
Adăugarea de capacități de divizare a codului unui site WordPress prin PoP
Publicat: 2022-03-10Viteza este printre prioritățile de top pentru orice site în zilele noastre. O modalitate de a face un site să se încarce mai rapid este prin împărțirea codului: împărțirea unei aplicații în bucăți care pot fi încărcate la cerere - încărcarea numai a JavaScript-ului necesar și nimic altceva. Site-urile web bazate pe cadre JavaScript pot implementa imediat divizarea codului prin Webpack, popularul bundler JavaScript. Pentru site-urile WordPress, totuși, nu este atât de ușor. În primul rând, Webpack nu a fost creat în mod intenționat pentru a funcționa cu WordPress, așa că configurarea acestuia va necesita o soluție destul de mare; în al doilea rând, nu pare să fie disponibil niciun instrument care să ofere capabilități native de încărcare a activelor la cerere pentru WordPress.
Având în vedere această lipsă a unei soluții adecvate pentru WordPress, am decis să implementez propria mea versiune de divizare a codului pentru PoP, un cadru open-source pentru construirea de site-uri web WordPress pe care l-am creat. Un site web WordPress cu PoP instalat va avea capabilități de divizare a codului în mod nativ, așa că nu va trebui să depindă de Webpack sau de orice alt bundler. În acest articol, vă voi arăta cum se face, explicând ce decizii au fost luate pe baza unor aspecte ale arhitecturii framework-ului. În cele din urmă, voi analiza performanța unui site web cu și fără divizarea codului, precum și beneficiile și dezavantajele utilizării unei implementări personalizate față de un bundler extern. Sper să vă placă călătoria!
Definirea Strategiei
Divizarea codului poate fi împărțită pe scară largă în acești doi pași:
- Calcularea activelor care trebuie încărcate pentru fiecare rută,
- Încărcarea dinamică a acestor active la cerere.
Pentru a aborda primul pas, va trebui să producem o hartă a dependenței de active, care să includă toate activele din aplicația noastră. Activele trebuie adăugate recursiv pe această hartă - trebuie adăugate și dependențe ale dependențelor, până când nu este nevoie de un alt activ. Putem calcula apoi toate dependențele necesare pentru o anumită rută parcurgând harta dependenței de active, pornind de la punctul de intrare al rutei (adică fișierul sau bucata de cod de la care începe execuția) până la ultimul nivel.
Pentru a face față celui de-al doilea pas, am putea calcula ce active sunt necesare pentru adresa URL solicitată de pe partea serverului și apoi fie să trimitem lista de active necesare în răspuns, pe care aplicația ar trebui să le încarce, fie direct HTTP/ 2 împingeți resursele alături de răspuns.
Aceste soluții, însă, nu sunt optime. În primul caz, aplicația trebuie să solicite toate activele după ce răspunsul este returnat, astfel încât ar exista o serie suplimentară de solicitări dus-întors pentru a prelua activele, iar vizualizarea nu a putut fi generată înainte ca toate acestea să se fi încărcat, rezultând în utilizatorul trebuie să aștepte (această problemă este atenuată prin precachearea tuturor activelor prin intermediul lucrătorilor de servicii, astfel încât timpul de așteptare este redus, dar nu putem evita analizarea activelor care are loc numai după ce răspunsul este înapoi). În cel de-al doilea caz, am putea împinge aceleași active în mod repetat (cu excepția cazului în care adăugăm o logică suplimentară, cum ar fi să indice ce resurse am încărcat deja prin cookie-uri, dar acest lucru într-adevăr adaugă complexitate nedorită și blochează ca răspunsul să fie stocat în cache) și nu poate servi activele dintr-un CDN.
Din acest motiv, am decis ca această logică să se ocupe de partea clientului. O listă cu care sunt activele necesare pentru fiecare rută este pusă la dispoziția aplicației pe client, astfel încât acesta să știe deja care sunt activele necesare pentru adresa URL solicitată. Aceasta abordează problemele menționate mai sus:
- Activele pot fi încărcate imediat, fără a fi nevoie să așteptați răspunsul serverului. (Când cuplăm asta cu lucrătorii din service, putem fi destul de siguri că, până la întoarcerea răspunsului, toate resursele vor fi fost încărcate și analizate, astfel încât nu mai există timp de așteptare suplimentar.)
- Aplicația știe ce active s-au încărcat deja; prin urmare, nu va solicita toate activele necesare pentru acea rută, ci doar acele active care nu s-au încărcat încă.
