
Analiza exploratorie a datelor în Python: Ce trebuie să știți?
Publicat: 2021-03-12Analiza exploratorie a datelor (EDA) este o practică foarte comună și importantă urmată de toți oamenii de știință de date. Este procesul de a privi tabele și tabele de date din diferite unghiuri pentru a le înțelege pe deplin. Obținerea unei bune înțelegeri a datelor ne ajută să le curățăm și să le rezumăm, care apoi scoate la iveală perspectivele și tendințele care altfel erau neclare.
EDA nu are un set de reguli stricte care să fie urmate, de exemplu, în „analiza datelor”. Oamenii care sunt noi în domeniu tind întotdeauna să confunde între cei doi termeni, care sunt în mare parte similari, dar diferiți în scopul lor. Spre deosebire de EDA, analiza datelor este mai înclinată către implementarea probabilităților și a metodelor statistice pentru a dezvălui fapte și relații între diferite variante.
Revenind, nu există nicio modalitate corectă sau greșită de a efectua EDA. Diferă de la persoană la persoană, totuși, există câteva linii directoare majore urmate în mod obișnuit, care sunt enumerate mai jos.
- Gestionarea valorilor lipsă: valorile nule pot fi văzute atunci când este posibil ca toate datele să nu fi fost disponibile sau înregistrate în timpul colectării.
- Eliminarea datelor duplicate: este important să preveniți orice supraadaptare sau părtinire creată în timpul antrenării algoritmului de învățare automată folosind înregistrări de date repetate
- Gestionarea valorilor aberante: valorile aberante sunt înregistrări care diferă drastic de restul datelor și nu urmează tendința. Poate apărea din cauza anumitor excepții sau a inexactității în timpul colectării datelor
- Scalare și normalizare: Acest lucru se face numai pentru variabilele de date numerice. De cele mai multe ori variabilele diferă foarte mult în intervalul și scara lor, ceea ce face dificilă compararea lor și găsirea corelațiilor.
- Analiza univariată și bivariată: Analiza univariată se face de obicei prin observarea modului în care o variabilă afectează variabila țintă. Analiza bivariată se efectuează între oricare 2 variabile, poate fi fie numerică, fie categorică sau ambele.
Ne vom uita la modul în care unele dintre acestea sunt implementate folosind un set de date foarte faimos „Riscul de neplată a creditului la domiciliu” disponibil pe Kaggle aici . Datele conțin informații despre solicitantul de împrumut la momentul solicitării împrumutului. Conține două tipuri de scenarii:
- Clientul cu dificultăți de plată : a avut întârziere la plată mai mare de X zile
pe cel puțin una dintre primele Y rate ale împrumutului din eșantionul nostru,
- Toate celelalte cazuri : Toate celelalte cazuri în care plata este plătită la timp.
Vom lucra doar la fișierele de date ale aplicației de dragul acestui articol.
Înrudit: Idei de proiecte și subiecte Python pentru începători
Cuprins
Privind Datele
app_data = pd.read_csv( 'application_data.csv' )
app_data.info()
După citirea datelor aplicației, folosim funcția info() pentru a obține o scurtă prezentare generală a datelor cu care ne vom ocupa. Rezultatul de mai jos ne informează că avem aproximativ 300000 de înregistrări de împrumut cu 122 de variabile. Dintre acestea, există 16 variabile categoriale, iar restul numerice.
<clasa „pandas.core.frame.DataFrame”>
RangeIndex: 307511 intrări, de la 0 la 307510
Coloane: 122 de intrări, de la SK_ID_CURR la AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: float64(65), int64(41), object(16)
utilizarea memoriei: 286,2+ MB
Este întotdeauna o practică bună să manipulați și să analizați separat datele numerice și categoriale.
categoric = app_data.select_dtypes(include = object).columns
date_aplicație[categorică].aplicare(pd.Series.nunique, axa = 0)
Privind doar caracteristicile categoriale de mai jos, vedem că majoritatea dintre ele au doar câteva categorii care le fac mai ușor de analizat folosind diagrame simple.
