
Ghidul pentru răzuirea etică a site-urilor web dinamice cu Node.js și Puppeteer
Publicat: 2022-03-10Să începem cu o mică secțiune despre ce înseamnă de fapt web scraping. Cu toții folosim web scraping în viața de zi cu zi. Descrie doar procesul de extragere a informațiilor de pe un site web. Prin urmare, dacă copiați și lipiți o rețetă a preparatului preferat cu tăiței de pe internet în caietul dvs. personal, efectuați răzuire pe web .
Când folosim acest termen în industria software, de obicei ne referim la automatizarea acestei sarcini manuale prin utilizarea unui software. Rămânând la exemplul nostru anterior de „mâncăr cu tăiței”, acest proces implică de obicei doi pași:
- Preluarea paginii
Mai întâi trebuie să descarcăm pagina în întregime. Acest pas este ca și cum ai deschide pagina în browser-ul tău web atunci când o faci manual. - Analizarea datelor
Acum, trebuie să extragem rețeta în HTML-ul site-ului web și să o convertim într-un format care poate fi citit de mașină, cum ar fi JSON sau XML.
În trecut, am lucrat pentru multe companii ca consultant de date. Am fost uimit să văd câte extrageri de date, agregare și activități de îmbogățire sunt încă efectuate manual, deși ar putea fi automatizate cu ușurință cu doar câteva linii de cod. Acesta este exact ceea ce înseamnă pentru mine web scraping: extragerea și normalizarea unor informații valoroase de pe un site web pentru a alimenta un alt proces de afaceri care generează valoare.
În acest timp, am văzut companii folosind web scraping pentru tot felul de cazuri de utilizare. Firmele de investiții s-au concentrat în primul rând pe colectarea de date alternative, cum ar fi recenzii despre produse , informații despre prețuri sau postări pe rețelele sociale pentru a-și susține investițiile financiare.
Iată un exemplu. Un client m-a abordat pentru a culege datele despre recenzii despre produse pentru o listă extinsă de produse de pe mai multe site-uri web de comerț electronic, inclusiv evaluarea, locația recenzentului și textul recenziei pentru fiecare recenzie trimisă. Datele rezultate au permis clientului să identifice tendințele privind popularitatea produsului pe diferite piețe. Acesta este un exemplu excelent al modului în care o singură informație aparent „inutilă” poate deveni valoroasă în comparație cu o cantitate mai mare.
Alte companii își accelerează procesul de vânzări folosind web scraping pentru generarea de clienți potențiali. Acest proces implică de obicei extragerea de informații de contact, cum ar fi numărul de telefon, adresa de e-mail și numele de contact pentru o anumită listă de site-uri web. Automatizarea acestei sarcini oferă echipelor de vânzări mai mult timp pentru abordarea potențialilor. Prin urmare, eficiența procesului de vânzare crește.
Respectați regulile
În general, scraping-ul web a datelor disponibile public este legal, așa cum este confirmat de jurisdicția cazului Linkedin vs. HiQ. Cu toate acestea, mi-am stabilit un set etic de reguli pe care îmi place să le respect atunci când încep un nou proiect de web scraping. Aceasta include:
- Verificarea fișierului robots.txt.
De obicei, conține informații clare despre ce părți ale site-ului proprietarul paginii poate fi accesată de roboți și scrapers și evidențiază secțiunile care nu ar trebui accesate. - Citirea termenilor și condițiilor.
În comparație cu robots.txt, această informație nu este disponibilă mai rar, dar de obicei precizează modul în care tratează datele scrapers. - Razuire cu viteza moderata.
Scrapingul creează încărcare de server pe infrastructura site-ului țintă. În funcție de ceea ce scrapeți și la ce nivel de concurență funcționează scraperul dvs., traficul poate cauza probleme pentru infrastructura de server a site-ului țintă. Desigur, capacitatea serverului joacă un rol important în această ecuație. Prin urmare, viteza scraper-ului meu este întotdeauna un echilibru între cantitatea de date pe care intenționez să o scraper și popularitatea site-ului țintă. Găsirea acestui echilibru poate fi atinsă răspunzând la o singură întrebare: „Viteza planificată va schimba semnificativ traficul organic al site-ului?”. În cazurile în care nu sunt sigur de volumul de trafic natural al unui site, folosesc instrumente precum ahrefs pentru a-mi face o idee aproximativă.
Alegerea tehnologiei potrivite
De fapt, scraping cu un browser fără cap este una dintre cele mai puțin performante tehnologii pe care le poți folosi, deoarece are un impact puternic asupra infrastructurii tale. Un nucleu din procesorul mașinii dvs. poate gestiona aproximativ o instanță Chrome.