Aspectul negativ al livrării acestei liste la front-end este că ar putea deveni grea, în funcție de dimensiunea site-ului web (cum ar fi câte rute pune la dispoziție). Trebuie să găsim o modalitate de a o încărca fără a crește timpul de încărcare perceput al aplicației. Mai multe despre asta mai târziu.
După ce am luat aceste decizii, putem trece la proiectarea și apoi implementarea divizării codului în aplicație. Pentru a facilita înțelegerea, procesul a fost împărțit în următorii pași:
- Înțelegerea arhitecturii aplicației,
- Cartografierea dependențelor de active,
- Listarea tuturor rutelor de aplicare,
- Generarea unei liste care definește ce active sunt necesare pentru fiecare rută,
- Încărcarea dinamică a activelor,
- Aplicarea optimizărilor.
Să intrăm direct în asta!
0. Înțelegerea arhitecturii aplicației
Va trebui să mapam relația tuturor activelor între ele. Să trecem peste particularitățile arhitecturii PoP pentru a proiecta cea mai potrivită soluție pentru atingerea acestui obiectiv.
PoP este un strat care înconjoară WordPress, permițându-ne să folosim WordPress ca CMS care alimentează aplicația, oferind totuși un cadru JavaScript personalizat pentru a reda conținut pe partea clientului pentru a construi site-uri web dinamice. Acesta redefinește componentele de construcție ale paginii web: în timp ce WordPress se bazează în prezent pe conceptul de șabloane ierarhice care produc HTML (cum ar fi single.php , home.php și archive.php ), PoP se bazează pe conceptul de „module, ” care sunt fie o funcționalitate atomică, fie o compoziție a altor module. Construirea unei aplicații PoP este asemănătoare cu jocul cu LEGO - stivuirea modulelor una peste alta sau împachetarea unele pe altele, creând în cele din urmă o structură mai complexă. De asemenea, ar putea fi considerată o implementare a designului atomic al lui Brad Frost și arată astfel:
Modulele pot fi grupate în entități de ordin superior, și anume: blocuri, grupuri de blocuri, secțiuni de pagină și niveluri superioare. Aceste entități sunt și ele module, doar cu proprietăți și responsabilități suplimentare, și se conțin unele pe altele urmând o arhitectură strict de sus în jos în care fiecare modul poate vedea și modifica proprietățile tuturor modulelor sale interioare. Relația dintre module este astfel:
- 1 topLevel conține N paginiSecțiuni,
- 1 paginăSecțiunea conține N blocuri sau blocuri,
- 1 blockGroup conține N blocuri sau blockGroups,
- 1 bloc conține N module,
- 1 modul conține N module, la infinit.
Executarea codului JavaScript în PoP
PoP creează în mod dinamic HTML, începând de la nivel de secțiune, repetând toate modulele de-a lungul liniei, redând fiecare dintre ele prin șablonul de ghidare predefinit al modulului și, în final, adăugând elementele corespunzătoare nou create în DOM. Odată făcut acest lucru, execută funcții JavaScript pe ele, care sunt predefinite modul cu modul.
PoP diferă de cadrele JavaScript (cum ar fi React și AngularJS) prin aceea că fluxul aplicației nu își are originea pe client, dar este configurat în continuare în back-end, în interiorul configurației modulului (care este codificat într-un obiect PHP). Influențat de cârligele de acțiune WordPress, PoP implementează un model de publicare-abonare:
- Fiecare modul definește ce funcții JavaScript trebuie executate pe elementele DOM nou create corespunzătoare, neștiind neapărat dinainte ce va executa acest cod sau de unde va veni.
- Obiectele JavaScript trebuie să înregistreze ce funcții JavaScript implementează.
- În cele din urmă, în timpul de execuție, PoP calculează ce obiecte JavaScript trebuie să execute ce funcții JavaScript și le invocă în mod corespunzător.
