
Vizualizarea datelor în Python: diagrame fundamentale explicate [cu ilustrație grafică]
Publicat: 2021-02-08Cuprins
Principii de bază de proiectare
Pentru orice cercetător de date aspirant sau de succes, a putea explica cercetarea și analiza dumneavoastră este o abilitate foarte importantă și utilă de posedat. Aici intervine vizualizarea datelor. Este vital să folosiți acest instrument cu onestitate, deoarece publicul poate fi foarte ușor dezinformat sau înșelat de alegerile proaste de design.
Ca oameni de știință ai datelor, cu toții avem anumite obligații în materie de păstrare a ceea ce este adevărat.
Primul este că ar trebui să fim complet sinceri cu noi înșine în timp ce curățăm și rezumăm datele. Preprocesarea datelor este un pas foarte crucial pentru ca orice algoritm de învățare automată să funcționeze și, prin urmare, orice necinste a datelor va duce la rezultate drastic diferite.
O altă obligație este față de publicul nostru țintă. Există diferite tehnici de vizualizare a datelor care sunt folosite pentru a evidenția anumite secțiuni de date și pentru a face unele alte părți de date mai puțin proeminente. Deci, dacă nu suntem suficient de atenți, cititorul nu va putea explora și judeca corect analiza, ceea ce poate duce la îndoieli și la lipsă de încredere.
Să te întrebi mereu pe tine însuți este o trăsătură bună pentru oamenii de știință ai datelor. Și ar trebui să ne gândim întotdeauna la cum să arătăm ceea ce contează cu adevărat într-un mod ușor de înțeles și plăcut din punct de vedere estetic, amintindu-ne totodată că contextul este important.
Este exact ceea ce Alberto Cairo încearcă să înfățișeze în învățăturile sale. El menționează Cele Cinci Calități ale Marilor Vizualizări: frumoase, iluminatoare, funcționale, perspicace și veridice, care merită reținute.
Câteva comploturi fundamentale
Acum că avem o înțelegere de bază a principiilor de proiectare, să ne aruncăm în câteva tehnici fundamentale de vizualizare folosind biblioteca matplotlib în python.
Tot codul de mai jos poate fi executat într-un notebook Jupyter.
Notebook %matplotlib
# aceasta oferă un mediu interactiv și stabilește back end. ( %matplotlib inline poate fi, de asemenea, utilizat, dar nu este interactiv. Aceasta înseamnă că orice apeluri suplimentare la funcțiile de plotare nu vor actualiza automat vizualizarea noastră originală.)
import matplotlib.pyplot ca plt # import modulul de bibliotecă necesar
Punct Plots
Cea mai simplă funcție matplotlib pentru a reprezenta un punct este plot() . Argumentele reprezintă coordonatele X și Y, apoi o valoare șir care descrie modul în care ar trebui să fie afișate datele de ieșire.
plt.figure()
plt.plot( 5, 6, '+' ) # semnul + acţionează ca un marker
Scatterplots
Un grafic de dispersie este un grafic bidimensional. Funcția scatter() ia, de asemenea, valoarea X ca prim argument și valoarea Y ca al doilea. Graficul de mai jos este o linie diagonală și matplotlib ajustează automat dimensiunea ambelor axe. Aici, diagrama de dispersie nu tratează elementele ca pe o serie. Deci, putem oferi și o listă de culori dorite corespunzătoare fiecărui punct.
import numpy ca np
x = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
y = x
plt.figure()
plt.scatter(x, y)
Grafice de linii
Un grafic de linii este creat cu funcția plot() și reprezintă un număr de serii diferite de puncte de date, cum ar fi un grafic de dispersie, dar conectează fiecare serie de puncte cu o linie.
import numpy ca np
date_liniare = np.array( [1, 2, 3, 4, 5, 6, 7, 8] )
date_patrate = date_liniare**2
plt.figure()
plt.plot(linear_data, '-o', squared_data, '-o')
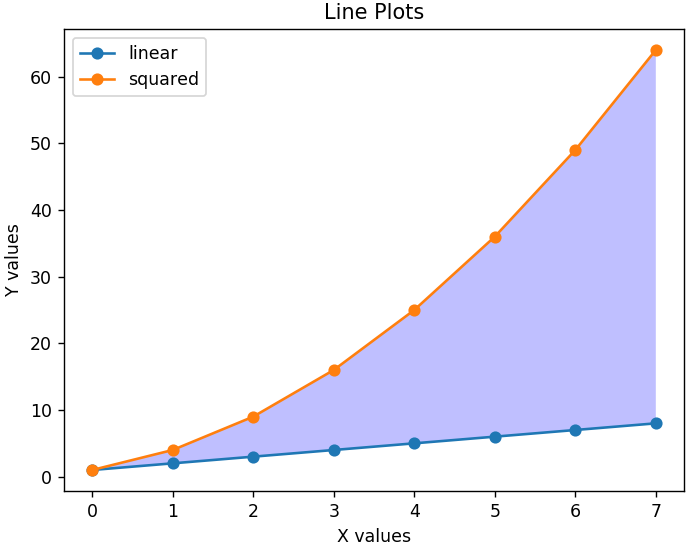
Pentru a face graficul mai lizibil, putem adăuga și o legendă care ne va spune ce reprezintă fiecare linie. Un titlu potrivit pentru grafic și pentru ambele axe este important. De asemenea, orice secțiune a graficului poate fi umbrită folosind funcția fill_between() pentru a evidenția regiunile relevante.