Să facem un exemplu rapid de calcul pentru a vedea ce înseamnă acest lucru pentru un proiect de web scraping din lumea reală.
Scenariu
- Vrei să răzuiești 20.000 de adrese URL.
- Timpul mediu de răspuns de la site-ul țintă este de 6 secunde.
- Serverul dvs. are 2 nuclee CPU.
Finalizarea proiectului va dura 16 ore .
Prin urmare, încerc întotdeauna să evit să folosesc un browser atunci când efectuez un test de fezabilitate de scraping pentru un site web dinamic.
Iată o mică listă de verificare pe care o parcurg mereu:
- Pot forța starea necesară a paginii prin parametrii GET din URL? Dacă da, pur și simplu putem rula o solicitare HTTP cu parametrii atașați.
- Informațiile dinamice fac parte din sursa paginii și sunt disponibile printr-un obiect JavaScript undeva în DOM? Dacă da, putem folosi din nou o solicitare HTTP normală și putem analiza datele din obiectul stringificat.
- Sunt datele preluate printr-o solicitare XHR? Dacă da, pot accesa direct punctul final cu un client HTTP? Dacă da, putem trimite o solicitare HTTP direct la punctul final. De multe ori, răspunsul este chiar formatat în JSON, ceea ce ne face viața mult mai ușoară.
Dacă la toate întrebările se răspunde cu un „Nu”, oficial rămânem fără opțiuni fezabile pentru utilizarea unui client HTTP. Desigur, ar putea exista mai multe modificări specifice site-ului pe care le-am putea încerca, dar, de obicei, timpul necesar pentru a le descoperi este prea mare, în comparație cu performanța mai lentă a unui browser fără cap. Frumusețea răzuirii cu un browser este că puteți răzui orice lucru care face obiectul următoarei reguli de bază:
Dacă îl puteți accesa cu un browser, îl puteți răzui.
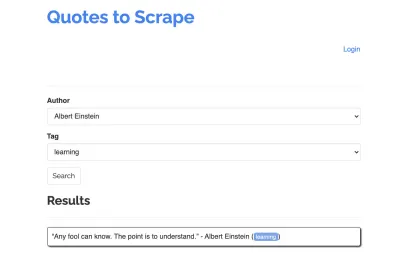
Să luăm următorul site ca exemplu pentru scraperul nostru: https://quotes.toscrape.com/search.aspx. Conține citate dintr-o listă de autori dați pentru o listă de subiecte. Toate datele sunt preluate prin XHR.
Cine s-a uitat atent la funcționarea site-ului și a trecut prin lista de verificare de mai sus și-a dat seama probabil că ghilimele ar putea fi de fapt răzuite folosind un client HTTP, deoarece pot fi preluate făcând o solicitare POST direct pe punctul final de ghilimele. Dar, deoarece acest tutorial ar trebui să acopere cum să răzuiți un site web folosind Puppeteer, ne vom preface că acest lucru a fost imposibil.
Cerințe preliminare de instalare
Deoarece vom construi totul folosind Node.js, mai întâi să creăm și să deschidem un folder nou și să creăm un nou proiect Node în interior, rulând următoarea comandă:
mkdir js-webscraper cd js-webscraper npm initVă rugăm să vă asigurați că ați instalat deja npm. Instalatorul ne va pune câteva întrebări despre metainformații despre acest proiect, pe care le putem sări cu toții, apăsând Enter .
Instalarea Puppeteer
Am mai vorbit despre scraping cu un browser. Puppeteer este un API Node.js care ne permite să vorbim cu o instanță Chrome fără cap în mod programatic.
Să-l instalăm folosind npm:
npm install puppeteerConstruirea Screperului nostru
Acum, să începem să construim scraper-ul nostru creând un fișier nou, numit scraper.js .
Mai întâi, importăm biblioteca instalată anterior, Puppeteer:
const puppeteer = require('puppeteer');Ca pas următor, îi spunem lui Puppeteer să deschidă o nouă instanță de browser într-o funcție asincronă și auto-executivă:
(async function scrape() { const browser = await puppeteer.launch({ headless: false }); // scraping logic comes here… })();Notă : În mod implicit, modul fără cap este dezactivat, deoarece aceasta crește performanța. Cu toate acestea, când construiesc o nouă racletă, îmi place să dezactivez modul fără cap. Acest lucru ne permite să urmărim procesul prin care trece browserul și să vedem tot conținutul redat. Acest lucru ne va ajuta să ne depanăm scriptul mai târziu.
În interiorul browserului nostru deschis, acum deschidem o nouă pagină și ne direcționăm către adresa URL țintă:
const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); Ca parte a funcției asincrone, vom folosi instrucțiunea await pentru a aștepta ca următoarea comandă să fie executată înainte de a continua cu următoarea linie de cod.
