
Ce este analiza exploratorie a datelor în Python? Învață de la zero
Publicat: 2021-03-04Analiza exploratorie a datelor sau EDA, pe scurt, cuprinde aproape 70% din Data Science Project. EDA este procesul de explorare a datelor prin utilizarea diferitelor instrumente de analiză pentru a scoate statisticile inferențiale din date. Aceste explorări se fac fie prin vizualizarea numerelor simple, fie prin trasarea graficelor și diagramelor de diferite tipuri.
Fiecare grafic sau diagramă descrie o poveste diferită și un unghi față de aceleași date. Pentru cea mai mare parte a analizei și curățării datelor, Pandas este instrumentul cel mai utilizat. Pentru vizualizări și trasarea graficelor/diagramelor, sunt utilizate biblioteci de trasare precum Matplotlib, Seaborn și Plotly.
EDA este extrem de necesar să fie efectuat, deoarece face ca datele să vă mărturisească. Un Data Scientist care face un EDA foarte bun știe multe despre date și, prin urmare, modelul pe care îl vor construi va fi automat mai bun decât Data Scientist care nu face un EDA bun.
Până la sfârșitul acestui tutorial, veți ști următoarele:
- Verificarea generală de bază a datelor
- Verificarea statisticii descriptive a datelor
- Manipularea numelor de coloane și a tipurilor de date
- Gestionarea valorilor lipsă și a rândurilor duplicate
- Analiza bivariată
Cuprins
Prezentare generală de bază a datelor
Vom folosi setul de date Cars pentru acest tutorial care poate fi descărcat de la Kaggle. Primul pas pentru aproape orice set de date este să îl importați și să verificați prezentarea generală a acestuia – forma, coloanele, tipurile de coloane, primele 5 rânduri etc. Acest pas vă oferă o scurtă prezentare a datelor cu care veți lucra. Să vedem cum să facem asta în Python.
| # Importul bibliotecilor necesare importa panda ca pd import numpy ca np import seaborn ca sns #vizualizare import matplotlib.pyplot ca plt #visualisation %matplotlib inline sns.set(color_codes= True ) |
Data Head & Tail
| date = pd.read_csv( „path/dataset.csv” ) # Verificați primele 5 rânduri ale cadrului de date data.head() |
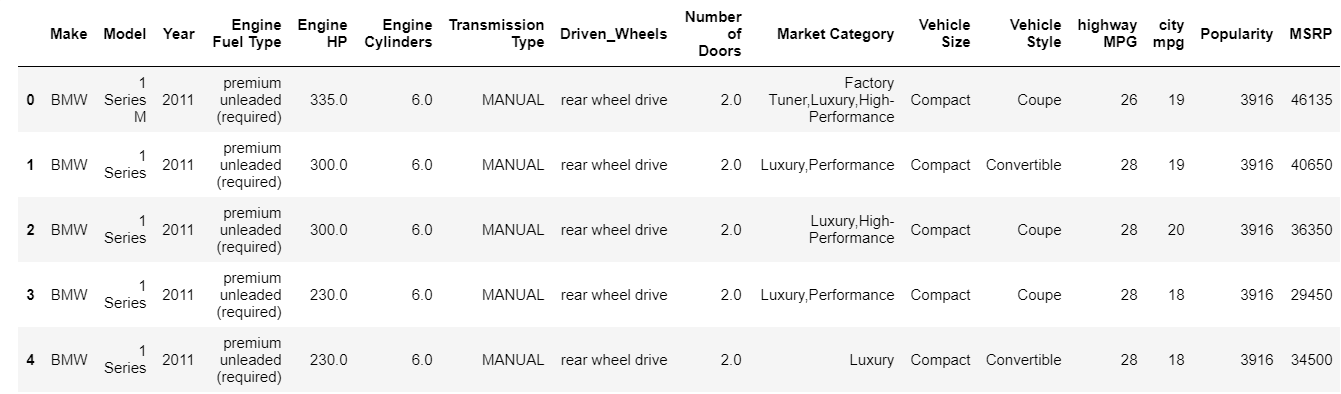
Funcția cap tipărește în mod implicit primii 5 indici ai cadrului de date. De asemenea, puteți specifica câți indici de top trebuie să vedeți ocolind acea valoare la cap. Imprimarea instantanee a capului ne oferă o privire rapidă asupra tipului de date pe care le avem, ce tip de caracteristici sunt prezente și ce valori conțin. Desigur, acest lucru nu spune întreaga poveste despre date, dar vă oferă o privire rapidă asupra datelor. Puteți imprima în mod similar partea de jos a cadrului de date utilizând funcția de coadă.