plt.xlabel('Valori X')
plt.ylabel('Valori Y')
plt.title('Trame cu linii')

plt.legend(['liniar', 'pătrat'] )
plt.gca().fill_between( interval ( len (linear_data ) ), linear_data, squared_data, facecolor = „albastru”, alfa = 0,25)
Așa arată graficul modificat -
Grafice de bare
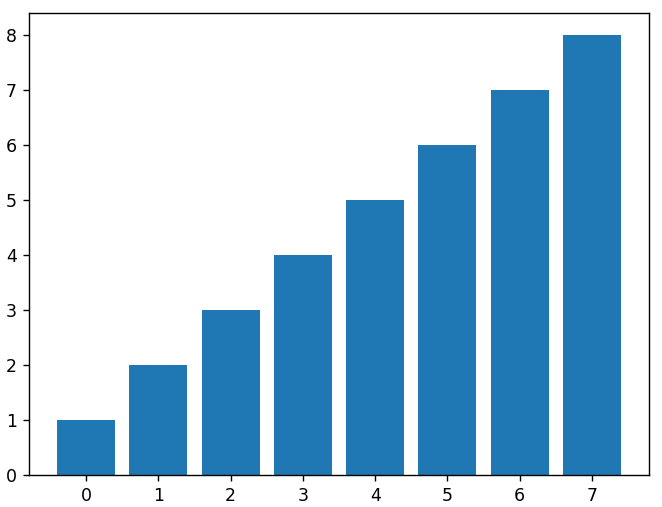
Putem trasa o diagramă cu bare trimițând argumente pentru valorile X și înălțimea fiecărei bare la funcția bar() . Mai jos este o diagramă cu bare a aceleiași matrice de date liniare pe care am folosit-o mai sus.
plt.figure()
x = interval (len (linear_data))
plt.bar( x, date_liniare)
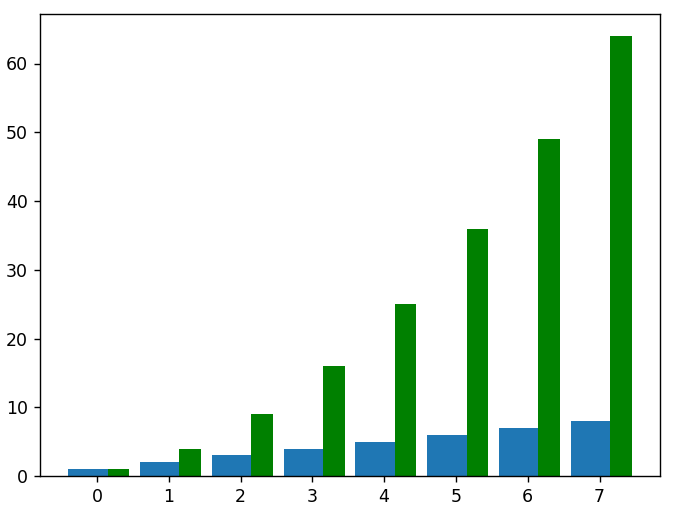
# pentru a trasa datele pătrate ca un alt set de bare pe același grafic, trebuie să ajustam noile valori x pentru a compensa primul set de bare
new_x = []
pentru datele din x:
new_x.append(data+0.3)
plt.bar(new_x, squared_data, lățime = 0,3, culoare = „verde”)
