
Cadre de date în Python: Tutorial aprofundat Python 2022
Publicat: 2021-01-09Dacă sunteți un dezvoltator sau un programator care lucrează în limbajul de programare Python, trebuie să fiți familiarizat cu una dintre cele mai uimitoare biblioteci de gestionare a datelor existente – Pandas, una dintre cele mai importante biblioteci Python de acolo. De-a lungul anilor, Pandas a devenit un instrument standard pentru analiza și gestionarea datelor folosind Python. Citiți despre alte instrumente Python importante.
Pandas este, fără îndoială, cel mai versatil pachet Python pentru știința datelor și pe bună dreptate. Oferă structuri de date puternice, expresive și flexibile pentru manipularea și analiza ușoară a datelor, iar Cadre de date în Python este una dintre aceste structuri.
Acesta este tocmai subiectele noastre de discuție în această postare – vă vom prezenta formatul de bază de date pentru Pandas, adică Pandas Data Frame.
Cuprins
Ce este un cadru de date?
Conform documentației bibliotecii Pandas , un cadru de date este „o structură de date tabulară bidimensională, cu dimensiuni modificabile, potențial eterogenă, cu axe etichetate (rânduri și coloane)”. Cu cuvinte simple, un cadru de date este o structură de date în care datele sunt aliniate într-un mod tabelar, adică în rânduri și coloane.
Un cadru de date are de obicei următoarele caracteristici:
- Poate avea mai multe rânduri și coloane.
- În timp ce fiecare rând reprezintă un eșantion de date, fiecare coloană cuprinde o variabilă diferită care descrie eșantioanele (rândurile).
- Datele din fiecare coloană sunt de obicei același tip de date (de exemplu, numere, șiruri, date etc.).
- Spre deosebire de seturile de date Excel, evită să aibă valori lipsă, astfel încât nu există goluri sau valori goale între rânduri sau coloane.
Într-un cadru de date Pandas, puteți specifica, de asemenea, numele de index și coloane pentru cadrul de date. În timp ce indexul indică diferența în rânduri, numele coloanelor arată diferența în coloane.
Cum se creează un cadru de date în Python (folosind Pandas)
Crearea unui cadru de date este primul pas pentru colectarea datelor în Python. Puteți crea un cadru de date Pandas folosind intrări precum:
- Dict
- Liste
- Serie
- Numpy „ndarray”
- Un alt cadru de date
- Fișiere externe, cum ar fi CS
- Crearea unui cadru de date gol
Este destul de ușor să creați un cadru de date de bază, adică un cadru de date gol. Iată un exemplu:
Intrare -

Ieșire –

- Crearea unui cadru de date din liste
Puteți crea un cadru de date folosind o singură listă sau mai multe liste.
Intrare -

Ieșire –

- Crearea unui cadru de date din Dict de „ndarrays” sau liste
Pentru a crea un cadru de date dintr-un dict de ndarrays, toate ndarray-urile trebuie să aibă aceeași lungime. De asemenea, dacă este indexat, lungimea indexului ar trebui să fie egală cu lungimea matricelor. Cu toate acestea, dacă nu este indexat, indexul va fi interval(n) în mod implicit, unde „n” denotă lungimea matricei.
Intrare -

Ieșire –

Aici valorile 0,1,2,3 sunt indexul implicit atribuit fiecărui rând folosind intervalul de funcții (n).
Care sunt operațiunile fundamentale ale cadrului de date?
Acum că am văzut trei moduri de a crea cadre de date în Python, este timpul să învățăm despre diferitele operațiuni dintr-un cadru de date.
- Selectarea unui index sau a unei coloane dintr-un cadru de date Pandas
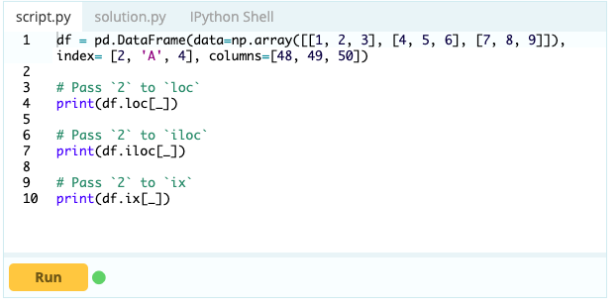
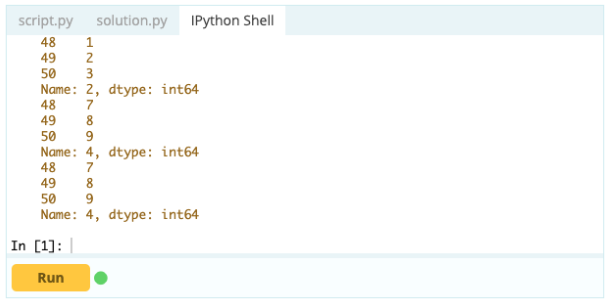
Este important să știți cum să selectați un index sau o coloană înainte de a putea începe adăugarea, ștergerea și redenumirea componentelor dintr-un DataFrame. Să presupunem că acesta este cadrul dvs. de date:

