea o simplă gândire ulterioară . Amânat adesea până la sfârșitul proiectului, se reduce la minificare, concatenare, optimizare a activelor și, eventual, câteva ajustări fine ale fișierului de config al serverului. Privind în urmă acum, lucrurile par să se fi schimbat destul de semnificativ.
Performanța nu este doar o preocupare tehnică: afectează totul, de la accesibilitate la uzabilitate până la optimizarea motoarelor de căutare, iar atunci când o includeți în fluxul de lucru, deciziile de proiectare trebuie să fie informate de implicațiile lor de performanță. Performanța trebuie măsurată, monitorizată și perfecționată în mod continuu , iar complexitatea tot mai mare a web-ului ridică noi provocări care fac dificilă urmărirea valorilor, deoarece datele vor varia semnificativ în funcție de dispozitiv, browser, protocol, tip de rețea și latență ( CDN-urile, ISP-urile, cache-urile, proxy-urile, firewall-urile, echilibrarea încărcăturii și serverele joacă toate un rol în performanță).
Deci, dacă am crea o privire de ansamblu asupra tuturor lucrurilor pe care trebuie să le ținem cont atunci când îmbunătățim performanța — de la începutul proiectului până la lansarea finală a site-ului web — cum ar arăta? Mai jos veți găsi o listă de verificare a performanței front-end (sperăm că nepărtinitoare și obiectivă) pentru 2021 — o privire de ansamblu actualizată a problemelor pe care ar trebui să le luați în considerare pentru a vă asigura că timpii de răspuns sunt rapid, că interacțiunea utilizatorului este fluidă și site-urile dvs. nu. scurgeți lățimea de bandă a utilizatorului.
Cuprins
- Toate pe pagini separate
- Pregătirea: planificare și valori
Cultura performanței, Core Web Vitals, profile de performanță, CrUX, Lighthouse, FID, TTI, CLS, dispozitive. - Stabilirea obiectivelor realiste
Bugete de performanță, obiective de performanță, cadru RAIL, bugete 170KB/30KB. - Definirea Mediului
Alegerea unui cadru, costul de performanță de bază, Webpack, dependențe, CDN, arhitectură front-end, CSR, SSR, CSR + SSR, randare statică, prerandare, model PRPL. - Optimizări ale activelor
Brotli, AVIF, WebP, imagini responsive, AV1, încărcare media adaptivă, compresie video, fonturi web, fonturi Google. - Construiți optimizări
Module JavaScript, model de modul/modulul, tree-shaking, cod-divizare, scope-hoisting, Webpack, servire diferențială, web worker, WebAssembly, pachete JavaScript, React, SPA, hidratare parțială, import la interacțiune, terțe părți, cache. - Optimizări de livrare
Încărcare leneșă, observator de intersecție, amânare redare și decodare, CSS critic, streaming, indicii de resurse, schimbări de aspect, lucrător de service. - Rețea, HTTP/2, HTTP/3
Capsare OCSP, certificate EV/DV, ambalare, IPv6, QUIC, HTTP/3. - Testare și monitorizare
Flux de lucru de audit, browsere proxy, pagină 404, solicitări de consimțământ cookie GDPR, diagnosticare performanță CSS, accesibilitate. - Victorii rapide
- Descărcați Lista de verificare (PDF, Apple Pages, MS Word)
- Plecăm!
(Puteți, de asemenea, să descărcați lista de verificare PDF (166 KB) sau să descărcați fișierul Apple Pages editabil (275 KB) sau fișierul .docx (151 KB). Optimizare fericită tuturor!)
Pregătirea: planificare și valori
Micro-optimizările sunt excelente pentru a menține performanța pe drumul cel bun, dar este esențial să aveți în vedere obiective clar definite - obiective măsurabile care ar influența orice decizie luată pe parcursul procesului. Există câteva modele diferite, iar cele discutate mai jos sunt destul de opinie - asigurați-vă că vă setați propriile priorități devreme.
- Stabiliți o cultură a performanței.
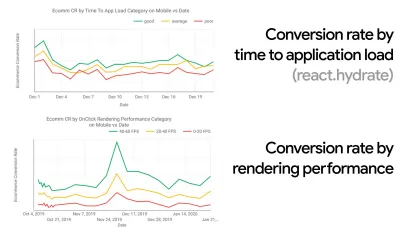
În multe organizații, dezvoltatorii front-end știu exact care sunt problemele de bază comune și ce strategii ar trebui folosite pentru a le remedia. Totuși, atâta timp cât nu există o susținere stabilită a culturii performanței, fiecare decizie se va transforma într-un câmp de luptă al departamentelor, rupând organizația în silozuri. Aveți nevoie de acceptarea părților interesate de afaceri și, pentru a o obține, trebuie să stabiliți un studiu de caz sau o dovadă a conceptului asupra modului în care viteza - în special Core Web Vitals , pe care le vom acoperi în detaliu mai târziu - metrici de beneficii și indicatori cheie de performanță ( KPI ) de care le pasă.De exemplu, pentru a face performanța mai tangibilă, puteți expune impactul asupra performanței veniturilor arătând corelația dintre rata de conversie și timpul până la încărcarea aplicației, precum și performanța redării. Sau rata de accesare cu crawlere a robotului de căutare (PDF, paginile 27–50).
Fără o aliniere puternică între echipele de dezvoltare/design și afaceri/marketing, performanța nu se va menține pe termen lung. Studiați reclamațiile frecvente care vin în echipa de servicii pentru clienți și de vânzări, studiați analizele pentru rate mari de respingere și scăderi de conversie. Explorați cum îmbunătățirea performanței poate ajuta la ameliorarea unora dintre aceste probleme comune. Ajustați argumentul în funcție de grupul de părți interesate cu care vorbiți.
Rulați experimente de performanță și măsurați rezultatele — atât pe mobil, cât și pe desktop (de exemplu, cu Google Analytics). Vă va ajuta să construiți un studiu de caz personalizat pentru companie, cu date reale. În plus, utilizarea datelor din studiile de caz și experimentele publicate pe WPO Stats va contribui la creșterea sensibilității afacerilor cu privire la motivul pentru care performanța contează și ce impact are asupra experienței utilizatorilor și a valorilor de afaceri. Afirmarea că performanța contează singură nu este suficientă – trebuie, de asemenea, să stabiliți niște obiective măsurabile și urmăribile și să le respectați în timp.
Cum să ajungem acolo? În discursul său despre Construirea performanței pe termen lung, Allison McKnight împărtășește un studiu de caz cuprinzător despre modul în care a contribuit la stabilirea unei culturi a performanței la Etsy (diapozitive). Mai recent, Tammy Everts a vorbit despre obiceiurile echipelor de performanță extrem de eficiente atât în organizațiile mici, cât și în cele mari.
În timp ce aveți aceste conversații în organizații, este important să rețineți că, așa cum UX este un spectru de experiențe, performanța web este o distribuție. După cum a remarcat Karolina Szczur, „a aștepta ca un singur număr să poată oferi un rating la care să aspirați este o presupunere greșită”. Prin urmare, obiectivele de performanță trebuie să fie granulare, urmăribile și tangibile.
- Obiectiv: Fii cu cel puțin 20% mai rapid decât cel mai rapid concurent al tău.
Conform cercetărilor psihologice, dacă vrei ca utilizatorii să simtă că site-ul tău web este mai rapid decât site-ul concurentului tău, trebuie să fii cu cel puțin 20% mai rapid. Studiază-ți principalii concurenți, colectează valori despre performanța acestora pe dispozitive mobile și desktop și stabilește praguri care te-ar ajuta să-i depășești. Totuși, pentru a obține rezultate și obiective precise, asigurați-vă că aveți mai întâi o imagine detaliată a experienței utilizatorilor dvs., studiindu-vă analizele. Apoi puteți imita experiența percentilei 90 pentru testare.Pentru a obține o primă impresie bună despre performanțele concurenților dvs., puteți utiliza Chrome UX Report ( CrUX , un set de date RUM gata făcut, introducere video de Ilya Grigorik și ghid detaliat de Rick Viscomi) sau Treo, un instrument de monitorizare RUM care este alimentat de Chrome UX Report. Datele sunt adunate de la utilizatorii browserului Chrome, astfel încât rapoartele vor fi specifice Chrome, dar vă vor oferi o distribuție destul de amănunțită a performanței, cel mai important scoruri Core Web Vitals, pentru o gamă largă de vizitatori. Rețineți că noile seturi de date CrUX sunt lansate în a doua zi de marți a fiecărei luni .
Alternativ, puteți utiliza și:
- Instrumentul de comparare a rapoartelor Chrome UX al lui Addy Osmani,
- Speed Scorecard (oferă și un estimator de impact asupra veniturilor),
- Comparație cu testele experienței utilizatorului real sau
- SiteSpeed CI (bazat pe teste sintetice).
Notă : dacă utilizați Page Speed Insights sau API-ul Page Speed Insights (nu, nu este depreciat!), puteți obține date de performanță CrUX pentru anumite pagini în loc de doar agregate. Aceste date pot fi mult mai utile pentru stabilirea obiectivelor de performanță pentru elemente precum „pagina de destinație” sau „lista de produse”. Și dacă utilizați CI pentru a testa bugetele, trebuie să vă asigurați că mediul dvs. testat se potrivește cu CrUX dacă ați folosit CrUX pentru setarea țintei ( mulțumesc Patrick Meenan! ).
Dacă aveți nevoie de ajutor pentru a arăta raționamentul din spatele prioritizării vitezei sau doriți să vizualizați scăderea ratei de conversie sau creșterea ratei de respingere cu o performanță mai lentă sau poate că ar trebui să susțineți o soluție RUM în organizația dvs., Sergey Chernyshev a construit un Calculator de viteză UX, un instrument open-source care vă ajută să simulați datele și să le vizualizați pentru a vă informa.
CrUX generează o imagine de ansamblu asupra distribuțiilor de performanță în timp, cu trafic colectat de la utilizatorii Google Chrome. Puteți să vă creați propria dvs. în Chrome UX Dashboard. (Previzualizare mare) 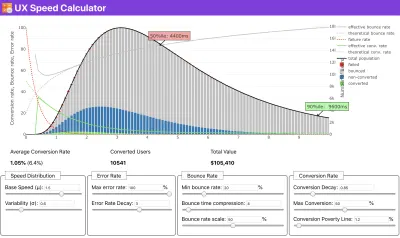
Exact atunci când trebuie să argumentați ca performanța să vă aducă punctul de vedere: Calculatorul de viteză UX vizualizează impactul performanței asupra ratelor de respingere, a conversiilor și a veniturilor totale – pe baza datelor reale. (Previzualizare mare) Uneori, s-ar putea să doriți să mergeți mai profund, combinând datele care provin de la CrUX cu orice alte date pe care le aveți deja pentru a afla rapid unde se află încetinirile, punctele oarbe și ineficiențele - pentru concurenții dvs. sau pentru proiectul dvs. În munca sa, Harry Roberts a folosit o foaie de calcul pentru topografia vitezei site-ului pe care o folosește pentru a defalca performanța în funcție de tipurile de pagini cheie și pentru a urmări cât de diferite sunt valorile cheie pe acestea. Puteți descărca foaia de calcul ca Foi de calcul Google, Excel, document OpenOffice sau CSV.
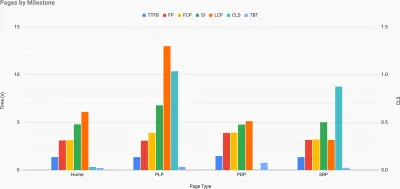
Topografia vitezei site-ului, cu valori cheie reprezentate pentru paginile cheie de pe site. (Previzualizare mare) Și dacă doriți să mergeți până la capăt, puteți rula un audit de performanță Lighthouse pe fiecare pagină a unui site (prin Lightouse Parade), cu o ieșire salvată ca CSV. Acest lucru vă va ajuta să identificați ce pagini specifice (sau tipuri de pagini) ale concurenților dvs. au performanțe mai slabe sau mai bune și pe ce ați putea dori să vă concentrați eforturile. (Pentru propriul site, probabil că este mai bine să trimiteți date către un punct final de analiză!).

Cu Lighthouse Parade, puteți rula un audit de performanță Lighthouse pe fiecare pagină a unui site, cu o ieșire salvată ca CSV. (Previzualizare mare) Colectați date, configurați o foaie de calcul, reduceți cu 20% și stabiliți-vă obiectivele ( bugetele de performanță ) în acest fel. Acum aveți ceva măsurabil cu care să testați. Dacă țineți cont de buget și încercați să expediați doar sarcina utilă minimă pentru a obține un timp rapid de interactiv, atunci sunteți pe o cale rezonabilă.
Ai nevoie de resurse pentru a începe?
- Addy Osmani a scris un articol foarte detaliat despre cum să începeți bugetul de performanță, cum să cuantificați impactul noilor funcții și de unde să începeți când depășiți bugetul.
- Ghidul Larei Hogan despre cum să abordați design-urile cu un buget de performanță poate oferi indicații utile designerilor.
- Harry Roberts a publicat un ghid despre configurarea unei foi Google pentru a afișa impactul scripturilor terțe asupra performanței, folosind Request Map,
- Calculatorul de buget de performanță al lui Jonathan Fielding, calculatorul de buget de performanță al lui Katie Hempenius și Caloriile din browser pot ajuta la crearea bugetelor (mulțumesc Karolinei Szczur pentru informare).
- În multe companii, bugetele de performanță nu ar trebui să fie aspiraționale, ci mai degrabă pragmatice, servind drept semn de reținere pentru a evita alunecarea peste un anumit punct. În acest caz, puteți alege cel mai prost punct de date din ultimele două săptămâni ca prag și îl puteți lua de acolo. Bugetele de performanță, vă arată pragmatic o strategie pentru a realiza asta.
- De asemenea, faceți vizibile atât bugetul de performanță, cât și performanța actuală prin configurarea tablourilor de bord cu grafice care raportează dimensiunile construcției. Există multe instrumente care vă permit să realizați acest lucru: tabloul de bord SiteSpeed.io (sursă deschisă), SpeedCurve și Caliber sunt doar câteva dintre ele și puteți găsi mai multe instrumente pe perf.rocks.

Browser Calories vă ajută să setați un buget de performanță și să măsurați dacă o pagină depășește sau nu aceste cifre. (Previzualizare mare) Odată ce aveți un buget stabilit, încorporați-le în procesul dvs. de construire cu Webpack Performance Hints and Bundlesize, Lighthouse CI, PWMetrics sau Sitespeed CI pentru a aplica bugetele la solicitările de extragere și pentru a oferi un istoric al scorului în comentariile PR.
Pentru a expune bugetele de performanță întregii echipe, integrați bugetele de performanță în Lighthouse prin Lightwallet sau utilizați LHCI Action pentru o integrare rapidă a Github Actions. Și dacă aveți nevoie de ceva personalizat, puteți utiliza webpagetest-charts-api, un API de puncte finale pentru a crea diagrame din rezultatele WebPagetest.
Conștientizarea performanței nu ar trebui să provină doar din bugetele de performanță. La fel ca Pinterest, ați putea crea o regulă eslint personalizată care să nu permită importul din fișiere și directoare despre care se știe că sunt grele de dependență și care ar întinde pachetul. Creați o listă de pachete „sigure” care pot fi partajate întregii echipe.
De asemenea, gândiți-vă la sarcinile critice ale clienților care sunt cele mai benefice pentru afacerea dvs. Studiați, discutați și definiți praguri de timp acceptabile pentru acțiunile critice și stabiliți marcajele de sincronizare a utilizatorului „UX ready” pe care întreaga organizație le-a aprobat. În multe cazuri, călătoriile utilizatorilor vor afecta munca multor departamente diferite, astfel încât alinierea în termeni de timpi acceptabili va ajuta la sprijinirea sau prevenirea discuțiilor de performanță pe viitor. Asigurați-vă că costurile suplimentare ale resurselor și caracteristicilor adăugate sunt vizibile și înțelese.
Aliniați eforturile de performanță cu alte inițiative tehnologice, variind de la noile caracteristici ale produsului în curs de construire la refactorizare până la atingerea unor noi audiențe globale. Deci, de fiecare dată când are loc o conversație despre dezvoltarea ulterioară, performanța este și ea o parte a acelei conversații. Este mult mai ușor să atingeți obiectivele de performanță atunci când baza de cod este proaspătă sau este doar refactorizată.
De asemenea, așa cum a sugerat Patrick Meenan, merită să planificați o secvență de încărcare și compromisuri în timpul procesului de proiectare. Dacă prioritizați din timp ce părți sunt mai critice și definiți ordinea în care ar trebui să apară, veți ști și ce poate fi amânat. În mod ideal, acea ordine va reflecta și secvența importurilor dvs. CSS și JavaScript, astfel încât gestionarea acestora în timpul procesului de construire va fi mai ușoară. De asemenea, luați în considerare ce experiență vizuală ar trebui să fie în stările „între”, în timp ce pagina este încărcată (de exemplu, când fonturile web nu sunt încă încărcate).
Odată ce ați stabilit o cultură puternică a performanței în organizația dvs., urmăriți să fiți cu 20% mai rapid decât fostul dvs. pentru a păstra prioritățile în tact pe măsură ce timpul trece ( mulțumesc, Guy Podjarny! ). Dar luați în considerare diferitele tipuri și comportamente de utilizare ale clienților dvs. (pe care Tobias Baldauf le-a numit cadență și cohorte), împreună cu traficul de bot și efectele sezoniere.
Planificare, planificare, planificare. S-ar putea să fie tentant să intri în niște optimizări rapide de „fructe care nu se așteaptă” devreme – și ar putea fi o strategie bună pentru câștiguri rapide – dar va fi foarte greu să păstrezi performanța o prioritate fără planificarea și stabilirea unei companii realiste. -obiective de performanță personalizate.
- Alegeți valorile potrivite.
Nu toate valorile sunt la fel de importante. Studiați ce valori contează cel mai mult pentru aplicația dvs.: de obicei, va fi definit de cât de repede puteți începe să redați cei mai importanți pixeli ai interfeței dvs. și cât de repede puteți oferi răspuns la intrare pentru acești pixeli randați. Aceste cunoștințe vă vor oferi cea mai bună țintă de optimizare pentru eforturile continue. În cele din urmă, nu evenimentele de încărcare sau timpii de răspuns ale serverului definesc experiența, ci percepția asupra cât de rapidă se simte interfața.Ce înseamnă? În loc să vă concentrați asupra timpului de încărcare a paginii întregi (prin timpii onLoad și DOMContentLoaded , de exemplu), acordați prioritate încărcării paginii așa cum este perceput de clienții dvs. Asta înseamnă să te concentrezi pe un set ușor diferit de valori. De fapt, alegerea valorii potrivite este un proces fără câștigători vădiți.
Pe baza cercetărilor lui Tim Kadlec și a notelor lui Marcos Iglesias din discursul său, valorile tradiționale ar putea fi grupate în câteva seturi. De obicei, vom avea nevoie de toate pentru a obține o imagine completă a performanței și, în cazul dvs., unele dintre ele vor fi mai importante decât altele.
- Valorile bazate pe cantitate măsoară numărul de solicitări, greutatea și un scor de performanță. Bun pentru a trage alarme și pentru a monitoriza schimbările în timp, nu atât de bun pentru a înțelege experiența utilizatorului.
- Valorile de referință folosesc stări pe durata de viață a procesului de încărcare, de exemplu, Time To First Byte și Time To Interactive . Bun pentru a descrie experiența utilizatorului și monitorizare, nu atât de bun pentru a ști ce se întâmplă între etape.
- Valorile de randare oferă o estimare a cât de repede este redat conținutul (de exemplu, timpul de pornire a redării, indicele de viteză ). Bun pentru măsurarea și ajustarea performanței de randare, dar nu atât de bun pentru a măsura când apare conținut important și cu care poate fi interacționat.
- Valorile personalizate măsoară un anumit eveniment personalizat pentru utilizator, de exemplu Time To First Tweet de la Twitter și PinnerWaitTime de la Pinterest. Bun pentru a descrie experiența utilizatorului cu precizie, nu atât de bun pentru a scala valorile și a compara cu concurenții.
Pentru a completa imaginea, am căuta de obicei valori utile pentru toate aceste grupuri. De obicei, cele mai specifice și relevante sunt:
- Time to Interactive (TTI)
Punctul în care aspectul s-a stabilizat , fonturile web cheie sunt vizibile, iar firul principal este suficient de disponibil pentru a gestiona intrarea utilizatorului - practic marca de timp în care un utilizator poate interacționa cu interfața de utilizare. Valorile cheie pentru a înțelege cât de mult trebuie să treacă un utilizator pentru a utiliza site-ul fără întârziere. Boris Schapira a scris o postare detaliată despre cum să măsurați în mod fiabil TTI. - Întârzierea primei intrări (FID) sau capacitatea de răspuns la intrare
Perioada de la momentul în care un utilizator interacționează pentru prima dată cu site-ul dvs. și până la momentul în care browserul este capabil să răspundă la acea interacțiune. Complementează foarte bine TTI, deoarece descrie partea lipsă a imaginii: ce se întâmplă atunci când un utilizator interacționează efectiv cu site-ul. Destinat numai ca valoare RUM. Există o bibliotecă JavaScript pentru măsurarea FID în browser. - Cea mai mare vopsea plină de conținut (LCP)
Marchează punctul din cronologia de încărcare a paginii în care probabil că s-a încărcat conținutul important al paginii. Presupunerea este că cel mai important element al paginii este cel mai mare vizibil în fereastra utilizatorului. Dacă elementele sunt redate atât deasupra cât și dedesubtul pliului, doar partea vizibilă este considerată relevantă. - Timp total de blocare ( TBT )
O valoare care ajută la cuantificarea gradului de neinteractivitate a unei pagini înainte ca aceasta să devină interactivă în mod fiabil (adică firul principal a fost liber de orice sarcini care rulează peste 50 ms ( sarcini lungi ) timp de cel puțin 5 secunde). Valoarea măsoară intervalul total de timp dintre prima vopsea și Time to Interactive (TTI) în care firul principal a fost blocat suficient de mult pentru a preveni receptivitatea la intrare. Nu e de mirare, așadar, că un TBT scăzut este un indicator bun pentru o performanță bună. (mulțumesc, Artem, Phil) - Schimbare cumulativă a aspectului ( CLS )
Valoarea evidențiază cât de des se confruntă utilizatorii schimbări neașteptate de aspect ( refluxuri ) atunci când accesează site-ul. Acesta examinează elementele instabile și impactul acestora asupra experienței generale. Cu cât scorul este mai mic, cu atât mai bine. - Indicele de viteză
Măsoară cât de repede este populat vizual conținutul paginii; cu cât scorul este mai mic, cu atât mai bine. Scorul Speed Index este calculat pe baza vitezei de progres vizual , dar este doar o valoare calculată. Este, de asemenea, sensibil la dimensiunea ferestrei de vizualizare, așa că trebuie să definiți o serie de configurații de testare care se potrivesc cu publicul țintă. Rețineți că devine din ce în ce mai puțin important, LCP devenind o măsură mai relevantă ( mulțumesc, Boris, Artem! ). - Timp CPU petrecut
O valoare care arată cât de des și cât de mult este blocat firul principal, lucrând la pictare, randare, scriptare și încărcare. Timpul ridicat al procesorului este un indicator clar al unei experiențe neplăcute , adică atunci când utilizatorul se confruntă cu un decalaj vizibil între acțiunea sa și un răspuns. Cu WebPageTest, puteți selecta „Capture Dev Tools Timeline” din fila „Chrome” pentru a expune defalcarea firului principal, așa cum rulează pe orice dispozitiv care utilizează WebPageTest. - Costuri CPU la nivel de componente
La fel ca în cazul timpului petrecut al procesorului , această măsurătoare, propusă de Stoyan Stefanov, explorează impactul JavaScript asupra procesorului . Ideea este să folosiți numărul de instrucțiuni CPU pe componentă pentru a înțelege impactul acestuia asupra experienței generale, în mod izolat. Ar putea fi implementat folosind Puppeteer și Chrome. - FrustrationIndex
În timp ce multe valori prezentate mai sus explică când are loc un anumit eveniment, FrustrationIndex al lui Tim Vereecke analizează decalajele dintre valori în loc să le analizeze individual. Se uită la reperele cheie percepute de utilizatorul final, cum ar fi Titlul este vizibil, Primul conținut este vizibil, Pregătit vizual și Pagina pare pregătită și calculează un scor care indică nivelul de frustrare în timpul încărcării unei pagini. Cu cât decalajul este mai mare, cu atât este mai mare șansa ca un utilizator să fie frustrat. Potențial un KPI bun pentru experiența utilizatorului. Tim a publicat o postare detaliată despre FrustrationIndex și cum funcționează. - Impactul ponderii reclamelor
Dacă site-ul dvs. depinde de veniturile generate de publicitate, este util să urmăriți ponderea codului legat de anunțuri. Scriptul lui Paddy Ganti construiește două adrese URL (una normală și una care blochează reclamele), solicită generarea unei comparații video prin WebPageTest și raportează o deltă. - Valori de abatere
După cum au remarcat inginerii Wikipedia, datele despre cât de multă variație există în rezultatele dvs. ar putea să vă informeze cât de fiabile sunt instrumentele dvs. și cât de multă atenție ar trebui să acordați abateri și valori externe. Varianta mare este un indicator al ajustărilor necesare în configurație. De asemenea, ajută la înțelegerea dacă anumite pagini sunt mai dificil de măsurat în mod fiabil, de exemplu din cauza scripturilor terță parte care provoacă variații semnificative. De asemenea, ar putea fi o idee bună să urmăriți versiunea browserului pentru a înțelege creșterile de performanță atunci când este lansată o nouă versiune de browser. - Valori personalizate
Valorile personalizate sunt definite de nevoile dvs. de afaceri și de experiența clienților. Este necesar să identificați pixeli importanți , scripturi critice , CSS necesare și active relevante și să măsurați cât de repede sunt livrați utilizatorului. Pentru aceasta, puteți monitoriza Hero Rendering Times sau utiliza Performance API, marcând anumite marcaje temporale pentru evenimentele care sunt importante pentru afacerea dvs. De asemenea, puteți colecta valori personalizate cu WebPagetest executând JavaScript arbitrar la sfârșitul unui test.
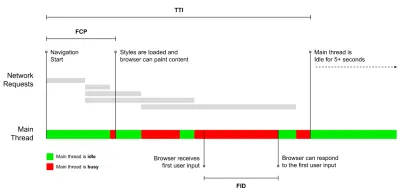
Rețineți că First Meaningful Paint (FMP) nu apare în prezentarea de mai sus. Obișnuia să ofere o perspectivă asupra cât de repede serverul scoate orice date. FMP lung a indicat de obicei JavaScript blocarea firului principal, dar ar putea fi legat și de probleme de back-end/server. Cu toate acestea, valoarea a fost retrasă recent, deoarece pare să nu fie exactă în aproximativ 20% din cazuri. A fost înlocuit efectiv cu LCP, care este atât mai fiabil, cât și mai ușor de raționat. Nu mai este acceptat în Lighthouse. Verificați cele mai recente valori și recomandări de performanță centrate pe utilizator doar pentru a vă asigura că vă aflați pe pagina sigură ( mulțumesc, Patrick Meenan ).
Steve Souders are o explicație detaliată a multora dintre aceste valori. Este important de observat că, în timp ce Time-To-Interactive este măsurat prin rularea de audituri automate în așa-numitul mediu de laborator , First Input Delay reprezintă experiența reală a utilizatorului, utilizatorii reali întâmpinând o întârziere vizibilă. În general, probabil că este o idee bună să le măsurați și să urmăriți întotdeauna ambele.
În funcție de contextul aplicației dvs., valorile preferate pot diferi: de exemplu, pentru Netflix TV UI, răspunsul la introducerea tastelor, utilizarea memoriei și TTI sunt mai critice, iar pentru Wikipedia, primele/ultimele modificări vizuale și valorile privind timpul petrecut CPU sunt mai importante.
Notă : atât FID, cât și TTI nu țin cont de comportamentul de defilare; defilarea se poate întâmpla independent, deoarece este în afara firului principal, așa că pentru multe site-uri de consum de conținut, aceste valori ar putea fi mult mai puțin importante ( mulțumesc, Patrick! ).
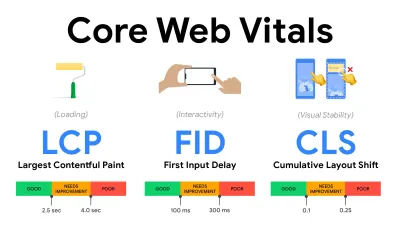
- Măsurați și optimizați Core Web Vitals .
Pentru o lungă perioadă de timp, valorile de performanță au fost destul de tehnice, concentrându-se pe vizualizarea de inginerie a cât de repede răspund serverele și cât de rapide sunt browserele la încărcare. Valorile s-au schimbat de-a lungul anilor - încercând să găsească o modalitate de a captura experiența reală a utilizatorului, mai degrabă decât timpul de timp al serverului. În mai 2020, Google a anunțat Core Web Vitals, un set de noi valori de performanță axate pe utilizator, fiecare reprezentând o fațetă distinctă a experienței utilizatorului.Pentru fiecare dintre ele, Google recomandă o serie de obiective de viteză acceptabile. Cel puțin 75% din toate vizualizările de pagină ar trebui să depășească intervalul Bun pentru a trece această evaluare. Aceste valori au câștigat rapid acțiune și, având în vedere că Core Web Vitals devenind semnale de clasare pentru Căutarea Google în mai 2021 ( actualizarea algoritmului de clasificare a experienței paginii ), multe companii și-au îndreptat atenția către scorurile lor de performanță.
Să defalcăm fiecare dintre elementele vitale de bază ale web, unul câte unul, împreună cu tehnici și instrumente utile pentru a vă optimiza experiențele ținând cont de aceste valori. (Este de remarcat faptul că veți obține scoruri mai bune Core Web Vitals urmând un sfat general din acest articol.)
- Cea mai mare vopsea cu conținut maxim ( LCP ) < 2,5 sec.
Măsoară încărcarea unei pagini și raportează timpul de randare al celui mai mare bloc de imagine sau text care este vizibil în fereastra de vizualizare. Prin urmare, LCP este afectat de tot ceea ce amână redarea informațiilor importante - fie că este vorba despre timpii de răspuns lenți ai serverului, blocarea CSS, JavaScript în timpul zborului (primă parte sau terță parte), încărcarea fonturilor web, operațiunile costisitoare de redare sau pictare, leneș. -imagini încărcate, ecrane schelet sau randare pe partea clientului.
Pentru o experiență bună, LCP ar trebui să apară în 2,5 secunde de când pagina începe pentru prima dată să se încarce. Aceasta înseamnă că trebuie să redăm prima porțiune vizibilă a paginii cât mai devreme posibil. Acest lucru va necesita CSS critic personalizat pentru fiecare șablon, orchestrarea ordinii<head>și preluarea prealabilă a activelor critice (le vom acoperi mai târziu).Motivul principal pentru un scor LCP scăzut sunt de obicei imaginile. Pentru a livra un LCP în <2,5 secunde pe Fast 3G - găzduit pe un server bine optimizat, totul static fără randare pe partea clientului și cu o imagine care provine de la un CDN de imagine dedicat - înseamnă că dimensiunea maximă teoretică a imaginii este de numai aproximativ 144KB . De aceea, imaginile receptive contează, precum și preîncărcarea timpurie a imaginilor critice (cu
preload).Sfat rapid : pentru a descoperi ceea ce este considerat LCP pe o pagină, în DevTools puteți trece cu mouse-ul peste insigna LCP sub „Timings” din Panoul de performanță ( mulțumesc, Tim Kadlec !).
- Întârziere la prima intrare ( FID ) < 100 ms.
Măsoară capacitatea de răspuns a interfeței de utilizare, adică cât timp browserul a fost ocupat cu alte sarcini înainte de a putea reacționa la un eveniment discret de intrare de utilizator, cum ar fi o atingere sau un clic. Este conceput pentru a capta întârzierile care rezultă din faptul că firul principal este ocupat, în special în timpul încărcării paginii.
Scopul este de a rămâne în interval de 50–100 ms pentru fiecare interacțiune. Pentru a ajunge acolo, trebuie să identificăm sarcini lungi (blochează firul principal pentru >50 ms) și să le despărțim, să împărțim un pachet de cod în mai multe bucăți, să reducem timpul de execuție JavaScript, să optimizăm preluarea datelor, să amânăm execuția scriptului de la terți. , mutați JavaScript în thread-ul de fundal cu lucrătorii web și utilizați hidratarea progresivă pentru a reduce costurile de rehidratare în SPA-uri.Sfat rapid : în general, o strategie de încredere pentru a obține un scor FID mai bun este de a minimiza munca pe firul principal , împărțind pachetele mai mari în altele mai mici și servind ceea ce are nevoie utilizatorul atunci când are nevoie, astfel încât interacțiunile utilizatorului să nu fie întârziate. . Vom acoperi mai multe despre asta în detaliu mai jos.
- Schimbarea aspectului cumulativ ( CLS ) < 0,1.
Măsoară stabilitatea vizuală a interfeței de utilizare pentru a asigura interacțiuni fluide și naturale, adică suma totală a tuturor scorurilor individuale de schimbare a aspectului pentru fiecare schimbare neașteptată a aspectului care are loc pe durata de viață a paginii. O schimbare individuală de aspect are loc de fiecare dată când un element care era deja vizibil își schimbă poziția pe pagină. Este punctat în funcție de dimensiunea conținutului și de distanța la care s-a mutat.
Deci, de fiecare dată când apare o schimbare — de exemplu, când fonturile alternative și fonturile web au valori diferite ale fonturilor, sau reclamele, încorporarile sau cadrele iframe care apar cu întârziere sau dimensiunile imaginii/video nu sunt rezervate sau CSS târziu forțează revopsirea sau modificările sunt injectate de către JavaScript târziu — are un impact asupra scorului CLS. Valoarea recomandată pentru o experiență bună este un CLS < 0,1.
Este de remarcat faptul că Core Web Vitals ar trebui să evolueze în timp, cu un ciclu anual previzibil . Pentru primul an de actualizare, ne putem aștepta ca First Contentful Paint să fie promovat la Core Web Vitals, un prag FID redus și un suport mai bun pentru aplicațiile cu o singură pagină. We might also see the responding to user inputs after load gaining more weight, along with security, privacy and accessibility (!) considerations.
Related to Core Web Vitals, there are plenty of useful resources and articles that are worth looking into:
- Web Vitals Leaderboard allows you to compare your scores against competition on mobile, tablet, desktop, and on 3G and 4G.
- Core SERP Vitals, a Chrome extension that shows the Core Web Vitals from CrUX in the Google Search Results.
- Layout Shift GIF Generator that visualizes CLS with a simple GIF (also available from the command line).
- web-vitals library can collect and send Core Web Vitals to Google Analytics, Google Tag Manager or any other analytics endpoint.
- Analyzing Web Vitals with WebPageTest, in which Patrick Meenan explores how WebPageTest exposes data about Core Web Vitals.
- Optimizing with Core Web Vitals, a 50-min video with Addy Osmani, in which he highlights how to improve Core Web Vitals in an eCommerce case-study.
- Cumulative Layout Shift in Practice and Cumulative Layout Shift in the Real World are comprehensive articles by Nic Jansma, which cover pretty much everything about CLS and how it correlates with key metrics such as Bounce Rate, Session Time or Rage Clicks.
- What Forces Reflow, with an overview of properties or methods, when requested/called in JavaScript, that will trigger the browser to synchronously calculate the style and layout.
- CSS Triggers shows which CSS properties trigger Layout, Paint and Composite.
- Fixing Layout Instability is a walkthrough of using WebPageTest to identify and fix layout instability issues.
- Cumulative Layout Shift, The Layout Instability Metric, another very detailed guide by Boris Schapira on CLS, how it's calcualted, how to measure and how to optimize for it.
- How To Improve Core Web Vitals, a detailed guide by Simon Hearne on each of the metrics (including other Web Vitals, such as FCP, TTI, TBT), when they occur and how they are measured.
So, are Core Web Vitals the ultimate metrics to follow ? Not quite. They are indeed exposed in most RUM solutions and platforms already, including Cloudflare, Treo, SpeedCurve, Calibre, WebPageTest (in the filmstrip view already), Newrelic, Shopify, Next.js, all Google tools (PageSpeed Insights, Lighthouse + CI, Search Console etc.) and many others.
However, as Katie Sylor-Miller explains, some of the main problems with Core Web Vitals are the lack of cross-browser support, we don't really measure the full lifecycle of a user's experience, plus it's difficult to correlate changes in FID and CLS with business outcomes.
As we should be expecting Core Web Vitals to evolve, it seems only reasonable to always combine Web Vitals with your custom-tailored metrics to get a better understanding of where you stand in terms of performance.
- Cea mai mare vopsea cu conținut maxim ( LCP ) < 2,5 sec.
- Gather data on a device representative of your audience.
To gather accurate data, we need to thoroughly choose devices to test on. In most companies, that means looking into analytics and creating user profiles based on most common device types. Yet often, analytics alone doesn't provide a complete picture. A significant portion of the target audience might be abandoning the site (and not returning back) just because their experience is too slow, and their devices are unlikely to show up as the most popular devices in analytics for that reason. So, additionally conducting research on common devices in your target group might be a good idea.Globally in 2020, according to the IDC, 84.8% of all shipped mobile phones are Android devices. An average consumer upgrades their phone every 2 years, and in the US phone replacement cycle is 33 months. Average bestselling phones around the world will cost under $200.
A representative device, then, is an Android device that is at least 24 months old , costing $200 or less, running on slow 3G, 400ms RTT and 400kbps transfer, just to be slightly more pessimistic. This might be very different for your company, of course, but that's a close enough approximation of a majority of customers out there. In fact, it might be a good idea to look into current Amazon Best Sellers for your target market. ( Thanks to Tim Kadlec, Henri Helvetica and Alex Russell for the pointers! ).
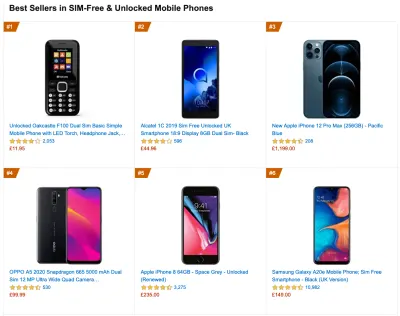
When building a new site or app, always check current Amazon Best Sellers for your target market first. (Previzualizare mare) What test devices to choose then? The ones that fit well with the profile outlined above. It's a good option to choose a slightly older Moto G4/G5 Plus, a mid-range Samsung device (Galaxy A50, S8), a good middle-of-the-road device like a Nexus 5X, Xiaomi Mi A3 or Xiaomi Redmi Note 7 and a slow device like Alcatel 1X or Cubot X19, perhaps in an open device lab. For testing on slower thermal-throttled devices, you could also get a Nexus 4, which costs just around $100.
Also, check the chipsets used in each device and do not over-represent one chipset : a few generations of Snapdragon and Apple as well as low-end Rockchip, Mediatek would be enough (thanks, Patrick!) .
If you don't have a device at hand, emulate mobile experience on desktop by testing on a throttled 3G network (eg 300ms RTT, 1.6 Mbps down, 0.8 Mbps up) with a throttled CPU (5× slowdown). Eventually switch over to regular 3G, slow 4G (eg 170ms RTT, 9 Mbps down, 9Mbps up), and Wi-Fi. To make the performance impact more visible, you could even introduce 2G Tuesdays or set up a throttled 3G/4G network in your office for faster testing.
Keep in mind that on a mobile device, we should be expecting a 4×–5× slowdown compared to desktop machines. Mobile devices have different GPUs, CPU, memory and different battery characteristics. That's why it's important to have a good profile of an average device and always test on such a device.
- Synthetic testing tools collect lab data in a reproducible environment with predefined device and network settings (eg Lighthouse , Calibre , WebPageTest ) and
- Real User Monitoring ( RUM ) tools evaluate user interactions continuously and collect field data (eg SpeedCurve , New Relic — the tools provide synthetic testing, too).
- use Lighthouse CI to track Lighthouse scores over time (it's quite impressive),
- run Lighthouse in GitHub Actions to get a Lighthouse report alongside every PR,
- run a Lighthouse performance audit on every page of a site (via Lightouse Parade), with an output saved as CSV,
- use Lighthouse Scores Calculator and Lighthouse metric weights if you need to dive into more detail.
- Lighthouse is available for Firefox as well, but under the hood it uses the PageSpeed Insights API and generates a report based on a headless Chrome 79 User-Agent.

