
Teste scazute: a scăpa de un coșmar viu în testare
Publicat: 2022-03-10Există o fabulă la care mă gândesc mult în aceste zile. Mi-a fost spusă fabula în copilărie. Se numește „The Boy Who Cried Wolf” de Esop. Este vorba despre un băiat care păzește oile satului său. Se plictisește și se preface că un lup atacă turma, strigând sătenii după ajutor - doar pentru ca aceștia să realizeze, dezamăgiți, că este o alarmă falsă și să-l lase pe băiat în pace. Apoi, când chiar apare un lup și băiatul cheamă ajutor, sătenii cred că este o altă alarmă falsă și nu vin în ajutor, iar oile ajung să fie mâncate de lup.
Morala poveștii este cel mai bine rezumată de autorul însuși:
„Un mincinos nu va fi crezut, chiar dacă spune adevărul.”
Un lup atacă oaia, iar băiatul strigă după ajutor, dar după nenumărate minciuni, nimeni nu-l mai crede. Această morală poate fi aplicată testării: povestea lui Esop este o alegorie drăguță pentru un model de potrivire pe care m-am dat peste cap: teste fulgice care nu reușesc să ofere nicio valoare.
Testare front-end: de ce să vă deranjați?
Majoritatea zilelor mele sunt petrecute pe testarea front-end. Deci nu ar trebui să vă surprindă că exemplele de cod din acest articol vor fi în mare parte din testele front-end pe care le-am întâlnit în munca mea. Cu toate acestea, în majoritatea cazurilor, acestea pot fi traduse cu ușurință în alte limbi și aplicate în alte cadre. Așadar, sper că articolul vă va fi de folos, indiferent de expertiză pe care ați avea.
Merită să ne amintim ce înseamnă testarea front-end. În esența sa, testarea front-end este un set de practici pentru testarea interfeței de utilizare a unei aplicații web, inclusiv funcționalitatea acesteia.
Începând ca inginer de asigurare a calității, cunosc durerea testării manuale nesfârșite dintr-o listă de verificare chiar înainte de lansare. Așadar, pe lângă obiectivul de a mă asigura că o aplicație rămâne fără erori în timpul actualizărilor succesive, m-am străduit să eliberez volumul de muncă al testelor cauzate de acele sarcini de rutină pentru care nu aveți nevoie de fapt de un om. Acum, în calitate de dezvoltator, găsesc subiectul încă relevant, mai ales că încerc să ajut direct utilizatorii și colegii deopotrivă. Și există o problemă cu testarea în special care ne-a dat coșmaruri.
Știința Testelor Flaky
Un test fulger este unul care nu reușește să producă același rezultat de fiecare dată când se execută aceeași analiză. Construirea va eșua doar ocazional: O dată va trece, alta dată va eșua, data viitoare va trece din nou, fără să fi fost făcute modificări la construcție.
Când îmi amintesc de coșmarurile mele de testare, îmi vine în minte un caz în special. A fost într-un test UI. Am construit o casetă combinată personalizată (adică o listă selectabilă cu câmp de intrare):
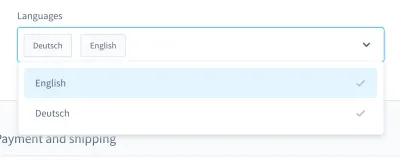
Cu această casetă combinată, puteți căuta un produs și puteți selecta unul sau mai multe rezultate. În multe zile, acest test a mers bine, dar la un moment dat, lucrurile s-au schimbat. Într-una dintre cele aproximativ zece versiuni ale sistemului nostru de integrare continuă (CI), testul pentru căutarea și selectarea unui produs din această casetă combinată a eșuat.
Captura de ecran a eșecului arată că lista de rezultate nu este filtrată, în ciuda faptului că căutarea a avut succes:
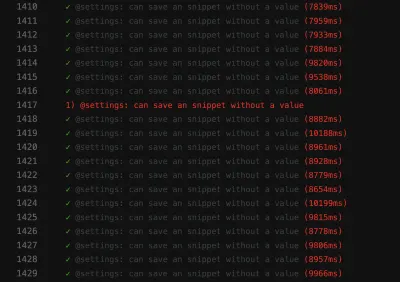
Un test neconformat ca acesta poate bloca conducta de implementare continuă , făcând livrarea caracteristicilor mai lentă decât trebuie. Mai mult decât atât, un test fulger este problematic, deoarece nu mai este determinist - făcându-l inutil. La urma urmei, nu ai avea încredere în cineva mai mult decât ai avea încredere într-un mincinos.