| # Imprimați ultimele 10 rânduri ale cadrului de date data.tail( 10 ) |
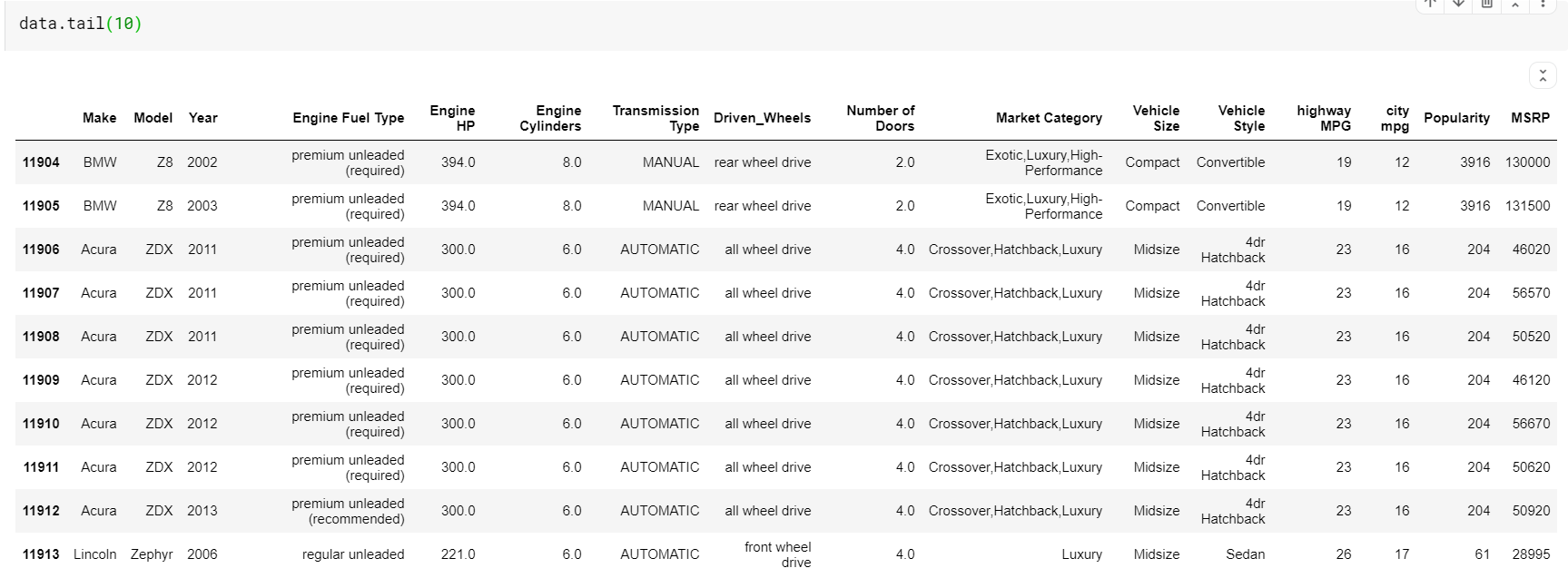
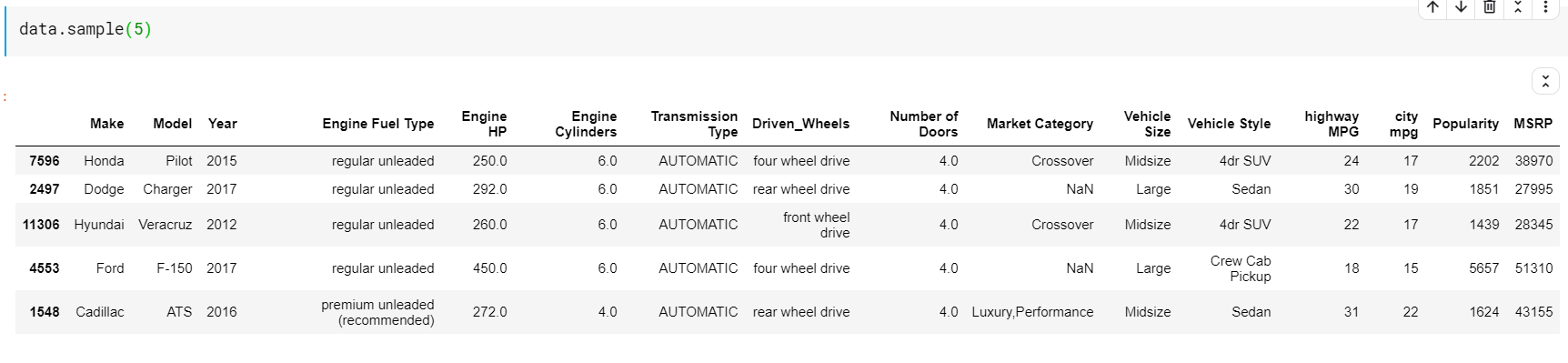
Un lucru de observat aici este că atât funcțiile-head, cât și tail ne oferă indicii de sus sau de jos. Dar rândurile de sus sau de jos nu sunt întotdeauna o previzualizare bună a datelor. Deci, puteți imprima, de asemenea, orice număr de rânduri eșantionate aleatoriu din setul de date folosind funcția sample().
| # Tipăriți 5 rânduri aleatorii date.sample( 5 ) |
Statisticile descriptive
În continuare, să verificăm statisticile descriptive ale setului de date. Statisticile descriptive constau în tot ceea ce „descrie” setul de date. Verificăm forma cadrului de date, care sunt toate coloanele prezente, care sunt toate caracteristicile numerice și categoriale. Vom vedea, de asemenea, cum să facem toate acestea în funcții simple.
Formă
| # Verificarea formei cadrului de date (mxn) # m=numărul de rânduri # n=numar de coloane date.forme |

După cum vedem, acest cadru de date conține 11914 rânduri și 16 coloane.