Luckily, there are many great options that help you automate the collection of data and measure how your website performs over time according to these metrics. Keep in mind that a good performance picture covers a set of performance metrics, lab data and field data:
The former is particularly useful during development as it will help you identify, isolate and fix performance issues while working on the product. The latter is useful for long-term maintenance as it will help you understand your performance bottlenecks as they are happening live — when users actually access the site.
By tapping into built-in RUM APIs such as Navigation Timing, Resource Timing, Paint Timing, Long Tasks, etc., synthetic testing tools and RUM together provide a complete picture of performance in your application. You could use Calibre, Treo, SpeedCurve, mPulse and Boomerang, Sitespeed.io, which all are great options for performance monitoring. Furthermore, with Server Timing header, you could even monitor back-end and front-end performance all in one place.
Note : It's always a safer bet to choose network-level throttlers, external to the browser, as, for example, DevTools has issues interacting with HTTP/2 push, due to the way it's implemented ( thanks, Yoav, Patrick !). For Mac OS, we can use Network Link Conditioner, for Windows Windows Traffic Shaper, for Linux netem, and for FreeBSD dummynet.
As it's likely that you'll be testing in Lighthouse, keep in mind that you can:
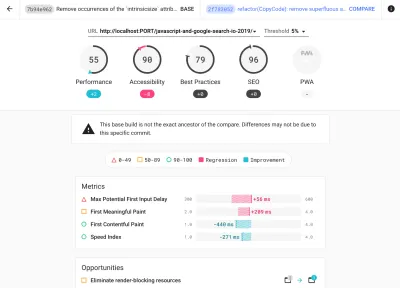
- Set up "clean" and "customer" profiles for testing.
While running tests in passive monitoring tools, it's a common strategy to turn off anti-virus and background CPU tasks, remove background bandwidth transfers and test with a clean user profile without browser extensions to avoid skewed results (in Firefox, and in Chrome).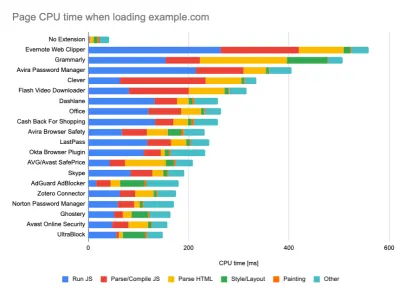
DebugBear's report highlights 20 slowest extensions, including password managers, ad-blockers and popular applications like Evernote and Grammarly. (Previzualizare mare) However, it's also a good idea to study which browser extensions your customers use frequently, and test with dedicated "customer" profiles as well. In fact, some extensions might have a profound performance impact (2020 Chrome Extension Performance Report) on your application, and if your users use them a lot, you might want to account for it up front. Hence, "clean" profile results alone are overly optimistic and can be crushed in real-life scenarios.
- Împărtășiți obiectivele de performanță cu colegii dvs.
Asigurați-vă că obiectivele de performanță sunt familiare pentru fiecare membru al echipei dvs. pentru a evita neînțelegerile pe linie. Fiecare decizie – fie că este vorba de design, marketing sau orice altceva intermediar – are implicații de performanță , iar distribuirea responsabilității și a proprietății în întreaga echipă ar eficientiza deciziile centrate pe performanță mai târziu. Hartați deciziile de proiectare în raport cu bugetul de performanță și prioritățile definite devreme.
Stabilirea obiectivelor realiste
- Timp de răspuns de 100 milisecunde, 60 fps.
Pentru ca o interacțiune să se simtă lină, interfața are 100 ms pentru a răspunde la intrarea utilizatorului. Mai mult decât atât, iar utilizatorul percepe aplicația ca fiind întârziată. RAIL, un model de performanță centrat pe utilizator, vă oferă obiective sănătoase : pentru a permite un răspuns <100 de milisecunde, pagina trebuie să cedeze controlul firului principal cel târziu la fiecare <50 de milisecunde. Latența de intrare estimată ne spune dacă atingem acel prag și, în mod ideal, ar trebui să fie sub 50 ms. Pentru punctele de înaltă presiune, cum ar fi animația, cel mai bine este să nu faci nimic altceva acolo unde poți și minimul absolut acolo unde nu poți.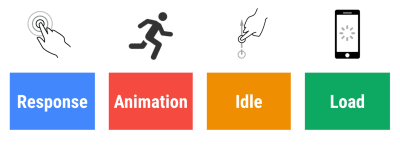
RAIL, un model de performanță centrat pe utilizator. De asemenea, fiecare cadru de animație ar trebui să fie finalizat în mai puțin de 16 milisecunde, obținând astfel 60 de cadre pe secundă (1 secundă ÷ 60 = 16,6 milisecunde) - de preferință sub 10 milisecunde. Deoarece browserul are nevoie de timp pentru a picta noul cadru pe ecran, codul dvs. ar trebui să se încheie înainte de a atinge marcajul de 16,6 milisecunde. Începem să avem conversații despre 120fps (de exemplu, ecranele iPad Pro rulează la 120Hz) și Surma a acoperit câteva soluții de randare de performanță pentru 120fps, dar probabil că nu este o țintă la care ne uităm încă .
Fii pesimist în ceea ce privește așteptările de performanță, dar fii optimist în proiectarea interfeței și folosește cu înțelepciune timpul de inactivitate (verificați idlize, idle-until-urgent și react-idle). Evident, aceste obiective se aplică performanței de rulare, mai degrabă decât performanței de încărcare.
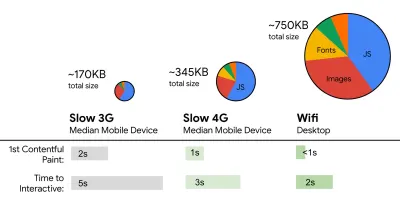
- FID < 100 ms, LCP < 2,5 s, TTI < 5 s pe 3G, buget de dimensiune critică a fișierului < 170 KB (gzipped).
Deși ar putea fi foarte dificil de atins, un obiectiv final bun ar fi Time to Interactive sub 5s, iar pentru vizite repetate, vizați sub 2s (atins doar cu un lucrător de service). Vizualizați cel mai mare conținut de vopsea de sub 2,5 secunde și minimizați timpul total de blocare și schimbarea cumulativă a aspectului . O întârziere acceptabilă pentru prima intrare este sub 100 ms–70 ms. Așa cum am menționat mai sus, considerăm că linia de bază este un telefon Android de 200 USD (ex. Moto G4) pe o rețea 3G lentă, emulată la 400 ms RTT și o viteză de transfer de 400 kbps.Avem două constrângeri majore care modelează efectiv un obiectiv rezonabil pentru livrarea rapidă a conținutului pe web. Pe de o parte, avem constrângeri de livrare a rețelei din cauza TCP Slow Start. Primii 14 KB din HTML — 10 pachete TCP, fiecare de 1460 de octeți, formând aproximativ 14,25 KB, deși nu trebuie luate la propriu — este cea mai critică bucată de sarcină utilă și singura parte a bugetului care poate fi livrată în prima călătorie dus-întors ( ceea ce este tot ce primești în 1 secundă la 400 ms RTT datorită timpilor de trezire a mobilului).

Cu conexiunile TCP, începem cu o mică fereastră de congestie și o dublem pentru fiecare dus-întors. În prima călătorie dus-întors, putem încadra 14 KB. De la: Rețea de browser de înaltă performanță de Ilya Grigorik. (Previzualizare mare) ( Notă : deoarece TCP subutiliza în general conexiunea la rețea într-o cantitate semnificativă, Google a dezvoltat TCP Bottleneck Bandwidth și RRT ( BBR ), un algoritm TCP de control al fluxului TCP controlat cu întârziere. Proiectat pentru web-ul modern, acesta răspunde la congestionarea reală, mai degrabă decât pierderea de pachete, așa cum o face TCP, este semnificativ mai rapidă, cu un debit mai mare și o latență mai mică - iar algoritmul funcționează diferit. ( Mulțumesc, Victor, Barry! )
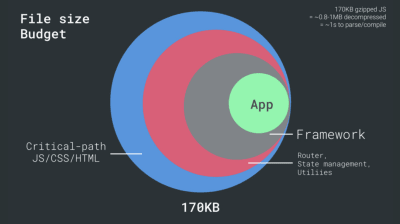
Pe de altă parte, avem constrângeri hardware asupra memoriei și CPU din cauza parsării JavaScript și timpilor de execuție (vom vorbi despre ele în detaliu mai târziu). Pentru a atinge obiectivele menționate în primul paragraf, trebuie să luăm în considerare bugetul de dimensiune critică a fișierului pentru JavaScript. Opiniile variază cu privire la bugetul respectiv (și depinde în mare măsură de natura proiectului dvs.), dar un buget de 170 KB JavaScript arhivat deja ar dura până la 1 secundă pentru a analiza și compila pe un telefon de gamă medie. Presupunând că 170 KB se extinde la 3 ori această dimensiune atunci când este decomprimat (0,7 MB), acesta ar putea fi deja clopotul unei experiențe de utilizator „decente” pe un Moto G4/G5 Plus.
În cazul site-ului web Wikipedia, în 2020, la nivel global, execuția codului a devenit cu 19% mai rapidă pentru utilizatorii Wikipedia. Deci, dacă valorile dvs. de performanță web de la an la an rămân stabile, acesta este de obicei un semn de avertizare, deoarece regresați de fapt, pe măsură ce mediul continuă să se îmbunătățească (detalii într-o postare pe blog de Gilles Dubuc).
Dacă doriți să vizați piețe în creștere, cum ar fi Asia de Sud-Est, Africa sau India, va trebui să vă uitați la un set foarte diferit de constrângeri. Addy Osmani acoperă constrângerile majore ale telefonului cu caracteristici, cum ar fi puține dispozitive de înaltă calitate și costuri reduse, indisponibilitatea rețelelor de înaltă calitate și date mobile scumpe - împreună cu bugetul PRPL-30 și liniile directoare de dezvoltare pentru aceste medii.
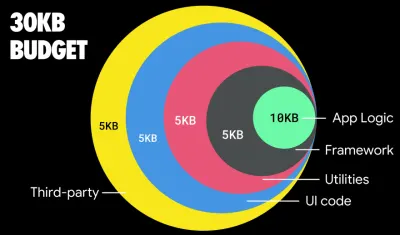
Potrivit lui Addy Osmani, o dimensiune recomandată pentru rutele încărcate lene este, de asemenea, mai mică de 35 KB. (Previzualizare mare) 
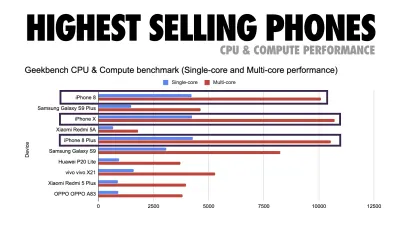
Addy Osmani sugerează bugetul de performanță PRPL-30 (30KB gzipped + pachet inițial minimizat) dacă vizează un telefon cu caracteristici. (Previzualizare mare) De fapt, Alex Russell de la Google recomandă să țintească 130–170KB gzipped ca limită superioară rezonabilă. În scenariile din lumea reală, majoritatea produselor nici măcar nu sunt aproape: dimensiunea medie a pachetului de astăzi este de aproximativ 452 KB, ceea ce este în creștere cu 53,6% față de începutul anului 2015. Pe un dispozitiv mobil de clasă de mijloc, aceasta reprezintă 12-20 de secunde pentru Time. -La-Interactiv .
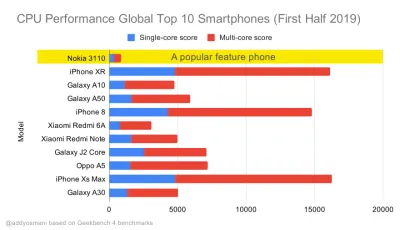
Criterii de referință pentru performanța procesorului Geekbench pentru cele mai vândute smartphone-uri la nivel global în 2019. JavaScript pune accentul pe performanța single-core (rețineți, este în mod inerent mai mult cu un singur thread decât restul platformei web) și este legat de CPU. Din articolul lui Addy „Încărcarea rapidă a paginilor web pe un telefon cu funcții de 20 USD”. (Previzualizare mare) Totuși, am putea depăși bugetul pentru dimensiunea pachetului. De exemplu, am putea stabili bugete de performanță în funcție de activitățile firului principal al browserului, adică timpul de vopsire înainte de începerea randării, sau de a urmări erorile CPU front-end. Instrumente precum Calibre, SpeedCurve și Bundlesize vă pot ajuta să vă mențineți bugetele sub control și pot fi integrate în procesul de construcție.
În cele din urmă, un buget de performanță probabil nu ar trebui să fie o valoare fixă . În funcție de conexiunea la rețea, bugetele de performanță ar trebui să se adapteze, dar sarcina utilă pentru o conexiune mai lentă este mult mai „costisitoare”, indiferent de modul în care sunt utilizate.
Notă : ar putea suna ciudat să stabilim bugete atât de rigide în vremuri de extindere HTTP/2, viitoarele 5G și HTTP/3, telefoane mobile cu evoluție rapidă și SPA-uri înfloritoare. Cu toate acestea, sună rezonabil atunci când avem de-a face cu natura imprevizibilă a rețelei și a hardware-ului, inclusiv totul, de la rețele aglomerate la infrastructura în dezvoltare lentă, la limite de date, browsere proxy, modul de salvare a datelor și tarife de roaming ascunse.
Definirea Mediului
- Alegeți și configurați-vă instrumentele de construcție.
Nu acordați prea multă atenție la ceea ce se presupune că este cool în aceste zile. Țineți de mediul dvs. pentru a construi, fie că este Grunt, Gulp, Webpack, Parcel sau o combinație de instrumente. Atâta timp cât obțineți rezultatele de care aveți nevoie și nu aveți probleme în menținerea procesului de construcție, vă descurci bine.Printre instrumentele de construire, Rollup continuă să câștige acțiune, la fel și Snowpack, dar Webpack pare să fie cel mai stabilit, cu literalmente sute de plugin-uri disponibile pentru a optimiza dimensiunea construcțiilor tale. Atenție la Foaia de parcurs Webpack 2021.
Una dintre cele mai notabile strategii care a apărut recent este fragmentarea granulară cu Webpack în Next.js și Gatsby pentru a minimiza codul duplicat. În mod implicit, modulele care nu sunt partajate în fiecare punct de intrare pot fi solicitate pentru rutele care nu îl folosesc. Acest lucru ajunge să devină o suprasarcină, deoarece se descarcă mai mult cod decât este necesar. Cu fragmentarea granulară în Next.js, putem folosi un fișier manifest de compilare pe partea serverului pentru a determina ce fragmente rezultate sunt utilizate de diferite puncte de intrare.
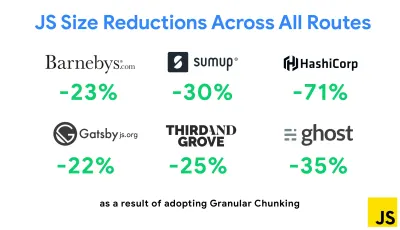
Pentru a reduce codul duplicat în proiectele Webpack, putem folosi fragmentarea granulară, activată în Next.js și Gatsby în mod implicit. Credit imagine: Addy Osmani. (Previzualizare mare) Cu SplitChunksPlugin, mai multe bucăți divizate sunt create în funcție de un număr de condiții pentru a preveni preluarea codului duplicat pe mai multe rute. Acest lucru îmbunătățește timpul de încărcare a paginii și stocarea în cache în timpul navigării. Livrat în Next.js 9.2 și în Gatsby v2.20.7.
Începerea cu Webpack poate fi totuși dificilă. Deci, dacă doriți să vă scufundați în Webpack, există câteva resurse excelente:
- Documentația Webpack – evident – este un bun punct de plecare, la fel și Webpack – The Confusing Bits de Raja Rao și An Annotated Webpack Config de Andrew Welch.
- Sean Larkin are un curs gratuit despre Webpack: Conceptele de bază, iar Jeffrey Way a lansat un curs gratuit fantastic despre Webpack pentru toată lumea. Ambele sunt introduceri grozave pentru scufundarea în Webpack.
- Webpack Fundamentals este un curs foarte cuprinzător de 4 ore cu Sean Larkin, lansat de FrontendMasters.
- Exemplele Webpack au sute de configurații Webpack gata de utilizare, clasificate după subiect și scop. Bonus: există și un configurator de configurare Webpack care generează un fișier de configurare de bază.
- awesome-webpack este o listă organizată de resurse, biblioteci și instrumente utile Webpack, inclusiv articole, videoclipuri, cursuri, cărți și exemple pentru proiecte Angular, React și agnostice de framework.
- Călătoria către construirea rapidă a activelor de producție cu Webpack este studiul de caz al Etsy despre modul în care echipa a trecut de la utilizarea unui sistem de compilare JavaScript bazat pe RequireJS la utilizarea Webpack și modul în care și-au optimizat versiunile, gestionând peste 13.200 de active în medie în 4 minute .
- Sfaturi de performanță Webpack este un fir de aur al lui Ivan Akulov, care conține multe sfaturi axate pe performanță, inclusiv cele axate în mod special pe Webpack.
- awesome-webpack-perf este o mină de aur GitHub repo cu instrumente utile Webpack și pluginuri pentru performanță. De asemenea, întreținut de Ivan Akulov.
- Utilizați îmbunătățirea progresivă ca implicită.
Totuși, după toți acești ani, păstrarea îmbunătățirii progresive ca principiu ghid al arhitecturii și implementării tale front-end este un pariu sigur. Proiectați și construiți mai întâi experiența de bază, apoi îmbunătățiți experiența cu funcții avansate pentru browsere capabile, creând experiențe rezistente. Dacă site-ul dvs. rulează rapid pe o mașină lentă cu un ecran slab într-un browser slab într-o rețea suboptimă, atunci va rula mai rapid doar pe o mașină rapidă cu un browser bun într-o rețea decentă.De fapt, cu modul de servire adaptiv, se pare că ducem îmbunătățirea progresivă la un alt nivel, oferind experiențe de bază „lite” dispozitivelor de ultimă generație și îmbunătățirea cu funcții mai sofisticate pentru dispozitivele de ultimă generație. Îmbunătățirea progresivă nu va dispărea în curând.
- Alegeți o bază de performanță puternică.
Cu atât de multe necunoscute care influențează încărcarea — rețea, limitarea termică, evacuarea memoriei cache, scripturi terță parte, modele de blocare a analizatorului, I/O disc, latența IPC, extensii instalate, software antivirus și firewall-uri, sarcini de fundal ale CPU, constrângeri hardware și memorie, diferențe de cache L2/L3, RTTS — JavaScript are cel mai mare cost al experienței, alături de fonturile web care blochează redarea în mod implicit și imaginile care consumă adesea prea multă memorie. Pe măsură ce blocajele de performanță se îndepărtează de la server la client, în calitate de dezvoltatori, trebuie să luăm în considerare toate aceste necunoscute mult mai detaliat.Cu un buget de 170 KB care conține deja calea critică HTML/CSS/JavaScript, router, management de stat, utilități, cadrul și logica aplicației, trebuie să examinăm amănunțit costul de transfer al rețelei, timpul de analizare/compilare și costul de rulare. a cadrului ales de noi. Din fericire, am observat o îmbunătățire uriașă în ultimii ani în ceea ce privește viteza cu care browserele pot analiza și compila scripturi. Cu toate acestea, execuția JavaScript este încă principalul blocaj, așa că acordarea unei atenții sporite timpului de execuție a scriptului și rețelei poate avea impact.
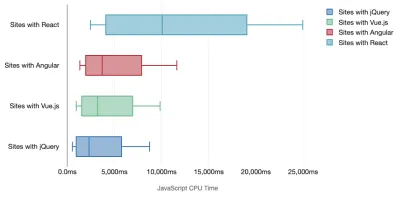
Tim Kadlec a efectuat o cercetare fantastică asupra performanței cadrelor moderne și le-a rezumat în articolul „Framelor JavaScript au un cost”. Vorbim adesea despre impactul cadrelor de sine stătătoare, dar, după cum remarcă Tim, în practică, nu este neobișnuit să aveți mai multe cadre în uz . Poate că o versiune mai veche a jQuery care este migrată încet la un cadru modern, împreună cu câteva aplicații vechi care folosesc o versiune mai veche de Angular. Prin urmare, este mai rezonabil să explorezi costul cumulativ al octeților JavaScript și al timpului de execuție a procesorului, care pot face cu ușurință experiențele utilizatorului abia utilizabile, chiar și pe dispozitivele de ultimă generație.
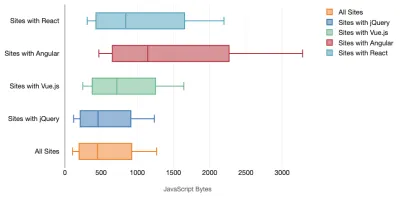
În general, cadrele moderne nu acordă prioritate dispozitivelor mai puțin puternice , așa că experiențele pe un telefon și pe desktop vor fi adesea dramatic diferite în ceea ce privește performanța. Conform cercetărilor, site-urile cu React sau Angular petrec mai mult timp pe procesor decât altele (ceea ce, desigur, nu înseamnă neapărat că React este mai scump pe procesor decât Vue.js).
Potrivit lui Tim, un lucru este evident: „dacă utilizați un cadru pentru a vă construi site-ul, faceți un compromis în ceea ce privește performanța inițială – chiar și în cele mai bune scenarii”.
- Evaluați cadrele și dependențele.
Acum, nu orice proiect are nevoie de un cadru și nu fiecare pagină a unei aplicații cu o singură pagină trebuie să încarce un cadru. În cazul Netflix, „eliminând React, mai multe biblioteci și codul de aplicație corespunzător din partea clientului a redus cantitatea totală de JavaScript cu peste 200 KB, provocând o reducere de peste 50% a timpului de interactivitate al Netflix pentru pagina de pornire deconectată. ." Apoi, echipa a folosit timpul petrecut de utilizatori pe pagina de destinație pentru a prelua React pentru paginile ulterioare pe care ar putea ajunge utilizatorii (citiți mai departe pentru detalii).Deci, ce se întâmplă dacă eliminați cu totul un cadru existent pe paginile critice? Cu Gatsby, puteți verifica gatsby-plugin-no-javascript care elimină toate fișierele JavaScript create de Gatsby din fișierele HTML statice. Pe Vercel, puteți permite, de asemenea, dezactivarea JavaScript de rulare în producție pentru anumite pagini (experimental).
Odată ce un cadru este ales, vom rămâne cu el cel puțin câțiva ani, așa că, dacă trebuie să folosim unul, trebuie să ne asigurăm că alegerea noastră este informată și bine luată în considerare - și asta este valabil mai ales pentru valorile cheie de performanță pe care le avem îți pasă de.
Datele arată că, în mod implicit, cadrele sunt destul de scumpe: 58,6% dintre paginile React sunt livrate peste 1 MB de JavaScript, iar 36% din încărcările paginilor Vue.js au un First Contentful Paint de <1,5 secunde. Potrivit unui studiu realizat de Ankur Sethi, „aplicația dvs. React nu se va încărca niciodată mai repede de aproximativ 1,1 secunde pe un telefon mediu din India, indiferent cât de mult îl optimizați. Aplicația Angular va dura întotdeauna cel puțin 2,7 secunde pentru a porni. utilizatorii aplicației tale Vue vor trebui să aștepte cel puțin o secundă înainte de a putea începe să o folosească.” Oricum, s-ar putea să nu vizați India ca piață principală, dar utilizatorii care vă accesează site-ul cu condiții de rețea suboptime vor avea o experiență comparabilă.
Bineînțeles că este posibil să facem SPA-uri rapid, dar nu sunt rapid scoase din cutie, așa că trebuie să luăm în considerare timpul și efortul necesar pentru a le face și a le menține rapid. Probabil că va fi mai ușor dacă aleg de la început un cost de performanță de bază ușor.
Deci, cum alegem un cadru ? Este o idee bună să luați în considerare cel puțin costul total pe dimensiune + timpii inițiali de execuție înainte de a alege o opțiune; Opțiunile ușoare precum Preact, Inferno, Vue, Svelte, Alpine sau Polymer pot face treaba foarte bine. Mărimea liniei de bază va defini constrângerile pentru codul aplicației dvs.
După cum a menționat Seb Markbage, o modalitate bună de a măsura costurile de pornire pentru cadre este să randați mai întâi o vizualizare, apoi să o ștergeți și apoi să randați din nou , deoarece vă poate spune cum se scalează cadrul. Prima randare tinde să încălzească o grămadă de cod compilat leneș, de care un copac mai mare poate beneficia atunci când se scalează. A doua randare este practic o emulare a modului în care reutilizarea codului pe o pagină afectează caracteristicile de performanță pe măsură ce pagina crește în complexitate.
Puteți merge până la evaluarea candidaților (sau a oricărei biblioteci JavaScript în general) pe sistemul de notare pe scară de 12 puncte al lui Sacha Greif, explorând funcții, accesibilitate, stabilitate, performanță, ecosistem de pachete , comunitate, curba de învățare, documentație, instrumente, istoric. , echipa, compatibilitate, securitate de exemplu.
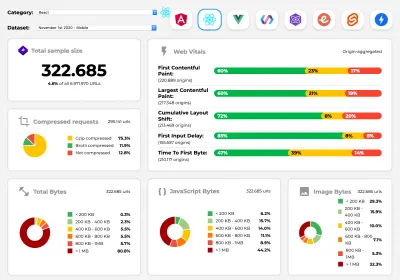
Perf Track urmărește performanța cadrului la scară. (Previzualizare mare) De asemenea, vă puteți baza pe datele colectate pe web pe o perioadă mai lungă de timp. De exemplu, Perf Track urmărește performanța cadrului la scară, arătând scorurile Core Web Vitals agregate la origine pentru site-urile web construite în Angular, React, Vue, Polymer, Preact, Ember, Svelte și AMP. Puteți chiar să specificați și să comparați site-uri web create cu aplicația Gatsby, Next.js sau Create React, precum și site-uri web create cu Nuxt.js (Vue) sau Sapper (Svelte).
Un bun punct de plecare este să alegeți o stivă implicită bună pentru aplicația dvs. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI și PWA Starter Kit oferă valori implicite rezonabile pentru încărcarea rapidă din cutie pe hardware-ul mobil mediu. De asemenea, aruncați o privire la ghidurile de performanță specifice cadrului web.dev pentru React și Angular ( mulțumesc, Phillip! ).
Și poate că ați putea adopta o abordare puțin mai revigorantă pentru a construi aplicații cu o singură pagină - Turbolinks, o bibliotecă JavaScript de 15 KB care utilizează HTML în loc de JSON pentru a reda vizualizări. Deci, atunci când urmați un link, Turbolinks preia automat pagina, schimbă
<body>și îmbină<head>, totul fără a suporta costul unei încărcări complete a paginii. Puteți verifica detalii rapide și documentația completă despre stivă (Hotwire).
- Redare pe partea client sau pe partea server? Ambii!
E o conversație destul de aprinsă. Abordarea finală ar fi să configurați un fel de pornire progresivă: utilizați randarea pe server pentru a obține o primă vopsea rapidă, dar includeți și niște JavaScript necesar minim pentru a menține timpul de interactiv aproape de First Contentful Paint. Dacă JavaScript vine prea târziu după FCP, browserul va bloca firul principal în timp ce analizează, compilează și execută JavaScript descoperit târziu, astfel cătușând interactivitatea site-ului sau a aplicației.Pentru a evita acest lucru, împărțiți întotdeauna execuția funcțiilor în sarcini separate, asincrone și, acolo unde este posibil, utilizați
requestIdleCallback. Luați în considerare încărcarea leneșă a părților interfeței de utilizare folosind suportul pentruimport()dinamic de la WebPack, evitând costurile de încărcare, analiză și compilare până când utilizatorii chiar au nevoie de ele ( mulțumesc Addy! ).După cum am menționat mai sus, Time to Interactive (TTI) ne indică timpul dintre navigare și interactivitate. În detaliu, valoarea este definită analizând prima fereastră de cinci secunde după redarea conținutului inițial, în care nicio activitate JavaScript nu durează mai mult de 50 ms ( Sarcini lungi ). Dacă are loc o sarcină de peste 50 ms, căutarea unei ferestre de cinci secunde începe de la capăt. Drept urmare, browserul va presupune mai întâi că a ajuns la Interactiv , doar pentru a trece la Înghețat , doar pentru a reveni în cele din urmă la Interactiv .
Odată ce ajungem la Interactive , putem apoi, fie la cerere, fie în funcție de timp, să pornim părți neesențiale ale aplicației. Din păcate, după cum a observat Paul Lewis, cadrele nu au de obicei un concept simplu de prioritate care să poată fi prezentat dezvoltatorilor și, prin urmare, pornirea progresivă nu este ușor de implementat cu majoritatea bibliotecilor și cadrelor.
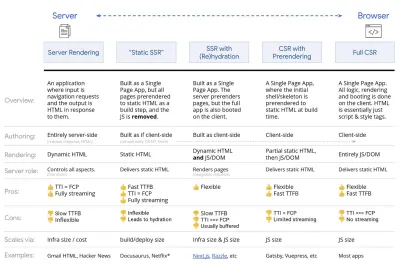
Totuși, ajungem acolo. În aceste zile, există câteva opțiuni pe care le putem explora, iar Houssein Djirdeh și Jason Miller oferă o imagine de ansamblu excelentă asupra acestor opțiuni în discursul lor despre Rendering on the Web și în articolul lui Jason și Addy despre arhitecturile moderne front-end. Prezentare generală de mai jos se bazează pe munca lor stelară.
- Redare completă pe partea de server (SSR)
În SSR clasic, cum ar fi WordPress, toate solicitările sunt gestionate în întregime pe server. Conținutul solicitat este returnat ca o pagină HTML finalizată, iar browserele îl pot reda imediat. Prin urmare, aplicațiile SSR nu pot folosi cu adevărat API-urile DOM, de exemplu. Diferența dintre First Contentful Paint și Time to Interactive este de obicei mică, iar pagina poate fi redată imediat pe măsură ce HTML este transmis în flux în browser.Acest lucru evită călătoriile dus-întors suplimentare pentru preluarea datelor și modelarea pe client, deoarece acestea sunt gestionate înainte ca browserul să primească un răspuns. Cu toate acestea, ajungem la un timp de gândire mai lung de server și, în consecință, Time To First Byte și nu folosim funcțiile receptive și bogate ale aplicațiilor moderne.
- Redare statică
Construim produsul ca o aplicație cu o singură pagină, dar toate paginile sunt preredate în HTML static cu JavaScript minim ca pas de construire. Aceasta înseamnă că, cu randarea statică, producem fișiere HTML individuale pentru fiecare adresă URL posibilă înainte de timp, ceea ce nu își pot permite multe aplicații. Dar pentru că HTML-ul pentru o pagină nu trebuie să fie generat din mers, putem obține un Time To First Byte constant rapid. Astfel, putem afișa rapid o pagină de destinație și apoi prefacem un cadru SPA pentru paginile ulterioare. Netflix a adoptat această abordare reducând încărcarea și Time-to-Interactive cu 50%. - Redare pe server cu (re)hidratare (Răzare universală, SSR + CSR)
Putem încerca să folosim tot ce este mai bun din ambele lumi - abordările SSR și CSR. Cu hidratare în amestec, pagina HTML returnată de la server conține și un script care încarcă o aplicație completă pe partea clientului. În mod ideal, se obține o primă vopsea cu conținut rapid (cum ar fi SSR) și apoi se continuă randarea cu (re)hidratare. Din păcate, asta se întâmplă rar. Mai des, pagina pare gata, dar nu poate răspunde la inputul utilizatorului, producând clicuri furioase și abandonuri.Cu React, putem folosi modulul
ReactDOMServerpe un server Node precum Express și apoi apelăm metodarenderToStringpentru a reda componentele de nivel superior ca șir HTML static.Cu Vue.js, putem folosi vue-server-renderer pentru a reda o instanță Vue în HTML folosind
renderToString. În Angular, putem folosi@nguniversalpentru a transforma cererile clienților în pagini HTML redate complet pe server. O experiență complet redată pe server poate fi obținută și imediat cu Next.js (React) sau Nuxt.js (Vue).Abordarea are dezavantajele ei. Drept urmare, obținem flexibilitate deplină a aplicațiilor de pe partea client, oferind în același timp o randare mai rapidă pe partea de server, dar ajungem și la un decalaj mai lung între First Contentful Paint și Time To Interactive și o întârziere crescută pentru prima introducere. Rehidratarea este foarte costisitoare și, de obicei, această strategie singură nu va fi suficient de bună, deoarece întârzie foarte mult Time To Interactive.
- Redare în flux pe server cu hidratare progresivă (SSR + CSR)
Pentru a minimiza diferența dintre Time To Interactive și First Contentful Paint, redăm mai multe solicitări simultan și trimitem conținutul în bucăți pe măsură ce sunt generate. Deci, nu trebuie să așteptăm șirul complet de HTML înainte de a trimite conținut către browser și, prin urmare, să îmbunătățim Time To First Byte.În React, în loc de
renderToString(), putem folosi renderToNodeStream() pentru a canaliza răspunsul și a trimite codul HTML în bucăți. În Vue, putem folosi renderToStream() care poate fi transmis și transmis în flux. Cu React Suspense, am putea folosi și redarea asincronă în acest scop.Pe partea clientului, mai degrabă decât pornirea întregii aplicații deodată, pornim componentele progresiv . Secțiunile aplicațiilor sunt mai întâi împărțite în scripturi de sine stătătoare cu împărțirea codului și apoi hidratate treptat (în ordinea priorităților noastre). De fapt, putem hidrata mai întâi componentele critice, în timp ce restul ar putea fi hidratate mai târziu. Rolul redării pe partea client și pe partea serverului poate fi apoi definit diferit pe componentă. De asemenea, putem amâna hidratarea unor componente până când acestea apar sau sunt necesare pentru interacțiunea cu utilizatorul sau când browserul este inactiv.
Pentru Vue, Markus Oberlehner a publicat un ghid despre reducerea timpului de interacțiune al aplicațiilor SSR folosind hidratarea în interacțiunea utilizatorului, precum și vue-lazy-hydration, un plugin în stadiu incipient care permite hidratarea componentelor pe vizibilitate sau interacțiunea utilizatorului specific. Echipa Angular lucrează la hidratarea progresivă cu Ivy Universal. Puteți implementa hidratarea parțială și cu Preact și Next.js.
- Redare trizomorfă
Cu lucrătorii de servicii la locul lor, putem folosi redarea serverului de streaming pentru navigarea inițială/non-JS și apoi îl putem lăsa pe lucrătorul de service să preia redarea HTML pentru navigații după ce acesta a fost instalat. În acest caz, lucrătorul de servicii redă în prealabil conținutul și activează navigarea în stil SPA pentru redarea de noi vizualizări în aceeași sesiune. Funcționează bine atunci când puteți partaja același cod de șabloane și rutare între server, pagina client și lucrător de service.
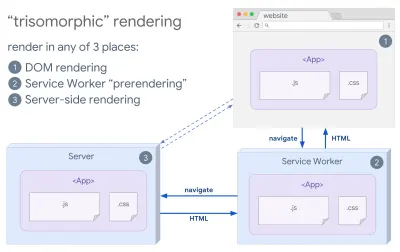
Redare trisomorfă, cu aceeași redare a codului în oricare 3 locuri: pe server, în DOM sau într-un service worker. (Sursa imagine: Google Developers) (Previzualizare mare) - CSR cu prerendare
Pre-rendarea este similară cu redarea pe server, dar mai degrabă decât redarea dinamică a paginilor de pe server, redăm aplicația la HTML static în momentul construirii. În timp ce paginile statice sunt complet interactive, fără prea mult JavaScript la nivel de client, pre- rendarea funcționează diferit . Practic, captează starea inițială a unei aplicații de pe partea client ca HTML static la momentul construirii, în timp ce cu pre-rendarea aplicația trebuie să fie pornită pe client pentru ca paginile să fie interactive.Cu Next.js, putem folosi exportul HTML static prin predarea unei aplicații în HTML static. În Gatsby, un generator de site-uri static open source care folosește React, folosește metoda
renderToStaticMarkupîn loc de metodarenderToStringîn timpul build-urilor, cu fragmentul JS principal preîncărcat și rutele viitoare sunt preîncărcate, fără atribute DOM care nu sunt necesare pentru paginile statice simple.Pentru Vue, putem folosi Vuepress pentru a atinge același obiectiv. De asemenea, puteți utiliza pre-render-loader cu Webpack. Navi oferă și randare statică.
Rezultatul este un Time To First Byte și First Contentful Paint mai bun și reducem decalajul dintre Time To Interactive și First Contentful Paint. Nu putem folosi abordarea dacă se preconizează că conținutul se va schimba mult. În plus, toate adresele URL trebuie cunoscute din timp pentru a genera toate paginile. Așadar, unele componente ar putea fi redate folosind prerendarea, dar dacă avem nevoie de ceva dinamic, trebuie să ne bazăm pe aplicație pentru a prelua conținutul.
- Redare completă la nivelul clientului (CSR)
Toată logica, randarea și pornirea se fac pe client. Rezultatul este de obicei un decalaj uriaș între Time To Interactive și First Contentful Paint. Ca rezultat, aplicațiile se simt adesea lente , deoarece întreaga aplicație trebuie pornită pe client pentru a reda orice.Deoarece JavaScript are un cost de performanță, pe măsură ce cantitatea de JavaScript crește cu o aplicație, împărțirea agresivă a codului și amânarea JavaScript va fi absolut necesar pentru a diminua impactul JavaScript. Pentru astfel de cazuri, o redare pe partea serverului va fi de obicei o abordare mai bună în cazul în care nu este nevoie de multă interactivitate. Dacă nu este o opțiune, luați în considerare utilizarea modelului App Shell.
În general, SSR este mai rapid decât CSR. Cu toate acestea, este o implementare destul de frecventă pentru multe aplicații de acolo.
Deci, partea client sau partea serverului? În general, este o idee bună să limitați utilizarea cadrelor pe partea clientului la paginile care le necesită absolut. Pentru aplicațiile avansate, nici nu este o idee bună să te bazezi doar pe randarea serverului. Atât redarea serverului, cât și redarea clientului sunt un dezastru dacă sunt făcute prost.
Indiferent dacă înclinați spre CSR sau SSR, asigurați-vă că redați pixeli importanți cât mai curând posibil și minimizați decalajul dintre acea redare și Time To Interactive. Luați în considerare pre-rendarea dacă paginile dvs. nu se schimbă prea mult și amânați pornirea cadrelor dacă puteți. Transmiteți HTML în bucăți cu randare pe partea de server și implementați hidratarea progresivă pentru randarea pe partea clientului - și hidratați-vă pe vizibilitate, interacțiune sau în timpul inactiv pentru a obține ce este mai bun din ambele lumi.
- Redare completă pe partea de server (SSR)