De exemplu, prin obiectul său PHP corespunzător, un modul calendar indică faptul că are nevoie ca funcția calendar să fie executată pe elementele sale DOM astfel:
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } Apoi, un obiect JavaScript - în acest caz, popFullCalendar - anunță că este implementată funcția calendar . Acest lucru se face apelând popJSLibraryManager.register :
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); În cele din urmă, popJSLibraryManager face potrivirea pe ceea ce execută ce cod. Permite obiectelor JavaScript să înregistreze funcțiile pe care le implementează și oferă o metodă de a executa o anumită funcție din toate obiectele JavaScript abonate:
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } După ce un nou element de calendar este adăugat la DOM, care are un ID calendar-293 , PoP va executa pur și simplu următoarea funcție:
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));Punct de intrare
Pentru PoP, punctul de intrare pentru executarea codului JavaScript este această linie de la sfârșitul rezultatului HTML:
<script type="text/javascript">popManager.init();</script> popManager.init() inițializează mai întâi cadrul front-end și apoi execută funcțiile JavaScript definite de toate modulele randate, așa cum s-a explicat mai sus. Mai jos este o formă foarte simplificată a acestei funcții (codul original este pe GitHub). Prin invocarea popJSLibraryManager.execute('pageSectionInitialized', pageSection) și popJSLibraryManager.execute('documentInitialized') , toate obiectele JavaScript care implementează acele funcții ( pageSectionInitialized și documentInitialized ) le vor executa.
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); Funcția runJSMethods execută metodele JavaScript definite pentru fiecare modul, începând de la pageSection, care este modulul cel mai de sus, și apoi în jos pentru toate blocurile sale interioare și modulele lor interne:
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);În rezumat, execuția JavaScript în PoP este slab cuplată: în loc să avem dependențe greu fixate, executăm funcții JavaScript prin cârlige la care se poate abona orice obiect JavaScript.
Pagini Web și API-uri
Un site web PoP este un API autoconsumat. În PoP, nu există nicio distincție între o pagină web și API: fiecare adresă URL returnează pagina web în mod implicit și, adăugând doar parametrul output=json , returnează API-ul său (de exemplu, getpop.org/en/ este un pagina web și getpop.org/en/?output=json este API-ul său). API-ul este folosit pentru redarea dinamică a conținutului în PoP; deci, atunci când faceți clic pe un link către o altă pagină, API-ul este ceea ce este solicitat, deoarece până atunci cadrul site-ului web se va fi încărcat (cum ar fi navigarea de sus și laterală) - atunci setul de resurse necesare pentru modul API se va încărca fi un subset al celui de pe pagina web. Va trebui să ținem cont de acest lucru atunci când calculăm dependențele pentru o rută: încărcarea rutei la prima încărcare a site-ului web sau încărcarea lui dinamic făcând clic pe un link va produce diferite seturi de active necesare.
Acestea sunt cele mai importante aspecte ale PoP care vor defini proiectarea și implementarea divizării codului. Să continuăm cu pasul următor.
1. Cartografierea activelor-dependențe
Am putea adăuga un fișier de configurare pentru fiecare fișier JavaScript, detaliind dependențele lor explicite. Cu toate acestea, acest lucru ar duplica codul și ar fi dificil de păstrat consecvent. O soluție mai curată ar fi păstrarea fișierelor JavaScript ca singura sursă de adevăr, extragerea codului din interiorul lor și apoi analizarea acestui cod pentru a recrea dependențele.
Metadatele pe care le căutăm în fișierele sursă JavaScript, pentru a putea recrea maparea, sunt următoarele:
- apeluri de metode interne, cum ar fi
this.runJSMethods(...); - apeluri de metode externe, cum ar fi
popJSRuntimeManager.getDOMElements(...); - toate aparițiile lui
popJSLibraryManager.execute(...), care execută o funcție JavaScript în toate acele obiecte care o implementează; - toate aparițiile lui
popJSLibraryManager.register(...), pentru a obține ce obiecte JavaScript implementează ce metode JavaScript.
Vom folosi jParser și jTokenizer pentru a tokeniza fișierele noastre sursă JavaScript în PHP și pentru a extrage metadatele, după cum urmează:
- Apelurile interne de metodă (cum ar fi
this.runJSMethods) sunt deduse atunci când se găsește următoarea secvență: fie tokenthissauthat+.+ un alt simbol, care este numele metodei interne (runJSMethods). - Apelurile de metode externe (cum ar fi
popJSRuntimeManager.getDOMElements) sunt deduse la găsirea următoarei secvențe: un token inclus în lista tuturor obiectelor JavaScript din aplicația noastră (vom avea nevoie de această listă în avans; în acest caz, va conține obiectulpopJSRuntimeManager) +.+ un alt simbol, care este numele metodei externe (getDOMElements). - Ori de câte ori găsim
popJSLibraryManager.execute("someFunctionName")deducem că metoda Javascript estesomeFunctionName. - Ori de câte ori găsim
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"])deducem obiectul JavascriptsomeJSObjectpentru a implementa metodesomeFunctionName1,someFunctionName2.