Coloane
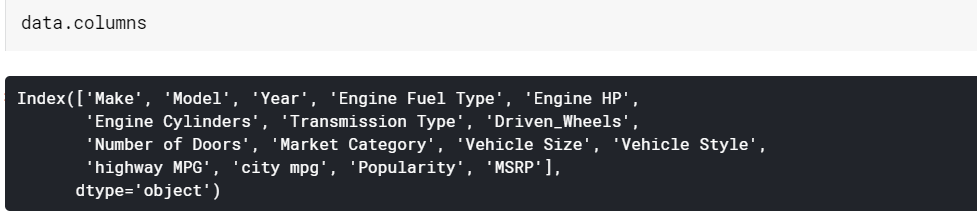
| # Tipăriți numele coloanelor date.coloane |
Informații din cadrul de date
| # Tipăriți tipurile de date coloane și numărul de valori care nu lipsesc data.info() |
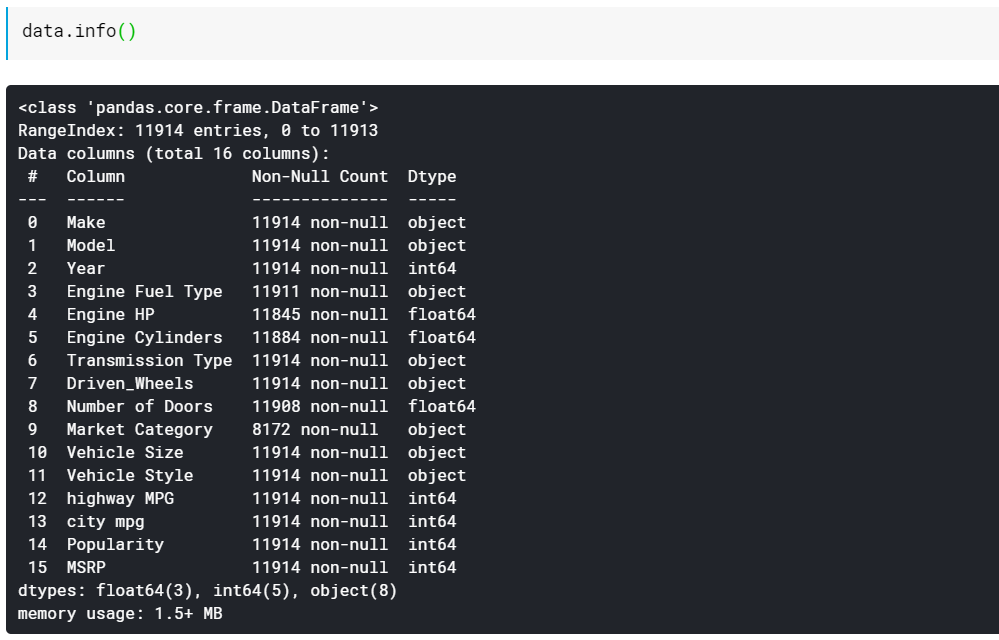
După cum vedeți, funcția info() ne oferă toate coloanele, câte valori nenule sau care nu lipsesc există în acele coloane și, în sfârșit, tipul de date al acelor coloane. Acesta este un mod rapid și frumos de a vedea care sunt toate caracteristicile numerice și ce sunt toate categorice/bazate pe text. De asemenea, acum avem informații despre valorile care lipsesc în toate coloanele. Vom analiza mai târziu cum să lucrăm cu valorile lipsă.
Manipularea numelor de coloane și a tipurilor de date
Verificarea și manipularea cu atenție a fiecărei coloane este extrem de crucială în EDA. Trebuie să vedem ce tip de conținut conține o coloană/funcție și ce a citit panda tipul de date. Tipurile de date numerice sunt în principal int64 sau float64. Caracteristicilor bazate pe text sau categoriale li se atribuie tipul de date „obiect”.
Caracteristicile bazate pe dată și oră sunt atribuite Există momente în care Pandas nu înțelege tipul de date al unei caracteristici. În astfel de cazuri, îi atribuie leneș tipul de date „obiect”. Putem specifica în mod explicit tipurile de date coloanei în timp ce citim datele cu read_csv.
Selectarea coloanelor categorice și numerice
| # Adăugați toate coloanele categoriale și numerice în liste separate categoric = data.select_dtypes( 'obiect' ).columns numeric = data.select_dtypes( 'numar' ).coloane |

Aici tipul pe care l-am trecut ca „număr” selectează toate coloanele cu tipuri de date care au orice fel de număr, fie el int64 sau float64.

Redenumirea coloanelor
| # Redenumirea numelor coloanelor data = data.rename(columns={ „Engine HP” : „HP” , „Cilindroi motor” : „Cilidri” , „Tip de transmisie” : „Transmisie” , „Driven_Wheels” : „Modul de conducere” , „Highway MPG” : „MPG-H” , „MSRP” : „Preț” }) data.head( 5 ) |

Funcția de redenumire preia doar un dicționar cu numele coloanelor care trebuie redenumite și noile lor nume.