- Cât putem servi static?
Indiferent dacă lucrați la o aplicație mare sau un site mic, merită să luați în considerare ce conținut ar putea fi servit static dintr-un CDN (adică JAM Stack), mai degrabă decât să fie generat dinamic din mers. Chiar dacă aveți mii de produse și sute de filtre cu o mulțime de opțiuni de personalizare, este posibil să doriți totuși să vă difuzați paginile de destinație critice în mod static și să decuplați aceste pagini de cadrul ales.Există o mulțime de generatoare de site-uri statice și paginile pe care le generează sunt adesea foarte rapide. The more content we can pre-build ahead of time instead of generating page views on a server or client at request time, the better performance we will achieve.
In Building Partially Hydrated, Progressively Enhanced Static Websites, Markus Oberlehner shows how to build out websites with a static site generator and an SPA, while achieving progressive enhancement and a minimal JavaScript bundle size. Markus uses Eleventy and Preact as his tools, and shows how to set up the tools, add partial hydration, lazy hydration, client entry file, configure Babel for Preact and bundle Preact with Rollup — from start to finish.
With JAMStack used on large sites these days, a new performance consideration appeared: the build time . In fact, building out even thousands of pages with every new deploy can take minutes, so it's promising to see incremental builds in Gatsby which improve build times by 60 times , with an integration into popular CMS solutions like WordPress, Contentful, Drupal, Netlify CMS and others.
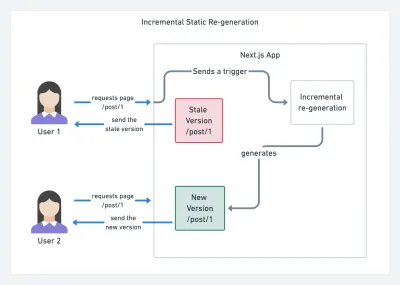
Incremental static regeneration with Next.js. (Image credit: Prisma.io) (Large preview) Also, Next.js announced ahead-of-time and incremental static generation, which allows us to add new static pages at runtime and update existing pages after they've been already built, by re-rendering them in the background as traffic comes in.
Need an even more lightweight approach? In his talk on Eleventy, Alpine and Tailwind: towards a lightweight Jamstack, Nicola Goutay explains the differences between CSR, SSR and everything-in-between, and shows how to use a more lightweight approach — along with a GitHub repo that shows the approach in practice.
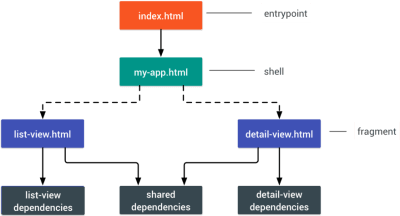
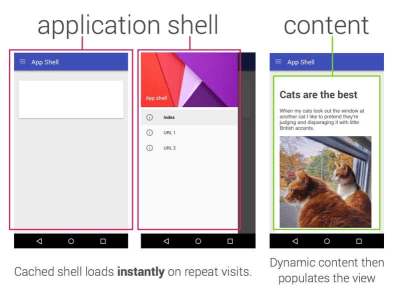
- Consider using PRPL pattern and app shell architecture.
Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you'll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
- Have you optimized the performance of your APIs?
APIs are communication channels for an application to expose data to internal and third-party applications via endpoints . When designing and building an API, we need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer ( REST ) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services .As with good ol' HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering . When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request , and the response will be exactly what is required, without over or under -fetching data as it typically happens with REST.
In addition, because GraphQL is using schema (metadata that tells how the data is structured), it can already organize data into the preferred structure, so, for example, with GraphQL, we could remove JavaScript code used for dealing with state management, producing a cleaner application code that runs faster on the client.
If you want to get started with GraphQL or encounter performance issues, these articles might be quite helpful:
- A GraphQL Primer: Why We Need A New Kind Of API by Eric Baer,
- A GraphQL Primer: The Evolution Of API Design by Eric Baer,
- Designing a GraphQL server for optimal performance by Leonardo Losoviz,
- GraphQL performance explained by Wojciech Trocki.
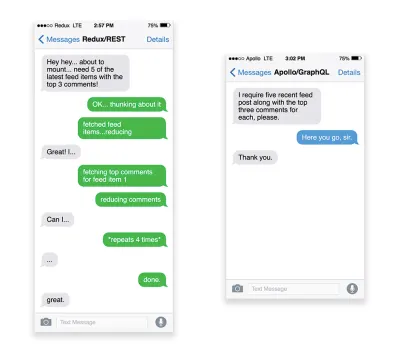
- Will you be using AMP or Instant Articles?
Depending on the priorities and strategy of your organization, you might want to consider using Google's AMP or Facebook's Instant Articles or Apple's Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.The seemingly obvious benefit of these technologies for users is guaranteed performance , so at times they might even prefer AMP-/Apple News/Instant Pages-links over "regular" and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don't. According to Tim Kadlec, for example, "AMP documents tend to be faster than their counterparts, but they don't necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective."
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines.
Well, at least that's how it used to be. As AMP is no longer a requirement for Top Stories , publishers might be moving away from AMP to a traditional stack instead ( thanks, Barry! ).
Still, you could build progressive web AMPs, too, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs (thanks Addy, Jeremy!) .
- Choose your CDN wisely.
As mentioned above, depending on how much dynamic data you have, you might be able to "outsource" some part of the content to a static site generator, pushing it to a CDN and serving a static version from it, thus avoiding requests to the server. In fact, some of those generators are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (eg image optimization and resizing at the edge), whether they provide support for servers workers, A/B testing, as well as edge-side includes, which assemble static and dynamic parts of pages at the CDN's edge (ie the server closest to the user), and other tasks. Also, check if your CDN supports HTTP over QUIC (HTTP/3).
Katie Hempenius has written a fantastic guide to CDNs that provides insights on how to choose a good CDN , how to finetune it and all the little things to keep in mind when evaluating one. In general, it's a good idea to cache content as aggressively as possible and enable CDN performance features like Brotli, TLS 1.3, HTTP/2, and HTTP/3.
Note : based on research by Patrick Meenan and Andy Davies, HTTP/2 prioritization is effectively broken on many CDNs, so be careful when choosing a CDN. Patrick has more details in his talk on HTTP/2 Prioritization ( thanks, Barry! ).
CDNPerf measures query speed for CDNs by gathering and analyzing 300 million tests every day. (Previzualizare mare) When choosing a CDN, you can use these comparison sites with a detailed overview of their features:
- CDN Comparison, o matrice de comparație CDN pentru Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai și multe altele.
- CDN Perf măsoară viteza de interogare pentru CDN-uri prin colectarea și analiza a 300 de milioane de teste în fiecare zi, toate rezultatele fiind bazate pe datele RUM de la utilizatori din întreaga lume. Verificați, de asemenea, Comparația performanței DNS și Comparația performanței cloud.
- CDN Planet Guides oferă o prezentare generală a CDN-urilor pentru anumite subiecte, cum ar fi Servire învechit, Purge, Origin Shield, Prefetch și Compression.
- Almanahul web: Adopția și utilizarea CDN oferă informații despre furnizorii de top CDN, gestionarea lor RTT și TLS, timpul de negociere TLS, adoptarea HTTP/2 și altele. (Din păcate, datele sunt doar din 2019).
Optimizări ale activelor
- Utilizați Brotli pentru comprimarea textului simplu.
În 2015, Google a introdus Brotli, un nou format de date open-source fără pierderi, care este acum acceptat în toate browserele moderne. Biblioteca Brotli cu sursă deschisă, care implementează un encoder și un decodor pentru Brotli, are 11 niveluri de calitate predefinite pentru encoder, cu un nivel de calitate mai ridicat care necesită mai mult CPU în schimbul unui raport de compresie mai bun. Comprimarea mai lentă va duce în cele din urmă la rate de compresie mai mari, totuși, Brotli se decomprimă rapid. De remarcat, totuși, Brotli cu nivelul de compresie 4 este mai mic și se comprimă mai repede decât Gzip.În practică, Brotli pare a fi mult mai eficient decât Gzip. Opiniile și experiențele diferă, dar dacă site-ul dvs. este deja optimizat cu Gzip, s-ar putea să vă așteptați la îmbunătățiri de cel puțin o singură cifră și, în cel mai bun caz, îmbunătățiri de două cifre în ceea ce privește reducerea dimensiunii și intervalele FCP. De asemenea, puteți estima economiile de compresie Brotli pentru site-ul dvs.
Browserele vor accepta Brotli numai dacă utilizatorul vizitează un site web prin HTTPS. Brotli este acceptat pe scară largă și multe CDN-uri îl acceptă (Akamai, Netlify Edge, AWS, KeyCDN, Fastly (în prezent doar ca un pass-through), Cloudflare, CDN77) și puteți activa Brotli chiar și pe CDN-uri care nu îl acceptă încă (cu un lucrător de service).
Problema este că, deoarece comprimarea tuturor activelor cu Brotli la un nivel de compresie ridicat este costisitoare, mulți furnizori de găzduire nu o pot folosi la scară largă doar din cauza costurilor uriașe pe care le produce. De fapt, la cel mai înalt nivel de compresie, Brotli este atât de lent încât orice câștig potențial în dimensiunea fișierului ar putea fi anulat de timpul necesar pentru ca serverul să înceapă să trimită răspunsul în timp ce așteaptă comprimarea dinamică a activului. (Dar dacă aveți timp în timpul construirii cu compresie statică, desigur, sunt de preferat setări de compresie mai mari.)
Compararea timpilor de back-end ale diferitelor metode de compresie. Deloc surprinzător, Brotli este mai lent decât gzip (deocamdată). (Previzualizare mare) Acest lucru s-ar putea schimba totuși. Formatul de fișier Brotli include un dicționar static încorporat și, pe lângă faptul că conține diverse șiruri în mai multe limbi, acceptă și opțiunea de a aplica mai multe transformări acelor cuvinte, sporind versatilitatea acestuia. În cercetările sale, Felix Hanau a descoperit o modalitate de a îmbunătăți compresia la nivelurile 5 până la 9, folosind „un subset mai specializat al dicționarului decât cel implicit” și bazându-se pe antetul
Content-Typepentru a spune compresorului dacă ar trebui să folosească un dicționar pentru HTML, JavaScript sau CSS. Rezultatul a fost „un impact neglijabil asupra performanței (cu 1% până la 3% mai mult CPU, comparativ cu 12% în mod normal) atunci când comprimați conținut web la niveluri ridicate de compresie, folosind o abordare limitată de utilizare a dicționarului”.
Cu abordarea îmbunătățită a dicționarului, putem comprima mai rapid elementele la niveluri de compresie mai ridicate, toate în timp ce utilizăm doar cu 1% până la 3% mai mult CPU. În mod normal, nivelul de compresie 6 peste 5 ar crește utilizarea procesorului cu până la 12%. (Previzualizare mare) În plus, cu cercetările Elenei Kirilenko, putem obține recomprimarea Brotli rapidă și eficientă folosind artefacte de compresie anterioare. Potrivit Elenei, „odată ce avem un activ comprimat prin Brotli și încercăm să comprimăm conținutul dinamic din mers, unde conținutul seamănă cu conținutul disponibil în avans, putem obține îmbunătățiri semnificative ale timpilor de compresie. "
Cât de des este cazul? De exemplu, cu livrarea de subseturi de pachete JavaScript (de exemplu, atunci când părți din cod sunt deja stocate în cache pe client sau cu pachetul dinamic de servire cu WebBundles). Sau cu HTML dinamic bazat pe șabloane cunoscute în avans sau fonturi WOFF2 subsetate dinamic . Potrivit Elenei, putem obține o îmbunătățire cu 5,3% la compresie și o îmbunătățire cu 39% la viteza de compresie atunci când eliminăm 10% din conținut și rate de compresie cu 3,2% mai bune și o compresie cu 26% mai rapidă, atunci când eliminăm 50% din conținut.
Compresia Brotli este din ce în ce mai bună, așa că dacă puteți ocoli costul comprimării dinamice a activelor statice, merită cu siguranță efortul. Este de la sine înțeles că Brotli poate fi folosit pentru orice încărcare de text simplu - HTML, CSS, SVG, JavaScript, JSON și așa mai departe.
Notă : de la începutul anului 2021, aproximativ 60% dintre răspunsurile HTTP sunt livrate fără compresie bazată pe text, cu 30,82% comprimare cu Gzip și 9,1% comprimare cu Brotli (atât pe mobil, cât și pe desktop). De exemplu, 23,4% din paginile Angular nu sunt comprimate (prin gzip sau Brotli). Cu toate acestea, deseori pornirea compresiei este una dintre cele mai ușoare câștiguri pentru a îmbunătăți performanța cu o simplă apăsare a unui comutator.
Strategia? Precomprimați elementele statice cu Brotli+Gzip la cel mai înalt nivel și comprimați HTML (dinamic) din mers cu Brotli la nivelul 4–6. Asigurați-vă că serverul gestionează corect negocierea conținutului pentru Brotli sau Gzip.
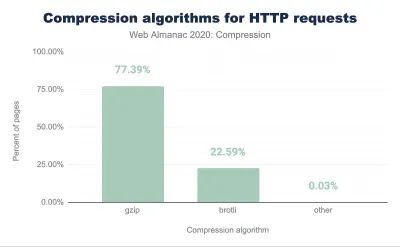
- Folosim încărcare media adaptivă și sugestii pentru clienți?
Vine din țara știrilor vechi, dar este întotdeauna un bun memento să folosiți imagini receptive cusrcset,sizesși elementul<picture>. În special pentru site-urile cu o amprentă media mare, putem face un pas mai departe cu încărcare media adaptivă (în acest exemplu React + Next.js), oferind o experiență ușoară pentru rețelele încetini și dispozitivele cu memorie redusă și experiență completă la rețea rapidă și înaltă. -dispozitive de memorie. În contextul React, îl putem realiza cu indicii de client pe server și cârlige adaptative de reactie pe client.Viitorul imaginilor receptive s-ar putea schimba dramatic odată cu adoptarea mai largă a sugestiilor clienților. Sugestiile clientului sunt câmpuri de antet de solicitare HTTP, de exemplu
DPR,Viewport-Width,Width,Save-Data,Accept(pentru a specifica preferințele de format de imagine) și altele. Aceștia ar trebui să informeze serverul despre specificul browserului utilizatorului, ecranului, conexiunii etc.Ca rezultat, serverul poate decide cum să completeze aspectul cu imagini de dimensiuni adecvate și să difuzeze numai aceste imagini în formatele dorite. Cu sugestii pentru client, mutăm selecția de resurse din marcajul HTML și în negocierea cerere-răspuns între client și server.
Serviciu media adaptiv în uz. Trimitem un substituent cu text utilizatorilor care sunt offline, o imagine cu rezoluție scăzută utilizatorilor 2G, o imagine de înaltă rezoluție utilizatorilor 3G și un videoclip HD utilizatorilor 4G. Prin încărcarea rapidă a paginilor web pe un telefon cu funcții de 20 USD. (Previzualizare mare) După cum a notat Ilya Grigorik cu ceva timp în urmă, sugestiile clienților completează imaginea - nu sunt o alternativă la imaginile receptive. „Elementul
<picture>oferă controlul necesar al direcției artistice în marcajul HTML. Sugestiile clientului oferă adnotări la solicitările de imagini rezultate care permit automatizarea selecției resurselor. Service Worker oferă capabilități complete de gestionare a cererilor și a răspunsurilor pe client.”Un lucrător de servicii ar putea, de exemplu, să adauge noi valori ale anteturilor de indicii pentru client la cerere, să rescrie adresa URL și să direcționeze cererea de imagine către un CDN, să adapteze răspunsul în funcție de conectivitate și preferințele utilizatorului etc. Este valabil nu numai pentru activele de imagine, ci și pentru pentru aproape toate celelalte cereri, de asemenea.
Pentru clienții care acceptă sugestii pentru clienți, s-ar putea măsura economii de 42% de octeți la imagini și cu 1MB+ octeți mai puțini pentru percentila 70+. Pe Smashing Magazine, am putea măsura și o îmbunătățire de 19-32%. Sugestiile pentru clienți sunt acceptate în browserele bazate pe Chromium, dar sunt încă luate în considerare în Firefox.
Cu toate acestea, dacă furnizați atât marcajul normal al imaginilor receptive, cât și eticheta
<meta>pentru Client Sugestii, atunci un browser compatibil va evalua marcarea imaginilor receptive și va solicita sursa de imagine adecvată utilizând anteturile HTTP Client Hints. - Folosim imagini receptive pentru imaginile de fundal?
Cu siguranță ar trebui! Cuimage-set, acum acceptat în Safari 14 și în majoritatea browserelor moderne, cu excepția Firefox, putem oferi și imagini de fundal receptive:background-image: url("fallback.jpg"); background-image: image-set( "photo-small.jpg" 1x, "photo-large.jpg" 2x, "photo-print.jpg" 600dpi);Practic, putem servi în mod condiționat imagini de fundal cu rezoluție scăzută cu un descriptor de
1xși imagini de rezoluție mai mare cu descriptor de2xși chiar o imagine la calitate de imprimare cu descriptor de600dpi. Atenție totuși: browserele nu oferă informații speciale despre imaginile de fundal pentru tehnologia de asistență, așa că în mod ideal, aceste fotografii ar fi doar un decor. - Folosim WebP?
Compresia imaginii este adesea considerată un câștig rapid, dar este încă foarte subutilizată în practică. Desigur, imaginile nu blochează redarea, dar contribuie în mare măsură la scorurile LCP slabe și, de multe ori, sunt prea grele și prea mari pentru dispozitivul pe care sunt consumate.Deci, cel puțin, am putea explora folosind formatul WebP pentru imaginile noastre. De fapt, saga WebP se apropie de sfârșit anul trecut, Apple adăugând suport pentru WebP în Safari 14. Deci, după mulți ani de discuții și dezbateri, de astăzi, WebP este acceptat în toate browserele moderne. Astfel, putem servi imagini WebP cu elementul
<picture>și un JPEG de rezervă dacă este necesar (a se vedea fragmentul de cod al lui Andreas Bovens) sau folosind negocierea conținutului (folosind anteteleAccept).Cu toate acestea, WebP nu este lipsit de dezavantaje . În timp ce dimensiunile fișierelor de imagine WebP în comparație cu echivalentele Guetzli și Zopfli, formatul nu acceptă randarea progresivă precum JPEG, motiv pentru care utilizatorii ar putea vedea imaginea finită mai repede cu un JPEG vechi, deși imaginile WebP ar putea deveni mai rapid prin rețea. Cu JPEG, putem oferi o experiență de utilizator „decentă” cu jumătate sau chiar un sfert din date și să încărcăm restul mai târziu, mai degrabă decât să avem o imagine pe jumătate goală, așa cum este în cazul WebP.
Decizia ta va depinde de ceea ce cauți: cu WebP, vei reduce sarcina utilă, iar cu JPEG vei îmbunătăți performanța percepută. Puteți afla mai multe despre WebP în WebP Rewind talk de la Pascal Massimino de la Google.
Pentru conversia în WebP, puteți utiliza WebP Converter, cwebp sau libwebp. Ire Aderinokun are și un tutorial foarte detaliat despre conversia imaginilor în WebP - la fel și Josh Comeau în lucrarea sa despre îmbrățișarea formatelor moderne de imagine.

