
Noțiuni introductive cu o stivă JavaScript Express și ES6+
Publicat: 2022-03-10Acest articol este a doua parte dintr-o serie, cu prima parte aflată aici, care a oferit o perspectivă de bază și (sperăm) intuitivă asupra Node.js, ES6+ JavaScript, Funcții de apel invers, Funcții săgeți, API-uri, Protocolul HTTP, JSON, MongoDB și Mai Mult.
În acest articol, ne vom baza pe abilitățile pe care le-am dobândit în cel precedent, învățând cum să implementăm și să implementăm o bază de date MongoDB pentru stocarea informațiilor despre lista de cărți ale utilizatorilor, să construim un API cu Node.js și cadrul aplicației Web Express pentru a expune acea bază de date. și efectuați operațiuni CRUD pe el și multe altele. Pe parcurs, vom discuta despre ES6 Object Destructurarea, ES6 Object Shorthand, sintaxa Async/Await, Operatorul Spread și vom arunca o scurtă privire asupra CORS, Politica Same Origin și multe altele.
Într-un articol ulterior, ne vom refactoriza baza de cod pentru a separa preocupările utilizând arhitectura cu trei straturi și realizând inversarea controlului prin injecția de dependență, vom efectua securitatea și controlul accesului bazat pe JSON Web Token și Firebase Authentication, vom afla cum să facem în siguranță. stocați parolele și folosiți Serviciul de stocare simplu AWS pentru a stoca avatarurile utilizatorilor cu Buffer-uri și fluxuri Node.js — totodată utilizând PostgreSQL pentru persistența datelor. Pe parcurs, ne vom rescrie baza de cod de la zero în TypeScript pentru a examina conceptele clasice de POO (cum ar fi polimorfismul, moștenirea, compoziția și așa mai departe) și chiar modelele de proiectare precum fabrici și adaptoare.
Un cuvânt de avertisment
Există o problemă cu majoritatea articolelor care discută despre Node.js astăzi. Majoritatea dintre ele, nu toate, nu merg mai departe decât să descrie cum să configurați Express Routing, să integrăm Mongoose și, probabil, să utilizați JSON Web Token Authentication. Problema este că ei nu vorbesc despre arhitectură, sau despre cele mai bune practici de securitate, sau despre principii de codare curată, sau despre conformitatea cu ACID, baze de date relaționale, a cincea formă normală, teorema CAP sau tranzacții. Se presupune fie că știți despre toate acestea, fie că nu veți construi proiecte suficient de mari sau de populare pentru a garanta acele cunoștințe menționate mai sus.
Se pare că există câteva tipuri diferite de dezvoltatori Node - printre altele, unii sunt noi în programare în general, iar alții provin dintr-o lungă istorie de dezvoltare a întreprinderilor cu C# și .NET Framework sau Java Spring Framework. Majoritatea articolelor se adresează fostului grup.
În acest articol, voi face exact ceea ce tocmai am afirmat că fac prea multe articole, dar într-un articol următor, ne vom refactoriza în întregime baza de cod, permițându-mi să explic principii precum Dependency Injection, Three- Arhitectură de straturi (controller/serviciu/depozitiv), cartografiere de date și înregistrare activă, modele de proiectare, testare de unitate, integrare și mutație, principii SOLID, unitate de lucru, codificare împotriva interfețelor, bune practici de securitate precum HSTS, CSRF, NoSQL și SQL Injection Prevenirea și așa mai departe. Vom migra, de asemenea, de la MongoDB la PostgreSQL, utilizând generatorul de interogări simplu Knex în loc de un ORM - permițându-ne să ne construim propria infrastructură de acces la date și să ne familiarizăm cu limbajul de interogare structurat, diferitele tipuri de relații (One- la-Unul, Multi-la-Mulți etc.) și multe altele. Prin urmare, acest articol ar trebui să atragă începătorii, dar următorii ar trebui să se adreseze mai multor dezvoltatori intermediari care doresc să-și îmbunătățească arhitectura.
În aceasta, ne vom face griji doar cu privire la persistența datelor din cărți. Nu ne vom ocupa de autentificarea utilizatorilor, hashingul parolelor, arhitectura sau orice altceva complex de acest gen. Toate acestea vor apărea în articolele următoare și viitoare. Pentru moment, și foarte practic, vom construi doar o metodă prin care să permitem unui client să comunice cu serverul nostru web prin protocolul HTTP pentru a salva informațiile cărții într-o bază de date.
Notă : L-am păstrat în mod intenționat extrem de simplu și poate nu atât de practic aici, deoarece acest articol, în sine, este extrem de lung, pentru că mi-am luat libertatea de a abate pentru a discuta subiecte suplimentare. Astfel, vom îmbunătăți progresiv calitatea și complexitatea API-ului în această serie, dar, din nou, pentru că consider că aceasta este una dintre primele tale introduceri în Express, păstrez lucrurile în mod intenționat extrem de simple.
- Destructurarea obiectelor ES6
- Stenografia obiectului ES6
- Operator de răspândire ES6 (...)
- Urmează...
Destructurarea obiectelor ES6
Destructurarea obiectelor ES6, sau Sintaxa de atribuire a destructurarii, este o metodă prin care se extrag sau se despachetează valori din matrice sau obiecte în propriile variabile. Vom începe cu proprietățile obiectului și apoi vom discuta elementele matricei.
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // Log properties: console.log('Name:', person.name); console.log('Occupation:', person.occupation); O astfel de operație este destul de primitivă, dar poate fi oarecum o bătaie de cap, având în vedere că trebuie să continuăm să facem referire la person.something . ceva peste tot. Să presupunem că există alte 10 locuri în codul nostru unde ar trebui să facem asta - ar deveni destul de dificil, destul de repede. O metodă de concizie ar fi atribuirea acestor valori propriilor variabile.
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; const personName = person.name; const personOccupation = person.occupation; // Log properties: console.log('Name:', personName); console.log('Occupation:', personOccupation); Poate că acest lucru pare rezonabil, dar dacă am avea alte 10 proprietăți imbricate și pe obiectul person ? Acestea ar fi multe linii inutile doar pentru a atribui valori variabilelor - moment în care suntem în pericol, deoarece, dacă proprietățile obiectului sunt modificate, variabilele noastre nu vor reflecta acea modificare (rețineți că numai referințele la obiect sunt imuabile cu atribuirea const , nu proprietățile obiectului), așa că, practic, nu mai putem menține „starea” (și folosesc cuvântul în mod liber) sincronizat. Trecerea prin referință vs trecerea prin valoare ar putea intra în joc aici, dar nu vreau să mă îndepărtez prea mult de domeniul de aplicare al acestei secțiuni.
ES6 Object Destructing practic ne permite să facem acest lucru:
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // This is new. It's called Object Destructuring. const { name, occupation } = person; // Log properties: console.log('Name:', name); console.log('Occupation:', occupation); Nu creăm un nou obiect/literal obiect, despachetăm name și proprietățile de occupation din obiectul original și le punem în propriile variabile cu același nume. Numele pe care le folosim trebuie să se potrivească cu numele proprietăților pe care dorim să le extragem.
Din nou, sintaxa const { a, b } = someObject; spune în mod specific că ne așteptăm ca o proprietate a și o proprietate b să existe în cadrul someObject (adică, someObject ar putea fi { a: 'dataA', b: 'dataB' } , de exemplu) și că vrem să plasăm oricare ar fi valorile a acelor chei/proprietăți din const variabile cu același nume. De aceea, sintaxa de mai sus ne-ar oferi două variabile const a = someObject.a și const b = someObject.b .
Ceea ce înseamnă asta este că există două laturi ale Destructurarii obiectelor. Partea „Șablon” și partea „Sursă”, unde partea const { a, b } (partea din stânga) este șablonul și partea someObject (partea dreaptă) este partea sursă - ceea ce are sens — definim o structură sau „șablon” în stânga care oglindește datele din partea „sursă”.
Din nou, doar pentru a clarifica acest lucru, iată câteva exemple:
// ----- Destructure from Object Variable with const ----- // const objOne = { a: 'dataA', b: 'dataB' }; // Destructure const { a, b } = objOne; console.log(a); // dataA console.log(b); // dataB // ----- Destructure from Object Variable with let ----- // let objTwo = { c: 'dataC', d: 'dataD' }; // Destructure let { c, d } = objTwo; console.log(c); // dataC console.log(d); // dataD // Destructure from Object Literal with const ----- // const { e, f } = { e: 'dataE', f: 'dataF' }; // <-- Destructure console.log(e); // dataE console.log(f); // dataF // Destructure from Object Literal with let ----- // let { g, h } = { g: 'dataG', h: 'dataH' }; // <-- Destructure console.log(g); // dataG console.log(h); // dataHÎn cazul proprietăților imbricate, oglindiți aceeași structură în misiunea dvs. de distrugere:
const person = { name: 'Richard P. Feynman', occupation: { type: 'Theoretical Physicist', location: { lat: 1, lng: 2 } } }; // Attempt one: const { name, occupation } = person; console.log(name); // Richard P. Feynman console.log(occupation); // The entire `occupation` object. // Attempt two: const { occupation: { type, location } } = person; console.log(type); // Theoretical Physicist console.log(location) // The entire `location` object. // Attempt three: const { occupation: { location: { lat, lng } } } = person; console.log(lat); // 1 console.log(lng); // 2După cum puteți vedea, proprietățile pe care decideți să le scoateți sunt opționale și, pentru a despacheta proprietățile imbricate, pur și simplu oglindiți structura obiectului original (sursa) în partea șablon a sintaxei dvs. de destructurare. Dacă încercați să destructurați o proprietate care nu există pe obiectul original, acea valoare va fi nedefinită.
În plus, putem destructura o variabilă fără a o declara mai întâi — atribuire fără declarare — folosind următoarea sintaxă:
let name, occupation; const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; ;({ name, occupation } = person); console.log(name); // Richard P. Feynman console.log(occupation); // Theoretical PhysicistPrecedăm expresia cu punct și virgulă pentru a ne asigura că nu creăm accidental un IIFE (Expresie Funcție Invocată Imediat) cu o funcție pe o linie anterioară (dacă există o astfel de funcție), iar parantezele din jurul instrucțiunii de atribuire sunt necesare pentru a opriți JavaScript să trateze partea stângă (șablon) ca pe un bloc.
Un caz de utilizare foarte comun de destructurare există în argumentele funcției:
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; // Destructures `baseUrl` and `awsBucket` off `config`. const performOperation = ({ baseUrl, awsBucket }) => { fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);După cum puteți vedea, am fi putut doar să folosim sintaxa normală de destructurare cu care suntem obișnuiți acum în interiorul funcției, astfel:
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; const performOperation = someConfig => { const { baseUrl, awsBucket } = someConfig; fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);Dar plasarea acestei sintaxe în interiorul semnăturii funcției efectuează destructurarea automată și ne salvează o linie.
Un caz de utilizare real al acestui lucru este în React Functional Components pentru props :
import React from 'react'; // Destructure `titleText` and `secondaryText` from `props`. export default ({ titleText, secondaryText }) => ( <div> <h1>{titleText}</h1> <h3>{secondaryText}</h3> </div> );Spre deosebire de:
import React from 'react'; export default props => ( <div> <h1>{props.titleText}</h1> <h3>{props.secondaryText}</h3> </div> );În ambele cazuri, putem seta valori implicite și proprietăților:
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(name); console.log(password); return { id: Math.random().toString(36) // <--- Should follow RFC 4122 Spec in real app. .substring(2, 15) + Math.random() .toString(36).substring(2, 15), name: name, // <-- We'll discuss this next. password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt Hash După cum puteți vedea, în cazul în care name nu este prezent atunci când este destructurat, îi oferim o valoare implicită. Putem face acest lucru și cu sintaxa anterioară:
const { a, b, c = 'Default' } = { a: 'dataA', b: 'dataB' }; console.log(a); // dataA console.log(b); // dataB console.log(c); // DefaultMatricele pot fi și ele destructurate:
const myArr = [4, 3]; // Destructuring happens here. const [valOne, valTwo] = myArr; console.log(valOne); // 4 console.log(valTwo); // 3 // ----- Destructuring without assignment: ----- // let a, b; // Destructuring happens here. ;([a, b] = [10, 2]); console.log(a + b); // 12Un motiv practic pentru destructurarea matricei apare cu React Hooks. (Și există multe alte motive, folosesc doar React ca exemplu).
import React, { useState } from "react"; export default () => { const [buttonText, setButtonText] = useState("Default"); return ( <button onClick={() => setButtonText("Toggled")}> {buttonText} </button> ); } Observați useState este destructurat din export, iar funcțiile/valorile matricei sunt destructurate din hook useState . Din nou, nu vă faceți griji dacă cele de mai sus nu au sens - ar trebui să înțelegeți React - și îl folosesc doar ca exemplu.
