
Detectarea știrilor false în învățarea automată [explicată cu un exemplu de codare]
Publicat: 2021-02-08Știrile false sunt una dintre cele mai mari probleme în era actuală a internetului și a rețelelor sociale. Deși este o binecuvântare că știrile curg dintr-un colț al lumii în altul în câteva ore, este și dureros să vezi mulți oameni și grupuri răspândind știri false.
Tehnicile de învățare automată care utilizează procesarea limbajului natural și învățarea profundă pot fi utilizate pentru a rezolva această problemă într-o oarecare măsură. Vom construi un model de detectare a știrilor false folosind Machine Learning în acest tutorial.
Până la sfârșitul acestui articol, veți ști următoarele:
- Manipularea datelor text
- Tehnici de procesare NLP
- Vectorizare numărătoare și TF-IDF
- Efectuarea de predicții și clasificarea textului de știri
Alăturați-vă cursului AI și ML online de la cele mai bune universități din lume - Master, Programe Executive Postuniversitare și Programul de Certificat Avansat în ML și AI pentru a vă accelera cariera.
Cuprins
Date și problemă
Vom folosi datele provocării Kaggle Fake News pentru a face un clasificator. Setul de date este format din 4 caracteristici și 1 țintă binară. Cele 4 caracteristici sunt următoarele:
- id : id unic pentru un articol de știri
- title : titlul unui articol de știri
- autor : autor al articolului de știri
- text : textul articolului; ar putea fi incomplet
Și ținta este „eticheta” care conține valori binare 0 și 1. Unde 0 înseamnă că este o sursă sigură de știri sau, cu alte cuvinte, Nu este fals. 1 înseamnă că este o știre potențial falsă și nu este de încredere. Setul de date pe care îl avem a constat din 20800 de instanțe. Să ne scufundăm direct.

Preprocesarea și curățarea datelor
| importa panda ca pd df=pd.read_csv( 'fake-news/train.csv' ) df.head() |
| X=df.drop( 'etichetă' ,axa= 1 ) # Caracteristici y=df[ 'etichetă' ] # Țintă |
Trebuie să renunțăm acum la instanțe cu date lipsă.
| df=df.dropna() |
![]()
După cum putem vedea, a eliminat toate instanțele cu date lipsă.
| mesaje=df.copy() messages.reset_index(inplace= True ) mesaje.head( 10 ) |
Să ne uităm o dată la date.
| mesaje['text'][6] |

După cum putem vedea, este necesar să faceți următorii pași:
- Eliminarea cuvintelor oprite: există o mulțime de cuvinte care nu adaugă nicio valoare textului, indiferent de date. De exemplu, „eu”, „a”, „sunt”, etc. Aceste cuvinte nu au valoare informațională și, prin urmare, pot fi eliminate pentru a reduce dimensiunea corpusului nostru, astfel încât să ne putem concentra doar asupra cuvintelor/semnalelor care au valoare reală. .
- Strângerea cuvintelor: Stemming și lematizarea sunt tehnici de reducere a cuvintelor la tulpinile sau rădăcinile lor. Principalul avantaj al acestui pas este reducerea dimensiunii vocabularului. De exemplu, cuvinte precum Play, Playing, Played vor fi reduse la „Play”. Stemming doar trunchiază cuvintele la cel mai scurt cuvânt și nu ia în considerare aspectul gramatical al textului. Lematizarea, pe de altă parte, ia în considerare și o atenție gramaticală și, prin urmare, produce rezultate mult mai bune. Cu toate acestea, lematizarea este de obicei mai lentă decât stemming, deoarece trebuie să se refere la dicționar și să ia în considerare aspectul gramatical.
- Eliminarea tuturor, în afară de valorile alfabetice: valorile non-alfabetice nu sunt foarte utile aici, așa că pot fi eliminate. Cu toate acestea, puteți explora în continuare pentru a vedea dacă prezența datelor numerice sau a altor tipuri de date are vreun impact asupra țintei.
- Minusculele cuvintelor: Minusculele cuvintelor pentru a reduce vocabularul.
- Tokenizarea propozițiilor: generarea de jetoane din propoziții.
| din sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer, HashingVectorizer de la nltk.corpus importarea cuvintelor oprite din nltk.stem.porter import PorterStemmer import re ps = PorterStemmer() corpus = [] pentru i în interval(0, len(mesaje)): recenzie = re.sub('[^a-zA-Z]', '', mesaje['text'][i]) review = review.lower() review = review.split() review = [ps.stem(word) pentru cuvânt în recenzie, dacă nu cuvânt în stopwords.words('english')] review = ' '.join(review) corpus.append(review) |
Să aruncăm o privire asupra corpusului nostru acum.
| corpus[ 3 ] |
![]()
După cum putem vedea, cuvintele sunt acum derivate din cuvintele rădăcină.