Doriți să accesați valoarea sub indexul 0 în coloana „A” – valoarea este 1. Există multe modalități de a accesa această valoare, dar două dintre cele mai importante sunt – .loc[] și .iloc[].
Intrare -
Ieșire –
Deci, după cum puteți vedea, puteți accesa valori fie apelându-le după etichetă, fie declarând poziția lor în index sau coloană. În timp ce aceasta a fost selectarea unei valori dintr-un cadru de date, cum puteți selecta rânduri și coloane din același?
Iată cum:
Intrare -
ieșire-
- Cum să adăugați un index, un rând sau o coloană la un cadru de date Pandas
După ce învățați cum să accesați valori și să selectați coloane dintr-un cadru de date, puteți învăța să adăugați index, rând sau coloană într-un cadru de date Pandas.
Adăugarea unui index:
În timp ce creați un cadru de date, puteți alege să adăugați o intrare la argumentul „index”. Acest lucru vă asigură că puteți accesa cu ușurință indexul dorit. Dacă nu specificați indexul, în mod implicit, i se va adăuga un index cu valoare numerică care începe cu 0 și continuă până la ultimul rând al DataFrame. Deși, chiar și după ce indexul este specificat în mod implicit, puteți utiliza o coloană și o puteți converti într-un index apelând funcția set_index() din Cadrul de date.

Adăugarea unui rând:
Puteți adăuga rânduri la un DataFrame folosind funcția de adăugare.
Intrare -