Deși există mai multe despre Destructurarea obiectelor ES6, voi acoperi încă un subiect aici: Redenumirea destructurarii, care este utilă pentru a preveni coliziunile sferei de aplicare sau umbrele variabile etc. Să presupunem că vrem să destructuram o proprietate numită name dintr-un obiect numit person , dar există deja o variabilă cu numele name în domeniu. Putem redenumi din mers cu două puncte:
// JS Destructuring Naming Collision Example: const name = 'Jamie Corkhill'; const person = { name: 'Alan Turing' }; // Rename `name` from `person` to `personName` after destructuring. const { name: personName } = person; console.log(name); // Jamie Corkhill <-- As expected. console.log(personName); // Alan Turing <-- Variable was renamed.În cele din urmă, putem seta valori implicite și cu redenumirea:
const name = 'Jamie Corkhill'; const person = { location: 'New York City, United States' }; const { name: personName = 'Anonymous', location } = person; console.log(name); // Jamie Corkhill console.log(personName); // Anonymous console.log(location); // New York City, United States După cum puteți vedea, în acest caz, name de la person ( person.name ) va fi redenumit în personName și va fi setat la valoarea implicită Anonymous dacă nu există.
Și, desigur, același lucru poate fi efectuat în semnăturile funcției:
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name: personName = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(personName); console.log(password); return { id: Math.random().toString(36).substring(2, 15) + Math.random().toString(36).substring(2, 15), name: personName, password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt HashStenografia obiectului ES6
Să presupunem că aveți următoarea fabrică: (vom acoperi fabricile mai târziu)
const createPersonFactory = (name, location, position) => ({ name: name, location: location, position: position }); S-ar putea folosi această fabrică pentru a crea un obiect person , după cum urmează. De asemenea, rețineți că fabrica returnează implicit un obiect, evident prin parantezele din jurul parantezelor funcției săgeată.
const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person); // { ... } Asta știm deja din sintaxa literală a obiectelor ES5. Observați, totuși, în funcția din fabrică, că valoarea fiecărei proprietăți este același nume ca și identificatorul proprietății (cheia). Adică — location: location sau name: name . S-a dovedit că acesta a fost o întâmplare destul de comună cu dezvoltatorii JS.
Cu sintaxa scurtă de la ES6, putem obține același rezultat prin rescrierea fabricii după cum urmează:
const createPersonFactory = (name, location, position) => ({ name, location, position }); const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person);Producerea rezultatului:
{ name: 'Jamie', location: 'Texas', position: 'Developer' }Este important să ne dăm seama că putem folosi această prescurtare numai atunci când obiectul pe care dorim să-l creăm este creat dinamic pe baza variabilelor, unde numele variabilelor sunt aceleași cu numele proprietăților cărora dorim să le fie atribuite variabilele.
Aceeași sintaxă funcționează cu valorile obiectului:
const createPersonFactory = (name, location, position, extra) => ({ name, location, position, extra // <- right here. }); const extra = { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] }; const person = createPersonFactory('Jamie', 'Texas', 'Developer', extra); console.log(person);Producerea rezultatului:
{ name: 'Jamie', location: 'Texas', position: 'Developer', extra: { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] } }Ca exemplu final, aceasta funcționează și cu literalele obiect:
const id = '314159265358979'; const name = 'Archimedes of Syracuse'; const location = 'Syracuse'; const greatMathematician = { id, name, location };Operator de răspândire ES6 (…)
Operatorul Spread ne permite să facem o varietate de lucruri, dintre care unele le vom discuta aici.
În primul rând, putem distribui proprietățile de la un obiect pe altul:
const myObjOne = { a: 'a', b: 'b' }; const myObjTwo = { ...myObjOne }: Acest lucru are ca efect plasarea tuturor proprietăților de pe myObjOne pe myObjTwo , astfel încât myObjTwo este acum { a: 'a', b: 'b' } . Putem folosi această metodă pentru a suprascrie proprietățile anterioare. Să presupunem că un utilizator dorește să-și actualizeze contul:
const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */
Același lucru se poate face cu matrice:
const apollo13Astronauts = ['Jim', 'Jack', 'Fred']; const apollo11Astronauts = ['Neil', 'Buz', 'Michael']; const unionOfAstronauts = [...apollo13Astronauts, ...apollo11Astronauts]; console.log(unionOfAstronauts); // ['Jim', 'Jack', 'Fred', 'Neil', 'Buz, 'Michael'];Observați aici că am creat o unire a ambelor seturi (matrice) prin răspândirea matricelor într-o nouă matrice.
Există mult mai mult pentru Operatorul Rest/Răspândire, dar este în afara domeniului de aplicare al acestui articol. Poate fi folosit pentru a obține mai multe argumente pentru o funcție, de exemplu. Dacă doriți să aflați mai multe, consultați documentația MDN aici.
ES6 Async/Așteptați
Async/Await este o sintaxă pentru a ușura durerea înlănțuirii promisiunilor.
Cuvântul cheie await rezervat vă permite să „așteptați” stingerea unei promisiuni, dar poate fi utilizat numai în funcțiile marcate cu cuvântul cheie async . Să presupunem că am o funcție care returnează o promisiune. Într-o nouă funcție async , pot await rezultatul acelei promisiuni în loc să folosesc .then și .catch .
// Returns a promise. const myFunctionThatReturnsAPromise = () => { return new Promise((resolve, reject) => { setTimeout(() => resolve('Hello'), 3000); }); } const myAsyncFunction = async () => { const promiseResolutionResult = await myFunctionThatReturnsAPromise(); console.log(promiseResolutionResult); }; // Writes the log statement after three seconds. myAsyncFunction(); Sunt câteva lucruri de remarcat aici. Când folosim await într-o funcție async , doar valoarea rezolvată intră în variabila din partea stângă. Dacă funcția respinge, aceasta este o eroare pe care trebuie să o surprindem, așa cum vom vedea peste un moment. În plus, orice funcție marcată async va returna, în mod implicit, o promisiune.
Să presupunem că trebuie să fac două apeluri API, unul cu răspunsul de la primul. Folosind promisiuni și înlănțuire de promisiuni, ați putea face acest lucru:
const makeAPICall = route => new Promise((resolve, reject) => { console.log(route) resolve(route); }); const main = () => { makeAPICall('/whatever') .then(response => makeAPICall(response + ' second call')) .then(response => console.log(response + ' logged')) .catch(err => console.error(err)) }; main(); // Result: /* /whatever /whatever second call /whatever second call logged */ Ceea ce se întâmplă aici este că mai întâi numim makeAPICall trecerea la acesta /whatever , care este înregistrat prima dată. Promisiunea se rezolvă cu acea valoare. Apoi apelăm din nou makeAPICall , trecându-i /whatever second call , care este înregistrat și din nou, promisiunea se rezolvă cu acea nouă valoare. În cele din urmă, luăm acea nouă valoare /whatever second call cu care tocmai s-a rezolvat promisiunea și o înregistrăm noi înșine în jurnalul final, anexând logged la sfârșit. Dacă acest lucru nu are sens, ar trebui să te uiți la înlănțuirea promisiunilor.
Folosind async / await , putem refactoriza următoarele:
const main = async () => { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); }; Iată ce se va întâmpla. Întreaga funcție se va opri la prima instrucțiune await până când promisiunea de la primul apel la makeAPICall rezolvă, după rezoluție, valoarea rezolvată va fi plasată în resultOne . Când se întâmplă acest lucru, funcția va trece la a doua declarație de await , făcând din nou o pauză chiar acolo pe durata încheierii promisiunii. Când promisiunea se rezolvă, rezultatul rezoluției va fi plasat în resultTwo . Dacă ideea despre execuția funcției sună blocant, nu vă temeți, este încă asincronă și voi discuta de ce într-un minut.
Aceasta descrie doar calea „fericită”. În cazul în care una dintre promisiuni respinge, putem prinde asta cu try/catch, deoarece dacă promisiunea respinge, va fi aruncată o eroare - care va fi orice eroare cu care a respins promisiunea.
const main = async () => { try { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); } catch (e) { console.log(e) } }; După cum am spus mai devreme, orice funcție declarată async va returna o promisiune. Deci, dacă doriți să apelați o funcție asincronă dintr-o altă funcție, puteți utiliza promisiuni normale sau puteți await dacă declarați funcția de apelare async . Cu toate acestea, dacă doriți să apelați o funcție async din codul de nivel superior și să așteptați rezultatul acesteia, atunci va trebui să utilizați .then și .catch .
De exemplu:
const returnNumberOne = async () => 1; returnNumberOne().then(value => console.log(value)); // 1Sau, puteți utiliza o expresie a funcției invocate imediat (IIFE):
(async () => { const value = await returnNumberOne(); console.log(value); // 1 })(); Când utilizați await într-o funcție async , execuția funcției se va opri la acea instrucțiune await până când promisiunea se stabilește. Cu toate acestea, toate celelalte funcții sunt libere să continue cu execuția, astfel încât nu sunt alocate resurse suplimentare ale procesorului și nici firul de execuție nu este blocat vreodată. Voi spune asta din nou - operațiunile în acea funcție specifică la acel moment specific se vor opri până când promisiunea se va stabili, dar toate celelalte funcții sunt libere să se declanșeze. Luați în considerare un server web HTTP - pe bază de solicitare, toate funcțiile sunt libere să se declanșeze pentru toți utilizatorii simultan pe măsură ce se fac cereri, doar că sintaxa async/wait va oferi iluzia că o operație este sincronă și blocantă . promite mai ușor de lucrat, dar din nou, totul va rămâne frumos și asincron.
Acest lucru nu este tot ce trebuie async / await , dar ar trebui să vă ajute să înțelegeți principiile de bază.
Fabrici OOP clasice
Acum vom părăsi lumea JavaScript și vom intra în lumea Java . Poate veni un moment în care procesul de creare a unui obiect (în acest caz, o instanță a unei clase - din nou, Java) este destul de complex sau când dorim să avem diferite obiecte produse pe baza unei serii de parametri. Un exemplu ar putea fi o funcție care creează diferite obiecte de eroare. O fabrică este un model de design obișnuit în programarea orientată pe obiecte și este practic o funcție care creează obiecte. Pentru a explora acest lucru, să ne îndepărtăm de JavaScript în lumea Java. Acest lucru va avea sens pentru dezvoltatorii care provin dintr-un limbaj OOP clasic (adică, nu prototip), un fundal de limbaj tipizat static. Dacă nu sunteți unul dintre astfel de dezvoltatori, nu ezitați să omiteți această secțiune. Aceasta este o mică abatere și, prin urmare, dacă urmărirea aici vă întrerupe fluxul de JavaScript, vă rugăm să omiteți din nou această secțiune.
Un model de creație obișnuit, Modelul Factory ne permite să creăm obiecte fără a expune logica de afaceri necesară pentru a realiza respectiva creație.
Să presupunem că scriem un program care ne permite să vizualizăm forme primitive în n dimensiuni. Dacă oferim un cub, de exemplu, am vedea un cub 2D (un pătrat), un cub 3D (un cub) și un cub 4D (un Tesseract sau Hypercube). Iată cum s-ar putea face acest lucru, în mod trivial, cu excepția părții reale a desenului, în Java.
// Main.java // Defining an interface for the shape (can be used as a base type) interface IShape { void draw(); } // Implementing the interface for 2-dimensions: class TwoDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 2D."); } } // Implementing the interface for 3-dimensions: class ThreeDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 3D."); } } // Implementing the interface for 4-dimensions: class FourDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 4D."); } } // Handles object creation class ShapeFactory { // Factory method (notice return type is the base interface) public IShape createShape(int dimensions) { switch(dimensions) { case 2: return new TwoDimensions(); case 3: return new ThreeDimensions(); case 4: return new FourDimensions(); default: throw new IllegalArgumentException("Invalid dimension."); } } } // Main class and entry point. public class Main { public static void main(String[] args) throws Exception { ShapeFactory shapeFactory = new ShapeFactory(); IShape fourDimensions = shapeFactory.createShape(4); fourDimensions.draw(); // Drawing a shape in 4D. } } După cum puteți vedea, definim o interfață care specifică o metodă de desenare a unei forme. Prin faptul că diferitele clase implementează interfața, putem garanta că toate formele pot fi desenate (pentru că toate trebuie să aibă o metodă de draw care poate fi suprascrisă conform definiției interfeței). Având în vedere că această formă este desenată diferit în funcție de dimensiunile în care este vizualizată, definim clase de ajutor care implementează interfața pentru a efectua munca intensivă GPU de simulare a randării n-dimensionale. ShapeFactory face munca de instanțiere a clasei corecte - metoda createShape este o fabrică și, ca și definiția de mai sus, este o metodă care returnează un obiect al unei clase. Tipul returnat de createShape este interfața IShape , deoarece interfața IShape este tipul de bază al tuturor formelor (deoarece au o metodă de draw ).
Acest exemplu Java este destul de banal, dar puteți vedea cu ușurință cât de util devine în aplicațiile mai mari în care configurarea pentru a crea un obiect ar putea să nu fie atât de simplă. Un exemplu în acest sens ar fi un joc video. Să presupunem că utilizatorul trebuie să supraviețuiască diferitor inamici. Clasele și interfețele abstracte ar putea fi folosite pentru a defini funcțiile de bază disponibile pentru toți inamicii (și metodele care pot fi suprascrise), poate folosind modelul de delegare (preferați compoziția în detrimentul moștenirii, așa cum a sugerat Gang of Four, astfel încât să nu rămâneți blocați în extinderea unui o singură clasă de bază și pentru a ușura testarea/batjocorirea/DI). Pentru obiectele inamice instanțiate în moduri diferite, interfața ar permite crearea de obiecte din fabrică, bazându-se pe tipul de interfață generic. Acest lucru ar fi foarte relevant dacă inamicul ar fi creat dinamic.