În plus, testele scazute sunt costisitoare de reparat , necesitând adesea ore sau chiar zile pentru depanare. Chiar dacă testele end-to-end sunt mai predispuse să fie fulgerătoare, le-am experimentat în tot felul de teste: teste unitare, teste funcționale, teste end-to-end și toate celelalte.
O altă problemă semnificativă cu testele neconformate este atitudinea pe care o au în noi dezvoltatorii. Când am început să lucrez în automatizarea testelor, am auzit adesea dezvoltatorii spunând asta ca răspuns la un test eșuat:
„Ah, construcția aceea. Nu contează, începe din nou. În cele din urmă, va trece, cândva.”
Acesta este un steag roșu imens pentru mine . Îmi arată că eroarea din build nu va fi luată în serios. Există o presupunere că un test fulger nu este o eroare reală, ci este „doar” scazut, fără a fi nevoie să fie îngrijit sau chiar depanat. Testul va trece din nou mai târziu oricum, nu? Nu! Dacă un astfel de commit este fuzionat, în cel mai rău caz vom avea un nou test flaky în produs.
Cauzele
Deci, testele de fulgi sunt problematice. Ce ar trebui să facem cu ei? Ei bine, dacă cunoaștem problema, putem proiecta o contrastrategie.
Întâlnesc adesea cauze în viața de zi cu zi. Ele pot fi găsite în cadrul testelor în sine . Testele ar putea fi scrise în mod suboptim, să conțină presupuneri greșite sau să conțină practici proaste. Cu toate acestea, nu numai atât. Testele fulminante pot fi un indiciu a ceva mult mai rău.
În secțiunile următoare, vom trece peste cele mai comune pe care le-am întâlnit.
1. Cauze din partea testului
Într-o lume ideală, starea inițială a aplicației dvs. ar trebui să fie impecabilă și previzibilă 100%. În realitate, nu știi niciodată dacă ID-ul pe care l-ai folosit în test va fi întotdeauna același.
Să inspectăm două exemple de un singur eșec din partea mea. Greșeala numărul unu a fost utilizarea unui ID în dispozitivele mele de testare:
{ "id": "f1d2554b0ce847cd82f3ac9bd1c0dfca", "name": "Variant product", }Greșeala numărul doi a fost căutarea unui selector unic pe care să-l folosească într-un test UI și gândirea: „Ok, acest ID pare unic. O voi folosi.”
<!-- This is a text field I took from a project I worked on --> <input type="text" />Cu toate acestea, dacă aș rula testul pe altă instalare sau, mai târziu, pe mai multe versiuni în CI, atunci acele teste ar putea eșua. Aplicația noastră ar genera ID-urile din nou, schimbându-le între versiuni. Așadar, prima cauză posibilă este de găsit în ID-urile hardcoded .
A doua cauză poate apărea din datele demo generate aleatoriu (sau altfel). Sigur, s-ar putea să vă gândiți că acest „defect” este justificat - la urma urmei, generarea datelor este aleatorie - dar gândiți-vă la depanarea acestor date. Poate fi foarte dificil să vezi dacă există o eroare în testele în sine sau în datele demo.
Urmează o cauză din partea testului cu care m-am luptat de multe ori: testele cu dependențe încrucișate . Este posibil ca unele teste să nu poată rula independent sau într-o ordine aleatorie, ceea ce este problematic. În plus, testele anterioare ar putea interfera cu cele ulterioare. Aceste scenarii pot provoca teste scazute prin introducerea de efecte secundare.
Cu toate acestea, nu uitați că testele sunt despre presupuneri provocatoare. Ce se întâmplă dacă presupunerile tale sunt greșite de la început? Am experimentat acestea des, preferatele mele fiind presupuneri greșite despre timp.
Un exemplu este utilizarea timpilor de așteptare inexacți, în special în testele UI - de exemplu, prin utilizarea timpilor de așteptare fixe . Următoarea linie este preluată dintr-un test Nightwatch.js.
// Please never do that unless you have a very good reason! // Waits for 1 second browser.pause(1000);O altă presupunere greșită se referă la timpul însuși. Odată am descoperit că un test PHPUnit defectuos nu a eșuat decât în versiunile noastre de noapte. După câteva depanări, am constatat că de vină era schimbarea oră dintre ieri și azi. Un alt exemplu bun sunt eșecurile din cauza fusurilor orare .