Vectorizator TF-IDF
Acum trebuie să vectorizăm cuvintele în date numerice care se mai numesc și vectorizare. Cea mai ușoară modalitate de a vectoriza este să utilizați Punga de Cuvinte. Dar Bag of Words creează o matrice rară și, prin urmare, este nevoie de multă memorie de procesare. Mai mult, BoW nu ia în considerare frecvența cuvintelor, ceea ce îl face un algoritm prost.
TF-IDF (Term Frequency – Inverse Document Frequency) este o altă modalitate de a vectoriza cuvintele care ia în considerare frecvențele cuvintelor. De exemplu, cuvinte comune precum „noi”, „nostru”, „cel” sunt în fiecare document/instanță, prin urmare valoarea BoW va fi prea mare și, prin urmare, va induce în eroare. Acest lucru va duce la un model prost. TF-IDF este multiplicarea frecvenței termenului și a frecvenței inverse a documentului.
Frecvența termenului ia în considerare frecvența cuvintelor dintr-un document, iar Frecvența documentului invers ia în considerare cuvintele care sunt prezente în întregul corpus. Cuvintele care sunt prezente în întregul corpus au o importanță redusă, deoarece valoarea IDF este mult mai mică. Cuvintele care sunt prezente în mod specific într-un document au o valoare IDF mare, ceea ce face ca valoarea totală a TF-IDF să fie ridicată.
| ## TFi df Vectorizer din sklearn.feature_extraction.text import TfidfVectorizer tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messages[ 'etichetă' ] |
În codul de mai sus, importăm Vectorizatorul TF-IDF din modulul de extracție a caracteristicilor Sklearn. Facem obiectul său trecând max_features ca 5000 și ngram_range ca (1,3). Parametrul max_features definește numărul maxim de vectori de caracteristici pe care dorim să-i creăm, iar parametrul ngram_range definește combinațiile de ngram pe care dorim să le includem. În cazul nostru, vom obține 3 combinații de 1 cuvânt, 2 cuvinte și 3 cuvinte. Să aruncăm o privire la unele dintre caracteristicile create.

| tfidf_v.get_feature_names()[: 20 ] |

După cum putem vedea, există mai multe tipuri de combinații formate. Există nume de caracteristici cu 1 jetoane, 2 jetoane și, de asemenea, cu 3 jetoane.
Realizarea unui cadru de date
| ## Împărțiți setul de date în Train și Test din sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = tren_test_split(X, y, test_size= 0,33 , random_state= 0 ) count_df = pd.DataFrame(X_train, columns=tfidf_v.get_feature_names()) count_df.head() |
Împărțim setul de date în tren și test, astfel încât să putem testa performanța modelului pe date nevăzute. Apoi facem un nou Dataframe care conține noile vectori de caracteristici în el.
Modelare și reglare
Algoritmul MultinomialNB
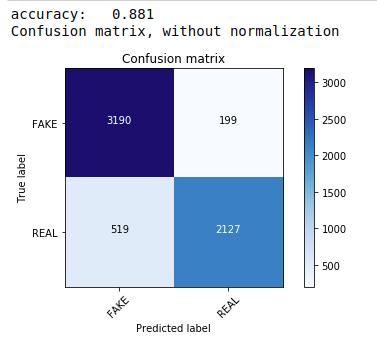
În primul rând, folosim teorema Multinomial Naive Bayes, care este cel mai comun și mai ușor algoritm preferat pentru clasificarea datelor text. Ne potrivim pe datele de antrenament și prezicem pe datele testului. Mai târziu calculăm și trasăm matricea de confuzie și obținem o precizie de 88,1%.
| din sklearn.naive_bayes import MultinomialNB din valorile de import sklearn import numpy ca np import iertools din sklearn.metrics import plot_confusion_matrix clasificator=MultinomialNB() classifier.fit(X_train, y_train) pred = clasificator.predict(X_test) scor = metrics.accuracy_score(y_test, pred) print( „precizie: %0.3f” % scor) cm = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm, classes=[ 'FAKE' , 'REAL' ]) |
Clasificator multinomial cu ajustare hiperparametrică
MultinomialNB are un parametru alfa care poate fi reglat în continuare. Prin urmare, rulăm o buclă pentru a încerca mai multe clasificatoare MultinomialNB cu diferite valori alfa și pentru a le verifica scorurile de precizie. Și verificăm dacă scorul curent este mai mare decât scorul anterior. Dacă este, atunci setăm clasificatorul ca fiind cel curent.
| scor_precedent= 0 pentru alfa în np.arange( 0 , 1 , 0.1 ): sub_classifier=MultinomialNB(alfa=alfa) sub_classifier.fit(X_train,y_train) y_pred=sub_classifier.predict(X_test) scor = metrics.accuracy_score(y_test, y_pred) if score>previous_score: clasificator=sub_clasificator print( „Alfa: {}, Scor: {}” .format(alpha,score)) |
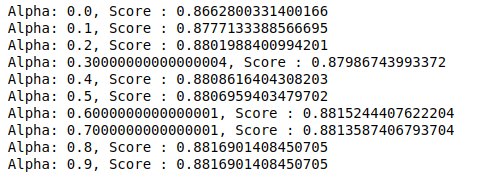
Prin urmare, putem vedea că o valoare alfa de 0,9 sau 0,8 a dat cel mai mare scor de precizie.
