
Preprocesarea datelor în Machine Learning: 7 pași simpli de urmat
Publicat: 2021-07-15Preprocesarea datelor în Machine Learning este un pas crucial care ajută la îmbunătățirea calității datelor pentru a promova extragerea de informații semnificative din date. Preprocesarea datelor în Machine Learning se referă la tehnica de pregătire (curățare și organizare) a datelor brute pentru a le face potrivite pentru construirea și formarea modelelor de Machine Learning. Cu cuvinte simple, preprocesarea datelor în Machine Learning este o tehnică de extragere a datelor care transformă datele brute într-un format ușor de înțeles și de citit.
Cuprins
De ce preprocesarea datelor în Machine Learning?
Când vine vorba de crearea unui model de învățare automată, preprocesarea datelor este primul pas care marchează inițierea procesului. În mod obișnuit, datele din lumea reală sunt incomplete, inconsecvente, inexacte (conțin erori sau valori aberante) și adesea nu au anumite valori/tendințe ale atributelor. Aici intră în scenariu preprocesarea datelor – ajută la curățarea, formatarea și organizarea datelor brute, făcându-le astfel gata de utilizare pentru modelele de învățare automată. Să explorăm diferiți pași ai preprocesării datelor în învățarea automată.
Alăturați-vă Cursului de Inteligență Artificială online de la cele mai bune universități din lume – Master, Programe Executive Postuniversitare și Program de Certificat Avansat în ML și AI pentru a vă accelera cariera.
Pași în preprocesarea datelor în Machine Learning
Există șapte pași semnificativi în preprocesarea datelor în Machine Learning:
1. Obțineți setul de date
Achiziționarea setului de date este primul pas în preprocesarea datelor în învățarea automată. Pentru a construi și dezvolta modele de învățare automată, trebuie mai întâi să achiziționați setul de date relevant. Acest set de date va fi compus din date culese din surse multiple și disparate, care sunt apoi combinate într-un format adecvat pentru a forma un set de date. Formatele setului de date diferă în funcție de cazurile de utilizare. De exemplu, un set de date de afaceri va fi complet diferit de un set de date medicale. În timp ce un set de date comerciale va conține date relevante despre industrie și afaceri, un set de date medicale va include date legate de asistența medicală.
Există mai multe surse online de unde puteți descărca seturi de date precum https://www.kaggle.com/uciml/datasets și https://archive.ics.uci.edu/ml/index.php . De asemenea, puteți crea un set de date prin colectarea datelor prin diferite API-uri Python. Odată ce setul de date este gata, trebuie să îl puneți în formate de fișiere CSV, HTML sau XLSX.

2. Importați toate bibliotecile esențiale
Deoarece Python este cea mai utilizată bibliotecă și, de asemenea, cea mai preferată de către oamenii de știință în date din întreaga lume, vă vom arăta cum să importați biblioteci Python pentru preprocesarea datelor în Machine Learning. Citiți mai multe despre bibliotecile Python pentru Data Science aici. Bibliotecile Python predefinite pot efectua sarcini specifice de preprocesare a datelor. Importarea tuturor bibliotecilor cruciale este al doilea pas în preprocesarea datelor în învățarea automată. Cele trei biblioteci de bază Python utilizate pentru această preprocesare a datelor în Machine Learning sunt:
- NumPy – NumPy este pachetul fundamental pentru calculul științific în Python. Prin urmare, este folosit pentru inserarea oricărui tip de operație matematică în cod. Folosind NumPy, puteți adăuga, de asemenea, matrice și matrice multidimensionale mari în codul dvs.
- Pandas – Pandas este o excelentă bibliotecă Python open-source pentru manipularea și analiza datelor. Este utilizat pe scară largă pentru importarea și gestionarea seturilor de date. Include structuri de date de înaltă performanță, ușor de utilizat și instrumente de analiză a datelor pentru Python.
- Matplotlib – Matplotlib este o bibliotecă de trasare 2D Python care este utilizată pentru a reprezenta orice tip de diagrame în Python. Poate furniza cifre de calitate publicației în numeroase formate de hârtie și medii interactive pe platforme (shell-uri IPython, notebook Jupyter, servere de aplicații web etc.).