O discuție amănunțită despre WebP: WebP Rewind de Pascal Massimino. (Previzualizare mare) Sketch acceptă în mod nativ WebP, iar imaginile WebP pot fi exportate din Photoshop utilizând un plugin WebP pentru Photoshop. Dar sunt disponibile și alte opțiuni.
Dacă utilizați WordPress sau Joomla, există extensii care vă ajută să implementați cu ușurință suport pentru WebP, cum ar fi Optimus și Cache Enabler pentru WordPress și extensia acceptată de Joomla (prin Cody Arsenault). De asemenea, puteți abstrage elementul
<picture>cu React, componente cu stil sau gatsby-image.Ah, priză nerușinată! — Jeremy Wagner a publicat chiar și o carte Smashing pe WebP, pe care ați putea dori să o verificați dacă sunteți interesat de tot ce este în jurul WebP.
- Folosim AVIF?
Poate ai auzit vestea cea mare: AVIF a aterizat. Este un nou format de imagine derivat din cadrele cheie ale videoclipului AV1. Este un format deschis, fără drepturi de autor, care acceptă compresie cu pierderi și fără pierderi, animație, canal alfa cu pierderi și poate gestiona linii clare și culori solide (ceea ce a fost o problemă cu JPEG), oferind în același timp rezultate mai bune la ambele.De fapt, în comparație cu WebP și JPEG, AVIF are performanțe semnificativ mai bune , producând economii de dimensiune medie a fișierului de până la 50% la același DSSIM ((dis)similaritate între două sau mai multe imagini folosind un algoritm care aproximează vederea umană). De fapt, în postarea sa amănunțită despre optimizarea încărcării imaginilor, Malte Ubl observă că AVIF „depășește în mod constant JPEG într-un mod foarte semnificativ. Acesta este diferit de WebP, care nu produce întotdeauna imagini mai mici decât JPEG și poate fi de fapt o rețea. pierdere din cauza lipsei de suport pentru încărcarea progresivă”.

Putem folosi AVIF ca o îmbunătățire progresivă, oferind WebP sau JPEG sau PNG browserelor mai vechi. (Previzualizare mare). Vedeți vizualizarea text simplu de mai jos. În mod ironic, AVIF poate funcționa chiar mai bine decât SVG-urile mari, deși, desigur, nu ar trebui să fie văzut ca un înlocuitor al SVG-urilor. Este, de asemenea, unul dintre primele formate de imagine care acceptă suport pentru culori HDR; oferind luminozitate mai mare, adâncime de biți de culoare și game de culori. Singurul dezavantaj este că, în prezent, AVIF nu acceptă decodarea progresivă a imaginii (încă?) și, similar cu Brotli, o codificare cu rată de compresie ridicată este în prezent destul de lentă, deși decodarea este rapidă.
AVIF este acceptat în prezent în Chrome, Firefox și Opera, iar suportul în Safari se așteaptă să vină în curând (întrucât Apple este membru al grupului care a creat AV1).
Atunci, care este cel mai bun mod de a difuza imagini în zilele noastre ? Pentru ilustrații și imagini vectoriale, SVG (comprimat) este, fără îndoială, cea mai bună alegere. Pentru fotografii, folosim metode de negociere a conținutului cu elementul
picture. Dacă AVIF este suportat, trimitem o imagine AVIF; dacă nu este cazul, revenim mai întâi la WebP, iar dacă nici WebP nu este acceptat, trecem la JPEG sau PNG ca alternativă (aplicând condițiile@mediadacă este necesar):<picture> <source type="image/avif"> <source type="image/webp"> <img src="image.jpg" alt="Photo" width="450" height="350"> </picture>Sincer, este mai probabil să folosim unele condiții în cadrul elementului
picturetotuși:<picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture><picture> <source type="image/avif" /> <source type="image/webp" /> <source type="image/jpeg" /> <img src="fallback-image.jpg" alt="Photo" width="450" height="350"> </picture>Puteți merge și mai departe schimbând imaginile animate cu imagini statice pentru clienții care optează pentru mai puțină mișcare cu
prefers-reduced-motion:<picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture><picture> <source media="(prefers-reduced-motion: reduce)" type="image/avif"></source> <source media="(prefers-reduced-motion: reduce)" type="image/jpeg"></source> <source type="image/avif"></source> <img src="motion.jpg" alt="Animated AVIF"> </picture>De-a lungul celor două luni, AVIF a câștigat destul de multă tracțiune:
- Putem testa alternativele WebP/AVIF în panoul de randare din DevTools.
- Putem folosi Squoosh, AVIF.io și libavif pentru a codifica, decoda, comprima și converti fișiere AVIF.
- Putem folosi componenta AVIF Preact a lui Jake Archibald care decodifică un fișier AVIF într-un lucrător și afișează rezultatul pe o pânză,
- Pentru a furniza AVIF numai browserelor compatibile, putem folosi un plugin PostCSS împreună cu un script 315B pentru a utiliza AVIF în declarațiile dvs. CSS.
- Putem livra progresiv noi formate de imagine cu CSS și Cloudlare Workers pentru a modifica în mod dinamic documentul HTML returnat, deducând informații din antetul de
acceptși apoi adăugați claselewebp/avifetc. după caz. - AVIF este deja disponibil în Cloudinary (cu limite de utilizare), Cloudflare acceptă AVIF în redimensionarea imaginii și puteți activa AVIF cu anteturi AVIF personalizate în Netlify.
- Când vine vorba de animație, AVIF funcționează la fel de bine ca
<img src=mp4>din Safari, depășind GIF și WebP în general, dar MP4 are totuși performanțe mai bune. - În general, pentru animații, AVC1 (h264) > HVC1 > WebP > AVIF > GIF, presupunând că browserele bazate pe Chromium vor accepta vreodată
<img src=mp4>. - Puteți găsi mai multe detalii despre AVIF în discuția AVIF pentru Next Generation Image Coding de Aditya Mavlankar de la Netflix și discuția The AVIF Image Format de Kornel Lesinski de la Cloudflare.
- O referință excelentă pentru tot ceea ce AVIF: postarea cuprinzătoare a lui Jake Archibald despre AVIF a aterizat.
Deci viitorul AVIF este atunci ? Jon Sneyers nu este de acord: AVIF are performanțe cu 60% mai slabe decât JPEG XL, un alt format gratuit și deschis dezvoltat de Google și Cloudinary. De fapt, JPEG XL pare să aibă performanțe mult mai bune la nivel general. Cu toate acestea, JPEG XL este încă în faza finală de standardizare și nu funcționează încă în niciun browser. (A nu se amesteca cu JPEG-XR de la Microsoft care vine de la vechiul Internet Explorer de 9 ori).
- Sunt JPEG/PNG/SVG optimizate corect?
Când lucrați la o pagină de destinație pe care este esențial ca o imagine de erou să se încarce extraordinar de rapid, asigurați-vă că JPEG-urile sunt progresive și comprimate cu mozJPEG (care îmbunătățește timpul de redare de pornire prin manipularea nivelurilor de scanare) sau Guetzli, sursă deschisă Google. codificatorul concentrându-se pe performanța perceptivă și utilizând învățările de la Zopfli și WebP. Singurul dezavantaj: timpii de procesare lenți (un minut de CPU per megapixel).Pentru PNG, putem folosi Pingo, iar pentru SVG, putem folosi SVGO sau SVGOMG. Și dacă trebuie să previzualizați rapid și să copiați sau să descărcați toate elementele SVG de pe un site web, svg-grabber poate face acest lucru și pentru dvs.
Fiecare articol de optimizare a imaginii ar spune acest lucru, dar păstrarea activelor vectoriale curate și strânse este întotdeauna demnă de menționat. Asigurați-vă că curățați activele neutilizate, eliminați metadatele inutile și reduceți numărul de puncte de cale în ilustrație (și, prin urmare, codul SVG). ( Mulțumesc, Jeremy! )
Există, de asemenea, instrumente online utile disponibile, totuși:
- Utilizați Squoosh pentru a comprima, redimensiona și manipula imaginile la nivelurile optime de compresie (cu pierderi sau fără pierderi),
- Utilizați Guetzli.it pentru a comprima și optimiza imaginile JPEG cu Guetzli, care funcționează bine pentru imagini cu margini ascuțite și culori solide (dar ar putea fi destul de lent)).
- Utilizați Generatorul de puncte de întrerupere a imaginii receptive sau un serviciu precum Cloudinary sau Imgix pentru a automatiza optimizarea imaginii. De asemenea, în multe cazuri, utilizarea
srcsetși asizesva aduce beneficii semnificative. - Pentru a verifica eficiența marcajului dvs. de răspuns, puteți utiliza imaging-heap, un instrument de linie de comandă care măsoară eficiența în dimensiunile ferestrelor de vizualizare și a raporturilor de pixeli ale dispozitivului.
- Puteți adăuga compresie automată a imaginii fluxurilor dvs. de lucru GitHub, astfel încât nicio imagine nu poate atinge producția necomprimată. Acțiunea folosește mozjpeg și libvips care funcționează cu PNG și JPG.
- Pentru a optimiza stocarea internă, puteți utiliza noul format Lepton al Dropbox pentru a comprima fără pierderi JPEG cu o medie de 22%.
- Utilizați BlurHash dacă doriți să afișați mai devreme o imagine de substituent. BlurHash preia o imagine și vă oferă un șir scurt (doar 20-30 de caractere!) care reprezintă substituentul pentru această imagine. Șirul este suficient de scurt încât să poată fi adăugat cu ușurință ca câmp într-un obiect JSON.
BlurHash este o reprezentare mică și compactă a unui substituent pentru o imagine. (Previzualizare mare) Uneori, doar optimizarea imaginilor nu va fi de folos. Pentru a îmbunătăți timpul necesar pentru a începe redarea unei imagini critice, încărcați leneș imaginile mai puțin importante și amânați încărcarea oricăror scripturi după ce imaginile critice au fost deja randate. Cea mai eficientă metodă este încărcarea leneră hibridă, când utilizăm încărcare leneră nativă și încărcare leneră, o bibliotecă care detectează orice modificări de vizibilitate declanșate prin interacțiunea utilizatorului (cu IntersectionObserver pe care îl vom explora mai târziu). În plus:
- Luați în considerare preîncărcarea imaginilor critice, astfel încât un browser să nu le descopere prea târziu. Pentru imaginile de fundal, dacă doriți să fiți și mai agresivi decât atât, puteți adăuga imaginea ca imagine obișnuită cu
<img src>și apoi o puteți ascunde de pe ecran. - Luați în considerare schimbarea imaginilor cu atributul Dimensiuni prin specificarea diferitelor dimensiuni de afișare a imaginii în funcție de interogările media, de exemplu pentru a manipula
sizespentru a schimba sursele într-o componentă de lupă. - Examinați inconsecvențele de descărcare a imaginilor pentru a preveni descărcările neașteptate pentru imaginile din prim-plan și din fundal. Atenție la imaginile care sunt încărcate implicit, dar care s-ar putea să nu fie afișate niciodată — de exemplu, în carusele, acordeoane și galerii de imagini.
- Asigurați-vă că setați întotdeauna
widthșiheightimaginilor. Atenție la proprietateaaspect-ratiodin CSS și atributulintrinsicsize, care ne va permite să setăm raporturi de aspect și dimensiuni pentru imagini, astfel încât browserul să poată rezerva mai devreme un spațiu de aspect predefinit pentru a evita săriturile de aspect în timpul încărcării paginii.
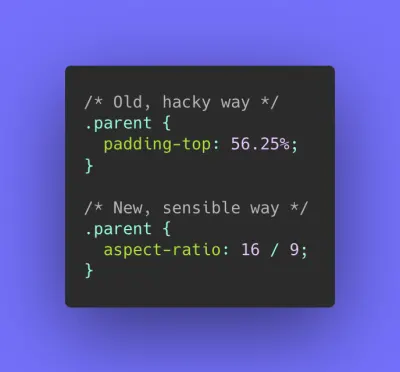
Ar trebui să fie doar o chestiune de săptămâni sau luni acum, cu aspect-ratio de aterizare în browsere. În Safari Technical Preview 118 deja. În prezent, în spatele steagului în Firefox și Chrome. (Previzualizare mare) Dacă vă simțiți aventuros, puteți tăia și rearanja fluxurile HTTP/2 folosind lucrătorii Edge, practic un filtru în timp real care trăiește pe CDN, pentru a trimite imagini mai rapid prin rețea. Lucrătorii Edge folosesc fluxuri JavaScript care folosesc bucăți pe care le puteți controla (în principiu sunt JavaScript care rulează pe marginea CDN, care poate modifica răspunsurile în flux), astfel încât să puteți controla livrarea imaginilor.
Cu un lucrător de service, este prea târziu, deoarece nu poți controla ceea ce este pe fir, dar funcționează cu lucrătorii Edge. Așa că le puteți folosi pe deasupra JPEG-urilor statice salvate progresiv pentru o anumită pagină de destinație.
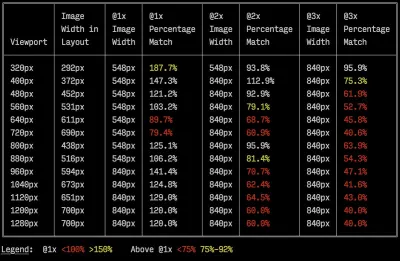
Un eșantion de ieșire de imaging-heap, un instrument de linie de comandă care măsoară eficiența în dimensiunile ferestrelor de vizualizare și a raporturilor de pixeli ale dispozitivului. (Sursa imagine) (Previzualizare mare) Nu indeajuns de bun? Ei bine, puteți îmbunătăți și performanța percepută pentru imagini cu tehnica imaginilor de fundal multiple. Rețineți că jocul cu contrast și estomparea detaliilor inutile (sau eliminarea culorilor) poate reduce și dimensiunea fișierului. Ah, trebuie să mărești o fotografie mică fără a pierde calitatea? Luați în considerare utilizarea Letsenhance.io.
Aceste optimizări acoperă până acum doar elementele de bază. Addy Osmani a publicat un ghid foarte detaliat despre Optimizarea esențială a imaginii, care intră foarte adânc în detalii despre compresia imaginii și gestionarea culorilor. De exemplu, ați putea estompa părțile inutile ale imaginii (prin aplicarea unui filtru de estompare gaussian) pentru a reduce dimensiunea fișierului și, în cele din urmă, puteți chiar să începeți să eliminați culorile sau să transformați imaginea în alb-negru pentru a reduce dimensiunea și mai mult. . Pentru imaginile de fundal, exportul fotografiilor din Photoshop cu o calitate de la 0 la 10% poate fi, de asemenea, absolut acceptabil.
Pe Smashing Magazine, folosim postfixul
-optpentru numele imaginilor - de exemplu,brotli-compression-opt.png; ori de câte ori o imagine conține acel postfix, toată lumea din echipă știe că imaginea a fost deja optimizată.Ah, și nu utilizați JPEG-XR pe web - „procesarea decodării JPEG-XR din partea software-ului pe CPU anulează și chiar depășește impactul potențial pozitiv al economisirii dimensiunii octetilor, mai ales în contextul SPA-urilor” (nu pentru a amesteca cu Cloudinary/JPEG XL de la Google).

- Videoclipurile sunt optimizate corect?
Am acoperit imagini până acum, dar am evitat o conversație despre vechile GIF-uri bune. În ciuda dragostei noastre pentru GIF-uri, este momentul să le abandonăm definitiv (cel puțin în site-urile și aplicațiile noastre). În loc să încărcați GIF-uri animate grele care afectează atât performanța de redare, cât și lățimea de bandă, este o idee bună să treceți fie la WebP animat (cu GIF-ul fiind o alternativă) sau să le înlocuiți cu videoclipuri HTML5 în buclă.Spre deosebire de imagini, browserele nu preîncarcă conținut
<video>, dar videoclipurile HTML5 tind să fie mult mai ușoare și mai mici decât GIF-urile. Nu este o opțiune? Ei bine, cel puțin putem adăuga compresie cu pierderi GIF-urilor cu GIF-uri Lossy, gifsicle sau giflossy.Testele efectuate de Colin Bendell arată că videoclipurile inline din etichetele
imgdin Safari Technology Preview se afișează cu cel puțin 20 de ori mai rapid și decodifică de 7 ori mai rapid decât echivalentul GIF, în plus față de o mică parte din dimensiunea fișierului. Cu toate acestea, nu este acceptat de alte browsere.În țara veștilor bune, formatele video au avansat masiv de-a lungul anilor. Multă vreme, am sperat că WebM va deveni formatul care să le conducă pe toate, iar WebP (care este practic o imagine statică în interiorul containerului video WebM) va deveni un înlocuitor pentru formatele de imagine datate. Într-adevăr, Safari acceptă acum WebP, dar în ciuda faptului că WebP și WebM au câștigat suport în aceste zile, descoperirea nu s-a întâmplat cu adevărat.
Totuși, am putea folosi WebM pentru majoritatea browserelor moderne de acolo:
<!-- By Houssein Djirdeh. https://web.dev/replace-gifs-with-videos/ --> <!-- A common scenartio: MP4 with a WEBM fallback. --> <video autoplay loop muted playsinline> <source src="my-animation.webm" type="video/webm"> <source src="my-animation.mp4" type="video/mp4"> </video>Dar poate că l-am revedea cu totul. În 2018, Alliance of Open Media a lansat un nou format video promițător numit AV1 . AV1 are compresie similară cu codecul H.265 (evoluția lui H.264), dar spre deosebire de acesta din urmă, AV1 este gratuit. Prețul licenței H.265 i-a împins pe furnizorii de browsere să adopte un AV1 comparabil în schimb: AV1 (la fel ca H.265) comprimă de două ori mai bine decât WebM .

AV1 are șanse mari să devină standardul suprem pentru video pe web. (Credit imagine: Wikimedia.org) (Previzualizare mare) De fapt, Apple folosește în prezent formatul HEIF și HEVC (H.265), iar toate fotografiile și videoclipurile de pe cel mai recent iOS sunt salvate în aceste formate, nu JPEG. În timp ce HEIF și HEVC (H.265) nu sunt expuse în mod corespunzător la web (încă?), AV1 este - și câștigă suport pentru browser. Prin urmare, adăugarea sursei
AV1în eticheta dvs.<video>este rezonabilă, deoarece toți furnizorii de browsere par să fie la bord.Deocamdată, cea mai utilizată și acceptată codificare este H.264, servită de fișiere MP4, așa că înainte de a servi fișierul, asigurați-vă că MP4-urile dvs. sunt procesate cu o codificare multipass, estompată cu efectul frei0r iirblur (dacă este cazul) și metadatele moov atom sunt mutate în capul fișierului, în timp ce serverul acceptă difuzarea octeților. Boris Schapira oferă instrucțiuni exacte pentru ca FFmpeg să optimizeze videoclipurile la maximum. Desigur, oferirea formatului WebM ca alternativă ar ajuta, de asemenea.
Trebuie să începeți să redați videoclipuri mai rapid, dar fișierele video sunt încă prea mari ? De exemplu, ori de câte ori aveți un videoclip de fundal mare pe o pagină de destinație? O tehnică obișnuită este să afișați primul cadru ca o imagine statică sau să afișați un segment de buclă scurt, puternic optimizat, care ar putea fi interpretat ca parte a videoclipului și apoi, ori de câte ori videoclipul este suficient de tamponat, începeți redarea videoclipul propriu-zis. Doug Sillars a scris un ghid detaliat pentru performanța video de fundal, care ar putea fi util în acest caz. ( Mulțumesc, Guy Podjarny! ).
Pentru scenariul de mai sus, este posibil să doriți să furnizați imagini de poster receptive . În mod implicit, elementele
videopermit doar o singură imagine ca poster, ceea ce nu este neapărat optim. Putem folosi Responsive Video Poster, o bibliotecă JavaScript care vă permite să utilizați diferite imagini de afiș pentru diferite ecrane, adăugând în același timp o suprapunere de tranziție și control complet de stil al substituenților video.Cercetarea arată că calitatea fluxului video are un impact asupra comportamentului spectatorilor. De fapt, spectatorii încep să abandoneze videoclipul dacă întârzierea de pornire depășește aproximativ 2 secunde. După acest punct, o creștere de 1 secundă a întârzierii are ca rezultat o creștere cu aproximativ 5,8% a ratei de abandon. Așa că nu este surprinzător faptul că timpul mediu de începere a videoclipului este de 12,8 s, cu 40% dintre videoclipuri având cel puțin 1 blocare și 20% cel puțin 2 secunde de redare video blocată. De fapt, blocajele video sunt inevitabile pe 3G, deoarece videoclipurile sunt redate mai repede decât poate furniza conținut de rețea.
Deci, care este soluția? De obicei, dispozitivele cu ecran mic nu pot gestiona 720p și 1080p pe care le oferim desktop-ului. Potrivit lui Doug Sillars, putem fie să creăm versiuni mai mici ale videoclipurilor noastre, fie să folosim Javascript pentru a detecta sursa pentru ecrane mai mici, pentru a asigura o redare rapidă și fluidă pe aceste dispozitive. Alternativ, putem folosi streaming video. Fluxurile video HLS vor livra dispozitivului un videoclip de dimensiuni adecvate - abstragând nevoia de a crea videoclipuri diferite pentru diferite ecrane. De asemenea, va negocia viteza rețelei și va adapta rata de biți video pentru viteza rețelei pe care o utilizați.
Pentru a evita risipa de lățime de bandă, am putea adăuga doar sursa video pentru dispozitivele care pot reda bine videoclipul. Alternativ, putem elimina atributul de
autoplaydin etichetavideoși putem folosi JavaScript pentru a inseraautoplaypentru ecrane mai mari. În plus, trebuie să adăugămpreload="none"pevideopentru a spune browserului să nu descarce niciunul dintre fișierele video până când nu are nevoie de fișier:<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Apoi putem viza în mod specific browserele care acceptă de fapt AV1:
<!-- Based on Doug Sillars's post. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ --> <video preload="none" playsinline muted loop width="1920" height="1080" poster="poster.jpg"> <source src="video.av1.mp4" type="video/mp4; codecs=av01.0.05M.08"> <source src="video.hevc.mp4" type="video/mp4; codecs=hevc"> <source src="video.webm" type="video/webm"> <source src="video.mp4" type="video/mp4"> </video>Apoi am putea adăuga din nou
autoplaypeste un anumit prag (de exemplu, 1000px):/* By Doug Sillars. https://dougsillars.com/2020/01/06/hiding-videos-on-the-mbile-web/ */ <script> window.onload = addAutoplay(); var videoLocation = document.getElementById("hero-video"); function addAutoplay() { if(window.innerWidth > 1000){ videoLocation.setAttribute("autoplay",""); }; } </script>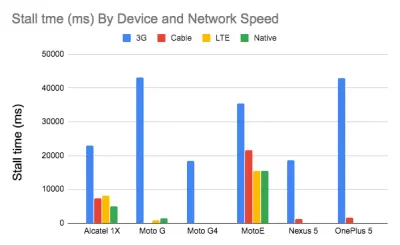
Numărul de blocări în funcție de dispozitiv și de viteza rețelei. Dispozitivele mai rapide din rețelele mai rapide practic nu au blocaje. Conform cercetărilor lui Doug Sillars. (Previzualizare mare) Performanța redării videoclipurilor este o poveste în sine și, dacă doriți să vă aprofundați în detalii, aruncați o privire la o altă serie a lui Doug Sillars despre Starea actuală a celor mai bune practici de difuzare video și video, care include detalii despre valorile de livrare video. , preîncărcare video, compresie și streaming. În cele din urmă, puteți verifica cât de lentă sau rapidă va fi fluxul video cu Stream or Not.
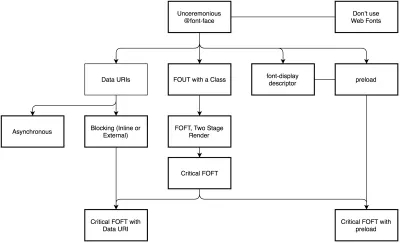
- Livrarea fonturilor web este optimizată?
The first question that's worth asking is if we can get away with using UI system fonts in the first place — we just need to make sure to double check that they appear correctly on various platforms. If it's not the case, chances are high that the web fonts we are serving include glyphs and extra features and weights that aren't being used. We can ask our type foundry to subset web fonts or if we are using open-source fonts, subset them on our own with Glyphhanger or Fontsquirrel. We can even automate our entire workflow with Peter Muller's subfont, a command line tool that statically analyses your page in order to generate the most optimal web font subsets, and then inject them into our pages.WOFF2 support is great, and we can use WOFF as fallback for browsers that don't support it — or perhaps legacy browsers could be served system fonts. There are many, many, many options for web font loading, and we can choose one of the strategies from Zach Leatherman's "Comprehensive Guide to Font-Loading Strategies," (code snippets also available as Web font loading recipes).
Probably the better options to consider today are Critical FOFT with
preloadand "The Compromise" method. Both of them use a two-stage render for delivering web fonts in steps — first a small supersubset required to render the page fast and accurately with the web font, and then load the rest of the family async. The difference is that "The Compromise" technique loads polyfill asynchronously only if font load events are not supported, so you don't need to load the polyfill by default. Need a quick win? Zach Leatherman has a quick 23-min tutorial and case study to get your fonts in order.In general, it might be a good idea to use the
preloadresource hint to preload fonts, but in your markup include the hints after the link to critical CSS and JavaScript. Withpreload, there is a puzzle of priorities, so consider injectingrel="preload"elements into the DOM just before the external blocking scripts. According to Andy Davies, "resources injected using a script are hidden from the browser until the script executes, and we can use this behaviour to delay when the browser discovers thepreloadhint." Otherwise, font loading will cost you in the first render time.
When everything is critical, nothing is critical. preload only one or a maximum of two fonts of each family. (Image credit: Zach Leatherman – slide 93) (Large preview) It's a good idea to be selective and choose files that matter most, eg the ones that are critical for rendering or that would help you avoiding visible and disruptive text reflows. In general, Zach advises to preload one or two fonts of each family — it also makes sense to delay some font loading if they are less critical.
It has become quite common to use
local()value (which refers to a local font by name) when defining afont-familyin the@font-facerule:/* Warning! Not a good idea! */ @font-face { font-family: Open Sans; src: local('Open Sans Regular'), local('OpenSans-Regular'), url('opensans.woff2') format ('woff2'), url('opensans.woff') format('woff'); }The idea is reasonable: some popular open-source fonts such as Open Sans are coming pre-installed with some drivers or apps, so if the font is available locally, the browser doesn't need to download the web font and can display the local font immediately. As Bram Stein noted, "though a local font matches the name of a web font, it most likely isn't the same font . Many web fonts differ from their "desktop" version. The text might be rendered differently, some characters may fall back to other fonts, OpenType features can be missing entirely, or the line height may be different."
Also, as typefaces evolve over time, the locally installed version might be very different from the web font, with characters looking very different. So, according to Bram, it's better to never mix locally installed fonts and web fonts in
@font-facerules. Google Fonts has followed suit by disablinglocal()on the CSS results for all users, other than Android requests for Roboto.Nobody likes waiting for the content to be displayed. With the
font-displayCSS descriptor, we can control the font loading behavior and enable content to be readable immediately (withfont-display: optional) or almost immediately (with a timeout of 3s, as long as the font gets successfully downloaded — withfont-display: swap). (Well, it's a bit more complicated than that.)However, if you want to minimize the impact of text reflows, we could use the Font Loading API (supported in all modern browsers). Specifically that means for every font, we'd creata a
FontFaceobject, then try to fetch them all, and only then apply them to the page. This way, we group all repaints by loading all fonts asynchronously, and then switch from fallback fonts to the web font exactly once. Take a look at Zach's explanation, starting at 32:15, and the code snippet):/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));/* Load two web fonts using JavaScript */ /* Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // Remove existing @font-face blocks // Create two let font = new FontFace("Noto Serif", /* ... */); let fontBold = new FontFace("Noto Serif, /* ... */); // Load two fonts let fonts = await Promise.all([ font.load(), fontBold.load() ]) // Group repaints and render both fonts at the same time! fonts.forEach(font => documents.fonts.add(font));To initiate a very early fetch of the fonts with Font Loading API in use, Adrian Bece suggests to add a non-breaking space
nbsp;at the top of thebody, and hide it visually witharia-visibility: hiddenand a.hiddenclass:<body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body><body class="no-js"> <!-- ... Website content ... --> <div aria-visibility="hidden" class="hidden"> <!-- There is a non-breaking space here --> </div> <script> document.getElementsByTagName("body")[0].classList.remove("no-js"); </script> </body>This goes along with CSS that has different font families declared for different states of loading, with the change triggered by Font Loading API once the fonts have successfully loaded:
body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }body:not(.wf-merriweather--loaded):not(.no-js) { font-family: [fallback-system-font]; /* Fallback font styles */ } .wf-merriweather--loaded, .no-js { font-family: "[web-font-name]"; /* Webfont styles */ } /* Accessible hiding */ .hidden { position: absolute; overflow: hidden; clip: rect(0 0 0 0); height: 1px; width: 1px; margin: -1px; padding: 0; border: 0; }If you ever wondered why despite all your optimizations, Lighthouse still suggests to eliminate render-blocking resources (fonts), in the same article Adrian Bece provides a few techniques to make Lighthouse happy, along with a Gatsby Omni Font Loader, a performant asynchronous font loading and Flash Of Unstyled Text (FOUT) handling plugin for Gatsby.
Now, many of us might be using a CDN or a third-party host to load web fonts from. In general, it's always better to self-host all your static assets if you can, so consider using google-webfonts-helper, a hassle-free way to self-host Google Fonts. And if it's not possible, you can perhaps proxy the Google Font files through the page origin.

