
Ultima fișă pentru știința datelor pe care ar trebui să o aibă fiecare cercetător de date
Publicat: 2021-01-29Pentru toți acei profesioniști în devenire și începători deopotrivă care se gândesc să se arunce în lumea în plină expansiune a științei datelor, am compilat o fișă rapidă pentru a vă familiariza cu elementele de bază și metodologiile care subliniază acest domeniu.
Cuprins
Știința datelor - Bazele
Datele care sunt generate în lumea noastră sunt într-o formă brută, adică numere, coduri, cuvinte, propoziții etc. Data Science preia aceste date foarte brute pentru a le procesa folosind metode științifice pentru a le transforma în forme semnificative pentru a obține cunoștințe și perspective. .
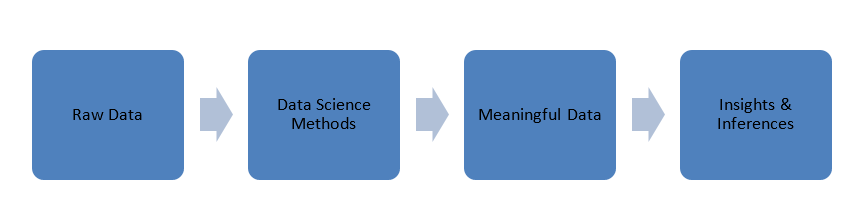
Date
Înainte de a ne aprofunda în principiile științei datelor, să vorbim puțin despre date, tipurile lor și procesarea datelor.
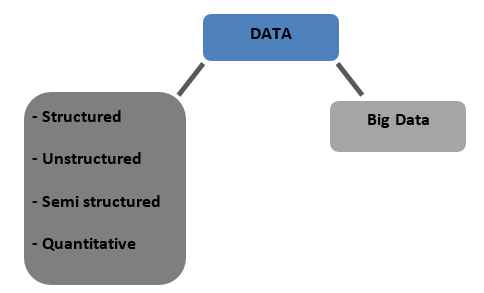
Tipuri de date
Structurat – Date care sunt stocate într-un format tabelat în baze de date. Poate fi numeric sau text
Nestructurat – Datele care nu pot fi tabulate cu nicio structură definitivă despre care să vorbim se numesc date nestructurate
Semistructurat – date mixte cu trăsături atât ale datelor structurate, cât și ale celor nestructurate
Cantitativ – Date cu valori numerice definite care pot fi cuantificate
Big Data – Datele stocate în baze de date uriașe care acoperă mai multe computere sau ferme de servere se numesc Big Data. Datele biometrice, datele din rețelele sociale etc. sunt considerate Big Data. Big Data este caracterizată de 4 V
Preprocesarea datelor
Clasificarea datelor – Este procesul de clasificare sau etichetare a datelor în clase precum numerice, textuale sau imagini, text, video etc.
Curățarea datelor – Constă în eliminarea datelor lipsă/inconsecvente/incompatibile sau înlocuirea datelor folosind una dintre următoarele metode.
- Interpolare
- Euristică
- Repartizarea aleatorie
- Cel mai apropiat vecin
Mascarea datelor – Ascunderea sau mascarea datelor confidențiale pentru a menține confidențialitatea informațiilor sensibile, în timp ce le puteți procesa.
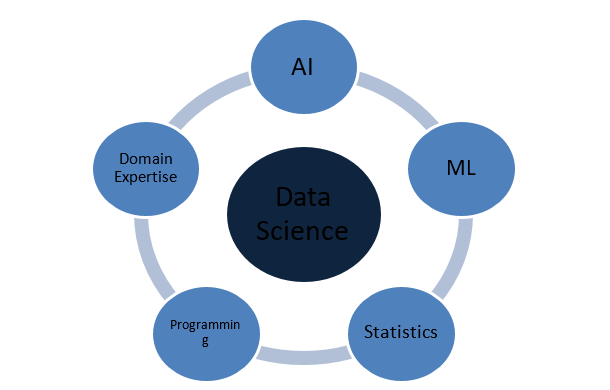
Din ce este făcută Data Science?