Citiți : Idei de proiecte de învățare automată pentru începători
3. Importați setul de date
În acest pas, trebuie să importați setul/seturile de date pe care le-ați adunat pentru proiectul ML la îndemână. Importarea setului de date este unul dintre pașii importanți în preprocesarea datelor în învățarea automată. Cu toate acestea, înainte de a putea importa setul/seturile de date, trebuie să setați directorul curent ca director de lucru. Puteți seta directorul de lucru în Spyder IDE în trei pași simpli:
- Salvați fișierul Python în directorul care conține setul de date.
- Accesați opțiunea File Explorer din Spyder IDE și alegeți directorul necesar.
- Acum, faceți clic pe butonul F5 sau pe opțiunea Run pentru a executa fișierul.
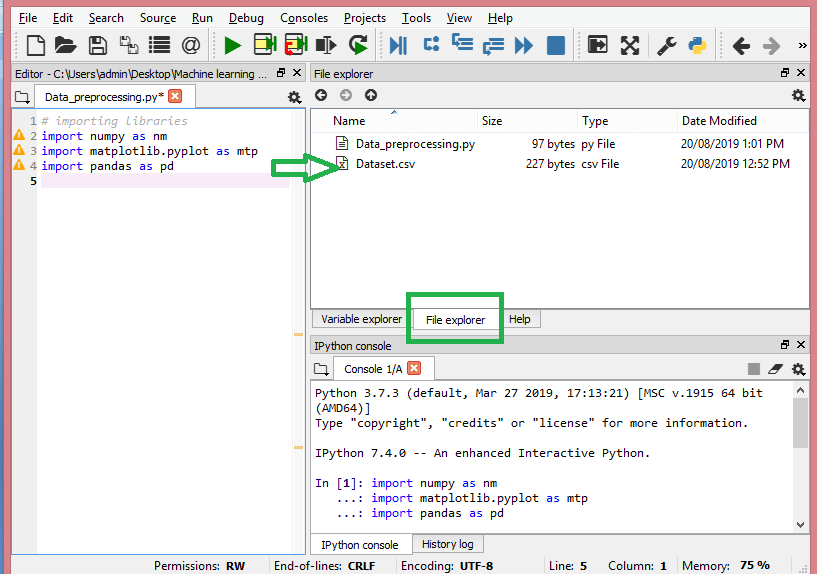
Sursă
Așa ar trebui să arate directorul de lucru.
După ce ați setat directorul de lucru care conține setul de date relevant, puteți importa setul de date folosind funcția „read_csv()” a bibliotecii Pandas. Această funcție poate citi un fișier CSV (fie local, fie printr-o adresă URL) și, de asemenea, poate efectua diverse operațiuni asupra acestuia. Read_csv() este scris ca:
data_set= pd.read_csv('Dataset.csv')
În această linie de cod, „data_set” denotă numele variabilei în care ați stocat setul de date. Funcția conține și numele setului de date. Odată ce executați acest cod, setul de date va fi importat cu succes.
În timpul procesului de import al setului de date, trebuie să faci un alt lucru esențial – extragerea variabilelor dependente și independente. Pentru fiecare model de învățare automată, este necesar să se separe variabilele independente (matricea caracteristicilor) și variabilele dependente dintr-un set de date.