Gestionarea valorilor lipsă și a rândurilor duplicate
Valorile lipsă sunt una dintre cele mai frecvente probleme/discrepanțe în orice set de date din viața reală. Gestionarea valorilor lipsă este în sine un subiect vast, deoarece există mai multe moduri de a face acest lucru. Unele moduri sunt moduri mai generice, iar altele sunt mai specifice setului de date cu care ar putea avea de-a face.
Verificarea valorilor lipsă
| # Verificarea valorilor lipsă data.isnull().sum() |
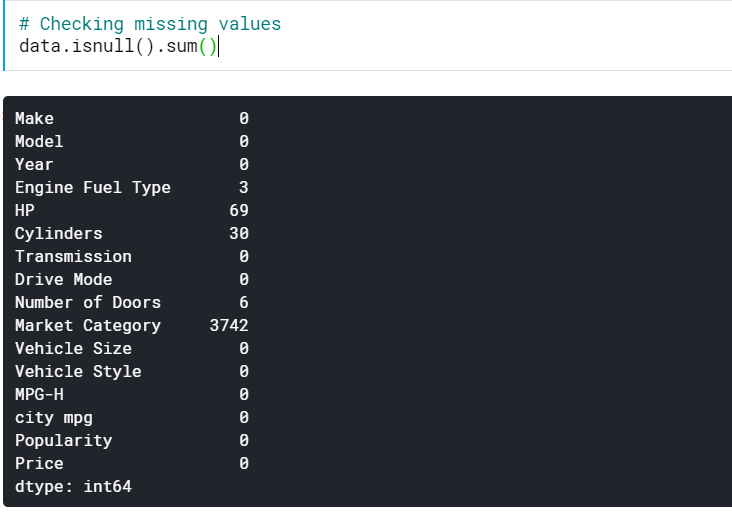
Aceasta ne oferă numărul de valori care lipsesc în toate coloanele. Putem vedea și procentul de valori care lipsesc.
| # Procent din valorile lipsă data.isnull().mean()* 100 |
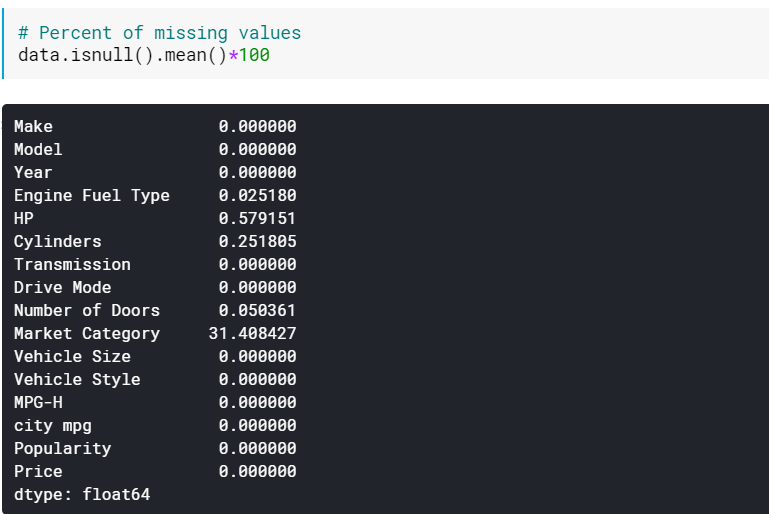
Verificarea procentelor poate fi utilă atunci când există o mulțime de coloane care au valori lipsă. În astfel de cazuri, coloanele cu multe valori lipsă (de exemplu, > 60% lipsesc) pot fi doar eliminate.