Concepte de statistică
Regresia
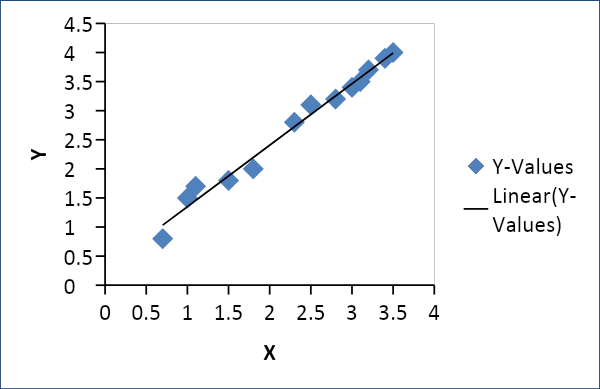
Regresie liniara
Regresia liniară este utilizată pentru a stabili o relație între două variabile, cum ar fi cererea și oferta, prețul și consumul, etc. Relaționează o variabilă x ca o funcție liniară a unei alte variabile y, după cum urmează
Y = f(x) sau Y =mx + c, unde m = coeficient
Regresie logistică
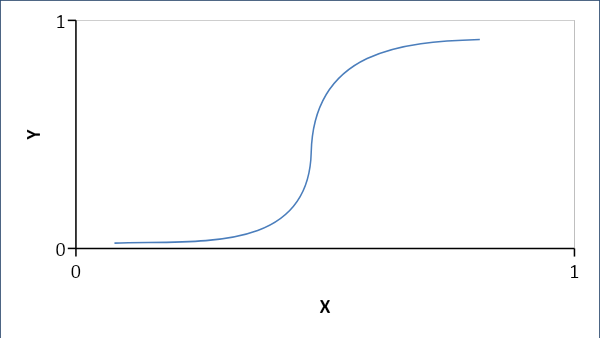
Regresia logistică stabilește o relație probabilistică mai degrabă decât una liniară între variabile. Răspunsul rezultat este fie 0, fie 1 și căutăm probabilități, iar curba este una în formă de S.
Dacă p < 0,5, atunci este 0 altfel 1
Formulă:
Y = e^ (b0 + b1x) / (1 + e^ (b0 +b1x))
unde b0 = bias și b1 = coeficient
Probabilitate
Probabilitatea ajută la prezicerea probabilității de apariție a unui eveniment. Câteva terminologii:
Eșantion: Setul de rezultate probabile
Eveniment: este un subset al spațiului eșantion
Variabilă aleatoare: variabilele aleatoare ajută la maparea sau cuantificarea rezultatelor probabile la numere sau o linie dintr-un spațiu eșantion
Distribuții de probabilitate
Distribuții discrete: oferă probabilitatea ca un set de valori discrete (întreg)
P[X=x] = p(x)
 Sursa imaginii
Sursa imaginii
Distribuții continue: oferă probabilitatea pe un număr de puncte sau intervale continue în loc de valori discrete. Formulă:
P[a ≤ x ≤ b] = a∫bf(x) dx, unde a, b sunt punctele
Sursa imaginii
Corelație și covarianță
Abatere standard: variația sau abaterea unui anumit set de date de la valoarea medie
σ = √ {(Σi=1N ( xi – x ) ) / (N -1)}
Covarianta
Acesta definește gradul de abatere a variabilelor aleatoare X și Y cu media setului de date.
Cov(X,Y) = σ2XY = E[(X−μX)(Y−μY)] = E[XY]−μXμY
Corelație
Corelația definește amploarea unei relații liniare între variabile împreună cu direcția lor, +ve sau -ve
ρXY= σ2XY/ σX * *σY
Inteligență artificială
Capacitatea mașinilor de a dobândi cunoștințe și de a lua decizii pe baza intrărilor se numește Inteligență Artificială sau pur și simplu AI.
Tipuri
- Mașini reactive: IA reactivă a mașinii funcționează învățând să reacționeze la scenarii predefinite prin restrângerea la cele mai rapide și mai bune opțiuni. Le lipsește memorie și sunt cele mai bune pentru sarcini cu un set definit de parametri. Foarte fiabil și consistent.
- Memorie limitată: această IA are câteva date de observație și moștenire din lumea reală. Poate învăța și poate lua decizii pe baza datelor date, dar nu poate câștiga experiențe noi.