Un alt exemplu este o funcție de constructor. Să presupunem că folosim modelul de delegare pentru a avea un delegat de clasă să lucreze la alte clase care onorează o interfață. Am putea plasa o metodă de build statică pe clasă pentru ca aceasta să-și construiască propria instanță (presupunând că nu utilizați un container/cadru de injecție de dependență). În loc să trebuiască să apelați fiecare setter, puteți face acest lucru:
public class User { private IMessagingService msgService; private String name; private int age; public User(String name, int age, IMessagingService msgService) { this.name = name; this.age = age; this.msgService = msgService; } public static User build(String name, int age) { return new User(name, age, new SomeMessageService()); } } Voi explica modelul de delegare într-un articol ulterior, dacă nu sunteți familiarizat cu el - practic, prin Compoziție și în ceea ce privește modelarea obiectelor, creează o relație „are-a” în loc de „este-a” relație așa cum ați obține cu moștenirea. Dacă aveți o clasă de Mammal și o clasă de Dog , iar Dog extinde Mammal , atunci un Dog este un Mammal . În timp ce, dacă ați avut o clasă Bark și tocmai ați trecut exemple de Bark în constructorul Dog , atunci Dog are-a Bark . După cum vă puteți imagina, acest lucru facilitează în special testarea unitară, deoarece puteți injecta false și afirma fapte despre simulare, atâta timp cât simularea respectă contractul de interfață în mediul de testare.
Metoda static „construire” din fabrică de mai sus creează pur și simplu un nou obiect al User și transmite un MessageService concret. Observați cum rezultă acest lucru din definiția de mai sus - fără a expune logica de afaceri pentru a crea un obiect al unei clase sau, în acest caz, neexpunerea creației serviciului de mesagerie către apelantul fabricii.
Din nou, așa nu este neapărat cum ați face lucrurile în lumea reală, dar prezintă destul de bine ideea unei funcții/metode din fabrică. Am putea folosi în schimb un container de injecție de dependență, de exemplu. Acum înapoi la JavaScript.
Începând cu Express
Express este un cadru de aplicații web pentru Node (disponibil printr-un modul NPM) care permite crearea unui server web HTTP. Este important de reținut că Express nu este singurul cadru care face acest lucru (există Koa, Fastify etc.) și că, așa cum sa văzut în articolul anterior, Node poate funcționa fără Express ca o entitate autonomă. (Express este doar un modul care a fost proiectat pentru Node — Node poate face multe lucruri fără el, deși Express este popular pentru serverele web).
Din nou, permiteți-mi să fac o distincție foarte importantă. Există o dihotomie prezentă între Node/JavaScript și Express. Node, timpul de rulare/mediul în care rulați JavaScript, poate face multe lucruri - cum ar fi să vă permită să creați aplicații React Native, aplicații desktop, instrumente de linie de comandă etc. - Express nu este altceva decât un cadru ușor care vă permite să utilizați Node/JS pentru a construi servere web, spre deosebire de a se ocupa de rețeaua de nivel scăzut și API-urile HTTP ale Node. Nu aveți nevoie de Express pentru a construi un server web.
Înainte de a începe această secțiune, dacă nu sunteți familiarizat cu cererile HTTP și HTTP (GET, POST etc.), atunci vă încurajez să citiți secțiunea corespunzătoare a fostului meu articol, care este legată mai sus.
Folosind Express, vom configura diferite rute către care pot fi făcute solicitări HTTP, precum și punctele finale aferente (care sunt funcții de apel invers) care se vor declanșa atunci când se face o solicitare către acea rută. Nu vă faceți griji dacă rutele și punctele finale sunt în prezent lipsite de sens - le voi explica mai târziu.
Spre deosebire de alte articole, voi adopta abordarea de a scrie codul sursă pe măsură ce mergem, linie cu linie, mai degrabă decât să arunc întreaga bază de cod într-un singur fragment și apoi să explic mai târziu. Să începem prin a deschide un terminal (folosesc Terminus pe deasupra Git Bash pe Windows - care este o opțiune bună pentru utilizatorii Windows care doresc un Bash Shell fără a configura subsistemul Linux), configurarea boilerplate a proiectului nostru și deschiderea acestuia. în Visual Studio Code.
mkdir server && cd server touch server.js npm init -y npm install express code . În interiorul fișierului server.js , voi începe prin a solicita express folosind funcția require() .
const express = require('express'); require('express') îi spune lui Node să iasă și să obțină modulul Express pe care l-am instalat mai devreme, care se află în prezent în folderul node_modules (pentru asta face npm install - creează un folder node_modules și pune modulele și dependențele lor acolo). Prin convenție, și când avem de-a face cu Express, numim variabila care deține rezultatul returnat de la require('express') express , deși poate fi numită orice.
This returned result, which we have called express , is actually a function — a function we'll have to invoke to create our Express app and set up our routes. Again, by convention, we call this app — app being the return result of express() — that is, the return result of calling the function that has the name express as express() .
const express = require('express'); const app = express(); // Note that the above variable names are the convention, but not required. // An example such as that below could also be used. const foo = require('express'); const bar = foo(); // Note also that the node module we installed is called express. The line const app = express(); simply puts a new Express Application inside of the app variable. It calls a function named express (the return result of require('express') ) and stores its return result in a constant named app . If you come from an object-oriented programming background, consider this equivalent to instantiating a new object of a class, where app would be the object and where express() would call the constructor function of the express class. Remember, JavaScript allows us to store functions in variables — functions are first-class citizens. The express variable, then, is nothing more than a mere function. It's provided to us by the developers of Express.
I apologize in advance if I'm taking a very long time to discuss what is actually very basic, but the above, although primitive, confused me quite a lot when I was first learning back-end development with Node.
Inside the Express source code, which is open-source on GitHub, the variable we called express is a function entitled createApplication , which, when invoked, performs the work necessary to create an Express Application:
A snippet of Express source code:
exports = module.exports = createApplication; /* * Create an express application */ // This is the function we are storing in the express variable. (- Jamie) function createApplication() { // This is what I mean by "Express App" (- Jamie) var app = function(req, res, next) { app.handle(req, res, next); }; mixin(app, EventEmitter.prototype, false); mixin(app, proto, false); // expose the prototype that will get set on requests app.request = Object.create(req, { app: { configurable: true, enumerable: true, writable: true, value: app } }) // expose the prototype that will get set on responses app.response = Object.create(res, { app: { configurable: true, enumerable: true, writable: true, value: app } }) app.init(); // See - `app` gets returned. (- Jamie) return app; }GitHub: https://github.com/expressjs/express/blob/master/lib/express.js
With that short deviation complete, let's continue setting up Express. Thus far, we have required the module and set up our app variable.
const express = require('express'); const app = express(); From here, we have to tell Express to listen on a port. Any HTTP Requests made to the URL and Port upon which our application is listening will be handled by Express. We do that by calling app.listen(...) , passing to it the port and a callback function which gets called when the server starts running:
const PORT = 3000; app.listen(PORT, () => console.log(`Server is up on port {PORT}.`)); We notate the PORT variable in capital by convention, for it is a constant variable that will never change. You could do that with all variables that you declare const , but that would look messy. It's up to the developer or development team to decide on notation, so we'll use the above sparsely. I use const everywhere as a method of “defensive coding” — that is, if I know that a variable is never going to change then I might as well just declare it const . Since I define everything const , I make the distinction between what variables should remain the same on a per-request basis and what variables are true actual global constants.
Here is what we have thus far:
const express = require('express'); const app = express(); const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`); });Let's test this to see if the server starts running on port 3000.
I'll open a terminal and navigate to our project's root directory. I'll then run node server/server.js . Note that this assumes you have Node already installed on your system (You can check with node -v ).
If everything works, you should see the following in the terminal:
Server is up on port 3000.
Go ahead and hit Ctrl + C to bring the server back down.
If this doesn't work for you, or if you see an error such as EADDRINUSE , then it means you may have a service already running on port 3000. Pick another port number, like 3001, 3002, 5000, 8000, etc. Be aware, lower number ports are reserved and there is an upper bound of 65535.
At this point, it's worth taking another small deviation as to understand servers and ports in the context of computer networking. We'll return to Express in a moment. I take this approach, rather than introducing servers and ports first, for the purpose of relevance. That is, it is difficult to learn a concept if you fail to see its applicability. In this way, you are already aware of the use case for ports and servers with Express, so the learning experience will be more pleasurable.
A Brief Look At Servers And Ports
A server is simply a computer or computer program that provides some sort of “functionality” to the clients that talk to it. More generally, it's a device, usually connected to the Internet, that handles connections in a pre-defined manner. In our case, that “pre-defined manner” will be HTTP or the HyperText Transfer Protocol. Servers that use the HTTP Protocol are called Web Servers.
When building an application, the server is a critical component of the “client-server model”, for it permits the sharing and syncing of data (generally via databases or file systems) across devices. It's a cross-platform approach, in a way, for the SDKs of platforms against which you may want to code — be they web, mobile, or desktop — all provide methods (APIs) to interact with a server over HTTP or TCP/UDP Sockets. It's important to make a distinction here — by APIs, I mean programming language constructs to talk to a server, like XMLHttpRequest or the Fetch API in JavaScript, or HttpUrlConnection in Java, or even HttpClient in C#/.NET. This is different from the kind of REST API we'll be building in this article to perform CRUD Operations on a database.
To talk about ports, it's important to understand how clients connect to a server. A client requires the IP Address of the server and the Port Number of our specific service on that server. An IP Address, or Internet Protocol Address, is just an address that uniquely identifies a device on a network. Public and private IPs exist, with private addresses commonly used behind a router or Network Address Translator on a local network. You might see private IP Addresses of the form 192.168.XXX.XXX or 10.0.XXX.XXX . When articulating an IP Address, decimals are called “dots”. So 192.168.0.1 (a common router IP Addr.) might be pronounced, “one nine two dot one six eight dot zero dot one”. (By the way, if you're ever in a hotel and your phone/laptop won't direct you to the AP captive portal, try typing 192.168.0.1 or 192.168.1.1 or similar directly into Chrome).
For simplicity, and since this is not an article about the complexities of computer networking, assume that an IP Address is equivalent to a house address, allowing you to uniquely identify a house (where a house is analogous to a server, client, or network device) in a neighborhood. One neighborhood is one network. Put together all of the neighborhoods in the United States, and you have the public Internet. (This is a basic view, and there are many more complexities — firewalls, NATs, ISP Tiers (Tier One, Tier Two, and Tier Three), fiber optics and fiber optic backbones, packet switches, hops, hubs, etc., subnet masks, etc., to name just a few — in the real networking world.) The traceroute Unix command can provide more insight into the above, displaying the path (and associated latency) that packets take through a network as a series of “hops”.
Un număr de port identifică un anumit serviciu care rulează pe un server. SSH, sau Secure Shell, care permite accesul de la distanță la un dispozitiv, rulează în mod obișnuit pe portul 22. FTP sau File Transfer Protocol (care ar putea fi, de exemplu, utilizat cu un client FTP pentru a transfera active statice pe un server) rulează de obicei pe Portul 21. Am putea spune, deci, că porturile sunt încăperi specifice în interiorul fiecărei case, în analogia noastră de mai sus, pentru că camerele din case sunt făcute pentru lucruri diferite - un dormitor pentru dormit, o bucătărie pentru pregătirea hranei, o sufragerie pentru consumul respectivului alimente etc., la fel ca și porturile corespund unor programe care efectuează anumite servicii. Pentru noi, serverele web rulează în mod obișnuit pe portul 80, deși sunteți liber să specificați numărul de port dorit, atâta timp cât acestea nu sunt utilizate de alt serviciu (nu se pot ciocni).
Pentru a accesa un site web, aveți nevoie de adresa IP a site-ului. În ciuda acestui fapt, în mod normal accesăm site-uri web prin intermediul unei adrese URL. În culise, un DNS sau un server de nume de domeniu convertește acea adresă URL într-o adresă IP, permițând browserului să facă o solicitare GET către server, să obțină codul HTML și să îl redeze pe ecran. 8.8.8.8 este adresa unuia dintre serverele DNS publice ale Google. Vă puteți imagina că necesitatea rezoluției unui nume de gazdă la o adresă IP prin intermediul unui server DNS la distanță va dura timp și ați avea dreptate. Pentru a reduce latența, sistemele de operare au un cache DNS - o bază de date temporară care stochează informații de căutare DNS, reducând astfel frecvența căutărilor respective trebuie să aibă loc. Cache-ul DNS Resolver poate fi vizualizat pe Windows cu comanda ipconfig /displaydns CMD și curățat prin comanda ipconfig /flushdns .
Pe un server Unix, mai multe porturi cu numere mai obișnuite, cum ar fi 80, necesită privilegii la nivel de rădăcină ( escalată dacă veniți dintr-un fundal Windows). Din acest motiv, vom folosi portul 3000 pentru munca noastră de dezvoltare, dar vom permite serverului să aleagă numărul portului (indiferent care este disponibil) atunci când vom implementa în mediul nostru de producție.