Luați în considerare acest set de date:
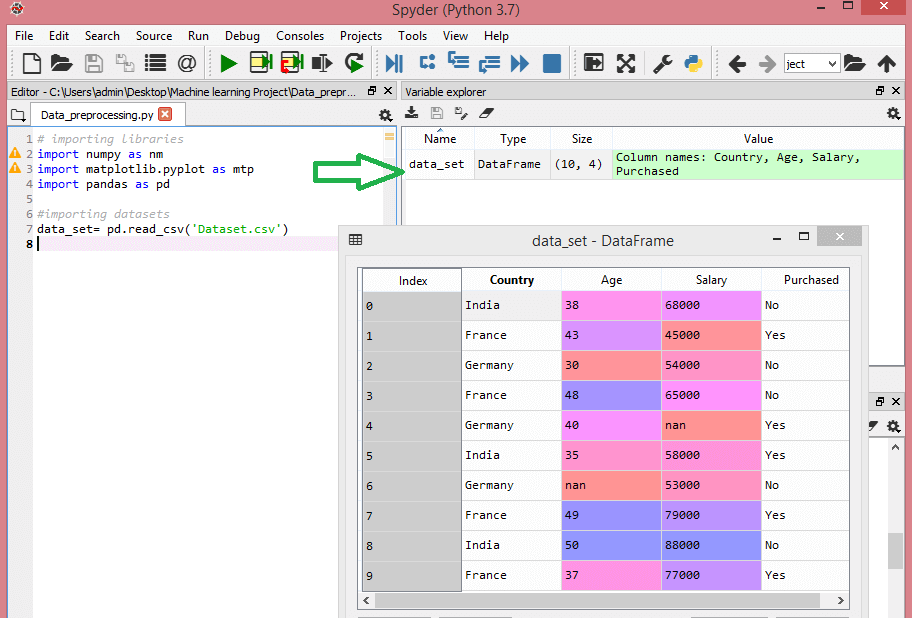
Sursă
Acest set de date conține trei variabile independente – țară, vârstă și salariu și o variabilă dependentă – achiziționată.
Cum se extrag variabilele independente?
Pentru a extrage variabilele independente, puteți folosi funcția „iloc[ ]” a bibliotecii Pandas. Această funcție poate extrage rândurile și coloanele selectate din setul de date.
x= data_set.iloc[:,:-1].valori
În linia de cod de mai sus, primele două puncte (:) iau în considerare toate rândurile, iar cele de-a doua două puncte (:) iau în considerare toate coloanele. Codul conține „:-1” deoarece trebuie să omiteți ultima coloană care conține variabila dependentă. Prin executarea acestui cod, veți obține matricea de caracteristici, ca aceasta -
[[„India” 38,0 68000,0]
[„Franța” 43,0 45000,0]
[„Germania” 30,0 54000,0]
[„Franța” 48,0 65000,0]
[„Germania” 40,0 nan]
[„India” 35,0 58000,0]
[„Germania” nan 53000.0]
[„Franța” 49,0 79000,0]
[„India” 50,0 88000,0]
[„Franța” 37,0 77000,0]]
Cum se extrage variabila dependentă?
Puteți utiliza funcția „iloc[ ]” pentru a extrage și variabila dependentă. Iată cum o scrii:
y= data_set.iloc[:,3].valori
Această linie de cod ia în considerare numai toate rândurile cu ultima coloană. Prin executarea codului de mai sus, veți obține matricea de variabile dependente, așa -
array([„Nu”, „Da”, „Nu”, „Nu”, „Da”, „Da”, „Nu”, „Da”, „Nu”, „Da”],
dtype=obiect)
4. Identificarea și manipularea valorilor lipsă
În preprocesarea datelor, este esențial să identificați și să gestionați corect valorile lipsă, în caz contrar, puteți trage concluzii și inferențe inexacte și greșite din date. Inutil să spun că acest lucru vă va împiedica proiectul ML.
Practic, există două moduri de a gestiona datele lipsă:
- Ștergerea unui anumit rând – În această metodă, eliminați un anumit rând care are o valoare nulă pentru o caracteristică sau o anumită coloană din care lipsesc mai mult de 75% dintre valori. Cu toate acestea, această metodă nu este eficientă 100% și este recomandat să o utilizați numai atunci când setul de date are mostre adecvate. Trebuie să vă asigurați că, după ștergerea datelor, nu rămâne nicio adăugare de părtinire.