Ipotezele false nu se opresc aici. De asemenea, putem avea presupuneri greșite cu privire la ordinea datelor . Imaginați-vă o grilă sau o listă care conține mai multe intrări cu informații, cum ar fi o listă de valute:
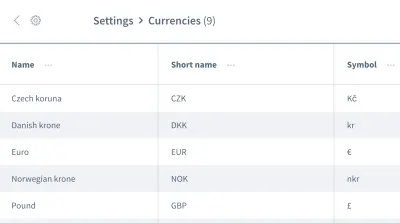
Dorim să lucrăm cu informațiile primei intrări, moneda „Coroana Cehă”. Puteți fi sigur că aplicația dvs. va plasa întotdeauna această bucată de date ca primă intrare de fiecare dată când testul este executat? S-ar putea ca „Euro” sau o altă monedă să fie prima intrare în unele ocazii?
Nu presupuneți că datele dvs. vor veni în ordinea în care aveți nevoie. Similar cu ID-urile codificate, o comandă se poate schimba între versiuni, în funcție de designul aplicației.
2. Cauze secundare mediului
Următoarea categorie de cauze se referă la tot ceea ce este în afara testelor dumneavoastră. Mai exact, vorbim despre mediul în care sunt executate testele, despre dependențele legate de CI și docker în afara testelor tale - toate acele lucruri pe care abia le poți influența, cel puțin în rolul tău de tester.
O cauză comună din partea mediului este scurgerile de resurse : de multe ori aceasta ar fi o aplicație sub încărcare, care provoacă timpi de încărcare variați sau comportament neașteptat. Testele mari pot provoca cu ușurință scurgeri, consumând multă memorie. O altă problemă comună este lipsa curățării .
Incompatibilitatea dintre dependențe îmi dă coșmaruri în special. A avut loc un coșmar când lucram cu Nightwatch.js pentru testarea UI. Nightwatch.js folosește WebDriver, care desigur depinde de Chrome. Când Chrome a avansat cu o actualizare, a apărut o problemă de compatibilitate: Chrome, WebDriver și Nightwatch.js în sine nu au mai funcționat împreună, ceea ce a cauzat eșuarea din când în când versiunile noastre.
Vorbind despre dependențe : o mențiune onorabilă se adresează oricăror probleme legate de npm, cum ar fi permisiunile lipsă sau npm nu este. Am experimentat toate acestea în observarea CI.
Când vine vorba de erori în testele UI din cauza problemelor de mediu, rețineți că aveți nevoie de întreaga stivă de aplicații pentru a putea rula. Cu cât sunt mai multe lucruri implicate, cu atât este mai mare potențialul de eroare . Testele JavaScript sunt, prin urmare, cele mai dificile teste de stabilizat în dezvoltarea web, deoarece acopera o cantitate mare de cod.
3. Cauze la nivelul produsului
Nu în ultimul rând, trebuie să fim foarte atenți la această a treia zonă - o zonă cu bug-uri reale. Vorbesc despre cauzele desprinderii din partea produsului. Unul dintre cele mai cunoscute exemple este condițiile de cursă dintr-o aplicație. Când se întâmplă acest lucru, bug-ul trebuie remediat în produs, nu în test! Încercarea de a repara testul sau mediul nu va avea niciun folos în acest caz.
Modalități de a lupta împotriva descuamării
Am identificat trei cauze ale descuamării. Ne putem construi contra-strategia pe asta! Desigur, deja vei fi câștigat foarte mult ținând cont de cele trei cauze atunci când te confrunți cu teste fulgerătoare. Veți ști deja ce să căutați și cum să îmbunătățiți testele. Cu toate acestea, pe lângă acestea, există câteva strategii care ne vor ajuta să proiectăm, să scriem și să depanăm teste și le vom analiza împreună în secțiunile următoare.
Concentrează-te pe echipa ta
Echipa ta este, fără îndoială, cel mai important factor . În primul pas, recunoașteți că aveți o problemă cu testele de fulgi. Obținerea angajamentului întregii echipe este crucială! Apoi, ca o echipă, trebuie să decideți cum să faceți față testelor scazute.
Pe parcursul anilor în care am lucrat în tehnologie, am întâlnit patru strategii folosite de echipe pentru a contracara deformarea:
- Nu faceți nimic și acceptați rezultatul testului slab.