Acum că am deschis cu succes o fereastră de browser și am navigat la pagină, trebuie să creăm starea site-ului web , astfel încât informațiile dorite să devină vizibile pentru răzuire.
Subiectele disponibile sunt generate dinamic pentru un autor selectat. Prin urmare, vom selecta mai întâi „Albert Einstein” și vom aștepta lista generată de subiecte. Odată ce lista a fost complet generată, selectăm „învățare” ca subiect și o selectăm ca al doilea parametru de formular. Apoi facem clic pe trimite și extragem citatele preluate din containerul care conține rezultatele.

Deoarece acum vom converti acest lucru în logica JavaScript, să facem mai întâi o listă cu toți selectorii de elemente despre care am vorbit în paragraful anterior:
| Câmp de selectare a autorului | #author |
| Câmp de selectare a etichetei | #tag |
| Buton de trimitere | input[type="submit"] |
| Container de citate | .quote |
Înainte de a începe să interacționăm cu pagina, ne vom asigura că toate elementele pe care le vom accesa sunt vizibile, adăugând următoarele rânduri la scriptul nostru:
await page.waitForSelector('#author'); await page.waitForSelector('#tag');În continuare, vom selecta valori pentru cele două câmpuri selectate:
await page.select('select#author', 'Albert Einstein'); await page.select('select#tag', 'learning');Acum suntem gata să efectuăm căutarea apăsând butonul „Căutare” de pe pagină și așteptând să apară ghilimele:
await page.click('.btn'); await page.waitForSelector('.quote'); Deoarece acum vom accesa structura DOM HTML a paginii, apelăm funcția page.evaluate() furnizată, selectând containerul care conține ghilimele (în acest caz este doar unul). Apoi construim un obiect și definim null ca valoare de rezervă pentru fiecare parametru de object :
let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, }; }); return quotes; });Putem face toate rezultatele vizibile în consola noastră, înregistrându-le:
console.log(quotes);În cele din urmă, să închidem browserul și să adăugăm o declarație catch:
await browser.close();Racleta completă arată astfel:
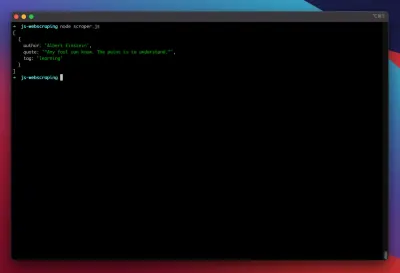
const puppeteer = require('puppeteer'); (async function scrape() { const browser = await puppeteer.launch({ headless: false }); const page = await browser.newPage(); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('#author'); await page.select('#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); // logging results console.log(quotes); await browser.close(); })();Să încercăm să rulăm racleta noastră cu:
node scraper.jsȘi iată-ne! Scraperul returnează obiectul nostru citat așa cum era de așteptat:
Optimizări avansate
Racleta noastră de bază funcționează acum. Să adăugăm câteva îmbunătățiri pentru a-l pregăti pentru niște sarcini mai serioase de răzuire.
Setarea unui User-Agent
În mod implicit, Puppeteer utilizează un user-agent care conține șirul HeadlessChrome . Destul de multe site-uri web caută acest tip de semnătură și blochează cererile primite cu o semnătură ca aceea. Pentru a evita ca acesta să fie un motiv potențial pentru care scraperul să eșueze, am setat întotdeauna un user-agent personalizat adăugând următoarea linie la codul nostru:
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36');Acest lucru ar putea fi îmbunătățit și mai mult prin alegerea unui user-agent aleatoriu cu fiecare solicitare dintr-o serie de primii 5 utilizatori-agenti cei mai obișnuiți. O listă cu cei mai obișnuiți agenți de utilizator poate fi găsită într-o bucată despre cei mai obișnuiți agenți de utilizator.
Implementarea unui proxy
Puppeteer face conectarea la un proxy foarte ușoară, deoarece adresa proxy poate fi transmisă lui Puppeteer la lansare, astfel:
const browser = await puppeteer.launch({ headless: false, args: [ '--proxy-server=<PROXY-ADDRESS>' ] });sslproxies oferă o listă mare de proxy-uri gratuite pe care le puteți utiliza. Alternativ, pot fi utilizate servicii de rotație proxy. Deoarece proxy-urile sunt de obicei partajate între mulți clienți (sau utilizatori gratuiti în acest caz), conexiunea devine mult mai nesigură decât este deja în circumstanțe normale. Acesta este momentul perfect pentru a vorbi despre gestionarea erorilor și gestionarea reîncercării.