- Calcularea mediei – Această metodă este utilă pentru caracteristicile care au date numerice precum vârsta, salariul, anul etc. Aici puteți calcula media, mediana sau modul unei anumite caracteristici sau coloane sau rând care conține o valoare lipsă și înlocuiți valoarea rezultat pentru valoarea lipsă. Această metodă poate adăuga variație setului de date și orice pierdere de date poate fi anulată eficient. Prin urmare, dă rezultate mai bune în comparație cu prima metodă (omiterea rândurilor/coloanelor). O altă modalitate de aproximare este prin abaterea valorilor învecinate. Cu toate acestea, acest lucru funcționează cel mai bine pentru date liniare.
Citiți: Aplicații ale aplicațiilor de învățare automată folosind cloud
5. Codificarea datelor categorice
Datele categoriale se referă la informațiile care au categorii specifice în setul de date. În setul de date citat mai sus, există două variabile categorice – țara și achiziția.
Modelele de învățare automată se bazează în primul rând pe ecuații matematice. Astfel, puteți înțelege intuitiv că păstrarea datelor categorice în ecuație va cauza anumite probleme, deoarece veți avea nevoie doar de numere în ecuații.
Cum se codifică variabila de țară?
După cum se vede în exemplul nostru de set de date, coloana de țară va cauza probleme, așa că trebuie să o convertiți în valori numerice. Pentru a face acest lucru, puteți utiliza clasa LabelEncoder() din biblioteca sci-kit Learn. Codul va fi după cum urmează -
#Date categorice
#pentru variabila de țară
din sklearn.preprocessing import LabelEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
Și rezultatul va fi -
Ieșit[15]:
matrice([[2, 38.0, 68000.0],
[0, 43,0, 45000,0],
[1, 30,0, 54000,0],
[0, 48,0, 65000,0],
[1, 40,0, 65222,22222222222],
[2, 35,0, 58000,0],
[1, 41,111111111111114, 53000,0],
[0, 49,0, 79000,0],
[2, 50,0, 88000,0],
[0, 37,0, 77000,0]], dtype=obiect)
Aici putem vedea că clasa LabelEncoder a codificat cu succes variabilele în cifre. Cu toate acestea, există variabile de țară care sunt codificate ca 0, 1 și 2 în rezultatul prezentat mai sus. Deci, modelul ML poate presupune că există o oarecare corelație între cele trei variabile, producând astfel o ieșire defectuoasă. Pentru a elimina această problemă, acum vom folosi Dummy Encoding.
Variabilele fictive sunt acelea care iau valorile 0 sau 1 pentru a indica absența sau prezența unui efect categorial specific care poate modifica rezultatul. În acest caz, valoarea 1 indică prezența acelei variabile într-o anumită coloană, în timp ce celelalte variabile devin de valoarea 0. În codificarea inactivă, numărul de coloane este egal cu numărul de categorii.
Deoarece setul nostru de date are trei categorii, va produce trei coloane având valorile 0 și 1. Pentru codificarea inactivă, vom folosi clasa OneHotEncoder a bibliotecii scikit-learn. Codul de introducere va fi după cum urmează -
#pentru variabila de țară
din sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Codificare pentru variabile fictive
onehot_encoder= OneHotEncoder(caracteristici_categorice= [0])

x= onehot_encoder.fit_transform(x).toarray()
La executarea acestui cod, veți obține următoarea ieșire -
matrice ([[0,00000000e+00, 0,00000000e+00, 1,00000000e+00, 3,80000000e+01,
6.80000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 4,30000000e+01,
4.50000000e+04],
[0,00000000e+00, 1,00000000e+00, 0,00000000e+00, 3,00000000e+01,
5.40000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 4,80000000e+01,
6.50000000e+04],
[0,00000000e+00, 1,00000000e+00, 0,00000000e+00, 4,00000000e+01,
6.52222222e+04],
[0,00000000e+00, 0,00000000e+00, 1,00000000e+00, 3,50000000e+01,
5.80000000e+04],
[0,00000000e+00, 1,00000000e+00, 0,00000000e+00, 4,11111111e+01,
5.30000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 4,90000000e+01,
7.90000000e+04],
[0,00000000e+00, 0,00000000e+00, 1,00000000e+00, 5,00000000e+01,
8.80000000e+04],
[1,00000000e+00, 0,00000000e+00, 0,00000000e+00, 3,70000000e+01,
7.70000000e+04]])
În rezultatul prezentat mai sus, toate variabilele sunt împărțite în trei coloane și codificate în valorile 0 și 1.