- Teoria minții: Este o IA interactivă care poate lua decizii bazate pe comportamentul entităților din jur.
- Conștientizarea de sine: Această IA este conștientă de existența și funcționarea sa în afară de mediul înconjurător. Poate dezvolta abilități cognitive și poate înțelege și evalua impactul propriilor acțiuni asupra mediului înconjurător.
termeni AI
Rețele neuronale
Rețelele neuronale sunt un grup sau o rețea de noduri interconectate care transmit date și informații într-un sistem. NN-urile sunt modelate pentru a imita neuronii din creierul nostru și pot lua decizii prin învățare și predicție.
Euristică
Euristica este capacitatea de a prezice pe baza aproximărilor și estimărilor rapid folosind experiența anterioară în situațiile în care informațiile disponibile sunt neregulate. Este rapid, dar nu este exact sau precis.
Raționamentul bazat pe caz
Abilitatea de a învăța din cazurile anterioare de rezolvare a problemelor și de a le aplica în situațiile curente pentru a ajunge la o soluție acceptabilă
Procesarea limbajului natural
Este pur și simplu capacitatea unei mașini de a înțelege și de a interacționa direct în vorbirea sau textul uman. De exemplu, comenzi vocale într-o mașină
Învățare automată
Învățarea automată este pur și simplu o aplicație a IA care utilizează diverse modele și algoritmi pentru a prezice și rezolva probleme.
Tipuri

Supravegheat
Această metodă se bazează pe datele de intrare care sunt asociative cu datele de ieșire. Mașina este prevăzută cu un set de variabile țintă Y și trebuie să ajungă la variabila țintă printr-un set de variabile de intrare X sub supravegherea unui algoritm de optimizare. Exemple de învățare supravegheată sunt rețelele neuronale, pădurea aleatorie, învățarea profundă, mașinile de suport vector etc.
Nesupravegheat
În această metodă, variabilele de intrare nu au etichetare sau asociere, iar algoritmii funcționează pentru a găsi modele și grupuri care au ca rezultat noi cunoștințe și perspective.
Armat
Învățarea consolidată se concentrează pe tehnici de improvizație pentru a ascuți sau a șlefui comportamentul de învățare. Este o metodă bazată pe recompense în care aparatul își îmbunătățește treptat tehnicile pentru a câștiga o recompensă țintă.
Metode de modelare
Regresia
Modelele de regresie dau întotdeauna numere ca rezultat prin interpolarea sau extrapolarea datelor continue.
Clasificare
Modelele de clasificare vin cu rezultate ca o clasă sau etichetă și sunt mai bune la prezicerea rezultatelor discrete precum „ce fel”
Atât regresia, cât și clasificarea sunt modele supravegheate.
Clustering
Clusteringul este un model nesupravegheat care identifică clustere pe baza trăsăturilor, atributelor, caracteristicilor etc.
Algoritmi ML
Arbori de decizie
Arborele de decizie utilizează o abordare binară pentru a ajunge la o soluție bazată pe întrebări succesive la fiecare etapă, astfel încât rezultatul să fie oricare dintre cele două posibile, cum ar fi „Da” sau „Nu”. Arborele de decizie sunt simplu de implementat și interpretat.
Pădure aleatoare sau însac
Random Forest este un algoritm avansat de arbori de decizie. Utilizează un număr mare de arbori de decizie, ceea ce face structura densă și complexă ca o pădure. Acesta generează rezultate multiple și, astfel, duce la rezultate și performanțe mai precise.
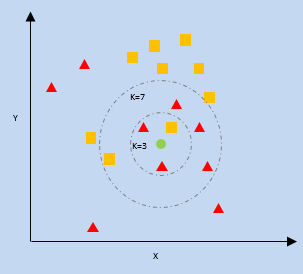
K- Cel mai apropiat vecin (KNN)
kNN folosește proximitatea celor mai apropiate puncte de date dintr-un diagramă în raport cu un nou punct de date pentru a prezice în ce categorie se încadrează. Noul punct de date este atribuit categoriei cu un număr mai mare de vecini.
k = numărul vecinilor cei mai apropiați
Bayes naiv
Naive Bayes lucrează pe doi piloni, în primul rând că fiecare caracteristică a punctelor de date este independentă, fără legătură între ele, adică unică, și în al doilea rând pe teorema Bayes care prezice rezultate pe baza unei condiții sau ipoteze.