Am implementat scriptul, dar nu îl voi descrie aici. (Este prea lung nu aduce prea multă valoare, dar poate fi găsit în depozitul PoP). Scriptul, care rulează la solicitarea unei pagini interne pe serverul de dezvoltare a site-ului web (metodologie despre care am scris într-un articol anterior despre lucrătorii de servicii), va genera fișierul de mapare și îl va stoca pe server. Am pregătit un exemplu de fișier de mapare generat. Este un fișier JSON simplu, care conține următoarele atribute:
-
internalMethodCalls
Pentru fiecare obiect JavaScript, enumerați între ele dependențele de la funcțiile interne. -
externalMethodCalls
Pentru fiecare obiect JavaScript, enumerați dependențele de la funcțiile interne la funcțiile din alte obiecte JavaScript. -
publicMethods
Listați toate metodele înregistrate și, pentru fiecare metodă, ce obiecte JavaScript o implementează. -
methodExecutions
Pentru fiecare obiect JavaScript și fiecare funcție internă, listați toate metodele executate prinpopJSLibraryManager.execute('someMethodName').
Vă rugăm să rețineți că rezultatul nu este încă o hartă de dependență de active, ci mai degrabă o hartă de dependență de obiect JavaScript. Din această hartă, putem stabili, ori de câte ori se execută o funcție de la un obiect, ce alte obiecte vor fi și ele necesare. Mai trebuie să configuram ce obiecte JavaScript sunt conținute în fiecare activ, pentru toate activele (în scriptul jTokenizer, obiectele JavaScript sunt token-urile pe care le căutăm pentru a identifica apelurile de metodă externă, deci aceste informații sunt o intrare în script și pot nu poate fi obținut din fișierele sursă în sine). Acest lucru se face prin obiecte PHP ResourceLoaderProcessor , cum ar fi resourceloader-processor.php.
În cele din urmă, combinând harta și configurația, vom putea calcula toate activele necesare pentru fiecare rută din aplicație.
2. Listarea tuturor rutelor de aplicații
Trebuie să identificăm toate rutele disponibile în aplicația noastră. Pentru un site web WordPress, această listă va începe cu adresa URL din fiecare dintre ierarhiile de șabloane. Cele implementate pentru PoP sunt acestea:
- pagina de start: https://getpop.org/en/
- autor: https://getpop.org/en/u/leo/
- single: https://getpop.org/en/blog/new-feature-code-splitting/
- etichetă: https://getpop.org/en/tags/internet/
- pagina: https://getpop.org/en/philosophy/
- categorie: https://getpop.org/en/blog/ (categoria este implementată de fapt ca o pagină, pentru a elimina
category/din calea URL) - 404: https://getpop.org/en/this-page-does-not-exist/
Pentru fiecare dintre aceste ierarhii, trebuie să obținem toate rutele care produc o configurație unică (adică care va necesita un set unic de active). În cazul PoP, avem următoarele:
- pagina de start și 404 sunt unice.
- Paginile de etichete au întotdeauna aceeași configurație pentru orice etichetă. Astfel, o singură adresă URL pentru orice etichetă va fi suficientă.
- O singură postare depinde de combinația tipului de postare (cum ar fi „eveniment” sau „postare”) și categoria principală a postării (cum ar fi „blog” sau „articol”). Apoi, avem nevoie de o adresă URL pentru fiecare dintre aceste combinații.
- Configurația unei pagini de categorie depinde de categorie. Deci, vom avea nevoie de adresa URL a fiecărei categorii de postări.
- O pagină de autor depinde de rolul autorului („individ”, „organizație” sau „comunitate”). Deci, vom avea nevoie de adrese URL pentru trei autori, fiecare dintre ei având unul dintre aceste roluri.
- Fiecare pagină poate avea propria sa configurație („autentificare”, „contactați-ne”, „misiunea noastră” etc.). Deci, toate adresele URL ale paginilor trebuie adăugate la listă.