It's worth noting though that Google is doing quite a bit of work out of the box, so a server might need a bit of tweaking to avoid delays ( thanks, Barry! )
This is quite important especially as since Chrome v86 (released October 2020), cross-site resources like fonts can't be shared on the same CDN anymore — due to the partitioned browser cache. This behavior was a default in Safari for years.
But if it's not possible at all, there is a way to get to the fastest possible Google Fonts with Harry Roberts' snippet:
<!-- By Harry Roberts. https://csswizardry.com/2020/05/the-fastest-google-fonts/ - 1. Preemptively warm up the fonts' origin. - 2. Initiate a high-priority, asynchronous fetch for the CSS file. Works in - most modern browsers. - 3. Initiate a low-priority, asynchronous fetch that gets applied to the page - only after it's arrived. Works in all browsers with JavaScript enabled. - 4. In the unlikely event that a visitor has intentionally disabled - JavaScript, fall back to the original method. The good news is that, - although this is a render-blocking request, it can still make use of the - preconnect which makes it marginally faster than the default. --> <!-- [1] --> <link rel="preconnect" href="https://fonts.gstatic.com" crossorigin /> <!-- [2] --> <link rel="preload" as="style" href="$CSS&display=swap" /> <!-- [3] --> <link rel="stylesheet" href="$CSS&display=swap" media="print" onload="this.media='all'" /> <!-- [4] --> <noscript> <link rel="stylesheet" href="$CSS&display=swap" /> </noscript>Harry's strategy is to pre-emptively warm up the fonts' origin first. Then we initiate a high-priority, asynchronous fetch for the CSS file. Afterwards, we initiate a low-priority, asynchronous fetch that gets applied to the page only after it's arrived (with a print stylesheet trick). Finally, if JavaScript isn't supported, we fall back to the original method.
Ah, talking about Google Fonts: you can shave up to 90% of the size of Google Fonts requests by declaring only characters you need with
&text. Plus, the support for font-display was added recently to Google Fonts as well, so we can use it out of the box.Un cuvânt rapid de precauție totuși. Dacă utilizați
font-display: optional, ar putea fi suboptim să utilizați șipreload, deoarece va declanșa acea solicitare de font web devreme (caucând congestionarea rețelei dacă aveți alte resurse de cale critică care trebuie preluate). Utilizațipreconnectpentru solicitări mai rapide de fonturi între origini, dar aveți grijă lapreload, deoarece preîncărcarea fonturilor de la o altă origine va genera conflicte în rețea. Toate aceste tehnici sunt acoperite în rețetele de încărcare a fonturilor web ale lui Zach.Pe de altă parte, ar putea fi o idee bună să renunțați la fonturile web (sau cel puțin randarea în a doua etapă) dacă utilizatorul a activat Reducerea mișcării în preferințele de accesibilitate sau a optat pentru Modul de economisire a datelor (consultați antetul
Save-Data) , sau când utilizatorul are o conectivitate lentă (prin intermediul API-ului pentru informații de rețea).De asemenea, putem folosi interogarea media CSS
prefers-reduced-datapentru a nu defini declarațiile de font dacă utilizatorul a optat pentru modul de salvare a datelor (există și alte cazuri de utilizare). Interogarea media ar expune practic dacă antetul cererii deSave-Datadin extensia HTTP Client Hint este activat/dezactivat pentru a permite utilizarea cu CSS. Momentan acceptat numai în Chrome și Edge în spatele unui steag.Valori? Pentru a măsura performanța de încărcare a fonturilor web, luați în considerare valoarea All Text Visible (momentul în care toate fonturile s-au încărcat și tot conținutul este afișat în fonturi web), Time to Real Italics, precum și Web Font Reflow Count după prima randare. Evident, cu cât ambele valori sunt mai mici, cu atât performanța este mai bună.
Ce zici de fonturile variabile , te-ai putea întreba? Este important de observat că fonturile variabile ar putea necesita o considerație semnificativă a performanței. Ele ne oferă un spațiu de design mult mai larg pentru alegeri tipografice, dar vine cu prețul unei singure solicitări în serie, spre deosebire de un număr de solicitări de fișiere individuale.
În timp ce fonturile variabile reduc drastic dimensiunea generală combinată a fișierelor cu fonturi, acea singură solicitare poate fi lentă, blocând redarea întregului conținut de pe o pagină. Deci subsetarea și împărțirea fontului în seturi de caractere încă contează. Pe partea bună, totuși, cu un font variabil, vom obține în mod implicit exact o redistribuire, așa că nu va fi necesar JavaScript pentru a grupa revopsirea.
Acum, ce ar face atunci o strategie de încărcare a fonturilor web antiglonț ? Subsetați fonturi și pregătiți-le pentru randarea în 2 etape, declarați-le cu un descriptor
font-display, utilizați API-ul de încărcare a fonturilor pentru a grupa revopsele și pentru a stoca fonturile în memoria cache a unui lucrător de serviciu persistent. La prima vizită, injectați preîncărcarea scripturilor chiar înainte de blocarea scripturilor externe. Dacă este necesar, puteți reveni la Font Face Observer al lui Bram Stein. Și dacă sunteți interesat să măsurați performanța încărcării fonturilor, Andreas Marschke explorează urmărirea performanței cu Font API și UserTiming API.În cele din urmă, nu uitați să includeți
unicode-rangepentru a descompune un font mare în fonturi mai mici specifice limbii și să utilizați funcția de potrivire a stilului de font al Monicai Dinculescu pentru a minimiza o schimbare neplăcută a aspectului, din cauza discrepanțelor de dimensionare dintre alternative și fonturi web.Alternativ, pentru a emula un font web pentru un font alternativ, putem folosi descriptori @font-face pentru a suprascrie valorile fontului (demo, activat în Chrome 87). (Rețineți că ajustările sunt complicate cu stivele complicate de fonturi.)
Viitorul pare luminos? Cu îmbogățirea progresivă a fontului, în cele din urmă s-ar putea să „descărcăm doar partea necesară a fontului pe orice pagină dată și, pentru solicitările ulterioare pentru acel font, să „corectăm” în mod dinamic descărcarea originală cu seturi suplimentare de glife, așa cum este necesar pe pagina succesivă. vederi”, după cum explică Jason Pamental. Demo de transfer incremental este deja disponibil și este în lucru.
Construiți optimizări
- Ne-am definit prioritățile?
Este o idee bună să știi mai întâi cu ce ai de-a face. Rulați un inventar al tuturor activelor dvs. (JavaScript, imagini, fonturi, scripturi de la terțe părți și module „scumpe” de pe pagină, cum ar fi carusele, infografice complexe și conținut multimedia) și împărțiți-le în grupuri.Configurați o foaie de calcul . Definiți experiența de bază de bază pentru browserele moștenite (adică conținut de bază complet accesibil), experiența îmbunătățită pentru browsere capabile (adică o experiență îmbogățită, completă) și extra -urile (materiale care nu sunt absolut necesare și care pot fi încărcate leneș, cum ar fi fonturi web, stiluri inutile, scripturi carusel, playere video, widget-uri pentru rețelele sociale, imagini mari). Cu ani în urmă, am publicat un articol despre „Îmbunătățirea performanței revistei Smashing”, care descrie această abordare în detaliu.
Când optimizăm pentru performanță, trebuie să ne reflectăm prioritățile. Încărcați imediat experiența de bază , apoi îmbunătățirile și apoi extrasele .
- Folosiți module JavaScript native în producție?
Vă amintiți tehnica bună de tăiere a muștarului pentru a trimite experiența de bază către browserele vechi și o experiență îmbunătățită către browserele moderne? O variantă actualizată a tehnicii ar putea folosi ES2017+<script type="module">, cunoscut și sub numele de model module/nomodule (introdus și de Jeremy Wagner ca servire diferențială ).Ideea este să compilați și să serviți două pachete JavaScript separate : versiunea „obișnuită”, cea cu transformări Babel și polyfills și să le serviți numai browserelor vechi care chiar au nevoie de ele și un alt pachet (aceeași funcționalitate) care nu are transformări sau poliumpluturi.
Drept urmare, ajutăm la reducerea blocării firului principal prin reducerea cantității de scripturi pe care browserul trebuie să le proceseze. Jeremy Wagner a publicat un articol cuprinzător despre servire diferențială și cum să o configurați în pipeline de construcție, de la configurarea Babel, până la ce ajustări va trebui să faceți în Webpack, precum și beneficiile de a face toată această muncă.
Scripturile native ale modulelor JavaScript sunt amânate în mod implicit, așa că în timp ce are loc parsarea HTML, browserul va descărca modulul principal.

Modulele native JavaScript sunt amânate în mod implicit. Aproape totul despre modulele JavaScript native. (Previzualizare mare) O notă de avertizare, totuși: modelul modul/modulul se poate întoarce împotriva unor clienți, așa că ar putea dori să luați în considerare o soluție: modelul de servire diferențial mai puțin riscant al lui Jeremy, care, totuși, ocolește scanerul de preîncărcare, ceea ce ar putea afecta performanța în moduri în care s-ar putea să nu anticipa. ( Multumesc, Jeremy! )
De fapt, Rollup acceptă module ca format de ieșire, astfel încât să putem să grupăm cod și să implementăm module în producție. Parcel are suport pentru module în Parcel 2. Pentru Webpack, module-nomodule-plugin automatizează generarea de scripturi module/nomodule.
Notă : merită să menționăm că numai detectarea caracteristicilor nu este suficientă pentru a lua o decizie în cunoștință de cauză cu privire la sarcina utilă de expediat către acel browser. Pe cont propriu, nu putem deduce capacitatea dispozitivului din versiunea browserului. De exemplu, telefoanele Android ieftine din țările în curs de dezvoltare rulează în cea mai mare parte Chrome și vor tăia muștarul, în ciuda capacităților lor limitate de memorie și CPU.
În cele din urmă, utilizând Antetul Sfaturi pentru clientul memoriei dispozitivului, vom putea ținti mai fiabil dispozitivele low-end. În momentul scrierii, antetul este acceptat doar în Blink (este valabil pentru indicii pentru clienți în general). Deoarece Device Memory are și un API JavaScript care este disponibil în Chrome, o opțiune ar putea fi detectarea caracteristicilor pe baza API-ului și revenirea la modelul modul/modulul dacă nu este acceptat ( mulțumesc, Yoav! ).
- Folosiți scuturarea copacilor, ridicarea lunetei și împărțirea codului?
Tree-shaking este o modalitate de a vă curăța procesul de construire prin includerea doar a codului care este utilizat efectiv în producție și prin eliminarea importurilor neutilizate în Webpack. Cu Webpack și Rollup, avem, de asemenea, ridicarea domeniului care permite ambelor instrumente să detecteze unde înlănțuirea deimportpoate fi aplatizată și convertită într-o singură funcție integrată fără a compromite codul. Cu Webpack, putem folosi și JSON Tree Shaking.Divizarea codului este o altă caracteristică Webpack care împarte baza de cod în „bucăți” care sunt încărcate la cerere. Nu tot JavaScript trebuie descărcat, analizat și compilat imediat. Odată ce definiți punctele de împărțire în codul dvs., Webpack se poate ocupa de dependențe și fișierele rezultate. Vă permite să păstrați descărcarea inițială mică și să solicitați cod la cerere atunci când este solicitat de aplicație. Alexander Kondrov are o introducere fantastică în divizarea codului cu Webpack și React.
Luați în considerare utilizarea preload-webpack-plugin care ia rutele pe care le-ați împărțit prin cod și apoi solicită browserului să le preîncarce folosind
<link rel="preload">sau<link rel="prefetch">. Directivele Webpack inline oferă, de asemenea, un anumit control asuprapreload/prefetch. (Atenție totuși la problemele de prioritizare.)Unde să definiți punctele de împărțire? Urmărind ce fragmente de CSS/JavaScript sunt folosite și care nu. Umar Hansa explică cum puteți utiliza Code Coverage de la Devtools pentru a realiza acest lucru.
Când avem de-a face cu aplicații cu o singură pagină, avem nevoie de ceva timp pentru a inițializa aplicația înainte de a putea reda pagina. Setarea dvs. va necesita soluția dvs. personalizată, dar puteți fi atenți la module și tehnici pentru a accelera timpul inițial de randare. De exemplu, iată cum să depanați performanța React și să eliminați problemele comune de performanță React și iată cum să îmbunătățiți performanța în Angular. În general, cele mai multe probleme de performanță provin din momentul inițial de pornire a aplicației.
Deci, care este cel mai bun mod de a împărți codul agresiv, dar nu prea agresiv? Potrivit lui Phil Walton, „pe lângă împărțirea codului prin importuri dinamice, [am putea] folosi și împărțirea codului la nivel de pachet , în care fiecare module de nod importate sunt puse într-o bucată în funcție de numele pachetului său.” Phil oferă și un tutorial despre cum să-l construiți.
- Putem îmbunătăți rezultatul Webpack-ului?
Deoarece Webpack este adesea considerat a fi misterios, există o mulțime de pluginuri Webpack care pot fi utile pentru a reduce și mai mult producția Webpack. Mai jos sunt câteva dintre cele mai obscure care ar putea avea nevoie de puțină atenție.Una dintre cele interesante vine din firul lui Ivan Akulov. Imaginați-vă că aveți o funcție pe care o apelați o dată, stocați rezultatul într-o variabilă și apoi nu utilizați acea variabilă. Tree-shaking va elimina variabila, dar nu și funcția, deoarece ar putea fi folosită altfel. Cu toate acestea, dacă funcția nu este folosită nicăieri, poate doriți să o eliminați. Pentru a face acest lucru, înaintează apelul funcției cu
/*#__PURE__*/care este susținut de Uglify și Terser - gata!
Pentru a elimina o astfel de funcție atunci când rezultatul ei nu este utilizat, adăugați înainte apelul funcției cu /*#__PURE__*/. Via Ivan Akulov. (Previzualizare mare)Iată câteva dintre celelalte instrumente pe care Ivan le recomandă:
- purgecss-webpack-plugin elimină clasele neutilizate, mai ales când utilizați Bootstrap sau Tailwind.
- Activați
optimization.splitChunks: 'all'cu plugin-ul split-chunks. Acest lucru ar face ca pachetul web să împartă automat pachetele de intrare pentru o mai bună stocare în cache. - Setați
optimization.runtimeChunk: true. Acest lucru ar muta durata de rulare a pachetului web într-o bucată separată - și ar îmbunătăți, de asemenea, stocarea în cache. - google-fonts-webpack-plugin descarcă fișiere cu fonturi, astfel încât să le puteți servi de pe serverul dvs.
- workbox-webpack-plugin vă permite să generați un service worker cu o configurație de precaching pentru toate activele dvs. webpack. De asemenea, consultați Service Worker Packages, un ghid cuprinzător de module care ar putea fi aplicat imediat. Sau utilizați preload-webpack-plugin pentru a genera
preload/prefetchpentru toate fragmentele JavaScript. - speed-measure-webpack-plugin măsoară viteza de construire a pachetului web, oferind informații despre pașii procesului de construire care consumă cel mai mult timp.
- duplicate-package-checker-webpack-plugin avertizează când pachetul tău conține mai multe versiuni ale aceluiași pachet.
- Utilizați izolarea domeniului și scurtați numele claselor CSS în mod dinamic în momentul compilării.
- Puteți descărca JavaScript într-un Web Worker?
Pentru a reduce impactul negativ asupra Time-to-Interactive, ar putea fi o idee bună să analizați posibilitatea de a descărca JavaScript grele într-un Web Worker.Pe măsură ce baza de cod continuă să crească, blocajele de performanță a UI vor apărea, încetinind experiența utilizatorului. Asta pentru că operațiunile DOM rulează împreună cu JavaScript în firul principal. Cu lucrătorii web, putem muta aceste operațiuni costisitoare într-un proces de fundal care rulează pe un fir diferit. Cazurile de utilizare tipice pentru lucrătorii web sunt preluarea în prealabil a datelor și aplicațiile web progresive pentru a încărca și stoca unele date în avans, astfel încât să le puteți utiliza mai târziu, atunci când este necesar. Și puteți folosi Comlink pentru a eficientiza comunicarea dintre pagina principală și lucrător. Mai e ceva de făcut, dar ajungem acolo.
Există câteva studii de caz interesante despre lucrătorii web care arată diferite abordări de mutare a cadrului și a logicii aplicației către lucrătorii web. Concluzia: în general, există încă unele provocări, dar există deja câteva cazuri bune de utilizare ( mulțumesc, Ivan Akulov! ).
Pornind de la Chrome 80, a fost livrat un nou mod pentru lucrătorii web cu beneficii de performanță ale modulelor JavaScript, numit lucrători de module. Putem modifica încărcarea și execuția scriptului pentru a se potrivi cu
script type="module", plus putem folosi și importuri dinamice pentru codul de încărcare leneră fără a bloca execuția lucrătorului.Cum să începeți? Iată câteva resurse care merită analizate:
- Surma a publicat un ghid excelent despre cum să rulați JavaScript din firul principal al browserului și, de asemenea, când ar trebui să utilizați Web Workers?
- De asemenea, verificați discuția lui Surma despre arhitectura firului principal.
- A Quest to Guarantee Responsiveness de Shubhie Panicker și Jason Miller oferă o perspectivă detaliată asupra modului de utilizare a lucrătorilor web și când să îi evite.
- Ieșirea din calea utilizatorilor: mai puțin Jank cu lucrătorii web evidențiază modele utile pentru lucrul cu lucrătorii web, modalități eficiente de comunicare între lucrători, gestionarea procesării complexe a datelor din firul principal și testarea și depanarea acestora.
- Workerize vă permite să mutați un modul într-un Web Worker, reflectând automat funcțiile exportate ca proxy asincron.
- Dacă utilizați Webpack, puteți folosi workerize-loader. Alternativ, puteți utiliza și pluginul pentru lucrător.

Folosiți lucrătorii web atunci când codul se blochează pentru o lungă perioadă de timp, dar evitați-i când vă bazați pe DOM, gestionați răspunsul la intrare și aveți nevoie de întârziere minimă. (prin Addy Osmani) (previzualizare mare) Rețineți că lucrătorii web nu au acces la DOM, deoarece DOM-ul nu este „sigur pentru fire”, iar codul pe care îl execută trebuie să fie conținut într-un fișier separat.
- Puteți descărca „căi fierbinți” în WebAssembly?
Am putea descărca sarcini grele din punct de vedere computațional în WebAssembly ( WASM ), un format de instrucțiuni binar, conceput ca o țintă portabilă pentru compilarea limbajelor de nivel înalt precum C/C++/Rust. Suportul său pentru browser este remarcabil și a devenit recent viabil, deoarece apelurile de funcții dintre JavaScript și WASM devin mai rapide. În plus, este acceptat chiar și pe edge cloud-ul Fastly.Desigur, WebAssembly nu ar trebui să înlocuiască JavaScript, dar îl poate completa în cazurile în care observați probleme CPU. Pentru majoritatea aplicațiilor web, JavaScript se potrivește mai bine, iar WebAssembly este cel mai bine utilizat pentru aplicațiile web cu utilizare intensivă de calcul , cum ar fi jocurile.
Dacă doriți să aflați mai multe despre WebAssembly:
- Lin Clark a scris o serie detaliată pentru WebAssembly, iar Milica Mihajlija oferă o prezentare generală a modului de rulare a codului nativ în browser, de ce ați putea dori să faceți asta și ce înseamnă totul pentru JavaScript și viitorul dezvoltării web.
- Cum am folosit WebAssembly pentru a accelera aplicația noastră web până la 20X (studiu de caz) evidențiază un studiu de caz despre modul în care calculele JavaScript lente au fost înlocuite cu WebAssembly compilat și au adus îmbunătățiri semnificative de performanță.
- Patrick Hamann a vorbit despre rolul din ce în ce mai mare al WebAssembly și el dezmintă unele mituri despre WebAssembly, explorează provocările sale și îl putem folosi practic în aplicații de astăzi.
- Google Codelabs oferă o Introducere în WebAssembly, un curs de 60 de minute în care veți învăța cum să luați cod nativ — în C și să îl compilați în WebAssembly, apoi să îl apelați direct din JavaScript.
- Alex Danilo a explicat WebAssembly și cum funcționează în cadrul discuției sale Google I/O. De asemenea, Benedek Gagyi a împărtășit un studiu de caz practic despre WebAssembly, în special modul în care echipa îl folosește ca format de ieșire pentru baza de cod C++ către iOS, Android și site-ul web.
Încă nu sunteți sigur când să utilizați Web Workers, Web Assembly, fluxuri sau poate API-ul JavaScript WebGL pentru a accesa GPU? Accelerarea JavaScript este un ghid scurt, dar util, care explică când să folosiți ce și de ce, de asemenea, cu o diagramă de flux la îndemână și o mulțime de resurse utile.
- Servim cod vechi doar browserelor vechi?
Având în vedere că ES2017 este remarcabil de bine acceptat în browserele moderne, putem folosibabelEsmPlugindoar pentru a transpila funcțiile ES2017+ neacceptate de browserele moderne pe care le vizați.Houssein Djirdeh și Jason Miller au publicat recent un ghid cuprinzător despre cum să transpilați și să serviți JavaScript modern și vechi, intrând în detalii despre cum să funcționeze cu Webpack și Rollup și cu instrumentele necesare. De asemenea, puteți estima cât de mult JavaScript puteți reduce pe site-ul sau pachetele de aplicații.
Modulele JavaScript sunt acceptate în toate browserele majore, așa că utilizați
script type="module"pentru a permite browserelor cu suport modul ES să încarce fișierul, în timp ce browserele mai vechi ar putea încărca versiuni vechi cuscript nomodule.În zilele noastre putem scrie JavaScript bazat pe module care rulează nativ în browser, fără transpilere sau bundlere.
<link rel="modulepreload">oferă o modalitate de a iniția încărcarea timpurie (și prioritară) a scripturilor modulelor. Practic, este o modalitate ingenioasă de a ajuta la maximizarea utilizării lățimii de bandă, spunând browserului ce trebuie să preia, astfel încât să nu rămână blocat cu nimic de făcut în timpul acestor călătorii lungi dus-întors. De asemenea, Jake Archibald a publicat un articol detaliat cu probleme și lucruri de reținut cu modulele ES care merită citite.
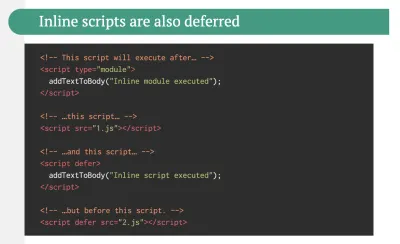
- Identificați și rescrieți codul vechi cu decuplare incrementală .
Proiectele de lungă durată au tendința de a aduna praf și cod datat. Revizuiți-vă dependențele și evaluați cât timp ar fi necesar pentru a refactoriza sau rescrie codul moștenit care a cauzat probleme în ultima vreme. Desigur, este întotdeauna o activitate mare, dar odată ce cunoașteți impactul codului moștenit, puteți începe cu decuplarea incrementală.Mai întâi, configurați valori care urmăresc dacă raportul dintre apelurile de cod vechi rămâne constant sau scade, nu crește. Descurajați în mod public echipa să folosească biblioteca și asigurați-vă că CI alertează dezvoltatorii dacă este folosit în cererile de extragere. polyfills ar putea ajuta la tranziția de la codul moștenit la o bază de cod rescrisă care utilizează caracteristici standard ale browserului.
- Identificați și eliminați CSS/JS neutilizat .
Acoperirea codului CSS și JavaScript în Chrome vă permite să aflați ce cod a fost executat/aplicat și care nu. Puteți începe să înregistrați acoperirea, să efectuați acțiuni pe o pagină și apoi să explorați rezultatele acoperirii codului. Odată ce ați detectat codul neutilizat, găsiți acele module și încărcați leneș cuimport()(vezi întregul fir). Apoi repetați profilul de acoperire și confirmați că acum trimite mai puțin cod la încărcarea inițială.Puteți folosi Puppeteer pentru a colecta în mod programatic acoperirea codului. Chrome vă permite și să exportați rezultatele acoperirii codului. După cum a remarcat Andy Davies, este posibil să doriți să colectați acoperire de cod atât pentru browserele moderne, cât și pentru cele vechi.
Există multe alte cazuri de utilizare și instrumente pentru Puppetter care ar putea avea nevoie de puțin mai multă expunere:
- Cazuri de utilizare pentru Puppeteer, cum ar fi, de exemplu, diferența vizuală automată sau monitorizarea CSS neutilizate cu fiecare construcție,
- Rețete de performanță web cu Puppeteer,
- Instrumente utile pentru înregistrarea și generarea de scenarii de pupisar și dramaturg,
- În plus, puteți chiar să înregistrați teste chiar în DevTools,
- Prezentare de ansamblu a Puppeteer de Nitay Neeman, cu exemple și cazuri de utilizare.
Putem folosi Puppeteer Recorder și Puppeteer Sandbox pentru a înregistra interacțiunea cu browserul și pentru a genera scenarii Puppeteer și Playwright. (Previzualizare mare) În plus, purgecss, UnCSS și Helium vă pot ajuta să eliminați stilurile neutilizate din CSS. Și dacă nu sunteți sigur dacă o bucată de cod suspectă este folosită undeva, puteți urma sfatul lui Harry Roberts: creați un GIF transparent de 1×1px pentru o anumită clasă și plasați-l într-un director
dead/, de exemplu/assets/img/dead/comments.gif.După aceea, setați acea imagine specifică ca fundal pe selectorul corespunzător din CSS, stați pe loc și așteptați câteva luni dacă fișierul va apărea în jurnalele dvs. Dacă nu există intrări, nimeni nu a avut acea componentă moștenită redată pe ecran: probabil că puteți continua și ștergeți totul.
Pentru departamentul I-feel-adventurous , puteți chiar să automatizați strângerea pe CSS neutilizate printr-un set de pagini prin monitorizarea DevTools folosind DevTools.
- Decupați dimensiunea pachetelor dvs. JavaScript.
După cum a remarcat Addy Osmani, există șanse mari să expediați biblioteci JavaScript complete atunci când aveți nevoie doar de o fracțiune, împreună cu polyfill-uri datate pentru browserele care nu au nevoie de ele sau doar cod duplicat. Pentru a evita suprasolicitarea, luați în considerare utilizarea webpack-libs-optimizations care elimină metodele neutilizate și polyfill-urile în timpul procesului de construire.Verificați și examinați polyfill -urile pe care le trimiteți către browserele vechi și către browserele moderne și fiți mai strategic în privința acestora. Aruncă o privire la polyfill.io, care este un serviciu care acceptă o solicitare pentru un set de caracteristici ale browserului și returnează numai polyfill-urile necesare browserului solicitant.
Adăugați și auditarea pachetului în fluxul de lucru obișnuit. S-ar putea să existe câteva alternative ușoare la bibliotecile grele pe care le-ați adăugat cu ani în urmă, de exemplu Moment.js (acum întrerupt) ar putea fi înlocuit cu:
- Native Internationalization API,
- Day.js cu un API Moment.js familiar și modele,
- data-fns sau
- Luxon.
- De asemenea, puteți utiliza Skypack Discover care combină recomandările de pachete revizuite de oameni cu o căutare axată pe calitate.
Cercetările lui Benedikt Rotsch au arătat că o trecere de la Moment.js la date-fns ar putea reduce aproximativ 300 ms pentru First paint pe 3G și un telefon mobil low-end.
Pentru auditarea pachetului, Bundlephobia ar putea ajuta la găsirea costului adăugării unui pachet npm la pachet. size-limit extinde verificarea de bază a dimensiunii pachetului cu detalii despre timpul de execuție JavaScript. Puteți chiar să integrați aceste costuri cu un audit personalizat Lighthouse. Acest lucru este valabil și pentru cadre. Prin îndepărtarea sau tăierea adaptorului Vue MDC (componente materiale pentru Vue), stilurile scad de la 194 KB la 10 KB.
Există multe instrumente suplimentare care vă ajută să luați o decizie informată cu privire la impactul dependențelor dvs. și al alternativelor viabile:
- webpack-bundle-analyzer
- Explorer Map Sursă
- Pachet Buddy
- Bundlephobia
- Analiza Webpack arată de ce un anumit modul este inclus în pachet.
- bundle-wizard construiește și o hartă a dependențelor pentru întreaga pagină.
- Webpack size-plugin
- Costul de import pentru codul vizual
Alternativ, la livrarea întregului cadru, ați putea să vă tăiați cadrul și să-l compilați într-un pachet JavaScript brut care nu necesită cod suplimentar. Svelte o face, la fel și pluginul Rawact Babel care transpilează componentele React.js în operațiunile DOM native în timpul construirii. De ce? Ei bine, așa cum explică menținătorii, „react-dom include cod pentru fiecare componentă/Element HTML posibil care poate fi randat, inclusiv cod pentru randarea incrementală, programarea, gestionarea evenimentelor etc. Dar există aplicații care nu au nevoie de toate aceste caracteristici (la început încărcarea paginii). Pentru astfel de aplicații, ar putea avea sens să folosiți operațiuni DOM native pentru a construi interfața interactivă cu utilizatorul."
- Folosim hidratare parțială?
Având în vedere cantitatea de JavaScript folosită în aplicații, trebuie să găsim modalități de a trimite cât mai puțin posibil către client. O modalitate de a face acest lucru - și am tratat-o deja pe scurt - este hidratarea parțială. Ideea este destul de simplă: în loc să facem SSR și apoi să trimiteți întreaga aplicație către client, doar bucăți mici din JavaScript-ul aplicației ar fi trimise clientului și apoi hidratate. Ne putem gândi la asta ca la mai multe aplicații React minuscule cu mai multe rădăcini de randare pe un site web altfel static.În articolul „Cazul hidratării parțiale (cu Next și Preact)”, Lukas Bombach explică modul în care echipa din spatele Welt.de, unul dintre posturile de știri din Germania, a obținut performanțe mai bune cu hidratarea parțială. De asemenea, puteți verifica următorul depozit GitHub de super-performanță cu explicații și fragmente de cod.
De asemenea, puteți lua în considerare opțiuni alternative:
- hidratare parțială cu Preact și Eleventy,
- hidratare progresivă în React GitHub repo,
- hidratare leneșă în Vue.js (repoziție GitHub),
- Importați pe modelul de interacțiune pentru a încărca lene resursele non-critice (de exemplu, componente, încorporare) atunci când un utilizator interacționează cu UI care are nevoie de el.
Jason Miller a publicat demonstrații de lucru despre cum ar putea fi implementată hidratarea progresivă cu React, astfel încât să le puteți folosi imediat: demo 1, demo 2, demo 3 (disponibil și pe GitHub). În plus, poți să te uiți în biblioteca de componente react-pre-rendată.
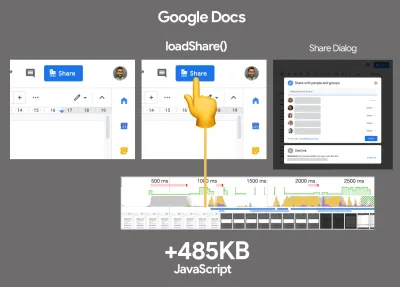
Importarea la interacțiune pentru codul primar ar trebui făcută numai dacă nu puteți prelua resursele înainte de interacțiune. (Previzualizare mare) - Am optimizat strategia pentru React/SPA?
Te lupți cu performanța în aplicația ta cu o singură pagină? Jeremy Wagner a explorat impactul performanței cadrului la nivelul clientului asupra unei varietăți de dispozitive, evidențiind unele dintre implicațiile și liniile directoare de care ar putea dori să fim conștienți atunci când folosim unul.Ca rezultat, iată o strategie SPA pe care Jeremy sugerează să o folosească pentru framework-ul React (dar nu ar trebui să se schimbe semnificativ pentru alte cadre):
- Refactorizați componentele cu stare ca componente fără stat ori de câte ori este posibil.
- Predați componentele apatride atunci când este posibil pentru a minimiza timpul de răspuns al serverului. Redați doar pe server.
- Pentru componentele stateful cu interactivitate simplă, luați în considerare randarea anterioară sau redarea pe server a acelei componente și înlocuiți interactivitatea acesteia cu ascultători de evenimente independenți de cadru .
- Dacă trebuie să hidratați componentele cu stare asupra clientului, utilizați hidratarea leneșă pentru vizibilitate sau interacțiune.
- Pentru componentele hidratate leneș, programați hidratarea lor în timpul inactiv al firului principal cu
requestIdleCallback.
Există alte câteva strategii pe care ați putea dori să le urmați sau să le revizuiți:
- Considerații de performanță pentru CSS-in-JS în aplicațiile React
- Reduceți dimensiunea pachetului Next.js încărcând polyfills numai atunci când este necesar, folosind importuri dinamice și hidratare leneșă.
- Secretele JavaScript: O poveste despre React, Optimizarea performanței și Multi-threading, o serie lungă de 7 părți despre îmbunătățirea provocărilor interfeței cu utilizatorul cu React,
- Cum să măsurați performanța React și Cum să profilați aplicațiile React.
- Crearea de animații web pe mobil în React, o discuție fantastică a lui Alex Holachek, împreună cu diapozitive și depozit GitHub ( mulțumesc pentru sfat, Addy! ).
- webpack-libs-optimizations este un depozit GitHub fantastic, cu o mulțime de optimizări utile legate de performanță specifice Webpack-ului. Menținută de Ivan Akulov.
- Îmbunătățirile de performanță React în Notion, un ghid de Ivan Akulov despre cum să îmbunătățiți performanța în React, cu o mulțime de indicații utile pentru a face aplicația cu aproximativ 30% mai rapidă.
- Pluginul React Refresh Webpack (experimental) permite reîncărcarea la cald care păstrează starea componentelor și acceptă cârlige și componente funcționale.
- Atenție la Componentele React Server de dimensiune zero a pachetului, un nou tip de componente propuse care nu vor avea niciun impact asupra dimensiunii pachetului. Proiectul este în prezent în curs de dezvoltare, dar orice feedback din partea comunității este foarte apreciat (explicator excelent de către Sophie Alpert).
- Utilizați preîncărcarea predictivă pentru fragmentele JavaScript?
Am putea folosi euristica pentru a decide când să preîncărcăm fragmentele JavaScript. Guess.js este un set de instrumente și biblioteci care utilizează datele Google Analytics pentru a determina ce pagină este cel mai probabil să o acceseze un utilizator dintr-o anumită pagină. Pe baza modelelor de navigare ale utilizatorilor colectate din Google Analytics sau din alte surse, Guess.js construiește un model de învățare automată pentru a prezice și a prelua în prealabil JavaScript care va fi necesar pe fiecare pagină ulterioară.Prin urmare, fiecare element interactiv primește un scor de probabilitate pentru implicare și, pe baza acestui scor, un script la nivelul clientului decide să prealizeze o resursă din timp. Puteți integra tehnica în aplicația dvs. Next.js, Angular și React, și există un plugin Webpack care automatizează și procesul de configurare.
Evident, este posibil să solicitați browserului să consume date inutile și să prelueze pagini nedorite, așa că este o idee bună să fiți destul de conservatori în ceea ce privește numărul de solicitări preîncărcate. Un caz de utilizare bun ar fi preluarea prealabilă a scripturilor de validare necesare la finalizarea plății sau preluarea prealabilă speculativă atunci când apare un îndemn critic în fereastra de vizualizare.
Ai nevoie de ceva mai puțin sofisticat? DNStradamus efectuează preîncărcarea DNS pentru legăturile de ieșire, așa cum apar în fereastra de vizualizare. Quicklink, InstantClick și Instant.page sunt biblioteci mici care preiau automat link -urile în fereastra de vizualizare în timpul inactiv, în încercarea de a face navigarea în pagina următoare să se încarce mai rapid. Quicklink permite preluarea prealabilă a rutelor React Router și Javascript; în plus, are în vedere datele, deci nu se prealează pe 2G sau dacă
Data-Savereste activat. La fel este Instant.page dacă modul este setat să utilizeze preîncărcarea viewportului (care este implicit).Dacă doriți să vă uitați în știința preluării predictive în detaliu, Divya Tagtachian are o discuție grozavă despre The Art of Predictive Prefetch, acoperind toate opțiunile de la început până la sfârșit.
- Profitați de optimizările pentru motorul JavaScript țintă.
Studiați ce motoarele JavaScript domină în baza dvs. de utilizatori, apoi explorați modalități de optimizare pentru ele. De exemplu, atunci când optimizați pentru V8, care este folosit în browserele Blink, runtime Node.js și Electron, utilizați fluxul de scripturi pentru scripturi monolitice.Fluxul de scripturi permite ca
defer scriptsasyncsau amânate să fie analizate pe un fir separat de fundal odată ce începe descărcarea, prin urmare, în unele cazuri, se îmbunătățește timpii de încărcare a paginii cu până la 10%. Practically, use<script defer>in the<head>, so that the browsers can discover the resource early and then parse it on the background thread.Caveat : Opera Mini doesn't support script deferment, so if you are developing for India or Africa,
deferwill be ignored, resulting in blocking rendering until the script has been evaluated (thanks Jeremy!) .You could also hook into V8's code caching as well, by splitting out libraries from code using them, or the other way around, merge libraries and their uses into a single script, group small files together and avoid inline scripts. Or perhaps even use v8-compile-cache.
When it comes to JavaScript in general, there are also some practices that are worth keeping in mind:
- Clean Code concepts for JavaScript, a large collection of patterns for writing readable, reusable, and refactorable code.
- You can Compress data from JavaScript with the CompressionStream API, eg to gzip before uploading data (Chrome 80+).
- Detached window memory leaks and Fixing memory leaks in web apps are detailed guides on how to find and fix tricky JavaScript memory leaks. Plus, you can use queryObjects(SomeConstructor) from the DevTools Console ( thanks, Mathias! ).
- Reexports are bad for loading and runtime performance, and avoiding them can help reduce the bundle size significantly.
- We can improve scroll performance with passive event listeners by setting a flag in the
optionsparameter. So browsers can scroll the page immediately, rather than after the listener has finished. (via Kayce Basques). - If you have any
scrollortouch*listeners, passpassive: trueto addEventListener. This tells the browser you're not planning to callevent.preventDefault()inside, so it can optimize the way it handles these events. (via Ivan Akulov) - We can achieve better JavaScript scheduling with isInputPending(), a new API that attempts to bridge the gap between loading and responsiveness with the concepts of interrupts for user inputs on the web, and allows for JavaScript to be able to check for input without yielding to the browser.
- You can also automatically remove an event listener after it has executed.
- Firefox's recently released Warp, a significant update to SpiderMonkey (shipped in Firefox 83), Baseline Interpreter and there are a few JIT Optimization Strategies available as well.
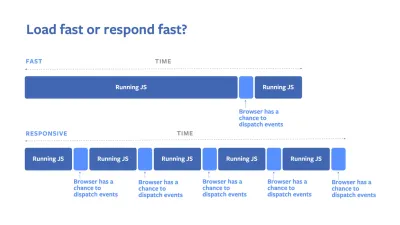
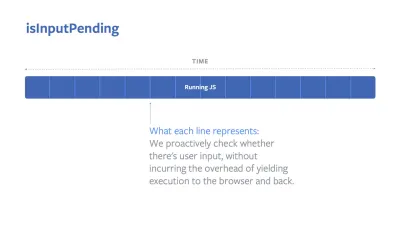
- Always prefer to self-host third-party assets.
Yet again, self-host your static assets by default. It's common to assume that if many sites use the same public CDN and the same version of a JavaScript library or a web font, then the visitors would land on our site with the scripts and fonts already cached in their browser, speeding up their experience considerably. However, it's very unlikely to happen.For security reasons, to avoid fingerprinting, browsers have been implementing partitioned caching that was introduced in Safari back in 2013, and in Chrome last year. So if two sites point to the exact same third-party resource URL, the code is downloaded once per domain , and the cache is "sandboxed" to that domain due to privacy implications ( thanks, David Calhoun! ). Hence, using a public CDN will not automatically lead to better performance.
Furthermore, it's worth noting that resources don't live in the browser's cache as long as we might expect, and first-party assets are more likely to stay in the cache than third-party assets. Therefore, self-hosting is usually more reliable and secure, and better for performance, too.
- Constrain the impact of third-party scripts.
With all performance optimizations in place, often we can't control third-party scripts coming from business requirements. Third-party-scripts metrics aren't influenced by end-user experience, so too often one single script ends up calling a long tail of obnoxious third-party scripts, hence ruining a dedicated performance effort. To contain and mitigate performance penalties that these scripts bring along, it's not enough to just defer their loading and execution and warm up connections via resource hints, iedns-prefetchorpreconnect.Currently 57% of all JavaScript code excution time is spent on third-party code. The median mobile site accesses 12 third-party domains , with a median of 37 different requests (or about 3 requests made to each third party).
Furthermore, these third-parties often invite fourth-party scripts to join in, ending up with a huge performance bottleneck, sometimes going as far as to the eigth-party scripts on a page. So regularly auditing your dependencies and tag managers can bring along costly surprises.
Another problem, as Yoav Weiss explained in his talk on third-party scripts, is that in many cases these scripts download resources that are dynamic. The resources change between page loads, so we don't necessarily know which hosts the resources will be downloaded from and what resources they would be.
Deferring, as shown above, might be just a start though as third-party scripts also steal bandwidth and CPU time from your app. We could be a bit more aggressive and load them only when our app has initialized.
/* Before */ const App = () => { return <div> <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> </div> } /* After */ const App = () => { const[isRendered, setRendered] = useState(false); useEffect(() => setRendered(true)); return <div> {isRendered ? <script> window.dataLayer = window.dataLayer || []; function gtag(){...} gtg('js', new Date()); </script> : null} </div> }In a fantastic post on "Reducing the Site-Speed Impact of Third-Party Tags", Andy Davies explores a strategy of minimizing the footprint of third-parties — from identifying their costs towards reducing their impact.
According to Andy, there are two ways tags impact site-speed — they compete for network bandwidth and processing time on visitors' devices, and depending on how they're implemented, they can delay HTML parsing as well. So the first step is to identify the impact that third-parties have, by testing the site with and without scripts using WebPageTest. With Simon Hearne's Request Map, we can also visualize third-parties on a page along with details on their size, type and what triggered their load.
Preferably self-host and use a single hostname, but also use a request map to exposes fourth-party calls and detect when the scripts change. You can use Harry Roberts' approach for auditing third parties and produce spreadsheets like this one (also check Harry's auditing workflow).
Afterwards, we can explore lightweight alternatives to existing scripts and slowly replace duplicates and main culprits with lighter options. Perhaps some of the scripts could be replaced with their fallback tracking pixel instead of the full tag.