Desigur, această strategie nu este deloc o soluție. Testul nu va aduce nicio valoare pentru că nu mai poți avea încredere în el - chiar dacă accepți slăbirea. Așa că îl putem sări peste acesta destul de repede. - Reîncercați testul până când trece.
Această strategie a fost comună la începutul carierei mele, rezultând răspunsul pe care l-am menționat mai devreme. A existat o oarecare acceptare cu reîncercarea testelor până când acestea au trecut. Această strategie nu necesită depanare, dar este leneșă. Pe lângă ascunderea simptomelor problemei, va încetini și mai mult suita dvs. de teste, ceea ce face ca soluția să nu fie viabilă. Cu toate acestea, ar putea exista unele excepții de la această regulă, pe care le voi explica mai târziu. - Ștergeți și uitați de test.
Acesta se explică de la sine: pur și simplu ștergeți testul fulger, astfel încât să nu vă mai deranjeze suita de teste. Sigur, vă va economisi bani, deoarece nu va mai trebui să depanați și să remediați testul. Dar vine în detrimentul pierderii unui pic de acoperire a testelor și pierderii potențialelor remedieri de erori. Testul există cu un motiv! Nu trageți messengerul ștergând testul. - Carantină și remediere.
Am avut cel mai mare succes cu această strategie. În acest caz, vom sări peste test temporar și ar fi suita de teste să ne reamintească în mod constant că un test a fost omis. Pentru a ne asigura că soluția nu este trecută cu vederea, vom programa un bilet pentru următorul sprint. De asemenea, mementourile pentru bot funcționează bine. Odată remediată problema care provoacă slăbirea, vom integra (adică vom anula) testul din nou. Din păcate, vom pierde temporar acoperirea, dar va reveni cu o remediere, așa că nu va dura mult.
Aceste strategii ne ajută să facem față problemelor de testare la nivel de flux de lucru și nu sunt singurul care le-a întâlnit. În articolul său, Sam Saffron ajunge la o concluzie similară. Dar în munca noastră de zi cu zi, ei ne ajută într-o măsură limitată. Deci, cum procedăm atunci când o astfel de sarcină ne vine în cale?

Păstrați testele izolate
Când vă planificați cazurile și structura de testare, păstrați întotdeauna testele izolate de alte teste, astfel încât acestea să poată fi rulate într-o ordine independentă sau aleatorie. Cel mai important pas este restabilirea unei instalații curate între teste . În plus, testați doar fluxul de lucru pe care doriți să îl testați și creați date simulate numai pentru testul în sine. Un alt avantaj al acestei comenzi rapide este că va îmbunătăți performanța testului . Dacă respectați aceste puncte, niciun efect secundar de la alte teste sau datele rămase nu va sta în cale.
Exemplul de mai jos este preluat din testele UI ale unei platforme de comerț electronic și se ocupă de autentificarea clientului în vitrina magazinului. (Testul este scris în JavaScript, folosind cadrul Cypress.)
// File: customer-login.spec.js let customer = {}; beforeEach(() => { // Set application to clean state cy.setInitialState() .then(() => { // Create test data for the test specifically return cy.setFixture('customer'); }) }): Primul pas este resetarea aplicației la o instalare curată. Se face ca prim pas în beforeEach ciclului de viață înainte de fiecare pentru a vă asigura că resetarea este executată de fiecare dată. Ulterior, datele de testare sunt create special pentru test - pentru acest caz de testare, un client ar fi creat printr-o comandă personalizată. Ulterior, putem începe cu singurul flux de lucru pe care dorim să-l testăm: autentificarea clientului.
Optimizați în continuare structura de testare
Putem face alte mici ajustări pentru a face structura noastră de testare mai stabilă. Primul este destul de simplu: începeți cu teste mai mici. După cum s-a spus anterior, cu cât faci mai multe într-un test, cu atât mai multe pot merge prost. Păstrați testele cât mai simple posibil și evitați multă logică în fiecare.
Când vine vorba de a nu presupune o ordine a datelor (de exemplu, când avem de-a face cu ordinea intrărilor dintr-o listă în testarea UI), putem proiecta un test să funcționeze independent de orice ordine. Pentru a aduce înapoi exemplul grilei cu informații în ea, nu am folosi pseudo-selectori sau alte CSS care au o dependență puternică de ordine. În loc de selectorul nth-child(3) , am putea folosi text sau alte lucruri pentru care ordinea nu contează. De exemplu, am putea folosi o afirmație de genul „Găsiți-mi elementul cu acest șir de text în acest tabel”.