După cum vedem, lista este deja destul de lungă. În plus, aplicația noastră poate adăuga parametri la adresa URL care modifică configurația, eventual modificând și ce active sunt necesare. PoP, de exemplu, oferă adăugarea următorilor parametri URL:
- filă (
?tab=…), pentru a afișa o informație asociată: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors; - format (
?format=…), pentru a modifica modul în care sunt afișate datele: https://getpop.org/en/blog/?format=list; - target (
?target=…), pentru a deschide pagina într-o altă paginăSecțiune: https://getpop.org/en/add-post/?target=addons.
Unele dintre rutele inițiale pot avea unul, doi sau chiar trei dintre parametrii de mai sus, creând o gamă largă de combinații:
- un singur post: https://getpop.org/en/blog/new-feature-code-splitting/
- autorii unei singure postări: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- autorii unei singure postări ca listă: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- autorii unei singure postări ca o listă într-o fereastră modală: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
În rezumat, pentru PoP, toate rutele posibile sunt o combinație a următoarelor elemente:
- toate rutele inițiale ale ierarhiei șablonului;
- toate valorile diferite pentru care ierarhia va produce o configurație diferită;
- toate filele posibile pentru fiecare ierarhie (diferitele ierarhii pot avea valori diferite de file: O singură postare poate avea filele „autori” și „răspunsuri”, în timp ce un autor poate avea file „postări” și „adepți”);
- toate formatele posibile pentru fiecare filă (se pot aplica diferite file în formate diferite: fila „autori” poate avea formatul „hartă”, dar fila „răspunsuri” nu);
- toate țintele posibile indicând paginaSecțiuni în care poate fi afișată fiecare rută (în timp ce o postare poate fi creată în secțiunea principală sau într-o fereastră plutitoare, pagina „Partajați cu prietenii” poate fi setată să se deschidă într-o fereastră modală).
Prin urmare, pentru o aplicație ușor complexă, producerea listei cu toate rutele nu se poate face manual. Trebuie, atunci, să creăm un script care să extragă aceste informații din baza de date, să o manipulăm și, în final, să o scoatem în formatul necesar. Acest script va obține toate categoriile de postări, din care putem produce lista tuturor adreselor URL diferite ale paginilor de categorii și apoi, pentru fiecare categorie, interogați baza de date pentru orice postare sub aceeași, care va produce adresa URL pentru o singură categorie. postați în fiecare categorie și așa mai departe. Scriptul complet este disponibil, pornind de la function get_resources() , care expune cârlige care urmează să fie implementate de fiecare dintre cazurile ierarhice.
3. Generarea listei care definește ce active sunt necesare pentru fiecare rută
Până acum, avem harta dependenței de active și lista tuturor rutelor din aplicație. Acum este timpul să le combinăm pe cele două și să producem o listă care să indice, pentru fiecare rută, ce active sunt necesare.
Pentru a crea această listă, aplicăm următoarea procedură:
- Produceți o listă care să conțină toate metodele JavaScript care trebuie executate pentru fiecare rută:
Calculați modulele rutei, apoi obțineți configurația pentru fiecare modul, apoi extrageți din configurație ce funcții JavaScript trebuie să execute modulul și adăugați-le pe toate. - Apoi, parcurgeți harta dependenței de active pentru fiecare funcție JavaScript, adunați lista tuturor dependențelor necesare și adăugați-le pe toate împreună.
- În cele din urmă, adăugați șabloanele de ghidare necesare pentru a reda fiecare modul din acel traseu.
În plus, după cum sa menționat anterior, fiecare URL are moduri de pagină web și API, așa că trebuie să rulăm procedura de mai sus de două ori, o dată pentru fiecare mod (adică adăugând o dată parametrul output=json la URL, reprezentând ruta pentru modul API, și odată păstrând adresa URL neschimbată pentru modul pagină web). Vom produce apoi două liste, care vor avea utilizări diferite:

- Lista modurilor paginii web va fi utilizată la încărcarea inițială a site-ului web, astfel încât scripturile corespunzătoare pentru acea rută să fie incluse în răspunsul HTML inițial. Această listă va fi stocată pe server.
- Lista modurilor API va fi folosită la încărcarea dinamică a unei pagini de pe site. Această listă va fi încărcată pe client, pentru a permite aplicației să calculeze ce active suplimentare trebuie încărcate, la cerere, atunci când se face clic pe un link.
Cea mai mare parte a logicii a fost implementată pornind de la function add_resources_from_settingsprocessors($fetching_json, ...) , (o puteți găsi în depozit). Parametrul $fetching_json diferența între modurile pagină web ( false ) și API ( true ).