Loading YouTube with facades, eg lite-youtube-embed that's significantly smaller than an actual YouTube player. (Sursa imagine) (Previzualizare mare) If it's not viable, we can at least lazy load third-party resources with facades, ie a static element which looks similar to the actual embedded third-party, but is not functional and therefore much less taxing on the page load. The trick, then, is to load the actual embed only on interaction .
For example, we can use:
- lite-vimeo-embed for the Vimeo player,
- lite-vimeo for the Vimeo player,
- lite-youtube-embed for the YouTube player,
- react-live-chat-loader for a live chat (case study, and another case-study),
- lazyframe for iframes.
One of the reasons why tag managers are usually large in size is because of the many simultaneous experiments that are running at the same time, along with many user segments, page URLs, sites etc., so according to Andy, reducing them can reduce both the download size and the time it takes to execute the script in the browser.
And then there are anti-flicker snippets. Third-parties such as Google Optimize, Visual Web Optimizer (VWO) and others are unanimous in using them. These snippets are usually injected along with running A/B tests : to avoid flickering between the different test scenarios, they hide the
bodyof the document withopacity: 0, then adds a function that gets called after a few seconds to bring theopacityback. This often results in massive delays in rendering due to massive client-side execution costs.
With A/B testing in use, customers would often see flickering like this one. Anti-Flicker snippets prevent that, but they also cost in performance. Via Andy Davies. (Previzualizare mare) Therefore keep track how often the anti-flicker timeout is triggered and reduce the timeout. Default blocks display of your page by up to 4s which will ruin conversion rates. According to Tim Kadlec, "Friends don't let friends do client side A/B testing". Server-side A/B testing on CDNs (eg Edge Computing, or Edge Slice Rerendering) is always a more performant option.
If you have to deal with almighty Google Tag Manager , Barry Pollard provides some guidelines to contain the impact of Google Tag Manager. Also, Christian Schaefer explores strategies for loading ads.
Atenție: unele widget-uri de la terțe părți se ascund de instrumentele de auditare, așa că ar putea fi mai dificil de identificat și măsurat. Pentru a testa terțe părți, examinați rezumatele de jos în sus din pagina de profil de performanță din DevTools, testați ce se întâmplă dacă o solicitare este blocată sau a expirat - pentru cea din urmă, puteți utiliza serverul Blackhole al WebPageTest,
blackhole.webpagetest.org, pe care îl puteți poate indica anumite domenii în fișierul dvs.hosts.Ce variante avem atunci? Luați în considerare folosirea lucrătorilor de service prin accelerarea descărcării resursei cu un timeout și, dacă resursa nu a răspuns într-un anumit timeout, returnați un răspuns gol pentru a spune browserului să continue analizarea paginii. De asemenea, puteți să înregistrați sau să blocați solicitările terților care nu au succes sau care nu îndeplinesc anumite criterii. Dacă puteți, încărcați scriptul terță parte de pe propriul server, mai degrabă decât de pe serverul furnizorului și încărcați-le leneș.
O altă opțiune este stabilirea unei politici de securitate a conținutului (CSP) pentru a restricționa impactul scripturilor terțe, de exemplu, interzicerea descărcării audio sau video. Cea mai bună opțiune este să încorporați scripturi prin
<iframe>, astfel încât scripturile să ruleze în contextul iframe-ului și, prin urmare, să nu aibă acces la DOM-ul paginii și să nu poată rula cod arbitrar pe domeniul dvs. Iframe-urile pot fi constrânse și mai mult folosind atributulsandbox, astfel încât să puteți dezactiva orice funcționalitate pe care o poate face iframe, de exemplu, împiedicați rularea scripturilor, prevenirea alertelor, trimiterea formularelor, plugin-uri, accesul la navigarea de sus și așa mai departe.De asemenea, puteți ține sub control terții prin alinierea performanței în browser cu politicile caracteristicilor, o caracteristică relativ nouă care vă permite
înscrierea sau renunțarea la anumite funcții ale browserului de pe site-ul dvs. (Ca o notă secundară, ar putea fi folosit și pentru a evita imaginile supradimensionate și neoptimizate, mediile nedimensionate, scripturile de sincronizare și altele). Acceptat în prezent în browserele bazate pe Blink. /* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'/* Via Tim Kadlec. https://timkadlec.com/remembers/2020-02-20-in-browser-performance-linting-with-feature-policies/ */ /* Block the use of the Geolocation API with a Feature-Policy header. */ Feature-Policy: geolocation 'none'Deoarece multe scripturi terță parte rulează în cadre iframe, probabil că trebuie să fii amănunțit în restricționarea permiselor lor. Cadrele iframe cu nisip sunt întotdeauna o idee bună, iar fiecare dintre limitări poate fi ridicată printr-un număr de valori
allowpe atributulsandbox. Sandboxing-ul este acceptat aproape peste tot, așa că restrângeți scripturile terță parte la strictul minim de ceea ce ar trebui să li se permită să facă.
ThirdPartyWeb.Today grupează toate scripturile de la terți în funcție de categorie (analitice, rețele sociale, publicitate, găzduire, manager de etichete etc.) și vizualizează cât timp durează executarea scripturilor entității (în medie). (Previzualizare mare) Luați în considerare utilizarea unui Observator de intersecție; care ar permite reclamelor să fie încadrate în format iframed , în timp ce încă trimit evenimente sau obține informațiile de care au nevoie din DOM (de exemplu, vizibilitatea anunțurilor). Atenție la noile politici, cum ar fi politica caracteristicilor, limitele de dimensiune a resurselor și prioritatea CPU/lățime de bandă pentru a limita caracteristicile web dăunătoare și scripturile care ar încetini browserul, de exemplu, scripturi sincrone, solicitări XHR sincrone, document.write și implementări învechite.
În cele din urmă, atunci când alegeți un serviciu terță parte, luați în considerare verificarea ThirdPartyWeb de la Patrick Hulce. Astăzi, un serviciu care grupează toate scripturile terților pe categorii (analitice, rețele sociale, publicitate, găzduire, manager de etichete etc.) și vizualizează cât timp scripturile entității ia pentru a executa (în medie). Evident, cele mai mari entități au cel mai rău impact asupra performanței paginilor pe care se află. Doar parcurgând pagina, vă veți face o idee despre amprenta de performanță la care ar trebui să vă așteptați.
Ah, și nu uitați de suspecții obișnuiți: în loc de widget-uri terțe pentru partajare, putem folosi butoane statice de partajare socială (cum ar fi prin SSBG) și link-uri statice către hărți interactive în loc de hărți interactive.
- Setați corect anteturile cache HTTP.
Memorarea în cache pare a fi un lucru atât de evident de făcut, dar ar putea fi destul de greu de făcut corect. Trebuie să verificăm din nou dacăexpires,max-age,cache-controlși alte anteturi cache HTTP au fost setate corect. Fără antetele cache HTTP adecvate, browserele le vor seta automat la 10% din timpul scurs de lalast-modified, ajungând la un potențial sub și supra-caching.În general, resursele ar trebui să poată fi stocate în cache pentru o perioadă foarte scurtă de timp (dacă este posibil să se schimbe) sau pe termen nelimitat (dacă sunt statice) - puteți doar să le schimbați versiunea în URL atunci când este necesar. O puteți numi o strategie Cache-Forever, în care am putea retransmite antetele
Cache-ControlșiExpirescătre browser pentru a permite ca activele să expire doar într-un an. Prin urmare, browserul nici măcar nu ar face o cerere pentru activ dacă îl are în cache.Excepție fac răspunsurile API (de ex
/api/user). Pentru a preveni stocarea în cache, putem folosiprivate, no store, și numax-age=0, no-store:Cache-Control: private, no-storeUtilizați
Cache-control: immutablepentru a evita revalidarea duratelor lungi de viață explicite ale cache-ului atunci când utilizatorii apasă butonul de reîncărcare. Pentru cazul de reîncărcare,immutablesalvează cererile HTTP și îmbunătățește timpul de încărcare a HTML dinamic, deoarece nu mai concurează cu multitudinea de răspunsuri 304.Un exemplu tipic în care dorim să folosim
immutablesunt activele CSS/JavaScript cu un hash în numele lor. Pentru ei, probabil că vrem să păstrăm în cache cât mai mult posibil și să ne asigurăm că nu vor fi revalidate:Cache-Control: max-age: 31556952, immutableConform cercetării lui Colin Bendell,
immutablereduce redirecționările 304 cu aproximativ 50%, deoarece chiar și cumax-ageîn uz, clienții încă revalidează și blochează la reîmprospătare. Este acceptat în Firefox, Edge și Safari, iar Chrome încă dezbate această problemă.Potrivit Web Almanac, „utilizarea sa a crescut la 3,5% și este utilizat pe scară largă în răspunsurile de la terți Facebook și Google”.

Cache-Control: Immutable reduce 304s cu aproximativ 50%, conform cercetării lui Colin Bendell la Cloudinary. (Previzualizare mare) Îți amintești vechiul vechi învechit-în timp ce-revalidezi? Când specificăm timpul de stocare în cache cu antetul de răspuns
Cache-Control(exCache-Control: max-age=604800), după ce expirămax-age, browserul va prelua din nou conținutul solicitat, ceea ce face ca pagina să se încarce mai lent. Această încetinire poate fi evitată custale-while-revalidate; practic definește o fereastră suplimentară de timp în care un cache poate folosi un activ învechit atâta timp cât îl revalidează asincron în fundal. Astfel, „ascunde” latența (atât în rețea, cât și pe server) de clienți.În iunie-iulie 2019, Chrome și Firefox au lansat suportul pentru
stale-while-revalidateîn antetul HTTP Cache-Control, astfel încât, în consecință, ar trebui să îmbunătățească latența ulterioară a încărcării paginii, deoarece activele învechite nu mai sunt pe calea critică. Rezultat: zero RTT pentru vizualizări repetate.Fiți atenți la antetul variabil, în special în ceea ce privește CDN-urile, și aveți grijă la variantele de reprezentare HTTP care ajută la evitarea unei călătorii dus-întors suplimentare pentru validare ori de câte ori o nouă solicitare diferă ușor (dar nu semnificativ) de cererile anterioare ( mulțumesc, Guy și Mark ! ).
De asemenea, verificați din nou dacă nu trimiteți anteturi inutile (de exemplu
x-powered-by,pragma,x-ua-compatible,expires,X-XSS-Protectionși altele) și că includeți anteturi utile de securitate și performanță (cum ar fi precumContent-Security-Policy,X-Content-Type-Optionsși altele). În cele din urmă, țineți cont de costul de performanță al solicitărilor CORS în aplicațiile cu o singură pagină.Notă : presupunem adesea că activele din cache sunt recuperate instantaneu, dar cercetările arată că recuperarea unui obiect din cache poate dura sute de milisecunde. De fapt, potrivit lui Simon Hearne, „uneori, rețeaua poate fi mai rapidă decât memoria cache, iar recuperarea activelor din cache poate fi costisitoare cu un număr mare de active stocate în cache (nu dimensiunea fișierului) și dispozitivele utilizatorului. De exemplu: regăsirea cache medie a sistemului de operare Chrome. se dublează de la ~50ms cu 5 resurse stocate în cache până la ~100ms cu 25 de resurse".
În plus, de multe ori presupunem că dimensiunea pachetului nu este o problemă uriașă și utilizatorii îl vor descărca o dată și apoi vor folosi versiunea în cache. În același timp, cu CI/CD împingem codul în producție de mai multe ori pe zi, memoria cache este invalidată de fiecare dată, deci fiind strategic în ceea ce privește chestiunile de cache.
Când vine vorba de memorarea în cache, există o mulțime de resurse care merită citite:
- Cache-Control pentru civili, o scufundare profundă în tot ce se păstrează în cache cu Harry Roberts.
- Introducere Heroku despre anteturile de cache HTTP,
- Cele mai bune practici de stocare în cache de Jake Archibald,
- Introducere pentru caching HTTP de Ilya Grigorik,
- Păstrarea lucrurilor proaspete cu revalidarea învechită de Jeff Posnick.
- CS Vizualizat: CORS de Lydia Hallie este un excelent explicator despre CORS, cum funcționează și cum să-i înțelegi sensul.
- Vorbind despre CORS, iată o scurtă actualizare despre politica privind aceeași origine de Eric Portis.
Optimizări de livrare
- Folosim
deferpentru a încărca JavaScript critic în mod asincron?
Când utilizatorul solicită o pagină, browserul preia HTML-ul și construiește DOM-ul, apoi preia CSS-ul și construiește CSSOM-ul și apoi generează un arbore de randare prin potrivirea DOM-ului și CSSOM. Dacă trebuie rezolvat vreun JavaScript, browserul nu va începe redarea paginii până când nu este rezolvată, întârziind astfel randarea. În calitate de dezvoltatori, trebuie să spunem în mod explicit browserului să nu aștepte și să înceapă redarea paginii. Modul de a face acest lucru pentru scripturi este cu atributeledeferșiasyncdin HTML.În practică, se dovedește că este mai bine să folosiți
deferîn loc deasync. Ah, care este din nou diferența ? Potrivit lui Steve Souders, odată ce sosesc scripturileasync, acestea sunt executate imediat - de îndată ce scriptul este gata. Dacă acest lucru se întâmplă foarte repede, de exemplu când scriptul este deja în cache, poate bloca de fapt parserul HTML. Cudefer, browserul nu execută scripturi până când HTML nu este analizat. Deci, dacă nu aveți nevoie de JavaScript pentru a executa înainte de a începe randarea, este mai bine să utilizațidefer. De asemenea, mai multe fișiere asincrone se vor executa într-o ordine nedeterministă.Este demn de remarcat faptul că există câteva concepții greșite despre
asyncșidefer. Cel mai important,asyncnu înseamnă că codul va rula ori de câte ori scriptul este gata; înseamnă că va rula ori de câte ori scripturile sunt gata și toate lucrările de sincronizare precedente sunt finalizate. În cuvintele lui Harry Roberts, „Dacă pui un scriptasyncdupă scripturile de sincronizare, scriptul tăuasynceste la fel de rapid ca cel mai lent script de sincronizare”.De asemenea, nu este recomandat să folosiți atât
async, cât șidefer. Browserele moderne acceptă ambele, dar ori de câte ori sunt folosite ambele atribute,asyncva câștiga întotdeauna.Dacă doriți să vă scufundați în mai multe detalii, Milica Mihajlija a scris un ghid foarte detaliat despre Construirea mai rapidă a DOM-ului, intrând în detaliile analizei speculative, asincronizării și amânării.
- Încărcați leneș componentele scumpe cu IntersectionObserver și indicii de prioritate.
În general, este recomandat să încărcați leneș toate componentele costisitoare, cum ar fi JavaScript grele, videoclipuri, iframes, widget-uri și eventual imagini. Încărcarea leneră nativă este deja disponibilă pentru imagini și cadre iframe cu atributul deloading(doar Chromium). Sub capotă, acest atribut amână încărcarea resursei până când ajunge la o distanță calculată de la fereastra de vizualizare.<!-- Lazy loading for images, iframes, scripts. Probably for images outside of the viewport. --> <img loading="lazy" ... /> <iframe loading="lazy" ... /> <!-- Prompt an early download of an asset. For critical images, eg hero images. --> <img loading="eager" ... /> <iframe loading="eager" ... />Acest prag depinde de câteva lucruri, de la tipul de resursă de imagine preluată până la tipul de conexiune eficientă. Dar experimentele efectuate folosind Chrome pe Android sugerează că, pe 4G, 97,5% din imaginile de sub orificiu care sunt încărcate leneș au fost încărcate complet în 10 ms de când au devenit vizibile, așa că ar trebui să fie în siguranță.
Putem folosi, de asemenea, atributul de
importance(highsaulow) pe un element<script>,<img>sau<link>(doar Blink). De fapt, este o modalitate excelentă de a deprioritiza imaginile din carusele, precum și de a re-prioritiza scripturile. Cu toate acestea, uneori s-ar putea să avem nevoie de un control un pic mai granular.<!-- When the browser assigns "High" priority to an image, but we don't actually want that. --> <img src="less-important-image.svg" importance="low" ... /> <!-- We want to initiate an early fetch for a resource, but also deprioritize it. --> <link rel="preload" importance="low" href="/script.js" as="script" />Cea mai performantă modalitate de a face încărcare leneșă puțin mai sofisticată este utilizarea API-ului Intersection Observer, care oferă o modalitate de a observa asincron modificările în intersecția unui element țintă cu un element strămoș sau cu o fereastră de vizualizare a unui document de nivel superior. Practic, trebuie să creați un nou obiect
IntersectionObserver, care primește o funcție de apel invers și un set de opțiuni. Apoi adăugăm o țintă de observat.Funcția de apel invers se execută atunci când ținta devine vizibilă sau invizibilă, așa că atunci când interceptează fereastra de vizualizare, puteți începe să efectuați unele acțiuni înainte ca elementul să devină vizibil. De fapt, avem un control granular asupra momentului în care ar trebui invocată callback-ul observatorului, cu
rootMargin(marja în jurul rădăcinii) șithreshold(un singur număr sau o matrice de numere care indică la ce procent din vizibilitatea țintei țintim).Alejandro Garcia Anglada a publicat un tutorial la îndemână despre cum să-l implementeze efectiv, Rahul Nanwani a scris o postare detaliată despre încărcarea leneșă a imaginilor din prim-plan și de fundal, iar Google Fundamentals oferă un tutorial detaliat despre încărcarea leneșă a imaginilor și a videoclipurilor cu Intersection Observer.
Îți amintești de povestirile direcționate de artă lecturi lungi cu obiecte în mișcare și lipicioase? Puteți implementa scrolltelling performant și cu Intersection Observer.
Verificați din nou ce altceva ați putea încărca leneș. Chiar și șirurile de traducere cu încărcare leneră și emoji-uri ar putea ajuta. Procedând astfel, Mobile Twitter a reușit să obțină o execuție JavaScript cu 80% mai rapidă din noua conductă de internaționalizare.
Totuși, un scurt cuvânt de precauție: merită remarcat faptul că încărcarea leneșă ar trebui să fie o excepție, mai degrabă decât o regulă. Probabil că nu este rezonabil să încărcați leneș ceva ce doriți ca oamenii să vadă rapid, de exemplu, imagini din pagina de produs, imagini eroi sau un script necesar pentru ca navigarea principală să devină interactivă.