Aștepta! Reîncercările de testare sunt uneori OK?
Reîncercarea testelor este un subiect controversat și pe bună dreptate. Încă mă gândesc la asta ca la un anti-model dacă testul este reîncercat orbește până la succes. Cu toate acestea, există o excepție importantă: când nu puteți controla erorile, reîncercarea poate fi o ultimă soluție (de exemplu, pentru a exclude erorile din dependențele externe). În acest caz, nu putem influența sursa erorii. Cu toate acestea, fiți deosebit de atenți atunci când faceți acest lucru: nu deveniți orbi la slăbiciune când reîncercați un test și utilizați notificările pentru a vă reaminti când un test este omis.
Următorul exemplu este unul pe care l-am folosit în CI cu GitLab. Alte medii ar putea avea o sintaxă diferită pentru a realiza reîncercări, dar acest lucru ar trebui să vă ofere un gust:
test: script: rspec retry: max: 2 when: runner_system_failureÎn acest exemplu, configurăm câte încercări ar trebui făcute dacă lucrarea eșuează. Ceea ce este interesant este posibilitatea de a reîncerca dacă există o eroare în sistemul de rulare (de exemplu, configurarea jobului a eșuat). Alegem să reîncercăm treaba numai dacă ceva din configurarea docker eșuează.
Rețineți că aceasta va reîncerca întreaga sarcină atunci când este declanșată. Dacă doriți să reîncercați doar testul defect, atunci va trebui să căutați o funcție în cadrul de testare pentru a sprijini acest lucru. Mai jos este un exemplu de la Cypress, care a acceptat reîncercarea unui singur test începând cu versiunea 5:
{ "retries": { // Configure retry attempts for 'cypress run` "runMode": 2, // Configure retry attempts for 'cypress open` "openMode": 2, } } Puteți activa reîncercări de testare în fișierul de configurare al lui Cypress, cypress.json . Acolo, puteți defini încercările de reîncercare în modul alergător de testare și fără cap.
Utilizarea timpilor dinamici de așteptare
Acest punct este important pentru tot felul de teste, dar mai ales pentru testarea UI. Nu pot sublinia îndeajuns acest lucru: nu utilizați niciodată timpi de așteptare fixe - cel puțin nu fără un motiv foarte întemeiat. Dacă o faci, ia în considerare posibilele rezultate. În cel mai bun caz, veți alege timpi de așteptare prea lungi, ceea ce face ca suita de teste să fie mai lentă decât trebuie. În cel mai rău caz, nu veți aștepta suficient, așa că testul nu va continua, deoarece aplicația nu este încă gata, ceea ce face ca testul să eșueze într-o manieră instabilă. Din experiența mea, aceasta este cea mai frecventă cauză a testelor de descuamare.
În schimb, utilizați timpi de așteptare dinamici. Există multe modalități de a face acest lucru, dar Cypress le gestionează deosebit de bine.
Toate comenzile Cypress dețin o metodă implicită de așteptare: verifică deja dacă elementul căruia i se aplică comanda există în DOM pentru timpul specificat, indicând capacitatea de reîncercare a lui Cypress. Cu toate acestea, verifică doar existența și nimic mai mult. Așa că vă recomand să faceți un pas mai departe - așteptați orice modificări în site-ul dvs. web sau în interfața de utilizare a aplicației pe care le-ar vedea și un utilizator real, cum ar fi modificări în interfața de utilizare în sine sau în animație.
Acest exemplu folosește un timp de așteptare explicit pe elementul cu selectorul .offcanvas . Testul va continua numai dacă elementul este vizibil până la expirarea specificată, pe care o puteți configura:
// Wait for changes in UI (until element is visible) cy.get(#element).should('be.visible'); O altă posibilitate bună în Cypress pentru așteptarea dinamică sunt caracteristicile sale de rețea. Da, putem aștepta să apară cereri și rezultatele răspunsurilor lor. Folosesc acest tip de așteptare mai ales des. În exemplul de mai jos, definim cererea de așteptat, folosim o comandă wait pentru a aștepta răspunsul și afirmăm codul de stare:
// File: checkout-info.spec.js // Define request to wait for cy.intercept({ url: '/widgets/customer/info', method: 'GET' }).as('checkoutAvailable'); // Imagine other test steps here... // Assert the response's status code of the request cy.wait('@checkoutAvailable').its('response.statusCode') .should('equal', 200);În acest fel, suntem capabili să așteptăm exact atâta timp cât are nevoie aplicația noastră, făcând testele mai stabile și mai puțin predispuse la deformare din cauza scurgerilor de resurse sau a altor probleme de mediu.