Când se rulează scriptul pentru modul pagină web, va scoate resourceloader-bundle-mapping.json, care este un obiect JSON cu următoarele proprietăți:
-
bundle-ids
Aceasta este o colecție de până la patru resurse (numele lor au fost modificate pentru mediul de producție:eq=>handlebars,er=>handlebars-helpers, etc.), grupate sub un ID de pachet. -
bundlegroup-ids
Aceasta este o colecție debundle-ids. Fiecare bundleGroup reprezintă un set unic de resurse. -
key-ids
Aceasta este maparea dintre rute (reprezentată prin hash-ul lor, care identifică setul de toate atributele care fac o rută unică) și bundleGroup-ul corespunzător.
După cum se poate observa, maparea dintre o rută și resursele sale nu este dreaptă. În loc să mapeze key-ids la o listă de resurse, le mapează la un bundleGroup unic, care este el însuși o listă de bundles și numai fiecare pachet este o listă de resources (cu până la patru elemente fiecare pachet). De ce s-a făcut așa? Aceasta servește la două scopuri:
- Ne permite să identificăm toate resursele într-un bundleGroup unic. Astfel, în loc să includem toate resursele în răspunsul HTML, putem include un activ JavaScript unic, care este fișierul bundleGroup corespunzător, care se grupează în toate resursele corespunzătoare. Acest lucru este util atunci când deservesc dispozitive care încă nu acceptă HTTP/2 și, de asemenea, va crește timpul de încărcare, deoarece Gzip-ul unui singur fișier pachet este mai eficient decât comprimarea fișierelor sale constitutive pe cont propriu și apoi adăugarea lor împreună. Alternativ, am putea încărca și o serie de pachete în loc de un bundleGroup unic, care este un compromis între resurse și bundleGroups (încărcarea pachetelor este mai lentă decât bundleGroups din cauza Gzip-ului, dar este mai performantă dacă invalidarea are loc des, astfel încât ar descărca numai pachetul actualizat și nu întregul bundleGroup). Scripturile pentru gruparea tuturor resurselor în pachete și bundleGroups se găsesc în filegenerator-bundles.php și filegenerator-bundlegroups.php.
- Împărțirea seturilor de resurse în pachete ne permite să identificăm modele comune (de exemplu, identificarea seturilor de patru resurse care sunt partajate între mai multe rute), permițând, în consecință, diferite rute să se conecteze la același pachet. Ca urmare, lista generată va avea o dimensiune mai mică. Acest lucru poate să nu fie de mare folos pentru lista de pagini web, care se află pe server, dar este grozav pentru lista API, care va fi încărcată pe client, așa cum vom vedea mai târziu.
Când se rulează scriptul pentru modul API, acesta va scoate fișierul resources.js, cu următoarele proprietăți:
-
bundlesșibundle-groupsservesc aceluiași scop ca și pentru modul de pagină web -
keysservesc, de asemenea, aceluiași scop cakey-idspentru modul pagină web. Cu toate acestea, în loc să aibă un hash ca cheie pentru a reprezenta ruta, este o concatenare a tuturor acelor atribute care fac o rută unică - în cazul nostru, formatul (f), tab (t) și țintă (r). -
sourceseste fișierul sursă pentru fiecare resursă. -
typeseste CSS sau JavaScript pentru fiecare resursă (deși, din motive de simplitate, nu am menționat în acest articol că resursele JavaScript pot seta și resursele CSS ca dependențe, iar modulele își pot încărca propriile active CSS, implementând strategia de încărcare CSS progresivă ). -
resourcescaptează ce bundleGroups trebuie încărcate pentru fiecare ierarhie. -
ordered-load-resourcesconține resursele care trebuie încărcate în ordine, pentru a preveni încărcarea scripturilor înainte de scripturile dependente (în mod implicit, sunt asincrone).
Vom explora cum să folosim acest fișier în secțiunea următoare.
4. Încărcarea dinamică a activelor
După cum sa menționat, lista de API-uri va fi încărcată pe client, astfel încât să putem începe încărcarea activelor necesare pentru o rută imediat după ce utilizatorul face clic pe un link.