Imputarea valorilor lipsă
| #Imputarea valorilor lipsă ale coloanelor numerice prin medie data[numerical] = data[numerical].fillna(data[numerical].mean().iloc[ 0 ]) #Imputarea valorilor lipsă ale coloanelor categorice în funcție de mod data[categoric] = data[categoric].fillna(data[categoric].mode().iloc[ 0 ]) |
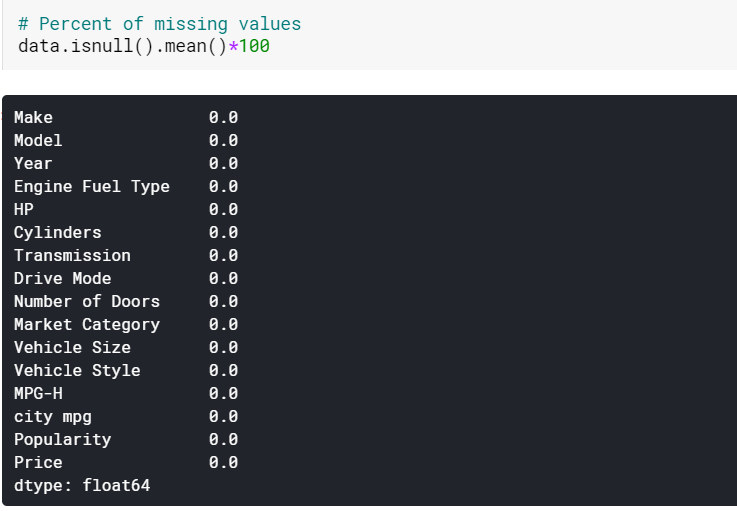
Aici imputăm pur și simplu valorile lipsă din coloanele numerice prin mijloacele respective și pe cele din coloanele categoriale după modurile lor. Și după cum putem vedea, nu există valori lipsă acum.
Vă rugăm să rețineți că acesta este cel mai primitiv mod de a imputa valorile și nu funcționează în cazurile din viața reală în care sunt dezvoltate moduri mai sofisticate, de exemplu, interpolarea, KNN etc.
Gestionarea rândurilor duplicate
| # Aruncă rândurile duplicate data.drop_duplicates(inplace= True ) |
Acest lucru scade doar rândurile duplicate.
Checkout: Idei și subiecte pentru proiecte Python
Analiza bivariată