Depanarea testelor scazute
Acum știm cum să prevenim testele scazute prin proiectare. Dar ce se întâmplă dacă ai deja de-a face cu un test fulger? Cum poți scăpa de ea?
Când depanam, punerea testului defectuos într-o buclă m-a ajutat foarte mult să descopăr slăbirea. De exemplu, dacă rulați un test de 50 de ori și acesta trece de fiecare dată, atunci puteți fi mai sigur că testul este stabil - poate că remedierea dvs. a funcționat. Dacă nu, puteți obține cel puțin mai multe informații despre testul de fulgi.
// Use in build Lodash to repeat the test 100 times Cypress._.times(100, (k) => { it(`typing hello ${k + 1} / 100`, () => { // Write your test steps in here }) }) Obținerea mai multor informații despre acest test fulger este deosebit de dificilă în CI. Pentru a obține ajutor, vedeți dacă cadrul dvs. de testare poate obține mai multe informații despre versiunea dvs. Când vine vorba de testarea front-end, puteți utiliza de obicei un console.log în testele dvs.:
it('should be a Vue.JS component', () => { // Mock component by a method defined before const wrapper = createWrapper(); // Print out the component's html console.log(wrapper.html()); expect(wrapper.isVueInstance()).toBe(true); }) Acest exemplu este luat dintr-un test unitar Jest în care folosesc un console.log pentru a obține rezultatul HTML-ului componentei testate. Dacă utilizați această posibilitate de înregistrare în testul Cypress, puteți chiar să inspectați rezultatul în instrumentele de dezvoltare alese. În plus, când vine vorba de Cypress în CI, puteți inspecta această ieșire în jurnalul CI folosind un plugin.
Priviți întotdeauna caracteristicile cadrului dvs. de testare pentru a obține asistență cu înregistrarea în jurnal. În testarea UI, majoritatea cadrelor oferă caracteristici de captură de ecran - cel puțin în caz de eșec, o captură de ecran va fi făcută automat. Unele cadre oferă chiar și înregistrare video , ceea ce poate fi de mare ajutor pentru a obține o perspectivă asupra a ceea ce se întâmplă în testul dvs.
Luptă împotriva coșmarurilor flakiness!
Este important să căutați în mod continuu testele scazute, fie prin prevenirea lor în primul rând, fie prin depanarea și remedierea lor imediat ce apar. Trebuie să le luăm în serios, deoarece pot sugera probleme în aplicația dvs.
Observând Steaguri Roșii
Cel mai bine este, desigur, prevenirea testelor de descuamare. Pentru a recapitula rapid, iată câteva semnale roșii:
- Testul este mare și conține multă logică.
- Testul acoperă o mulțime de cod (de exemplu, în testele UI).
- Testul folosește timpi de așteptare fixați.
- Testul depinde de testele anterioare.
- Testul afirmă date care nu sunt 100% previzibile, cum ar fi utilizarea ID-urilor, a orelor sau a datelor demonstrative, în special a celor generate aleatoriu.
Dacă țineți cont de indicațiile și strategiile din acest articol, puteți preveni testele neconformate înainte ca acestea să aibă loc. Și dacă vin, veți ști cum să le depanați și să le remediați.
Acești pași m-au ajutat cu adevărat să-mi recapăt încrederea în suita noastră de teste. Suita noastră de teste pare să fie stabilă în acest moment. Ar putea apărea probleme în viitor - nimic nu este 100% perfect. Aceste cunoștințe și aceste strategii mă vor ajuta să le fac față. Astfel, voi crește încrezător în capacitatea mea de a lupta împotriva acelor coșmaruri de test .
Sper că am reușit să-ți scad măcar o parte din durerea și îngrijorările tale cu privire la desprindere!
Lectură suplimentară
Dacă doriți să aflați mai multe despre acest subiect, iată câteva resurse și articole îngrijite, care m-au ajutat foarte mult:
- Articole despre „fulg”, Cypress.io
- „Reîncercarea testelor este de fapt un lucru bun (dacă abordarea dvs. este corectă)”, Filip Hric, Cypress.io
- „Test Flakiness: Methods for Identification and Dealing With Flakiness Tests”, Jason Palmer, Spotify R&D Engineering
- „Testele scazute la Google și cum le atenuăm”, John Micco, Blogul de testare Google