Se încarcă scriptul de cartografiere
Fișierul JavaScript generat cu lista de resurse pentru toate rutele din aplicație nu este ușor - în acest caz, a ieșit la 85 KB (care este în sine optimizat, după ce au alterat numele resurselor și au produs pachete pentru a identifica modele comune pe rute) . Timpul de analiză nu ar trebui să fie un blocaj mare, deoarece analizarea JSON este de 10 ori mai rapidă decât analizarea JavaScript pentru aceleași date. Cu toate acestea, dimensiunea este o problemă din transferul de rețea, așa că trebuie să încărcăm acest script într-un mod care să nu afecteze timpul de încărcare perceput al aplicației și să nu țină utilizatorul să aștepte.
Soluția pe care am implementat-o este să precachezi acest fișier utilizând lucrători de serviciu, să îl încarc folosind defer , astfel încât să nu blocheze firul principal în timpul executării metodelor JavaScript critice și apoi să afișez un mesaj de notificare de rezervă dacă utilizatorul face clic pe un link înainte ca scriptul să se încarce: „Site-ul încă se încarcă, așteptați câteva momente pentru a da clic pe linkuri.” Acest lucru se realizează prin adăugarea unui div fix cu o clasă de ecran de loadingscreen plasat deasupra tuturor în timp ce scripturile se încarcă, apoi adăugând mesajul de notificare, cu o clasă de notificationmsg , în interiorul div, și aceste câteva linii de CSS:
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }O altă soluție este să împărțiți acest fișier în mai multe și să le încărcați progresiv după cum este necesar (o strategie pe care am codificat-o deja). Mai mult decât atât, fișierul de 85 KB include toate rutele posibile în aplicație, inclusiv rute precum „anunțurile autorului, afișate în miniaturi, afișate în fereastra modale”, care ar putea fi accesate o dată într-o lună albastră, dacă este deloc. Rutele care sunt accesate cel mai mult sunt abia câteva (home page, single, author, tag și toate paginile, toate fără atribute suplimentare), care ar trebui să producă un fișier mult mai mic, în apropiere de 30 KB.
Obținerea traseului de la adresa URL solicitată
Trebuie să putem identifica ruta din URL-ul solicitat. De exemplu:
-
https://getpop.org/en/u/leo/mapează traseul „autor”, -
https://getpop.org/en/u/leo/?tab=followershărți cu traseul „adepți ai autorului”, -
https://getpop.org/en/tags/internet/mapează traseul „tag”, -
https://getpop.org/en/tags/mapează traseul „pagina/tags/”, - și așa mai departe.
Pentru a realiza acest lucru, va trebui să evaluăm URL-ul și să deducem din acesta elementele care fac un traseu unic: ierarhia și toate atributele (format, filă și țintă). Identificarea atributelor nu este o problemă, deoarece aceștia sunt parametri din URL. Singura provocare este de a deduce ierarhia (acasă, autor, singur, pagină sau etichetă) din URL, potrivind adresa URL cu mai multe modele. De exemplu,
- Orice lucru care începe cu
https://getpop.org/en/u/este un autor. - Orice lucru care începe cu dar nu este tocmai
https://getpop.org/en/tags/este o etichetă. Dacă este exacthttps://getpop.org/en/tags/, atunci este o pagină. - Și așa mai departe.
Funcția de mai jos, implementată începând de la linia 321 a resourceloader.js, trebuie să fie alimentată cu o configurație cu modelele pentru toate aceste ierarhii. Mai întâi verifică dacă nu există o cale secundară în URL - caz în care, este „acasă”. Apoi, verifică unul câte unul pentru a se potrivi cu ierarhiile pentru „autor”, „etichetă” și „singur”. Dacă nu reușește cu niciuna dintre acestea, atunci este cazul implicit, care este „pagina”:
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };Deoarece toate datele necesare sunt deja în baza de date (toate categoriile, toate slug-urile de pagină etc.), vom executa un script pentru a crea automat acest fișier de configurare într-un mediu de dezvoltare sau de staging. The implemented script is resourceloader-config.php, which produces config.js with the URL patterns for the hierarchies “author”, “tag” and “single”, under the key “paths”:
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
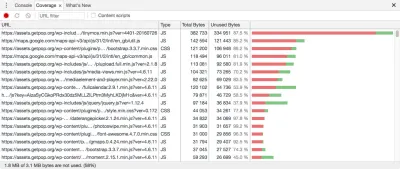
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
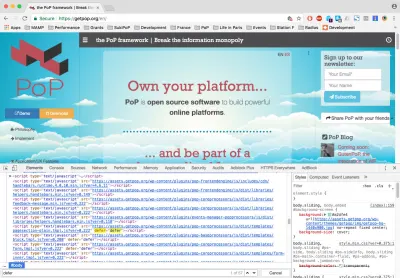
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
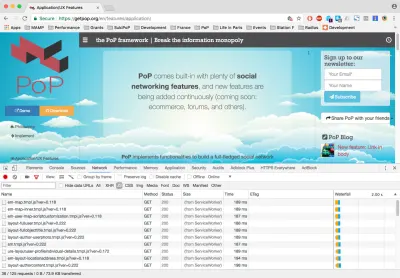
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
Dezavantaje
- Trebuie să-l menținem.