NAME_CONTRACT_TYPE 2
CODE_GEN 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64
Acum, pentru caracteristicile numerice, metoda describe() ne oferă statisticile datelor noastre:
numer= app_data.describe()
numeric= numer.coloane
numărul
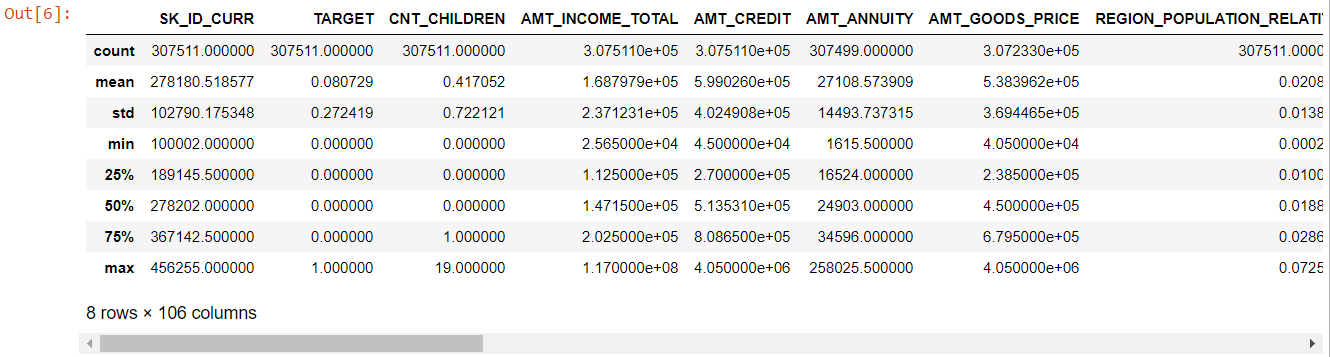
Privind întregul tabel, este evident că:
- zile_naștere este negativă: vârsta solicitantului (în zile) față de ziua depunerii cererii
- days_employed are valori aberante (valoarea maximă este de aproximativ 100 de ani) (635243)
- amt_annuity- înseamnă mult mai mică decât valoarea maximă
Deci acum știm ce caracteristici vor trebui analizate în continuare.
Date lipsa
Putem face un grafic punctual al tuturor caracteristicilor care au valori lipsă prin reprezentarea procentului de date lipsă de-a lungul axei Y.
lipsă = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.figure(figsize = (16,5))
ax = sns.pointplot('index', 0, date = lipsesc)

plt.xticks(rotație = 90, dimensiunea fontului = 7)
plt.title(„Procentul valorilor lipsă”)
plt.ylabel(„PERCENTAGE”)
plt.show()
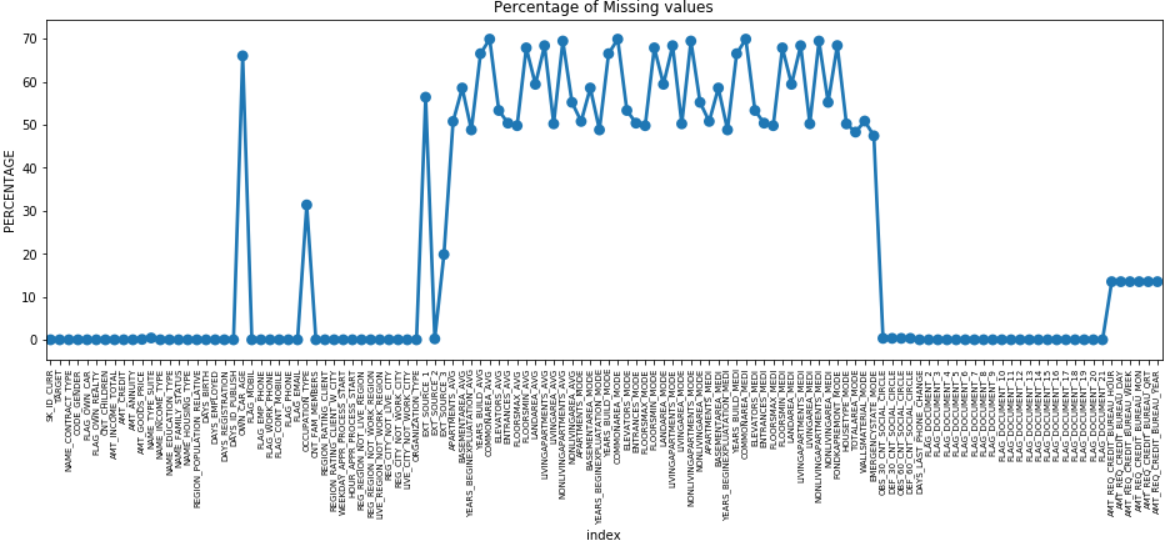
Multe coloane au multe date lipsă (30-70%), unele au puține date lipsă (13-19%) și multe coloane, de asemenea, nu au deloc date lipsă. Nu este cu adevărat necesar să modificați setul de date atunci când trebuie doar să efectuați EDA. Cu toate acestea, mergând mai departe cu preprocesarea datelor, ar trebui să știm cum să gestionăm valorile lipsă.