În sfârșit, rețineți că putem introduce adrese IP direct în bara de căutare a Google Chrome, ocolind astfel mecanismul de rezoluție DNS. Tastând 216.58.194.36 , de exemplu, vă va duce la Google.com. În mediul nostru de dezvoltare, când folosim propriul nostru computer ca server de dezvoltare, vom folosi localhost și portul 3000. O adresă este formatată ca hostname:port , astfel încât serverul nostru va fi activ pe localhost:3000 . Localhost, sau 127.0.0.1 , este adresa de loopback și înseamnă adresa „acest computer”. Este un nume de gazdă, iar adresa sa IPv4 se rezolvă la 127.0.0.1 . Încercați să trimiteți ping localhost pe mașina dvs. chiar acum. Este posibil să primiți ::1 înapoi — care este adresa IPv6 de loopback sau 127.0.0.1 înapoi — care este adresa IPv4 de loopback. IPv4 și IPv6 sunt două formate diferite de adrese IP asociate cu standarde diferite - unele adrese IPv6 pot fi convertite în IPv4, dar nu toate.
Revenind la Express
Am menționat solicitări HTTP, verbe și coduri de stare în articolul meu anterior, Începeți cu Node: o introducere în API-uri, HTTP și ES6+ JavaScript. Dacă nu aveți o înțelegere generală a protocolului, nu ezitați să accesați secțiunea „Solicitări HTTP și HTTP” a piesei respective.
Pentru a înțelege Express, pur și simplu ne vom configura punctele finale pentru cele patru operațiuni fundamentale pe care le vom efectua în baza de date - Creare, Citire, Actualizare și Ștergere, cunoscute în mod colectiv sub numele de CRUD.
Amintiți-vă, accesăm punctele finale după rute din URL. Adică, deși cuvintele „rută” și „punct final” sunt utilizate în mod obișnuit în mod interschimbabil, un punct final este, din punct de vedere tehnic, o funcție a limbajului de programare (cum ar fi ES6 Arrow Functions) care efectuează unele operații pe partea serverului, în timp ce o rută este locul în care se află punctul final. de . Specificăm aceste puncte finale ca funcții de apel invers, pe care Express le va declanșa atunci când solicitarea corespunzătoare este făcută de la client către ruta în spatele căreia se află punctul final. Vă puteți aminti cele de mai sus realizând că punctele finale sunt cele care îndeplinesc o funcție și ruta este numele care este folosit pentru a accesa punctele finale. După cum vom vedea, aceeași rută poate fi asociată cu mai multe puncte finale prin utilizarea diferitelor verbe HTTP (similar cu supraîncărcarea metodei dacă provin dintr-un fundal OOP clasic cu polimorfism).
Rețineți că urmăm arhitectura REST (Representational State Transfer) permițând clienților să facă cereri către serverul nostru. Acesta este, până la urmă, un API REST sau RESTful. Solicitările specifice făcute către anumite rute vor declanșa anumite puncte finale care vor face anumite lucruri . Un exemplu de astfel de „lucru” pe care l-ar putea face un punct final este adăugarea de date noi la o bază de date, eliminarea datelor, actualizarea datelor etc.
Express știe ce punct final să declanșeze pentru că îi spunem, în mod explicit, metoda de solicitare (GET, POST etc.) și ruta — definim ce funcții să declanșeze pentru combinații specifice ale celor de mai sus, iar clientul face cererea, specificând o ruta si metoda. Pentru a spune acest lucru mai simplu, cu Node, vom spune Express - „Hei, dacă cineva face o solicitare GET pe această rută, atunci mergeți mai departe și activați această funcție (folosește acest punct final)”. Lucrurile se pot complica: „Express, dacă cineva face o solicitare GET către această rută, dar nu trimite un token de purtător de autorizare valid în antetul solicitării, atunci vă rugăm să răspundeți cu un HTTP 401 Unauthorized . Dacă posedă un Bearer Token valid, atunci trimiteți orice resursă protejată pe care o căutau, declanșând punctul final. Mulțumesc foarte mult și o zi bună.” Într-adevăr, ar fi frumos dacă limbajele de programare ar putea fi la un nivel atât de înalt, fără a pierde ambiguitate, dar demonstrează totuși conceptele de bază.
Amintiți-vă, punctul final, într-un fel, locuiește în spatele traseului. Așa că este imperativ ca clientul să furnizeze, în antetul cererii, ce metodă dorește să folosească pentru ca Express să-și dea seama ce să facă. Solicitarea va fi făcută către o anumită rută, pe care clientul o va specifica (împreună cu tipul de solicitare) atunci când contactează serverul, permițându-i lui Express să facă ceea ce trebuie să facă și nouă să facem ceea ce trebuie să facem atunci când Express ne declanșează apelurile. . La asta se rezumă totul.
În exemplele de cod de mai devreme, am numit funcția de listen care era disponibilă în app , transmițându-i un port și apel invers. app în sine, dacă vă amintiți, este rezultatul returnat din apelarea variabilei express ca funcție (adică express() ), iar variabila express este ceea ce am numit rezultatul returnării din solicitarea 'express' din folderul nostru node_modules . La fel cum se apelează listen în app , specificăm punctele finale de solicitare HTTP apelându-le în app . Să ne uităm la GET:
app.get('/my-test-route', () => { // ... }); Primul parametru este un string și este ruta în spatele căreia va locui punctul final. Funcția de apel invers este punctul final. Voi spune asta din nou: funcția de apel invers - al doilea parametru - este punctul final care se va declanșa atunci când se face o solicitare HTTP GET pe orice rută pe care o specificăm ca prim argument ( /my-test-route în acest caz).
Acum, înainte de a mai lucra cu Express, trebuie să știm cum funcționează rutele. Ruta pe care o specificăm ca șir va fi apelată făcând cererea către www.domain.com/the-route-we-chose-earlier-as-a-string . În cazul nostru, domeniul este localhost:3000 , ceea ce înseamnă că, pentru a declanșa funcția de apel invers de mai sus, trebuie să facem o solicitare GET către localhost:3000/my-test-route . Dacă am folosit un șir diferit ca primul argument de mai sus, adresa URL ar trebui să fie diferită pentru a se potrivi cu ceea ce am specificat în JavaScript.
Când vorbiți despre astfel de lucruri, probabil veți auzi de Glob Patterns. Am putea spune că toate rutele API-ului nostru sunt situate la localhost:3000/** Glob Pattern, unde ** este un metacar, adică orice director sau subdirector (rețineți că rutele nu sunt directoare) la care rădăcină este părinte - adică totul.
Să mergem mai departe și să adăugăm o instrucțiune de jurnal în acea funcție de apel invers, astfel încât să avem:
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); Vom pune în funcțiune serverul nostru executând node server/server.js (cu Node instalat pe sistemul nostru și accesibil global din variabilele de mediu ale sistemului) în directorul rădăcină al proiectului. Ca și mai devreme, ar trebui să vedeți mesajul că serverul este activat în consolă. Acum că serverul rulează, deschideți un browser și vizitați localhost:3000 în bara de adrese URL.
Ar trebui să fiți întâmpinat cu un mesaj de eroare care spune Cannot GET / . Apăsați Ctrl + Shift + I pe Windows în Chrome pentru a vedea consola pentru dezvoltatori. Acolo, ar trebui să vedeți că avem un 404 (Resursa nu a fost găsită). Acest lucru are sens - i-am spus serverului doar ce să facă atunci când cineva vizitează localhost:3000/my-test-route . Browserul nu are nimic de redat la localhost:3000 (care este echivalent cu localhost:3000/ cu o bară oblică).
Dacă vă uitați la fereastra terminalului în care rulează serverul, nu ar trebui să existe date noi. Acum, vizitați localhost:3000/my-test-route în bara de adrese URL a browserului dvs. Este posibil să vedeți aceeași eroare în Consola Chrome (deoarece browserul memorează conținutul în cache și încă nu are HTML de randat), dar dacă vă vedeți terminalul în care rulează procesul serverului, veți vedea că funcția de apel invers s-a declanșat într-adevăr iar mesajul de jurnal a fost într-adevăr înregistrat.
Închideți serverul cu Ctrl + C.
Acum, să dăm browserului ceva de redat atunci când se face o solicitare GET către acea rută, astfel încât să putem pierde mesajul Cannot GET / . Voi lua app.get() de mai devreme, iar în funcția de apel invers, voi adăuga două argumente. Amintiți-vă, funcția de apel invers pe care o transmitem este apelată de Express în culise și Express poate adăuga orice argument dorește. De fapt, adaugă două (ei bine, tehnic trei, dar vom vedea asta mai târziu) și, deși ambele sunt extrem de importante, nu ne pasă de primul deocamdată. Al doilea argument se numește res , prescurtare pentru response , și îl voi accesa setând undefined ca prim parametru:
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); }); Din nou, putem numi argumentul res cum vrem, dar res este convenție atunci când avem de-a face cu Express. res este de fapt un obiect, iar pe el există diferite metode de trimitere a datelor înapoi către client. În acest caz, voi accesa funcția send(...) disponibilă pe res pentru a trimite înapoi HTML pe care browserul îl va reda. Cu toate acestea, nu ne limităm la trimiterea HTML înapoi și putem alege să trimitem înapoi text, un obiect JavaScript, un flux (fluxurile sunt deosebit de frumoase) sau orice altceva.
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); res.send('<h1>Hello, World!</h1>'); }); Dacă închideți serverul și apoi îl aduceți înapoi și apoi reîmprospătați browserul la /my-test-route , veți vedea că HTML-ul este redat.
Fila Rețea din Instrumentele pentru dezvoltatori Chrome vă va permite să vedeți această solicitare GET cu mai multe detalii în ceea ce privește anteturile.
În acest moment, ne va folosi bine să începem să învățăm despre Express Middleware - funcții care pot fi activate la nivel global după ce un client face o solicitare.
Express Middleware
Express oferă metode prin care să definiți middleware personalizat pentru aplicația dvs. Într-adevăr, sensul Express Middleware este cel mai bine definit în Express Docs, aici)
Funcțiile middleware sunt funcții care au acces la obiectul cerere (
req), la obiectul răspuns (res) și la următoarea funcție middleware din ciclul cerere-răspuns al aplicației. Următoarea funcție middleware este de obicei desemnată printr-o variabilă numitănext.
Funcțiile middleware pot îndeplini următoarele sarcini:
- Executați orice cod.
- Efectuați modificări la obiectele de solicitare și răspuns.
- Încheiați ciclul cerere-răspuns.
- Apelați următoarea funcție middleware din stivă.
Cu alte cuvinte, o funcție middleware este o funcție personalizată pe care noi (dezvoltatorul) o putem defini și care va acționa ca un intermediar între momentul în care Express primește cererea și momentul în care funcția noastră de apel invers corespunzătoare se declanșează. Am putea face o funcție de log , de exemplu, care se va înregistra de fiecare dată când se face o solicitare. Rețineți că putem alege, de asemenea, să facem ca aceste funcții middleware să se declanșeze după ce punctul nostru final s-a declanșat, în funcție de locul în care îl plasați în stivă - ceva ce vom vedea mai târziu.
Pentru a specifica middleware personalizat, trebuie să-l definim ca o funcție și să-l transmitem în app.use(...) .
const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } app.use(myMiddleware); // This is the app variable returned from express().Toți împreună, avem acum:
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Our middleware function. const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } // Tell Express to use the middleware. app.use(myMiddleware); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); Dacă faceți din nou solicitările prin browser, ar trebui să vedeți acum că funcția dvs. de middleware declanșează și înregistrează marcaje temporale. Pentru a stimula experimentarea, încercați să eliminați apelul la next funcție și vedeți ce se întâmplă.
Funcția de callback middleware este apelată cu trei argumente, req , res și next . req este parametrul pe care l-am sărit peste când am construit Handler-ul GET mai devreme și este un obiect care conține informații despre cerere, cum ar fi anteturi, anteturi personalizate, parametri și orice corp care ar fi putut fi trimis de la client (cum ar fi faci cu o solicitare POST). Știu că aici vorbim despre middleware, dar atât punctele finale, cât și funcția middleware sunt apelate cu req și res . req și res vor fi aceleași (cu excepția cazului în care unul sau celălalt le modifică) atât în middleware, cât și în punctul final, în cadrul unei singure solicitări din partea clientului. Aceasta înseamnă, de exemplu, că puteți utiliza o funcție middleware pentru a igieniza datele prin eliminarea oricăror caractere care ar putea avea ca scop efectuarea injecțiilor SQL sau NoSQL și apoi transmiterea req sigure către punctul final.
res , așa cum am văzut mai devreme, vă permite să trimiteți date înapoi către client într-o mână de moduri diferite.
next este o funcție de apel invers pe care trebuie să o executați când middleware-ul și-a terminat de făcut treaba pentru a apela următoarea funcție middleware din stivă sau punct final. Asigurați-vă că rețineți că va trebui să apelați acest lucru în blocul de then al oricăror funcții asincrone pe care le declanșați în middleware. În funcție de operațiunea asincronă, este posibil să doriți sau nu să o apelați în blocul catch . Adică, funcția myMiddleware se declanșează după ce cererea este făcută de la client, dar înainte ca funcția de punct final a cererii să fie declanșată. Când executăm acest cod și facem o solicitare, ar trebui să vedeți că Middleware has fired... mesajul înainte ca mesajul A GET Request was made to... în consolă. Dacă nu apelați next() , ultima parte nu va rula niciodată - funcția dvs. finală la cerere nu se va declanșa.