Dacă am folosi doar Webpack, ne-am putea baza pe comunitatea sa pentru a menține software-ul la zi și am putea beneficia de ecosistemul său de pluginuri. - Scripturile necesită timp pentru a rula.
Site-ul PoP Agenda Urbana are 304 de rute diferite, din care produce 422 de seturi de resurse unice. Pentru acest site web, rularea scriptului care generează harta dependenței de active, folosind un MacBook Pro din 2012, durează aproximativ 8 minute, iar rularea scriptului care generează listele cu toate resursele și creează pachetul și fișierele bundleGroup durează 15 minute. . Este timp mai mult decât suficient pentru a merge la o cafea! - Este nevoie de un mediu de scenă.
Dacă trebuie să așteptăm aproximativ 25 de minute pentru a rula scripturile, atunci nu îl putem rula în producție. Ar trebui să avem un mediu de pregătire cu exact aceeași configurație ca și sistemul de producție. - Cod suplimentar este adăugat pe site, doar pentru management.
Codul de 85 KB nu este funcțional în sine, ci pur și simplu codează pentru a gestiona alt cod. - Se adaugă complexitate.
Acest lucru este inevitabil în orice caz dacă dorim să ne împărțim activele în unități mai mici. Webpack ar adăuga, de asemenea, complexitate aplicației.
Avantaje
- Funcționează cu WordPress.
Webpack nu funcționează cu WordPress din cutie și pentru a-l face să funcționeze necesită o soluție destul de mare. Această soluție funcționează imediat pentru WordPress (atâta timp cât PoP este instalat). - Este scalabil și extensibil.
Dimensiunea și complexitatea aplicației pot crește fără limite, deoarece fișierele JavaScript sunt încărcate la cerere. - Acesta acceptă Gutenberg (alias WordPress-ul de mâine).
Deoarece ne permite să încărcăm framework-uri JavaScript la cerere, va suporta blocurile lui Gutenberg (numite Gutenblocks), care se așteaptă să fie codificate în cadrul ales de dezvoltator, rezultatul potențial al diferitelor framework-uri fiind necesare pentru aceeași aplicație. - Este convenabil.
Instrumentul de compilare se ocupă de generarea fișierelor de configurare. În afară de așteptare, nu este nevoie de niciun efort suplimentar din partea noastră. - Face optimizarea ușoară.
În prezent, dacă un plugin WordPress dorește să încarce selectiv active JavaScript, va folosi o mulțime de condiționale pentru a verifica dacă ID-ul paginii este cel corect. Cu acest instrument, nu este nevoie de asta; procesul este automat. - Aplicația se va încărca mai repede.
Acesta a fost motivul pentru care am codificat acest instrument. - Este nevoie de un mediu de scenă.
Un efect secundar pozitiv este creșterea fiabilității: nu vom rula scripturile în producție, așa că nu vom sparge nimic acolo; procesul de implementare nu va eșua din cauza unui comportament neașteptat; iar dezvoltatorul va fi obligat să testeze aplicația folosind aceeași configurație ca în producție. - Este personalizat pentru aplicația noastră.
Nu există costuri generale sau soluții alternative. Ceea ce obținem este exact ceea ce avem nevoie, pe baza arhitecturii cu care lucrăm.
În concluzie: da, merită, pentru că acum suntem capabili să aplicăm active de încărcare la cerere pe site-ul nostru WordPress și să îl facem să se încarce mai rapid.
Resurse suplimentare
- Webpack, inclusiv ghidul „”Code Splitting”.
- „Better Webpack Builds” (video), K. Adam White
Integrarea Webpack cu WordPress - „Gutenberg și WordPress-ul de mâine”, Morten Rand-Hendriksen, WP Tavern
- „WordPress explorează o abordare agnostică a cadrului JavaScript pentru construirea blocurilor Gutenberg”, Sarah Gooding, WP Tavern