Ieșire –

De asemenea, puteți utiliza .loc pentru a insera rânduri în DataFrame astfel:
Intrare -
Ieșire –
Adăugarea unei coloane
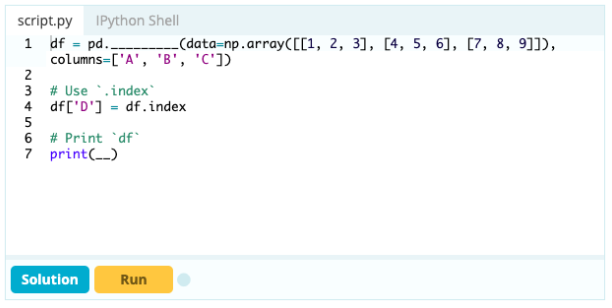
Dacă doriți să faceți ca un index să fie parte dintr-un cadru de date, puteți lua o coloană din cadrul de date sau puteți face referire la o coloană care nu a fost creată încă și să o atribui proprietății .index astfel:
Intrare -
Ieșire –
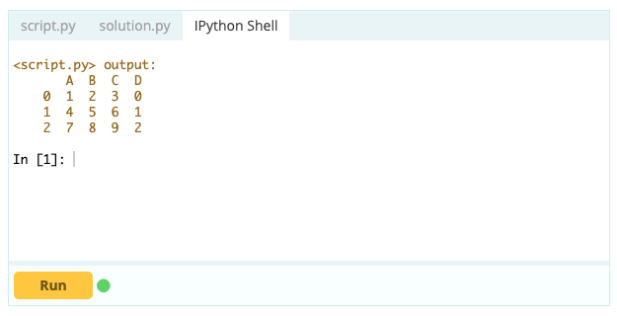
Pentru adăugarea coloanelor la un cadru de date, puteți utiliza, de asemenea, aceeași abordare pe care ați folosi-o pentru adăugarea unui index la cadrul de date, adică puteți utiliza funcția .loc[ ] sau .iloc[ ]. De exemplu:
Intrare -
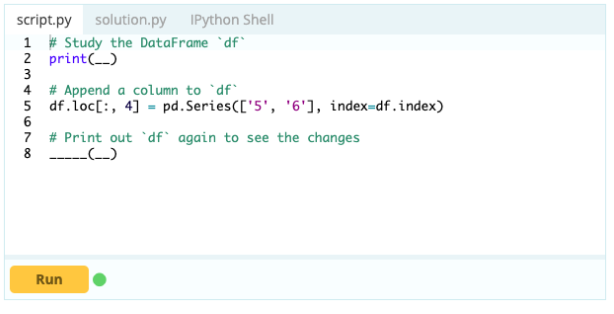
Ieșire
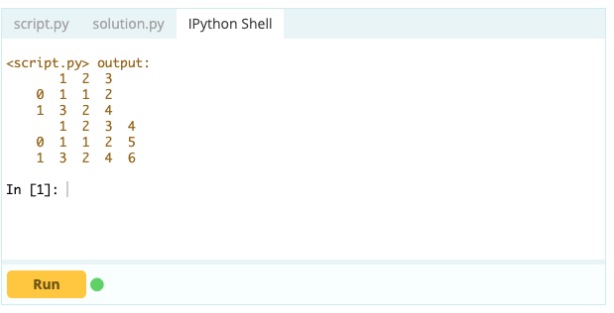
Cu .loc[ ], puteți adăuga o serie la un DataFrame existent. Deoarece un obiect Series este destul de similar cu o coloană a unui cadru de date, este foarte ușor să adăugați o serie la un cadru de date existent.
- Cum să resetați indexul unui cadru de date?
Puteți reseta indexul unui cadru de date dacă nu este așa cum doriți. Puteți utiliza funcția .reset_index() pentru a face acest lucru.
Intrare -
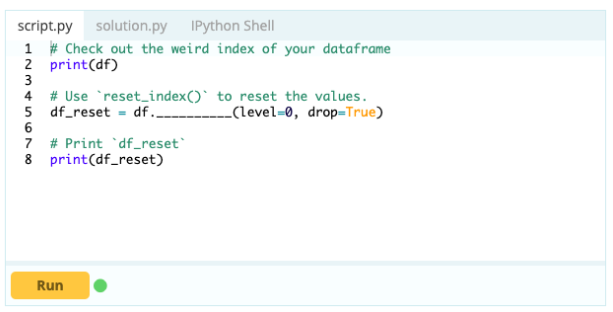
Ieșire –
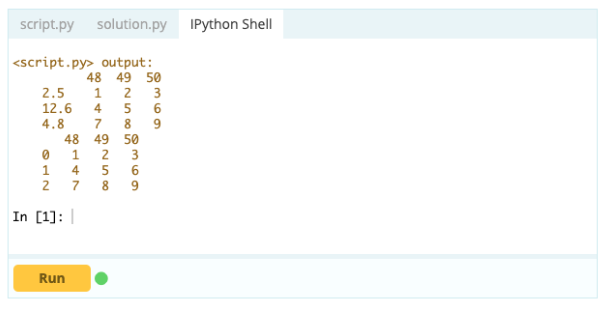
- Cum să ștergeți un index, un rând sau o coloană dintr-un cadru de date Pandas
Ștergerea unui index
- Resetarea indexului cadrului de date.
- Eliminați numele indexului (dacă există) utilizând funcția del df.index.name.
- Eliminați un index împreună cu un rând.
- Eliminați toate valorile indexului duplicat prin resetarea indexului, eliminând duplicatele coloanei index care a fost adăugată la Cadrul de date și reinstalând noua coloană (fără un index duplicat) din nou ca index.
Ștergerea unei coloane
Pentru a elimina coloanele dintr-un cadru de date, puteți utiliza funcția drop().
Intrare -
Ieșire –
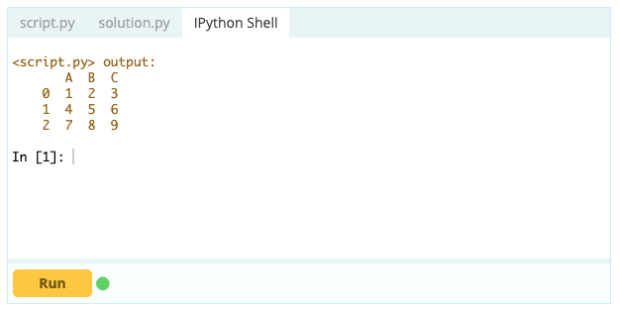
Ștergerea unui rând
Pentru a șterge un rând dintr-un cadru de date, puteți utiliza funcția drop() folosind proprietatea index pentru a specifica indexul rândurilor pe care doriți să le ștergeți din cadrul de date.
Intrare -
Ieșire –
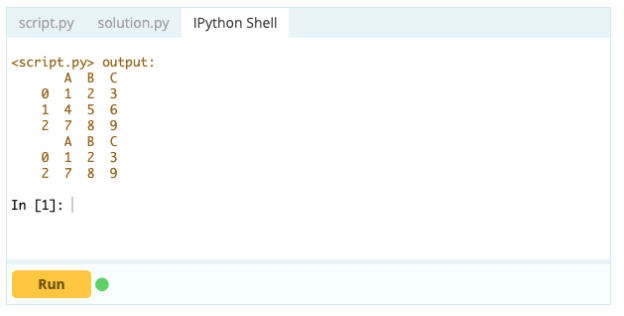
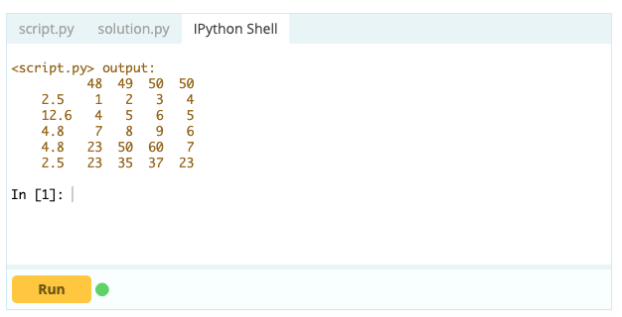
Cu toate acestea, pentru a șterge rândurile duplicate, puteți utiliza funcția df.drop_duplicates().
Intrare -
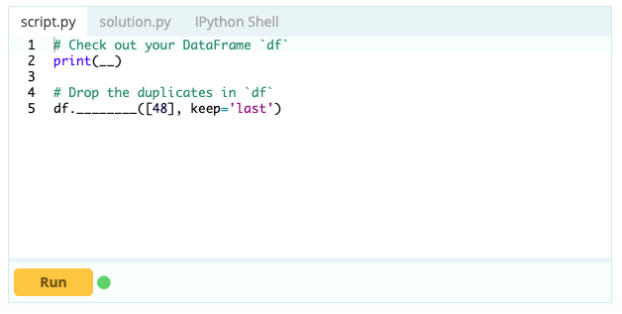
Ieșire –
Surse: Tutorialspoint Datacamp
Concluzie
Deci, există tutorialul tău de bază pentru Data Frame în Python folosind Pandas.