Rețineți, de asemenea, că aș fi putut defini această funcție în mod anonim, ca atare (o convenție la care voi rămâne):
app.use((req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); }); Pentru oricine nou în JavaScript și ES6, dacă modul în care funcționează cele de mai sus nu are sens imediat, exemplul de mai jos ar trebui să fie de ajutor. Pur și simplu definim o funcție de apel invers (funcția anonimă) care ia o altă funcție de apel invers ( next ) ca argument. Numim o funcție care ia un argument de funcție o funcție de ordin superior. Priviți-l în felul de mai jos - prezintă un exemplu de bază despre cum ar putea funcționa Codul sursă Express în culise:
console.log('Suppose a request has just been made from the client.\n'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middleware. const next = () => console.log('Terminating Middleware!\n'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the "middleware" function that is passed into "use". // "next" is the above function that pretends to stop the middleware. callback(req, res, next); }; // This is analogous to the middleware function we defined earlier. // It gets passed in as "callback" in the "use" function above. const myMiddleware = (req, res, next) => { console.log('Inside the myMiddleware function!'); next(); } // Here, we are actually calling "use()" to see everything work. use(myMiddleware); console.log('Moving on to actually handle the HTTP Request or the next middleware function.'); Mai întâi numim use care ia myMiddleware ca argument. myMiddleware , în sine, este o funcție care ia trei argumente - req , res și next . În interiorul use , myMiddlware este apelat și acele trei argumente sunt transmise. next este o funcție definită în use . myMiddleware este definit ca callback în metoda de use . Dacă aș fi plasat use , în acest exemplu, pe un obiect numit app , am fi putut imita în întregime configurația Express, deși fără prize sau conectivitate la rețea.

În acest caz, atât myMiddleware , cât și callback sunt funcții de ordin superior, deoarece ambele iau funcții ca argumente.
Dacă executați acest cod, veți vedea următorul răspuns:
Suppose a request has just been made from the client. Inside use() - the "use" function has been called. Inside the middleware function! Terminating Middleware! Moving on to actually handle the HTTP Request or the next middleware function.Rețineți că aș fi putut folosi și funcții anonime pentru a obține același rezultat:
console.log('Suppose a request has just been made from the client.'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middlewear. const next = () => console.log('Terminating Middlewear!'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the function which is passed into "use". // "next" is the above function that pretends to stop the middlewear. callback(req, res, () => { console.log('Terminating Middlewear!'); }); }; // Here, we are actually calling "use()" to see everything work. use((req, res, next) => { console.log('Inside the middlewear function!'); next(); }); console.log('Moving on to actually handle the HTTP Request.');Cu asta, sperăm, rezolvată, acum putem reveni la sarcina actuală - configurarea middleware-ului nostru.
Adevărul este că, de obicei, va trebui să trimiteți date printr-o solicitare HTTP. Aveți câteva opțiuni diferite pentru a face acest lucru — trimiterea parametrilor de interogare URL, trimiterea de date care vor fi accesibile pe obiectul req despre care am aflat mai devreme etc. Acest obiect nu este disponibil doar în apelarea la apelarea app.use() , dar și la orice punct final. Am folosit mai devreme undefined ca umplere, astfel încât să ne putem concentra pe res pentru a trimite HTML înapoi către client, dar acum avem nevoie de acces la el.
app.use('/my-test-route', (req, res) => { // The req object contains client-defined data that is sent up. // The res object allows the server to send data back down. });Solicitările HTTP POST ar putea necesita trimiterea unui obiect body către server. Dacă aveți un formular pe client și luați numele utilizatorului și e-mailul, probabil că veți trimite acele date către serverul de pe corpul cererii.
Să aruncăm o privire la cum ar putea arăta din partea clientului:
<!DOCTYPE html> <html> <body> <form action="https://localhost:3000/email-list" method="POST" > <input type="text" name="nameInput"> <input type="email" name="emailInput"> <input type="submit"> </form> </body> </html>Pe partea de server:
app.post('/email-list', (req, res) => { // What do we now? // How do we access the values for the user's name and email? }); Pentru a accesa numele și e-mailul utilizatorului, va trebui să folosim un anumit tip de middleware. Aceasta va pune datele pe un obiect numit body disponibil la req . Body Parser a fost o metodă populară de a face acest lucru, disponibilă de dezvoltatorii Express ca modul NPM independent. Acum, Express vine pre-ambalat cu propriul său middleware pentru a face acest lucru și îl vom numi așa:
app.use(express.urlencoded({ extended: true }));Acum putem face:
app.post('/email-list', (req, res) => { console.log('User Name: ', req.body.nameInput); console.log('User Email: ', req.body.emailInput); }); Tot ceea ce face este să ia orice intrare definită de utilizator care este trimisă de la client și să le facă disponibile pe obiectul body al req . Rețineți că pe req.body , avem acum nameInput și emailInput , care sunt numele etichetelor de input în HTML. Acum, aceste date definite de client ar trebui să fie considerate periculoase (niciodată, niciodată să nu ai încredere în client) și trebuie să fie dezinfectate, dar vom trata asta mai târziu.
Un alt tip de middleware oferit de express este express.json() . express.json este folosit pentru a împacheta orice încărcături utile JSON trimise într-o solicitare de la client pe req.body , în timp ce express.urlencoded va împacheta orice solicitări primite cu șiruri de caractere, matrice sau alte date codificate URL pe req.body . Pe scurt, ambele manipulează req.body , dar .json() este pentru încărcături utile JSON și .urlencoded() este, printre altele, pentru parametrii de interogare POST.
Un alt mod de a spune acest lucru este că cererile primite cu un antet Content-Type: application/json (cum ar fi specificarea unui corp POST cu API-ul fetch ) vor fi gestionate de express.json() , în timp ce cererile cu antet Content-Type: application/x-www-form-urlencoded (cum ar fi Formulare HTML) va fi tratat cu express.urlencoded() . Acest lucru sperăm că acum are sens.
Începem rutele noastre CRUD pentru MongoDB
Notă : atunci când efectuăm solicitări PATCH în acest articol, nu vom urma specificațiile JSONPatch RFC - o problemă pe care o vom remedia în următorul articol din această serie.
Având în vedere că înțelegem că specificăm fiecare punct final apelând funcția relevantă din app , transmițându-i ruta și o funcție de apel invers care conține obiectele de cerere și răspuns, putem începe să definim rutele noastre CRUD pentru API-ul Bookshelf. Într-adevăr, și având în vedere că acesta este un articol introductiv, nu voi avea grijă să urmez complet specificațiile HTTP și REST și nici nu voi încerca să folosesc cea mai curată arhitectură posibilă. Asta va veni într-un articol viitor.
Voi deschide fișierul server.js pe care l-am folosit până acum și voi goli totul pentru a începe din lista curată de mai jos:
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true )); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); Luați în considerare tot codul următor pentru a prelua porțiunea // ... a fișierului de mai sus.
Pentru a ne defini punctele finale și pentru că construim un API REST, ar trebui să discutăm modalitatea corectă de a numi rutele. Din nou, ar trebui să aruncați o privire la secțiunea HTTP a fostului meu articol pentru mai multe informații. Avem de-a face cu cărți, așa că toate rutele vor fi situate în spatele /books (convenția de denumire la plural este standard).
| Cerere | Traseu |
|---|---|
| POST | /books |
| OBȚINE | /books/id |
| PLASTURE | /books/id |
| ȘTERGE | /books/id |
După cum puteți vedea, nu trebuie specificat un ID la POSTAREA unei cărți, deoarece noi (sau mai degrabă, MongoDB), îl vom genera pentru noi, automat, pe partea serverului. Obținerea, corecția și ștergerea cărților vor necesita toate să transmitem acel ID către punctul nostru final, despre care vom discuta mai târziu. Deocamdată, să creăm pur și simplu punctele finale:
// HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); Sintaxa :id îi spune Express că id este un parametru dinamic care va fi transmis în URL. Avem acces la el pe obiectul params care este disponibil la req . Știu că „avem acces la el la req ” sună ca magie și magia (care nu există) este periculoasă în programare, dar trebuie să rețineți că Express nu este o cutie neagră. Este un proiect open-source disponibil pe GitHub sub o licență MIT. Puteți vizualiza cu ușurință codul sursă dacă doriți să vedeți cum parametrii dinamici de interogare sunt puși pe obiectul req .
Toate împreună, avem acum următoarele în fișierul server.js :
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); Continuați și porniți serverul, rulând node server.js de pe terminal sau din linia de comandă și vizitați browserul. Deschideți Consola de dezvoltare Chrome și, în bara URL (Uniform Resource Locator), accesați localhost:3000/books . Ar trebui să vedeți deja indicatorul în terminalul sistemului de operare că serverul este activ, precum și declarația de jurnal pentru GET.
Până acum, am folosit un browser web pentru a efectua solicitări GET. Acest lucru este bun pentru abia la început, dar vom descoperi rapid că există instrumente mai bune pentru a testa rutele API. Într-adevăr, am putea lipi apelurile de fetch direct în consolă sau să folosim un serviciu online. În cazul nostru, și pentru a economisi timp, vom folosi cURL și Postman. Le folosesc pe ambele in acest articol (desi ai putea sa le folosesti pe oricare sau) ca sa le pot prezenta pentru daca nu le-ai folosit. cURL este o bibliotecă (o bibliotecă foarte, foarte importantă) și un instrument de linie de comandă conceput pentru a transfera date folosind diferite protocoale. Postman este un instrument bazat pe GUI pentru testarea API-urilor. După ce ați urmat instrucțiunile relevante de instalare pentru ambele instrumente de pe sistemul dvs. de operare, asigurați-vă că serverul încă rulează și apoi executați următoarele comenzi (una câte una) într-un terminal nou. Este important să le tastați și să le executați individual, apoi să urmăriți mesajul de jurnal în terminalul separat de serverul dvs. De asemenea, rețineți că simbolul de comentariu standard al limbajului de programare // nu este un simbol valid în Bash sau MS-DOS. Va trebui să omiteți acele linii și le folosesc aici doar pentru a descrie fiecare bloc de comenzi cURL .
// HTTP POST Request (Localhost, IPv4, IPv6) curl -X POST https://localhost:3000/books curl -X POST https://127.0.0.1:3000/books curl -X POST https://[::1]:3000/books // HTTP GET Request (Localhost, IPv4, IPv6) curl -X GET https://localhost:3000/books/123abc curl -X GET https://127.0.0.1:3000/books/book-id-123 curl -X GET https://[::1]:3000/books/book-abc123 // HTTP PATCH Request (Localhost, IPv4, IPv6) curl -X PATCH https://localhost:3000/books/456 curl -X PATCH https://127.0.0.1:3000/books/218 curl -X PATCH https://[::1]:3000/books/some-id // HTTP DELETE Request (Localhost, IPv4, IPv6) curl -X DELETE https://localhost:3000/books/abc curl -X DELETE https://127.0.0.1:3000/books/314 curl -X DELETE https://[::1]:3000/books/217 După cum puteți vedea, ID-ul care este transmis ca parametru URL poate fi orice valoare. Indicatorul -X specifică tipul de solicitare HTTP (poate fi omis pentru GET) și furnizăm adresa URL la care va fi făcută cererea ulterior. Am duplicat fiecare cerere de trei ori, permițându-vă să vedeți că totul funcționează în continuare, indiferent dacă utilizați numele de gazdă localhost , adresa IPv4 ( 127.0.0.1 ) la care se rezolvă localhost sau adresa IPv6 ( ::1 ) la care se rezolvă localhost . Rețineți că cURL necesită împachetarea adreselor IPv6 între paranteze drepte.
Suntem într-un loc decent acum - avem structura simplă a rutelor și punctelor finale configurate. Serverul rulează corect și acceptă solicitările HTTP așa cum ne așteptăm. Spre deosebire de ceea ce v-ați putea aștepta, nu mai este mult de făcut în acest moment - trebuie doar să ne setăm baza de date, să o găzduim (folosind o bază de date ca serviciu - MongoDB Atlas) și să păstrăm datele în ea (și efectuează validarea și creează răspunsuri de eroare).
Configurarea unei baze de date MongoDB de producție
Pentru a configura o bază de date de producție, ne vom îndrepta către Pagina principală MongoDB Atlas și ne vom înscrie pentru un cont gratuit. După aceea, creați un nou cluster. Puteți păstra setările implicite, alegând o regiune aplicabilă pentru nivelul taxei. Apoi apăsați butonul „Creați cluster”. Crearea clusterului va dura ceva timp, iar apoi veți putea obține adresa URL și parola bazei de date. Luați notă de acestea când le vedeți. Le vom codifica deocamdată și apoi le vom stoca în variabilele de mediu mai târziu, din motive de securitate. Pentru ajutor în crearea și conectarea la un cluster, vă voi trimite la documentația MongoDB, în special această pagină și această pagină, sau puteți lăsa un comentariu mai jos și voi încerca să vă ajut.
Crearea unui model de mangustă
Se recomandă să înțelegeți semnificațiile documentelor și colecțiilor în contextul NoSQL (Nu numai SQL — Limbajul de interogare structurat). Pentru referință, poate doriți să citiți atât Ghidul de pornire rapidă Mongoose, cât și secțiunea MongoDB a fostului meu articol.