Pentru caracteristicile cu mai puține valori lipsă, putem folosi regresia pentru a prezice valorile lipsă sau completam cu media valorilor prezente, în funcție de caracteristică. Și pentru caracteristicile cu un număr foarte mare de valori lipsă, este mai bine să renunțați la acele coloane, deoarece oferă o perspectivă foarte mică asupra analizei.
Dezechilibru de date
În acest set de date, debitorii de credit sunt identificați folosind variabila binară „TARGET”.
100 * app_data['TARGET'].value_counts() / len(app_data['TARGET'])
0 91.927118
1 8,072882
Nume: TARGET, dtype: float64
Vedem că datele sunt foarte dezechilibrate cu un raport de 92:8. Majoritatea creditelor au fost rambursate la timp (țintă = 0). Deci, ori de câte ori există un dezechilibru atât de mare, este mai bine să luați caracteristici și să le comparați cu variabila țintă (analiza vizată) pentru a determina ce categorii din acele caracteristici tind să nu plătească împrumuturile mai mult decât altele.
Mai jos sunt doar câteva exemple de grafice care pot fi realizate folosind biblioteca seaborn de python și funcții simple definite de utilizator.
Gen
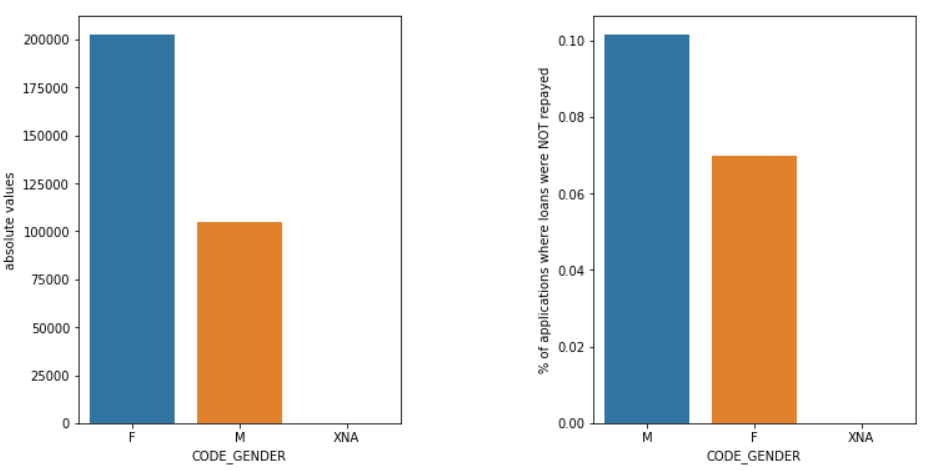
Bărbații (M) au o șansă mai mare de a rămâne fără plată în comparație cu femeile (F), chiar dacă numărul solicitanților de sex feminin este aproape de două ori mai mare. Deci, femeile sunt mai de încredere decât bărbații pentru a-și rambursa împrumuturile.
Tipul de educație
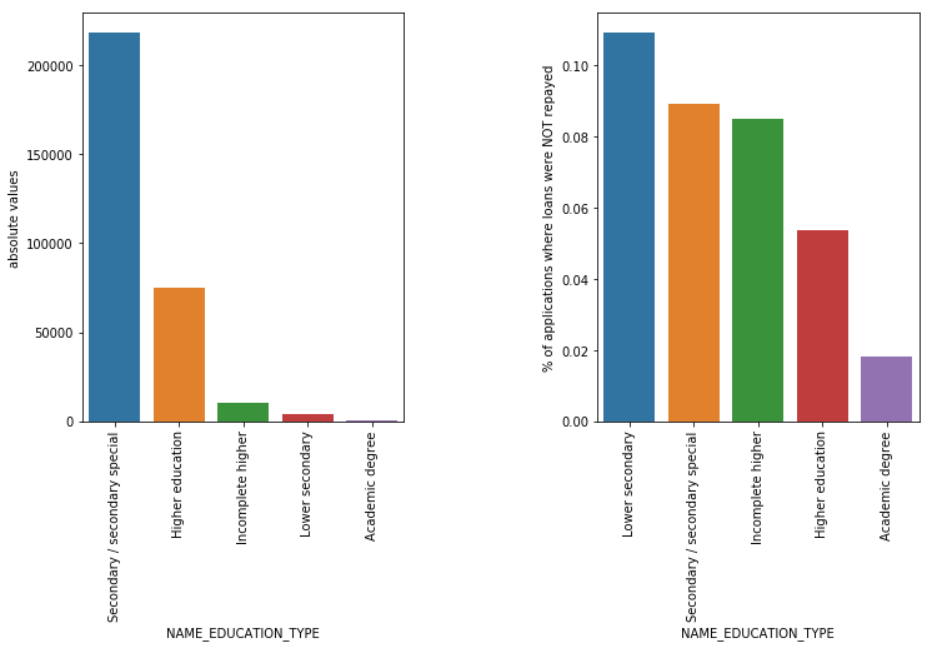
Chiar dacă majoritatea împrumuturilor pentru studenți sunt pentru studii medii sau superioare, împrumuturile pentru învățământul secundar inferior sunt cele mai riscante pentru companie, urmate de cele secundare.