Acum să vedem cum să obținem mai multe informații făcând analize bivariate. Bivariat înseamnă o analiză care constă din 2 variabile sau caracteristici. Există diferite tipuri de parcele disponibile pentru diferite tipuri de caracteristici.
Pentru Numeric – Numeric
- Graficul de dispersie
- Graficul de linii
- Hartă termică pentru corelații
Pentru categoric-numeric
- Diagramă cu bare
- Complot pentru vioară
- Complot roi
Pentru Categoric-Categoric
- Diagramă cu bare
- Graficul punctual
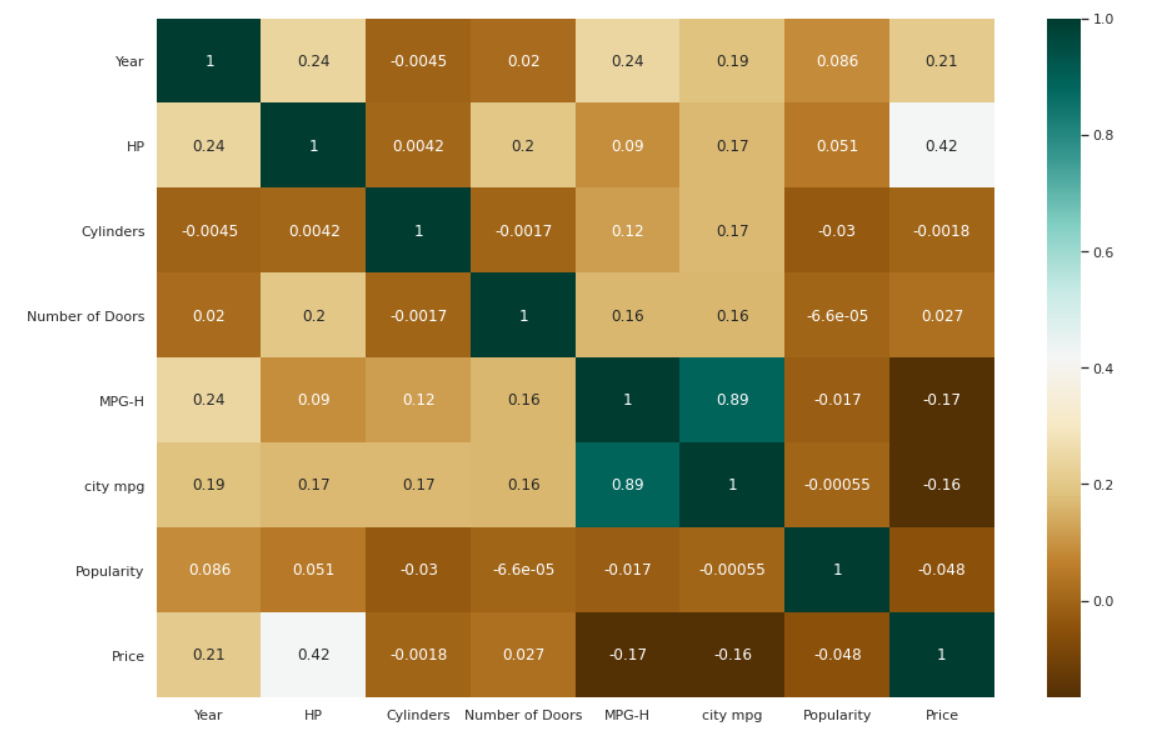
Hartă termică pentru corelații
| # Verificarea corelațiilor dintre variabile. plt.figure(figsize=( 15 , 10 )) c= data.corr() sns.heatmap(c,cmap= „BrBG” ,not= True ) |
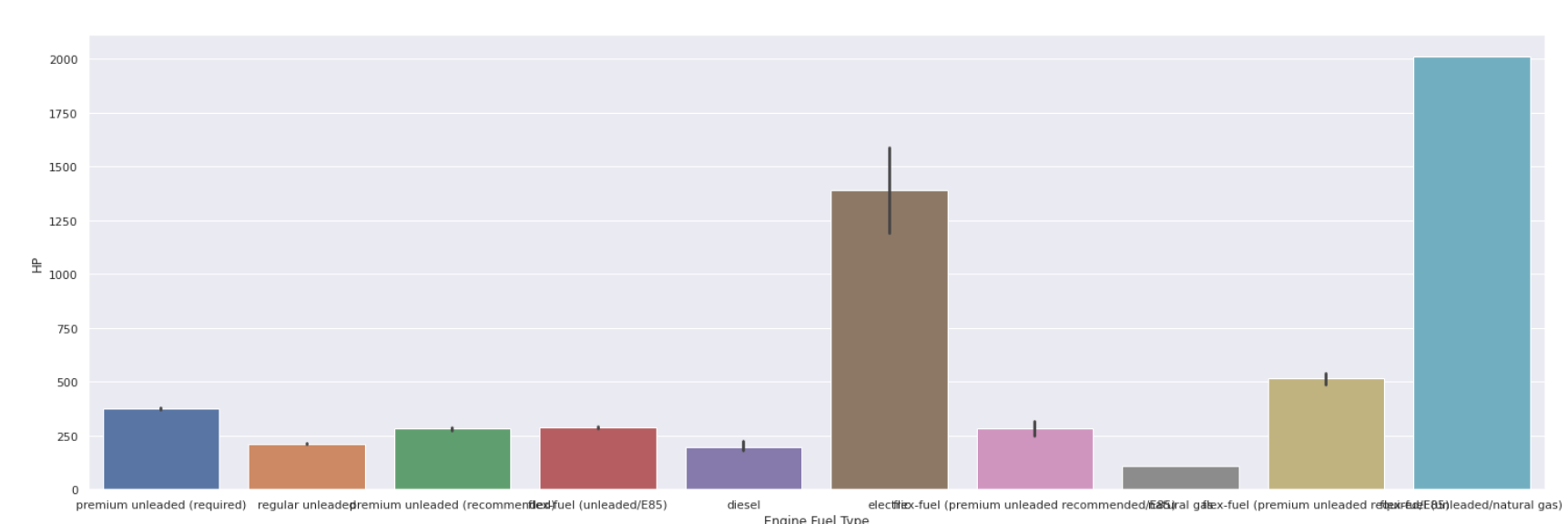
Bar Plot
| sns.barplot(data[ 'Tipul de combustibil al motorului' ], date[ 'HP' ]) |
Obțineți certificare în știința datelor de la cele mai bune universități din lume. Învață programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.