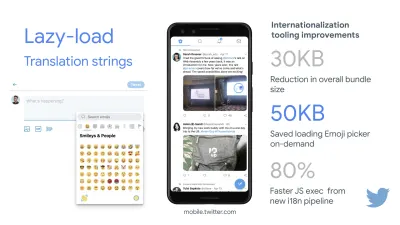
- Încărcați imaginile progresiv.
Puteți chiar să duceți încărcarea leneșă la următorul nivel, adăugând încărcare progresivă a imaginii în paginile dvs. Similar cu Facebook, Pinterest, Medium și Wolt, puteți încărca mai întâi imagini de calitate scăzută sau chiar neclare, apoi, pe măsură ce pagina continuă să se încarce, înlocuiți-le cu versiuni de calitate completă utilizând tehnica BlurHash sau LQIP (Low Quality Image Placeholders). tehnică.Opiniile diferă dacă aceste tehnici îmbunătățesc sau nu experiența utilizatorului, dar cu siguranță îmbunătățesc timpul pentru First Contentful Paint. Îl putem automatiza chiar și utilizând SQIP care creează o versiune de calitate scăzută a unei imagini ca substituent SVG sau substituenți pentru imagini cu gradient cu gradienți liniari CSS.
Acești substituenți ar putea fi încorporați în HTML, deoarece se comprimă bine în mod natural cu metodele de comprimare a textului. În articolul său, Dean Hume a descris cum poate fi implementată această tehnică folosind Intersection Observer.
Da înapoi? Dacă browserul nu acceptă observatorul de intersecție, putem încărca leneș un polyfill sau încărcăm imaginile imediat. Și există chiar și o bibliotecă pentru el.
Vrei să devii mai fantezie? Puteți să vă urmăriți imaginile și să utilizați forme și margini primitive pentru a crea un substituent SVG ușor, să îl încărcați mai întâi și apoi să treceți de la imaginea vectorială cu substituent la imaginea bitmap (încărcată).
- Amânați redarea cu
content-visibility?
Pentru un aspect complex, cu o mulțime de blocuri de conținut, imagini și videoclipuri, decodarea datelor și redarea pixelilor ar putea fi o operațiune destul de costisitoare - mai ales pe dispozitivele low-end. Cucontent-visibility: auto, putem solicita browserului să ignore aspectul copiilor în timp ce containerul se află în afara ferestrei de vizualizare.De exemplu, puteți sări peste redarea subsolului și a secțiunilor târzii de la încărcarea inițială:
footer { content-visibility: auto; contain-intrinsic-size: 1000px; /* 1000px is an estimated height for sections that are not rendered yet. */ }Rețineți că vizibilitatea conținutului: automat; se comportă ca preaplin: ascuns; , dar îl puteți remedia aplicând
padding-leftșipadding-rightîn loc demargin-left: auto;,margin-right: auto;și o lățime declarată. Umplutura permite, practic, elementelor să depășească caseta de conținut și să intre în caseta de umplutură fără a părăsi modelul de cutie în întregime și a fi tăiate.De asemenea, rețineți că ați putea introduce niște CLS atunci când conținutul nou va fi redat în cele din urmă, așa că este o idee bună să utilizați
contain-intrinsic-sizecu un substituent dimensionat corespunzător ( mulțumesc, Una! ).Thijs Terluin are mult mai multe detalii despre ambele proprietăți și despre modul în care browser-ul calculează
contain-intrinsic-sizea conținutului, Malte Ubl vă arată cum o puteți calcula și un scurt explicator video de Jake și Surma explică cum funcționează totul.Și dacă aveți nevoie să obțineți un pic mai granular, cu CSS Containment, puteți sări manual aspectul, stilul și lucrările de vopsire pentru descendenții unui nod DOM dacă aveți nevoie doar de dimensiune, aliniere sau stiluri calculate pentru alte elemente - sau elementul este în prezent în afara pânzei.


content-visibility: auto în zonele de conținut fragmentate oferă o creștere a performanței de redare de 7 ori la încărcarea inițială. (Previzualizare mare)- Amânați decodarea cu
decoding="async"?
Uneori, conținutul apare în afara ecranului, dar dorim să ne asigurăm că este disponibil atunci când clienții au nevoie de el - în mod ideal, nu blocând nimic din calea critică, ci decodând și redând asincron. Putem folosidecoding="async"pentru a acorda browserului permisiunea de a decoda imaginea din firul principal, evitând impactul utilizatorului al timpului CPU utilizat pentru a decoda imaginea (prin Malte Ubl):<img decoding="async" … />Alternativ, pentru imaginile în afara ecranului, putem afișa mai întâi un substituent, iar când imaginea se află în fereastra de vizualizare, folosind IntersectionObserver, declanșăm un apel de rețea pentru ca imaginea să fie descărcată în fundal. De asemenea, putem amâna randarea până la decodare cu img.decode() sau putem descărca imaginea dacă API-ul Image Decode nu este disponibil.
Când redăm imaginea, putem folosi, de exemplu, animații cu fade-in. Katie Hempenius și Addy Osmani împărtășesc mai multe informații în discursul lor Viteză la scară: Sfaturi și trucuri de performanță web din tranșee.
- Generați și serviți CSS critic?
Pentru a vă asigura că browserele încep să redeze pagina dvs. cât mai repede posibil, a devenit o practică obișnuită să colectați toate CSS-urile necesare pentru a începe redarea primei părți vizibile a paginii (cunoscută sub numele de „CSS critic” sau „CSS de deasupra paginii”. ") și includeți-l în linie în<head>a paginii, reducând astfel călătoriile dus-întors. Datorită dimensiunii limitate a pachetelor schimbate în timpul fazei de pornire lentă, bugetul dumneavoastră pentru CSS critic este de aproximativ 14KB.Dacă treceți mai departe, browserul va avea nevoie de călătorii dus-întors suplimentare pentru a prelua mai multe stiluri. CriticalCSS și Critical vă permit să scoateți CSS critic pentru fiecare șablon pe care îl utilizați. Totuși, din experiența noastră, niciun sistem automat nu a fost vreodată mai bun decât colectarea manuală a CSS-urilor critice pentru fiecare șablon și, într-adevăr, aceasta este abordarea la care am revenit recent.
Puteți apoi să integrați CSS critic și să încărcați leneș restul cu pluginul Critters Webpack. Dacă este posibil, luați în considerare utilizarea abordării condiționale în linie utilizată de Filament Group sau convertiți din mers codul în linie în active statice.
Dacă în prezent încărcați CSS complet asincron cu biblioteci precum loadCSS, nu este chiar necesar. Cu
media="print", puteți păcăli browserul să preia CSS-ul în mod asincron, dar să se aplice în mediul ecranului odată ce se încarcă. ( Mulțumesc, Scott! )<!-- Via Scott Jehl. https://www.filamentgroup.com/lab/load-css-simpler/ --> <!-- Load CSS asynchronously, with low priority --> <link rel="stylesheet" href="full.css" media="print" onload="this.media='all'" />Atunci când colectați toate CSS-urile esențiale pentru fiecare șablon, este obișnuit să explorați numai zona „de deasupra pliului”. Cu toate acestea, pentru layout-uri complexe, ar putea fi o idee bună să includeți și bazele aspectului pentru a evita costurile masive de recalculare și revopsire, rănind astfel scorul Core Web Vitals.
Ce se întâmplă dacă un utilizator primește o adresă URL care trimite direct la mijlocul paginii, dar CSS-ul nu a fost încă descărcat? În acest caz, a devenit obișnuit să se ascundă conținut necritic, de exemplu cu
opacity: 0;în CSS inline șiopacity: 1în fișierul CSS complet și afișați-l când CSS este disponibil. Totuși, are un dezavantaj major , deoarece utilizatorii cu conexiuni lente s-ar putea să nu poată citi niciodată conținutul paginii. De aceea, este mai bine să păstrați întotdeauna conținutul vizibil, chiar dacă este posibil să nu fie stilat corespunzător.Punerea CSS-ului critic (și a altor active importante) într-un fișier separat pe domeniul rădăcină are avantaje, uneori chiar mai mult decât inline, datorită stocării în cache. Chrome deschide în mod speculativ o a doua conexiune HTTP la domeniul rădăcină atunci când solicită pagina, ceea ce elimină necesitatea unei conexiuni TCP pentru a prelua acest CSS. Aceasta înseamnă că puteți crea un set de fișiere -CSS critice (de exemplu critical-homepage.css , critical-product-page.css etc.) și le puteți servi de la rădăcină, fără a fi nevoie să le introduceți. ( Multumesc, Philip! )
Un cuvânt de precauție: cu HTTP/2, CSS-ul critic ar putea fi stocat într-un fișier CSS separat și livrat printr-un push de server fără a umfla HTML. Problema este că împingerea serverului a fost deranjantă cu multe probleme și condiții de cursă în browsere. Nu a fost niciodată acceptat în mod consecvent și a avut unele probleme de cache (vezi diapozitivul 114 de la prezentarea lui Hooman Beheshti).
Efectul ar putea, de fapt, să fie negativ și să umfle tampoanele de rețea, împiedicând livrarea cadrelor autentice din document. Deci nu a fost foarte surprinzător că, deocamdată, Chrome plănuiește să elimine suportul pentru Server Push.
- Experimentați cu regruparea regulilor dvs. CSS.
Ne-am obișnuit cu CSS critic, dar există câteva optimizări care ar putea depăși asta. Harry Roberts a efectuat o cercetare remarcabilă cu rezultate destul de surprinzătoare. De exemplu, ar putea fi o idee bună să împărțiți fișierul CSS principal în interogări media individuale. În acest fel, browserul va prelua CSS critic cu prioritate mare și orice altceva cu prioritate scăzută - complet în afara căii critice.De asemenea, evitați să plasați
<link rel="stylesheet" />înaintea fragmentelorasync. Dacă scripturile nu depind de foile de stil, luați în considerare plasarea scripturilor de blocare deasupra stilurilor de blocare. Dacă o fac, împărțiți acel JavaScript în două și încărcați-l pe fiecare parte a CSS-ului dvs.Scott Jehl a rezolvat o altă problemă interesantă prin memorarea în cache a unui fișier CSS inline cu un lucrător de service, o problemă comună cunoscută dacă utilizați CSS critic. Practic, adăugăm un atribut ID pe elementul de
style, astfel încât să fie ușor de găsit folosind JavaScript, apoi o mică bucată de JavaScript găsește acel CSS și folosește API-ul Cache pentru a-l stoca într-un cache local al browserului (cu un tip de conținut detext/css) pentru utilizare pe paginile următoare. Pentru a evita introducerea pe paginile ulterioare și, în schimb, facem referire la activele stocate în cache în exterior, apoi setăm un cookie la prima vizită pe un site. Voila!Merită remarcat faptul că stilul dinamic poate fi și costisitor, dar de obicei numai în cazurile în care te bazezi pe sute de componente compuse redate concomitent. Deci, dacă utilizați CSS-in-JS, asigurați-vă că biblioteca dvs. CSS-in-JS optimizează execuția atunci când CSS-ul dvs. nu are dependențe de temă sau elemente de recuzită și nu supracompuneți componente cu stil . Aggelos Arvanitakis oferă mai multe informații despre costurile de performanță ale CSS-in-JS.
- Transmiteți răspunsuri?
Adesea uitate și neglijate, fluxurile oferă o interfață pentru citirea sau scrierea unor bucăți asincrone de date, dintre care doar un subset ar putea fi disponibil în memorie la un moment dat. Practic, ele permit paginii care a făcut cererea inițială să înceapă să lucreze cu răspunsul de îndată ce prima bucată de date este disponibilă și utilizează parsere care sunt optimizate pentru streaming pentru a afișa progresiv conținutul.Am putea crea un flux din mai multe surse. De exemplu, în loc să serviți un shell UI gol și să lăsați JavaScript să-l populeze, puteți lăsa lucrătorul de servicii să construiască un flux în care shell-ul provine dintr-un cache, dar corpul provine din rețea. După cum a remarcat Jeff Posnick, dacă aplicația dvs. web este alimentată de un CMS care redă HTML prin împletire a șabloanelor parțiale, modelul respectiv se traduce direct în utilizarea răspunsurilor în flux, cu logica de șabloane replicată în serviciul de lucru în loc de server. Articolul The Year of Web Streams al lui Jake Archibald evidențiază cum exact l-ați putea construi. Creșterea performanței este destul de vizibilă.
Un avantaj important al transmiterii întregului răspuns HTML este că HTML redat în timpul solicitării inițiale de navigare poate profita din plin de analizatorul HTML de streaming al browserului. Bucățile de HTML care sunt inserate într-un document după ce pagina s-a încărcat (cum este obișnuit în cazul conținutului populat prin JavaScript) nu pot profita de această optimizare.
Suport pentru browser? Încă ajung acolo cu suport parțial în Chrome, Firefox, Safari și Edge, care acceptă API și Service Workers, care sunt acceptate în toate browserele moderne. Și dacă te simți din nou aventuros, poți verifica o implementare experimentală a cererilor de streaming, care îți permite să începi să trimiți cererea în timp ce generezi corpul. Disponibil în Chrome 85.
- Luați în considerare să vă faceți conexiunea componentelor.
Datele pot fi costisitoare și, cu sarcina utilă în creștere, trebuie să respectăm utilizatorii care aleg să opteze pentru economisirea datelor în timp ce accesează site-urile sau aplicațiile noastre. Antetul cererii de indiciu pentru client Save-Data ne permite să personalizăm aplicația și sarcina utilă pentru utilizatorii cu costuri limitate și performanță.De fapt, puteți rescrie solicitările pentru imagini cu DPI ridicat în imagini cu DPI scăzut, elimina fonturile web, efectele de paralaxă fanteziste, previzualizați miniaturile și derularea infinită, dezactivați redarea automată a videoclipurilor, împingerea serverului, reduceți numărul de elemente afișate și reduceți calitatea imaginii sau chiar schimbați modul în care livrați marcajul. Tim Vereecke a publicat un articol foarte detaliat despre strategiile de economisire a datelor, oferind multe opțiuni pentru salvarea datelor.
Cine folosește
save-data, s-ar putea să vă întrebați? 18% dintre utilizatorii Android Chrome la nivel global au Modul simplificat activat (cuSave-Dataactivată), iar numărul este probabil mai mare. Conform cercetărilor lui Simon Hearne, rata de înscriere este cea mai mare pe dispozitivele mai ieftine, dar există o mulțime de valori aberante. De exemplu: utilizatorii din Canada au o rată de înscriere de peste 34% (comparativ cu ~7% în SUA), iar utilizatorii de pe cel mai recent flagship Samsung au o rată de înscriere de aproape 18% la nivel global.Cu modul
Save-Dataactivat, Chrome Mobile va oferi o experiență optimizată, adică o experiență web proxy cu scripturi amânate ,font-display: swapși încărcare leneră forțată. Este mai sensibil să construiți experiența pe cont propriu decât să vă bazați pe browser pentru a face aceste optimizări.În prezent, antetul este acceptat numai în Chromium, pe versiunea Android a Chrome sau prin extensia Data Saver pe un dispozitiv desktop. În cele din urmă, puteți utiliza și API-ul Network Information pentru a furniza module JavaScript costisitoare, imagini de înaltă rezoluție și videoclipuri bazate pe tipul de rețea. Network Information API și în special
navigator.connection.effectiveTypeutilizează valorileRTT,downlink,effectiveType(și altele) pentru a oferi o reprezentare a conexiunii și a datelor pe care utilizatorii le pot gestiona.În acest context, Max Bock vorbește despre componentele conștiente de conexiune, iar Addy Osmani vorbește despre servirea modulelor adaptive. De exemplu, cu React, am putea scrie o componentă care se redă diferit pentru diferite tipuri de conexiune. După cum a sugerat Max, o componentă
<Media />dintr-un articol de știri ar putea scoate:-
Offline: un substituent cu textalt, -
2G/ modulsave-data: o imagine cu rezoluție scăzută, -
3Gpe ecran non-Retina: o imagine cu rezoluție medie, -
3Gpe ecranele Retina: imagine Retina de înaltă rezoluție, -
4G: un videoclip HD.
Dean Hume oferă o implementare practică a unei logici similare folosind un lucrător de service. Pentru un videoclip, am putea afișa implicit un poster video și apoi să afișăm pictograma „Redare”, precum și shell-ul playerului video, metadatele videoclipului etc. pe conexiuni mai bune. Ca o alternativă pentru browserele care nu acceptă, am putea asculta evenimentul
canplaythroughși am putea folosiPromise.race()pentru a opri încărcarea sursei dacă evenimentulcanplaythroughnu se declanșează în 2 secunde.Dacă doriți să vă aprofundați puțin, iată câteva resurse pentru a începe:
- Addy Osmani arată cum să implementați servirea adaptivă în React.
- React Adaptive Loading Hooks & Utilities oferă fragmente de cod pentru React,
- Netanel Basel explorează componentele conștiente de conexiune în Angular,
- Theodore Vorilas împărtășește cum funcționează Servirea componentelor adaptive folosind API-ul de informații de rețea în Vue.
- Umar Hansa arată cum să descărcați/executați JavaScript în mod selectiv.
-
- Luați în considerare posibilitatea de a face componentele dispozitivului conștient de memorie.
Totuși, conexiunea la rețea ne oferă o singură perspectivă asupra contextului utilizatorului. Mergând mai departe, puteți, de asemenea, să ajustați dinamic resursele în funcție de memoria disponibilă a dispozitivului, cu API-ul Device Memory.navigator.deviceMemoryreturns how much RAM the device has in gigabytes, rounded down to the nearest power of two. The API also features a Client Hints Header,Device-Memory, that reports the same value.Bonus : Umar Hansa shows how to defer expensive scripts with dynamic imports to change the experience based on device memory, network connectivity and hardware concurrency.
- Warm up the connection to speed up delivery.
Use resource hints to save time ondns-prefetch(which performs a DNS lookup in the background),preconnect(which asks the browser to start the connection handshake (DNS, TCP, TLS) in the background),prefetch(which asks the browser to request a resource) andpreload(which prefetches resources without executing them, among other things). Well supported in modern browsers, with support coming to Firefox soon.Remember
prerender? The resource hint used to prompt browser to build out the entire page in the background for next navigation. The implementations issues were quite problematic, ranging from a huge memory footprint and bandwidth usage to multiple registered analytics hits and ad impressions.Unsurprinsingly, it was deprecated, but the Chrome team has brought it back as NoState Prefetch mechanism. In fact, Chrome treats the
prerenderhint as a NoState Prefetch instead, so we can still use it today. As Katie Hempenius explains in that article, "like prerendering, NoState Prefetch fetches resources in advance ; but unlike prerendering, it does not execute JavaScript or render any part of the page in advance."NoState Prefetch only uses ~45MiB of memory and subresources that are fetched will be fetched with an
IDLENet Priority. Since Chrome 69, NoState Prefetch adds the header Purpose: Prefetch to all requests in order to make them distinguishable from normal browsing.Also, watch out for prerendering alternatives and portals, a new effort toward privacy-conscious prerendering, which will provide the inset
previewof the content for seamless navigations.Using resource hints is probably the easiest way to boost performance , and it works well indeed. When to use what? As Addy Osmani has explained, it's reasonable to preload resources that we know are very likely to be used on the current page and for future navigations across multiple navigation boundaries, eg Webpack bundles needed for pages the user hasn't visited yet.
Addy's article on "Loading Priorities in Chrome" shows how exactly Chrome interprets resource hints, so once you've decided which assets are critical for rendering, you can assign high priority to them. To see how your requests are prioritized, you can enable a "priority" column in the Chrome DevTools network request table (as well as Safari).
Most of the time these days, we'll be using at least
preconnectanddns-prefetch, and we'll be cautious with usingprefetch,preloadandprerender. Note that even withpreconnectanddns-prefetch, the browser has a limit on the number of hosts it will look up/connect to in parallel, so it's a safe bet to order them based on priority ( thanks Philip Tellis! ).Since fonts usually are important assets on a page, sometimes it's a good idea to request the browser to download critical fonts with
preload. However, double check if it actually helps performance as there is a puzzle of priorities when preloading fonts: aspreloadis seen as high importance, it can leapfrog even more critical resources like critical CSS. ( thanks, Barry! )<!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /><!-- Loading two rendering-critical fonts, but not all their weights. --> <!-- crossorigin="anonymous" is required due to CORS. Without it, preloaded fonts will be ignored. https://github.com/w3c/preload/issues/32 via https://twitter.com/iamakulov/status/1275790151642423303 --> <link rel="preload" as="font" href="Elena-Regular.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" /> <link rel="preload" as="font" href="Mija-Bold.woff2" type="font/woff2" crossorigin="anonymous" media="only screen and (min-width: 48rem)" />Since
<link rel="preload">accepts amediaattribute, you could choose to selectively download resources based on@mediaquery rules, as shown above.Furthermore, we can use
imagesrcsetandimagesizesattributes to preload late-discovered hero images faster, or any images that are loaded via JavaScript, eg movie posters:<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image><!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="image" href="poster.jpg" image image>We can also preload the JSON as fetch , so it's discovered before JavaScript gets to request it:
<!-- Addy Osmani. https://addyosmani.com/blog/preload-hero-images/ --> <link rel="preload" as="fetch" href="foo.com/api/movies.json" crossorigin>We could also load JavaScript dynamically, effectively for lazy execution of the script.
/* Adding a preload hint to the head */ var preload = document.createElement("link"); link.href = "myscript.js"; link.rel = "preload"; link.as = "script"; document.head.appendChild(link); /* Injecting a script when we want it to execute */ var script = document.createElement("script"); script.src = "myscript.js"; document.body.appendChild(script);A few gotchas to keep in mind:
preloadis good for moving the start download time of an asset closer to the initial request, but preloaded assets land in the memory cache which is tied to the page making the request.preloadplays well with the HTTP cache: a network request is never sent if the item is already there in the HTTP cache.Hence, it's useful for late-discovered resources, hero images loaded via
background-image, inlining critical CSS (or JavaScript) and pre-loading the rest of the CSS (or JavaScript).
Preload important images early; no need to wait on JavaScript to discover them. (Image credit: “Preload Late-Discovered Hero Images Faster” by Addy Osmani) (Large preview) A
preloadtag can initiate a preload only after the browser has received the HTML from the server and the lookahead parser has found thepreloadtag. Preloading via the HTTP header could be a bit faster since we don't to wait for the browser to parse the HTML to start the request (it's debated though).Early Hints will help even further, enabling preload to kick in even before the response headers for the HTML are sent (on the roadmap in Chromium, Firefox). Plus, Priority Hints will help us indicate loading priorities for scripts.
Beware : if you're using
preload,asmust be defined or nothing loads, plus preloaded fonts without thecrossoriginattribute will double fetch. If you're usingprefetch, beware of theAgeheader issues in Firefox.
- Use service workers for caching and network fallbacks.
No performance optimization over a network can be faster than a locally stored cache on a user's machine (there are exceptions though). If your website is running over HTTPS, we can cache static assets in a service worker cache and store offline fallbacks (or even offline pages) and retrieve them from the user's machine, rather than going to the network.As suggested by Phil Walton, with service workers, we can send smaller HTML payloads by programmatically generating our responses. A service worker can request just the bare minimum of data it needs from the server (eg an HTML content partial, a Markdown file, JSON data, etc.), and then it can programmatically transform that data into a full HTML document. So once a user visits a site and the service worker is installed, the user will never request a full HTML page again. The performance impact can be quite impressive.
Browser support? Service workers are widely supported and the fallback is the network anyway. Does it help boost performance ? Oh yes, it does. And it's getting better, eg with Background Fetch allowing background uploads/downloads via a service worker as well.
There are a number of use cases for a service worker. For example, you could implement "Save for offline" feature, handle broken images, introduce messaging between tabs or provide different caching strategies based on request types. In general, a common reliable strategy is to store the app shell in the service worker's cache along with a few critical pages, such as offline page, frontpage and anything else that might be important in your case.
There are a few gotchas to keep in mind though. With a service worker in place, we need to beware range requests in Safari (if you are using Workbox for a service worker it has a range request module). If you ever stumbled upon
DOMException: Quota exceeded.error in the browser console, then look into Gerardo's article When 7KB equals 7MB.Așa cum scrie Gerardo, „Dacă construiți o aplicație web progresivă și întâmpinați stocare cache umflată atunci când lucrătorul dvs. de servicii memorează în cache activele statice furnizate de la CDN-uri, asigurați-vă că există antetul de răspuns CORS adecvat pentru resursele de origine încrucișată, nu stocați în cache răspunsurile opace. împreună cu lucrătorul dvs. de servicii, în mod neintenționat, activați elementele de imagine cu origini încrucișate în modul CORS adăugând atributul
crossoriginla eticheta<img>.”Există o mulțime de resurse excelente pentru a începe cu lucrătorii de service:
- Service Worker Mindset, care vă ajută să înțelegeți cum lucrează lucrătorii din service în culise și lucruri de înțeles atunci când construiți unul.
- Chris Ferdinandi oferă o serie grozavă de articole despre lucrătorii de servicii, explicând cum să creați aplicații offline și acoperind o varietate de scenarii, de la salvarea offline a paginilor vizualizate recent până la setarea unei date de expirare pentru articolele dintr-un cache pentru lucrătorii de service.
- Capcanele și cele mai bune practici pentru lucrătorii de service, cu câteva sfaturi despre domeniul de aplicare, întârzierea înregistrării unui lucrător de service și memorarea în cache a lucrătorului în service.
- Serial grozav de Ire Aderinokun pe „Offline First” cu Service Worker, cu o strategie de precaching a shell-ului aplicației.
- Service Worker: o introducere cu sfaturi practice despre cum să utilizați service worker pentru experiențe bogate offline, sincronizări periodice în fundal și notificări push.
- Merită întotdeauna să vă referiți la cartea de bucate offline a lui Jake Archibald, cu o serie de rețete despre cum să vă coaceți propriul lucrător de service.
- Workbox este un set de biblioteci de lucrători ai serviciului construit special pentru construirea de aplicații web progresive.
- Executați lucrători de server pe CDN/Edge, de exemplu pentru testarea A/B?
În acest moment, suntem destul de obișnuiți să rulăm lucrători de servicii pe client, dar cu CDN-urile care le implementează pe server, le-am putea folosi pentru a îmbunătăți performanța și pe margine.De exemplu, în testele A/B, când HTML trebuie să-și modifice conținutul pentru diferiți utilizatori, am putea folosi Service Workers pe serverele CDN pentru a gestiona logica. De asemenea, am putea transmite rescrierea HTML pentru a accelera site-urile care folosesc Fonturi Google.
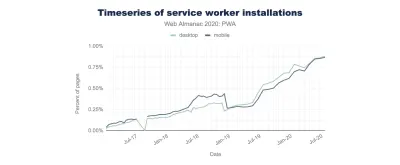
- Optimizați performanța de redare.
Ori de câte ori aplicația este lentă, este vizibilă imediat. Așa că trebuie să ne asigurăm că nu există nicio întârziere la derularea paginii sau când un element este animat și că atingeți constant 60 de cadre pe secundă. Dacă acest lucru nu este posibil, atunci este de preferat ca cel puțin să faceți consecvența cadrelor pe secundă față de un interval mixt de 60 până la 15. Utilizațiwill-changeCSS pentru a informa browserul despre ce elemente și proprietăți se vor schimba.Ori de câte ori vă confruntați, depanați revopsirile inutile în DevTools:
- Măsurați performanța de redare la timpul de execuție. Consultați câteva sfaturi utile despre cum să le înțelegeți.
- Pentru a începe, consultați cursul gratuit Udacity al lui Paul Lewis despre optimizarea redării browserului și articolul lui Georgy Marchuk despre pictarea browserului și considerente pentru performanța web.
- Activați Paint Flashing în „Mai multe instrumente → Redare → Paint Flashing” din Firefox DevTools.
- În React DevTools, bifați „Evidențiați actualizările” și activați „Înregistrați de ce este randată fiecare componentă”,
- De asemenea, puteți utiliza De ce ați randat, astfel încât, atunci când o componentă este redată din nou, un flash vă va anunța despre modificare.
Folosiți un aspect de zidărie? Rețineți că s-ar putea să construiți un aspect Masonry doar cu grila CSS, foarte curând.
Dacă doriți să aprofundați subiectul, Nolan Lawson a împărtășit trucuri pentru a măsura cu exactitate performanța aspectului în articolul său, iar Jason Miller a sugerat și tehnici alternative. Avem și un mic articol al lui Sergey Chikuyonok despre cum să obțineți animația GPU corect.