Citește și: Carieră în știința datelor
Concluzie
O astfel de analiză văzută mai sus este realizată în mare măsură în analiza riscului în serviciile bancare și financiare. În acest fel, arhivele de date pot fi folosite pentru a minimiza riscul de a pierde bani în timp ce acordați împrumuturi clienților. Sfera de aplicare a EDA în toate celelalte sectoare este nesfârșită și ar trebui utilizată pe scară largă.
Dacă sunteți curios să aflați despre știința datelor, consultați PG executiv în știința datelor de la IIIT-B și upGrad, care este creat pentru profesioniști care lucrează și oferă peste 10 studii de caz și proiecte, ateliere practice practice, mentorat cu experți din industrie, 1- on-1 cu mentori din industrie, peste 400 de ore de învățare și asistență profesională cu firme de top.
Analiza exploratorie a datelor este considerată a fi nivelul inițial atunci când începeți să vă modelați datele. Aceasta este o tehnică destul de perspicace pentru a analiza cele mai bune practici pentru modelarea datelor dvs. Veți putea extrage diagrame vizuale, grafice și rapoarte din date pentru a obține o înțelegere completă a acestora. Valorile aberante se referă la anomaliile sau diferențele ușoare ale datelor dvs. Se poate întâmpla în timpul colectării datelor. Există 4 moduri prin care putem detecta un valori aberanți în setul de date. Aceste metode sunt după cum urmează: Spre deosebire de analiza datelor, nu există reguli și reglementări stricte și rapide de urmat pentru EDA. Nu se poate spune că aceasta este metoda corectă sau că este metoda greșită de a efectua EDA. Începătorii sunt adesea înțeleși greșit și se confundă între EDA și analiza datelor.De ce este necesară analiza exploratorie a datelor (EDA)?
EDA implică anumiți pași pentru a analiza complet datele, inclusiv obținerea rezultatelor statistice, găsirea valorilor datelor lipsă, gestionarea intrărilor de date defecte și, în final, deducerea diferitelor diagrame și grafice.
Scopul principal al acestei analize este de a se asigura că setul de date pe care îl utilizați este adecvat pentru a începe aplicarea algoritmilor de modelare. Acesta este motivul pentru care acesta este primul pas pe care ar trebui să-l efectuați asupra datelor dumneavoastră înainte de a trece la etapa de modelare. Ce sunt valorile aberante și cum să le gestionăm?
1. Boxplot - Boxplot este o metodă de detectare a valorii aberante în care separăm datele prin quartilele lor.
2. Scatterplot - Un scatter plot afișează datele a 2 variabile sub forma unei colecții de puncte marcate pe planul cartezian. Valoarea unei variabile reprezintă axa orizontală (x-ais), iar valoarea celeilalte variabile reprezintă axa verticală (axa y).
3. Scorul Z - În timp ce calculăm scorul Z, căutăm punctele care sunt departe de centru și le considerăm aberante.
4. InterQuartile Range (IQR) - InterQuartile Range sau IQR este diferența dintre quartilele superioare și inferioare sau a 75-a și a 25-a quartile, adesea denumită dispersie statistică. Care sunt liniile directoare pentru a efectua EDA?
Cu toate acestea, există câteva îndrumări care sunt practicate în mod obișnuit:
1. Gestionarea valorilor lipsă
2. Eliminarea datelor duplicate
3. Manipularea valorii aberante
4. Scalare și normalizare
5. Analiza univariată și bivariată