Dacă sunteți interesat să învățați Python, știința datelor, consultați Diploma PG în știința datelor de la IIIT-B și upGrad, care este creată pentru profesioniști care lucrează și oferă peste 10 studii de caz și proiecte, ateliere practice practice, mentorat cu experți din industrie, 1-la-1 cu mentori din industrie, peste 400 de ore de învățare și asistență profesională cu firme de top.
De ce este Pandas una dintre cele mai preferate biblioteci pentru a crea cadre de date în Python?
Biblioteca Pandas este considerată a fi cea mai potrivită pentru crearea de cadre de date, deoarece oferă diverse caracteristici care fac eficientă crearea unui cadru de date. Unele dintre aceste caracteristici sunt următoarele: Pandas ne oferă diverse cadre de date care nu numai că permit o reprezentare eficientă a datelor, dar ne permit și să le manipulăm. Oferă funcții eficiente de aliniere și indexare care oferă modalități inteligente de etichetare și organizare a datelor. Unele caracteristici ale Pandas fac codul curat și îi sporesc lizibilitatea, făcându-l astfel mai eficient. De asemenea, poate citi mai multe formate de fișiere. JSON, CSV, HDF5 și Excel sunt unele dintre formatele de fișiere acceptate de Pandas. Fuzionarea mai multor seturi de date a fost o adevărată provocare pentru mulți programatori. Pandas depășesc acest lucru și îmbină mai multe seturi de date foarte eficient.
Care sunt celelalte biblioteci și instrumente care completează biblioteca Pandas?
Pandas nu numai că funcționează ca o bibliotecă centrală pentru crearea cadrelor de date, dar funcționează și cu alte biblioteci și instrumente Python pentru a fi mai eficient. Pandas este construit pe pachetul NumPy Python, ceea ce indică faptul că cea mai mare parte a structurii bibliotecii Pandas este replicată din pachetul NumPy. Analiza statistică a datelor din biblioteca Pandas este operată de SciPy, funcții de trasare pe Matplotlib și algoritmi de învățare automată în Scikit-learn. Jupyter Notebook este un mediu interactiv bazat pe web care funcționează ca IDE și oferă un mediu bun pentru Pandas.
Care sunt operațiunile fundamentale ale cadrului de date?
Selectarea unui index sau a unei coloane înainte de a începe orice operațiune, cum ar fi adăugarea sau ștergerea, este importantă. Odată ce învățați cum să accesați valori și să selectați coloane dintr-un cadru de date, puteți învăța să adăugați index, rând sau coloană într-un cadru de date Pandas. Dacă indexul din cadrul de date nu iese așa cum doriți, îl puteți reseta. Pentru resetarea indexului, puteți utiliza funcția „reset_index()”.