Interpretarea rezultatelor
Acum să vedem ce înseamnă aceste valori ale coeficientului de clasificator. Mai întâi vom salva toate numele caracteristicilor într-o altă variabilă.
| ## G et Features nume feature_names = cv.get_feature_names() |
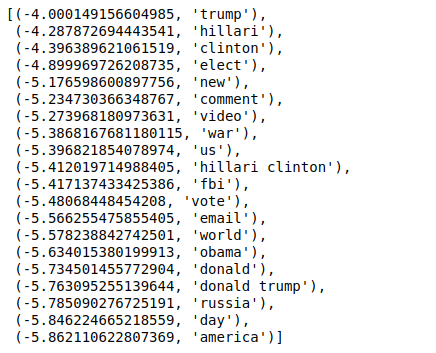
Acum, când sortăm valorile în ordine inversă, obținem valori cu o valoare minimă de -4. Acestea denotă cuvintele care sunt cele mai reale sau cel mai puțin false.
| ### Cel mai real sortat(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
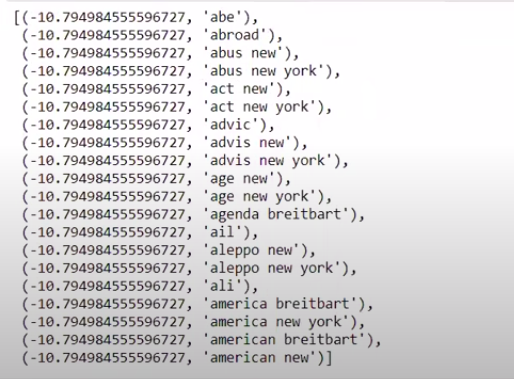
Când sortăm valorile în ordine inversă, obținem valori cu o valoare minimă de -10. Acestea denotă cuvintele care sunt cel mai puțin reale sau cele mai false.
| ### Cel mai real sortat(zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
Concluzie
În acest tutorial, am folosit doar algoritmi ML, dar utilizați și alte metode de rețele neuronale. Mai mult, pentru a vectoriza datele text, am folosit vectorizatorul TF-IDF. Există și mai multe vectorizatoare, cum ar fi Count Vectorizer, Hashing Vectorizer, etc., care pot fi mai bune în a face treaba. Încercați și experimentați cu alți algoritmi și tehnici pentru a vedea dacă puteți obține rezultate mai bune sau nu.
Dacă sunteți interesat să aflați mai multe despre învățarea automată, consultați Programul Executive PG de la IIIT-B și upGrad în Învățare automată și IA, care este conceput pentru profesioniști care lucrează și oferă peste 450 de ore de pregătire riguroasă, peste 30 de studii de caz și sarcini, IIIT -B Statut de absolvenți, peste 5 proiecte practice practice și asistență pentru locuri de muncă cu firme de top.
De ce este nevoie să detectăm știrile false?
În starea lor actuală, platformele de social media sunt foarte puternice și valoroase, deoarece permit utilizatorilor să discute și să facă schimb de idei, precum și să dezbată subiecte precum democrația, educația și sănătatea. Cu toate acestea, anumite entități folosesc astfel de platforme prost, pentru câștiguri monetare în anumite circumstanțe și pentru a produce puncte de vedere cu prejudecăți, pentru a modifica mentalitățile și pentru a difuza satiră sau ridicol în altele. Fake News este termenul pentru acest fenomen. Proliferarea postării de articole online care nu aderă la realitate a dus la o serie de probleme în politică, sport, sănătate, știință și alte domenii.
Ce companii folosesc în principal detectarea știrilor false?
Detectarea știrilor false este utilizată pe platforme precum rețelele sociale și site-urile de știri. Mașinii rețelelor sociale precum Facebook, Instagram și Twitter sunt vulnerabili la știrile false, deoarece majoritatea utilizatorilor săi se bazează pe ele ca surse de știri zilnice pentru a obține cele mai actualizate informații. Tehnicile de detectare a falsului sunt folosite și de companiile media pentru a determina autenticitatea informațiilor pe care le dețin. Emailul este un alt mediu prin care indivizii pot primi știri, ceea ce face dificilă identificarea și verificarea veridicității acestora. Farsele, spam-ul și mesajele nedorite sunt binecunoscute pentru că sunt transmise prin e-mail. Ca urmare, majoritatea platformelor de e-mail folosesc detectarea știrilor false pentru a identifica spam-ul și mesajele nedorite.