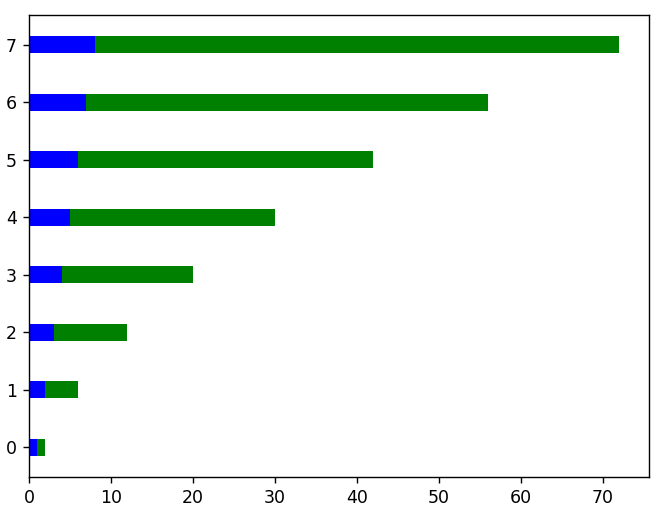
# Pentru graficele cu orientare orizontală folosim funcția barh () .
plt.figure()
x = interval(len(linear_data))
plt.barh( x, date_liniare, înălțime = 0,3, culoare = „b”)
plt.barh( x, date_pătrate, înălțime = 0,3, stânga = date_liniare, culoare = „g”)
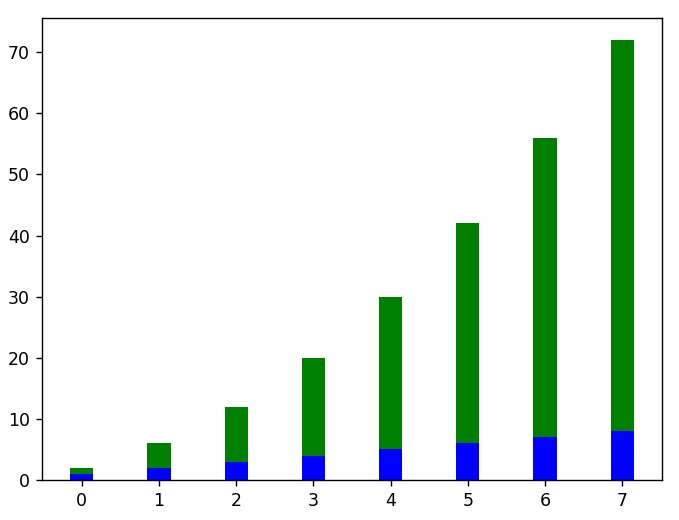
#iată un exemplu de stivuire verticală a graficelor cu bare
plt.figure()
x = interval(len(linear_data))
plt.bar( x, date_liniare, lățime = 0,3, culoare = „b”)
plt.bar( x, squared_data, width = 0,3, bottom = linear_data, culoare = 'g')
Învață cursuri de știință a datelor de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.
Concluzie
Tipurile de vizualizare nu se termină doar aici. Python are, de asemenea, o bibliotecă grozavă numită seaborn , care merită cu siguranță explorată. Vizualizarea corectă a informațiilor ajută foarte mult la creșterea valorii datelor noastre. Vizualizarea datelor va fi întotdeauna opțiunea mai bună pentru obținerea de informații și identificarea diferitelor tendințe și modele, mai degrabă decât să căutați prin tabele plictisitoare cu milioane de înregistrări.
Dacă sunteți curios să aflați despre știința datelor, consultați Diploma PG în știința datelor de la IIIT-B și upGrad, care este creată pentru profesioniști care lucrează și oferă peste 10 studii de caz și proiecte, ateliere practice practice, mentorat cu experți din industrie, 1- on-1 cu mentori din industrie, peste 400 de ore de învățare și asistență profesională cu firme de top.
Care sunt câteva pachete utile Python pentru vizualizarea datelor?
Python are câteva pachete uimitoare și utile pentru vizualizarea datelor. Unele dintre aceste pachete sunt menționate mai jos:
1. Matplotlib - Matplotlib este o bibliotecă populară Python utilizată pentru vizualizarea datelor sub diferite forme, cum ar fi diagrame de dispersie, grafice cu bare, diagrame circulare și diagrame cu linii. Folosește Numpy pentru operațiile sale matematice.
2. Seaborn - Biblioteca Seaborn este folosită pentru reprezentări statistice în Python. Este dezvoltat pe partea de sus a Matplotlib și este integrat cu structurile de date Pandas.
3. Altair - Altair este o altă bibliotecă populară Python pentru vizualizarea datelor. Este o bibliotecă statistică declarativă care vă permite să creați imagini vizuale cu codificare minimă posibilă.
4. Plotly - Plotly este o bibliotecă interactivă și open-source de vizualizare a datelor din Python. Imaginile create de această bibliotecă bazată pe browser sunt acceptate de multe platforme, cum ar fi Jupyter Notebook și fișiere HTML independente.
Ce știi despre diagramele de puncte și diagramele de dispersie?
Diagramele de puncte sunt cele mai simple și mai simple diagrame pentru vizualizarea datelor. Un grafic de puncte afișează datele sub formă de puncte pe un plan cartezian. „+” arată creșterea valorii, în timp ce „-” arată scăderea valorii în timp.
Pe de altă parte, un grafic de dispersie este un grafic optimizat în care datele sunt vizualizate pe un plan 2-D. Este definit folosind funcția scatter() care ia valoarea axei x ca prim parametru și valoarea axei y ca al doilea parametru.
Care sunt avantajele vizualizării datelor?
Următoarele avantaje arată cum vizualizările de date pot deveni adevăratul erou pentru creșterea unei organizații:
1. Vizualizarea datelor facilitează interpretarea datelor brute și înțelegerea lor pentru analize ulterioare.
2. După cercetarea și analizarea datelor, rezultatele pot fi afișate folosind vizualizări semnificative. Acest lucru facilitează conectarea cu publicul și explicarea rezultatelor.
3. Una dintre cele mai esențiale aplicații ale acestei tehnici este de a analiza modele și tendințe pentru a deduce predicții și zone potențiale de creștere.
4. De asemenea, vă permite să separați datele în funcție de preferințele clienților. De asemenea, puteți identifica zonele care necesită mai multă atenție.