Acum avem o bază de date care este gata să accepte operațiuni CRUD. Mongoose este un modul Node (sau ODM — Object Document Mapper) care ne va permite să efectuăm acele operațiuni (extrăgând unele dintre complexități), precum și să setăm schema sau structura colecției bazei de date.
Ca o declinare importantă, există o mulțime de controverse în jurul ORM-urilor și modelelor precum Active Record sau Data Mapper. Unii dezvoltatori înjură pe ORM-uri, iar alții înjură împotriva lor (crezând că le stau în cale). De asemenea, este important de reținut că ORM-urile abstrac mult, cum ar fi gruparea conexiunilor, conexiunile socket și manipularea, etc. Ați putea folosi cu ușurință driverul nativ MongoDB (un alt modul NPM), dar ar fi mult mai mult de lucru. Deși este recomandat să jucați cu Native Driver înainte de a utiliza ORM-urile, omit Native Driver aici pentru concizie. Pentru operațiuni SQL complexe pe o bază de date relațională, nu toate ORM-urile vor fi optimizate pentru viteza de interogare și este posibil să ajungeți să vă scrieți propriul SQL brut. ORMs can come into play a lot with Domain-Driven Design and CQRS, among others. They are an established concept in the .NET world, and the Node.js community has not completely caught up yet — TypeORM is better, but it's not NHibernate or Entity Framework.
To create our Model, I'll create a new folder in the server directory entitled models , within which I'll create a single file with the name book.js . Thus far, our project's directory structure is as follows:
- server - node_modules - models - book.js - package.json - server.js Indeed, this directory structure is not required, but I use it here because it's simple. Allow me to note that this is not at all the kind of architecture you want to use for larger applications (and you might not even want to use JavaScript — TypeScript could be a better option), which I discuss in this article's closing. The next step will be to install mongoose , which is performed via, as you might expect, npm i mongoose .
The meaning of a Model is best ascertained from the Mongoose documentation:
Models are fancy constructors compiled from
Schemadefinitions. An instance of a model is called a document. Models are responsible for creating and reading documents from the underlying MongoDB database.
Before creating the Model, we'll define its Schema. A Schema will, among others, make certain expectations about the value of the properties provided. MongoDB is schemaless, and thus this functionality is provided by the Mongoose ODM. Let's start with a simple example. Suppose I want my database to store a user's name, email address, and password. Traditionally, as a plain old JavaScript Object (POJO), such a structure might look like this:
const userDocument = { name: 'Jamie Corkhill', email: '[email protected]', password: 'Bcrypt Hash' };If that above object was how we expected our user's object to look, then we would need to define a schema for it, like this:
const schema = { name: { type: String, trim: true, required: true }, email: { type: String, trim: true, required: true }, password: { type: String, required: true } }; Notice that when creating our schema, we define what properties will be available on each document in the collection as an object in the schema. In our case, that's name , email , and password . The fields type , trim , required tell Mongoose what data to expect. If we try to set the name field to a number, for example, or if we don't provide a field, Mongoose will throw an error (because we are expecting a type of String ), and we can send back a 400 Bad Request to the client. This might not make sense right now because we have defined an arbitrary schema object. However, the fields of type , trim , and required (among others) are special validators that Mongoose understands. trim , for example, will remove any whitespace from the beginning and end of the string. We'll pass the above schema to mongoose.Schema() in the future and that function will know what to do with the validators.
Understanding how Schemas work, we'll create the model for our Books Collection of the Bookshelf API. Let's define what data we require:
Title
ISBN Number
Autor
Nume
Numele de familie
Publishing Date
Finished Reading (Boolean)
I'm going to create this in the book.js file we created earlier in /models . Like the example above, we'll be performing validation:
const mongoose = require('mongoose'); // Define the schema: const mySchema = { title: { type: String, required: true, trim: true, }, isbn: { type: String, required: true, trim: true, }, author: { firstName:{ type: String, required: true, trim: true }, lastName: { type: String, required: true, trim: true } }, publishingDate: { type: String }, finishedReading: { type: Boolean, required: true, default: false } } default will set a default value for the property if none is provided — finishedReading for example, although a required field, will be set automatically to false if the client does not send one up.
Mongoose also provides the ability to perform custom validation on our fields, which is done by supplying the validate() method, which attains the value that was attempted to be set as its one and only parameter. In this function, we can throw an error if the validation fails. Iată un exemplu:
// ... isbn: { type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } } // ... Now, if anyone supplies an invalid ISBN to our model, Mongoose will throw an error when trying to save that document to the collection. I've already installed the NPM module validator via npm i validator and required it. validator contains a bunch of helper functions for common validation requirements, and I use it here instead of RegEx because ISBNs can't be validated with RegEx alone due to a tailing checksum. Remember, users will be sending a JSON body to one of our POST routes. That endpoint will catch any errors (such as an invalid ISBN) when attempting to save, and if one is thrown, it'll return a blank response with an HTTP 400 Bad Request status — we haven't yet added that functionality.
Finally, we have to define our schema of earlier as the schema for our model, so I'll make a call to mongoose.Schema() passing in that schema:
const bookSchema = mongoose.Schema(mySchema); To make things more precise and clean, I'll replace the mySchema variable with the actual object all on one line:
const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } });Let's take a final moment to discuss this schema. We are saying that each of our documents will consist of a title, an ISBN, an author with a first and last name, a publishing date, and a finishedReading boolean.
-
titlewill be of typeString, it's a required field, and we'll trim any whitespace. -
isbnwill be of typeString, it's a required field, it must match the validator, and we'll trim any whitespace. -
authoris of typeobjectcontaining a required, trimmed,stringfirstName and a required, trimmed,stringlastName. -
publishingDateis of type String (although we could make it of typeDateorNumberfor a Unix timestamp. -
finishedReadingis a requiredbooleanthat will default tofalseif not provided.
With our bookSchema defined, Mongoose knows what data and what fields to expect within each document to the collection that stores books. However, how do we tell it what collection that specific schema defines? We could have hundreds of collections, so how do we correlate, or tie, bookSchema to the Book collection?
The answer, as seen earlier, is with the use of models. We'll use bookSchema to create a model, and that model will model the data to be stored in the Book collection, which will be created by Mongoose automatically.
Append the following lines to the end of the file:
const Book = mongoose.model('Book', bookSchema); module.exports = Book; As you can see, we have created a model, the name of which is Book (— the first parameter to mongoose.model() ), and also provided the ruleset, or schema, to which all data is saved in the Book collection will have to abide. We export this model as a default export, allowing us to require the file for our endpoints to access. Book is the object upon which we'll call all of the required functions to Create, Read, Update, and Delete data which are provided by Mongoose.
Altogether, our book.js file should look as follows:
const mongoose = require('mongoose'); const validator = require('validator'); // Define the schema. const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String, required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } }); // Create the "Book" model of name Book with schema bookSchema. const Book = mongoose.model('Book', bookSchema); // Provide the model as a default export. module.exports = Book;Connecting To MongoDB (Basics)
Don't worry about copying down this code. I'll provide a better version in the next section. To connect to our database, we'll have to provide the database URL and password. We'll call the connect method available on mongoose to do so, passing to it the required data. For now, we are going hardcode the URL and password — an extremely frowned upon technique for many reasons: namely the accidental committing of sensitive data to a public (or private made public) GitHub Repository. Realize also that commit history is saved, and that if you accidentally commit a piece of sensitive data, removing it in a future commit will not prevent people from seeing it (or bots from harvesting it), because it's still available in the commit history. CLI tools exist to mitigate this issue and remove history.
As stated, for now, we'll hard code the URL and password, and then save them to environment variables later. At this point, let's look at simply how to do this, and then I'll mention a way to optimize it.
const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false, useUnifiedTopology: true });Aceasta se va conecta la baza de date. Oferim adresa URL pe care am obținut-o din tabloul de bord MongoDB Atlas, iar obiectul transmis ca al doilea parametru specifică caracteristicile de utilizat pentru, printre altele, a preveni avertismentele de depreciere.
Mongoose, care folosește driverul nativ MongoDB de bază în culise, trebuie să încerce să țină pasul cu modificările ulterioare aduse driverului. Într-o versiune nouă a driverului, mecanismul folosit pentru a analiza adresele URL de conexiune a fost modificat, așa că trecem useNewUrlParser: true pentru a specifica că dorim să folosim cea mai recentă versiune disponibilă din driverul oficial.
În mod implicit, dacă setați indecși (și se numesc „indici” nu „indici”) (pe care nu le vom acoperi în acest articol) pentru datele din baza dvs. de date, Mongoose utilizează funcția ensureIndex() disponibilă din Native Driver. MongoDB a depreciat acea funcție în favoarea createIndex() și astfel setarea flag useCreateIndex la true îi va spune lui Mongoose să folosească metoda createIndex() din driver, care este funcția nedepreciată.
Versiunea originală a lui Mongoose a findOneAndUpdate (care este o metodă de a găsi un document într-o bază de date și de a-l actualiza) este anterioară versiunii Native Driver. Adică findOneAndUpdate() nu a fost inițial o funcție Native Driver, ci mai degrabă una oferită de Mongoose, așa că Mongoose a trebuit să folosească findAndModify furnizat în culise de driver pentru a crea funcționalitatea findOneAndUpdate . Cu driverul actualizat acum, acesta conține propria sa funcție, așa că nu trebuie să folosim findAndModify . S-ar putea să nu aibă sens și este în regulă - nu este o informație importantă la scara lucrurilor.
În cele din urmă, MongoDB și-a depreciat vechiul sistem de monitorizare a serverului și a motorului. Folosim noua metodă cu useUnifiedTopology: true .
Ceea ce avem până acum este o modalitate de a ne conecta la baza de date. Dar iată problema - nu este scalabil sau eficient. Când scriem teste unitare pentru acest API, testele unitare vor folosi propriile lor date de testare (sau dispozitive) în propriile baze de date de testare. Așadar, dorim o modalitate de a putea crea conexiuni în diferite scopuri - unele pentru medii de testare (pe care le putem roti și demola după bunul plac), altele pentru medii de dezvoltare și altele pentru medii de producție. Pentru a face asta, vom construi o fabrică. (Îți amintești asta de mai devreme?)
Conectarea la Mongo — Construirea unei implementări a unei fabrici JS
Într-adevăr, obiectele Java nu sunt deloc analoage cu obiectele JavaScript și, prin urmare, ceea ce știm mai sus din Factory Design Pattern nu se va aplica. Am oferit doar asta ca exemplu pentru a arăta modelul tradițional. Pentru a obține un obiect în Java, sau C#, sau C++, etc., trebuie să instanțiem o clasă. Acest lucru se face cu cuvântul cheie new , care indică compilatorului să aloce memorie pentru obiectul din heap. În C++, acest lucru ne oferă un pointer către obiectul pe care trebuie să-l curățăm singuri, astfel încât să nu avem pointeri suspendați sau scurgeri de memorie (C++ nu are colector de gunoi, spre deosebire de Node/V8 care este construit pe C++) În JavaScript, de mai sus nu trebuie făcut - nu trebuie să instanțiem o clasă pentru a obține un obiect - un obiect este doar {} . Unii oameni vor spune că totul în JavaScript este un obiect, deși nu este adevărat din punct de vedere tehnic, deoarece tipurile primitive nu sunt obiecte.
Din motivele de mai sus, fabrica noastră JS va fi mai simplă, rămânând la definiția liberă a unei fabrici fiind o funcție care returnează un obiect (un obiect JS). Deoarece o funcție este un obiect (pentru că function moștenește de la object prin moștenire prototipală), exemplul nostru de mai jos va îndeplini acest criteriu. Pentru a implementa fabrica, voi crea un nou folder în interiorul server numit db . În db voi crea un fișier nou numit mongoose.js . Acest fișier va face conexiuni la baza de date. În interiorul mongoose.js , voi crea o funcție numită connectionFactory și o voi exporta implicit:
// Directory - server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; const connectionFactory = () => { return mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false }); }; module.exports = connectionFactory; Folosind prescurtarea oferită de ES6 pentru funcțiile săgeată care returnează o instrucțiune pe aceeași linie cu semnătura metodei, voi simplifica acest fișier scăpând de definiția connectionFactory și doar exportând implicit fabrica:
// server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; module.exports = () => mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: true });Acum, tot ce trebuie să faceți este să solicitați fișierul și să apelați metoda care este exportată, astfel:
const connectionFactory = require('./db/mongoose'); connectionFactory(); // OR require('./db/mongoose')();Puteți inversa controlul dacă adresa URL MongoDB va fi furnizată ca parametru al funcției din fabrică, dar vom schimba dinamic adresa URL ca variabilă de mediu în funcție de mediu.
Avantajele realizării conexiunii noastre ca funcție sunt că putem apela acea funcție mai târziu în cod pentru a vă conecta la baza de date din fișiere destinate producției și cele care vizează testarea integrării locale și de la distanță atât pe dispozitiv, cât și cu o conductă CI/CD la distanță /build server.
Construirea punctelor noastre finale
Acum începem să adăugăm logica foarte simplă legată de CRUD la punctele noastre finale. După cum sa menționat anterior, o scurtă declinare a răspunderii este necesară. Metodele prin care ne implementăm aici logica de afaceri nu sunt cele pe care ar trebui să le oglindiți pentru altceva decât pentru proiecte simple. Conectarea la bazele de date și efectuarea logicii direct în punctele finale este (și ar trebui să fie) descurajată, deoarece pierdeți capacitatea de a schimba serviciile sau SGBD-uri fără a fi nevoie să efectuați o refactorare la nivel de aplicație. Cu toate acestea, având în vedere că acesta este un articol pentru începători, folosesc aceste practici proaste aici. Un articol viitor din această serie va discuta despre cum putem crește atât complexitatea, cât și calitatea arhitecturii noastre.