Cum se codifică variabila achiziționată?
Pentru a doua variabilă categorială, adică cumpărată, puteți folosi obiectul „labelencoder” al clasei LableEncoder. Nu folosim clasa OneHotEncoder, deoarece variabila achiziționată are doar două categorii da sau nu, ambele fiind codificate în 0 și 1.
Codul de intrare pentru această variabilă va fi -
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
Ieșirea va fi -
Out[17]: matrice([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
6. Împărțirea setului de date
Împărțirea setului de date este următorul pas în preprocesarea datelor în învățarea automată. Fiecare set de date pentru modelul Machine Learning trebuie împărțit în două seturi separate - set de antrenament și set de testare.
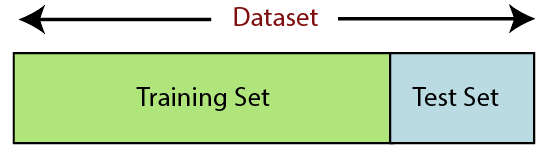
Sursă
Setul de instruire denotă subsetul unui set de date care este utilizat pentru antrenarea modelului de învățare automată. Aici, ești deja conștient de rezultat. Un set de testare, pe de altă parte, este subsetul de date care este utilizat pentru testarea modelului de învățare automată. Modelul ML folosește setul de teste pentru a prezice rezultate.
De obicei, setul de date este împărțit în raport de 70:30 sau raport de 80:20. Aceasta înseamnă că fie luați 70% sau 80% din date pentru antrenamentul modelului, în timp ce lăsați deoparte restul 30% sau 20%. Procesul de împărțire variază în funcție de forma și dimensiunea setului de date în cauză.
Pentru a împărți setul de date, trebuie să scrieți următoarea linie de cod -
din sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0,2, random_state=0)
Aici, prima linie împarte matricele setului de date în subseturi aleatoare de tren și de testare. A doua linie de cod include patru variabile:
- x_train – caracteristici pentru datele de antrenament
- x_test – caracteristici pentru datele de testare
- y_train – variabile dependente pentru datele de antrenament
- y_test – variabilă independentă pentru testarea datelor
Astfel, funcția train_test_split() include patru parametri, primii doi fiind pentru matrice de date. Funcția test_size specifică dimensiunea setului de testare. Dimensiunea testului poate .5, .3 sau .2 – aceasta specifică raportul de împărțire dintre seturile de antrenament și de testare. Ultimul parametru, „random_state” setează semințele pentru un generator aleatoriu, astfel încât ieșirea să fie întotdeauna aceeași.
7. Scalarea caracteristicilor
Scalarea caracteristicilor marchează sfârșitul preprocesării datelor în Machine Learning. Este o metodă de standardizare a variabilelor independente ale unui set de date într-un interval specific. Cu alte cuvinte, scalarea caracteristicilor limitează gama de variabile, astfel încât să le puteți compara pe baze comune.
Luați în considerare acest set de date de exemplu -
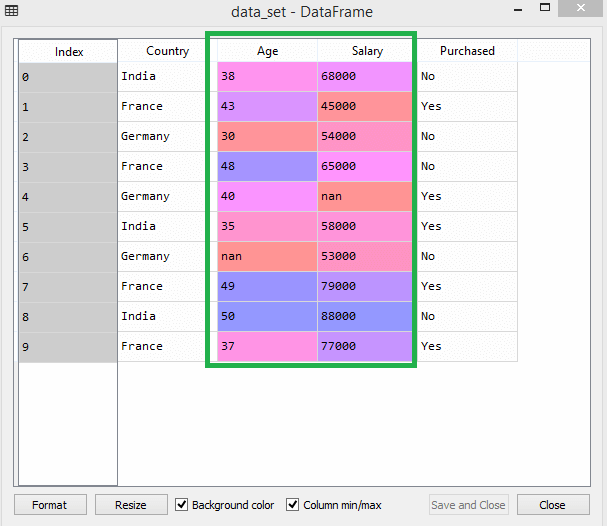
Sursă
În setul de date, puteți observa că coloanele de vârstă și salariu nu au aceeași scară. Într-un astfel de scenariu, dacă calculați oricare două valori din coloanele de vârstă și salariu, valorile salariului vor domina valorile vârstei și vor oferi rezultate incorecte. Astfel, trebuie să eliminați această problemă efectuând scalarea caracteristicilor pentru Machine Learning.