Eroare și reîncercați-Management
O mulțime de factori pot cauza defectarea racletei. Prin urmare, este important să gestionați erorile și să decideți ce ar trebui să se întâmple în cazul unei defecțiuni. Deoarece ne-am conectat scraperul la un proxy și ne așteptăm ca conexiunea să fie instabilă (mai ales pentru că folosim proxy-uri gratuite), vrem să încercăm din nou de patru ori înainte de a renunța.
De asemenea, nu are rost să reîncercați din nou o solicitare cu aceeași adresă IP dacă anterior a eșuat. Prin urmare, vom construi un mic sistem de rotație proxy .
În primul rând, creăm două variabile noi:
let retry = 0; let maxRetries = 5; De fiecare dată când rulăm funcția scrape() , vom crește variabila de reîncercare cu 1. Apoi împachetăm logica noastră completă de scraping cu o instrucțiune try and catch, astfel încât să putem gestiona erorile. Gestionarea reîncercării are loc în cadrul funcției noastre catch :
Instanța anterioară a browserului va fi închisă, iar dacă variabila noastră maxRetries este mai mică decât variabila maxRetries, funcția scrape este apelată recursiv.
Screperul nostru va arăta acum astfel:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); … // our scraping logic } catch(e) { console.log(e); await browser.close(); if (retry < maxRetries) { scrape(); } };Acum, să adăugăm rotatorul proxy menționat anterior.
Să creăm mai întâi o matrice care să conțină o listă de proxy:
let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ];Acum, alegeți o valoare aleatorie din matrice:
var proxy = proxyList[Math.floor(Math.random() * proxyList.length)];Acum putem rula proxy-ul generat dinamic împreună cu instanța noastră Puppeteer:
const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] });Desigur, acest rotator de proxy ar putea fi optimizat în continuare pentru a semnala proxy-uri morți și așa mai departe, dar acest lucru ar depăși cu siguranță scopul acestui tutorial.
Acesta este codul scraperului nostru (inclusiv toate îmbunătățirile):
const puppeteer = require('puppeteer'); // starting Puppeteer let retry = 0; let maxRetries = 5; (async function scrape() { retry++; let proxyList = [ '202.131.234.142:39330', '45.235.216.112:8080', '129.146.249.135:80', '148.251.20.79' ]; var proxy = proxyList[Math.floor(Math.random() * proxyList.length)]; console.log('proxy: ' + proxy); const browser = await puppeteer.launch({ headless: false, args: ['--proxy-server=' + proxy] }); try { const page = await browser.newPage(); await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4298.0 Safari/537.36'); await page.goto('https://quotes.toscrape.com/search.aspx'); await page.waitForSelector('select#author'); await page.select('select#author', 'Albert Einstein'); await page.waitForSelector('#tag'); await page.select('select#tag', 'learning'); await page.click('.btn'); await page.waitForSelector('.quote'); // extracting information from code let quotes = await page.evaluate(() => { let quotesElement = document.body.querySelectorAll('.quote'); let quotes = Object.values(quotesElement).map(x => { return { author: x.querySelector('.author').textContent ?? null, quote: x.querySelector('.content').textContent ?? null, tag: x.querySelector('.tag').textContent ?? null, } }); return quotes; }); console.log(quotes); await browser.close(); } catch (e) { await browser.close(); if (retry < maxRetries) { scrape(); } } })();Voila! Rularea răzuitorului în interiorul terminalului nostru va returna ghilimele.
Dramaturgul ca alternativă la păpușar
Puppeteer a fost dezvoltat de Google. La începutul anului 2020, Microsoft a lansat o alternativă numită Playwright. Microsoft a vânat o mulțime de ingineri din echipa Puppeteer-Team. Prin urmare, Playwright a fost dezvoltat de o mulțime de ingineri care au pus deja mâna să lucreze la Puppeteer. Pe lângă faptul că este noul copil de pe blog, cel mai mare punct de diferențiere al lui Playwright este suportul între browsere, deoarece acceptă Chromium, Firefox și WebKit (Safari).
Testele de performanță (cum ar fi cel realizat de Checkly) arată că Puppeteer oferă în general o performanță cu aproximativ 30% mai bună, în comparație cu Playwright, care se potrivește cu propria mea experiență – cel puțin la momentul scrierii.
Alte diferențe, cum ar fi faptul că puteți rula mai multe dispozitive cu o singură instanță de browser, nu sunt cu adevărat valoroase pentru contextul web scraping.
Resurse și link-uri suplimentare
- Documentația păpușarului
- Învățând păpușar și dramaturg
- Web Scraping cu Javascript de Zenscrape
- Cei mai comuni utilizatori-agenti
- Păpușar vs. Dramaturg