Deocamdată, să revenim la fișierul server.js și să ne asigurăm că ambii avem același punct de plecare. Observați că am adăugat declarația require pentru fabrica noastră de conexiuni la baza de date și am importat modelul pe care l-am exportat din ./models/book.js .
const express = require('express'); // Database connection and model. require('./db/mongoose.js'); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); Voi începe cu app.post() . Avem acces la modelul Book pentru că l-am exportat din fișierul în care l-am creat. După cum se precizează în documentele Mongoose, Book poate fi construit. Pentru a crea o carte nouă, apelăm constructorul și transmitem datele cărții, după cum urmează:
const book = new Book(bookData); În cazul nostru, vom avea bookData ca obiect trimis în cerere, care va fi disponibil pe req.body.book . Rețineți că middleware-ul express.json express.json() va pune orice date JSON pe care le trimitem pe req.body . Trebuie să trimitem JSON în următorul format:
{ "book": { "title": "The Art of Computer Programming", "isbn": "ISBN-13: 978-0-201-89683-1", "author": { "firstName": "Donald", "lastName": "Knuth" }, "publishingDate": "July 17, 1997", "finishedReading": true } } Ceea ce înseamnă, atunci, este că JSON-ul pe care îl transmitem va fi analizat, iar întregul obiect JSON (prima pereche de acolade) va fi plasat pe req.body de către middleware-ul express.json express.json() . Singura proprietate a obiectului nostru JSON este book și astfel obiectul book va fi disponibil pe req.body.book .
În acest moment, putem apela funcția constructor de model și putem transmite datele noastre:
app.post('/books', async (req, res) => { // <- Notice 'async' const book = new Book(req.body.book); await book.save(); // <- Notice 'await' }); Observați câteva lucruri aici. Apelarea metodei de save pe instanța pe care o revenim de la apelarea funcției constructor va persista obiectul req.body.book în baza de date dacă și numai dacă respectă schema pe care am definit-o în modelul Mongoose. Acțiunea de a salva date într-o bază de date este o operație asincronă, iar această metodă save() returnează o promisiune - a cărei soluționare o așteptăm cu mult. În loc să înlănțuiesc un apel .then .then() , folosesc sintaxa ES6 Async/Await, ceea ce înseamnă că trebuie să fac funcția de apel invers la app.post async .
book.save() va respinge cu o ValidationError dacă obiectul trimis de client nu respectă schema pe care am definit-o. Configurația noastră actuală generează un cod foarte slab și prost scris, pentru că nu vrem ca aplicația noastră să se blocheze în cazul unui eșec în ceea ce privește validarea. Pentru a remedia asta, voi încadra operația periculoasă într-o clauză try/catch . În cazul unei erori, voi returna o solicitare HTTP 400 incorectă sau o entitate neprocesabilă HTTP 422. Există o oarecare dezbatere cu privire la care să folosiți, așa că voi rămâne cu un 400 pentru acest articol, deoarece este mai generic.
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { return res.status(400).send({ error: 'ValidationError' }); } }); Observați că folosesc ES6 Object Shorthand doar pentru a returna obiectul book direct înapoi clientului în cazul de succes cu res.send({ book }) - care ar fi echivalent cu res.send({ book: book }) . De asemenea, returnez expresia doar pentru a mă asigura că funcția mea iese. În blocul catch , am setat starea să fie 400 în mod explicit și returnez șirul „ValidationError” pe proprietatea de error a obiectului care este trimis înapoi. A 201 este codul de stare a căii de succes care înseamnă „CREAT”.
Într-adevăr, nici aceasta nu este cea mai bună soluție, deoarece nu putem fi siguri că motivul eșecului a fost o cerere greșită din partea clientului. Poate că am pierdut conexiunea (se presupune că o conexiune socket întreruptă, deci o excepție tranzitorie) la baza de date, caz în care ar trebui probabil să returnăm o eroare 500 Internal Server. O modalitate de a verifica acest lucru ar fi să citiți obiectul de eroare e și să returnați selectiv un răspuns. Să facem asta acum, dar așa cum am spus de mai multe ori, un articol de continuare va discuta despre arhitectura adecvată în ceea ce privește routerele, controlere, servicii, depozite, clase de eroare personalizate, middleware personalizat de eroare, răspunsuri personalizate de eroare, model de bază de date/date entități de domeniu mapare și Separarea interogărilor de comandă (CQS).
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'ValidationError' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); Continuați și deschideți Postman (presupunând că îl aveți, în caz contrar, descărcați-l și instalați-l) și creați o nouă solicitare. Vom face o solicitare POST către localhost:3000/books . Sub fila „Corps” din secțiunea Solicitare poștaș, voi selecta butonul radio „brut” și voi selecta „JSON” în butonul drop-down din extrema dreaptă. Aceasta va continua și va adăuga automat antetul Content-Type: application/json la cerere. Apoi, voi copia și lipi obiectul Book JSON de mai devreme în zona de text Body. Aceasta este ceea ce avem:
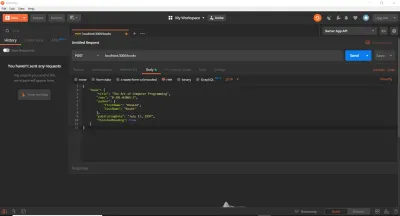
După aceea, voi apăsa butonul de trimitere și ar trebui să vedeți un răspuns 201 Created în secțiunea „Răspuns” din Postman (rândul de jos). Vedem acest lucru deoarece i-am cerut expres să răspundă cu un 201 și obiectul Book - dacă tocmai am fi făcut res.send() fără cod de stare, express ar fi răspuns automat cu un 200 OK. După cum puteți vedea, obiectul Book este acum salvat în baza de date și a fost returnat clientului ca răspuns la cererea POST.
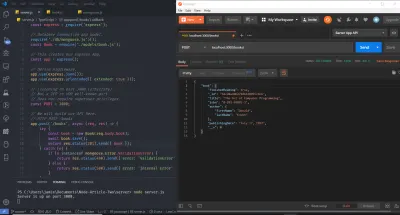
Dacă vizualizați baza de date colecția de cărți prin MongoDB Atlas, veți vedea că cartea a fost într-adevăr salvată.
De asemenea, puteți spune că MongoDB a inserat câmpurile __v și _id . Primul reprezintă versiunea documentului, în acest caz, 0, iar cel de-al doilea este ObjectID-ul documentului — care este generat automat de MongoDB și este garantat să aibă o probabilitate scăzută de coliziune.
Un rezumat al ceea ce am acoperit până acum
Am acoperit multe până acum în articol. Să luăm o scurtă amânare trecând peste un scurt rezumat înainte de a reveni pentru a finaliza Express API.
Am aflat despre ES6 Object Destructurarea, sintaxa ES6 Object Shorthand, precum și despre operatorul ES6 Rest/Spread. Toate cele trei ne permit să facem următoarele (și mai mult, așa cum am discutat mai sus):
// Destructuring Object Properties: const { a: newNameA = 'Default', b } = { a: 'someData', b: 'info' }; console.log(`newNameA: ${newNameA}, b: ${b}`); // newNameA: someData, b: info // Destructuring Array Elements const [elemOne, elemTwo] = [() => console.log('hi'), 'data']; console.log(`elemOne(): ${elemOne()}, elemTwo: ${elemTwo}`); // elemOne(): hi, elemTwo: data // Object Shorthand const makeObj = (name) => ({ name }); console.log(`makeObj('Tim'): ${JSON.stringify(makeObj('Tim'))}`); // makeObj('Tim'): { "name": "Tim" } // Rest, Spread const [c, d, ...rest] = [0, 1, 2, 3, 4]; console.log(`c: ${c}, d: ${d}, rest: ${rest}`) // c: 0, d: 1, rest: 2, 3, 4 Am acoperit, de asemenea, Express, Expess Middleware, Servere, Porturi, Adresare IP, etc. Lucrurile au devenit interesante când am aflat că există metode disponibile pentru rezultatul returnat de la require('express')(); cu numele verbelor HTTP, cum ar fi app.get și app.post .
Dacă acea parte require('express')() nu avea sens pentru tine, acesta era punctul pe care îl spuneam:
const express = require('express'); const app = express(); app.someHTTPVerbAr trebui să aibă sens în același mod în care am dezactivat fabrica de conexiuni înainte pentru Mongoose.
Fiecare handler de rută, care este funcția punct final (sau funcția de apel invers), este transmis într-un obiect req și un obiect res din Express în culise. (Din punct de vedere tehnic primesc și next , așa cum vom vedea într-un minut). req conține date specifice cererii primite de la client, cum ar fi anteturi sau orice JSON trimis. res este ceea ce ne permite să returnăm răspunsuri clientului. next funcție este, de asemenea, transmisă în handlere.
Cu Mongoose, am văzut cum ne putem conecta la baza de date cu două metode - o modalitate primitivă și una mai avansată/practică, care împrumută din modelul Factory. Vom sfârși prin a folosi acest lucru atunci când discutăm despre Testarea unitară și de integrare cu Jest (și testarea mutațiilor), deoarece ne va permite să pornim o instanță de testare a DB populată cu date de bază împotriva căreia putem rula aserțiuni.
După aceea, am creat un obiect de schemă Mongoose și l-am folosit pentru a crea un model, apoi am învățat cum putem apela constructorul acelui model pentru a crea o nouă instanță a acestuia. Disponibilă pe instanță este o metodă de save (printre altele), care este de natură asincronă și care va verifica dacă structura obiectului pe care am transmis-o respectă schema, rezolvând promisiunea dacă o face și respingând promisiunea cu o ValidationError dacă aceasta nu. În cazul unei rezoluții, noul document este salvat în baza de date și răspundem cu un HTTP 200 OK/201 CREAT, în caz contrar, prindem eroarea aruncată în punctul nostru final și returnăm clientului un HTTP 400 Bad Request.
Pe măsură ce continuăm să construiți punctele noastre finale, veți afla mai multe despre unele dintre metodele disponibile pe model și pe instanța modelului.
Finalizarea punctelor noastre finale
După ce am finalizat punctul final POST, să ne ocupăm de GET. După cum am menționat mai devreme, sintaxa :id din interiorul rutei îi informează pe Express că id este un parametru de rută, accesibil din req.params . Ai văzut deja că, atunci când potriviți un ID pentru parametrul „wildcard” din traseu, acesta a fost imprimat pe ecran în primele exemple. De exemplu, dacă ați făcut o solicitare GET către „/books/test-id-123”, atunci req.params.id ar fi șirul test-id-123 , deoarece numele paramului era id , având ruta ca HTTP GET /books/:id .
Deci, tot ce trebuie să facem este să preluăm acel ID din obiectul req și să verificăm dacă vreun document din baza noastră de date are același ID - ceva făcut foarte ușor de Mongoose (și Native Driver).
app.get('/books/:id', async (req, res) => { const book = await Book.findById(req.params.id); console.log(book); res.send({ book }); }); Puteți vedea că accesibilă pe modelul nostru este o funcție pe care o putem apela și care va găsi un document după ID-ul său. În culise, Mongoose va arunca orice ID pe care îl trecem în findById la tipul câmpului _id din document sau, în acest caz, un ObjectId . Dacă se găsește un ID care se potrivește (și doar unul va fi găsit pentru ObjectId are o probabilitate de coliziune extrem de scăzută), acel document va fi plasat în variabila constantă book noastre. Dacă nu, book va fi nulă - un fapt pe care îl vom folosi în viitorul apropiat.
Deocamdată, haideți să repornim serverul (trebuie să reporniți serverul dacă nu utilizați nodemon ) și să ne asigurăm că mai avem un document de carte de mai înainte în interiorul Colecției de Books . Continuați și copiați ID-ul acelui document, partea evidențiată a imaginii de mai jos:

Și folosiți-l pentru a face o solicitare GET către /books/:id cu Postman, după cum urmează (rețineți că datele corpului sunt doar rămase din cererea mea POST anterioară. Nu este de fapt folosită în ciuda faptului că este descrisă în imaginea de mai jos) :
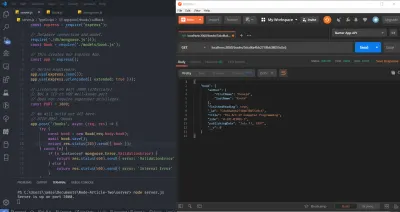
După ce faceți acest lucru, ar trebui să primiți documentul de carte cu ID-ul specificat înapoi în secțiunea de răspuns a Poștașului. Observați că mai devreme, cu Ruta POST, care este concepută pentru a „POST” sau „împinge” resurse noi către server, am răspuns cu un 201 Created — deoarece a fost creată o nouă resursă (sau document). În cazul GET, nu a fost creat nimic nou - doar am solicitat o resursă cu un ID specific, astfel că am primit înapoi un cod de stare 200 OK, în loc de 201 Created.