Concluzie
După cum am văzut, există o mulțime de pași care trebuie parcurși în timpul explorării unui set de date. Am acoperit doar câteva aspecte în acest tutorial, dar acest lucru vă va oferi mai mult decât cunoștințe de bază despre un EDA bun.
Dacă sunteți curios să aflați despre Python, totul despre știința datelor, consultați Diploma PG în știința datelor de la IIIT-B și upGrad, care este creată pentru profesioniști care lucrează și oferă peste 10 studii de caz și proiecte, ateliere practice practice, mentorat cu industrie experți, 1-la-1 cu mentori din industrie, peste 400 de ore de învățare și asistență la locul de muncă cu firme de top.
Care sunt etapele analizei exploratorii a datelor?
Principalii pași pe care trebuie să îi efectuați pentru a efectua analiza exploratorie a datelor sunt:
Trebuie identificate variabilele și tipurile de date.
Analiza metricilor fundamentale
Analiză negrafică univariată
Analiza grafică univariată
Analiza datelor bivariate
Transformări care sunt variabile
Tratament pentru valoarea lipsă
Tratamentul valorilor aberante
Analiza corelației
Reducerea dimensionalității
Care este scopul analizei exploratorii a datelor?
Scopul principal al EDA este de a ajuta la analiza datelor înainte de a face ipoteze. Poate ajuta la detectarea erorilor evidente, precum și la o mai bună înțelegere a tiparelor de date, la detectarea valorii aberante sau a evenimentelor neobișnuite și la descoperirea unor relații interesante între variabile.
Analiza exploratorie poate fi folosită de oamenii de știință ai datelor pentru a garanta că rezultatele pe care le creează sunt exacte și adecvate oricăror rezultate și obiective de afaceri vizate. EDA ajută, de asemenea, părțile interesate, asigurându-se că abordează întrebările adecvate. Deviațiile standard, datele categorice și intervalele de încredere pot fi răspunse cu EDA. După finalizarea EDA și extragerea de informații, caracteristicile sale pot fi aplicate la analiza sau modelarea mai avansată a datelor, inclusiv învățarea automată.
Care sunt diferitele tipuri de analiză exploratorie a datelor?
Există două tipuri de tehnici EDA: grafice și cantitative (non-grafice). Abordarea cantitativă, pe de altă parte, necesită compilarea de statistici rezumative, în timp ce metodele grafice presupun colectarea datelor într-o manieră schematică sau vizuală. Abordările univariate și multivariate sunt subseturi ale acestor două tipuri de metodologii.
Pentru a investiga relațiile, abordările univariate se uită la o variabilă (coloana de date) la un moment dat, în timp ce metodele multivariate se uită la două sau mai multe variabile simultan. Graficele și non-grafice univariate și multivariate sunt cele patru forme de EDA. Procedurile cantitative sunt mai obiective, în timp ce metodele picturale sunt mai subiective.