Majoritatea modelelor ML se bazează pe Distanța Euclidiană, care este reprezentată ca:
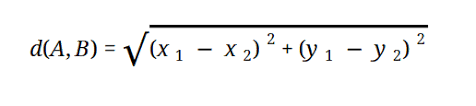
Sursă
Puteți efectua scalarea caracteristicilor în Machine Learning în două moduri:
Standardizare
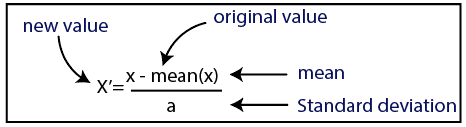
Sursă
Normalizare
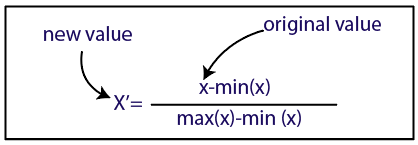
Sursă
Pentru setul nostru de date, vom folosi metoda de standardizare. Pentru a face acest lucru, vom importa clasa StandardScaler a bibliotecii sci-kit-learn folosind următoarea linie de cod:
din sklearn.preprocessing import StandardScaler
Următorul pas va fi crearea obiectului clasei StandardScaler pentru variabile independente. După aceasta, puteți potrivi și transforma setul de date de antrenament folosind următorul cod:
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
Pentru setul de date de testare, puteți aplica direct funcția transform() (nu trebuie să utilizați funcția fit_transform() deoarece este deja făcută în setul de antrenament). Codul va fi după cum urmează -
x_test= st_x.transform(x_test)
Ieșirea pentru setul de date de testare va afișa valorile scalate pentru x_train și x_test ca:
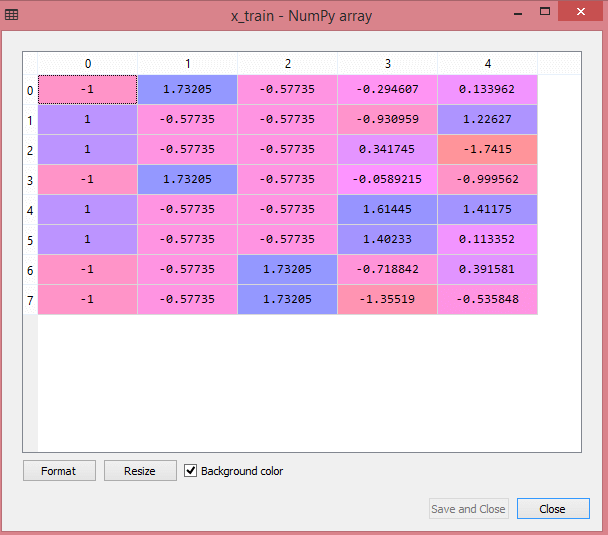
Sursă
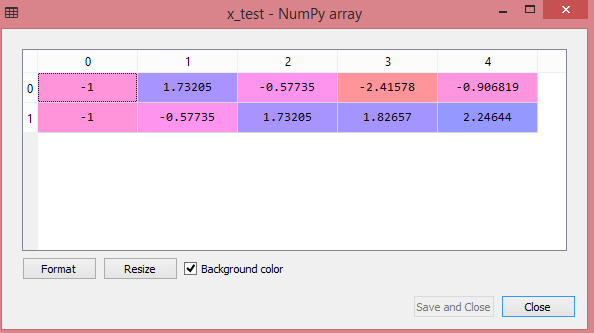
Sursă
Toate variabilele din ieșire sunt scalate între valorile -1 și 1.