Așa cum este obișnuit în domeniul dezvoltării de software, cazurile marginale trebuie luate în considerare — inputul utilizatorului este în mod inerent nesigur și eronat și este datoria noastră, ca dezvoltatori, să fim flexibili la tipurile de input care ni se pot oferi și să le răspundem. în consecinţă. Ce facem dacă utilizatorul (sau apelantul API) ne transmite un ID care nu poate fi turnat la un ObjectID MongoDB sau un ID care poate fi turnat, dar care nu există?
Pentru primul caz, Mongoose va arunca un CastError - ceea ce este de înțeles deoarece, dacă furnizăm un ID precum math-is-fun , atunci evident că nu este ceva care poate fi turnat la un ObjectID, iar turnarea la un ObjectID este în mod special ceea ce Mangusta se descurcă sub capotă.
Pentru cel din urmă caz, am putea remedia cu ușurință problema printr-o verificare nulă sau o clauză de gardă. Oricum, voi trimite înapoi și răspunsul HTTP 404 Not Found. Îți voi arăta câteva moduri prin care putem face asta, o modalitate proastă și apoi una mai bună.
În primul rând, am putea face următoarele:
app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) throw new Error(); return res.send({ book }); } catch (e) { return res.status(404).send({ error: 'Not Found' }); } }); Funcționează și îl putem folosi foarte bine. Mă aștept ca instrucțiunea await Book.findById() să arunce un Mongoose CastError dacă șirul ID nu poate fi turnat la un ObjectID, determinând executarea blocului catch . Dacă poate fi turnat, dar ObjectID-ul corespunzător nu există, atunci book va fi null și Null Check va arunca o eroare, lansând din nou blocul catch . În interiorul catch , doar returnăm un 404. Sunt două probleme aici. În primul rând, chiar dacă Cartea este găsită, dar apare o altă eroare necunoscută, trimitem înapoi un 404 când probabil ar trebui să dăm clientului un generic catch-all 500. În al doilea rând, nu facem nicio diferență între dacă ID-ul trimis este valid, dar inexistent, sau dacă este doar un ID prost.
Deci, iată o altă modalitate:
const mongoose = require('mongoose'); app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); Lucrul frumos este că putem gestiona toate cele trei cazuri de 400, 404 și 500 generic. Observați că după verificarea nulă pe book , folosesc cuvântul cheie return în răspunsul meu. Acest lucru este foarte important pentru că vrem să ne asigurăm că ieșim de acolo de rută.
Alte opțiuni ar putea fi pentru noi să verificăm dacă id -ul de pe req.params poate fi turnat la un ObjectID în mod explicit, spre deosebire de a permite lui Mongoose să arunce implicit cu mongoose.Types.ObjectId.isValid('id); , dar există un caz marginal cu șiruri de 12 octeți care face ca uneori să funcționeze în mod neașteptat.
Am putea face respectiva repetiție mai puțin dureroasă cu Boom , o bibliotecă HTTP Response, de exemplu, sau am putea folosi Error Handling Middleware. De asemenea, am putea transforma erorile Mongoose în ceva mai lizibil cu Mongoose Hooks/Middleware așa cum este descris aici. O opțiune suplimentară ar fi definirea obiectelor de eroare personalizate și utilizarea programului global Express Error Handling Middleware, totuși, o voi păstra pentru un articol viitor în care vom discuta despre metode arhitecturale mai bune.
În punctul final pentru PATCH /books/:id , ne vom aștepta să treacă un obiect de actualizare care să conțină actualizări pentru cartea în cauză. Pentru acest articol, vom permite actualizarea tuturor câmpurilor, dar în viitor, voi arăta cum putem interzice actualizările anumitor câmpuri. În plus, veți vedea că logica de gestionare a erorilor din punctul nostru final PATCH va fi aceeași cu punctul nostru final GET. Acesta este un indiciu că încălcăm principiile DRY, dar din nou, vom aborda asta mai târziu.
Mă aștept ca toate actualizările să fie disponibile pe obiectul de updates al req.body (adică clientul va trimite JSON care conține un obiect de updates ) și va folosi funcția Book.findByAndUpdate cu un steag special pentru a efectua actualizarea.
app.patch('/books/:id', async (req, res) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); Observați câteva lucruri aici. Mai întâi destructuram id -ul din req.params și updates din req.body .
Disponibilă pe modelul Book este o funcție cu numele findByIdAndUpdate care preia ID-ul documentului în cauză, actualizările de efectuat și un obiect opțional opțional. În mod normal, Mongoose nu va reefectua validarea pentru operațiunile de actualizare, așa că runValidators: true îl transmitem pe măsură ce obiectul options îl forțează să facă acest lucru. În plus, începând cu Mongoose 4, Model.findByIdAndUpdate nu mai returnează documentul modificat, ci returnează documentul original. new: true (care este fals în mod implicit) înlocuiește acest comportament.
În cele din urmă, putem construi punctul nostru final DELETE, care este destul de similar cu toate celelalte:
app.delete('/books/:id', async (req, res) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } });Cu asta, API-ul nostru primitiv este complet și îl puteți testa făcând solicitări HTTP către toate punctele finale.
O scurtă declinare a răspunderii despre arhitectură și cum o vom rectifica
Din punct de vedere arhitectural, codul pe care îl avem aici este destul de rău, este dezordonat, nu este USCAT, nu este SOLID, de fapt, l-ai putea numi chiar detestabil. Acești așa-numiți „Manipulatori de rute” fac mult mai mult decât „predarea rutelor” – ei interacționează direct cu baza noastră de date. Asta înseamnă că nu există absolut nicio abstracție.
Să recunoaștem, majoritatea aplicațiilor nu vor fi niciodată atât de mici sau probabil că ați putea scăpa de arhitecturi fără server cu baza de date Firebase. Poate, după cum vom vedea mai târziu, utilizatorii doresc posibilitatea de a încărca avatare, citate și fragmente din cărțile lor etc. Poate dorim să adăugăm o funcție de chat live între utilizatorii cu WebSockets și să mergem chiar până la a spune că Vom deschide aplicația noastră pentru a le permite utilizatorilor să împrumute cărți între ei pentru o taxă mică – moment în care trebuie să luăm în considerare integrarea plăților cu API-ul Stripe și logistica de expediere cu API-ul Shippo.
Să presupunem că continuăm cu arhitectura noastră actuală și adăugăm toate aceste funcționalități. Aceste trasee, cunoscute și sub numele de Controller Actions, vor ajunge să fie foarte, foarte mari, cu o complexitate ciclomatică ridicată. Un astfel de stil de codare s-ar putea să ne convină bine în primele zile, dar ce se întâmplă dacă decidem că datele noastre sunt referențiale și, prin urmare, PostgreSQL este o alegere de bază de date mai bună decât MongoDB? Acum trebuie să refactorăm întreaga noastră aplicație, eliminând Mongoose, modificându-ne controlerele etc., toate acestea ar putea duce la potențiale erori în restul logicii de afaceri. Un alt astfel de exemplu ar fi acela de a decide că AWS S3 este prea scump și dorim să migrăm la GCP. Din nou, acest lucru necesită un refactor la nivel de aplicație.
Deși există multe opinii despre arhitectură, de la proiectare bazată pe domenii, segregarea responsabilității pentru interogări de comandă și aprovizionare cu evenimente, până la dezvoltare bazată pe teste, SOILD, arhitectură stratificată, arhitectură Onion și multe altele, ne vom concentra pe implementarea arhitecturii stratificate simple în articole viitoare, constând din controlere, servicii și depozite și care utilizează modele de proiectare precum Compoziție, adaptoare/învelișuri și inversarea controlului prin injecția de dependență. Deși, într-o anumită măsură, acest lucru ar putea fi oarecum realizat cu JavaScript, vom analiza opțiunile TypeScript pentru a realiza și această arhitectură, permițându-ne să folosim paradigme de programare funcțională, cum ar fi Either Monads, pe lângă conceptele OOP precum Generics.
Deocamdată, există două mici modificări pe care le putem face. Deoarece logica noastră de gestionare a erorilor este destul de similară în blocul catch al tuturor punctelor finale, o putem extrage într-o funcție personalizată Express Error Handling Middleware la sfârșitul stivei.
Ne curățăm arhitectura
În prezent, repetăm o cantitate foarte mare de logică de gestionare a erorilor în toate punctele noastre finale. În schimb, putem construi o funcție Express Error Handling Middleware, care este o funcție Express Middleware care este apelată cu o eroare, obiectele req și res și următoarea funcție.
Deocamdată, să construim acea funcție de middleware. Tot ce voi face este să repet aceeași logică de gestionare a erorilor cu care suntem obișnuiți:
app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); Acest lucru nu pare să funcționeze cu erorile Mongoose, dar, în general, în loc să utilizați if/else if/else pentru a determina instanțe de eroare, puteți comuta constructorul erorii. Totuși, voi lăsa ceea ce avem.
Într-un handler de punct final/rută sincron , dacă aruncați o eroare, Express o va prinde și o va procesa fără a fi nevoie de muncă suplimentară din partea dvs. Din păcate, nu este cazul la noi. Avem de-a face cu cod asincron . Pentru a delega gestionarea erorilor către Express cu handlere de rută asincrone, noi înșine prindem eroarea și o transmitem la next() .
Deci, voi permite doar ca next să fie al treilea argument în punctul final și voi elimina logica de gestionare a erorilor din blocurile catch în favoarea doar a trece instanța de eroare la next , ca atare:
app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { next(e) } });Dacă faceți acest lucru tuturor gestionarilor de rută, ar trebui să ajungeți cu următorul cod:
const express = require('express'); const mongoose = require('mongoose'); // Database connection and model. require('./db/mongoose.js')(); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { next(e) } }); // HTTP GET /books/:id app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { next(e); } }); // HTTP PATCH /books/:id app.patch('/books/:id', async (req, res, next) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { next(e); } }); // HTTP DELETE /books/:id app.delete('/books/:id', async (req, res, next) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { next(e); } }); // Notice - bottom of stack. app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); Mergând mai departe, ar merita să ne separăm middleware-ul de manipulare a erorilor într-un alt fișier, dar asta este banal și îl vom vedea în articolele viitoare din această serie. În plus, am putea folosi un modul NPM numit express-async-errors pentru a ne permite să nu mai trebuim să apelăm în blocul catch, dar din nou, încerc să vă arăt cum se fac lucrurile în mod oficial.
Un cuvânt despre CORS și aceeași politică de origine
Să presupunem că site-ul dvs. este deservit de domeniul myWebsite.com , dar serverul dvs. este la myOtherDomain.com/api . CORS înseamnă Cross-Origin Resource Sharing și este un mecanism prin care pot fi efectuate solicitări între domenii. În cazul de mai sus, deoarece serverul și codul JS front-end se află pe domenii diferite, ați face o solicitare din două origini diferite, care este de obicei restricționată de browser din motive de securitate și atenuată prin furnizarea de anteturi HTTP specifice.
Politica Aceeași Origine este cea care îndeplinește acele restricții menționate mai sus - un browser web va permite doar ca cerințe să fie făcute pe aceeași origine.
Vom aborda CORS și SOP mai târziu, când vom construi un pachet Webpack pentru API-ul nostru Book cu React.
Concluzie și ce urmează
Am discutat multe în acest articol. Poate că nu a fost complet practic, dar sperăm că v-a făcut să lucrați mai confortabil cu funcțiile JavaScript Express și ES6. Dacă sunteți nou în programare și Node este prima cale pe care o porniți, sperăm că referințele la limbaje cu tipuri statice precum Java, C++ și C# au ajutat la evidențierea unora dintre diferențele dintre JavaScript și omologii săi statici.
Next time, we'll finish building out our Book API by making some fixes to our current setup with regards to the Book Routes, as well as adding in User Authentication so that users can own books. We'll do all of this with a similar architecture to what I described here and with MongoDB for data persistence. Finally, we'll permit users to upload avatar images to AWS S3 via Buffers.
In the article thereafter, we'll be rebuilding our application from the ground up in TypeScript, still with Express. We'll also move to PostgreSQL with Knex instead of MongoDB with Mongoose as to depict better architectural practices. Finally, we'll update our avatar image uploading process to use Node Streams (we'll discuss Writable, Readable, Duplex, and Transform Streams). Along the way, we'll cover a great amount of design and architectural patterns and functional paradigms, including:
- Controllers/Controller Actions
- Servicii
- Repositories
- Data Mapping
- The Adapter Pattern
- The Factory Pattern
- The Delegation Pattern
- OOP Principles and Composition vs Inheritance
- Inversion of Control via Dependency Injection
- SOLID Principles
- Coding against interfaces
- Data Transfer Objects
- Domain Models and Domain Entities
- Either Monads
- Validare
- Decorators
- Logging and Logging Levels
- Unit Tests, Integration Tests (E2E), and Mutation Tests
- The Structured Query Language
- Relations
- HTTP/Express Security Best Practices
- Node Best Practices
- OWASP Security Best Practices
- Și altele.
Using that new architecture, in the article after that, we'll write Unit, Integration, and Mutation tests, aiming for close to 100 percent testing coverage, and we'll finally discuss setting up a remote CI/CD pipeline with CircleCI, as well as Message Busses, Job/Task Scheduling, and load balancing/reverse proxying.
Hopefully, this article has been helpful, and if you have any queries or concerns, let me know in the comments below.