Teorema Bayes:
P(X|Y) = {P(Y|X) * P(X)} / P(Y)
Unde P(X|Y) = Probabilitatea condiționată a lui X dată de apariția lui Y
P(Y|X) = Probabilitatea condiționată a lui Y având în vedere apariția lui X
P(X), P(Y) = Probabilitatea X și Y individual
Suport mașini vectoriale
Acest algoritm încearcă să separe datele în spațiu pe baza granițelor care pot fi fie o linie, fie un plan. Această limită se numește „hiperplan” și este definită de cele mai apropiate puncte de date ale fiecărei clase, care la rândul lor sunt numite „vectori suport”. Distanța maximă dintre vectorii suport de ambele părți se numește margine.
Rețele neuronale
Perceptron
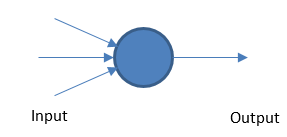
Rețeaua neuronală fundamentală funcționează luând intrări și ieșiri ponderate pe baza unei valori de prag.
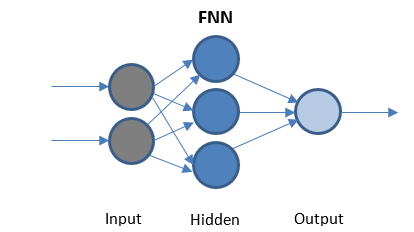
Rețeaua neuronală Feed Forward
FFN este cea mai simplă rețea care transmite date într-o singură direcție. Poate avea sau nu straturi ascunse.
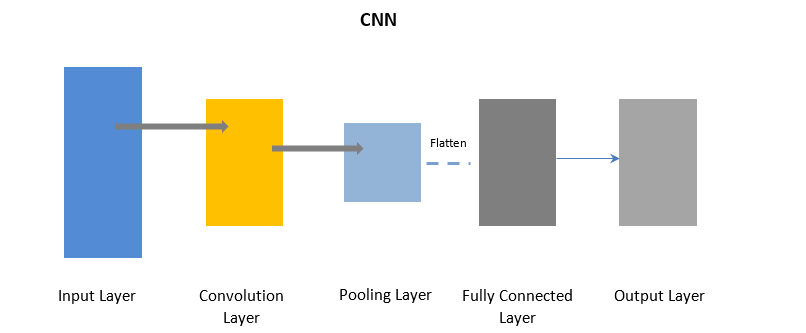
Rețele neuronale convoluționale
CNN folosește un strat de convoluție pentru a procesa anumite părți ale datelor de intrare în loturi, urmate de un strat de pooling pentru a finaliza rezultatul.
Rețele neuronale recurente
RNN constă din câteva straturi recurente între straturile I/O care pot stoca date „istorice”. Fluxul de date este bidirecțional și este alimentat straturilor recurente pentru îmbunătățirea predicțiilor.
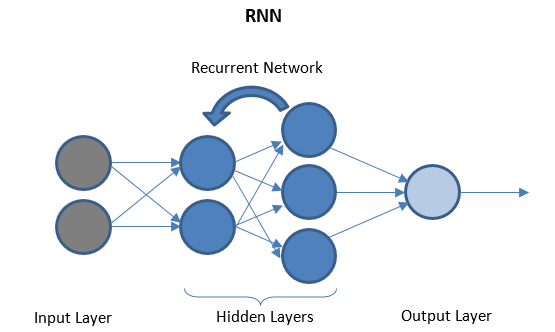
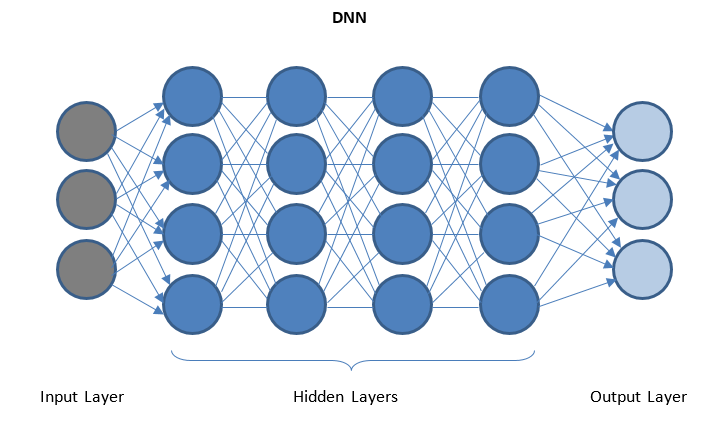
Rețele neuronale profunde și învățare profundă
DNN este o rețea cu mai multe straturi ascunse între straturile I/O. Straturile ascunse aplică transformări succesive datelor înainte de a le trimite la stratul de ieșire.