Acum, pentru a combina toți pașii pe care i-am efectuat până acum, obțineți:
# import biblioteci
import numpy ca nm
import matplotlib.pyplot ca mtp
importa panda ca pd
#importing seturi de date
data_set= pd.read_csv('Dataset.csv')
#Extragerea variabilei independente
x= data_set.iloc[:, :-1].valori
#Extragerea variabilei dependente
y= data_set.iloc[:, 3].valori
#handling missing data(Înlocuirea datelor lipsă cu valoarea medie)
din sklearn.preprocessing import Imputer
imputer= Imputer(mising_values ='NaN', strategy='mean', axis = 0)
#Ajustarea obiectului imputer la variabilele independente x.
imputerimputer= imputer.fit(x[:, 1:3])
#Înlocuirea datelor lipsă cu valoarea medie calculată
x[:, 1:3]= imputer.transform(x[:, 1:3])
#pentru variabila de țară
din sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#Codificare pentru variabile fictive
onehot_encoder= OneHotEncoder(caracteristici_categorice= [0])
x= onehot_encoder.fit_transform(x).toarray()
#codare pentru variabila achiziționată
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
# Împărțirea setului de date în set de antrenament și test.
din sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0,2, random_state=0)
#Feature Scaling of datasets
din sklearn.preprocessing import StandardScaler
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
Deci, aceasta este procesarea datelor în Machine Learning pe scurt!
Puteți verifica Programul Executive PG al IIT Delhi în Învățare automată și AI în asociere cu upGrad . IIT Delhi este una dintre cele mai prestigioase instituții din India. Cu mai mult de 500 de membri ai facultății interne, care sunt cei mai buni în materie.
Care este importanța preprocesării datelor?
Deoarece erorile, redundanțele, valorile lipsă și inconsecvențele pun în pericol integritatea setului de date, trebuie să le abordați pe toate pentru un rezultat mai precis. Să presupunem că utilizați un set de date defect pentru a instrui un sistem de învățare automată pentru a face față achizițiilor clienților dvs. Este posibil ca sistemul să genereze părtiniri și abateri, ceea ce duce la o experiență proastă pentru utilizator. Ca urmare, înainte de a utiliza acele date în scopul propus, acestea trebuie să fie cât mai organizate și „curate” pe cât posibil. În funcție de tipul de dificultate cu care te confrunți, există numeroase opțiuni.
Ce este curățarea datelor?
Aproape sigur vor fi date lipsă și zgomotoase din seturile dvs. de date. Deoarece procedura de colectare a datelor nu este ideală, veți avea o mulțime de informații inutile și lipsă. Curățarea datelor este modalitatea pe care ar trebui să o utilizați pentru a rezolva această problemă. Aceasta poate fi împărțită în două categorii. Prima discută cum să faceți față datelor lipsă. Puteți alege să ignorați valorile lipsă din această secțiune a culegerii de date (numită tuplu). A doua metodă de curățare a datelor este pentru datele care sunt zgomotoase. Este esențial să scăpați de datele inutile care nu pot fi citite de sisteme dacă doriți ca întregul proces să funcționeze fără probleme.
Ce înțelegeți prin transformarea și reducerea datelor?
Preprocesarea datelor trece la etapa de transformare după ce s-a rezolvat cu preocupările. Îl folosești pentru a converti datele în conformații relevante pentru analiză. Normalizarea, selecția atributelor, discretizarea și generarea ierarhiei conceptului sunt câteva dintre abordările care pot fi utilizate pentru a realiza acest lucru. Chiar și pentru metodele automate, trecerea prin seturi mari de date poate dura mult timp. De aceea, etapa de reducere a datelor este atât de crucială: reduce dimensiunea seturilor de date limitându-le la cele mai importante informații, sporind eficiența stocării, reducând în același timp cheltuielile financiare și de timp ale lucrului cu acestea.