Browserele pot anima transformarea și opacitatea ieftin. Declanșatoarele CSS sunt utile pentru a verifica dacă CSS declanșează re-aspectări sau reflow. (Credit imagine: Addy Osmani) (Previzualizare mare) Notă : modificările aduse straturilor compuse din GPU sunt cele mai puțin costisitoare, așa că dacă puteți scăpa declanșând numai compunerea prin
opacityșitransform, veți fi pe drumul cel bun. Anna Migas a oferit o mulțime de sfaturi practice în discursul ei despre Debugging UI Rendering Performance, de asemenea. Și pentru a înțelege cum să depanați performanța vopselei în DevTools, verificați videoclipul de audit al performanței vopselei al lui Umar. - Ați optimizat pentru performanța percepută?
Deși secvența modului în care apar componentele pe pagină și strategia modului în care deservim activele browserului contează, nu ar trebui să subestimăm și rolul performanței percepute. Conceptul tratează aspectele psihologice ale așteptării, practic menținând clienții ocupați sau implicați în timp ce altceva se întâmplă. Acolo intră în joc managementul percepției, pornirea preventivă, finalizarea timpurie și managementul toleranței.Ce înseamnă toate acestea? În timpul încărcării activelor, putem încerca să fim întotdeauna cu un pas înaintea clientului, astfel încât experiența să fie rapidă, în timp ce se întâmplă destul de multe în fundal. Pentru a menține clientul implicat, putem testa ecrane schelete (demo de implementare) în loc de indicatori de încărcare, putem adăuga tranziții/animații și, practic, înșela UX-ul când nu mai este nimic de optimizat.
În studiul lor de caz despre The Art of UI Skeletons, Kumar McMillan împărtășește câteva idei și tehnici despre cum să simuleze liste dinamice, text și ecranul final, precum și cum să ia în considerare gândirea scheletului cu React.
Atenție totuși: ecranele scheletului ar trebui testate înainte de implementare, deoarece unele teste au arătat că ecranele scheletului pot funcționa cel mai rău după toate valorile.
- Preveniți schimbările de aspect și revopsiți?
În domeniul performanței percepute, probabil, una dintre experiențele cele mai perturbatoare este schimbarea aspectului sau refluxurile , cauzate de imagini și videoclipuri redimensionate, fonturi web, anunțuri injectate sau scripturi descoperite târziu care populează componente cu conținut real. Ca rezultat, un client ar putea începe să citească un articol doar pentru a fi întrerupt de un salt de aspect deasupra zonei de lectură. Experiența este adesea abruptă și destul de dezorientatoare: și acesta este probabil un caz de încărcare a priorităților care trebuie reconsiderate.Comunitatea a dezvoltat câteva tehnici și soluții alternative pentru a evita refluxurile. În general, este o idee bună să evitați inserarea de conținut nou deasupra conținutului existent , cu excepția cazului în care se întâmplă ca răspuns la o interacțiune a utilizatorului. Setați întotdeauna atributele de lățime și înălțime pe imagini, astfel încât browserele moderne alocă caseta și rezervă spațiul în mod implicit (Firefox, Chrome).
Atât pentru imagini, cât și pentru videoclipuri, putem folosi un substituent SVG pentru a rezerva caseta de afișare în care va apărea media. Aceasta înseamnă că zona va fi rezervată corect atunci când trebuie să-i mențineți și raportul de aspect. De asemenea, putem folosi substituenți sau imagini de rezervă pentru anunțuri și conținut dinamic, precum și pre-alocați spații de aspect.
În loc de încărcarea leneră a imaginilor cu scripturi externe, luați în considerare utilizarea încărcării leneșe native sau a încărcării leneșe hibride atunci când încărcăm un script extern numai dacă încărcarea leneră nativă nu este acceptată.
După cum s-a menționat mai sus, grupați întotdeauna revopsele fonturilor web și treceți de la toate fonturile alternative la toate fonturile web simultan - asigurați-vă doar că comutatorul nu este prea brusc, ajustând înălțimea liniilor și distanța dintre fonturi cu font-style-matcher .
Pentru a suprascrie valorile fonturilor pentru un font alternativ pentru a emula un font web, putem folosi descriptori @font-face pentru a înlocui valorile fontului (demo, activat în Chrome 87). (Rețineți că ajustările sunt complicate cu stivele complicate de fonturi.)
Pentru CSS târziu, ne putem asigura că CSS-ul critic pentru aspect este introdus în antetul fiecărui șablon. Mai mult decât atât: pentru paginile lungi, când este adăugată bara de defilare verticală, se deplasează conținutul principal cu 16 pixeli la stânga. Pentru a afișa o bară de derulare mai devreme, putem adăuga
overflow-y: scrollonhtmlpentru a impune o bară de defilare la prima vopsea. Acesta din urmă ajută, deoarece barele de defilare pot provoca modificări non-triviale ale aspectului din cauza refluxării conținutului de deasupra pliului atunci când lățimea se schimbă. Totuși, ar trebui să se întâmple mai ales pe platforme cu bare de defilare fără suprapunere, cum ar fi Windows. Dar:position: sticky, deoarece acele elemente nu vor derula niciodată din container.Dacă aveți de-a face cu anteturi care devin fixe sau lipicioase, poziționate în partea de sus a paginii pe defilare, rezervați spațiu pentru antet atunci când acesta devine blocat, de exemplu, cu un element substituent sau
margin-toppe conținut. O excepție ar trebui să fie bannerele de consimțământ pentru cookie-uri care nu ar trebui să aibă impact asupra CLS, dar uneori o fac: depinde de implementare. Există câteva strategii și concluzii interesante în acest thread de Twitter.Pentru o componentă a filei care ar putea include diverse cantități de texte, puteți preveni schimbările de aspect cu stivele de grilă CSS. Prin plasarea conținutului fiecărei file în aceeași zonă de grilă și ascunderea uneia dintre ele odată, ne putem asigura că containerul ia întotdeauna înălțimea elementului mai mare, astfel încât să nu apară schimbări de layout.
Ah, și bineînțeles, derularea infinită și „Încărcați mai mult” pot provoca și schimbări de aspect, dacă există conținut sub listă (de exemplu, subsol). Pentru a îmbunătăți CLS, rezervați suficient spațiu pentru conținutul care ar fi încărcat înainte ca utilizatorul să defileze la acea parte a paginii, eliminați subsolul sau orice elemente DOM din partea de jos a paginii care ar putea fi împins în jos prin încărcarea conținutului. De asemenea, preluați în prealabil datele și imaginile pentru conținutul de mai jos, astfel încât, în momentul în care un utilizator derulează atât de departe, acesta este deja acolo. Puteți utiliza biblioteci de virtualizare a listelor, cum ar fi react-window, pentru a optimiza și liste lungi ( mulțumesc, Addy Osmani! ).
Pentru a vă asigura că impactul refluxurilor este limitat, măsurați stabilitatea aspectului cu API-ul Layout Instability. Cu acesta, puteți calcula scorul Cumulative Layout Shift ( CLS ) și îl puteți include ca o cerință în testele dvs., astfel încât oricând apare o regresie, puteți să o urmăriți și să o remediați.
Pentru a calcula scorul deplasării aspectului, browserul analizează dimensiunea ferestrei de vizualizare și mișcarea elementelor instabile în fereastra de vizualizare între două cadre randate. În mod ideal, scorul ar fi aproape de
0. Există un ghid grozav de Milica Mihajlija și Philip Walton despre ce este CLS și cum să-l măsoare. Este un bun punct de plecare pentru a măsura și menține performanța percepută și pentru a evita întreruperea, în special pentru sarcinile esențiale pentru afaceri.Sfat rapid : pentru a descoperi ce a cauzat o schimbare de aspect în DevTools, puteți explora schimbările de aspect în „Experiență” din Panoul de performanță.
Bonus : dacă doriți să reduceți reflow-urile și revopsele, consultați ghidul lui Charis Theodoulou pentru Minimizarea DOM Reflow/Layout Thrashing și lista lui Paul Irish de Ce forțează layout-ul/reflow, precum și CSSTriggers.com, un tabel de referință cu proprietățile CSS care declanșează aspectul, pictura și compoziție.
Rețea și HTTP/2
- Este activată capsarea OCSP?
Prin activarea capsării OCSP pe serverul dvs., puteți accelera strângerile de mână TLS. Online Certificate Status Protocol (OCSP) a fost creat ca o alternativă la protocolul Certificate Revocation List (CRL). Ambele protocoale sunt folosite pentru a verifica dacă un certificat SSL a fost revocat.Cu toate acestea, protocolul OCSP nu necesită ca browserul să petreacă timp descarcând și apoi căutând o listă pentru informații despre certificat, reducând astfel timpul necesar pentru o strângere de mână.
- Ați redus impactul revocării certificatului SSL?
În articolul său despre „Costul de performanță al certificatelor EV”, Simon Hearne oferă o privire de ansamblu excelentă asupra certificatelor comune și impactul pe care alegerea unui certificat îl poate avea asupra performanței generale.După cum scrie Simon, în lumea HTTPS, există câteva tipuri de niveluri de validare a certificatelor utilizate pentru a securiza traficul:
- Validarea domeniului (DV) validează faptul că solicitantul de certificat deține domeniul,
- Validarea organizației (OV) validează faptul că o organizație deține domeniul,
- Extended Validation (EV) validează faptul că o organizație deține domeniul, cu o validare riguroasă.
Este important de menționat că toate aceste certificate sunt aceleași în ceea ce privește tehnologia; diferă doar prin informațiile și proprietățile furnizate în certificatele respective.
Certificatele EV sunt costisitoare și necesită timp , deoarece necesită ca o persoană să revizuiască un certificat și să asigure valabilitatea acestuia. Certificatele DV, pe de altă parte, sunt adesea furnizate gratuit - de exemplu de Let's Encrypt - o autoritate de certificare deschisă, automată, care este bine integrată în mulți furnizori de găzduire și CDN-uri. De fapt, la momentul redactării acestui articol, alimentează peste 225 de milioane de site-uri web (PDF), deși reprezintă doar 2,69% din pagini (deschise în Firefox).
Deci care este problema atunci? Problema este că certificatele EV nu acceptă pe deplin capsarea OCSP menționată mai sus. În timp ce capsarea permite serverului să verifice cu autoritatea de certificare dacă certificatul a fost revocat și apoi să adauge ("capsare") aceste informații la certificat, fără capsare, clientul trebuie să facă toată munca, rezultând solicitări inutile în timpul negocierii TLS . În cazul conexiunilor slabe, acest lucru ar putea duce la costuri de performanță vizibile (1000 ms+).
Certificatele EV nu sunt o alegere excelentă pentru performanța web și pot avea un impact mult mai mare asupra performanței decât certificatele DV. Pentru o performanță web optimă, trimiteți întotdeauna un certificat DV capsat OCSP. Ele sunt, de asemenea, mult mai ieftine decât certificatele de vehicule electrice și mai puține bătăi de cap de achiziționat. Ei bine, cel puțin până când CRLite este disponibil.
Comprimarea contează: 40–43% din lanțurile de certificate necomprimate sunt prea mari pentru a se potrivi într-un singur zbor QUIC de 3 datagrame UDP. (Credit imagine:) Rapid) (Previzualizare mare) Notă : Cu QUIC/HTTP/3 asupra noastră, merită remarcat faptul că lanțul de certificate TLS este singurul conținut de dimensiune variabilă care domină numărul de octeți în QUIC Handshake. Dimensiunea variază între câteva sute de byes și peste 10 KB.
Prin urmare, păstrarea certificatelor TLS mici contează foarte mult pe QUIC/HTTP/3, deoarece certificatele mari vor provoca mai multe strângeri de mână. De asemenea, trebuie să ne asigurăm că certificatele sunt comprimate, deoarece în caz contrar lanțurile de certificate ar fi prea mari pentru a se potrivi într-un singur zbor QUIC.
Puteți găsi mult mai multe detalii și indicații către problemă și soluții pe:
- Certificatele EV fac web-ul lent și nesigur de Aaron Peters,
- Impactul revocării certificatului SSL asupra performanței web de către Matt Hobbs,
- Costul de performanță al certificatelor EV de Simon Hearne,
- Strângerea de mână QUIC necesită compresie pentru a fi rapidă? de Patrick McManus.
- Ați adoptat încă IPv6?
Deoarece rămânem fără spațiu cu IPv4 și rețelele mobile majore adoptă IPv6 rapid (SUA aproape a atins un prag de adoptare IPv6 de 50%), este o idee bună să vă actualizați DNS-ul la IPv6 pentru a rămâne fără glonț pentru viitor. Doar asigurați-vă că suportul dual-stack este oferit în rețea - acesta permite IPv6 și IPv4 să ruleze simultan unul lângă celălalt. La urma urmei, IPv6 nu este compatibil cu versiunea inversă. De asemenea, studiile arată că IPv6 a făcut acele site-uri web cu 10 până la 15% mai rapide datorită descoperirii vecinilor (NDP) și optimizării rutei. - Asigurați-vă că toate activele rulează prin HTTP/2 (sau HTTP/3).
Cu Google îndreptându-se spre un web HTTPS mai sigur în ultimii ani, trecerea la mediul HTTP/2 este cu siguranță o investiție bună. De fapt, conform Web Almanac, 64% din toate solicitările rulează deja prin HTTP/2.Este important să înțelegeți că HTTP/2 nu este perfect și are probleme de prioritizare, dar este susținut foarte bine; și, în cele mai multe cazuri, ești mai bine cu el.
Un cuvânt de precauție: HTTP/2 Server Push este eliminat din Chrome, așa că, dacă implementarea dvs. se bazează pe Server Push, este posibil să fie necesar să îl revedeți. În schimb, s-ar putea să ne uităm la Early Hints, care sunt deja integrate ca experiment în Fastly.
Dacă încă rulați pe HTTP, sarcina cea mai consumatoare de timp va fi să migrați mai întâi la HTTPS, apoi să vă ajustați procesul de compilare pentru a satisface multiplexarea și paralelizarea HTTP/2. Aducerea HTTP/2 la Gov.uk este un studiu de caz fantastic despre acest lucru, găsind o cale prin CORS, SRI și WPT pe parcurs. Pentru restul acestui articol, presupunem că fie treceți la sau ați trecut deja la HTTP/2.
- Implementați corect HTTP/2.
Din nou, difuzarea materialelor prin HTTP/2 poate beneficia de o revizuire parțială a modului în care ați difuzat materiale până acum. Va trebui să găsiți un echilibru fin între modulele de ambalare și încărcarea multor module mici în paralel. La sfârșitul zilei, cea mai bună solicitare este nicio solicitare, cu toate acestea, scopul este de a găsi un echilibru fin între prima livrare rapidă a activelor și stocarea în cache.Pe de o parte, ați putea dori să evitați concatenarea totală a activelor, în loc să vă descompuneți întreaga interfață în multe module mici, să le comprimați ca parte a procesului de construire și să le încărcați în paralel. O modificare a unui fișier nu va necesita re-descărcarea întregii foi de stil sau JavaScript. De asemenea, minimizează timpul de analiză și menține un volum scăzut al paginilor individuale.
Pe de altă parte, ambalajul contează încă. Prin utilizarea multor scripturi mici, compresia generală va avea de suferit , iar costul de recuperare a obiectelor din cache va crește. Comprimarea unui pachet mare va beneficia de reutilizarea dicționarului, în timp ce pachetele mici separate nu vor beneficia. Există o muncă standard pentru a rezolva asta, dar este departe deocamdată. În al doilea rând, browserele nu au fost încă optimizate pentru astfel de fluxuri de lucru. De exemplu, Chrome va declanșa comunicații între procese (IPC) liniare cu numărul de resurse, astfel încât includerea a sute de resurse va avea costuri de rulare a browserului.
Pentru a obține cele mai bune rezultate cu HTTP/2, luați în considerare să încărcați CSS progresiv, așa cum a sugerat Jake Archibald de la Chrome. Totuși, puteți încerca să încărcați CSS progresiv. De fapt, CSS încorporat nu mai blochează redarea pentru Chrome. Dar există câteva probleme de prioritizare, așa că nu este la fel de simplu, dar merită experimentat.
Ați putea scăpa cu coalescerea conexiunii HTTP/2, care vă permite să utilizați fragmentarea domeniului beneficiind în același timp de HTTP/2, dar atingerea acestui lucru în practică este dificilă și, în general, nu este considerată a fi o bună practică. De asemenea, HTTP/2 și Integritatea subresursei nu funcționează întotdeauna.
Ce sa fac? Ei bine, dacă rulați prin HTTP/2, trimiterea a aproximativ 6-10 pachete pare un compromis decent (și nu este prea rău pentru browserele vechi). Experimentați și măsurați pentru a găsi echilibrul potrivit pentru site-ul dvs.
- Trimitem toate activele printr-o singură conexiune HTTP/2?
Unul dintre principalele avantaje ale HTTP/2 este că ne permite să trimitem active prin cablu printr-o singură conexiune. Cu toate acestea, uneori s-ar putea să fi făcut ceva greșit - de exemplu, am avut o problemă CORS sau am configurat greșit atributulcrossorigin, astfel încât browserul ar fi forțat să deschidă o nouă conexiune.Pentru a verifica dacă toate solicitările folosesc o singură conexiune HTTP/2 sau ceva este configurat greșit, activați coloana „ID conexiune” în DevTools → Rețea. De exemplu, aici, toate cererile au aceeași conexiune (286) - cu excepția manifest.json, care deschide una separată (451).
- Serverele și CDN-urile dvs. acceptă HTTP/2?
Diferite servere și CDN-uri (încă) acceptă HTTP/2 în mod diferit. Utilizați Comparația CDN pentru a vă verifica opțiunile sau căutați rapid cum funcționează serverele dvs. și ce caracteristici vă puteți aștepta să fie acceptate.Consultați cercetările incredibile ale lui Pat Meenan privind prioritățile HTTP/2 (video) și testați suportul serverului pentru prioritizarea HTTP/2. Potrivit lui Pat, este recomandat să activați controlul congestiei BBR și să setați
tcp_notsent_lowatla 16KB pentru ca prioritizarea HTTP/2 să funcționeze în mod fiabil pe nucleele Linux 4.9 și mai târziu ( mulțumesc, Yoav! ). Andy Davies a făcut o cercetare similară pentru prioritizarea HTTP/2 în browsere, CDN-uri și servicii de găzduire în cloud.În timp ce sunteți în el, verificați dacă nucleul dvs. acceptă TCP BBR și activați-l dacă este posibil. În prezent, este utilizat pe Google Cloud Platform, Amazon Cloudfront, Linux (de exemplu, Ubuntu).
- Este utilizată compresia HPACK?
Dacă utilizați HTTP/2, verificați de două ori dacă serverele dvs. implementează compresia HPACK pentru anteturile de răspuns HTTP pentru a reduce costurile inutile. Este posibil ca unele servere HTTP/2 să nu accepte pe deplin specificația, HPACK fiind un exemplu. H2spec este un instrument excelent (dacă foarte detaliat din punct de vedere tehnic) pentru a verifica asta. Algoritmul de compresie HPACK este destul de impresionant și funcționează. - Asigurați-vă că securitatea serverului dvs. este antiglonț.
Toate implementările browserului HTTP/2 rulează prin TLS, așa că probabil că veți dori să evitați avertismentele de securitate sau unele elemente de pe pagina dvs. să nu funcționeze. Verificați de două ori dacă anteturile dvs. de securitate sunt setate corect, eliminați vulnerabilitățile cunoscute și verificați configurarea HTTPS.De asemenea, asigurați-vă că toate pluginurile externe și scripturile de urmărire sunt încărcate prin HTTPS, că nu este posibilă crearea de scripturi între site-uri și că atât anteturile HTTP Strict Transport Security, cât și anteturile Politicii de securitate a conținutului sunt setate corect.
- Serverele și CDN-urile dvs. acceptă HTTP/3?
În timp ce HTTP/2 a adus o serie de îmbunătățiri semnificative de performanță pe web, a lăsat, de asemenea, o anumită zonă de îmbunătățire - în special blocarea head-of-line în TCP, care a fost vizibilă pe o rețea lentă, cu o pierdere semnificativă de pachete. HTTP/3 rezolvă definitiv aceste probleme (articol).Pentru a rezolva problemele legate de HTTP/2, IETF, împreună cu Google, Akamai și alții, au lucrat la un nou protocol care a fost recent standardizat ca HTTP/3.
Robin Marx a explicat foarte bine HTTP/3, iar următoarea explicație se bazează pe explicația sa. În nucleul său, HTTP/3 este foarte asemănător cu HTTP/2 în ceea ce privește caracteristicile, dar sub capotă funcționează foarte diferit. HTTP/3 oferă o serie de îmbunătățiri: strângeri de mână mai rapide, criptare mai bună, fluxuri independente mai fiabile, criptare mai bună și control al fluxului. O diferență notabilă este că HTTP/3 utilizează QUIC ca strat de transport, cu pachetele QUIC încapsulate deasupra diagramelor UDP, mai degrabă decât TCP.
QUIC integrează complet TLS 1.3 în protocol, în timp ce în TCP este stratificat deasupra. În stiva tipică TCP, avem câțiva timpi de supraîncălcare dus-întors, deoarece TCP și TLS trebuie să facă propriile strângeri de mână separate, dar cu QUIC ambele pot fi combinate și finalizate într-o singură călătorie dus-întors . Deoarece TLS 1.3 ne permite să setăm chei de criptare pentru o conexiune ulterioară, începând cu a doua conexiune, putem deja trimite și primi date de la nivelul aplicației în prima călătorie dus-întors, care se numește „0-RTT”.
De asemenea, algoritmul de compresie a antetului HTTP/2 a fost rescris în întregime, împreună cu sistemul său de prioritizare. În plus, QUIC acceptă migrarea conexiunii de la Wi-Fi la rețeaua celulară prin ID-urile de conexiune din antetul fiecărui pachet QUIC. Majoritatea implementărilor se fac în spațiul utilizatorului, nu în spațiul kernel (cum se face cu TCP), așa că ar trebui să ne așteptăm ca protocolul să evolueze în viitor.
Ar face totul o mare diferență? Probabil că da, mai ales având un impact asupra timpilor de încărcare pe mobil, dar și asupra modului în care deservim activele utilizatorilor finali. În timp ce în HTTP/2, cererile multiple partajează o conexiune, în HTTP/3 solicitările partajează și o conexiune, dar sunt transmise în mod independent, astfel încât un pachet abandonat nu mai afectează toate solicitările, doar un singur flux.
Aceasta înseamnă că, în timp ce cu un pachet JavaScript mare, procesarea activelor va fi încetinită atunci când un flux se întrerupe, impactul va fi mai puțin semnificativ atunci când mai multe fișiere sunt transmise în paralel (HTTP/3). Deci ambalajul încă contează .
HTTP/3 este încă în lucru. Chrome, Firefox și Safari au deja implementări. Unele CDN-uri acceptă deja QUIC și HTTP/3. La sfârșitul anului 2020, Chrome a început să implementeze HTTP/3 și IETF QUIC și, de fapt, toate serviciile Google (Google Analytics, YouTube etc.) rulează deja prin HTTP/3. LiteSpeed Web Server acceptă HTTP/3, dar nici Apache, nginx sau IIS nu îl acceptă încă, dar este posibil să se schimbe rapid în 2021.
Concluzia : dacă aveți o opțiune de a utiliza HTTP/3 pe server și pe CDN-ul dvs., probabil că este o idee foarte bună să faceți acest lucru. Principalul beneficiu va veni din preluarea mai multor obiecte simultan, în special în cazul conexiunilor cu latență ridicată. Nu știm încă sigur, deoarece nu s-au făcut multe cercetări în acel spațiu, dar primele rezultate sunt foarte promițătoare.
Dacă doriți să vă scufundați mai mult în specificul și avantajele protocolului, iată câteva puncte de plecare bune de verificat:
- HTTP/3 Explained, un efort de colaborare pentru a documenta protocoalele HTTP/3 și QUIC. Disponibil în diferite limbi, și în format PDF.
- Creșterea performanței web cu HTTP/3 cu Daniel Stenberg.
- Ghidul academic pentru QUIC cu Robin Marx introduce conceptele de bază ale protocoalelor QUIC și HTTP/3, explică modul în care HTTP/3 gestionează blocarea head-of-line și migrarea conexiunii și modul în care HTTP/3 este conceput pentru a fi mereu verde (mulțumesc, Simon !).
- Puteți verifica dacă serverul dumneavoastră rulează pe HTTP/3 pe HTTP3Check.net.
Testare și monitorizare
- V-ați optimizat fluxul de lucru de audit?
S-ar putea să nu sune mare lucru, dar dacă aveți setările potrivite la îndemână, vă poate economisi destul de mult timp în testare. Luați în considerare utilizarea Fluxului de lucru Alfred de la Tim Kadlec pentru WebPageTest pentru a trimite un test la instanța publică a WebPageTest. De fapt, WebPageTest are multe caracteristici obscure, așa că alocați timp pentru a învăța cum să citiți o diagramă WebPageTest Waterfall View și cum să citiți o diagramă WebPageTest Connection View pentru a diagnostica și rezolva problemele de performanță mai rapid.Puteți, de asemenea, să conduceți WebPageTest dintr-o foaie de calcul Google și să încorporați scorurile de accesibilitate, performanță și SEO în configurația dvs. Travis cu Lighthouse CI sau direct în Webpack.
Aruncă o privire la AutoWebPerf lansat recent, un instrument modular care permite colectarea automată a datelor de performanță din mai multe surse. De exemplu, am putea stabili un test zilnic pe paginile tale critice pentru a capta datele de câmp din API-ul CrUX și datele de laborator dintr-un raport Lighthouse de la PageSpeed Insights.
Și dacă trebuie să depanați ceva rapid, dar procesul dvs. de construire pare să fie remarcabil de lent, rețineți că „eliminarea spațiilor albe și alterarea simbolurilor reprezintă 95% din reducerea dimensiunii codului minimizat pentru majoritatea JavaScript - nu transformările elaborate de cod. Puteți pur și simplu dezactivați compresia pentru a accelera construirea Uglify de 3 până la 4 ori."
- Ați testat în browsere proxy și browsere vechi?
Testarea în Chrome și Firefox nu este suficientă. Priviți cum funcționează site-ul dvs. în browserele proxy și browserele vechi. UC Browser și Opera Mini, de exemplu, au o cotă de piață semnificativă în Asia (până la 35% în Asia). Măsurați viteza medie a internetului în țările dvs. de interes pentru a evita surprizele mari pe drum. Testați cu limitarea rețelei și emulați un dispozitiv cu DPI ridicat. BrowserStack este fantastic pentru testarea pe dispozitive reale de la distanță și completați-l cu cel puțin câteva dispozitive reale și în biroul dvs. - merită.
- Ați testat performanța celor 404 pagini?
În mod normal, nu ne gândim de două ori când vine vorba de 404 de pagini. La urma urmei, atunci când un client solicită o pagină care nu există pe server, serverul va răspunde cu un cod de stare 404 și pagina 404 asociată. Nu e atât de mult, nu-i așa?Un aspect important al răspunsurilor 404 este dimensiunea efectivă a corpului răspunsului care este trimis către browser. Conform cercetării pe 404 de pagini realizate de Matt Hobbs, marea majoritate a celor 404 răspunsuri provin din favicon-uri lipsă, solicitări de încărcare WordPress, solicitări JavaScript întrerupte, fișiere manifest, precum și fișiere CSS și fonturi. De fiecare dată când un client solicită un activ care nu există, va primi un răspuns 404 - și de multe ori acest răspuns este uriaș.
Asigurați-vă că examinați și optimizați strategia de stocare în cache pentru cele 404 pagini. Scopul nostru este să difuzăm HTML în browser numai atunci când acesta așteaptă un răspuns HTML și să returnăm o mică sarcină de eroare pentru toate celelalte răspunsuri. Potrivit lui Matt, „dacă plasăm un CDN în fața originii noastre, avem șansa de a stoca în cache răspunsul de 404 pagini pe CDN. Acest lucru este util deoarece fără el, lovirea unei pagini 404 ar putea fi folosită ca vector de atac DoS, prin forțând serverul de origine să răspundă la fiecare cerere 404, în loc să lase CDN-ul să răspundă cu o versiune în cache.”
Erorile 404 nu numai că vă pot afecta performanța, dar pot costa și în trafic, așa că este o idee bună să includeți o pagină de eroare 404 în suita dvs. de testare Lighthouse și să urmăriți scorul acesteia în timp.
- Ați testat performanța solicitărilor dvs. de consimțământ GDPR?
În vremurile GDPR și CCPA, a devenit obișnuit să se bazeze pe terțe părți pentru a oferi opțiuni pentru clienții din UE de a se înscrie sau de a renunța la urmărire. Cu toate acestea, ca și în cazul oricărui alt script terță parte, performanța lor poate avea un impact destul de devastator asupra întregului efort de performanță.Desigur, este posibil ca consimțământul real să schimbe impactul scripturilor asupra performanței generale, așa că, așa cum a remarcat Boris Schapira, ar putea dori să studiem câteva profiluri diferite de performanță web:
- Consimțământul a fost refuzat în totalitate,
- Consimțământul a fost parțial refuzat,
- Consimțământul a fost dat în întregime.
- Utilizatorul nu a acționat la solicitarea de consimțământ (sau solicitarea a fost blocată de un blocator de conținut),
În mod normal, solicitările de consimțământ pentru cookie-uri nu ar trebui să aibă un impact asupra CLS, dar uneori o fac, așa că luați în considerare utilizarea opțiunilor gratuite și open source Osano sau cookie-consent-box.
În general, merită să analizați performanța pop-up-ului , deoarece va trebui să determinați decalajul orizontal sau vertical al evenimentului mouse-ului și să poziționați corect pop-up-ul în raport cu ancora. Noam Rosenthal împărtășește cunoștințele echipei Wikimedia în articolul Studiu de caz privind performanța web: previzualizări ale paginii Wikipedia (disponibil și ca videoclip și minute).
- Păstrați un CSS de diagnosticare a performanței?
Deși putem include tot felul de verificări pentru a ne asigura că este implementat codul neperformant, de multe ori este util să ne facem o idee rapidă despre unele dintre fructele care ar putea fi rezolvate cu ușurință. Pentru asta, am putea folosi genialul Performance Diagnostics CSS al lui Tim Kadlec (inspirat de fragmentul lui Harry Roberts, care evidențiază imaginile încărcate lene, imaginile nedimensionate, imaginile în format vechi și scripturile sincrone.De exemplu, poate doriți să vă asigurați că nicio imagine de deasupra pliului nu este încărcată leneș. Puteți personaliza fragmentul pentru nevoile dvs., de exemplu, pentru a evidenția fonturile web care nu sunt utilizate sau pentru a detecta fonturile pentru pictograme. Un mic instrument grozav pentru a vă asigura că greșelile sunt vizibile în timpul depanării sau doar pentru a audita foarte rapid proiectul curent.
/* Performance Diagnostics CSS */ /* via Harry Roberts. https://twitter.com/csswizardry/status/1346477682544951296 */ img[loading=lazy] { outline: 10px solid red; }
- Have you tested the impact on accessibility?
When the browser starts to load a page, it builds a DOM, and if there is an assistive technology like a screen reader running, it also creates an accessibility tree. The screen reader then has to query the accessibility tree to retrieve the information and make it available to the user — sometimes by default, and sometimes on demand. And sometimes it takes time.When talking about fast Time to Interactive, usually we mean an indicator of how soon a user can interact with the page by clicking or tapping on links and buttons. The context is slightly different with screen readers. In that case, fast Time to Interactive means how much time passes by until the screen reader can announce navigation on a given page and a screen reader user can actually hit keyboard to interact.
Leonie Watson has given an eye-opening talk on accessibility performance and specifically the impact slow loading has on screen reader announcement delays. Screen readers are used to fast-paced announcements and quick navigation, and therefore might potentially be even less patient than sighted users.
Large pages and DOM manipulations with JavaScript will cause delays in screen reader announcements. A rather unexplored area that could use some attention and testing as screen readers are available on literally every platform (Jaws, NVDA, Voiceover, Narrator, Orca).
- Is continuous monitoring set up?
Having a private instance of WebPagetest is always beneficial for quick and unlimited tests. However, a continuous monitoring tool — like Sitespeed, Calibre and SpeedCurve — with automatic alerts will give you a more detailed picture of your performance. Set your own user-timing marks to measure and monitor business-specific metrics. Also, consider adding automated performance regression alerts to monitor changes over time.Look into using RUM-solutions to monitor changes in performance over time. For automated unit-test-alike load testing tools, you can use k6 with its scripting API. Also, look into SpeedTracker, Lighthouse and Calibre.
Victorii rapide
This list is quite comprehensive, and completing all of the optimizations might take quite a while. So, if you had just 1 hour to get significant improvements, what would you do? Let's boil it all down to 17 low-hanging fruits . Obviously, before you start and once you finish, measure results, including Largest Contentful Paint and Time To Interactive on a 3G and cable connection.
- Measure the real world experience and set appropriate goals. Aim to be at least 20% faster than your fastest competitor. Stay within Largest Contentful Paint < 2.5s, a First Input Delay < 100ms, Time to Interactive < 5s on slow 3G, for repeat visits, TTI < 2s. Optimize at least for First Contentful Paint and Time To Interactive.
- Optimize images with Squoosh, mozjpeg, guetzli, pingo and SVGOMG, and serve AVIF/WebP with an image CDN.
- Prepare critical CSS for your main templates, and inline them in the
<head>of each template. For CSS/JS, operate within a critical file size budget of max. 170KB gzipped (0.7MB decompressed). - Trim, optimize, defer and lazy-load scripts. Invest in the config of your bundler to remove redundancies and check lightweight alternatives.
- Always self-host your static assets and always prefer to self-host third-party assets. Limit the impact of third-party scripts. Use facades, load widgets on interaction and beware of anti-flicker snippets.
- Be selective when choosing a framework. For single-page-applications, identify critical pages and serve them statically, or at least prerender them, and use progressive hydration on component-level and import modules on interaction.
- Client-side rendering alone isn't a good choice for performance. Prerender if your pages don't change much, and defer the booting of frameworks if you can. If possible, use streaming server-side rendering.
- Serve legacy code only to legacy browsers with
<script type="module">and module/nomodule pattern. - Experiment with regrouping your CSS rules and test in-body CSS.
- Add resource hints to speed up delivery with faster
dns-lookup,preconnect,prefetch,preloadandprerender. - Subset web fonts and load them asynchronously, and utilize
font-displayin CSS for fast first rendering. - Check that HTTP cache headers and security headers are set properly.
- Enable Brotli compression on the server. (If that's not possible, at least make sure that Gzip compression is enabled.)
- Enable TCP BBR congestion as long as your server is running on the Linux kernel version 4.9+.
- Enable OCSP stapling and IPv6 if possible. Always serve an OCSP stapled DV certificate.
- Enable HPACK compression for HTTP/2 and move to HTTP/3 if it's available.
- Cache assets such as fonts, styles, JavaScript and images in a service worker cache.
Download The Checklist (PDF, Apple Pages)
With this checklist in mind, you should be prepared for any kind of front-end performance project. Feel free to download the print-ready PDF of the checklist as well as an editable Apple Pages document to customize the checklist for your needs:
- Download the checklist PDF (PDF, 166 KB)
- Download the checklist in Apple Pages (.pages, 275 KB)
- Download the checklist in MS Word (.docx, 151 KB)
If you need alternatives, you can also check the front-end checklist by Dan Rublic, the "Designer's Web Performance Checklist" by Jon Yablonski and the FrontendChecklist.
Plecăm!
Some of the optimizations might be beyond the scope of your work or budget or might just be overkill given the legacy code you have to deal with. That's fine! Use this checklist as a general (and hopefully comprehensive) guide, and create your own list of issues that apply to your context. But most importantly, test and measure your own projects to identify issues before optimizing. Happy performance results in 2021, everyone!
A huge thanks to Guy Podjarny, Yoav Weiss, Addy Osmani, Artem Denysov, Denys Mishunov, Ilya Pukhalski, Jeremy Wagner, Colin Bendell, Mark Zeman, Patrick Meenan, Leonardo Losoviz, Andy Davies, Rachel Andrew, Anselm Hannemann, Barry Pollard, Patrick Hamann, Gideon Pyzer, Andy Davies, Maria Prosvernina, Tim Kadlec, Rey Bango, Matthias Ott, Peter Bowyer, Phil Walton, Mariana Peralta, Pepijn Senders, Mark Nottingham, Jean Pierre Vincent, Philipp Tellis, Ryan Townsend, Ingrid Bergman, Mohamed Hussain SH, Jacob Groß, Tim Swalling, Bob Visser, Kev Adamson, Adir Amsalem, Aleksey Kulikov and Rodney Rehm for reviewing this article, as well as our fantastic community which has shared techniques and lessons learned from its work in performance optimization for everybody to use. Ești cu adevărat uluitor!