„Învățarea profundă” este facilitată prin DNN și poate gestiona cantități uriașe de date complexe și poate obține o precizie ridicată datorită mai multor straturi ascunse
Obțineți certificare în știința datelor de la cele mai bune universități din lume. Învață programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.
Concluzie
Știința datelor este un domeniu vast care trece prin diferite fluxuri, dar apare ca o revoluție și o revelație pentru noi. Știința datelor este în plină expansiune și va schimba modul în care sistemele noastre funcționează și se simt în viitor.
Dacă sunteți curios să aflați despre știința datelor, consultați Diploma PG în știința datelor de la IIIT-B și upGrad, care este creată pentru profesioniști care lucrează și oferă peste 10 studii de caz și proiecte, ateliere practice practice, mentorat cu experți din industrie, 1- on-1 cu mentori din industrie, peste 400 de ore de învățare și asistență profesională cu firme de top.
Ce limbaj de programare este cel mai potrivit pentru Data Science și de ce?
Există zeci de limbaje de programare pentru știința datelor, dar majoritatea comunității științei datelor consideră că, dacă doriți să excelați în știința datelor, atunci Python este alegerea potrivită. Mai jos sunt câteva dintre motivele care susțin această credință:
1. Python are o gamă largă de module și biblioteci, cum ar fi TensorFlow și PyTorch, care facilitează gestionarea conceptelor științei datelor.
2. O vastă comunitate de dezvoltatori Python îi ajută în mod constant pe începători să treacă la următoarea fază a călătoriei lor în domeniul științei datelor.
3. Această limbă este de departe una dintre cele mai convenabile și ușor de scris limbi cu o sintaxă curată, care îi îmbunătățește lizibilitatea.
Care sunt conceptele care fac știința datelor completă?
Știința datelor este un domeniu vast care acționează ca o umbrelă pentru diverse alte domenii cruciale. Următoarele sunt cele mai proeminente concepte care constituie știința datelor:
Statistici
Statistica este un concept important în care trebuie să excelați, pentru a avansa în știința datelor. Mai are câteva subteme:
1. Regresia liniară
2. Probabilitate
3. Distribuția probabilității
Inteligență artificială
Știința de a oferi mașinilor un creier și de a le lăsa să ia propriile decizii pe baza intrărilor este cunoscută sub numele de inteligență artificială. Mașinile reactive, memoria limitată, teoria minții și conștientizarea de sine sunt câteva dintre tipurile de inteligență artificială.
Învățare automată
Învățarea automată este o altă componentă crucială a științei datelor care se ocupă de mașinile de predare pentru a prezice rezultatele viitoare pe baza datelor furnizate. Învățarea automată are trei metode proeminente de modelare - Clustering, regresie și clasificare.
Descrieți tipurile de învățare automată?
Învățarea automată sau ML simplu are trei tipuri majore bazate pe metodele lor de lucru. Aceste tipuri sunt după cum urmează:
1. Învățare supravegheată
Acesta este cel mai primitiv tip de ML în care datele de intrare sunt etichetate. Aparatul este furnizat cu un set mai mic de date care oferă mașinii o perspectivă asupra problemei și este instruit asupra acesteia.
2. Învățare nesupravegheată
Cel mai mare avantaj al acestui tip este că datele nu sunt etichetate aici și munca umană este aproape neglijabilă. Acest lucru deschide poarta pentru ca seturi de date mult mai mari să fie introduse în model.
3. Învățare consolidată Acesta este cel mai avansat tip de ML care se inspiră din viețile ființelor umane. Ieșirile dorite sunt consolidate, în timp ce ieșirile inutile sunt descurajate.